1. Introduction
With the rapid development of remote sensing technologies, remote sensing images are gradually becoming versatile and have been widely applied in many domains: including scene classification [
1], target detection [
2], denoising [
3], and spectral unmixing [
4]. There are two commonly prevalent categories remote sensing images: hyperspectral image (HSI) and panchromatic image (PAN). The HSI records abundant spectral information by densely sampling dozens or even hundreds of continuous spectral bands from visible to infrared wavelengths. The extensive spectral coverage empowers the identification of various materials on Earth through spectral signatures [
5]. However, the spatial resolution of HSI is low. In contrast to HSI, PAN excel in recording the elaborate textural details of ground objects within a single spectral band. Restricted by the hardware limitations, the hyperspectral imaging system cannot captures a remote sensing images with both high spectral and spatial quality. The cost of high spectral resolution for HSI is blurry textural details. The absence of spatial information in HSI significantly hinders its application potential. Therefore, it becomes imperative to leverage super-resolution techniques to enhance the spatial resolution of HSI. These methods can be broadly categorized into two types: single-image super-resolution (SISR) and multi-image super-resolution (MISR) [
6]. While SISR applies the super-resolution algorithm solely to a single HSI without auxiliary PAN, MISR boosts the spatial resolution of HSI by incorporating the refined textural details from PAN. This integration often yields superior super-resolution performance in terms of both spectral and spatial fidelity. In general, MISR is commonly referred as hyperspectral (HS) pansharpening by the official.
To obtain high spatial resolution HSI, numerous pansharpening approaches have been proposed over the past few decades, which can be divided into traditional and emerging methods. Among traditional methods, component substitution (CS)-based methods depend on replacement of the spatial component of the source HSI with the corresponding PAN, which includes Intensity-Hue-Saturation (IHS) [
7], Brovey [
8], Principal Component Analysis (PCA) [
9], Gram-Schmidt (GS) [
10], and Gram-Schmidt Adaptive (GSA) [
11]. While CS-based methods effectively achieve the transmission of the spatial information from PAN to HSI, they often introduce spectral distortions in the pansharpened image. In contrast, multi resolution analysis (MRA)-based methods begin by decomposing the source HSI and PAN into different scales using a multi-scale decomposition algorithm. Subsequently, the spectral and spatial features are fused within each scale. The family of MRA-based methods mainly involve Smoothing Filter-based Intensity Modulation (SFIM) [
12], Generalized Laplacian Pyramid (GLP) with Modulation Transfer Function (MTF) matched filter (MTF-GLP) [
13], MTF-GLP with High-Pass Modulation (MTF-GLP-HPM) [
14]. Unlike CS-based methods, MRA-based methods demonstrate superior performance in spectral preservation, albeit at the expense of introducing spatial distortions in the pansharpened image. In addition to these purely CS- or MRA-based methods, hybrid approaches for HS pansharpening have also been studied. Examples include guided filter PCA (GFPCA) [
15], which simultaneously inherit the advantages of both CS- and MRA-based methods. In addition to above approaches, variational optimization (VO)-based methods approach HS pansharpening as an optimization problem, formulating a constrained objective function with prior knowledge derived from the source HSI, PAN, and the ideal HSI. Interactive optimization algorithms are typically employed to find suitable solutions. Representative examples include Coupled Non-negative Matrix Factorization (CNMF) [
16], Convex Regularization under a Bayesian Gaussian prior (HySure) [
17], and naive Bayesian Gaussian prior (BF) [
18]. While VO-based methods yield relatively high pansharpening quality, they are often characterized by slow processing speeds and challenging fine-tuning requirements.
The advantages and shortcomings of different categories HS pansharpening methods have been represented in
Table 1. In a word, traditional methods often suffer from inadequate representation ability or inappropriate assumptions, resulting in notable spectral and spatial distortions in the pansharpened image.
In recent years, deep learning (DL)-based methods, especially convolutional neural network (CNN), gradually emerge as a transformative solution for HS pansharpening. Leveraging their powerful capabilities of feature extraction and nonlinear optimization, CNN-based methods have already achieved state-of-the-art (SOTA) performance. Following the design philosophy of natural image super-resolution, Masi et al. [
19] introduced a pansharpening neural network (PNN) comprising three convolutional layers as an initial attempt. However, the performance of PNN is constrained due to its simple architecture and less parameters. Yang et al. [
20] developed PanNet, a pansharpening neural network that incorporates domain-specific knowledge, emphasizing both spectral preservation and spatial enhancement. To achieve spectral preservation, PanNet employs a direct propagation of spectral information through a summation operation between the up-sampled multispectral and reconstructed image. For spatial enhancement, PanNet is trained in the high-pass filtering domain rather than image domain. A lot of CNN-based methods [
21,
22,
23,
24] have been proposed to address HS pansharpening problem, achieving impressive performance. With the growing recognition of both convolution and HS pansharpening, the dual-branch design paradigm has emerged as a common approach. This paradigm involves the parallel processing of spectral and spatial information on two branches, followed by the integration of advanced spatial information into the spectral features through specially designed aggregation component. He et al. [
25] introduced HyperPNN, a spectrally predictive convolutional neural network designed for HS pansharpening. HyperPNN comprises two sub-networks: a spectral prediction sub-network dedicated to spectral prediction and a spatial-spectral inference sub-network aimed at leveraging both spectral and spatial contextual information. Wang et al. [
5] proposed a dual-path fusion network (DPFN) designed to capture both global spectral-spatial and local high-pass spatial information through two distinct learning paths. The model is trained using a combinatorial loss function, which includes pixel-wise mean square error (MSE) and feature-wise near-infrared-VGG loss, aiming to enhance performance. Qu [
26] proposed a dual-branch detail extraction pansharpening network (DBDENet) that can solve the pansharpening problem with any number of spectral bands. However, 2D CNNs are primarily adept at capturing spatial information along the width and height dimensions, making it challenging to preserve the spectral features of HSI data cubes. To address this limitation, Zheng et al. [
27] introduced an edge-conditioned feature transform network (EC-FTN) that utilizes 3D convolutional layers. This design enables the joint extraction of spectral and spatial features from HSI, resulting in the preservation of fine details and high spectral fidelity.
Despite the numerous CNN-based methods proposed for HS pansharpening, two critical issues persist:
Cross-Modality Dependency Modeling: In order to fuse the diverse modality information, most CNN-based methods often concatenate HSI with PAN in either the image domain or feature domain. However, concatenating a single spectral band PAN with dozens or even hundreds of spectral bands HSI fails to properly model the cross-modality dependencies between them.
Limited Exploitation of Global Information: CNN-based methods, constrained by their receptive field, typically focus on extracting local information from the input image. Unfortunately, this approach neglects the importance of global information. However, both local and global information are crucial for accurate pansharpening.
In addition to convolution, another emerging DL model, the transformer architecture, has shown promising prospect in computer vision community. Transformer exclusively relies on the self-attention mechanism, which enables the adjustment of each pixel based on the long-range dependencies of input features. Researchers have begun exploring transformer-based pansharpening model and there already exists some relevant works in the community. Meng et al. [
28] introduced a modified Vision Transformer (ViT) [
29] style model for HS pansharpening. Chaminda Bandara et al. [
30] proposed HyperTransformer, a textural-spectral feature fusion transformer. In HyperTransformer, an improved self-attention mechanism is designed to identify spectrally similar and texturally superior features for source HSI. Notably, the features of low spatial resolution HSI, down-sampled PAN, and PAN are formulated as Query, Key, and Value, respectively. HyperTransformer can extract cross-modality dependencies in a global manner, which is completely different to convolution. Moreover, Fusformer [
31] and Panformer [
32] have further verified the performance of transformer architecture for pansharpening. While several Transformer-based HS pansharpening methods have been explored, challenges persist (
Table 2):
Modification of Self-Attention Mechanism: In general, the self-attention mechanism depends on a large-scale learning sample images and consumes a higher computational and time cost. How to properly modify the self-attention mechanism to effectively and efficiently process the high spectral and spatial resolution remote sensing images remains a challenge.
Balancing Local and Global Information: In contrast to convolution, the self-attention mechanism intends to adjust each pixel value based on the long-range dependencies, potentially neglecting the local information.
Table 2.
Advantages and shortcomings of state-of-the-art deep learning based HS pansharpening methods.
Table 2.
Advantages and shortcomings of state-of-the-art deep learning based HS pansharpening methods.
| Method | Advantage | Shortcoming |
|---|
| DARN [24] | Insensitive to the scale ratio Trainable on less labeled images Acceptable spectral and spatial quality | Sensitive to the spectral bands |
| HyperKite [23] | Insensitive to the scale ratio Trainable on less labeled images Acceptable spectral and spatial quality | Sensitive to the spectral bands Large computational budget and memory |
| DBDENet [26] | Insensitive to the spectral bands Acceptable spectral and spatial quality | Sensitive to the scale ratio |
| Vision Transformer [28] | Extraction of global features Acceptable spectral and spatial quality | Sensitive to the image resolution Large computational budget and memory Depend on large scale dataset |
| HyperTransformer [30] | Extraction of both local and global features Impressive spectral and spatial quality | Hard to pre-train and fine tune Large computational budget and memory Depend on large scale dataset |
Recent research indicates that the properties of convolution and self-attention are complementary [
33], the authors designed a Convolutional Vision Transformer (CvT), which introduces convolutional token embedding and convolutional projection into the vision transformer to merge the advantages of self-attention and convolution. Liu et al. proposed the InteractFormer [
6], suitable for hyperspectral image super-resolution, capable of extracting and interacting both local and global features. However, they only stack them sequentially rather than designing a more integrated hybrid model. Pan et al. [
34] proposed that self-attention and convolution are essentially performed by the same operations. They designed a hybrid operator to combine them and applied it to image recognition tasks.
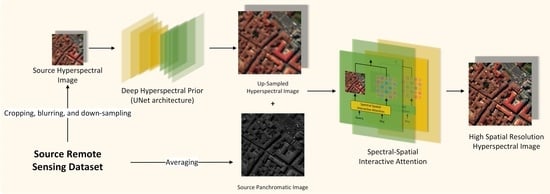
Motivated by aforementioned studies, we are encouraged to design a HS pansharpening model which can leverage the strengths of both paradigms and overcome their intrinsic drawbacks. Drawing inspiration from [
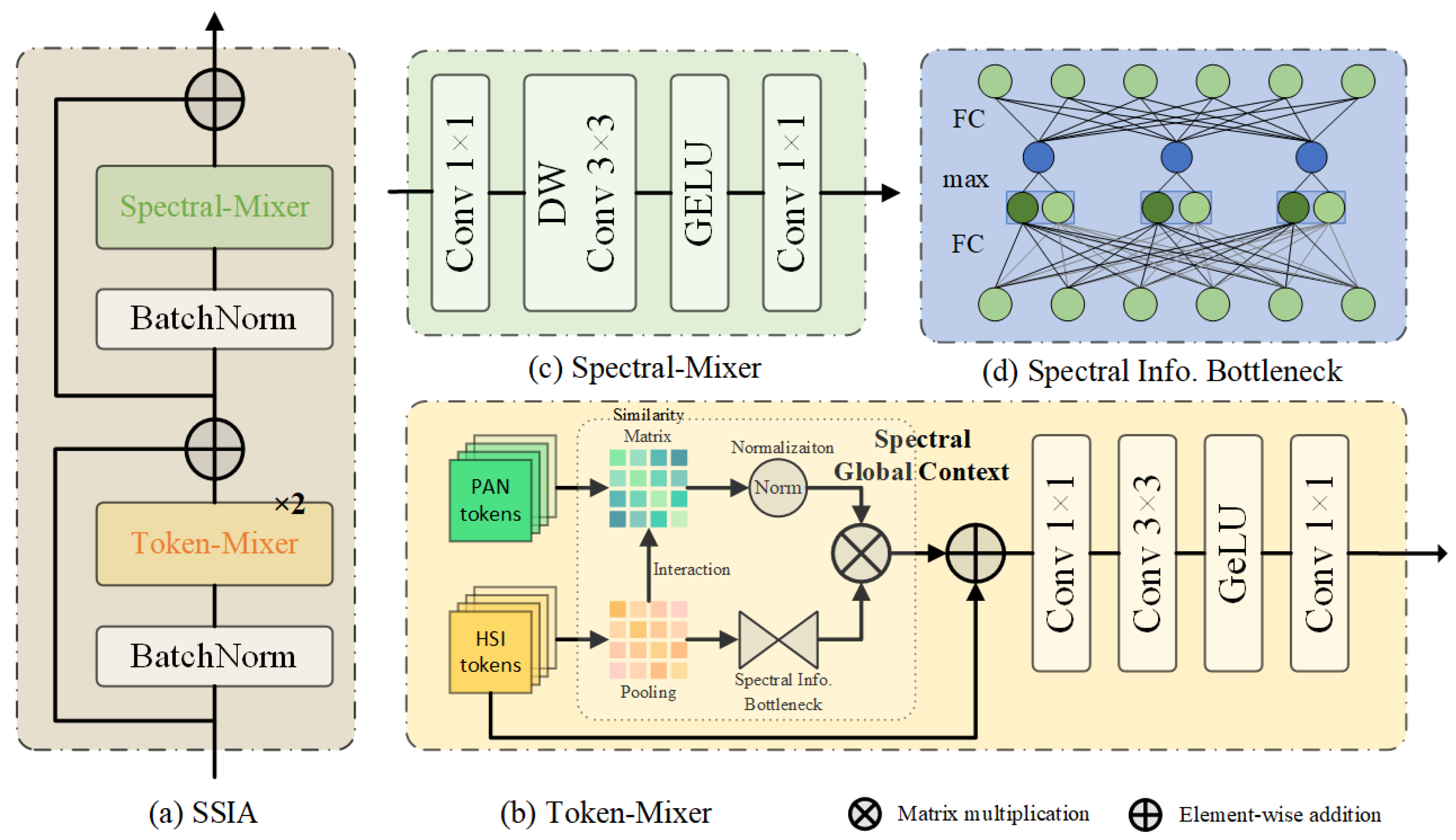
35], we introduce an Attention-Interactive Dual-Branch Convolutional Neural Network (AIDB-Net) in this paper. AIDB-Net exclusively comprises convolutional layers, strategically inheriting the merits of both convolution and self-attention. Specifically, our model adopts a dual-branch learning strategy to independently process HSI and PAN. We incorporate a dedicated Overlapping Patch Embedding block into two branches to generate attention tokens. In the primary branch, we introduce the Residual Attention-Interactive (Res-AI) module, facilitating hierarchical interaction between advanced spatial information and spectral features. To dynamically model long-range and cross-modality dependencies between HSI and PAN features, we propose a specialized Spectral-Spatial Interactive Attention (SSIA). We consider our AIDB-Net achieves deep combination of convolution and self-attention by the following approaches. First, we design a convolutional tokenization component in order to introduce the convolutional inductive bias into attention mechanism. Second, our interactive attention dynamically calculates the token-globality similarity scores based on the convolutional features. Third, the global context abstracted by attention is further propagated into the local convolutional features, thereby coupling the local and global information.
In summary, we highlight the main contributions of this paper as follows:
We propose AIDB-Net, a novel HS pansharpening model exclusively consists of convolutional layers, effectively inheriting the merits of both convolution and self-attention. To the best of our knowledge, this study is the first attempt to deeply combined them for HS pansharpening, instead of sequentially or parallelly stacking.
We design the residual attention-interactive module to simultaneously capture the short- and long-range dependencies of HSI and PAN, in which an specialized spectral-spatial interactive attention is proposed to globally interact and fuse the spectral and spatial features.
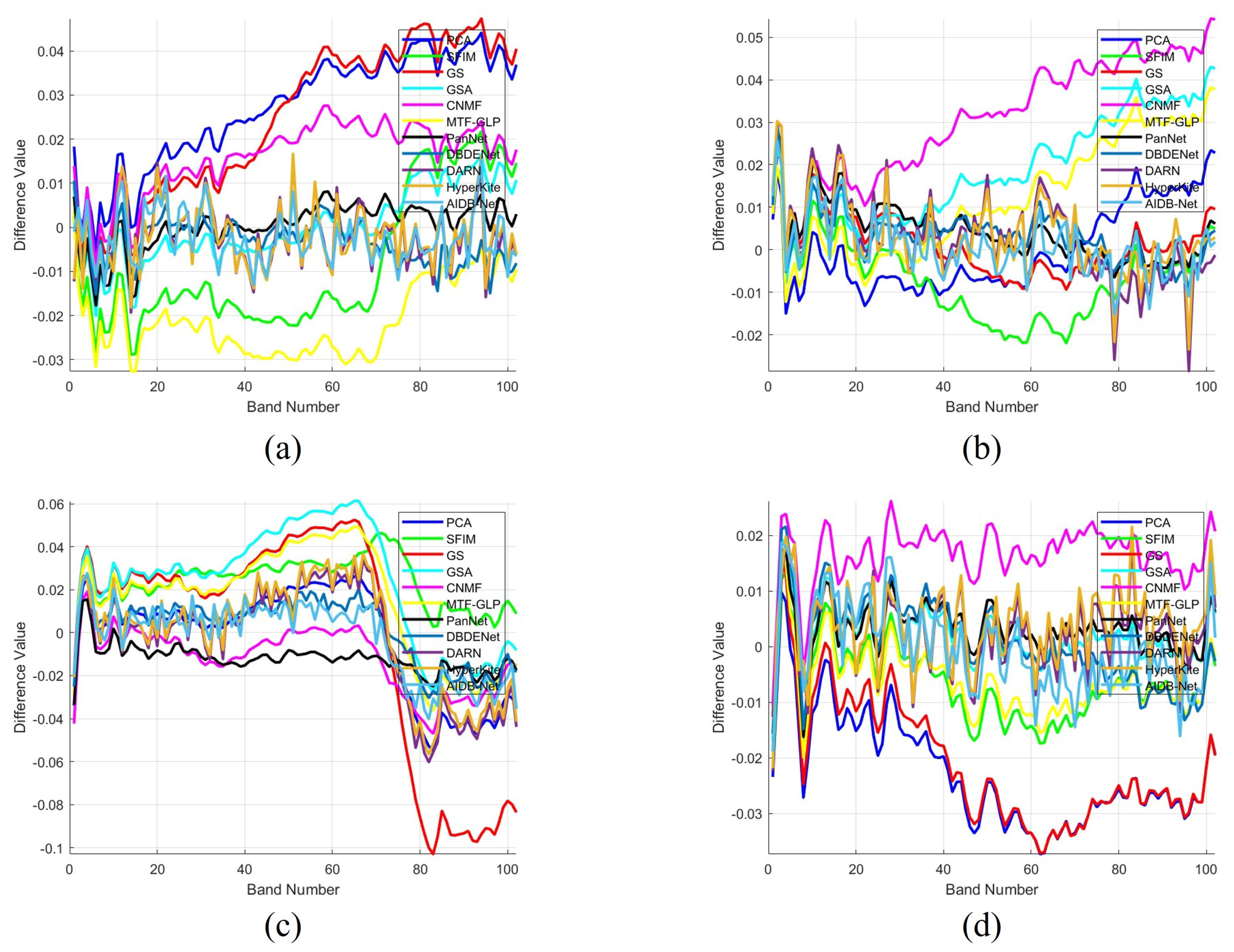
Comprehensive experiments on three public datasets quantitatively and qualitatively demonstrate the effectiveness and superiority of the proposed method. We clearly exhibit the global attention behaviors of our interactive attention through visualization of the heat maps.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











