3.1. Workflow of the Proposed Method
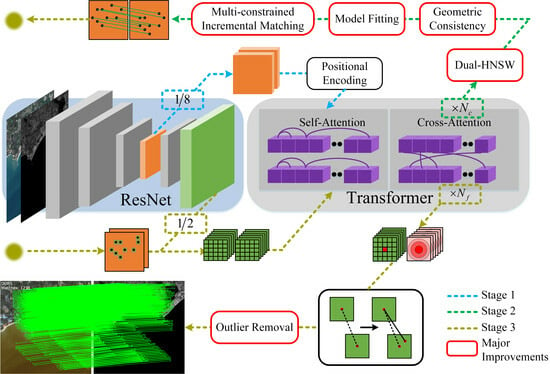
As shown in
Figure 1, we propose an end-to-end algorithm for infrared and visible remote sensing image registration named RIZER. The algorithm is divided into three main stages. The first stage utilizes a pre-trained ResNet [
41] combined with Transformer [
11] for feature extraction. In the second stage, coarse-level matching broad correspondences are obtained using the Dual HNSW algorithm. Then, the local geometric soft constraints are utilized to filter the set of control points, after which model fitting is performed. Finally, an incremental matching method with multiple constraints is used. In the third stage, after combining the coarse-level matchpoint locations with the fine-level map, Transformer is then used for fine-level feature fusion, coordinating fine-tuning by calculating the expectation between the matchpoints, and finally, efficient outlier rejection is performed to obtain the final matching results. Among them, the second stage and the outlier rejection part in the third stage are our main focus, which will be described in detail below. Here, we briefly describe how the feature maps are generated in the first stage.
The infrared and visible remote sensing images are fed into the feature extraction network, and the standard convolutional structure of Feature Pyramid Networks (FPNs) is used to extract multilevel features from the two images. The initial features extracted by the CNN have translational invariance. Thus, they can recognize similar patterns occurring at different locations in the image, and the FPN achieves multiscale feature fusion. The extracted 1/8-resolution feature maps are used to generate global context-dependent feature descriptors, and downsampling reduces the input length of the subsequent Transformer module. Then, 1/2-resolution feature maps are used to fine-tune the coordinates of the coarse matchpoints, which ensures that the final matchpoints have higher localization accuracy.
The 1/8-resolution feature maps are subjected to sine–cosine positional encoding, which makes the output features location-dependent and improves the feature representation of the model for sparse texture and repetitive regions. After that, the features are fed into the Transformer module for feature enhancement, which is repeated several times. The Transformer module consists of multiple alternating self-attention and cross-attention layers, where the self-attention layer allows each point to focus on all other points around it within an image to capture the correlation between them, while the cross-attention layer allows each point to focus on all the points in another image. By utilizing the excellent property of Transformer’s global attention, the features of each point are fused with the contextual information of other related points, obtaining a richer representation, and coarse-level feature maps and are obtained.
Here, for the feature extraction network, we used the outdoor weights trained by the LoFTR [
31] model. Due to the small labeled dataset of infrared and visible remote sensing images, we tried not to train the scene in a targeted way, but directly utilize the feature vectors obtained from the pre-trained weights for subsequent processing, i.e., zero-shot learning. The results show that such a strategy is efficient and feasible, and the feature maps are shown in the Results Section.
3.2. Dual HNSW
In order to achieve overall differentiability, current detector-free algorithms [
31,
32,
33] commonly use the inner product between vectors to obtain the similarity matrix and then search for the maximum value to establish a match, e.g., the dual-softmax method used by LoFTR [
31] to find the two-way maximum of the match probability. Although this strategy achieves differentiability in similarity measurement, it is too strict and does not fully utilize the relationship between the feature vectors, especially for infrared and visible multimodal images, which can filter out some of the correct matches or even establish incorrect matches. In this study, we adopted the strategy of increasing reliability, i.e., initially establishing one-to-many fuzzy correspondences and then establishing reliable matches through screening. Since we utilize pretrained weights, our subsequent matching strategy does not rely on differentiability. Therefore, we introduce a graph model-based K-nearest neighbor algorithm, HNSW [
12], in the field of deep learning-based image registration. HNSW is an efficient approximate nearest neighbor search algorithm, which is not yet very widely used in the field of image registration. It accelerates the nearest-neighbor search process by constructing a hierarchical graph index structure and jumping between and within layers, which can significantly reduce the amount of distance computations that need to be performed.
The query index and template index are established, respectively, corresponding to the input template vector
and the query vector
for the search of K-nearest neighbors, to obtain the K-nearest neighbor set
of each coarse-level point, as shown in Equation (1), as well as
,
, where
stands for the K-nearest neighbor distance to the ith point in the template image, the default distance metric of HNSW is the square of P-paradigm, and
is the corresponding point in the query image. Filtering is performed using the nearest neighbor and next nearest neighbor through the proportional approach in the SIFT [
18] algorithm. A match is established if Equation (2) is satisfied, and here,
is set to 0.8. Unsatisfied or unused K-nearest neighbor relationships will be fully utilized in subsequent processing.
The threshold-filtered template vectors and the mutual nearest neighbors of the query vectors are used to establish preliminary matches, and the preliminary matched template point set
and the query point set
are obtained. This threshold-filtered bidirectional matching method can filter out most false matches and guarantee that the preliminary matches have a high in-points rate. The specific diagram is shown in
Figure 2.
3.3. Local Geometric Soft Constraint
After the dual HNSW algorithm establishes the initial matching, some pseudo-correspondences may still exist due to the complexity of the heterogeneous remote sensing images, which will have a great impact on the fitting of the subsequent transformation model and even lead to the failure of the matching. We introduce the a priori information of geometric consistency [
42] between matchpoints to establish constraints and then carry out another pseudo-correspondence rejection. Meanwhile, compared with the heat map approach, the introduction of a priori knowledge can improve the interpretability of the deep learning method, and the results it obtains are not irregular, but they all satisfy the geometric consistency, which makes the obtained registration results more reliable. When the image does not contain severe affine or projective transformations, the spatial structure between correct matchpoints is similar. Based on this feature, the mismatched matchpoints can be eliminated by calculating the Euclidean distance and direction angle between their neighboring matchpoints.
The difficulty in matching between heterologous remote sensing images in infrared and visible is mainly caused by different imaging mechanisms, considerable nonlinear spectral radiation variations, and obvious differences in the grayscale gradient, whereas geometric structural attributes are less affected by radiation differences. Heterologous remote sensing images captured by satellites usually do not have a large perspective deflection in a small area, and the viewing angle of satellite remote sensing images is relatively high. The ground can be regarded as an approximate plane, and the depth of the scene is relatively small, which makes the remote sensing images a two-dimensional planar projection, which satisfies the condition of spatial structure similarity.
The core idea of geometric consistency is that for all correct matchpoint pairs, the distance ratios of any two matchpoint pairs should be equal or approximately equal, and the distance ratios should also be approximately equal to the true scale ratios of the two images and the angles formed by any three matchpoint pairs should be approximately equal. So, the distance ratios of all correct matchpoint pairs can form a class centered on the true scale ratio. The matchpoint pairs that are farther away from the center of the class are the false matches, and the angles between the matchpoint pairs should also satisfy the corresponding constraints.
In this study, we build on the preliminary matching point sets
and
for culling in order to improve the efficiency of the algorithm; for each matching point pair, any five-point pairs among the remaining matching point pairs are selected to establish two corresponding local random matrices, where
is the local random matrix of the template image, as shown in Equation (3), and
is the local random matrix of the query image.
stands for the coordinates
of the uth point as the center of the point;
,
, stands for the coordinates
of the randomly selected points among the remaining matchpoints.
,
represents the number of matchpoints established by the preliminary matching.
The Euclidean distance is used to calculate the distance
between
and
, as shown in Equation (4), as well as to calculate
through the matrix
to form the length matrices
and
.
To further improve the computational efficiency, only the angle between the current edge and the next edge is computed, while the fifth edge forms an angle with the first edge, and the computation yields
, as shown in Equation (5), which composes the angle matrix
, and
is computed by query image and composes the angle matrix
. A schematic diagram of the established double feature constraints of the length and the angle is shown in
Figure 3.
After calculating the length matrices and and the angle matrices and , it is necessary to judge whether the ratio between them satisfies the a priori information of geometric consistency. In this study, we adopted the method of soft constraints, i.e., instead of requiring each distance and pinch angle to be within the threshold range, we take their overall error mean as a soft constraint, which reduces the number of judgments and avoids making the algorithm too strict while also reducing the influence of a small number of outlier points, and this excludes matchpoints that do not satisfy the soft constraints as outlier points.
Specifically, the mean value of the length ratio
is first calculated, as shown in Equation (6), and then the length error
is calculated, as shown in Equation (7). For the angle, the ratio should be approximately equal to 1. The angle error
is calculated using Equation (8). Finally, the mean length error and the mean angle error are calculated for each pair of matchpoints, and if they are not simultaneously within the allowable error range, then the pair of pseudo-matches is eliminated, and the remaining pairs of matchpoints that satisfy the conditions of Equation (9) are summarized as the control point pairs
and
,
, and
is the number of pairs of matchpoints of the control point set, which constitute the control point set
, as well as
, where the threshold
is set to 0.1.
3.4. Least Squares Fitting Transform Model
In recent years, many approaches have tended to formulate the registration problem as an optimization problem [
43,
44]. The prevailing principle is to optimize the transformation model to obtain the best possible registration results, which can be measured by minimizing an objective function that measures the registration’s accuracy. The method of fitting a change model can avoid the direct use of complex feature vectors to align between the full matchpoint sets and converting the matching problem into a model fitting problem greatly reduces the difficulty of matching and avoids complete blind matching. At the same time, it is also in line with the process used by the human eye for registration; first, it finds the general rule of change among images through the significant matchpoint sets and then makes corresponding predictions and judgments one by one.
Fitting the change model is commonly used to estimate the affine transform model coefficients based on Random Sample Consensus (RANSAC) [
45] and its improved algorithms, but the coarse-level map also destroys the original geometrical structure of the image based on the structure of the single-response matrix, which may lead to inaccurate estimation of the single-response matrix if the structure is changed. And, based on high-order nonlinear change models, such as the Thin-Plate Spline (TPS) [
44] model, if the complexity of the algorithm is too high, it will significantly increase the running time. In addition, because the coarse-level map extracts semi-dense local feature points at certain intervals in the image, which are uniformly distributed in the whole image with strong regularity, the spatial transformation model is essentially a coordinate mapping function, and because the coarse-level map has a low resolution, it can greatly reduce the nonlinear variation between matchpoints, so the coordinates of matchpoints of the coarse-level map can be approximated as a linear relationship.
For a pair of control points
and
, a polynomial fit is used, as shown in Equation (10).
Which reduces to a least squares matrix in the form of:
Substituting the control point sets into the above equation:
Then, the transformed model matrix is solved:
3.5. Multi-Constraint Incremental Matching
Most of the matching algorithms use a single constraint for a one-size-fits-all judgment of interior and exterior points, which is difficult to adapt to the complexity of registration between remote sensing images from different sources. A single constraint will inevitably produce a misjudgment, resulting in a large number of interior points being eliminated, and the small number of matchpoints obtained does not guarantee a high interior point rate. To avoid this situation, single-constraint algorithms will commonly use an iterative elimination of outer points, which again leads to the inefficiency of the algorithm. In this study, we adopted a multi-constraint incremental matching approach, which combines multiple in-point prediction and out-point rejection methods to provide more potential one-to-one matches while guaranteeing a high in-point rate with high algorithmic efficiency.
First, based on the transform model constraints,
and
remain after removing the preliminary matches
and
. Using
and the solved transform model matrix
, the prediction is performed in the query image with rounding as well as the elimination of the obvious erroneous points outside the image to obtain
and the corresponding
, to ensure that each point in
falls within
. After that, the mutual three-nearest-neighbor constraints are performed using the three-nearest-neighbor matrices previously obtained by the dual HNSW algorithm. It is too harsh to consider only the nearest-neighbor relationships in the heterologous remote sensing images and tends to exclude a large number of correct correspondences. Using mutual three-nearest-neighbor constraints can efficiently obtain most of the correct correspondences, make full use of the data obtained from the establishment of the dual index in the previous section, and judging point by point so that only when the point
of
and the corresponding point
of
are mutual three-nearest-neighbors to each other, are they saved as inner points, and we obtain the mutual three-nearest-neighbor matchpoint sets
and
. The rest of the pairs of points that cannot satisfy the conditions at the same time are saved into the matrices
and
. Finally, double feature constraints are then applied to
and
using length and angle, although the two point sets do not satisfy the nearest-neighbor constraints, it is possible that the obtained feature vectors and the HNSW algorithm cannot find the correspondence between them, and the spatial structural similarity between the matchpoints can be used as an additional source of matching. The specific implementation is similar to the above, but the first column of the random matrix consists of the points in
and
, the last five columns are randomly selected pairs of points in the control point sets
and
, and finally, the spatial structural similarity matchpoint sets
and
are obtained. Eventually, the set of all coarse-level matchpoints obtained,
and
, consists of the control point sets
and
, the mutual three-nearest-neighbor matchpoint sets
and
, and the spatial structural similarity matchpoint sets
and
, and is composed of three parts, as shown in Equation (14).
3.6. Fine-Level Matching
After establishing the coarse-level matches and finding the approximate correspondences in the local area, fine-level matching is needed to fine-tune the coordinate positions. Here, LoFTR’s [
31] coordinate refinement adjustment strategy and pre-training weights are used. For each coarse-level match, its position is mapped in the fine-level map, and then a pair of local windows of size
are cropped out, which is then inputted into the Transformer [
11] module to perform
times the feature fusion to obtain the fine-level feature maps
and
. After that, the center vector of the template local window is similar to all the vectors of the query local window to obtain the heat map, and by calculating the expectation of the probability distribution, the final position with sub-pixel accuracy can be obtained in the query window.
However, the LoFTR [
31] algorithm does not incorporate the outlier rejection method. Although the overall correct matching rate of the algorithm is high, a small number of false matches will have a large impact on the subsequent homography estimation and various scenarios. Iteratively Re-weighted Least-Squares (IRSL) [
46] and RANSAC [
45] are commonly used in the traditional methods for false matchpoint rejection, and both are robust estimation methods based on the iterative strategy, which needs to be optimized through the process of repeated optimization to suppress outlier points. Traditionally, iterative outlier removal conducted across all matched points generally requires hundreds or thousands of iterations, leading to low computational efficiency. Additionally, it struggles with robustness and attaining high correct matching rates when encountering numerous outliers. In this paper, we present a simple yet effective improvement to the RANSAC algorithm, building upon the multi-stage matching approach described previously. We invoke OpenCV’s findHomography function using RANSAC with default parameters. Instead of sampling across all matches, we leverage the high confidence set of control points with refined coordinates to estimate the homography matrix
. Subsequently, the template point
is mapped to obtain the ideal corresponding point, which is categorized as an interior point if it is kept within the distance of threshold
from the query point
, as shown in Equation (15). Therefore, the proposed algorithm enables efficient outlier removal with an extremely low iteration count. Simultaneously, it resolves robustness issues due to the high correct matching rate attained by the control point set, ultimately obtaining the fine-level matching point sets
and
.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}