
Spatial Visualization Based on Geodata Fusion Using an Autonomous Unmanned Vessel

 ,
,  , , and
, , and
Abstract
:1. Introduction
- model and schemes of the fusion of four different kinds of data to obtain a spherical projection of panoramic data,
- investigating the use of different algorithms including machine learning for data processing in geodata tasks,
- real case studies of the proposal by use of an autonomous unmanned vessel.
2. Method
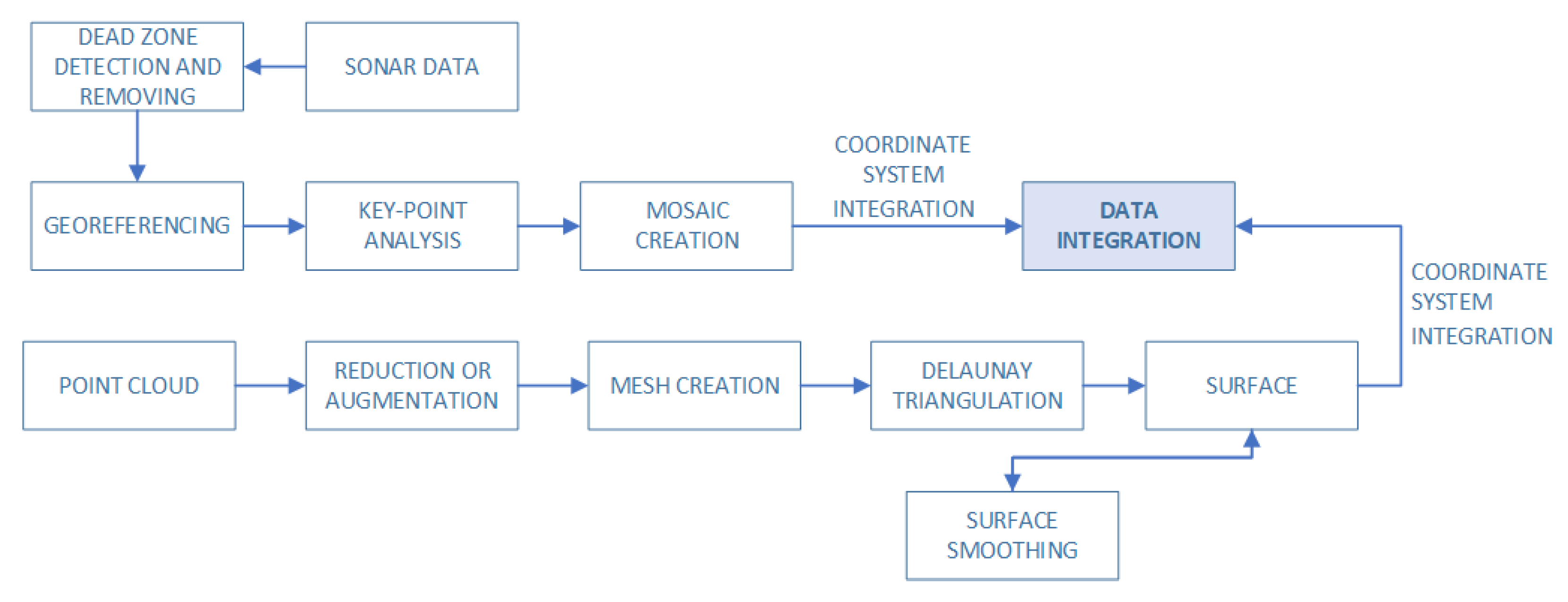
2.1. Underwater Data Fusion: Bathymetric Points and Sonar Data
2.1.1. Bathymetric Points
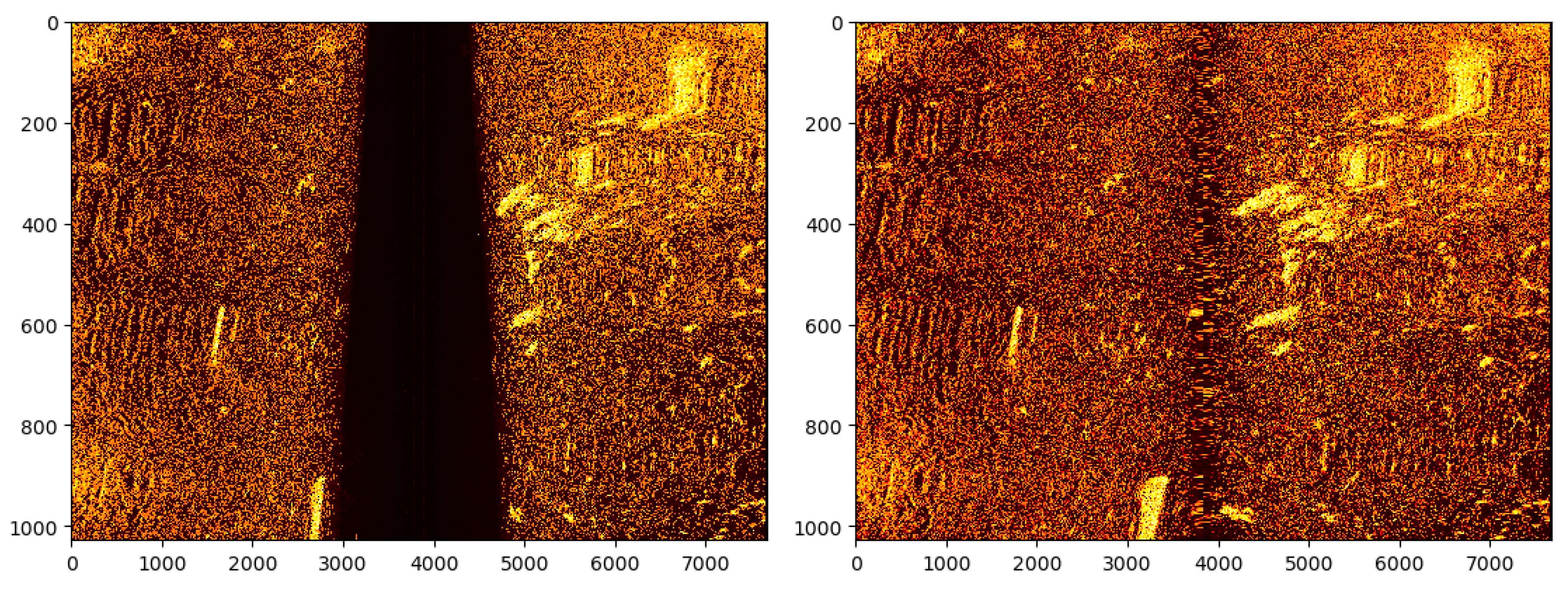
2.1.2. Sonar Data
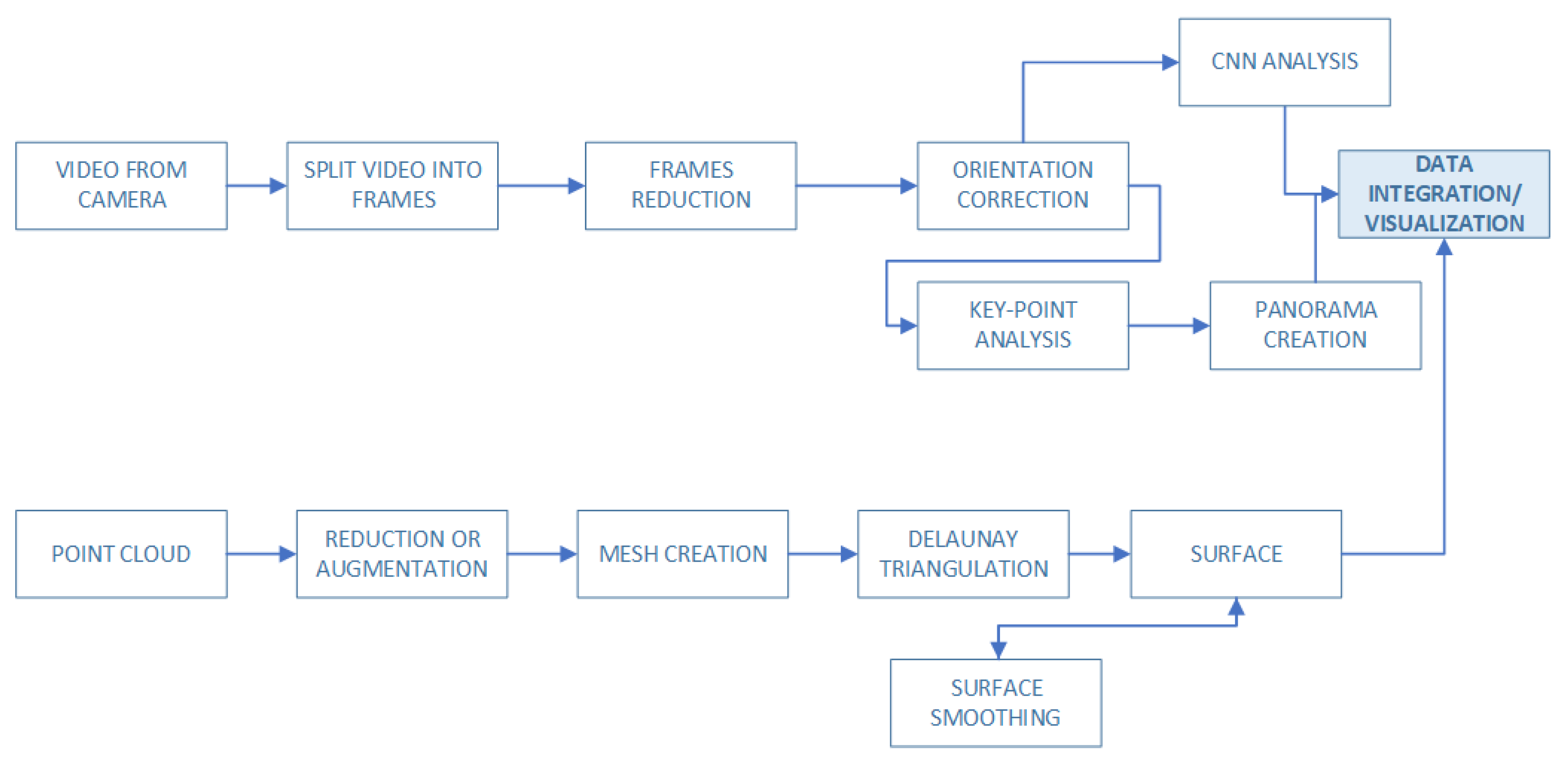
2.2. Above the Sea Data Fusion Model: Lidar and Camera Video
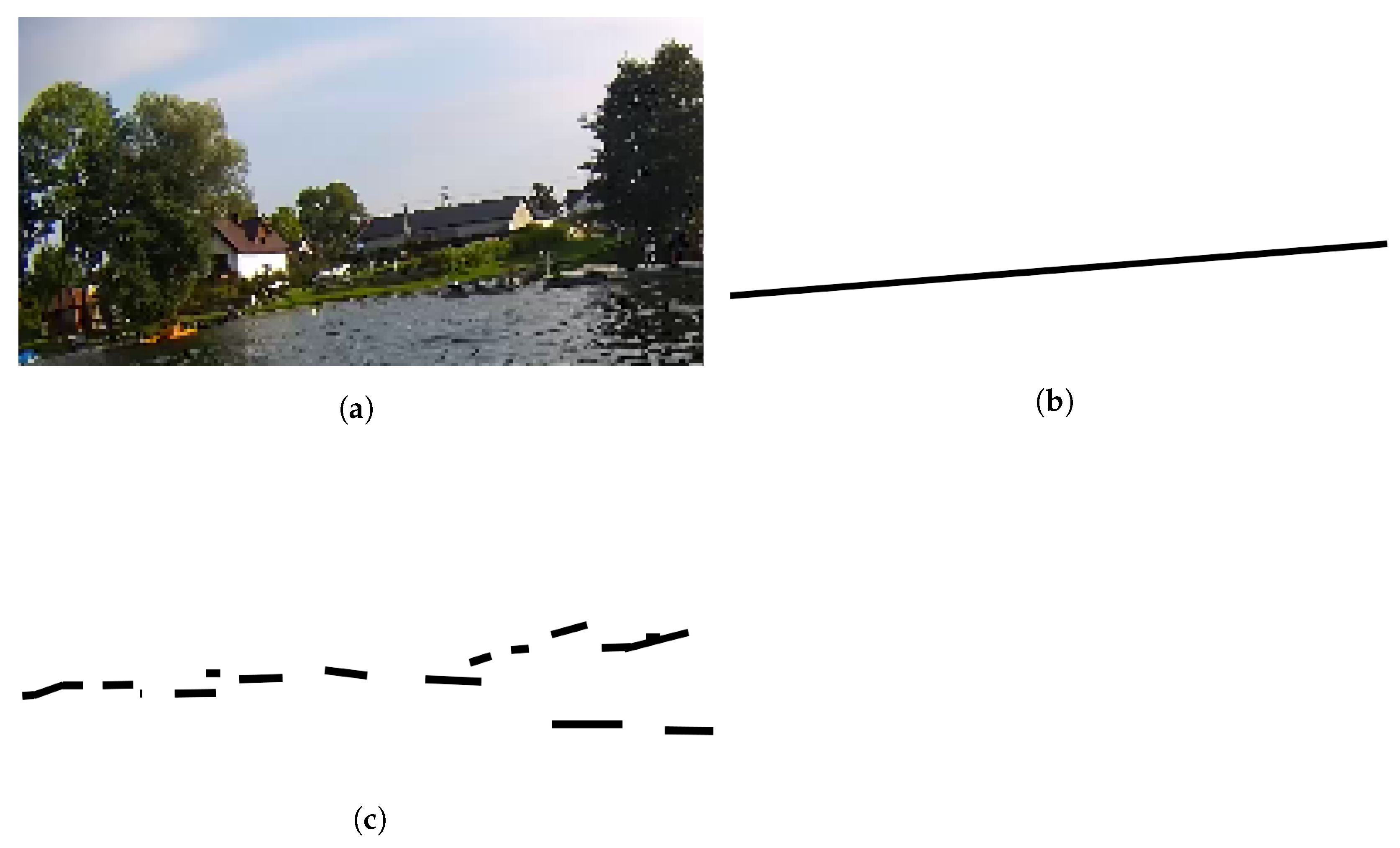
2.2.1. Cropping the Image according to the Selected Methods: Image Processing with Approximation Technique
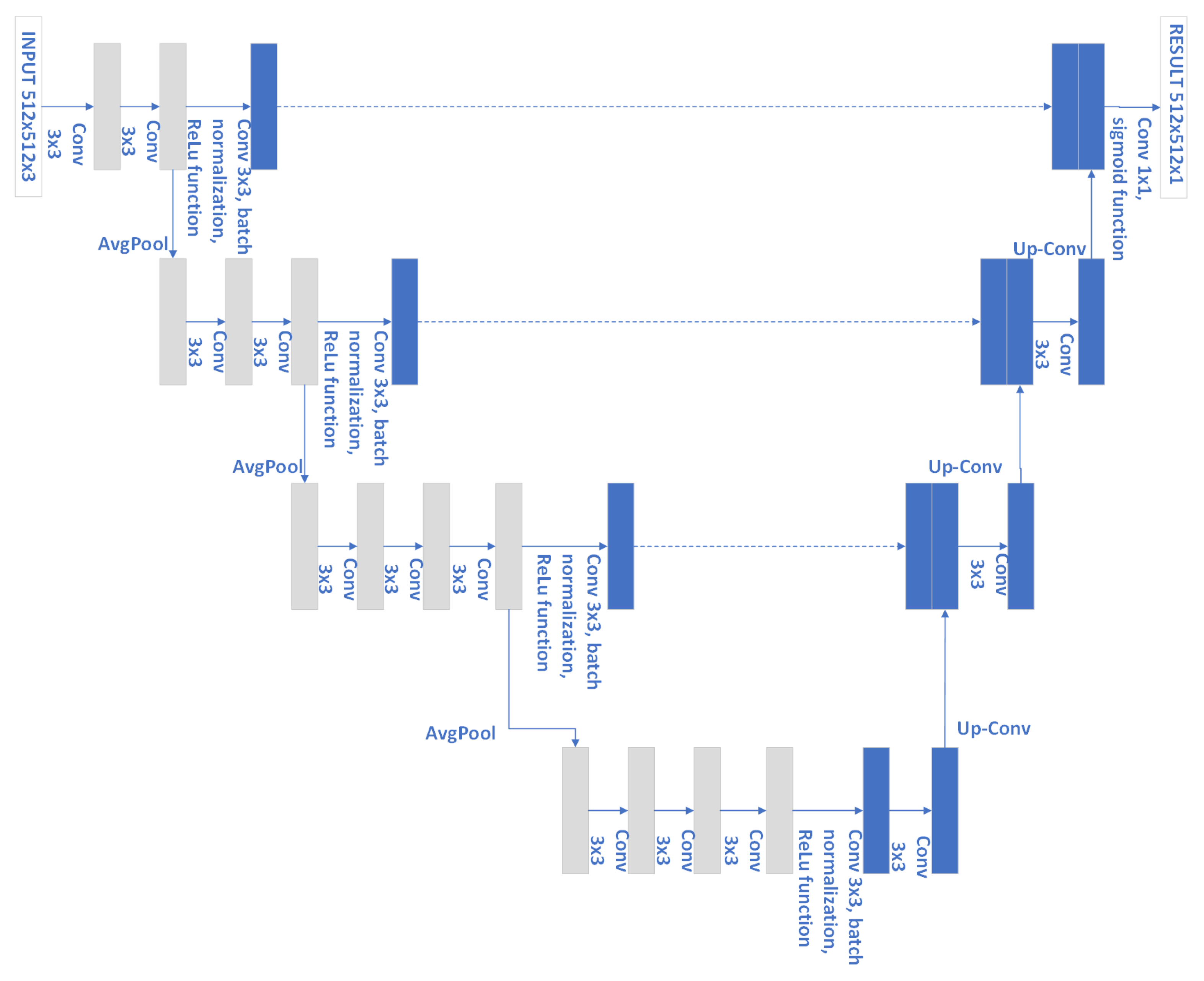
2.2.2. Cropping the Image according to the Selected Methods: U-Nets
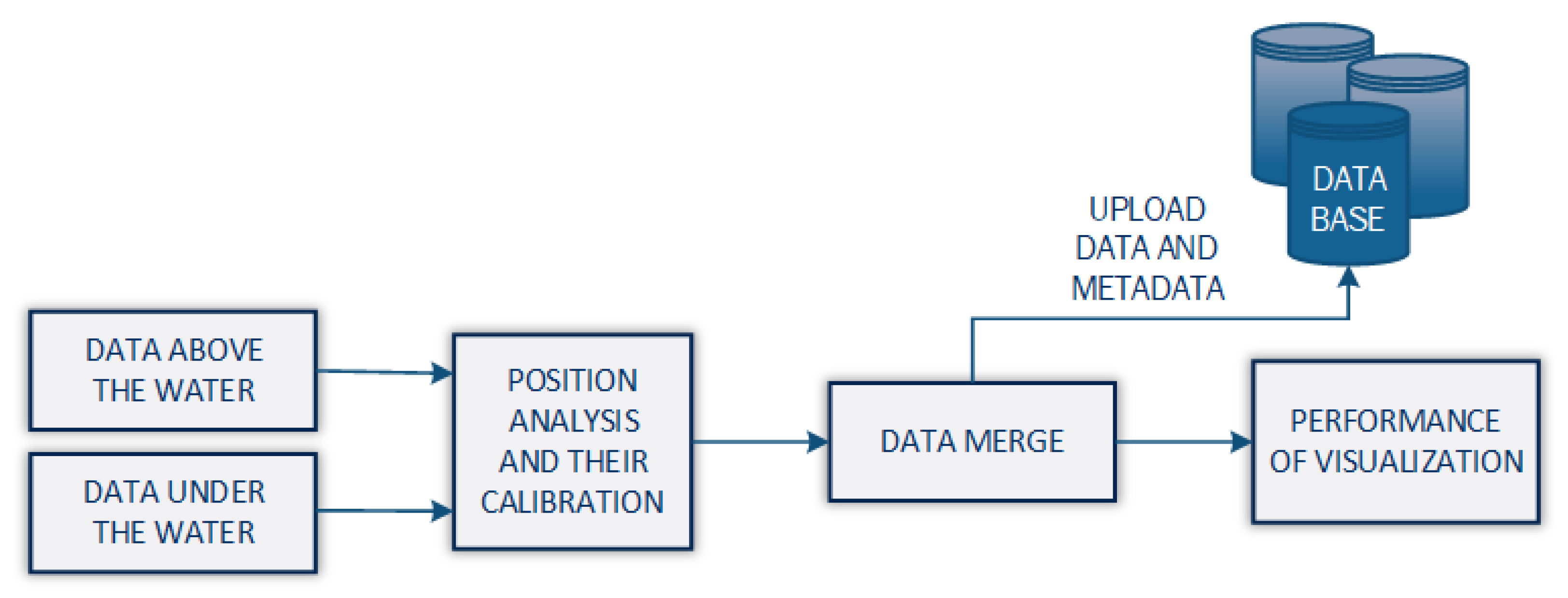
2.3. Data Fusion Based on All Gathered Data
2.4. Analysis Module
| Algorithm 1: Pseudocode of the proposed data processing to obtain chart based on integrated data from various sensors. |
 |
3. Results
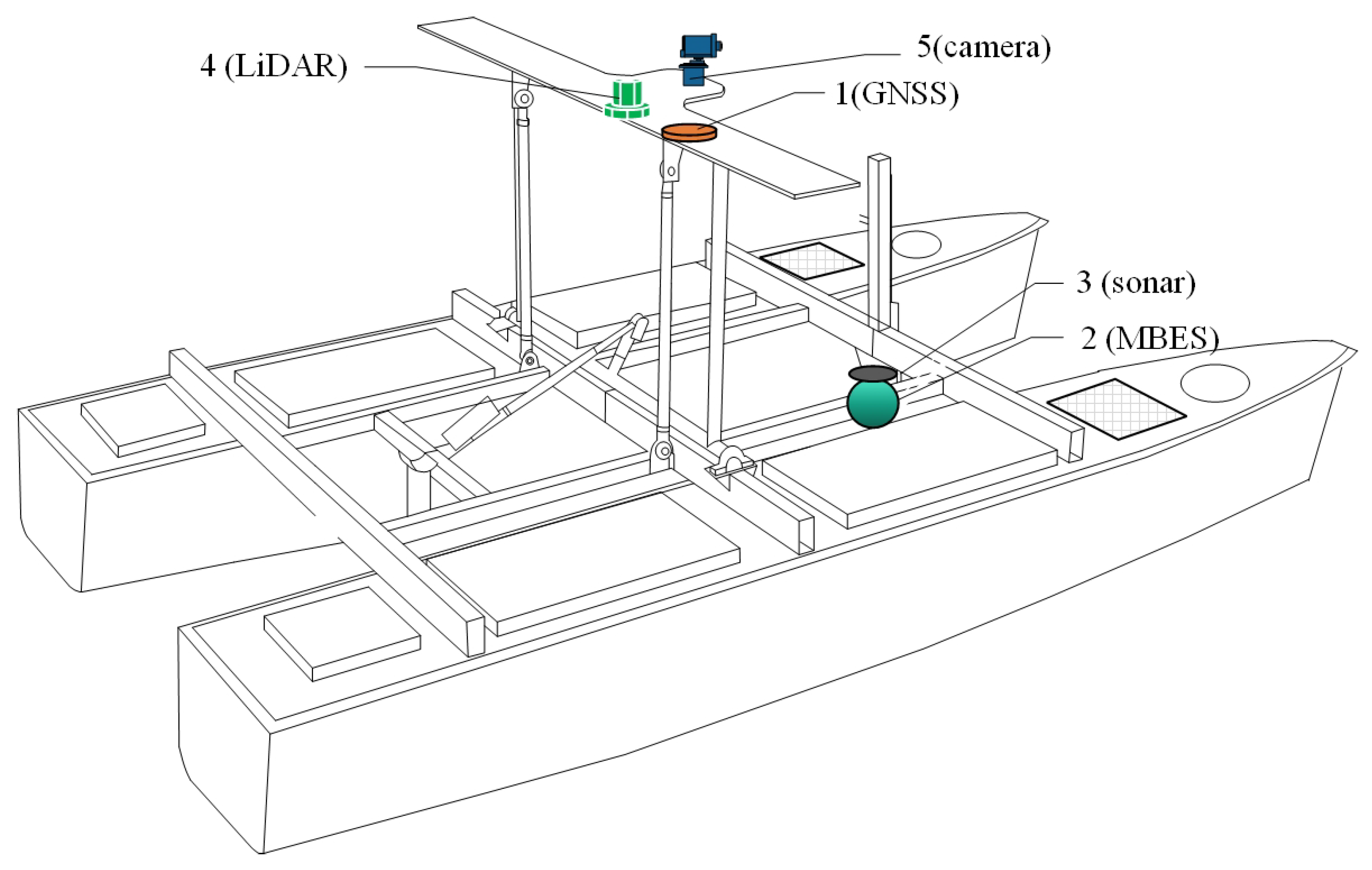
3.1. Settings
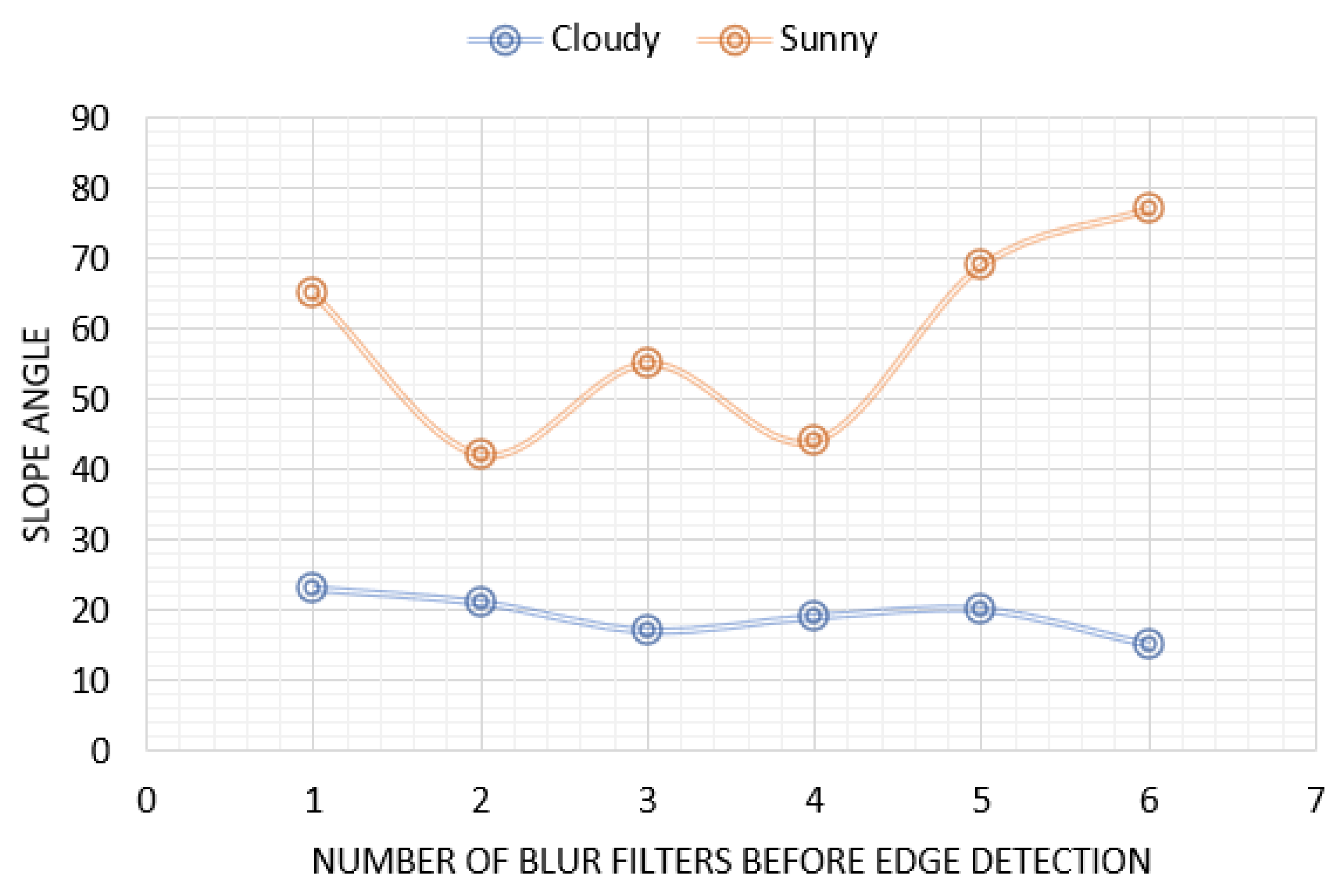
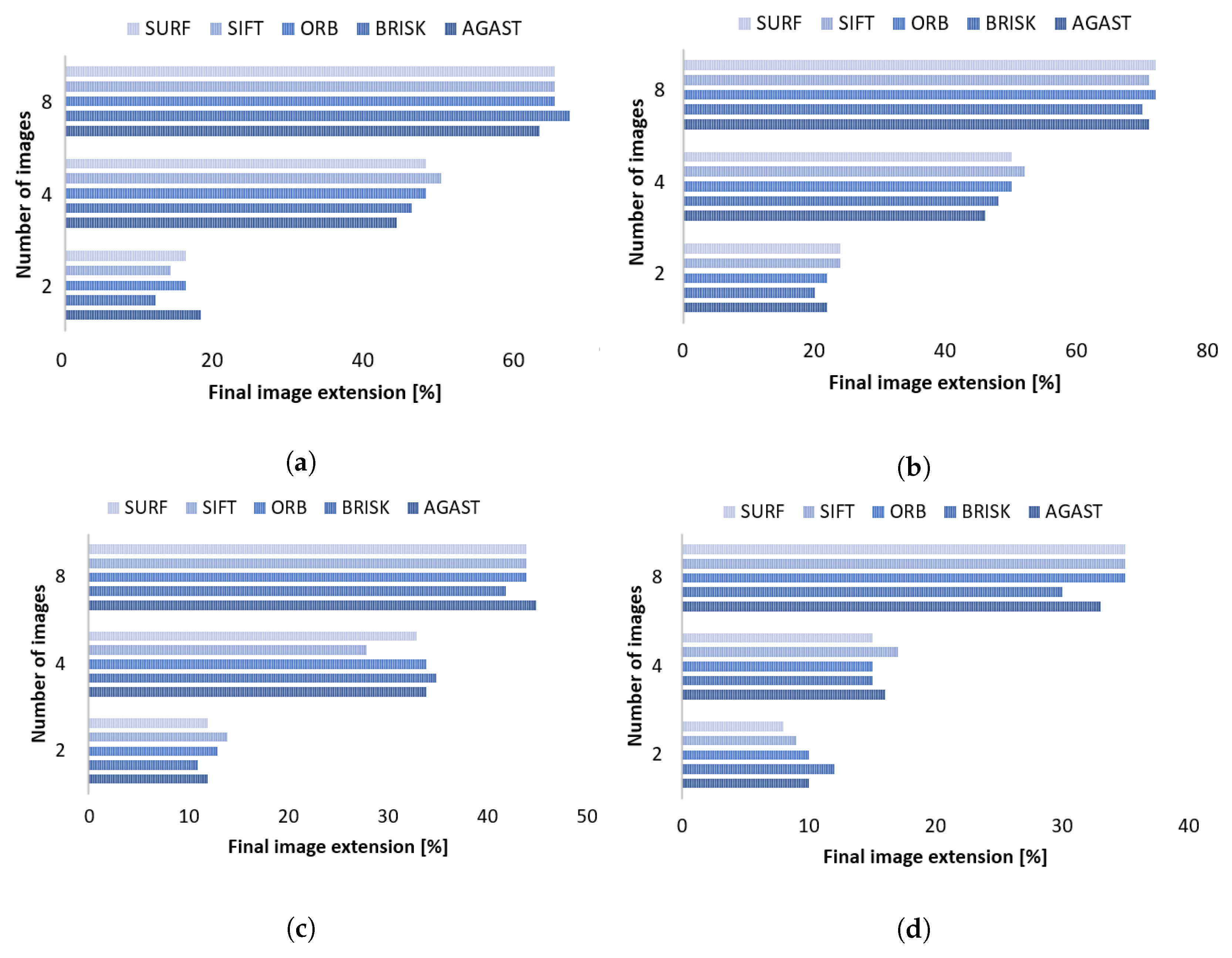
3.2. Image Processing Techniques
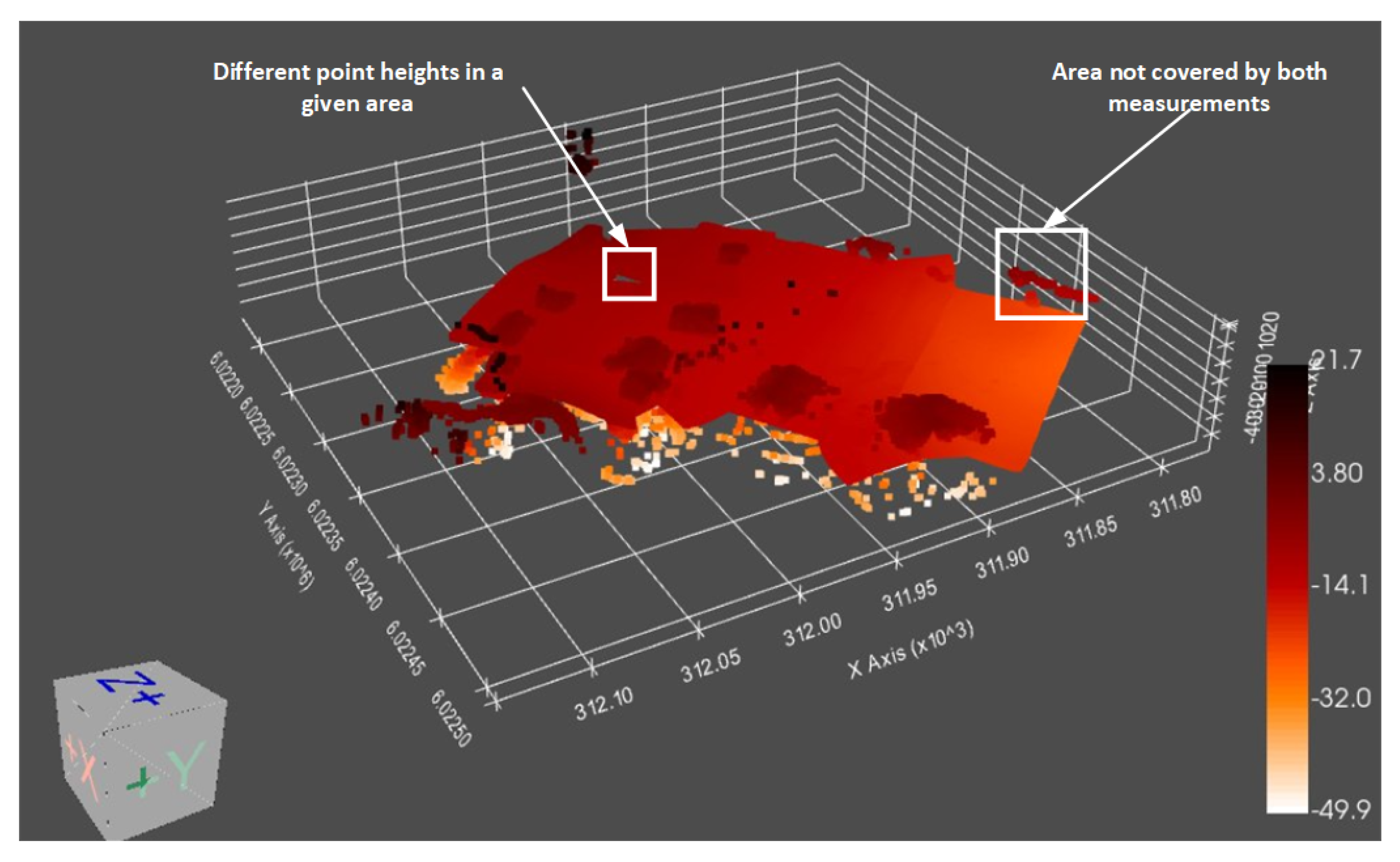
3.3. Surface Creation and Data Integration
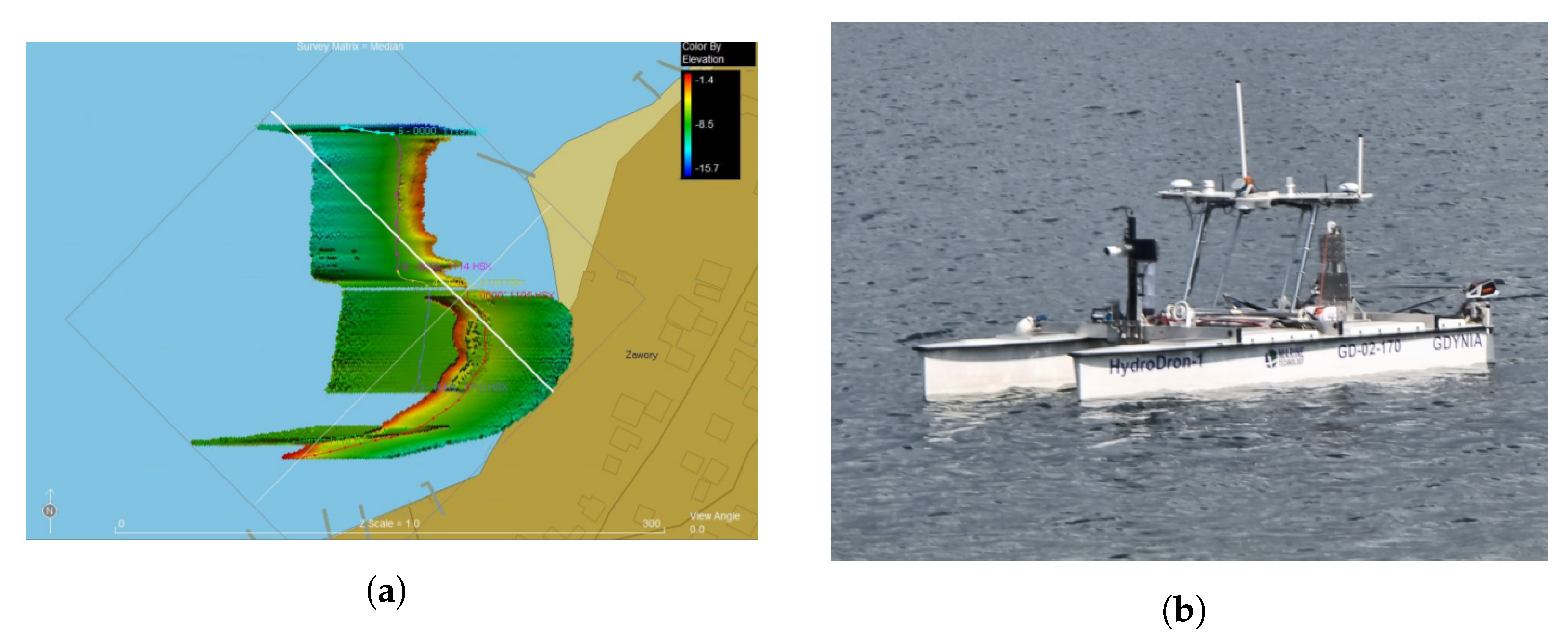
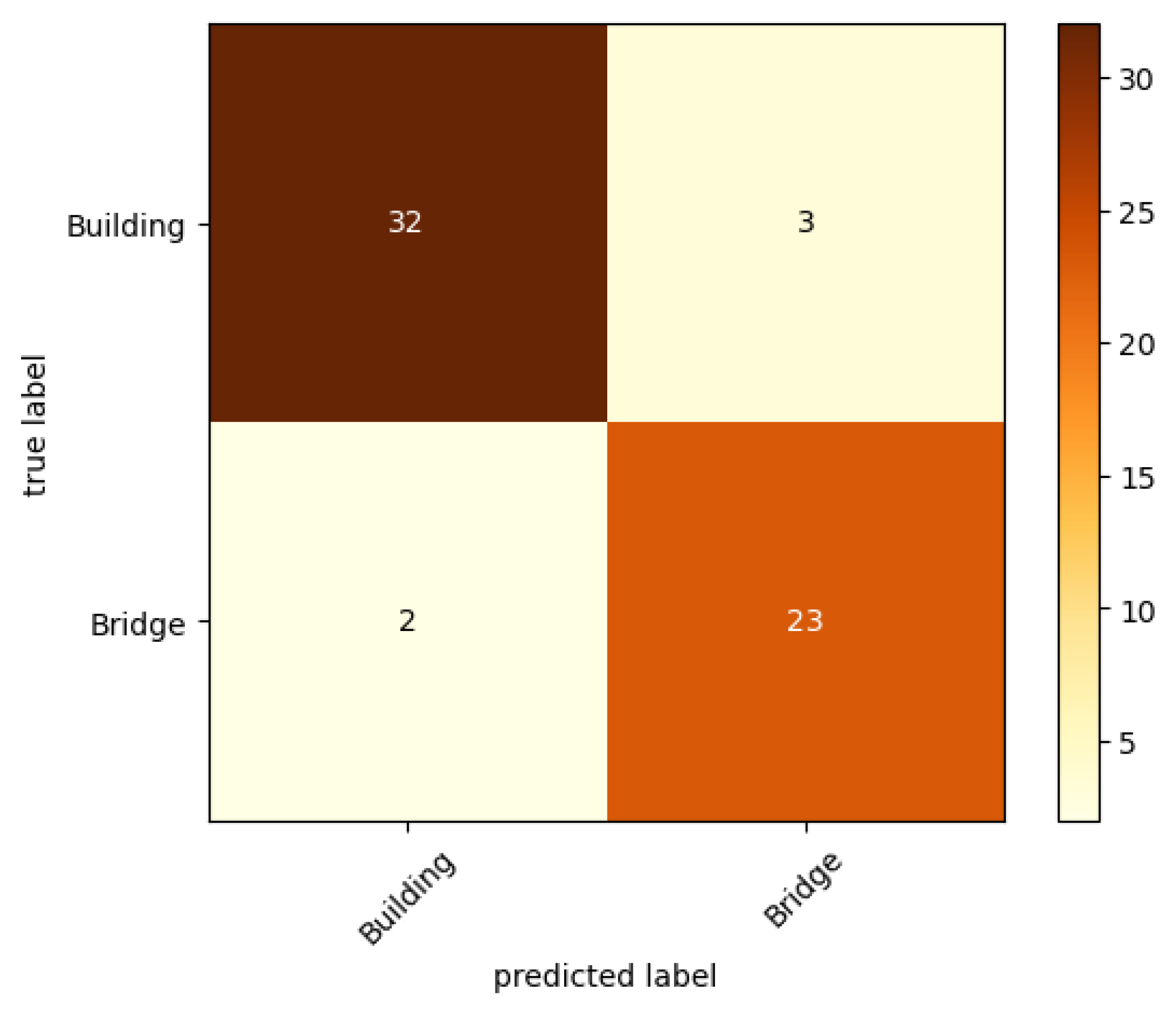
3.3.1. Case Study
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wawrzyniak, N.; Hyla, T.; Bodus-Olkowska, I. Vessel identification based on automatic hull inscriptions recognition. PLoS ONE 2022, 17, e0270575. [Google Scholar] [CrossRef] [PubMed]
- Trigg, A. Geospatial Data Integration: Panacea or Nightmare? Int. Arch. Photogramm. Remote Sens. 1997, 32, 333–340. [Google Scholar]
- Manoj, M.; Dhilip Kumar, V.; Arif, M.; Bulai, E.R.; Bulai, P.; Geman, O. State of the art techniques for water quality monitoring systems for fish ponds using iot and underwater sensors: A review. Sensors 2022, 22, 2088. [Google Scholar] [CrossRef] [PubMed]
- Hoegner, L.; Abmayr, T.; Tosic, D.; Turzer, S.; Stilla, U. Fusion of 3D point clouds with tir images for indoor scene reconstruction. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 5194. [Google Scholar] [CrossRef] [Green Version]
- Fujimura, S.; Kiyasu, S. A feature extraction scheme for qualitative and quantitative analysis from hyperspectral data-data integration of hyperspectral data. Int. Arch. Photogramm. Remote Sens. 1997, 32, 74–79. [Google Scholar]
- Honikel, M. Improvement of InSAR DEM accuracy using data and sensor fusion. In International Geoscience and Remote Sensing Symposium; Institute of Electrical & Electronicsengineers, Inc. (IEE): Piscataway, NJ, USA, 1998; Volume 5, pp. 2348–2350. [Google Scholar]
- Wang, X.; Yang, F.; Zhang, H.; Su, D.; Wang, Z.; Xu, F. Registration of Airborne LiDAR Bathymetry and Multibeam Echo Sounder Point Clouds. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Skovgaard Andersen, M.; Øbro Hansen, L.; Al-Hamdani, Z.; Schilling Hansen, S.; Niederwieser, M.; Baran, R.; Steinbacher, F.; Brandbyge Ernstsen, V. Mapping shallow water bubbling reefs-a method comparison between topobathymetric lidar and multibeam echosounder. In Proceedings of the EGU General Assembly Conference Abstracts, Online, 19–30 April 2021; p. EGU21-15899. [Google Scholar]
- Shang, X.; Zhao, J.; Zhang, H. Obtaining high-resolution seabed topography and surface details by co-registration of side-scan sonar and multibeam echo sounder images. Remote Sens. 2019, 11, 1496. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Qin, H.; Wang, J.; Li, J. OpenStreetMap-based autonomous navigation for the four wheel-legged robot via 3D-Lidar and CCD camera. IEEE Trans. Ind. Electron. 2021, 69, 2708–2717. [Google Scholar] [CrossRef]
- Kunz, C.; Singh, H. Map building fusing acoustic and visual information using autonomous underwater vehicles. J. Field Robot. 2013, 30, 763–783. [Google Scholar] [CrossRef] [Green Version]
- Xie, S.; Pan, C.; Peng, Y.; Liu, K.; Ying, S. Large-scale place recognition based on camera-lidar fused descriptor. Sensors 2020, 20, 2870. [Google Scholar] [CrossRef]
- Hartling, S.; Sagan, V.; Sidike, P.; Maimaitijiang, M.; Carron, J. Urban tree species classification using a WorldView-2/3 and LiDAR data fusion approach and deep learning. Sensors 2019, 19, 1284. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shin, Y.S.; Park, Y.S.; Kim, A. Direct visual slam using sparse depth for camera-lidar system. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 5144–5151. [Google Scholar]
- Subedi, D.; Jha, A.; Tyapin, I.; Hovland, G. Camera-lidar data fusion for autonomous mooring operation. In Proceedings of the 2020 15th IEEE Conference on Industrial Electronics and Applications (ICIEA), Kristiansand, Norway, 9–13 November 2020; pp. 1176–1181. [Google Scholar]
- Wang, M.; Wu, Z.; Yang, F.; Ma, Y.; Wang, X.H.; Zhao, D. Multifeature extraction and seafloor classification combining LiDAR and MBES data around Yuanzhi Island in the South China Sea. Sensors 2018, 18, 3828. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- De Silva, V.; Roche, J.; Kondoz, A. Robust fusion of LiDAR and wide-angle camera data for autonomous mobile robots. Sensors 2018, 18, 2730. [Google Scholar] [CrossRef] [Green Version]
- Ge, C.; Du, Q.; Li, W.; Li, Y.; Sun, W. Hyperspectral and LiDAR data classification using kernel collaborative representation based residual fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1963–1973. [Google Scholar] [CrossRef]
- Liu, H.; Yao, Y.; Sun, Z.; Li, X.; Jia, K.; Tang, Z. Road segmentation with image-LiDAR data fusion in deep neural network. Multimed. Tools Appl. 2020, 79, 35503–35518. [Google Scholar] [CrossRef]
- Hu, C.; Wang, Y.; Yu, W. Mapping digital image texture onto 3D model from LiDAR data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2008, 37, 611–614. [Google Scholar]
- Dąbrowska, D.; Witkowski, A.; Sołtysiak, M. Representativeness of the groundwater monitoring results in the context of its methodology: Case study of a municipal landfill complex in Poland. Environ. Earth Sci. 2018, 77, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Blachnik, M.; Sołtysiak, M.; Dąbrowska, D. Predicting presence of amphibian species using features obtained from gis and satellite images. ISPRS Int. J. Geo-Inf. 2019, 8, 123. [Google Scholar] [CrossRef] [Green Version]
- Toth, C.K.; Grejner-Brzezinska, D.A. Performance analysis of the airborne integrated mapping system (AIMS). Int. Arch. Photogramm. Remote Sens. 1997, 32, 320–326. [Google Scholar]
- Li, R.; Wang, W.; Tu, Z.; Tseng, H.Z. Object recognition and measurement from mobile mapping image sequences using Hopfield neural networks: Part II. Int. Arch. Photogramm. Remote Sens. 1997, 32, 192–197. [Google Scholar]
- Chen, Y.; Hu, V.T.; Gavves, E.; Mensink, T.; Mettes, P.; Yang, P.; Snoek, C.G. Pointmixup: Augmentation for point clouds. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 330–345. [Google Scholar]
- Szlobodnyik, G.; Farkas, L. Data augmentation by guided deep interpolation. Appl. Soft Comput. 2021, 111, 107680. [Google Scholar] [CrossRef]
- Li, L.; Heizmann, M. 2.5D-VoteNet: Depth map based 3D object detection for real-time applications. In Proceedings of the British Machine Vision Conference, Online, 22–25 November 2021. [Google Scholar]
- Li, Q.; Nevalainen, P.; Peña Queralta, J.; Heikkonen, J.; Westerlund, T. Localization in unstructured environments: Towards autonomous robots in forests with delaunay triangulation. Remote Sens. 2020, 12, 1870. [Google Scholar] [CrossRef]
- Xu, X.; Li, J.; Zhou, M. Delaunay-triangulation-based variable neighborhood search to solve large-scale general colored traveling salesman problems. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1583–1593. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International conference on computer vision, Washington, DC, USA, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary robust invariant scalable keypoints. In Proceedings of the 2011 International conference on computer vision, Washington, DC, USA, 6–13 November 2011; pp. 2548–2555. [Google Scholar]
- Zhang, H.; Wohlfeil, J.; Grießbach, D. Extension and evaluation of the AGAST feature detector. In Proceedings of the XXIII ISPRS Congress Annals 2016, Prague, Czech Republic, 12–19 July 2016; Volume 3, pp. 133–137. [Google Scholar]
- Lindeberg, T. Scale Invariant Feature Transform; KTH Royal Institute of Technology: Stockholm, Sweden, 2012; Volume 7, p. 10491. [Google Scholar]
- Wang, Y.; Du, L.; Dai, H. Unsupervised SAR image change detection based on SIFT keypoints and region information. IEEE Geosci. Remote Sens. Lett. 2016, 13, 931–935. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Gool, L.V. Surf: Speeded up robust features. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Villar, S.A.; Rozenfeld, A.; Acosta, G.G.; Prados, R.; García, R. Mosaic construction from side-scan sonar: A comparison of two approaches for beam interpolation. In Proceedings of the 2015 IEEE/OES Acoustics in Underwater Geosciences Symposium (RIO Acoustics), Rio de Janeiro, Brazil, 29–31 July 2015; pp. 1–8. [Google Scholar]
- Zhan, W.; Xiao, C.; Wen, Y.; Zhou, C.; Yuan, H.; Xiu, S.; Zou, X.; Xie, C.; Li, Q. Adaptive semantic segmentation for unmanned surface vehicle navigation. Electronics 2020, 9, 213. [Google Scholar] [CrossRef] [Green Version]
- Bala, R.; Braun, K.M. Color-to-grayscale conversion to maintain discriminability. In Proceedings of the Color Imaging IX: Processing, Hardcopy, and Applications, San Jose, CA, USA, 18 January 2003; Volume 5293, pp. 196–202. [Google Scholar]
- Kim, S.; Casper, R. Applications of Convolution in Image Processing with MATLAB; University of Washington: Seattle, WA, USA, 2013; pp. 1–20. [Google Scholar]
- Peli, T.; Malah, D. A study of edge detection algorithms. Comput. Graph. Image Process. 1982, 20, 1–21. [Google Scholar] [CrossRef]
- Siddique, N.; Paheding, S.; Elkin, C.P.; Devabhaktuni, V. U-net and its variants for medical image segmentation: A review of theory and applications. IEEE Access 2021, 9, 82031–82057. [Google Scholar] [CrossRef]
- Huang, T.; Cheng, M.; Yang, Y.; Lv, X.; Xu, J. Tiny Object Detection based on YOLOv5. In Proceedings of the 2022 the 5th International Conference on Image and Graphics Processing (ICIGP), Beijing, China, 7–9 January 2022; pp. 45–50. [Google Scholar]
- Sullivan, C.; Kaszynski, A. PyVista: 3D plotting and mesh analysis through a streamlined interface for the Visualization Toolkit (VTK). J. Open Source Softw. 2019, 4, 1450. [Google Scholar] [CrossRef]
- Ghosh, S.; Chaki, A.; Santosh, K. Improved U-Net architecture with VGG-16 for brain tumor segmentation. Phys. Eng. Sci. Med. 2021, 44, 703–712. [Google Scholar] [CrossRef]
- Kanaeva, I.; Ivanova, J.A. Road pavement crack detection using deep learning with synthetic data. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Sanya, China, 12–14 November 2021; Volume 1019, p. 012036. [Google Scholar]
- Zhang, Z. Improved adam optimizer for deep neural networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–2. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
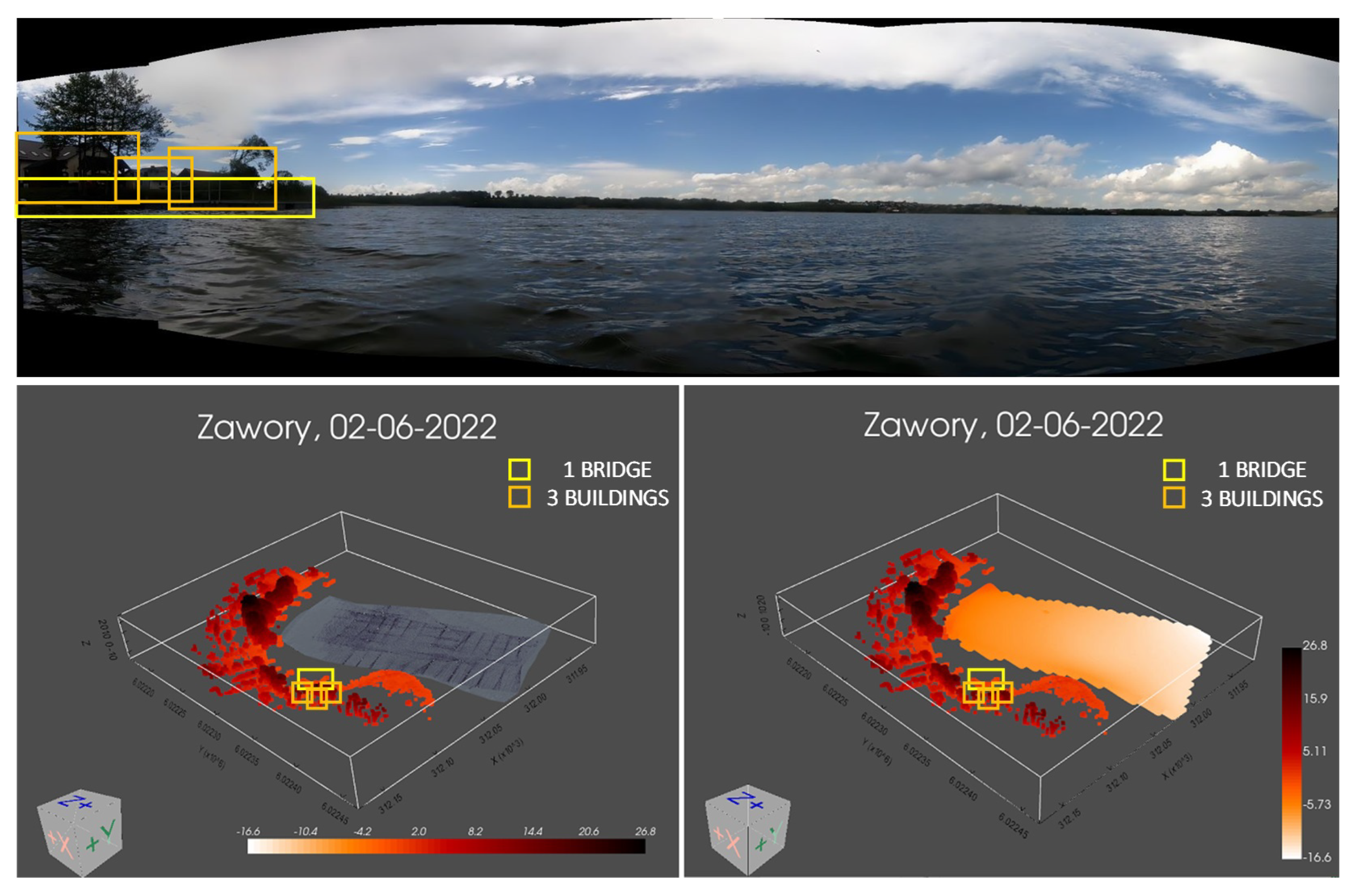{kind=link}
| 1 s | 2 s | 3 s | 4 s | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Number of Images | 2 | 4 | 8 | 2 | 4 | 8 | 2 | 4 | 8 | 2 | 4 | 8 |
| AGAST | 0.11 | 0.56 | 1.13 | 0.11 | 0.61 | 1.13 | 0.16 | 0.63 | 1.18 | 0.21 | 0.66 | 1.22 |
| BRISK | 0.13 | 0.66 | 1.14 | 0.156 | 0.71 | 1.18 | 0.166 | 0.75 | 1.23 | 0.19 | 0.75 | 1.2 |
| ORB | 0.12 | 0.63 | 1.11 | 0.133 | 0.64 | 1.18 | 0.162 | 0.65 | 1.19 | 0.18 | 0.63 | 1.2 |
| SIFT | 0.11 | 0.55 | 1.16 | 0.12 | 0.6 | 1.21 | 0.12 | 0.64 | 1.18 | 0.17 | 0.61 | 1.22 |
| SURF | 0.12 | 0.56 | 1.12 | 0.14 | 0.59 | 1.16 | 0.17 | 0.59 | 1.15 | 0.18 | 0.63 | 1.19 |
| Number of Points | ||||
|---|---|---|---|---|
| 100,000 | 1,000,000 | 1,000,000 | ||
| MBES | All data analysis | 2049 | 5374 | 7143 |
| Proposed iterative method | 2184 | 5388 | 7222 | |
| LIDAR | All data analysis | 2346 | 5503 | 6940 |
| Proposed iterative method | 2013 | 5800 | 6972 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Włodarczyk-Sielicka, M.; Połap, D.; Prokop, K.; Połap, K.; Stateczny, A. Spatial Visualization Based on Geodata Fusion Using an Autonomous Unmanned Vessel. Remote Sens. 2023, 15, 1763. https://doi.org/10.3390/rs15071763
Włodarczyk-Sielicka M, Połap D, Prokop K, Połap K, Stateczny A. Spatial Visualization Based on Geodata Fusion Using an Autonomous Unmanned Vessel. Remote Sensing. 2023; 15(7):1763. https://doi.org/10.3390/rs15071763
Chicago/Turabian StyleWłodarczyk-Sielicka, Marta, Dawid Połap, Katarzyna Prokop, Karolina Połap, and Andrzej Stateczny. 2023. "Spatial Visualization Based on Geodata Fusion Using an Autonomous Unmanned Vessel" Remote Sensing 15, no. 7: 1763. https://doi.org/10.3390/rs15071763