



Remote Sensing Micro-Object Detection under Global and Local Attention Mechanism

Abstract
:1. Introduction
2. Related Work
2.1. Data Augmentation
2.2. Object Detection
2.3. Attention Mechanism
3. The Proposed Method
3.1. Overall Structure
3.2. Feature Fusion Module CGAL
3.2.1. Attention Mechanism
3.2.2. Global and Local Attention (GAL) Mechanism
3.2.3. Feature Fusion Module: CGAL
3.2.4. Multi-Decoupled Prediction Heads Structure
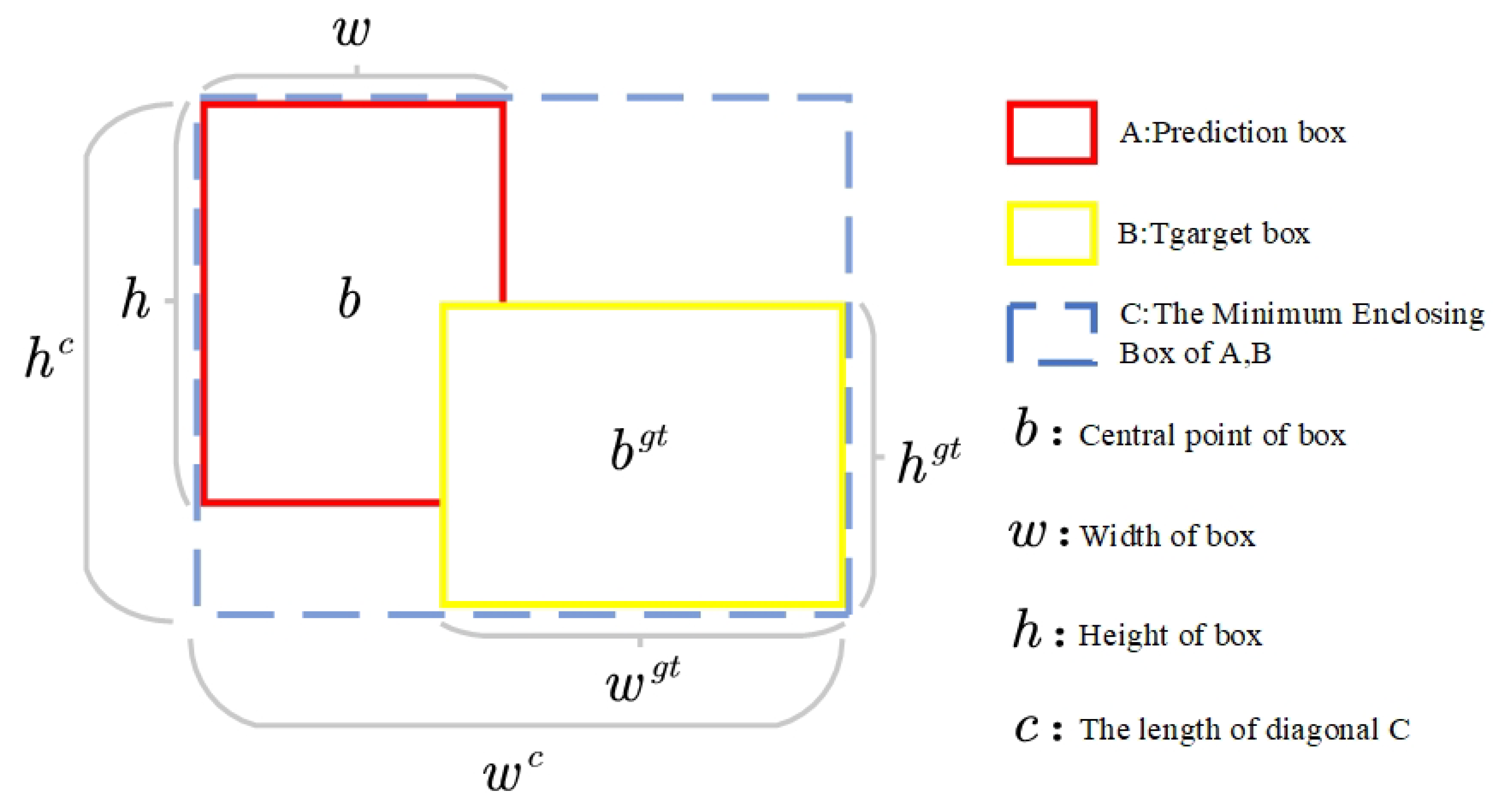
3.2.5. Ziou Loss Function
4. Experiment
4.1. Dataset and Evaluation Metrics
4.2. Implementation Details
4.3. Experimental Results and Comparative Analysis

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Size | APval | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|
| YOLO5-X [25] | 640 × 640 | 22.60% | 38.60% | - | - | - | - |
| TOOD+ [42] | 640 × 640 | - | 43.50% | - | - | - | - |
| CascadeRCNN+ResNeXt [41] | 640 × 640 | 24.40% | 41.20% | - | - | - | - |
| FasterRCNN+ [42] | 640 × 640 | 23.60% | 37.40% | - | - | - | - |
| CenterNet-Hourglass104 [43] | 640 × 640 | 25.60% | 50.30% | 22.22% | - | - | - |
| EfficientDet±D0 [44] | 640 × 640 | 20.80% | 37.10% | 20.60% | - | - | - |
| M2S [45] | 640 × 640 | - | 16.10% | 29.70% | - | - | - |
| YOLOX-X [46] | 640 × 640 | 25.80% | 43.20% | 26.20% | 15.90% | 38.00% | 52.40% |
| EdgeYOLO [39] | 640 × 640 | 26.40% | 44.80% | 26.20% | 16.40% | 38.70% | 53.10% |
| YOLOV8-X | 640 × 640 | 27.90% | 45.60% | 17.50% | 28.60% | 48.80% | 41.60% |
| Ours | 640 × 640 | 32.00% | 52.30% | 33.00% | 22.30% | 44.70% | 50.10% |
| Methods | Backbone | PL | BD | BR | GTF | SV | LV | mAP |
|---|---|---|---|---|---|---|---|---|
| PPYOLOE-R-s [40] | CRN-s | 88.80 | 79.24 | 45.92 | 66.88 | 80.41 | 82.95 | 73.82 |
| DRN [47] | H-104 | 89.71 | 82.34 | 47.22 | 64.10 | 76.22 | 74.43 | 73.23 |
| O2-DNet [48] | H-104 | 89.31 | 82.14 | 47.33 | 61.21 | 71.32 | 74.03 | 71.04 |
| DAL [49] | R-101-FPN | 88.61 | 79.69 | 46.27 | 70.37 | 65.89 | 76.10 | 71.78 |
| SCRDet [50] | R-101-FPN | 89.98 | 80.65 | 52.09 | 68.36 | 68.36 | 60.32 | 72.61 |
| S2A-Net [38] | R-50-FPN | 89.11 | 82.84 | 48.37 | 71.11 | 78.11 | 78.39 | 74.12 |
| YOLOV8-S | CSP | 69.91 | 85.12 | 50.75 | 81.34 | 88.11 | 79.81 | 72.31 |
| Ours | CSP | 71.23 | 86.25 | 54.58 | 84.41 | 90.44 | 84.81 | 75.12 |
4.4. Ablation Study
Analysis
5. Limitation and Future Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hird, J.N.; Montaghi, A.; McDermid, G.J.; Kariyeva, J.; Moorman, B.J.; Nielsen, S.E.; McIntosh, A.C. Use of unmanned aerial vehicles for monitoring recovery of forest vegetation on petroleum well sites. Remote Sens. 2017, 9, 413. [Google Scholar] [CrossRef]
- Kellenberger, B.; Volpi, M.; Tuia, D. Fast animal detection in UAV images using convolutional neural networks. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Worth, TX, USA, 23–28 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 866–869. [Google Scholar]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Wang, M.; Yang, W.; Wang, L.; Chen, D.; Wei, F.; KeZiErBieKe, H.; Liao, Y. FE-YOLOv5: Feature enhancement network based on YOLOv5 for small object detection. J. Vis. Commun. Image Represent. 2023, 90, 103752. [Google Scholar] [CrossRef]
- Yang, C.; Huang, Z.; Wang, N. QueryDet: Cascaded sparse query for accelerating high-resolution small object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13668–13677. [Google Scholar]
- Li, L.; Li, B.; Zhou, H. Lightweight multi-scale network for small object detection. PeerJ Comput. Sci. 2022, 8, e1145. [Google Scholar] [CrossRef] [PubMed]
- Deng, C.; Wang, M.; Liu, L.; Liu, Y.; Jiang, Y. Extended feature pyramid network for small object detection. IEEE Trans. Multimed. 2021, 24, 1968–1979. [Google Scholar] [CrossRef]
- Mahaur, B.; Mishra, K. Small-object detection based on YOLOv5 in autonomous driving systems. Pattern Recognit. Lett. 2023, 168, 115–122. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Min, K.; Lee, G.H.; Lee, S.W. Attentional feature pyramid network for small object detection. Neural Netw. 2022, 155, 439–450. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Yan, J.; Ming, Q.; Wang, W.; Zhang, X.; Tian, Q. Rethinking rotated object detection with gaussian wasserstein distance loss. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 11830–11841. [Google Scholar]
- Yang, X.; Yang, X.; Yang, J.; Ming, Q.; Wang, W.; Tian, Q.; Yan, J. Learning high-precision bounding box for rotated object detection via kullback-leibler divergence. Adv. Neural Inf. Process. Syst. 2021, 34, 18381–18394. [Google Scholar]
- Qi, G.; Zhang, Y.; Wang, K.; Mazur, N.; Liu, Y.; Malaviya, D. Small object detection method based on adaptive spatial parallel convolution and fast multi-scale fusion. Remote Sens. 2022, 14, 420. [Google Scholar] [CrossRef]
- Zhu, Z.; Wei, H.; Hu, G.; Li, Y.; Qi, G.; Mazur, N. A novel fast single image dehazing algorithm based on artificial multiexposure image fusion. IEEE Trans. Instrum. Meas. 2020, 70, 1–23. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhang, Y.; Ming, Y.; Zhang, R. Object detection and tracking based on recurrent neural networks. In Proceedings of the 2018 14th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 12–16 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 338–343. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Solawetz, J. What is YOLOv8? The Ultimate Guide. 2023. Available online: https://blog.roboflow.com/whats-new-in-yolov8/ (accessed on 18 December 2023).
- Jocher, G.; Stoken, A.; Borovec, J.; Chaurasia, A.; Changyu, L.; Hogan, A.; Hajek, J.; Diaconu, L.; Kwon, Y.; Defretin, Y.; et al. Ultralytics/yolov5: v5. 0-YOLOv5-P6 1280 Models, AWS, Supervise. ly and YouTube Integrations; Zenodo: Geneva, Switzerland, 2021. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent models of visual attention. arXiv 2014, arXiv:1406.6247. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. arXiv 2015, arXiv:1506.02025. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Zhu, Z.; Luo, Y.; Qi, G.; Meng, J.; Li, Y.; Mazur, N. Remote sensing image defogging networks based on dual self-attention boost residual octave convolution. Remote Sens. 2021, 13, 3104. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11534–11542. [Google Scholar]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Ling, H.; Hu, Q.; Nie, Q.; Cheng, H.; Liu, C.; Liu, X.; et al. Visdrone-det2018: The vision meets drone object detection in image challenge results. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Han, J.; Ding, J.; Li, J.; Xia, G.S. Align deep features for oriented object detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–11. [Google Scholar] [CrossRef]
- Liang, S.; Wu, H.; Zhen, L.; Hua, Q.; Garg, S.; Kaddoum, G.; Hassan, M.M.; Yu, K. Edge YOLO: Real-time intelligent object detection system based on edge-cloud cooperation in autonomous vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 25345–25360. [Google Scholar] [CrossRef]
- Wang, X.; Wang, G.; Dang, Q.; Liu, Y.; Hu, X.; Yu, D. PP-YOLOE-R: An Efficient Anchor-Free Rotated Object Detector. arXiv 2022, arXiv:2211.02386. [Google Scholar]
- Tang, W.; Sun, J.; Wang, G. Horizontal Feature Pyramid Network for Object Detection in UAV Images. In Proceedings of the 2021 China Automation Congress (CAC), Beijing, China, 22–24 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 7746–7750. [Google Scholar]
- Akyon, F.C.; Altinuc, S.O.; Temizel, A. Slicing aided hyper inference and fine-tuning for small object detection. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 966–970. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Guo, X. A novel Multi to Single Module for small object detection. arXiv 2023, arXiv:2303.14977. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Pan, X.; Ren, Y.; Sheng, K.; Dong, W.; Yuan, H.; Guo, X.; Ma, C.; Xu, C. Dynamic refinement network for oriented and densely packed object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11207–11216. [Google Scholar]
- Wei, H.; Zhang, Y.; Chang, Z.; Li, H.; Wang, H.; Sun, X. Oriented objects as pairs of middle lines. ISPRS J. Photogramm. Remote Sens. 2020, 169, 268–279. [Google Scholar] [CrossRef]
- Ming, Q.; Zhou, Z.; Miao, L.; Zhang, H.; Li, L. Dynamic anchor learning for arbitrary-oriented object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 2355–2363. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. Scrdet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8232–8241. [Google Scholar]
- Zheng, M.; Qi, G.; Zhu, Z.; Li, Y.; Wei, H.; Liu, Y. Image dehazing by an artificial image fusion method based on adaptive structure decomposition. IEEE Sens. J. 2020, 20, 8062–8072. [Google Scholar] [CrossRef]
- Zhu, Z.; Luo, Y.; Wei, H.; Li, Y.; Qi, G.; Mazur, N.; Li, Y.; Li, P. Atmospheric light estimation based remote sensing image dehazing. Remote Sens. 2021, 13, 2432. [Google Scholar] [CrossRef]










| Setting | Apval | Ap50 | Ap75 | Aps | Apm | Apl | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|
| baseline | 27.90% | 45.60% | 28.60% | 17.5% | 41.6% | 48.8% | 365.3 | 60.97 |
| +CGAL | 30.60% | 50.20% | 31.7% | 21.5% | 42.3% | 49.3% | 386.6 | 46.04 |
| +Four headed structure | 31.5% | 51.5% | 32.4% | 22.1% | 43.8% | 49.8% | 392.4 | 43.90 |
| +Ziou | 32.00% | 52.30% | 33.00% | 22.3% | 44.7% | 50.1% | 394.7 | 44.39 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Zhou, Z.; Qi, G.; Hu, G.; Zhu, Z.; Huang, X. Remote Sensing Micro-Object Detection under Global and Local Attention Mechanism. Remote Sens. 2024, 16, 644. https://doi.org/10.3390/rs16040644
Li Y, Zhou Z, Qi G, Hu G, Zhu Z, Huang X. Remote Sensing Micro-Object Detection under Global and Local Attention Mechanism. Remote Sensing. 2024; 16(4):644. https://doi.org/10.3390/rs16040644
Chicago/Turabian StyleLi, Yuanyuan, Zhengguo Zhou, Guanqiu Qi, Gang Hu, Zhiqin Zhu, and Xin Huang. 2024. "Remote Sensing Micro-Object Detection under Global and Local Attention Mechanism" Remote Sensing 16, no. 4: 644. https://doi.org/10.3390/rs16040644