
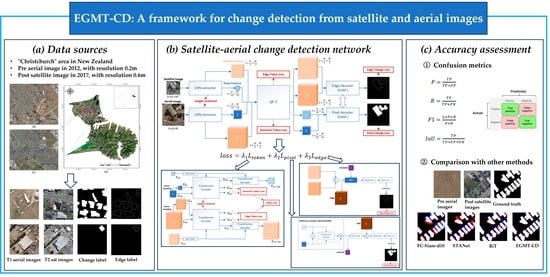
EGMT-CD: Edge-Guided Multimodal Transformers Change Detection from Satellite and Aerial Images

Abstract
:
1. Introduction
- (1)
- Huge difference in resolution between satellite and aerial images. Due to satellite and aircraft having different shooting heights and sensors, a satellite image’s resolution is usually lower than that of aerial images. A HR satellite’s resolution is approximately 0.5–2 m [8], while an aerial image’s resolution is usually lower than 0.5 m [9], and can even reach the centimeter level. Aligning the resolution of satellite and aerial image pairs through interpolation, convolution, or pooling is a direct solution to the problem, but it can cause the image to lose a large amount of detailed information and introduce some accumulated errors and speckle noise.
- (2)
- Blurred edges caused by complex terrain scenes and interference from the satellite and aerial image gap. Dense building clusters are often obstructed by shadow occlusion, similar ground objects, and intraclass differences caused by very different materials, resulting in blurred edges. Moreover, the parallax and inference from the lower resolution of satellite images than aerial images further increases the difficulties in change detection for buildings.
- (1)
- We propose a novel method, Edge-Guided Multimodal Transformers Change Detection (EGMT-CD) for heterogeneous SACD tasks, and design an imp SP-T to build up image resolution gaps. We also introduce a token loss to assist SP-T to obtain a scale-invariant core feature in the training process, which helps recover the LR satellite features to align with HR aerial features.
- (2)
- To overcome the blurred edges caused by complex terrain scenes and interference from the satellite–aerial image gap, we introduce a dual-branch decoder, adding an edge branch, fuse both semantic and edge information, and design an edge change loss to constrain the output change mask.
- (3)
- To test our proposed SACD method, we made a new satellite–aerial heterogeneous change detection dataset, named SACD. We also conducted sufficient experiments on the dataset and the results demonstrate the potential of our method for SACD tasks and show that it had the best performance by increasing the F1 score and IoU score compared to BiT (one of state-of-the-art change detection method) by 3.97% and 5.88%, respectively. The SACD dataset can be found at https://github.com/xiangyunfan/Satellite-Aerial-Change-Detection, accessed on 15 November 2023.
2. Related Work
2.1. Different Resolution for Change Detection
2.2. Deep Learning for Change Detection
3. Methods
3.1. Overview
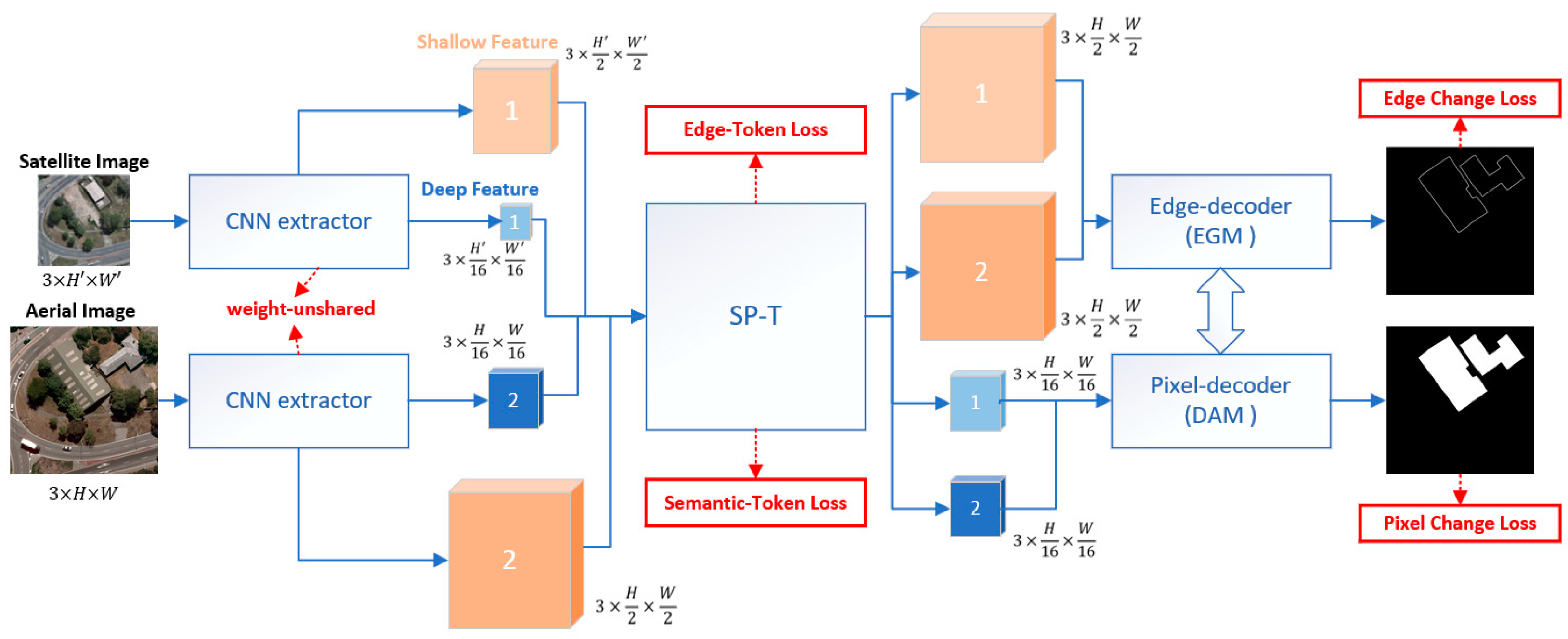
- (1)
- Input a pair of satellite and aerial image to the backbone based on a weight-unshared CNN Siamese Network and extract the bitemporal features, including shallow features (edge level), , and deep features (semantic level), .
- (2)
- Send the obtained features, , , and into the improved spatially aligned transformer (SP-T) to recover and to the same size with target features and . We adopted the idea of super resolution to simulate the sampling process and combined SP-T with sub-pixel convolution to achieve feature alignment. Obtain spatially aligned feature both in the edge level and semantic level, , .
- (3)
- Decode and predict the change area using dual branch decoders, including an edge decoder and a pixel decoder. Input and into the pixel decoder, go through using Difference Analysis Module (DAM) and concatenate the edge decoder branch result to generate the pixel change map. Input and into the edge decoder, go through using Edge-Guided Module (EGM) and combine the pixel decoder branch result to obtain the edge change result.
3.2. Backbone
3.3. Spatially Aligned Transformer (SP-T)
- (1)
- Transformer
- (2)
- Sub-pixel Convolution
- (3)
- SP-T
3.4. Dual-Branch Decoders
3.4.1. Pixel Decoder
3.4.2. Edge Decoder
3.5. Loss Function
4. Experiments
4.1. Dataset
4.2. Experimental Details
4.3. Evaluation Metrics
4.4. Comparison Methods
- (1)
- (2)
- (3)
- (4)
- STANet [16]: This is a method introduced for the spatial-temporal attention mechanism to adjust weights in the space and time dimensions between two paired images to obtain the location and better distinguish changes.
- (5)
- SNUNet-CD [43]: This is a channel attention-based method inspired by the structure of the NestedUNet [44]. The network introduces dense connections and a large number of skip connections to deeply mine multiscale features. Furthermore, the channel attention module (ECAM) is used to assign appropriate weights to semantic features at different levels to obtain better overall change information
- (6)
- BIT [45]: This is a method embedded with a transformer module in a Siamese network. The network adopts an improved ResNet-18 as its backbone [36], introducing a bitemporal image transformer to map pre and post temporal images to global contextual information, aiming to capture the core difference from the high-level semantic token.
5. Results
5.1. Comparisons of the SACD Dataset
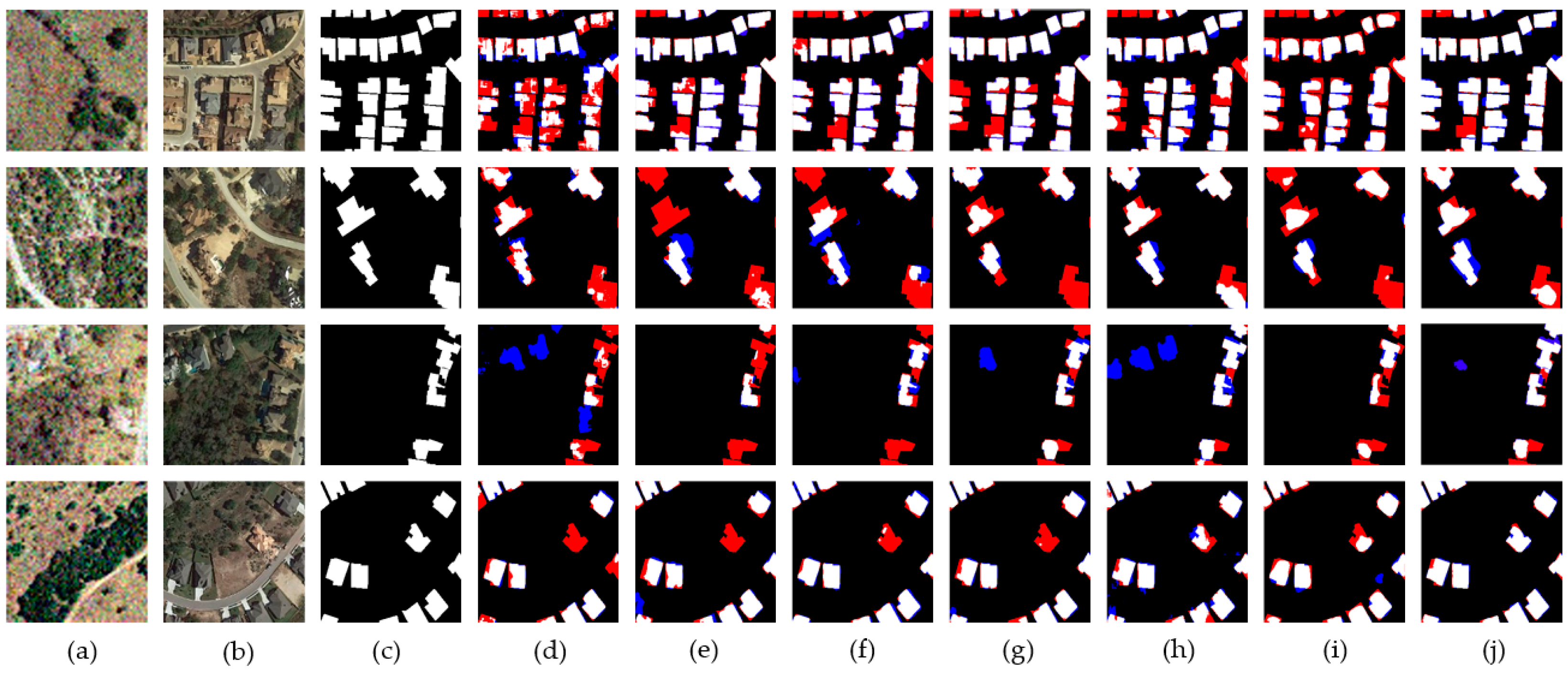
- (1)
- It is very difficult to detect small changes in complex building clusters in pre- and post-event image pairs. The resolution gap between satellite and aerial images further aggravates this difficulty, making small buildings blurrier and narrowing feature dissimilarity from the background and other objects. As shown in Figure 9, we can see that EGMT-CD effectively captured small building changes, and the phenomenon of missed detections (the red marked area) was significantly improved. In contrast, other CD networks failed to correctly identify changing areas on account of the resolution gap.
- (2)
- It is hard to identify each changed building shape in densely connected building areas. The resolution gap and parallax from satellite and ariel image pairs also worsens the situation, as the building object edge is much harder to determine and match. As shown in Figure 9, the EGMT-CD model could reduce the boundary noise of the changing region and obtained finer region boundary descriptions than the other CD networks (the blue marked area).
5.2. Ablation Study
5.2.1. Ablation Study of Each Component in EGMT-CD
5.2.2. Ablation Study of Loss Function Parameters
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional neural network |
| EGMT-CD | Edge-Guided Multimodal Transformers Change Detection |
| SACD | Satellite–Aerial heterogeneous Change Dataset |
| SP-T | Spatially Aligned Transformer |
| DAM | Difference Analysis Module |
| EGM | Edge-Guided Module |
| EDB | Edge detection branch |
| SNUNet-CD | Siamese NestedUNet |
| STANet | Spatial Temporal Attention Network |
References
- Jérôme, T. Change Detection. In Springer Handbook of Geographic Information; Springer: Berlin/Heidelberg, Germany, 2022; pp. 151–159. [Google Scholar]
- Hu, J.; Zhang, Y. Seasonal Change of Land-Use/Land-Cover (Lulc) Detection Using Modis Data in Rapid Urbanization Regions: A Case Study of the Pearl River Delta Region (China). IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 1913–1920. [Google Scholar] [CrossRef]
- Jensen, J.R.; Im, J. Remote Sensing Change Detection in Urban Environments. In Geo-Spatial Technologies in Urban Environments; Springer: Berlin/Heidelberg, Germany, 2007; pp. 7–31. [Google Scholar]
- Zhang, J.-F.; Xie, L.-L.; Tao, X.-X. Change Detection of Earthquake-Damaged Buildings on Remote Sensing Image and Its Application in Seismic Disaster Assessment. In Proceedings of the IGARSS 2003, 2003 IEEE International Geoscience and Remote Sensing Symposium, Proceedings (IEEE Cat. No. 03CH37477), Toulouse, France, 21–25 July 2003. [Google Scholar]
- Bitelli, G.; Camassi, R.; Gusella, L.; Mognol, A. Image Change Detection on Urban Area: The Earthquake Case. In Proceedings of the Xth ISPRS Congress, Istanbul, Turkey, 12–23 July 2004. [Google Scholar]
- Zhan, T.; Gong, M.; Jiang, X.; Li, S. Log-based transformation feature learning for change detection in heterogeneous images. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1352–1356. [Google Scholar] [CrossRef]
- Shao, R.; Du, C.; Chen, H.; Li, J. SUNet: Change detection for heterogeneous remote sensing images from satellite and UAV using a dual-channel fully convolution network. Remote Sens. 2021, 13, 3750. [Google Scholar] [CrossRef]
- Lu, D.; Mausel, P.; Brondizio, E.; Moran, E. Change detection techniques. Int. J. Remote Sens. 2004, 25, 2365–2401. [Google Scholar] [CrossRef]
- Zongjian, L. UAV for mapping—Low altitude photogrammetric survey. Int. Arch. Photogram. Remote Sens. Beijing China 2008, 37, 1183–1186. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision transformers for remote sensing image classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Liu, M.; Shi, Q.; Marinoni, A.; He, D.; Liu, X.; Zhang, L. Super-resolution-based change detection network with stacked attention module for images with different resolutions. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–18. [Google Scholar] [CrossRef]
- Papadomanolaki, M.; Verma, S.; Vakalopoulou, M.; Gupta, S.; Karantzalos, K. Detecting urban changes with recurrent neural networks from multitemporal Sentinel-2 data. In Proceedings of the IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 214–217. [Google Scholar]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully convolutional Siamese networks for change detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP 2018), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Daudt, R.C.; Le Saux, B.; Boulch, A.; Gousseau, Y. Urban change detection for multispectral earth observation using convolutional neural networks. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 2115–2118. [Google Scholar]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Wang, Q.; Shi, W.; Atkinson, P.M.; Li, Z. Land cover change detection at subpixel resolution with a hopfield neural network. IEEE J. Sel.Topics Appl. Earth Observ. Remote Sens. 2015, 8, 1339–1352. [Google Scholar] [CrossRef]
- Li, X.; Ling, F.; Foody, G.M.; Du, Y. A super resolution land-cover change detection method using remotely sensed images with different spatial resolutions. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3822–3841. [Google Scholar] [CrossRef]
- Wu, K.; Du, Q.; Wang, Y.; Yang, Y. Supervised sub-pixel mapping for change detection from remotely sensed images with different resolutions. Remote Sens. 2017, 9, 284. [Google Scholar] [CrossRef]
- Liu, M.; Shi, Q.; Li, J.; Chai, Z. Learning token-aligned representations with multimodel transformers for different-resolution change detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Lin, S.; Zhang, M.; Cheng, X.; Shi, L.; Gamba, P.; Wang, H. Dynamic Low-Rank and Sparse Priors Constrained Deep Autoencoders for Hyperspectral Anomaly Detection. IEEE Trans. Instrum. Meas. 2023, 73, 2500518. [Google Scholar] [CrossRef]
- Lin, S.; Zhang, M.; Cheng, X.; Zhou, K.; Zhao, S.; Wang, H. Hyperspectral anomaly detection via sparse representation and collaborative representation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 16, 946–961. [Google Scholar] [CrossRef]
- Cheng, X.; Zhang, M.; Lin, S.; Li, Y.; Wang, H. Deep Self-Representation Learning Framework for Hyperspectral Anomaly Detection. IEEE Trans. Instrum. Meas. 2023, 73, 5002016. [Google Scholar] [CrossRef]
- Bai, T.; Wang, L.; Yin, D.; Sun, K.; Chen, Y.; Li, W. Deep learning for change detection in remote sensing: A review. Geo-Spat. Inf. Sci. 2023, 26, 262–288. [Google Scholar] [CrossRef]
- Bromley, J.; Guyon, I.; Lecun, Y.; Sackinger, E.; Shah, R. Signature verification using a “siamese” time delay neural network. Int. J. Pattern Recognit. Artif. Intell. 1993, 7, 669–688. [Google Scholar] [CrossRef]
- MArabi, E.A.; Karoui, M.S.; Djerriri, K. Optical remote sensing change detection through deep siamese network. In Proceedings of the IGARSS 2018–2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 5041–5044. [Google Scholar]
- Zhang, M.; Xu, G.; Chen, K.; Yan, M.; Sun, X. Triplet-based semantic relation learning for aerial remote sensing image change detection. IEEE Geosci. Remote Sens. Lett. 2018, 16, 266–270. [Google Scholar] [CrossRef]
- Zheng, H.; Gong, M.; Liu, T.; Jiang, F.; Zhan, T.; Lu, D.; Zhang, M. HFA-Net: High frequency attention siamese network for building change detection in VHR remote sensing images. Pattern Recogn. 2022, 129, 108717. [Google Scholar] [CrossRef]
- Song, K.; Jiang, J. AGCDetNet: An Attention-Guided Network for Building Change Detection in High-Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4816–4831. [Google Scholar] [CrossRef]
- Wei, Y.; Zhao, Z.; Song, J. Urban Building Extraction from High-Resolution Satellite Panchromatic Image Using Clustering and Edge Detection. In Proceedings of the IGARSS 2004. 2004 IEEE International Geoscience and Remote Sensing Symposium, Anchorage, AK, USA, 20–24 September 2004. [Google Scholar]
- Chen, Z.; Zhou, Y.; Wang, B.; Xu, X.; He, N.; Jin, S.; Jin, S. EGDE-Net: A building change detection method for high-resolution remote sensing imagery based on edge guidance and differential enhancement. ISPRS J. Photogramm. Remote Sens. 2022, 191, 203–222. [Google Scholar] [CrossRef]
- Zheng, Z.; Wan, Y.; Zhang, Y.; Xiang, S.; Peng, D.; Zhang, B. CLNet: Cross-layer convolutional neural network for change detection in optical remote sensing imagery. ISPRS J. Photogram. Remote Sens. 2021, 175, 247–267. [Google Scholar] [CrossRef]
- Zhou, Y.; Chen, Z.; Wang, B.; Li, S.; Liu, H.; Xu, D.; Ma, C. BOMSC-Net: Boundary Optimization and Multi-Scale Context Awareness Based Building Extraction from High-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Jung, H.; Choi, H.-S.; Kang, M. Boundary Enhancement Semantic Segmentation for Building Extraction from Remote Sensed Image. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–12. [Google Scholar] [CrossRef]
- Zhang, J.; Shao, Z.; Ding, Q.; Huang, X.; Wang, Y.; Zhou, X.; Li, D. AERNet: An attention-guided edge refinement network and a dataset for remote sensing building change detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Bridging nonlinearities and stochastic regularizers with Gaussian error linear units. arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Doll’ar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction from an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A Densely Connected Siamese Network for Change Detection of VHR Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Chen, H.; Qi, Z.; Shi, Z. Remote sensing image change detection with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–6. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Precision | Recall | F1 Score | IoU |
|---|---|---|---|---|
| FC-EF | 69.97 | 71.70 | 70.82 | 54.83 |
| FC-Siam-Conc | 70.59 | 74.02 | 72.26 | 56.57 |
| FC-Siam-Diff | 73.35 | 71.58 | 72.45 | 56.81 |
| STANet | 85.05 | 69.79 | 76.67 | 62.16 |
| SNUNet-CD | 76.73 | 82.78 | 79.64 | 66.17 |
| BiT | 80.48 | 83.06 | 81.75 | 69.13 |
| EGMT-CD(ours) | 84.08 | 87.43 | 85.72 | 75.01 |
| Baseline | DAM | SP-T | EDB | Precision | Recall | F1 Score | IoU |
|---|---|---|---|---|---|---|---|
| √ | 76.47 | 74.62 | 75.53 | 60.69 | |||
| √ | √ | 78.28 | 77.90 | 78.09 | 64.05 | ||
| √ | √ | √ | 82.05 | 84.36 | 83.19 | 71.22 | |
| √ | √ | √ | 83.84 | 79.06 | 81.37 | 68.61 | |
| √ | √ | √ | √ | 84.08 | 87.43 | 85.72 | 75.01 |
| Network | F1 (%) | IoU (%) | Params (M) | FLOPs (G) |
|---|---|---|---|---|
| FC-EF | 75.71 | 60.92 | 1.35 | 3.55 |
| FC-Siam-Conc | 79.85 | 66.46 | 1.54 | 5.29 |
| FC-Siam-Diff | 77.42 | 63.16 | 1.35 | 4.68 |
| STANet | 82.14 | 69.69 | 16.93 | 40.45 |
| SNUNet-CD | 83.21 | 71.25 | 12.03 | 54.82 |
| BiT | 83.08 | 71.06 | 11.48 | 26.29 |
| EGMT-CD (ours) | 86.36 | 75.99 | 36.27 | 37.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiang, Y.; Tian, X.; Xu, Y.; Guan, X.; Chen, Z. EGMT-CD: Edge-Guided Multimodal Transformers Change Detection from Satellite and Aerial Images. Remote Sens. 2024, 16, 86. https://doi.org/10.3390/rs16010086
Xiang Y, Tian X, Xu Y, Guan X, Chen Z. EGMT-CD: Edge-Guided Multimodal Transformers Change Detection from Satellite and Aerial Images. Remote Sensing. 2024; 16(1):86. https://doi.org/10.3390/rs16010086
Chicago/Turabian StyleXiang, Yunfan, Xiangyu Tian, Yue Xu, Xiaokun Guan, and Zhengchao Chen. 2024. "EGMT-CD: Edge-Guided Multimodal Transformers Change Detection from Satellite and Aerial Images" Remote Sensing 16, no. 1: 86. https://doi.org/10.3390/rs16010086