1. Introduction
Due to the very fine spectral resolution provided by hundreds of contiguous spectral bands, hyperspectral imaging (HSI) can reveal and uncover many unknown subtle material substances which cannot be identified by prior knowledge or visual inspection [
1]. Many of these unidentified substances are generally considered to be anomalies and can provide crucial and vital information for hyperspectral image analysis. Accordingly, hyperspectral anomaly detection (HAD) has received considerable interest in recent years [
2]. However, detecting anomalies in hyperspectral imagery is very challenging because there is no definite understanding of how a hyperspectral anomaly (HA) is defined. Nevertheless, we can clearly define the difference between HA and a spatial anomaly. In traditional 2D image processing, each pixel is a scalar value specified by a single gray level since there are no spectral dimensions involved. This implies that a spatial anomaly can only be defined according to its spatial properties which are distinct from its surrounding neighboring spatial data samples. By contrast, an image pixel in HSI is a pixel vector in which each vector component is a single pixel value acquired by a particular wavelength. As a result, a hyperspectral image pixel carries a wealth of spectral information obtained from all wavelengths across its acquisition range. Therefore, an HA is quite different from a spatial anomaly in the sense that an HA has spectral characteristics that are distinct from that of its surrounding pixel vectors and not the same as a 2D spatial anomaly which is characterized by its spatial properties only. To make it clear, the anomaly that is to be discussed in this paper is HA, not spatial anomaly. In this case, HA and HAD will be abbreviated as anomaly and AD, respectively, throughout the rest of this paper unless there is a need of emphasizing “hyperspectral”.
On the other hand, according to military and intelligence applications, hyperspectral anomalies usually possess the following unique properties [
3]. First of all, a target is anomaly because it is not a spatial anomaly that cannot be identified by visual inspection or prior knowledge. Such a target is generally a man-made object which can either be an invisible object embedded in a single pixel or unidentified visible object by prior knowledge. Secondly, the existence of an anomaly is unexpected. Thirdly, the probability of the occurrence of an anomaly is relatively low. Fourthly, once anomalies are present, their populations cannot be too large. Finally, due to nature of anomalies, the number of anomalies contained in the data is relatively small, in which case anomalies cannot constitute Gaussian distributions of statistics.
Due to the fact that an HA is determined by its spectral properties, many early AD approaches were developed as spectral anomaly detectors to explore spectral correlation among its surrounding pixel vectors such as a classic anomaly detector developed by Reed–Xiaoli [
4], referred to as Reed–Xiaoli anomaly detector (RXAD). However, since a hyperspectral image is a 3D data cube, an HA should not only have a “spectral” correlation within a pixel vector but also “spectral” correlation among its neighboring pixel vectors. To address this issue, many recent AD methods have been proposed to take into account such spectral correlation among neighboring pixel vectors via local windows or subspaces, called spectral and spatial anomaly detectors [
5], low rank and sparse representation (LRaSR) [
6], low rank and sparse matrix decomposition (LRaSMD) [
7], tensor Tucker decomposition [
8] and training sampling-based deep-learning AD methods [
9], etc.
However, as noted in [
10], three factors play critical roles in evaluating an anomaly detector, that is, anomaly detectability, background suppressibility (BS) and noise, specifically, anomalies sandwiched between the BKG and noise. So, in order to effectively perform AD, noise needs to be removed from the data and then the BKG needs to be characterized to separate anomalies from the BKG. To accomplish the first task, several approaches have been developed lately. One is to develop an LRaSMD model which represents a data space as a low rank subspace to characterize the BKG, a sparse space to specify anomalies and a noise subspace in a linear three-subspace decomposition [
7]. Another is to take advantage of principal component analysis (PCA) and independent component analysis (ICA) [
11] to derive a component decomposition analysis (CDA) model where the principal component (PC) space and the independent component (IC) space represents the BKG and anomaly space, respectively [
12]. A third one is deep-learning-based networks which separate [
13], estimate [
14] or reconstruct [
15] the BKG. Most recently, a new concept called effective anomaly space (EAS) was developed further in [
10] to particularly address the issue of anomalies embedded in the BKG and the issue of anomalies contaminated by noise. Once noise is separated from the BKG, the follow-up task is to design anomaly detectors that effectively detect anomalies in the BKG-removed residual space.
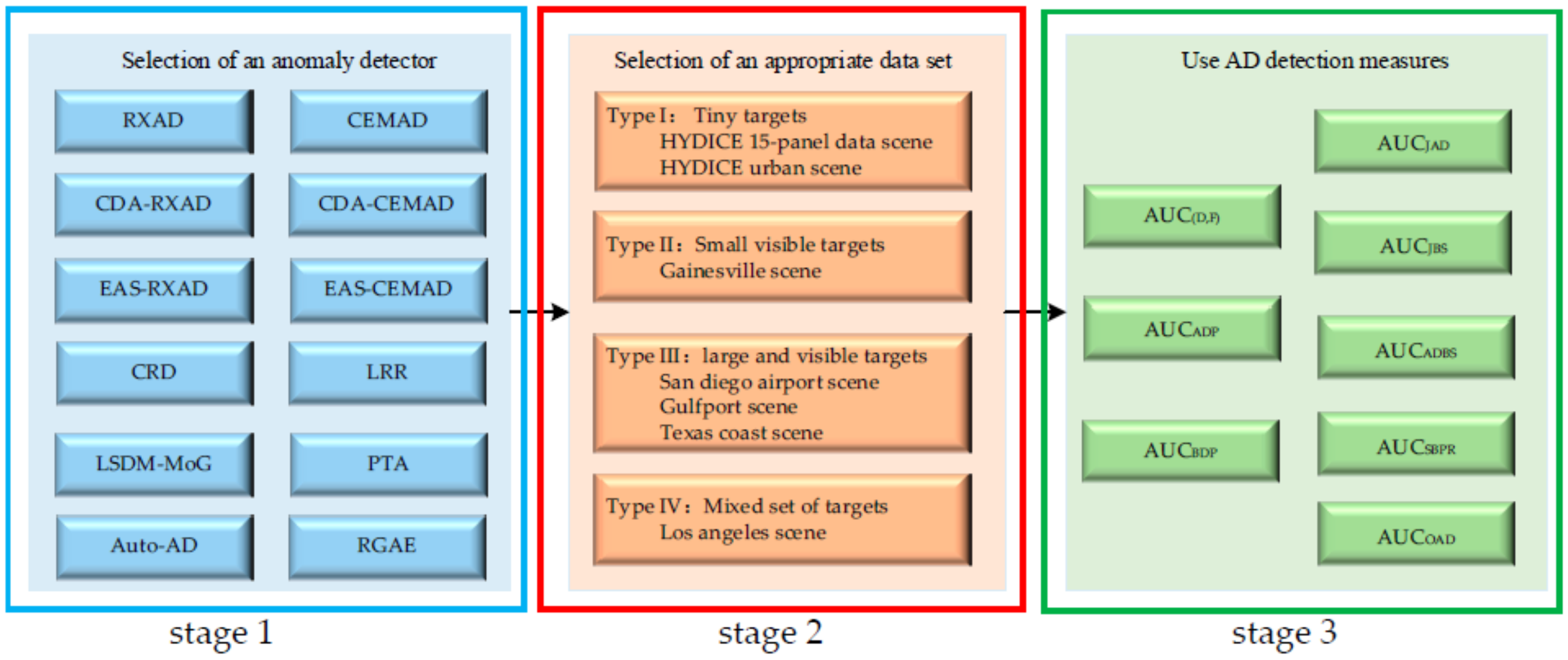
In addition to the issues of anomalies embedded in BKG and contaminated by noise, how to enhance anomaly detectability and to improve BS are also another two major issues. Three attributed elements are identified in this paper, which are (i) selected anomaly detectors, (ii) datasets used for experiments and (iii) detection measures used for performance evaluation.
First of all, the selection of an effective anomaly detector is key to the success of AD. As pointed out above, many AD methods have been already developed in the literature which claim that their AD performances are better than other AD methods. Is this true? If not, how can we justify or verify this?
Second of all, the selection of an appropriate dataset has significant impact on AD since a selected dataset should have sufficient image characteristics that characterize anomalies and BKG complexity to some extent. Of particular importance is that the provided ground truth (GT) should be reliable to reflect true anomalies. Although there is no clear-cut definition of anomalies, it is a general understanding that an anomaly should have its spectral characteristics be distinctly different from its surrounding data samples. How much distinction and difference are up to various interpretations. Nevertheless, from a practical and application viewpoint, it seems that there is no controversy to define an anomaly as a target which is barely visible and cannot be identified spatially by prior knowledge or visual inspection. Using this as a guideline for selecting a dataset should be creditable.
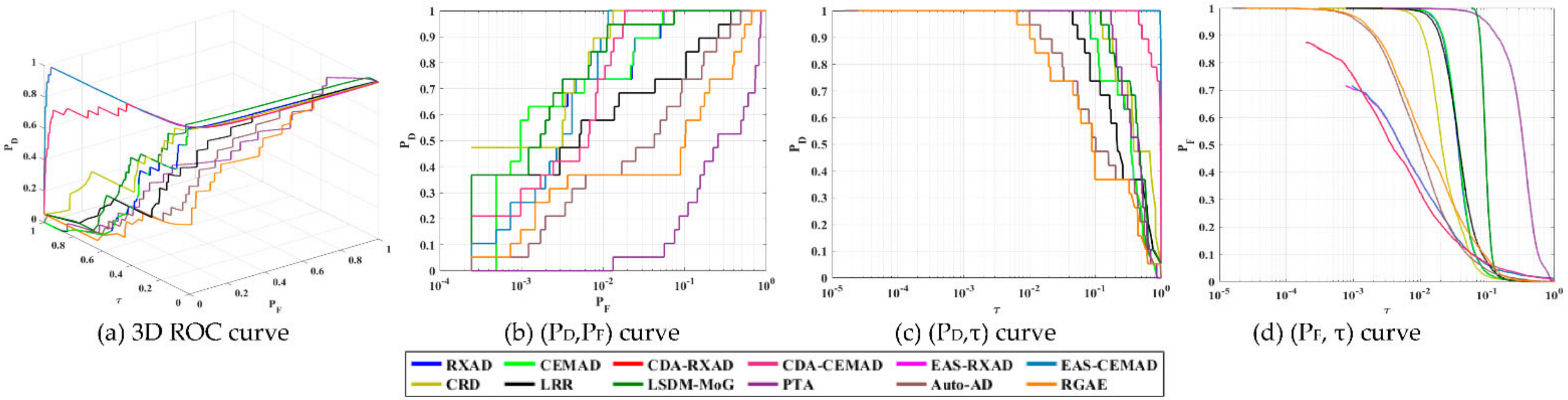
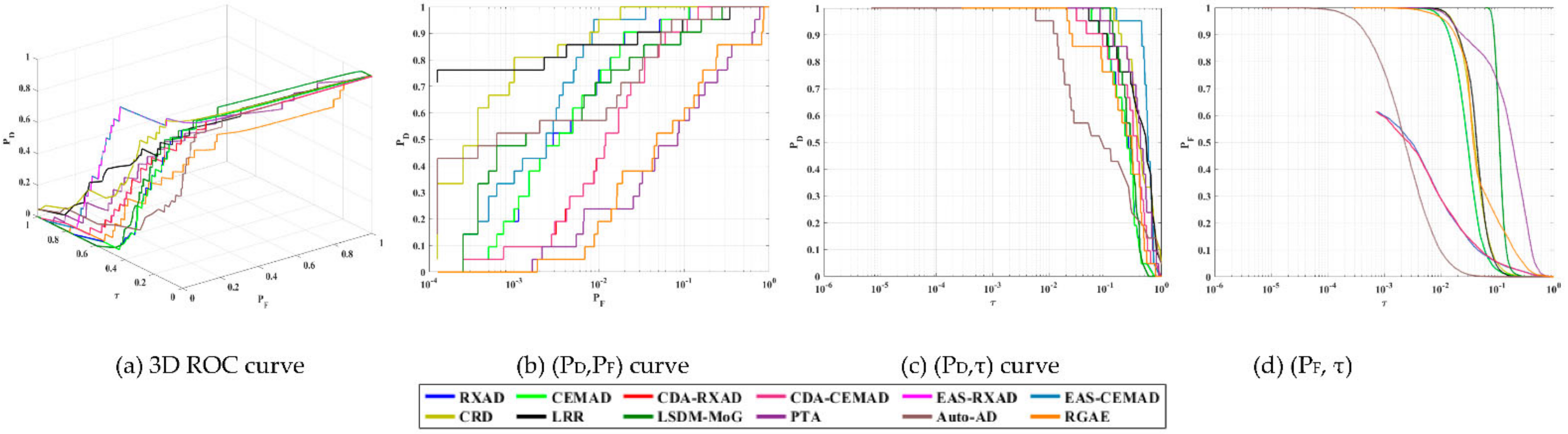
Third of all, in order to assess the performance of an anomaly detector in anomaly detectability and BS, a general and commonly used evaluation tool called the receiver operating characteristic (ROC) curve has been shown to be ineffective [
16]. It is a 2D plot of detection probability, P
D versus false alarm probability, P
F for a given Neyman–Pearson detector [
17]. The value of the area under an ROC curve (AUC
(D,F)) is used as a metric to evaluate detection performance. By virtue of AUC
(D,F), many AD methods in the literature claimed that their developed anomaly detectors performed better than other anomaly detectors by showing their high values of AUC
(D,F). Unfortunately, such a conclusion is misleading for the following reasons. The first reason is the inappropriate use of datasets for AD. For example, one of most widely used datasets, the San Diego Airport data scene, has been shown to not be appropriate for AD [
10] because the three airplanes in the scene are too large to be considered anomalies. A second reason is because P
D and P
F in a 2D ROC curve are determined by the same threshold τ. As a consequence, P
D and P
F cannot work alone independently. Therefore, the AUC
(D,F) value cannot evaluate anomaly detectability because a higher AUC
(D,F) value can result from higher P
D and P
F. Similarly, a lower AUC
(D,F) value which also results from lower values of both P
D and P
F cannot be used to evaluate BS. In particular, the traditional 2D ROC curve of (P
D,P
F) is developed from the signal detection in noise where the BKG is considered to be part of noise. Under this the circumstance, noise and BKG are blended and cannot be separated one way or another. To resolve this issue, in [
18] Chang developed an anomalous BKG model from which a 3D ROC curve analysis was further derived for AD. This same dilemma was also encountered with robust principal component analysis (RPCA) [
19], robust subspace earning (RSL) [
20,
21] and tensor decomposition [
22]. This phenomenon is specifically evident when it comes to AD. So, separating the BKG from noise is critical to AD performance [
10]. If an anomaly is weak, it may be mistakenly treated as noise. On the other hand, if an anomaly is strong, it will be considered to be a part of the BKG. Either case will cause incorrect AD. Apparently, AUC
(D,F) cannot address this issue. What is worse is that the data scene complexity further complicates the mixing of anomalies with the BKG and noise. This leads to the key issue of how to choose an appropriate data scene to effectively validate a designed anomaly detector. Over recent years, the issue of data scene characterization, along with its BKG complexity, has been overlooked and has not been investigated. This paper explores this issue in anomaly detectability and BS.
As noted above, both the P
D and P
F of a 2D ROC inter-act each other and cannot stand alone to be used for analysis. For example, it is often the case that two detectors may have very close AUC
(D,F) values within a negligible difference but behave quite differently as shown in [
23,
24,
25]. This says that using only AUC
(D,F) cannot evaluate the effectiveness of anomaly detectability and BS. Unfortunately, many reports published in the literature have supported their proposed methods solely based on AUC
(D,F), which is very likely to lead to incorrect conclusions. In addition, there is a lack of criteria to measure anomaly detectability as well as BS. To address this issue, a 3D ROC analysis developed recently in [
16,
18] provide a feasible solution. It deviates from the traditional 2D ROC curve of (P
D,P
F) by considering the threshold value τ as an independent parameter to make both P
D and P
F dependent functions of τ. As a consequence, a 3D ROC curve becomes a plot of three parameters, P
D, P
F, τ, which can be used to generate three respective 2D ROC curves of (P
D,P
F), (P
D,τ) and (P
F,τ), each of which produced its own AUC values, AUC
(D,F), AUC
(D,τ
) and AUC
(F,τ
). By manipulating these three AUC values, eight AD measures can be further derived to evaluate anomaly detectability, BS, joint anomaly detectability and BS from all around aspects for AD performance.
Finally, we come to the most crucial issue, which is how to select an appropriate dataset for AD. There are many datasets available on websites that can be used for AD. This paper particularly selects the seven most popular datasets for experiments and conducts a very comprehensive and comparative analysis. These datasets can be categorized into four types of data sets, Type I–Type IV. The two data sets of Type I consist of hyperspectral digital collection experiment (HYDICE) panel data scene and HYDICE urban data scene which contain tiny or barely recognizable targets as anomalies. A data set of Type II, the Gainesville scene, has relatively small visible targets that may only occupy a few full pixels and can be viewed as anomalies. Three data sets of Type III comprise of a San Diego Airport scene, Gulfport scene and Texas coast scene, each of which contains large and visible targets that are hardly considered to be anomalies. The data set of Type IV, a Los Angeles scene, is a mixed-data scene which contains targets of different sizes made up of a data set of Type II that contains small targets and a data set of Type IV that contains large targets. So, for data sets of Type I and II, the detector to be used should be an anomaly detector because the targets to be detected are small and nearly invisible. By contrast, the detectors used for the targets in data sets of Type III and IV should be considered target detectors rather than anomaly detectors because the targets are large and visible and the required target knowledge can be obtained directly by visual inspection. This type of knowledge obtained from observation, i.e., visual inspection, is generally referred to as a posteriori target knowledge. A target detection (TD) method using such a posteriori target knowledge is called a posteriori target detection (PSTD). Now, if we apply PSTD and AD to data sets of Type III and IV, their respective detection results are quite different, as are their drawn conclusions. The most troublesome issue resulting from using data sets of Type III and IV is that a true anomaly detector may not detect large targets as anomalies, but rather detects real anomalies at somewhere else which are not identified by the GT. Consequently, AD using this type of dataset may perform worse than PSTD, which performs TD using the obtained a posteriori target information. Another issue is that the GT maps provided by these datasets may only include targets which can be identified by visual inspection but may not include true anomalies, which cannot be identified through visual inspection or prior knowledge. Therefore, using a visual-based GT to evaluate an anomaly generally yields misleading conclusions, as will be shown later in the experiments.
To see the differences between PSTD and AD, this paper further explores the above issues and performs a detailed comparative analysis on AD and PSTD via extensive experiments. A comprehensive study, along with a detailed comparative analysis, was also conducted for TD and AD via 3D ROC curve-analysis. Specifically, data sets of Type II–Type IV were used for PSTD and AD to simply provide hard evidence that PSTD and AD can lead to different conclusions.
The major contributions of this paper are summarized as follows.
This paper is believed to be the first work to investigate the suitability issue of data scene characterization for AD. In particular, it categorizes data scenes into four types of dataset. It further shows that data sets of Type I and II are suitable for AD, while data sets of Type III and IV are not appropriate for AD or PSTD.
A comprehensive study and analysis on four different types of dataset was conducted for AD to illustrate and demonstrate that different conclusions can be drawn for various anomaly detectors from datasets of different types.
A comparative study and analysis was also performed on data sets of Type III and IV using PSTD and AD to reveal their quite different conclusions.
To evaluate the detection performance of various data scenes, the 3D ROC analysis provides creditable assessments for AD methods and data scenes in terms of BKG and noise issues.
4. Relationship between TD and AD
With no target knowledge, anomalies face two main issues, (i) being unknowingly embedded in the BKG and (ii) being contaminated by noise. More specifically, anomalies are in fact sandwiched between the BKG and noise. So, when a target detector works well, it does not necessarily imply that it also works for AD. A crucial difference between TD and AD is that the former is an active target detection which assumes that the targets to be detected must be known, while the latter is a passive target detection which does not require any target knowledge at all. This taxonomy was initially used in military and intelligence applications where the active TD is considered to be a reconnaissance application which requires prior target knowledge to be used for target detection as opposed to AD, which is considered to be a passive form of TD for surveillance applications without knowing any target knowledge. As a result, active TD is generally evaluated by the detectability of known targets of interest without much concern about noise or the BKG. By contrast, since AD does not know the targets it detects, its performance must rely on its ability in BS. Good BS can increase the contrast of enhancement between the BKG and anomalies which can bring anomalies out of the BKG to light. So, BS is a key measure to evaluate AD performance and has triggered the most recent trends of developing and designing AD algorithms. However, there is one type of detector that can bridge the gap between TD and AD. It is unsupervised TD (UTD) which detects targets without prior target knowledge in an unsupervised means. There are two detection modes that UTD can be carried out. One is active UTD which makes use of a posteriori target knowledge that can be obtained by observation via visual inspection without prior knowledge. Such UTD is called PSTD. The other is passive UTD, which is carried out in a completely blind environment without any target knowledge. Depending upon the specific type of unknown targets to be detected, passive UTD can be interpreted differently. For example, when the unknown targets are those whose spectral signatures are distinct from that of their surrounding data samples, such passive UTD is referred to as AD. On the other hand, if the targets to be detected are endmembers, the resulting passive UTD is called endmember detection (ED). With this interpretation, many of the AD methods developed in the literature are actually passive UTD, but not necessarily anomaly detectors.
To further illustrate the differences between PSTD and AD, datasets of Types II-IV, which contains small targets, large targets and a mixed set of small and large targets, will be used again for experiments.
4.1. Target Detection Measures and Target Detectors to Be Used for Experiments
There are significant differences between PSTD and AD in terms of target/anomaly detectability and BS. As a result, the 3D ROC curve-derived detection measures used for the TD in [
16] are also slightly different from those defined for the AD in [
18]. In this case, detection measures for the TD derived in [
16] will be used for performance evaluation.
Corresponding to AUC
JAD in (41).
Corresponding to 1 + AUC
BS = AUC
JBS in (43).
Corresponding to AUC
ADBS in (45).
Corresponding to 1 + AUC
ODP = AUC
OAD + AUC
(D,F) or AUC
ODP = AUC
OAD + AUC
(D,F) - 1 in (45).
Corresponding to AUC
SBPR in (46).
The target detectors to be used for experiments are CEM in (27) and its variants, kernel CEM (KCEM) [
69], hierarchical CEM (hCEM) [
70] and ensemble CEM (ECEM) [
71] with the following parameter settings.
CEM:
Gaussian kernel
hCEM:
= 200; = 1 × 10−5; max iterations = 100
ECEM:
window size: [1/4, 2/4, 3/4, 4/4]
number of detection layers: 5
number of CEMs per layer: 6
regularization coefficient: 1 × 10−6
4.2. Data Set of Type II: Gainesville Data Scene
There are 11 targets in Gainesville data scene in
Figure 28a which are small but visible.
Table 9 tabulates the size of each target specified by the number of pixels according to the GT.
So, by inspection of
Figure 28a according to GT in
Figure 28b we performed PSTD by selecting a center pixel from each target highlighted by red in
Figure 28c. As a result, a total of 11 pixels out of the 52 GT pixels obtained from
Figure 28b were averaged to generate the desired target signature
used for CEM in (27).
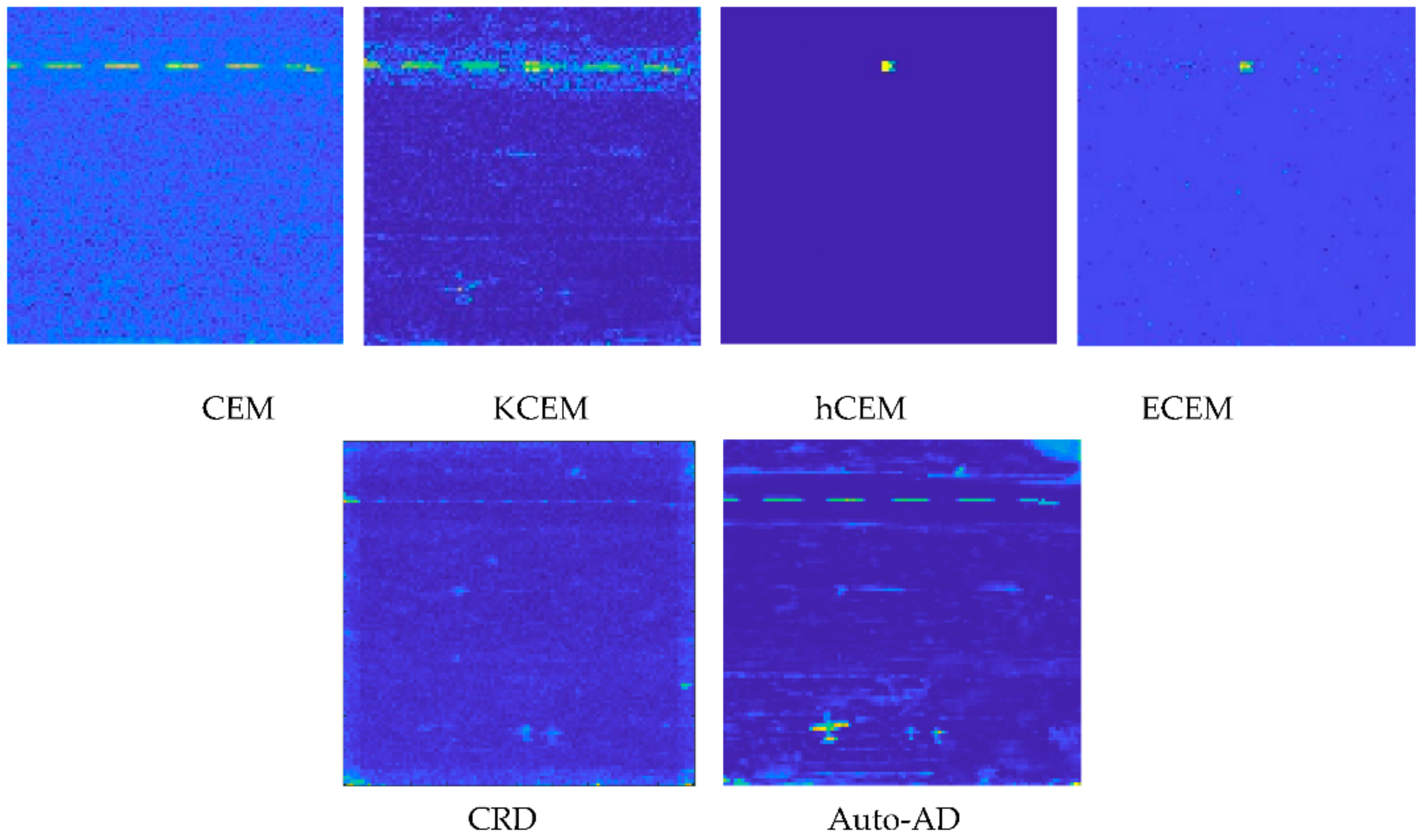
Figure 29 shows the detection maps of 11 targets produced by the CEM, KCEM, hCEM and ECEM with
used as the desired target signature.
By visual inspection of
Figure 29, the KCEM was the best to detect all targets with very good BS, while the CEM could also detect all targets with slightly poor BS. Interestingly, the hCEM had best BS followed by the ECEM, both of which detected all target pixels that were used to calculate
, but they also over-suppressed all other target pixels.
To compare AD, also included in
Figure 29 are AD maps reproduced from
Figure 13 by the best anomaly detectors, the LRR corresponding to the KCEM and Auto-AD corresponding to the hCEM and ECEM along with the CEMAD corresponding to the CEM for comparison. As we can see from
Figure 29, TD using target information obtained by visual inspection performed much better than AD without using target knowledge. This is mainly due to the fact that PSTD knows exactly what targets it intends to detect, opposed to AD which detects all targets simultaneously as an anomaly detector without using any target knowledge. This is justified by evidence that the CEMAD, LRR and Auto-AD also picked up many of the BKG pixels as anomalies. For example, the CEM could detect all the target pixels using
compared to its corresponding anomaly detector counterpart, CEMAD without using
which detected all the target pixels weakly but also picked up the BKG pixels in the upper-right quadrant. As another example, the LRR was the best anomaly detector in terms of target detectability. But when compared to the best target detector, KCEM, the LRR detected quite a few of the BKG pixels. On the other hand, hCEM and ECEM performed excellent BS by only detecting the target pixels used to generate target information,
. Their corresponding anomaly detector counterpart is Auto-AD which also performed best BS. However, Auto-AD still could not compete against hCEM and ECEM in terms of cleaning up the BKG.
To further visualize this,
Table 10 tabulates the eight TD measures using (48)–(52) where the best results for PSTD and AD boldfaced by black and red, respectively. It is very clear that the KCEM was the best with six out of eight quantitative measures, whereas hCEM was the worst in target detectability but best in BS. For comparison,
Table 10 also tabulates eight AD measures produced by the CEMAD, LRR, Auto-AD and running times for Gainesville Scene where the AD-based AUC values produced by the CEMAD, LRR and Auto-AD in
Table 4 are reinterpreted as TD-based AUC values by AUC
ADP = AUC
(D,τ
), AUC
BDP = 1 − AUC
(F,τ
), AUC
JAD = AUC
(D,
F) + AUC
(D,τ
), AUC
JBS = AUC
(D,
F) + 1 − AUC
(F,τ
), AUC
ADBS = AUC
TDBS, AUC
SBPR = AUC
SNPR and AUC
OAD = AUC
(D,τ
) + 1 − AUC
(F,τ
), i.e., AUC
OAD = 1 + AUC
ODP − AUC
(D,F). The quantitative comparison in
Figure 29 between PSTD and AD shows that the best PSTD did better than its corresponding anomaly detector counterpart across board with notable discrepancy. Nevertheless, their difference may not be that much.
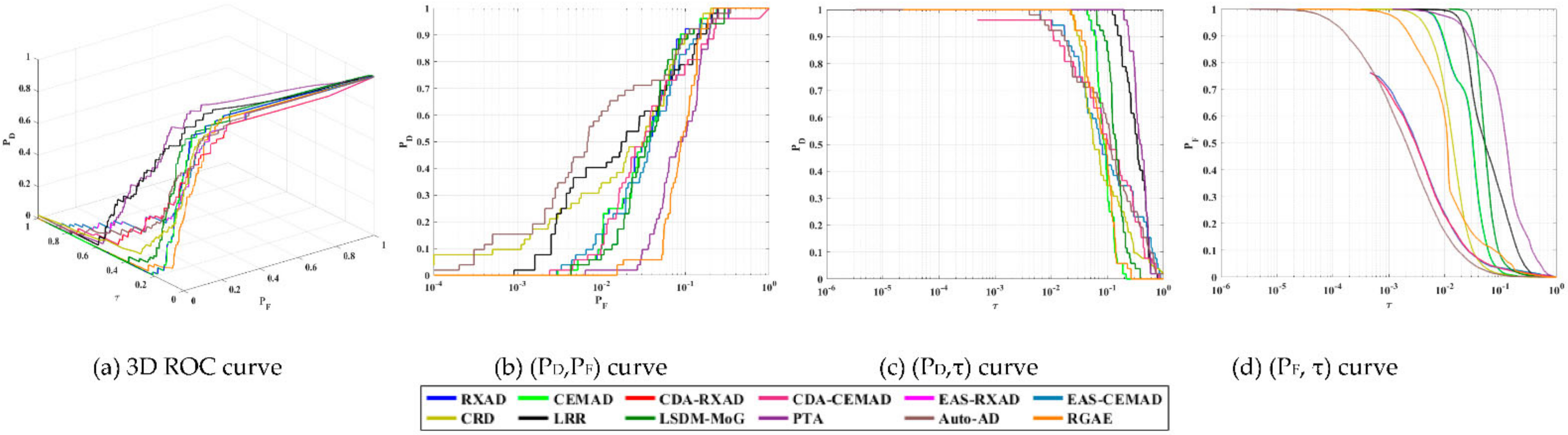
4.3. Data Set of Type III: Gulfport Scene
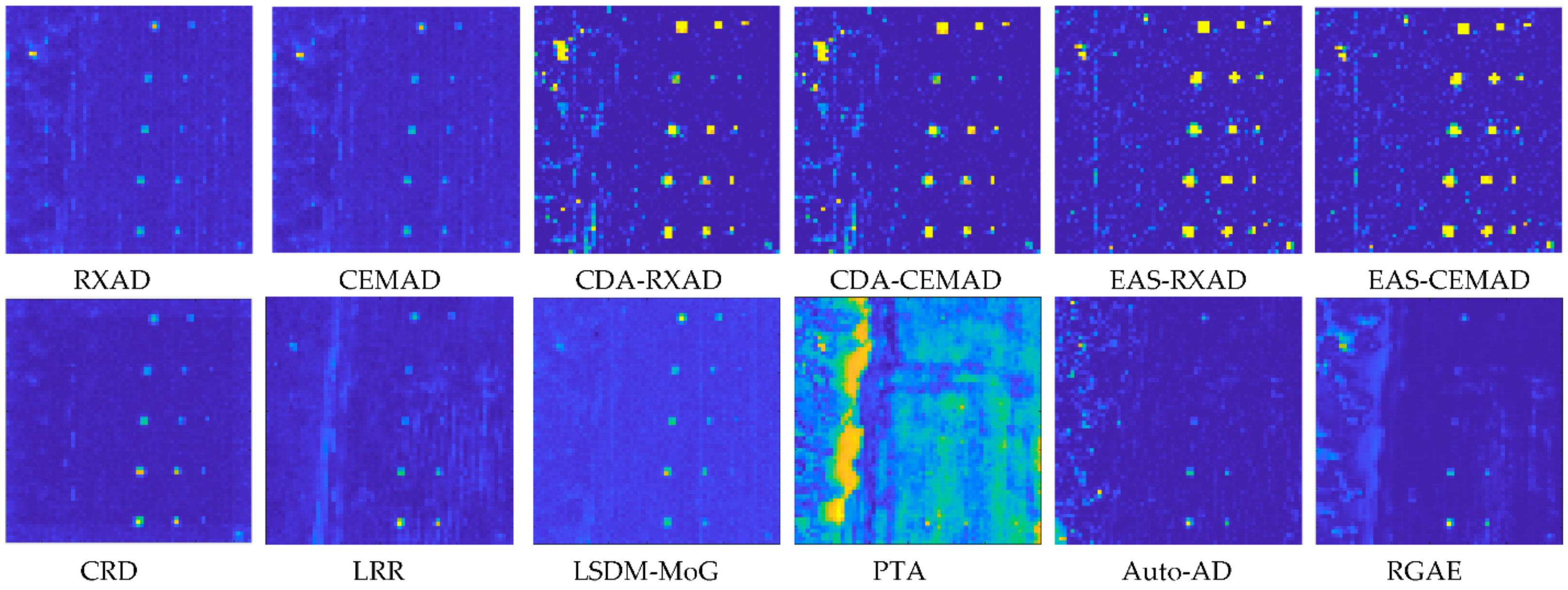
The San Diego Airport scene in
Figure 4 was one of most widely used datasets for AD and has been studied extensively in the literature. Its inappropriateness furfure use in AD was discussed in great detail in ([
10], Section VIII). To avoid duplication, this section investigates another similar but rather interesting data scene, Gulfport in
Figure 30a which also has three airplanes, one large and two small airplanes at the bottom but has a runway at the top part of the scene which was absent in the San Diego Airport data scene. By visual inspection, this runway should not be considered to be an anomaly but rather a specific target object. Accordingly, a detector which detects runway should not be considered for use as an anomaly detector. Two scenarios of PSTD were studied for this scene, one for detection of three airplanes and the other for detection of the runway.
Figure 30b shows its GT map along with
Figure 30c which selected the pixels highlighted by red. These red pixels were averaged to be used as the desired target signature
for
d used for CEM in (27).
Figure 31 shows the detection maps of the CEM, KCEM, hCEM and ECEM. From the visual inspection of
Figure 31, it is interesting to note that the KCEM clearly detected all the three airplanes plus the center line of the runway compared to the CEM, which also detected the three airplanes weakly but did not detect the runway. As for hCEM and ECEM, they were very sensitive to the used target knowledge and only detected those pixels used to obtain the
d for CEM.
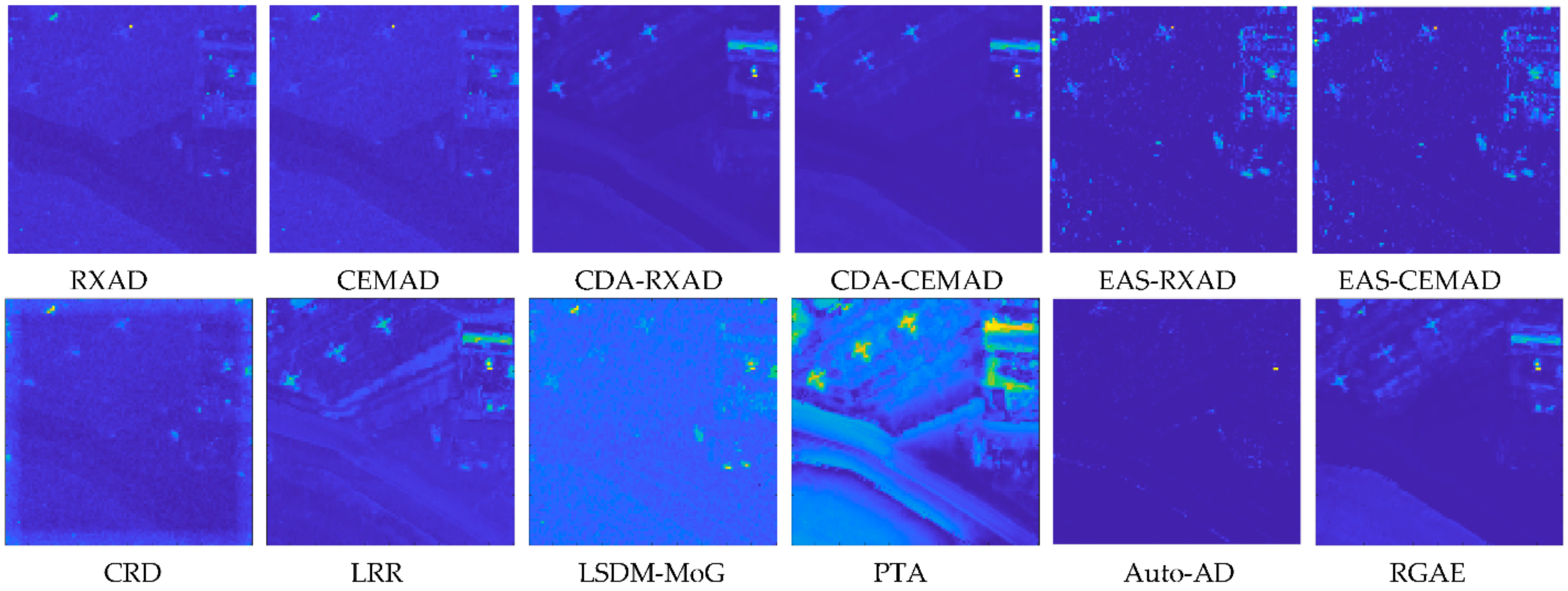
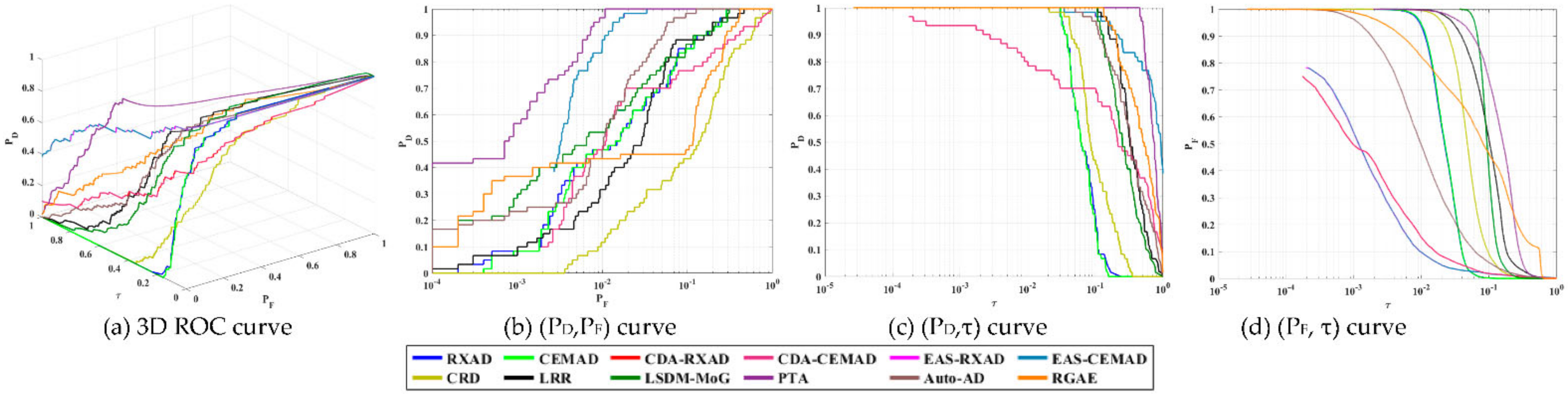
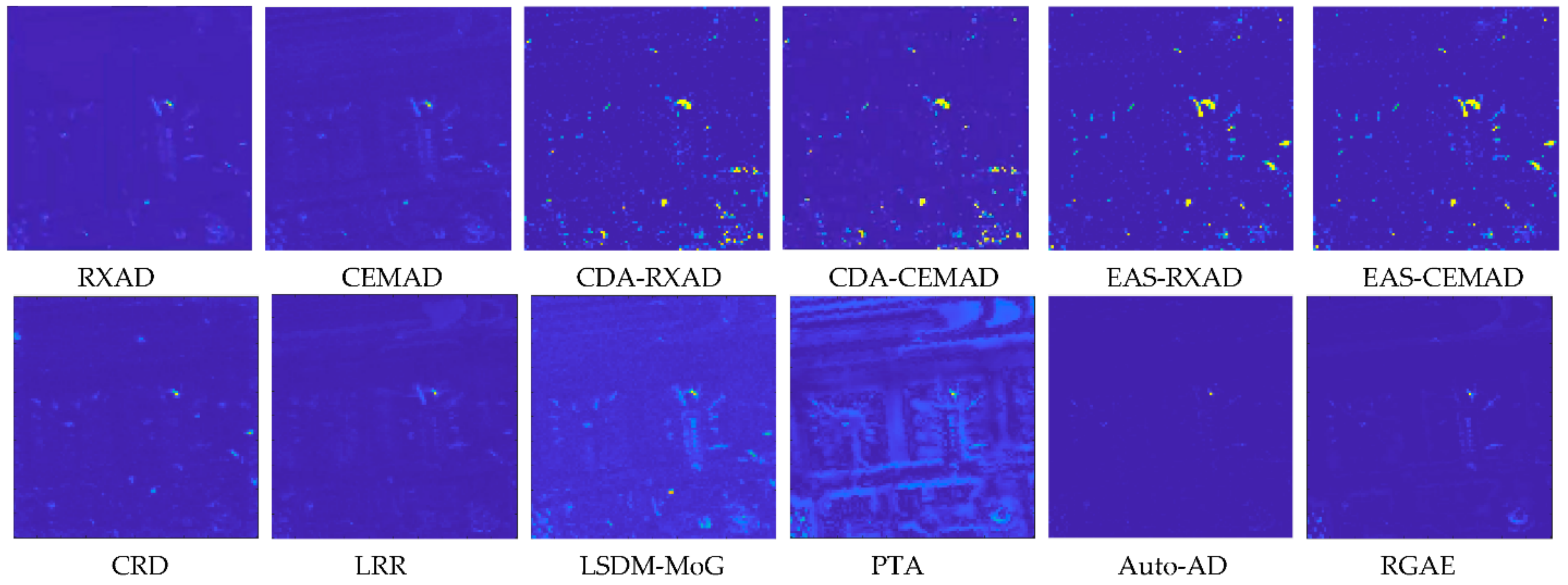
To further compare AD, we also reproduced the AD maps from
Figure 17 and included them in
Figure 31 for comparison with EAS-CEMAD corresponding to CEM and LSDM-MoG corresponding to KCEM most closely by visual inspection where EAS-CEMAD detected the three airplanes but did not detect the runway and LSDM-MoG detected the airplanes as well as the runway.
As we visually inspected the detection maps in
Figure 31, it seemed that the best detector to detect all the three airplanes was EAS-CEMAD with the best AUC
(F,τ), AUC
BS, AUC
TDBS and AUC
SBPR, and not the CEM-based target detectors. However,
Table 11 tabulates the detection maps in
Figure 31 using the eight TD measures including (47)–(51) where the best results for PSTD and AD boldfaced by black and red, respectively. We immediately found that the conclusions made from the visual inspection of
Figure 30 may not be true. As a matter of fact, the detector with best TD was CEM. On the other hand, KCEM achieved the best BS with highest values of AUC
BS and AUC
SBPR where EAS-CEMAD achieved the best AUC
TDBS and AUC
OAD.
Using the small area of the center line in the runway highlighted by yellow in
Figure 31a,
Figure 32 shows the detection maps of the runway produced by CEM, KCEM, hCEM and ECEM. It clearly showed that CEM was the best and even performed better than KCEM, hCEM and ECEM. This was mainly due to the fact that KCEM, hCEM and ECEM were very sensitive to the pixels selected to calculate the desired target signature
d. Also included in
Figure 32 are the two corresponding anomaly detectors, CRD and Auto-AD reproduced from
Figure 17 which yielded the best match the TD maps of CEM and KCEM, respectively by visual inspection. As long as the runway detection is concerned, Auto-AD outperformed all the target detectors and anomaly detectors in the visual inspection even Auto-AD did not use the runway signatures as target knowledge.
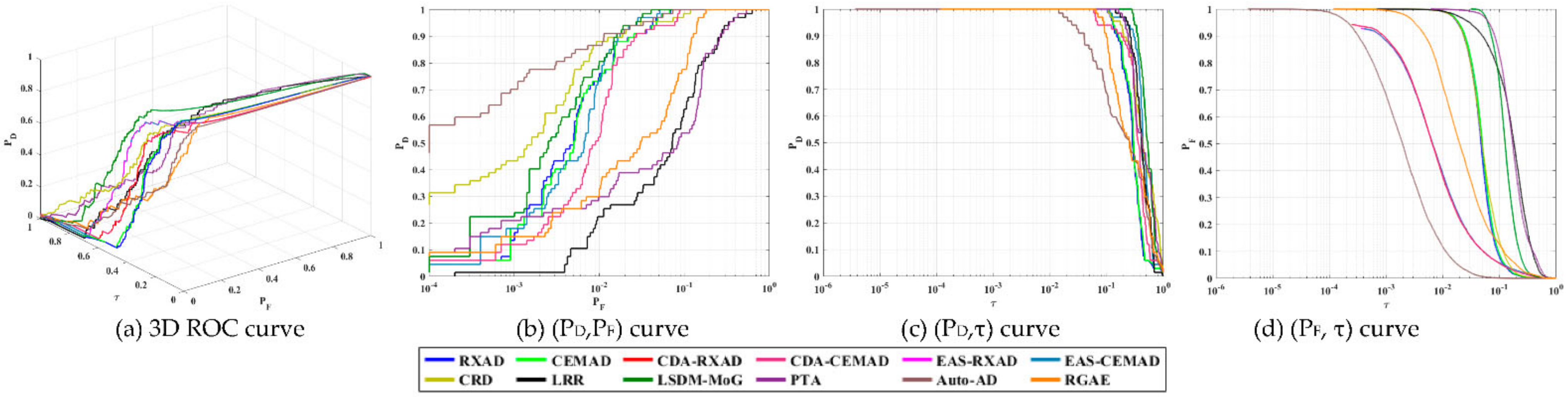
As a summary, the Gulfport scene produced mixed results. It is a good dataset for PSTD, but not AD where PSTD used
a posteriori target knowledge obtained directly from the data by visual inspection without prior knowledge. This is because the GT used for the AD includes only three airplanes without a runway. According to the detection maps in
Figure 17, half of 12 test anomaly detectors, RXAD/CEMAD, CDA-RXAD/CEMAD and EAS-RXAD/CEMAD, did not detect the runway but the other half, CRD, LRR, LSDM-MoG, PTA, Auto-AD and RGAE did. So, if the provided GT does not include the runway, EAS-RXAD/CEMAD were the best. On the other hand, if the GT includes the runway, Auto-AD was clearly the only winner.
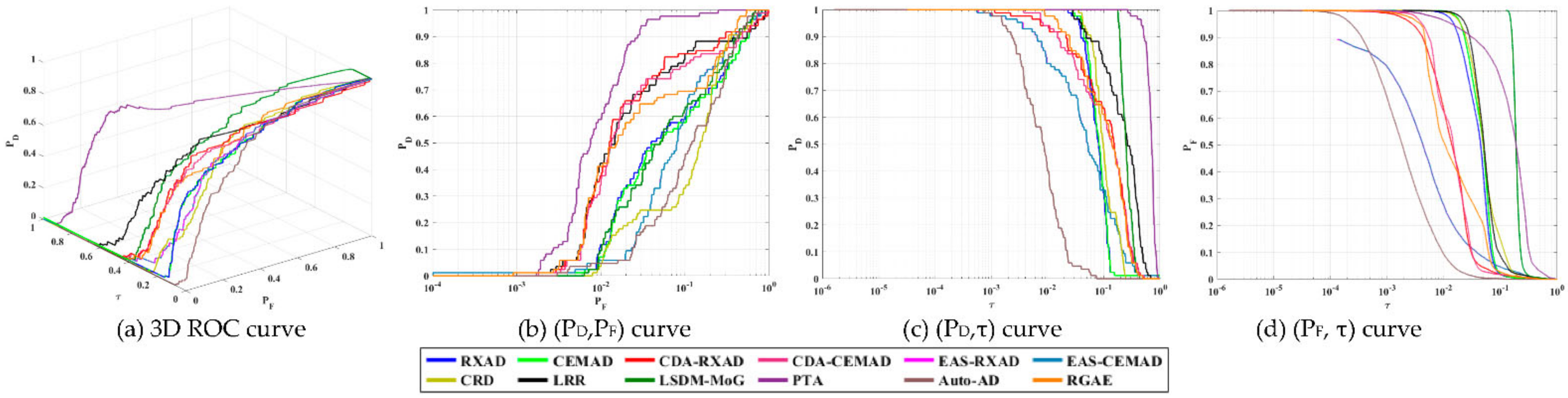
4.4. Data Set of Type IV: Los Angeles Scene
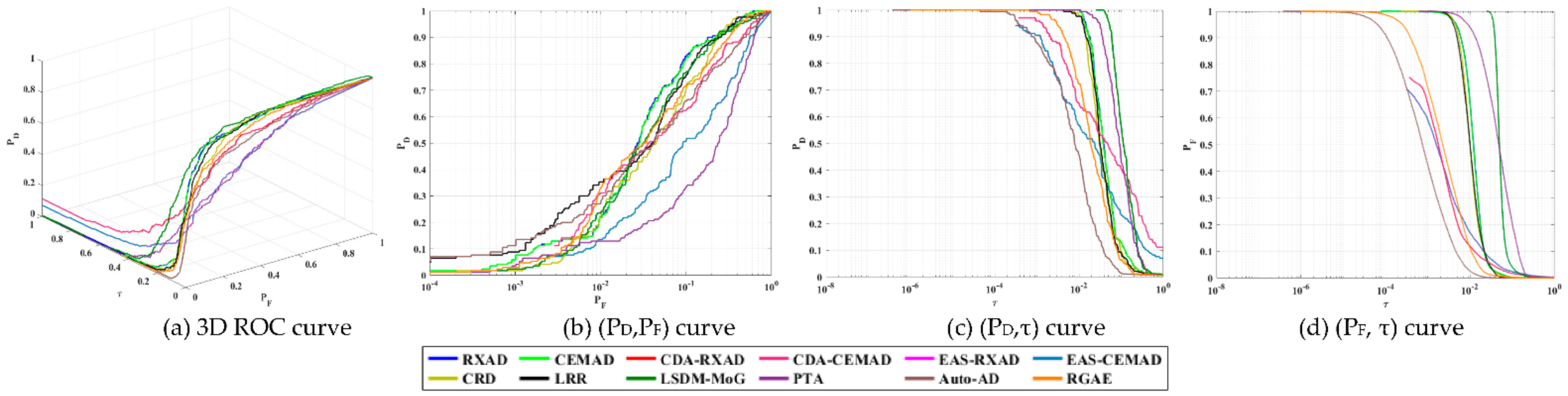
In
Section 3.5.4 the AD maps of the Los Angeles dataset in
Figure 7a produced by 12 test anomaly detectors yielded two sets of completely different detection results shown in
Figure 26a and
Figure 27a. In this section, we investigated the PSTD on the Los Angeles scene further by taking advantage of visual inspection to obtain target knowledge for target detectors, CEM, KCEM, hCEM and ECEM. This scene has two sets of targets of interest, small airplanes and large airplanes.
Table 12 and
Table 13 tabulates the size of each target specified by the number of pixels according to the GT in
Figure 7a and
Figure 7b respectively.
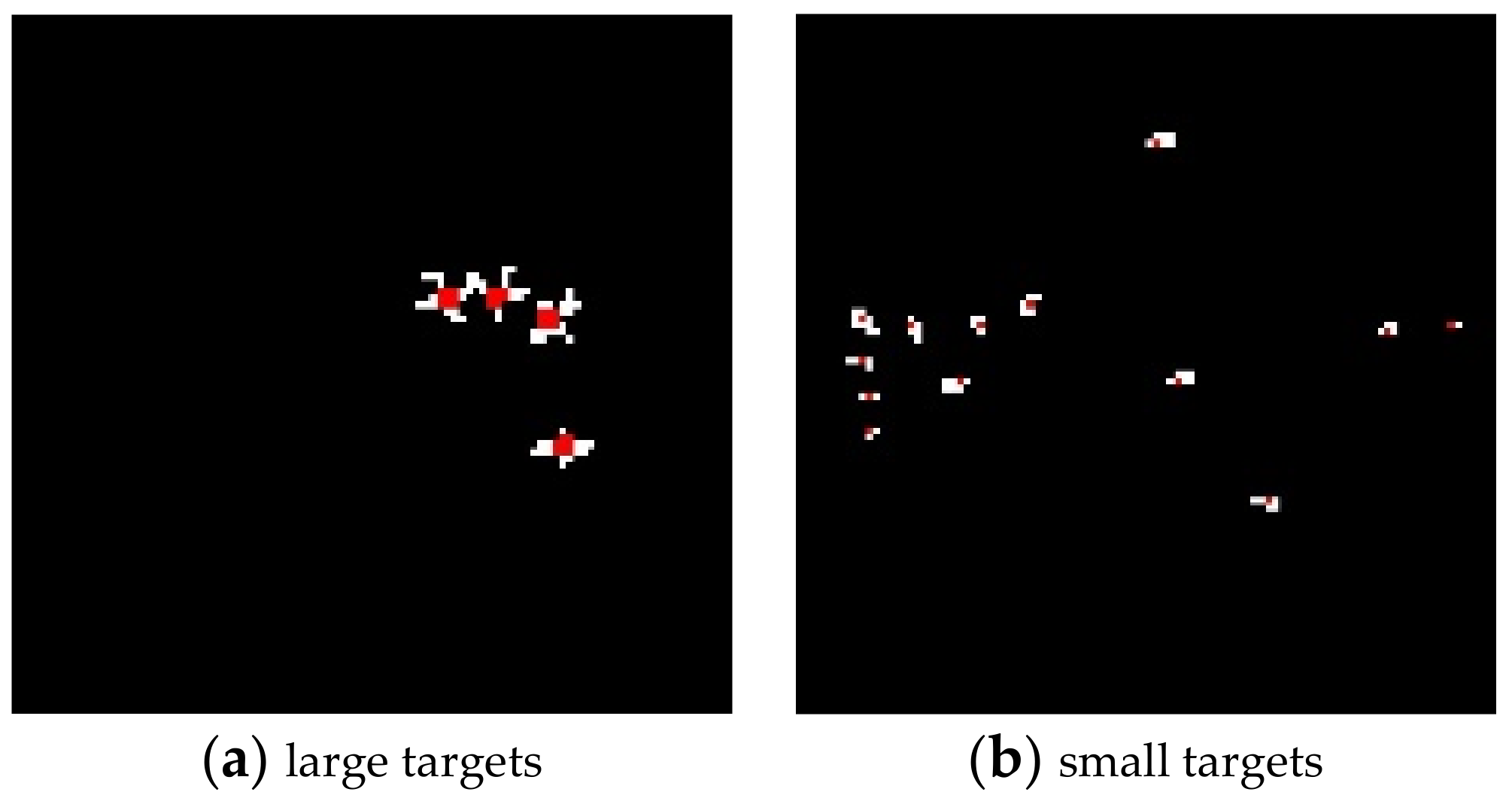
According to GT in
Figure 7b align with our visual inspection, we selected 3 × 3 center pixels from each of large targets and a center pixel from each of small targets highlighted in red shown in
Figure 33a,b, respectively. Then, these selected red pixels obtained in
Figure 33a,b were averaged to generate the desired target signature
used for CEM in (27).
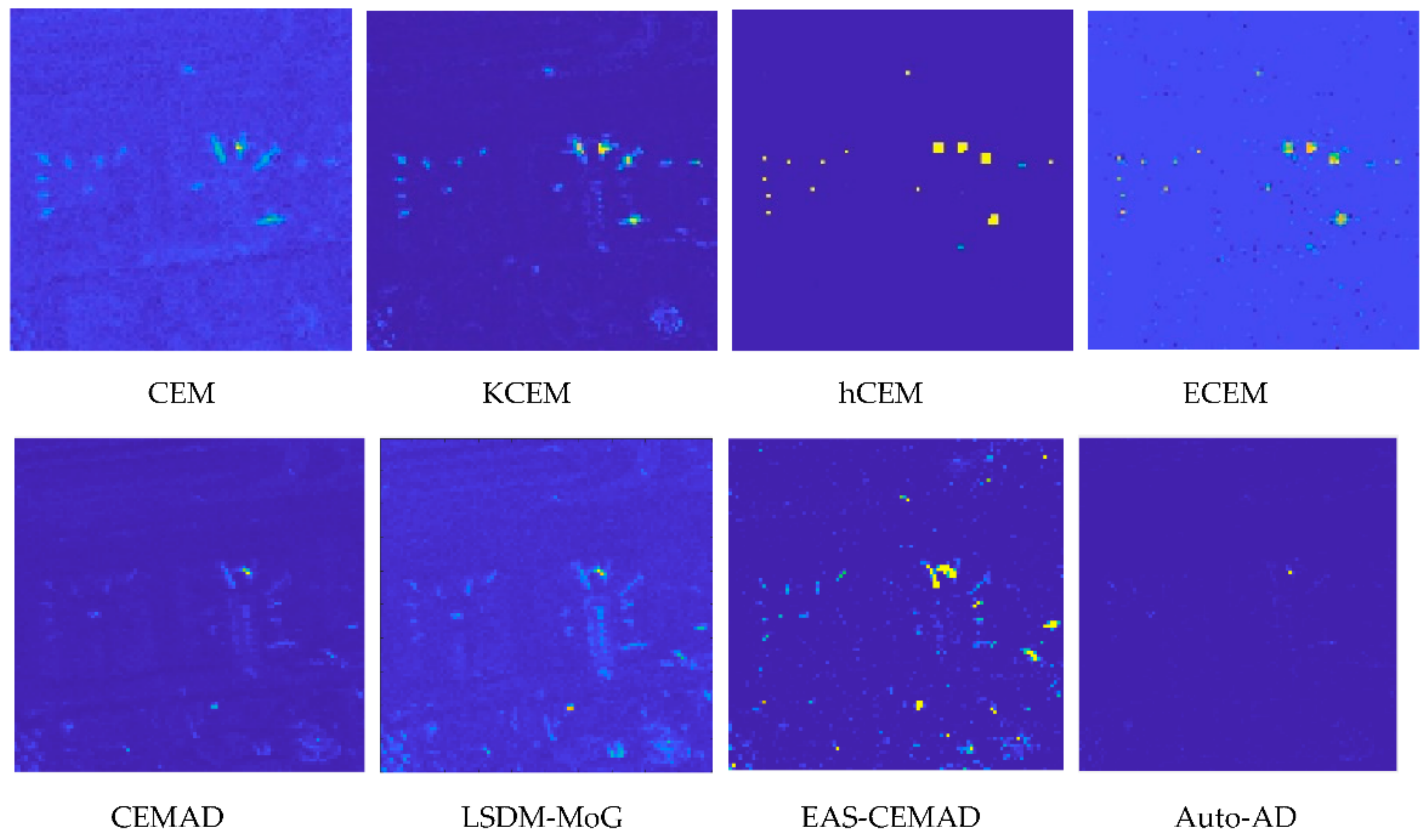
Figure 34 shows the detection maps of 11 targets produced by CEM, KCEM, hCEM and ECEM with
used as the desired target signature where 47 out of the 170 GT pixels for small and large targets selected from
Figure 33a,b were averaged to calculate
.
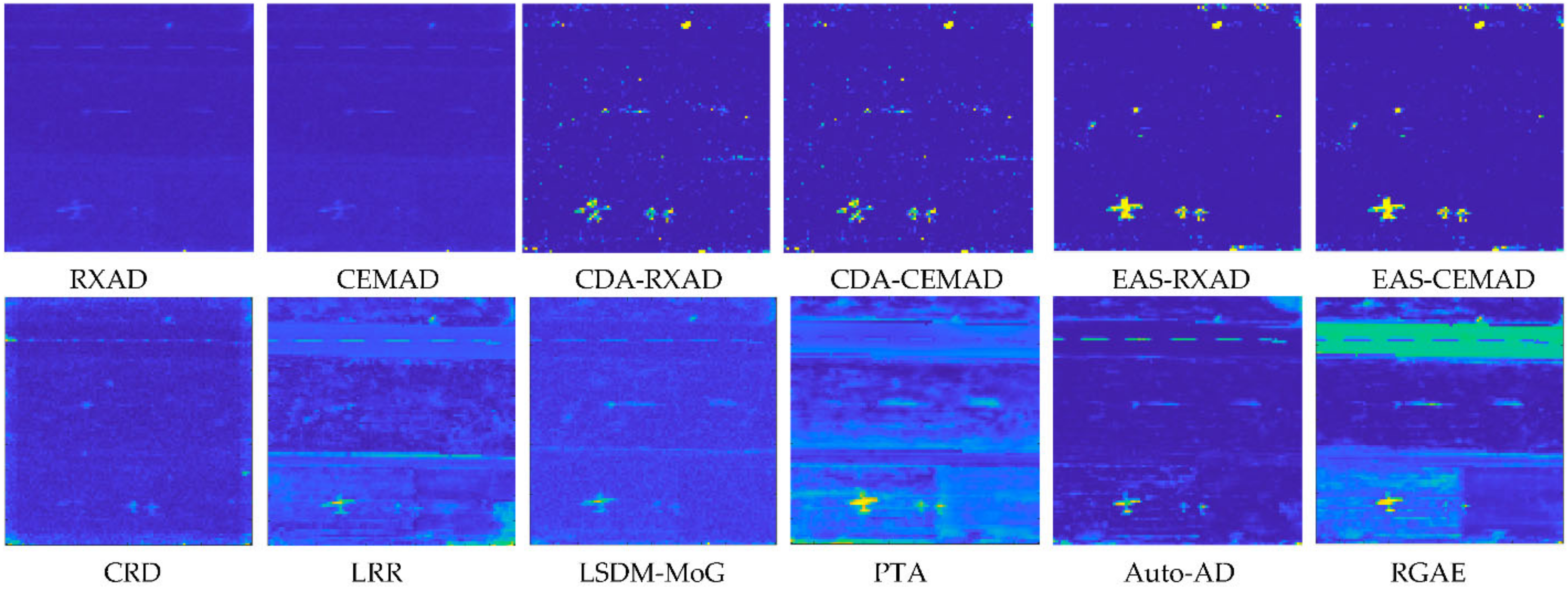
To compare AD, we examined the detection maps in
Figure 34 and tried to identify the best possible anomaly detectors that produced AD maps to best match the detection maps produced by CEM, KCEM, hCEM and ECEM it turns out to be LSDM-MoG corresponding to KCEM, EAS-CEMAD corresponding to hCEM, Auto-AD corresponding to ECEM along with CEMAD corresponding to CEM. As we can see from
Figure 34, PSTD using
a posteriori target information obtained by visual inspection performed much better than its corresponding counterpart AD without using target knowledge. This is because PSTD knows exactly what targets it intended to detect by using
a posteriori target knowledge compared to AD which detects all targets all at once as an anomaly detector without knowing any target knowledge. Like
Table 11,
Table 14 tabulates the detection maps in
Figure 34 using the eight TD measures (47)–(51) where the best results for PSTD boldfaced by black. It is very clear to show that KCEM was the best with four out of the eight qualitative measures, while the ECEM was the worst in target detectability. In addition, the hCEM and ECEM also performed the best in BS. In order to make comparison with
Table 8,
Table 14 also tabulates the eight AD measures produced by the CEMAD, LSDM-MoG, EAS-CEMAD and Auto-AD in terms of the TD measures and running times where the best result for AD are boldfaced by red. The quantitative comparison in
Table 14 between the TD and AD shows that the best target detector did better than its corresponding anomaly detector counterpart across board with notable discrepancy except AUC
(F,τ
) which was only slightly worse within 10
−2 range.
From
Figure 34, CEM detected nearly all the target pixels using
compared to its corresponding anomaly detector counterpart, CEMAD without using
which weakly detected the center pixels of the second large airplane. Also,
Table 14 shows that there is no comparison between the best target detector, KCEM, and the best anomaly detector, LSDM-MoG. It is interesting to see that compared to hCEM, EAS-CEMAD performed relatively well in detecting small targets including small airplanes, while missing a large part of large targets. This is exactly what an anomaly detector is expected to do. Moreover, the EAS-CEMAD also achieved reasonably good results in BS compared to hCEM and ECEM. It is also worth noting that both hCEM and ECEM clearly detected the target pixels used to generate target information,
with very good BS, whereas their corresponding anomaly detector counterparts are (i) EAS-CEMAD, which performed well in BS but also produced many falsely alarmed target pixels, and (ii) Auto-AD, which over-suppressed the BKG at the expense of missing nearly all target pixels.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

































