1. Introduction
Deep learning technology is used ubiquitously in industry and is developing at an incredible rate. Therefore, the performance of simple classification and detection tasks using representative benchmark datasets such as ImageNet [
1], COCO [
2], and Pascal VOC [
3] is saturated. Accordingly, much research is being conducted in each field to perform special and applied tasks depending on the purpose of use. Problem area diagnosis and segmentation using medical images [
4,
5], small object detection using aerial imagery datasets [
6,
7], and object detection in SAR military imagery [
8,
9] are examples.
As the performance of SOTA models becomes saturated, they have high detection rates and accuracy in images that are not very complex. Nevertheless, performance improvement is still needed for partially overlapping objects or small objects. When 2D images and videos are used, small objects, having a limited number of pixels and low resolution, provide insufficient information for deep learning models to extract features through convolution operations. In particular, in the case of aerial image datasets such as DOTA [
10], compared to the very high resolution of up to 20,000 × 20,000, the spatial proportion of small objects is very small, as low as 10 pixels, and simple resizing and pooling operations performed during the learning process can cause information loss in small objects. Transformer-based models [
11,
12] have recently performed well and are topping the benchmark leaderboard. On the other hand, these models, which divide images into patches and perform attention operations [
13,
14,
15], may not be suitable for detecting small objects.
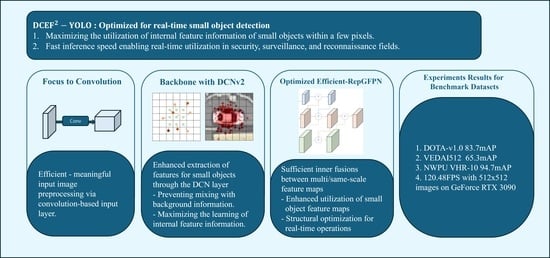
Accordingly, this study examines detection rate improvement from two major perspectives to detect small objects of 32 × 32 pixels or smaller in long-distance aerial images. Therefore, we propose aerial detection YOLO with deformable convolution-efficient feature fusion for small target detection (DCEF-YOLO; Deformable Convolution-Efficient Feature Fusion-YOLO).
Make full use of the internal feature information of small objects in a few pixels: The deformable convolution (DFConv) module was used for this purpose [
16,
17]. The convolution kernel is square in shape, so the object and surrounding background information may be mixed during operation. This can be fatal when learning tiny objects with a small amount of information and can be compensated for using the DFConv module, which allows the shape of the kernel to be modified. DFConv acquires the offset values through additional kernel training to adjust the sampling points of the kernel and performs sampling feature masking according to learning contribution through sampling weight. This was proposed to ensure that the kernel has an appropriate receptive field by training it to be robust to various forms of geometric transformations caused by camera angles, object posture or state, location, etc. And we expect to improve learning for small objects by preventing mixing with background information and focusing on areas of interest more effectively than possible with the original kernels. And several previous studies dealing with small object detection have confirmed that this actually leads to performance improvements. Ref. [
18] improved the detection accuracy of thin and rotated targets during remote sensing by replacing all convolution layers of YOLOv5 with DFConv and adding the box aspect ratio to the loss function to improve the detection accuracy for specific classes. In addition, in [
19,
20], DFConv was applied to YOLOv5 to detect small objects in complex environments, and channel-level attention was applied through a CBAM (convolutional block attention module), resulting in performance improvement. In this paper, in order to prevent an increase in the number of calculations, we found the optimal location and number of each module through experiments and applied them to the network to improve performance with minimal changes and applications.
Must be usable for real-time tasks: Small object detection in aerial images is expected to be used mainly in surveillance/reconnaissance and military fields, requiring onboard real-time task completion. Configuring the network to be complex in order to have good performance limits real-time operations. Therefore, YOLOv5 [
21] was used as the base model because it is lightweight but has good detection performance and scalability. In addition, Efficient-RepGFPN [
22], which performs various stages of feature fusion, was applied to make the most of the small object feature information extracted from the backbone. Unlike the YOLOv5 series, which perform relatively simple fusions in the neck, Efficient-RepGFPN performs sufficient inner fusion between multiple and same scales of feature maps to extract more meaningful information. However, this naturally brings a lot of computational cost and is not suitable for real-time tasks. Therefore, we optimize the structure considering performance and computational cost to suit our purpose and improve small object detection performance without computational overhead. In addition, the focus module of YOLOv5 was replaced with convolution-based processing, which is faster on a GPU, and the deformable convolution used in the backbone does not pose a large computational burden. Based on this, we propose a DCEF
-YOLO that is suitable for real-time tasks.
The contributions are summarized as follows:
- (1)
To make the most of a small amount of small object internal information, DCN and an optimized efficient feature fusion neck are applied. This actually improves the small object detection performance in the benchmark aerial dataset without significant computational burden. DCEF-YOLO improves mAP by 6.1% in DOTA, mAP by 1.5% in VEDAI, and mAP by 0.3% in NWPU VHR-10 compared to the latest comparison model.
- (2)
Each module and structure is applied through an appropriate number and location selection and optimization process in consideration of the amount of calculation for real-time tasks. Accordingly, DCEF-YOLO has the smallest amount of calculations (GFLOPs) compared to the comparative models, and shows a detection speed of 120.48 FPS on 512 × 512 images.
Section 2 introduces the recent research trends related to small object detection in aerial images and briefly explains YOLOv5, which was selected as the base model.
Section 3 explains the DCN module, optimization of Efficient-RepGFPN, and the focus to conv function.
Section 4 evaluates the network performance using several public datasets, and
Section 5 presents the conclusions.
3. Methods
Figure 3 presents the overall structure of DCEF
-YOLO. Based on the YOLOv5s model, the focus module that processes the input image was replaced with convolution-based processing. A deformable convolution module was applied in the backbone to extract meaningful small object features. The relatively simple existing neck was replaced with an optimized version of Efficient-RepGFPN, which undergoes sufficient fusion. These improvements enable small object detection in aerial images with high real-time performance.
Section 3.1 explains the DFConv module.
Section 3.2 and
Section 3.3 explain Optimized-Efficient-RepGFPN, and focus to conv, respectively.
3.1. DCN
Figure 4 presents the operation of deformable convolution. Unlike basic convolution, which uses a 3 × 3 square kernel (first from the left), DCNv1 (second from the left) uses the sampling offset to adjust the sampling position, and DCNv2 (second from the right) uses the sampling weight to improve the detection accuracy. The first picture on the right is an example of a kernel with a sampling offset applied, which was the output after training in DCEF
-YOLO.
Deformable convolution (DFConv) was used to derive meaningful small object feature extraction in the YOLOv5 backbone. DCNv1 [
16] presented the first deformable convolution–deformable ROI (region of interest) pooling concept that utilizes a learnable sampling offset. Deformable convolution obtains an offset value through additional kernel training performed simultaneously with the existing kernel training and performs a transformation of the sampling position of the kernel. Through this, it fits the object more closely than basic convolution and becomes robust against geometric transformations. On the other hand, even if a deformable offset is given, the sampling space may still deviate from the area of interest. By DCNv2 [
17], an additional sampling weight value is introduced to compensate for this. The sampling weight is also obtained through additional kernel training, where a large value is weighted if the sampled location significantly influences learning the correct answer by belonging to the characteristics of the object, and conversely, a small value is weighted. Deformable convolution can be confirmed by the following formula.
Assuming a 3 × 3 kernel with a dilation of 1, the output feature map for each position through a general convolution operation has the following values:
where
= (−1, −1), (−1, 0), …, (1, 1), which is the existing kernel sampling location;
x is the input feature map;
y is the output feature map;
is the weight for each sampling position. The output of the DCNv2 kernel reflecting the sampling offset and sampling weight is as follows:
The DCNv2 kernel multiplies the output from , which reflects the sampling offset , by the sampling weight , which is between 0 and 1. At this time, is a fractional value obtained through a bilinear interpolation kernel . The sampling offset and sampling weight are obtained through separate convolution training, and the values of the 3K channels are finally output: 2K channels with learnable offsets in the x- and y-directions and K channels with sampling weight scalar values that can be obtained through a sigmoid function.
We use a DCNv2 kernel (DFConv in this paper) to derive meaningful small object feature extraction from the YOLOv5 backbone. As shown in
Table 2, when the DFConv module was applied, the recall improved by 3.2%, and the classification precision and mAP@0.5 improved by 3.3% and 2.2%, respectively. However, during the experiment, we discovered that stable learning can be difficult in small object detection tasks if an appropriate convergence direction is not found in the early stages of learning. This is presumed to be derived from the fact that parallel training is performed using two kernels (offset and existing feature extraction) simultaneously and that object information is lacking. We confirmed that applying DFConv at the layer immediately before SPP after learning enough about the input, rather than applying many DFConv modules, is the most stable method and results in sufficient performance improvement.
Table 3 presents a performance comparison based on the location and number of DFConv modules. The backbone of YOLOv5 consists of nine layers, excluding the input stage, as shown in
Figure 2. The labels (3), (5), and (7) in the table indicate the application positions of the DFConv module. We applied one to three DFConv modules and compared their performance. In
Table 3, when one DFConv module was located in the (7) layer immediately before the SPP, the F1 score, which is an indicator of the precision–recall balance, was the highest, and the overall performance was the best, so stable training and general-purpose application to new data were possible. On the other hand, the model showed a tendency to diverge when three layers were replaced.
3.2. Efficient-RepGFPN
We adopt the Efficient-RepGFPN structure, which performs sufficient feature map fusion to make full use of the small object information extracted through the DFConv module. Efficient-RepGFPN improves detection performance through sufficient inner fusions between multi/same-scale feature maps, but this naturally leads to a large increase in the amount of computation. Accordingly, we optimize the structure by reducing the neck and detection head to suit real-time small object detection tasks. DCEF-YOLO performs detection using only one feature map that has undergone sufficient fusion, which efficiently detects small objects without imposing a computational burden compared to detection with the three feature maps of the existing YOLOv5.
GFPN (Generalized-FPN) [
46], the base of Efficient-RepGFPN, is a structure proposed to compensate for the fact that FPN [
47], PAFP [
48], and BiFPN [
49] only focus on the fusion of feature maps of different resolutions and lack connections between internal layers. A deep network was formed without significantly increasing computational complexity by adjusting the shortest gradient distance through log2n-link. Moreover, it fuses all feature maps from the current, previous, and subsequent layers through queen fusion by going beyond the existing structure that only performs feature map fusion between the current and previous layers. RepGFPN provides feature maps containing rich information to the detection head through sufficient feature fusion but was limited in its use in real-time applications. Therefore, DAMO-YOLO proposes Efficient-RepGFPN (called E-RGFPN), which optimizes GFPN and improves its performance.
E-RGFPN improves GFPN in three aspects. (1) Adjustment of channel depth by scale: GFPN unifies the channel depth of feature maps for each scale. In E-RGFPN, however, higher performance was achieved at a flexible channel depth of (96, 192, 384) by considering the trade-off between the channel depth for each scale and the fusion bottleneck width. (2) Adjustment of the number of upsampling operators: The number of upsampling operators in the overall structure was adjusted, suggesting that the upsampling operation and the corresponding connection layer do not significantly improve performance compared to the delay time. (3) Fusion block improvement: Convolution-based fusion was replaced with CSPNet [
45], and re-parameterization and ELAN were applied like in YOLOv7 [
50] to improve the accuracy without increasing the inference cost. Re-parameterization [
51,
52] optimizes the shared and task-specific weights through two convolutions. For task-specific loss, only the relevant weights were optimized to reduce the interference between tasks, and at the inference time, only shared weights optimized for joint indicators of interest were used, allowing for general-purpose application to a wide range of data without increasing the inference costs. ELAN [
53] designed an efficient propagation path hierarchical aggregation structure by controlling the longest and shortest gradient paths, with the view that a shorter gradient length indicates more powerful network learning. This solved the problem of low convergence when expanding the network and amplified the usability of gradients.
DCEF
-YOLO uses only the medium-sized output feature map through E-RGFPN for detection. Since the final output feature map that passes the backbone has a considerably lower spatial resolution than the input, by combining it with a low-level feature map, the information can be meaningfully utilized in a wider image unit at detection. At this time, the size of the object that is mainly referenced and detected varies according to the size of the feature map. The feature maps with small sizes and deep channels through several layers mainly contribute to detecting large objects and learning the overall context of the image. And the feature maps with relatively large sizes and shallow channels containing the wide part of the image contribute to small object detection. Therefore, in some networks for which primary purpose is small object detection, medium or larger object detection layers are removed for efficient and intensive training [
6,
7].
In
Figure 5, Efficient-RepGFPN finally outputs feature maps with three scales: s, m, and l. In this case, the l-scale feature map has relatively less fusion between multi-scale maps, and the s-scale feature map lacks information for small object detection because of the loss of spatial dimension information during the resizing process. On the other hand, for medium-sized feature maps, fusion between small- and large-sized feature maps is relatively sufficient. The medium-sized feature map that is finally output after fusion reflects high-level semantic information and low-level spatial information, so it will be useful on its own for small object detection tasks. Accordingly, we reduced the neck structure to use only the m-scale feature map for the real-time detection task, which ultimately made it possible to utilize feature information at various levels without incurring a large computational burden.
Table 4 shows a comparison before and after application of Efficient-RepGFPN. Compared to the case for which the structure was not applied, recall increased by 1.2% and mAP increased by up to 3.5%. And when comparing results by feature map sizes, it can be seen that the m-scale feature map resulted in the best performance.
3.3. Focus to Conv
YOLOv5 uses the focus module to adjust the size of network input images. The focus module expands the image from the spatial dimension to the depth dimension and generates an image with an appropriate resolution and a deeper channel for convolution operations. In this process, the image is divided into grid units and is processed, which can cause information loss in small objects, similar to the patch embedding of the transformer mentioned above. In YOLOv6 [
54], the focus module was replaced with convolution-based processing for faster computation on the GPU. According to [
7], this change improves small object detection model performance because during the training process, the corresponding input image processing convolution operation is also trained to improve the detection performance.
Figure 6 compares the focus module and the convolution-based input preprocessing stage, and
Table 5 compares the performance according to whether or not the focus module was replaced. Considerable improvement in small object learning performance was achieved.
4. Experimental Results
In this study, we evaluated the comprehensive detection performance of DCEF-YOLO using DOTA and NWPU VHR-10, which are well-known aerial object detection benchmark datasets, as well as the VEDAI dataset, which specifically focuses on small objects. Our proposed model exhibited a mAP improvement of +6.1% compared to the baseline model on the DOTA-v1.0 test set, +1.5% on the VEDAI512 test set, and +0.3% on the NWPU VHR-10 test set. Using a GeFore RTX 3090, the network had a detection speed of 120.48 FPS on 512 × 512 images, confirming its suitability as a real-time small object detection model for aerial images. DOTA and VEDAI image results are compared with the results of training each aerial dataset on YOLOv7, which is widely recognized as a superior object detector in terms of speed and accuracy. Furthermore, through inference on the NWPU VHR-10 test set, we conducted a comparison between the detection results and the ground truth and analyzed the detection performance of the proposed network.
4.1. DOTA
DOTA is a large-scale dataset for object detection in aerial images [
10], consists of images collected by Google Earth, GF-2, and JL-1 satellites, and is provided by the Chinese Center for Resources for Satellite Data and Applications. The dataset contains objects of various sizes, orientations, and shapes and consists of RGB images and gray-scale images with various resolutions ranging from 800 × 800 to 20,000 × 20,000 pixels. DOTA provides oriented and horizontal bounding box annotation and is currently available in three versions: DOTA-v1.0, v1.5, and v2.0.
The proposed model was evaluated on the DOTA-v1.0 (HBB) dataset. For fair verification,
Table 6 shows a comparison using the same settings as Tian et al. [
39]. The DOTA dataset is utilized for training by dividing it into patches due to its irregular and very large image size. All images were divided into patches with a size of 1024 × 1024 and with an overlap range of 200 pixels, and 10,000 patches were randomly selected and divided at a ratio of 7:1:2 and used as training, validation, and test sets, respectively. Training lasted for 150 epochs. The dataset consisted of 15 classes: plane (PL), baseball diamond (BD), bridge (BR), ground track field (GTF), small vehicle (SV), large vehicle (LV), ship (SH), tennis court (TC), basketball court (BC), storage tank (ST), soccer ball field (SBF), roundabout (RA), harbor (HA), swimming pool (SP), and helicopter (HC).
Figure 7 is an example of detection results for the DOTA test set.
Table 6 compares the performance of the proposed model with the SOTA model DCN-YOLO announced in July 2023 and other YOLO-based models. DCEF
-YOLO showed improved performance by mAP@0.5 +6.1% and mAP@0.5:0.95 +3.9% with the lowest computational cost (from -2 GFLOPs up to -60.2 GFLOPs). This proves that DCEF
-YOLO has successfully achieved low computation and high detection performance through appropriate optimization and combination of each structure and module. Furthermore, the verification results were compared according to the object size. Similar to the COCO benchmark method, the results were divided into small- and medium-sized objects of 32 × 32 pixels and 96 × 96 pixels, respectively, and AP values were calculated for each size. The proposed model, which focuses on improving the performance of small object detection in aerial images, showed significantly improved performance in
and
, which are small and medium object detection results, respectively. This proves that the proposed model can be effectively applied to aerial detection tasks and shows good performance.
Table 7 compares the results of sufficient training for 300 epochs by class for all patches rather than 10,000 patches to verify the scalability of the proposed model. Compared to the training results of 150 epochs on 10,000 randomly selected patches in
Table 6, mAP@0.5 showed an improvement of +14.2% to 83.7mAP@0.5. This is similar performance to the DOTA-v1.0 benchmark model. Therefore, DCEF
-YOLO can bring about a clear performance improvement after sufficient training with a sufficient dataset. And for inference purposes,
Figure 8 is an example of detection results for the entire image rather than a patch image. It can be observed that the proposed network consistently delivers more stable detection results compared to YOLOv7.
4.2. VEDAI
VEDAI is a dataset for vehicle detection in aerial images [
32] and provides RGB and IR image sets that are 512 × 512 and 1024 × 1024 in size. Each consists of approximately 1200 images, and a 512 × 512 RGB set was used to verify the performance of the proposed model. Each image has a spatial resolution of 25 cm at 512 × 512 and contains 3757 small instances from 8 to 20 pixels in width. The dataset was divided at a ratio of 8:1:1 for training, validation, and test sets, respectively. The dataset includes nine classes: car, truck, pickup, tractor, camper, boat, van, plane, and other instances.
Table 8 compares the performance with YOLO-based models, and
Table 9 compares the detection performance by class with [
6,
7,
55], which were also proposed for aerial object detection.
In
Table 8, DCEF
-YOLO showed the best balance between detection rate and accuracy (F1 score) and the highest detection rate and mAP compared to the comparison models. In particular, compared to YOLOv7, there was a 12.1% improvement in detection rate and a 25.4% improvement in mAP. Additionally, when compared to the model proposed for small object detection [
55] in June 2023, there was a mAP improvement of 1.5%. And the computational amount was also 36 GFLOPs lower than the YOLOv5-based small object detection comparison model and 7.1 GFLOPs lower than YOLOv7. YOLOv7 has superior processing speed among object detectors, and with the VEDAI dataset, it has a processing speed of 88.49 FPS. However, DCEF
-YOLO has a processing speed of 120.48 FPS. This means that 31.99 more images per second can be processed with the proposed method with high performance even with higher efficiency.
Figure 9 is an comparison of detection results on VEDAI test set. By comparing the results with YOLOv7, it is evident that the proposed network exhibits significantly more stable and accurate detection of small objects.
4.3. NWPU VHR-10
The NWPU VHR-10 dataset [
37] comprises 800 high-resolution remote sensing images collected from Google Earth and Vaihingen that have been annotated manually by experts. It provides 650 labeled images and 150 negative images without objects, with images having widths ranging from around 400 to 1000 pixels. It contains 3775 instances with widths and heights ranging from around 20 to 400 pixels and primarily consisting of medium-sized objects. We utilized NWPU VHR-10 for experimentation to verify the scalability of the network and for comprehensive performance analysis. We split the 650 labeled images into a ratio of 8:2 for training and testing, respectively. The dataset consists of 10 classes: airplane (AP), ship (SH), storage tank (ST), baseball diamond (BD), tennis court (TC), basketball court (BC), ground track field (GT), harbor (HA), bridge (BR), and vehicle (VE).
The proposed network achieved a precision of 90.7% and a mAP@0.5 of 94.7% at a recall of 93.1%. Furthermore, even with a relatively lower recall of approximately 89.3%, the mAP@0.5 increased to 95.7%. We compared the performance of the first training result, which achieved sufficiently high recall, with recent aerial image-based detection networks.
Table 10 compares the detection performance on the NWPU VHR-10 test set. The proposed network exhibited a mAP 0.3% higher than the top-performing MSCCA [
56] among the comparison networks, +0.6% compared to DS-YOLOv8 [
57], which was proposed in 2023, and +1.3% compared to SuperYOLO [
7], which was proposed in 2022.
Table 11 compares the detection performance class-wise. The highest values are highlighted in bold, and the second-highest values are underlined. Despite most objects being medium-sized or larger, the proposed network consistently exhibits high detection performance among the compared networks, achieving mAPs exceeding 90% for all classes except VE.
Figure 10 shows the inference images for NWPU VHR-10, while
Figure 11 specifically focuses on the inference images for the VE class. Here, we were able to identify the reason for the relatively low mAP of the proposed network for VE through the inference images.
Figure 11 depicts the detection of unlabeled vehicles that are partially visible in the image. This indicates that objects were detected even when only a portion of them was visible, showcasing the network’s effective utilization of internal object information. Such instances were particularly common, especially in the VE class. In other classes, it was observed that the proposed network often produced bounding boxes that better fit the objects compared to the ground truth bounding boxes. This issue stems from the limitations of manually labeled datasets and potentially impacts numerical detection performance metrics like recall and mAP. However, these results ultimately affirm the proposed network’s capability to accurately detect objects even in situations where feature information is lacking.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









