1. Introduction
Remote sensing image change detection is an important component of geography and national status monitoring. It is of great significance to urban dynamic monitoring, geographic information update, natural disaster monitoring, investigation and punishment of illegal buildings, military target strike effect analysis, and land and resource investigation. High-resolution remote sensing image change detection has developed rapidly from data accumulation to algorithm models because of the rapid development of deep learning technology and earth observation technology in recent years. However, a certain gap still exists in commercial applications.
The traditional change detection algorithms mainly include layer arithmetic, post-classification change, direct classification, transformation, change vector analysis (CVA), and hybrid change detection. More details, which will not be repeated in this work, can be observed in the literature [
1]. In recent years, with the continuous development of deep learning technology, change detection based on deep learning algorithms has also achieved rapid development. Deep learning-based change detection methods can be classified into four categories: supervised-based, semi-supervised-based, weakly supervised-based, and unsupervised-based. The supervised deep learning-based change detection method has become a mainstream algorithm in the field of remote sensing image change detection because of its simple implementation and stable and reliable results. However, such methods often require a large number of labeled high-quality sample sets, whereas the labeling of change detection datasets is labor-intensive and time-consuming. In addition, when the amount of training data decreases, the effect of change detection also drops sharply, especially when the training dataset is only 10% of the original dataset or less. On the other hand, the volume of existing semantic segmentation datasets is much larger than that of current change detection datasets; change detection datasets are much more difficult to produce than single-phase semantic segmentation datasets because the production of change detection datasets usually requires semantic segmentation labels of the bi-temporal images, following the comparative analysis and manual inspection to obtain the labels of change detection. How to make full use of the existing geographic information (e.g., semantic segmentation datasets) to effectively improve the accuracy and reliability of change detection with limited samples has been a research hotspot in recent years. In this view, a prior semantic information-guided change detection framework is proposed in this paper. In this framework, existing semantic segmentation datasets are first used to obtain prior semantic information, and then a new change detection network guided by prior semantic information is designed to reduce the workload of the change detection annotation effectively.
The main contributions of this paper are presented as follows.
On the basis of the existing public change detection dataset (LEVIR-CD), a set of semantic segmentation datasets that correspond to the bi-temporal images, which enables the use of the dataset for both semantic segmentation and change detection, is annotated.
A new change detection framework that makes full use of the prior semantic information generated by semantic segmentation and greatly reduces the dependence on the sample size of change detection datasets is proposed. The proposed prior semantic information-guided change detection framework (PSI-CD) achieves state-of-the-art performance on the WHU and LEVIR-CD datasets.
A new change analysis module (CAM) is designed, which adopts different processing methods for the features of different layers and effectively combines multi-scale prior semantic features and attention mechanisms. Ablation study shows that this module can effectively improve the difference representation ability of the model.
The remainder of this paper is arranged as follows.
Section 2 introduces an overall review of related works.
Section 3 describes the proposed method.
Section 4 presents the experiments, including the comparison of different methods, the comparison of different sample data volumes, the ablation study, and finally, the conclusion of this paper.
2. Related Works
In recent years, with the continuous maturity of deep learning technology, high-resolution remote sensing image change detection technology has developed rapidly, and its accuracy and reliability far exceeded traditional algorithms. According to the degree of dependence of the change detection algorithm on sample data, the existing change detection algorithms can be divided into four categories, namely, supervised change detection, semi-supervised change detection, weakly supervised change detection, and unsupervised change detection.
In terms of supervised change detection, the earliest methods of this kind are the three different convolutional neural network (CNN) structures proposed by Zagoruyko and Komodakis [
2] to calculate the similarity of bi-temporal image patches. Subsequently, CNN was used to extract features, and then the final change map was obtained through the distance calculation of the bi-temporal features [
3], a simple threshold segmentation [
4], or discrimination learning [
5]. Furthermore, to overcome the limitations of existing algorithms, skip connections are used between the encoder and the decoder to replace the simple upsampling operation, thereby forming the most popular end-to-end fully convolutional neural networks, such as FCN [
6,
7], Unet and its variants [
8,
9,
10,
11,
12,
13], and UNet++ [
14,
15]. In the use of the attention module, Shi et al. [
16] proposed a deeply supervised attention metric-based network (DSAMNet) in which convolutional block attention modules (CBAM) were integrated to provide more discriminative features. Zhang et al. [
17] proposed a dual correlation attention-guided detector (DCA-Det) to detect the change objects. Chen et al. [
18] presented a densely connected feature fusion module to fuse semantic segmentation features into the change detection decoder. Zhu et al. [
19] added a global hierarchical (G-H) sampling mechanism to the network to solve the imbalance problem of insufficient samples. In addition, given the great success of transformers in the fields of image classification, semantic segmentation, and object detection, Chen et al. [
20] proposed a bi-temporal image transformer (BIT) to model contexts within the spatial–temporal domain and outperformed the purely convolutional baseline. Zheng et al. [
21] proposed a transformer module to learn the difference representation from the bi-temporal semantic representation. Chen et al. [
22] focused on the boundary accuracy and the integrity of the change area. They introduced a transformer-based edge-guided encoder to achieve long-range context modeling and a feature difference enhancement module to learn the differences between bi-temporal features. In addition to implementing change detection, Liu et al. [
23], Yang et al. [
24], Tian et al. [
25], and Shen et al. [
26] designed a semantic change detection network that simultaneously implemented semantic segmentation and change detection. The change detection effect of this type of supervised learning is usually fine in a small area because of a large number of labeled sample datasets. However, the sample annotation workload is large, and its cost is high, thereby making its popularization and application in a large number of areas difficult.
To reduce the number of labeled samples effectively, some semi-supervised, weakly supervised, and unsupervised change detection methods have been developed in recent years. For semi-supervised change detection, Peng et al. [
27] proposed a semi-supervised convolutional network for change detection (SemiCDNet) based on a GAN. In terms of weakly supervised change detection, Sakurada [
28] divided semantic change detection into two parts, namely, change detection and semantic extraction. In this method, the bi-temporal images were first placed into the pre-trained correlated Siamese change detection network (CSCDNet) to generate a change probability map, then the change map and the bi-temporal images were inputted into the silhouette-based semantic change detection network (SSCDNet) to realize semantic change detection. In terms of unsupervised change detection, Hou et al. [
29] and Saha et al. [
30] used pre-trained convolutional neural networks and low-order decomposition [
29] or CVA [
30] to extract features from multi-temporal images to obtain the change map. Some researchers employ unsupervised deep learning frameworks, such as deep belief networks (DBNs) [
31], symmetric convolutional coupling networks (SCCN) [
32], and iterative feature mapping networks [
33], to extract the difference representation between the image pairs of homologous or different sources, and then the change detection results are obtained in an unsupervised way, such as unsupervised clustering [
31], a thresholding algorithm [
32], or hierarchical clustering analysis [
33]. Other researchers [
34,
35,
36,
37,
38,
39] used the results of traditional methods as the pre-classification result to train deep neural networks, and the networks used include sparse denoising autoencoder (SDAE) [
38], CNNs [
35,
40], a noise modeling-based unsupervised fully convolutional network, a capsule network [
37], and a GAN [
34,
39], so that the entire change detection process does not require manual intervention.
In conclusion, weakly supervised, semi-supervised, or unsupervised change detection methods can significantly reduce the workload of manually annotating sample sets, and the cost is low. However, due to the lack of strict supervision, guaranteeing the change detection effect using such methods is usually difficult. In recent years, the supervised change detection method developed with the help of existing geographic information can effectively reduce the amount of annotation, and the effect has significant advantages over the supervised change detection method with limited samples. Thus, in this paper, on the basis of making full use of the existing datasets for the other supervised training tasks, the trained semantic segmentation model is introduced as prior semantic information to guide change detection, which can reduce the sample size of the required change detection dataset effectively.
3. Methodology
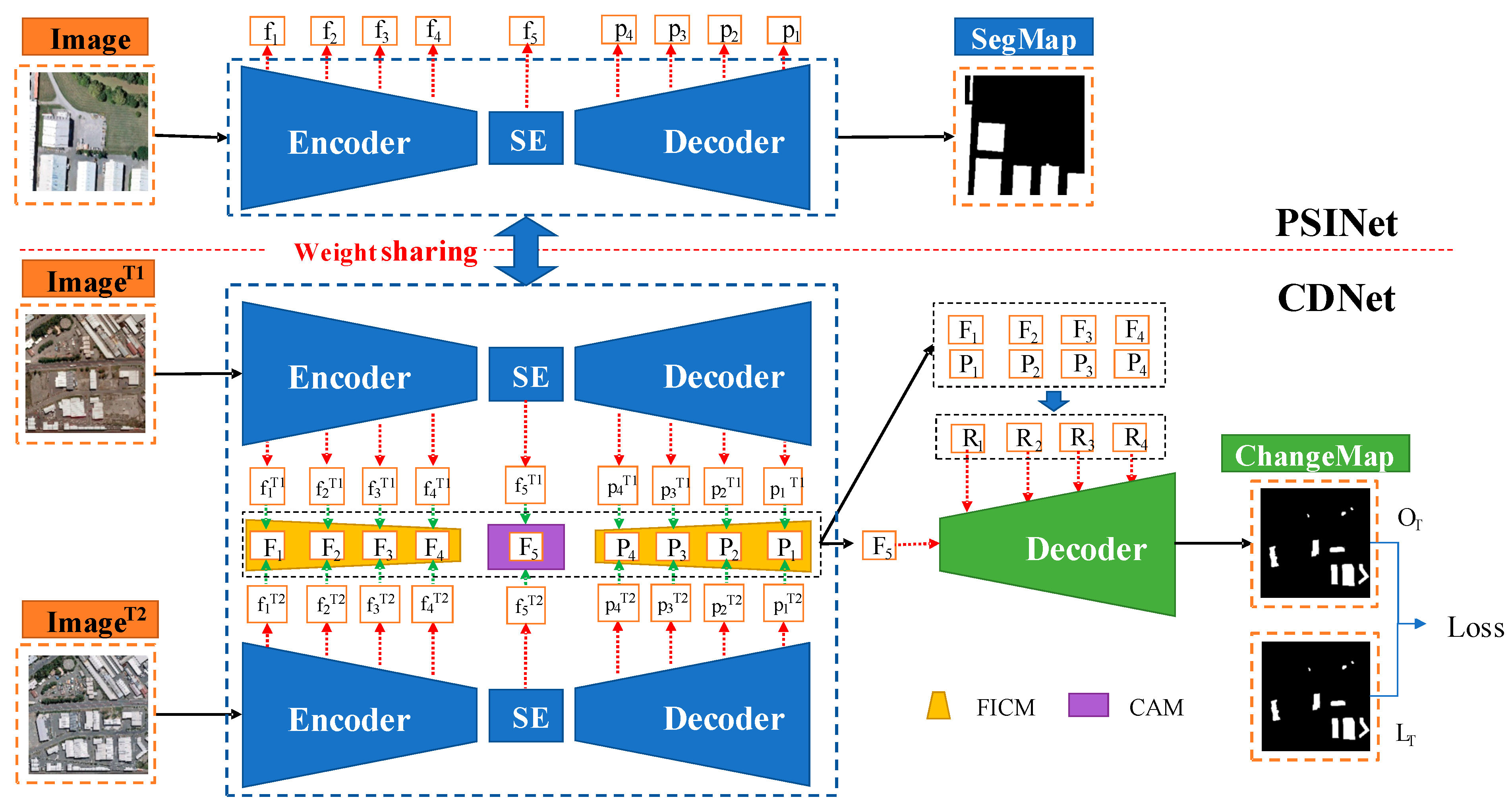
In this paper, a PSI-CD method is proposed for bi-temporal high-resolution remote sensing images, as shown in
Figure 1. The whole framework mainly consists of two parts. (1) A priori semantic information generation network (PSINet): relying on the semantic segmentation dataset constructed from the existing geographic information database, a reliable semantic segmentation model is constructed to obtain the prior semantic information. (2) A change detection network (CDNet): a change detection network is designed to make full use of prior semantic information. In this network, first, the encoder and decoder of the semantic segmentation model are directly used to extract the multi-scale convolution features of each single phase; second, these bi-temporal multi-scale convolution features are combined to obtain the multi-scale change features of the bi-temporal images; finally, these multi-scale change features are placed into the decoder to obtain the final change map.
3.1. Overview
PSI-CD in this paper consists of two networks that share weights: PSINet and CDNet. PSINet first extracts prior semantic information from a large number of semantic segmentation datasets, and then the extracted prior semantic information is incorporated into CDNet, thereby enabling CDNet to achieve change detection tasks under limited samples. PSINet uses the SENet module to enhance the discrimination of high-order features on channels. CDNet inherits this module because the two networks share weights. At the same time, CDNet uses the change analysis module (CAM) to extract the change information in the bi-temporal data, and the attention mechanism used in the CAM can help the network capture more useful information.
Let and denote a pair of images of the same region shooting at different times and , respectively; whereas and denote the pixel-level semantic segmentation labels of the two images; and denotes the change detection labels of the two images. The PSI-CD process can be summarized as follows:
The semantic segmentation model (PSINet) is first trained. During the training of PSINet, images and and the labels and are inputted into PSINet to extract multi-scale convolution features. The best PSINet is selected, and the weight parameters of the entire PSINet network are retained.
Next, the trained PSINet is embedded into CDNet to extract the multi-scale convolution features of each image. The bi-temporal images and and the change labels are inputted into CDNet, and the trained PSINet is used to extract the multi-scale convolutional features of the bi-temporal images, including two sets of encoder features and two sets of decoder features .
The bi-temporal image features are inputted into the change analysis module to obtain the multi-scale change features of the bi-temporal data. To improve the performance of the change analysis module, the attention mechanism and the concatenation of the multi-scale convolutional features are introduced to make the change analysis module more discriminating.
The multi-scale change features are inputted into the decoder, and the predicted change map is generated through operations such as convolution, upsampling, and skip connections. Losses are calculated from and the ground truth , and backpropagation is performed to optimize the network.
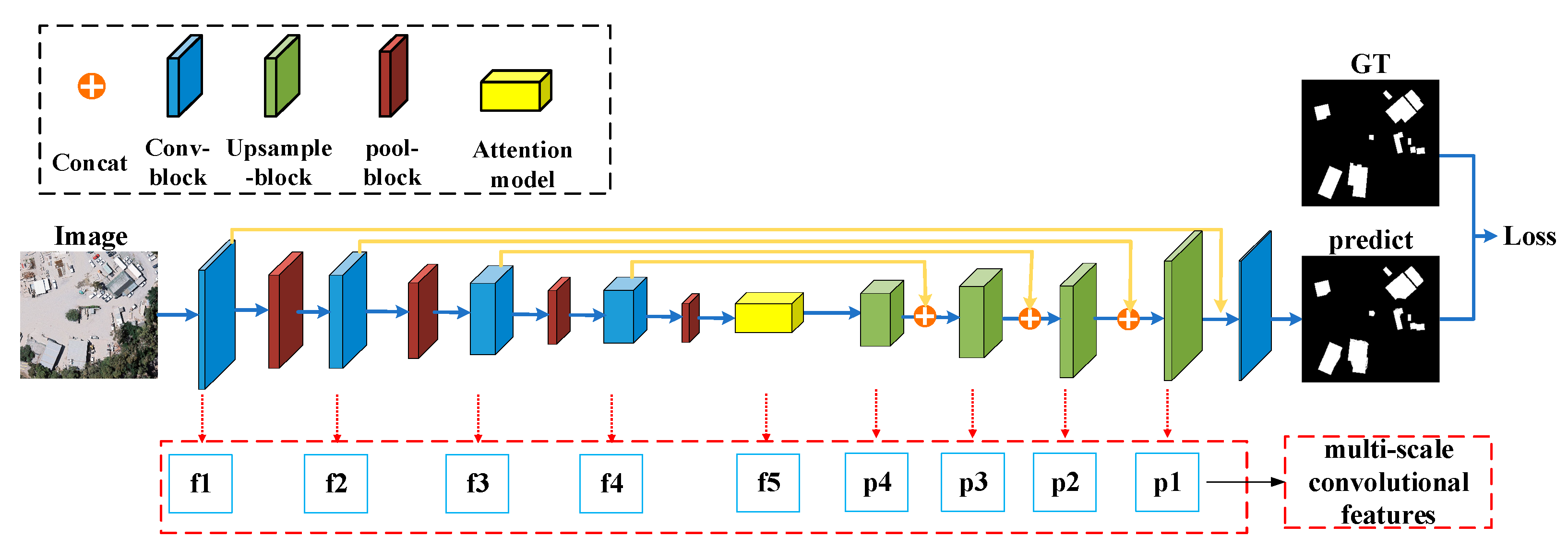
3.2. PSINet
The main role of PSINet is to extract the prior semantic information for the downstream change detection task. Based on the semantic segmentation dataset constructed by the existing geographic information database, a reliable remote sensing image semantic segmentation model, which is the prior semantic information of this paper, is obtained by training. PSINet in this paper is shown in
Figure 2.
In this paper, PSINet consists of three parts: encoder, attention module, and decoder. Skip connections are used between the encoder and the decoder to fuse the deep, semantic, and rough features in the decoder and the shallow, low-level, and fine-grained features in the encoder.
The encoder in this paper adopts a classic ResNet50 network [
41] and initializes it with pre-trained parameters on ImageNet. The encoder consists of convolution (conv), batch normalization (Batch Normalization, BN), maximum pooling (MaxPooling), and rectified linear unit (Rectified Liner Units, ReLU). Shallow features are mapped into a high-dimensional space, thereby resulting in deep, high-dimensional features.
To improve the feature extraction ability of the network for small targets, we introduced the SENet attention module [
42] to further improve the quality of feature extraction. SENet is a lightweight attention module with a small number of parameters with good results. The SE module first compresses the channel dimensions of high-dimensional features and then performs global average pooling on the features to obtain channel-level global features. Finally, the feature is processed with a fully connected layer and a sigmoid activation function and then dot-multiplied with the original feature so that the high-dimensional feature can obtain a global view and better learn the difference between channels. The calculation of SENet is shown in Formulas (1) and (2):
where
is the feature after compression on channel;
represents channel-level global features;
and
represent the height and width of the feature, respectively;
and
are two fully connected layers;
ReLU represents rectified linear unit; and
represents the sigmoid function.
After the SE attention module generates a high-dimensional feature map, it is passed to the decoder of the multi-layer convolution upsampling module for dimensionality reduction. The decoder consists of upsampling, convolution, batch normalization, and ReLU. The upsampling doubles the width and height of the feature map and fuses the multi-level features extracted in the encoder to restore the image to the original dimension and size gradually.
3.3. CDNet
Based on the semantic information obtained by PSINet, a prior semantic information-guided change detection (CDNet) is designed to reduce the sample size of the change detection by sharing network weights. The workflow of CDNet introduced in this paper mainly includes five parts: weight sharing, embedding of prior features, change analysis module, decoder, and loss function, which is shown in
Figure 1. Details are explained as follows.
3.3.1. Weight Sharing
In general, the training of the change detection network is mostly conducted from scratch, thereby consuming considerable computing resources and time, and the effect of the training model is poor when the dataset is small. On the one hand, the upstream tasks of semantic segmentation and change detection have strong similarities. On the other hand, the semantic information generated by semantic segmentation cannot be utilized effectively in the change detection task in the way of designing the semantic segmentation network and change detection network separately. Thus, in this paper, we attempt to combine the two tasks of semantic segmentation and change detection, hence, making full use of semantic segmentation information in the process of change detection. The weight parameters of the feature extraction module of the change detection network and the parameters of the semantic segmentation network are shared so that the prior semantic information generated by the semantic segmentation network can be applied fully to the change detection task, thereby reducing the number of parameters of change detection network needs to be adjusted effectively. In the specific implementation process, the change detection network adopts the same structure as the semantic segmentation network to extract the high-order features of the image. During the training process of the change detection network, the parameters of the high-order feature extraction part of the image are fixed, and only the parameters of the change analysis module and the decoder are trained.
Let
be the weights of PSINet, and
be the weights of CDNet. Given that the weights of the high-order feature extraction part of CDNet are the same as the weights of PSINet, the weights of CDNet can be expressed as:
where
represents the weights of the change analysis module of the change detection network, and
represents the weights of the decoder of the change detection network. During training,
remains the same, and only
and
are trained to make full use of the prior semantic information obtained by PSINet. Experiments have verified that this method can improve the results of the change detection and the convergence speed of the training model significantly, especially when the dataset is small.
3.3.2. Embedding of Prior Features
Given bi-temporal images, the bi-temporal multi-level features
are extracted separately by the two branches of the change detection network, which are the same as those of PSINet. Given that the multi-level features are extracted simultaneously by the same network for the two images, the feature shapes of each level of the two are the same, that is,
Therefore, we can operate on two sets of features at the same level in two periods without changing the dimension of the feature, hence, avoiding the loss of feature information. Similarly, the feature scales at the same level of the encoder and decoder in the same network are the same because the PSINet in this paper is a symmetric U-shaped structure, that is:
Therefore, we can operate on the two sets of features at the corresponding level in the same period without changing the dimension of the feature, and this operation is convenient to integrate the feature information of the encoder and the decoder and improve the representation ability of the prior semantic information.
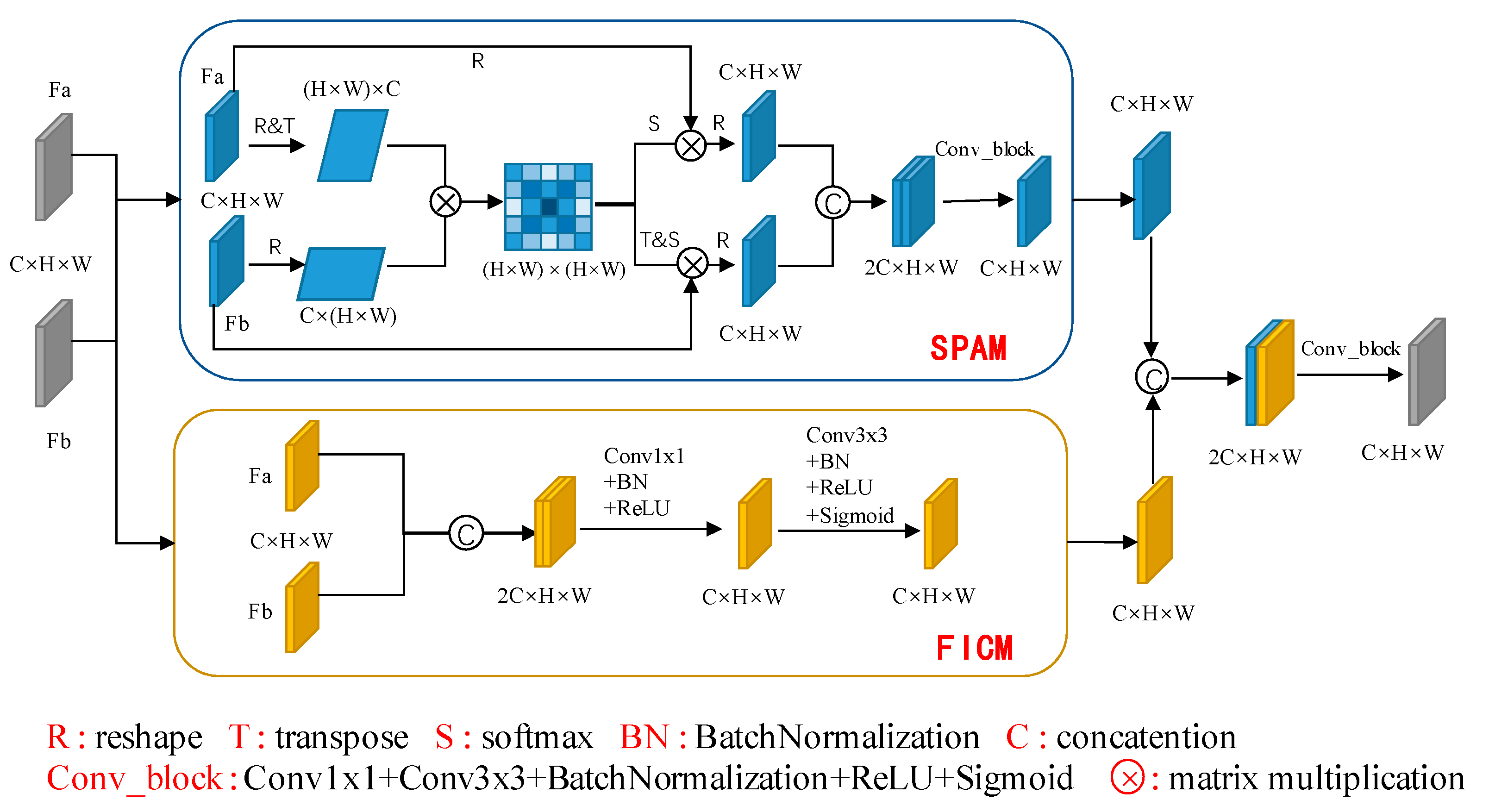
3.3.3. Change Analysis Module (CAM)
The high-level features of the images extracted by the PSINet correspond to the semantic information of the images. In the change detection task, the corresponding change features must be calculated according to the high-level features of the bi-temporal images, and the change features should be inputted into the decoder of the change detection network to obtain the change map. We design a change analysis module to enhance the network’s ability to learn the difference between the high-order features. The change analysis module learns the change information by comparing the embedded features of the bi-temporal images. In this module, a spatial attention module, abbreviated as SPAM, is introduced to improve the discrimination of features in space. At the same time, a feature integration and concatenation module, abbreviated as FICM, is introduced to strengthen the ability of the network to extract the difference of the bi-temporal features. The entire change analysis module is shown in
Figure 3. In this module, SPAM and FICM are parallel and have the same input. After a series of different processing, these two modules output features of the same size. Subsequent operations, such as concatenation and convolution, are performed on these output features, and the processed features and other multi-level features are passed to the decoder. Details of the SPAM and FICM are presented as follows.
Considering that we have already carried out channel-wise enhancement on the features in the PSINet, we design SPAM to strengthen the spatial discriminativeness of the change features. Let the features of the two phases be and , and the channel, height, and width of the features are C, H, and W, respectively.
First, the spatial attention feature
is obtained by multiplying
and
after transformation, and
is calculated as follows:
where
is the feature of
obtained through operations, such as reshape and transposition;
is the feature of
obtained through reshape operation;
represents the operation of matrix transpose; and
represents the operation of matrix multiplication.
After obtaining the spatial attention features
, operations with
and
should be performed to obtain attention matrix
and
which are consistent with the dimensions of the input data. Here,
is calculated from
and
, and
is calculated from
and
. This process can be expressed as follows:
where
and
are the features after spatial attention enhancement, and the size is C × H × W; the
function represents the column-by-column normalization operation.
Finally, the bi-temporal features are concatenated, and the output feature
with the same size and number of channels as the input data is calculated as follows:
where
represents the feature after
and
are concatenated,
represents the function of feature concatenation,
represents the sigmoid function mapping features to the range of (0, 1),
represents the rectified linear unit,
represents batch normalization,
represents a convolutional layer with a convolution kernel of 3, and
compress the number of channels of the feature to the specified number of channels.
We designed FICM to preserve the details of the bi-temporal features as much as possible. In FICM, the bi-temporal features are first concatenated, and then through a series of operations, such as convolution,
and
, the change features
that are consistent with the dimension of the input features are obtained. This process can be expressed as follows:
where
,
,
,
, and
are the same as those in Formulas (11) and (12).
After obtaining two sets of features
and
, we fuse these two sets of features to obtain the final feature
after 1 × 1 convolution, 3 × 3 convolution, batch normalization,
, and sigmoid operation.
is calculated as follows:
where
,
,
,
,
, and
are the same as those in Formulas (11) and (12).
Since SPAM in CAM adopts the spatial attention mechanism, dealing with the bi-temporal features with large sizes is difficult. Here, we make a simplification. We only apply SPAM to the last layer (e.g.,
F5). For other layers (e.g.,
F1-
F4,
P1-
P4), we only use FCIM in CAM to obtain the change features. Change features
for the encoder and
for the decoder of PSINet are calculated as follows:
where
and
correspond to the input
,
in
Figure 3;
and
are the bi-temporal multi-scale convolutional features of the encoder of PSINet; and
and
are the bi-temporal multi-scale convolutional features of the encoder of PSINet.
This change analysis module (CAM) can make full use of the multi-level features extracted by the encoder and decoder of the semantic segmentation network and tap the potential of semantic information to the greatest extent, thereby reducing the model’s dependence on datasets effectively.
3.3.4. Decoder
To tap the potential of semantic information more fully, a suitable network must be designed, and the multi-scale high-order features generated by the encoder and the decoder in PSINet must be used fully. In detail, the change analysis module is first used to extract the change features from the bi-temporal high-order convolutional features at each scale, and then the change features in the encoder of each layer are concatenated correspondingly with the change features of the same size in the decoder to obtain the fused change features
.
is calculated as follows:
where
is the change feature obtained by the bi-temporal encoder, and
is the change feature obtained by the bi-temporal decoder.
Similar to the decoder of the classical Unet structure, the fused change features are upsampled by the decoder from the last layer () and concatenated with the fused features of the corresponding level, and the feature map is finally upsampled to the size of the input image to obtain the final change map.
3.3.5. Loss Function
In terms of loss function, binary cross-entropy is used as the loss function in this paper with only two classes, and the predicted probabilities for each class are
p and 1-
p, respectively. Here, the formula of the loss function
can be expressed as follows:
where
is the number of pixels in the image;
represents the label of sample
i, in which the positive class is 1 and, the negative class is 0, the base of log is
e, and
is the probability that sample
i is predicted to be a positive class.
4. Experiments
4.1. Datasets
In this paper, two datasets (e.g., WHU and LEVIR-CD) are mainly used to validate the proposed method. Each dataset is a semantic change detection dataset that can be used for semantic segmentation and change detection tasks. Among them, WHU is a public dataset that includes one phase of image
T1 and corresponding building semantic labels, another phase of image
T2 and corresponding building semantic labels, and building change labels. For the LEVIR-CD dataset, we newly annotated the corresponding semantic segmentation labels on the basis of the public dataset to form a semantic change detection dataset. To distinguish it from the public change detection dataset LEVIR-CD, we will use LEVIR to represent the semantic change detection dataset subsequently. Examples of the two datasets are shown in
Figure 4. The details of the two datasets are presented as follows.
Semantic Segmentation: This dataset is located in Christchurch, New Zealand. The original aerial images were obtained from the New Zealand Land Information Service website. Approximately 22,000 independent buildings can be found here. Ji et al. [
43] first downsampled the image from a ground resolution of 0.075 m to 0.3 m. Then they cropped them into 8189 tiles, and each tile has 512 × 512 pixels. Each image has a corresponding ground truth. In our experiments, we randomly split it into three parts: 4736/1036/2416 for training/validation/test, respectively.
Change detection: This dataset belongs to the same region as the semantic segmentation dataset. The bi-temporal images were obtained in April 2012 and 2016. A total of 2386 image pairs of 512 × 512 pixels are available, and each image pair has a corresponding change label. During the experiment, we randomly split it into three parts: 1559/315/512 for training/validation/test, respectively.
Semantic Segmentation: The original images of this dataset are from the public change detection dataset LEVIR-CD [
7]. The semantic labels include two classes of buildings and non-buildings, which were manually produced and checked by our research group. The entire semantic segmentation dataset contains 637 × 2 images, and each image has a corresponding ground truth; the image resolution is 0.5 m/pixel, and the original image is 1024 × 1024 pixels. Based on the training set, validation set, and test set of the public dataset, we cropped the images into small patches of size 512 × 512, and the training set, validation set, and test set for semantic segmentation are 8650, 512, and 1024 images, respectively.
Change detection: LEVIR-CD [
7] is a building change detection dataset in the field of remote sensing. The original images come from Google Earth. It consists of 637 pairs of bi-temporal very high-resolution (VHR) images. The time span of the bi-temporal VHR images is 5 to 14 years. The ground resolution of the VHR images is 0.5 m. The original image size is 1024 × 1024 pixels. Each image pair has corresponding ground truth of building change detection. In our experiment, based on the training set, validation set, and test set of the original dataset, we cropped the images into small patches of size 512 × 512, and the training set, validation set, and test set for semantic segmentation are 1524, 256, and 512 images, respectively.
4.2. Training Details
The proposed method (e.g., PSI-CD) is implemented with PyTorch. All experiments are conducted on an NVIDIA RTX2080Ti GPU with 11 GB RAM. It consists of two networks, namely, PSINet and CDNet. Details are presented as follows.
PSINet: During network training, the initialization parameters of the ResNet backbone module come from the pretraining weights of the ImageNet dataset. The number of training epochs is 400. We used the Adam optimizer with β1 = 0.9, β2 = 0.999, an initial learning rate of 0.0001, and a weight decay of
. The input and output image sizes are 512 × 512 × 3 and 512 × 512 × 1, respectively. During data loading, random rotation and random color transformation [
11] are adopted to augment the dataset.
CDNet: During training, the feature extraction part that corresponds to PSINet adopts the weights of the trained PSINet. The number of training epochs is 200. We used the Adam optimizer with β1 = 0.9, β2 = 0.999, an initial learning rate of
, and weight decay of
. The input of the network corresponds to the bi-temporal images. The input and output image sizes are 512 × 512 × 3 and 512 × 512 × 1, respectively. During data loading, random rotation and random color transformation [
11] are adopted to augment the dataset.
At the same time, to reduce the difficulty of training and reduce the dependence of the model on the dataset, the parameters of the feature extraction part of CDNet are fixed during training, and only the change analysis module and the decoder of CDNet are updated, which greatly reduces the training parameters of the model and reduces the training time and computing power of the change detection network effectively.
4.3. Comparison of Different Methods
To verify the effectiveness of the proposed method, extensive comparisons are made with state-of-the-art change detection methods on the two datasets, namely, FC-EF [
13], FC-CONC [
13], FC-DIFF [
13], DTCDSCN [
23], SNUNET [
15], and BIT [
20]. A brief description of the above methods is as follows.
- (1)
FC-EF [
13] is based on the Unet model, including four max-pooling and upsampling layers, and its input is the concatenation of image pairs.
- (2)
FC-CONC [
13] is a Siamese extension of the FC-EF model. The two encoders share the weight, and then the bi-temporal features are concatenated into the decoder.
- (3)
FC-DIFF [
13] is another Siamese extension of FC-EF. During decoding, different from EF-CONC’s concatenation of the bi-temporal image features, FC-DIFF is replaced with the absolute value of the difference between bi-temporal image features.
- (4)
DTCDSCN [
23] consists of a change detection network and two semantic segmentation networks. It realizes change detection under dual-task constraints by sharing the parameters of feature extraction.
- (5)
SNUNET [
15] has designed a dense connected Siamese network for change detection to achieve dense skip connections between encoders and decoders and between decoders and decoders.
- (6)
BIT [
20] introduces a transformer into change detection and proposes a bi-temporal image transformer to model contexts within the spatial–temporal domain.
The above CD networks use the same hyperparameters. In this section, all comparisons are conducted using the same data augmentation, and details of the data augmentation can be seen in [
11].
4.3.1. Comparisons on WHU Dataset
On the WHU dataset, the quantitative results of IoU, OA, precision, recall, and F1 of all methods are shown in
Table 1.
Table 1 shows that FC-EF achieves the lowest IoU and F1 of 59.52% and 74.62%, respectively; the second lowest is FC-DIFF, with 63.24% and 77.48% on IoU and F1, respectively. These results indicate that on the WHU dataset, the Siamese network is beneficial for improving the change detection results. The IoU and F1 of FC-CONC are 71.99% and 83.72%, which shows that the fusion feature, after directly contacting the bi-temporal features, is more helpful to the network than the difference feature of subtracting the two and taking the absolute value. The former network structure can achieve higher detection results on the WHU dataset. These three networks have the fewest number of training parameters and the largest number of frames per second (e.g., Fps). As the amount of training parameters increases, the IoU of SNUNet is 79.29%, and F1 reaches 88.32%, indicating that complex backbone networks, such as dense residual network structures and sophisticated attention modules, can capture the change information of the bi-temporal images effectively. The BIT network achieves high scores of 81.29% and 89.68% in terms of IoU and F1, hence, proving that the use of the transformer structure can extract more useful information from the convolutional features. The DTCDSCN network achieves high scores of 82.19% and 90.22% in terms of IoU and F1, proving that the use of reliable semantic information can improve the network performance; however, the number of training parameters is the highest, and the frames per second are lowest. Our method achieves the best results among all methods, with IoU and F1 of 83.25 and 90.86, respectively, proving that using prior semantic features and more advanced attention mechanisms can enable the network to capture the difference representations more efficiently, which helps improve the change detection accuracy significantly.
Figure 5 shows the performance of all methods on the WHU dataset more intuitively. We select as many different building images as possible, including different types, shapes, sizes, and spatial distribution. For example, (a)~(f) are sparsely distributed buildings of different types and sizes, (g) is a building image with obvious radiation changes, (h) is a dense small building image, and (i) and (j) are large and medium-sized building images. Methods such as FC-EF, FC-CONC, and FC-DIFF have the worst change detection effect on the WHU dataset, especially in the areas with relatively small changes. These three methods have many false and missed detections. The SNUNet and DTCDSCN results are slightly better. However, when the target is partially occluded, the detection effect is likely to be poor, as shown in
Figure 5h,i, and the detection effect on the edge of the target is also poor, as shown in
Figure 5e,h, which indicates that the attention mechanism is helpful for the extraction of small targets. However, the extraction ability of building edges is limited. The BIT network has improved the detection results of small targets and target edge regions. However, the network is more sensitive to changes in image radiation, such as the serious false detection in
Figure 5g. At the same time, given the full combination of prior semantic information, our network achieves the best visual detection effect on the WHU dataset. Even for areas with large radiation differences, the proposed algorithm still achieves good change detection results.
4.3.2. Comparisons on LEVIR Dataset
To further verify the effect of the proposed method, more experiments were conducted on the LEVIR dataset.
Table 2 shows that due to the simple building structure of the LEVIR dataset, FC-EF, FC-DIFF, and FC-CONC have different degrees of improvement in the change detection effect on LEVIR. At the same time, due to the complex background of the LEVIR dataset and many small targets, the densely connected strategy-based SNUNet achieves higher change detection results than that of the DTCDSCN method. The proposed method still achieves the best results on the LEVIR dataset. It achieves 83.80% and 91.19% on IoU and F1, respectively. Compared with the second-ranked BIT, the IoU and F1 are 1.17% and 0.7% higher, respectively.
Figure 6 visually shows the change detection results of different methods on the LEVIR dataset. The same as that on the WHU dataset, the performance of EF-FC, FC-CONC, and FC-DIFF is poor, and the missed detection is serious, which also corresponds to the high OA rate, high precision rate, and low recall rate in
Table 2. SNUNet and DTCDSCN are slightly worse in the building edge areas, as shown in
Figure 6b,c, and DTCDSCN has slightly more false detections than SNUNet. BIT has good detection results in most cases, but it is still prone to occasional obvious missed detections, as shown in
Figure 6a,f,i. Similar to the WHU dataset, PSI-CD performs best among all methods.
4.4. Comparisons of Different Methods with Different Amounts of Data
To verify the effect of prior semantic information in our PSI-CD, we randomly selected change detection samples with different training amounts according to the ratios of 5%, 10%, 20%, 40%, 60%, 80%, and 100%. For the comparison method, we chose three models, namely, DTCDSCN, SNUNet, and BIT, because they achieved better experimental results when trained on the 100% dataset, and DTCDSCN also used semantic information to guide change detection. We used the same test set to perform statistics on the
IoU metrics. The comparisons of the two datasets are shown in
Table 3 and
Table 4.
Table 3 and
Table 4 show that on the WHU and LEVIR datasets, when the data volume is 100%, the IoU metrics of the three algorithms are not much different, but with the continuous reduction in the change detection sample data volume, the results of the three algorithms, DTCDSCN, SNUNet, and BIT, have dropped significantly. Comparing the three cases of 5% sample size and 100% sample size, the IoU of the proposed method reduces by 6.13% on the WHU dataset, which is more difficult and only reduces by 2.48% on the LEVIR dataset. The IoU of the BIT algorithm reduces by 9.86% and 7.26%, the IoU of the SNUNet algorithm reduces by 14.38% and 12.16%, and the IoU of the DTCDSCN algorithm reduces by 20.3% and 17.23%.
Compared with DTCDSCN, although the latter uses a semantic segmentation dataset in the training process, the accuracy of change detection is not significantly higher than those of SNUNet and BIT and lower than those of PSI-CD. The reasons may be as follows. (1) The structure of DTCDSCN is more sensitive to the dataset. (2) The reduction in data volume affects the extraction of semantic features, especially when the data volume is less than 60%, the semantic features have little effect on change detection.
Compared with SNUNet and BIT, with the guidance of prior semantic information, the results of PSI-CD on the 5% dataset are much higher than those of SNUNet and BIT, and they also show the best results on other sample sizes. Therefore, PSI-CD has better performance in the small sample change detection task.
4.5. Ablation Study
To evaluate the effectiveness of each component of the proposed method effectively, we divide our method into a combination of different components and conduct ablation study on the two datasets, WHU and LEVIR. The experimental data and hyperparameters used in this section are consistent with other experiments in this paper. The combined settings of the different components in the ablation study are detailed as follows.
“Baseline”: Only the encoder part of the PSINet is used, the decoder part of the PSINet is not used, the attention model (e.g., SPAM) is not used in the change analysis module, and only the FICM is used in the change analysis module.
“+Decoder”: The decoder part of the PSINet is added on the basis of the baseline model; that is, the encoder and decoder of the PSINet are used.
“+CAM”: On the basis of “Baseline ”, the change analysis module of the last layer (e.g., F5) adds an attention mechanism (e.g., SPAM) but does not use the decoder of the PSINet.
“PSI-CD”: Add “CAM” on the basis of “+Decoder”, which is all part of our network.
At the same time, to verify the influence of the accuracy of prior semantic information on change detection, two kinds of prior semantic information in the ablation study, namely, fully trained PSINet and incompletely trained PSINet, are used in this paper. The incompletely trained PSINet is the model of the eighth epoch during training.
The results of the ablation study for the two datasets are shown in
Table 5.
Table 5 shows that our baseline model can achieve relatively desirable results even when guided by prior semantic information that is not fully trained. The IoU of the WHU and LEVIR datasets reached 79.71% and 80.21%, respectively. After adding the decoder of PSINet, the change detection performance was improved, with IoU improving by 1.83% and 1.98% on the two datasets, respectively, compared to 2.27% and 1.94% after adding the CAM module. This shows that both the decoder’s semantic information and CAM modules help to improve the effectiveness of change detection. The combined effect of the two PSI-CD increased by 3.31% and 2.94% in WHU and LEVIR compared to baseline.
When better prior semantic information was used, the baseline model also performed better on WHU and LEVIR, with IoU of 82.33% and 82.70%, respectively, an improvement of 2.62% and 2.49%. Compared with the decoder’s semantic information and CAM alone, the improvement of the baseline is higher, which indicates that the accuracy of prior semantic information has a greater impact on change detection results. At this time, the semantic information and CAM of the decoder improved by 0.51% and 0.57% in WHU and 0.58% and 0.56% on LEVIR, respectively. It can be demonstrated that every component of the network in this article is effective. The combined effect of PSI-CD increased by 0.92% and 1.1% on WHU and LEVIR relative to baseline.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}