
Machine Learning in the Classification of Soybean Genotypes for Primary Macronutrients’ Content Using UAV–Multispectral Sensor
 ,
,  ,
,  ,
,  , ,
, ,  , and
, and
Abstract
:1. Introduction
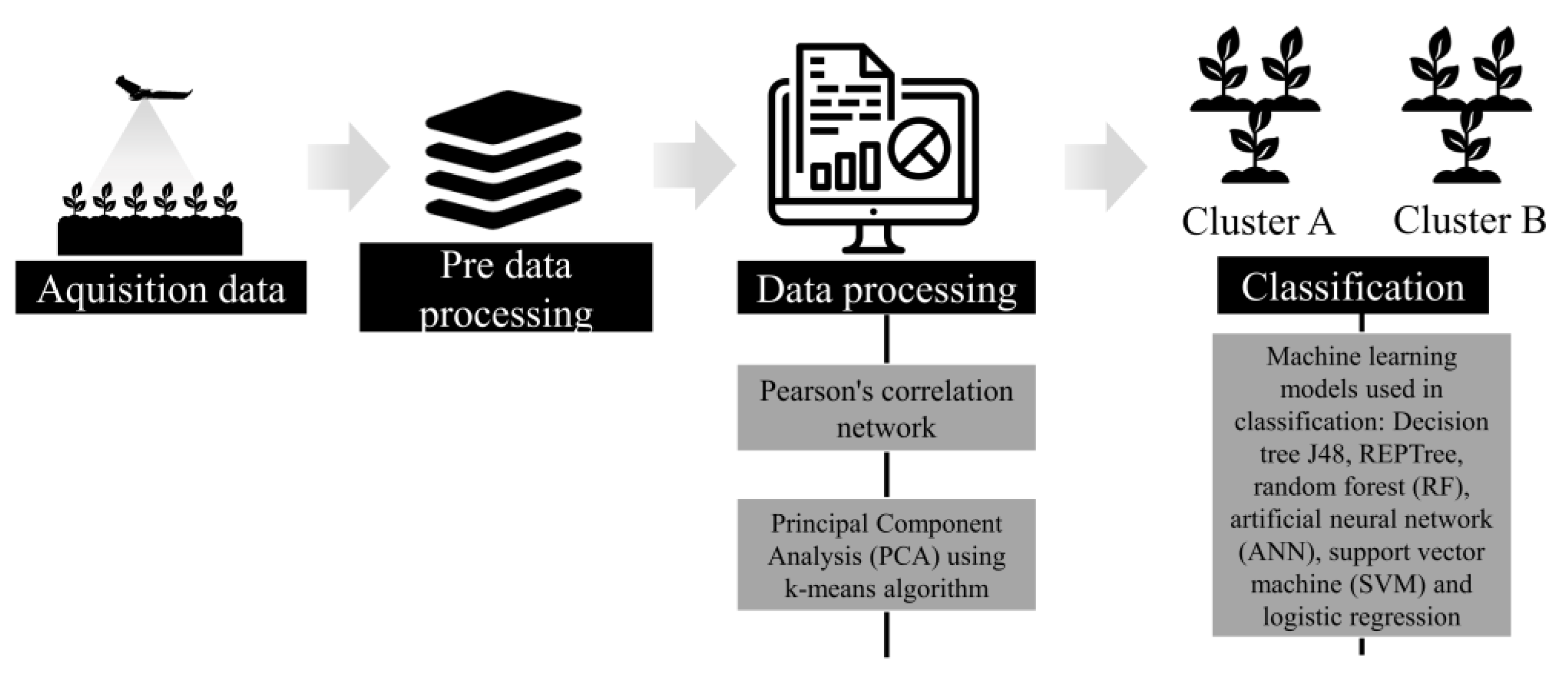
2. Materials and Methods
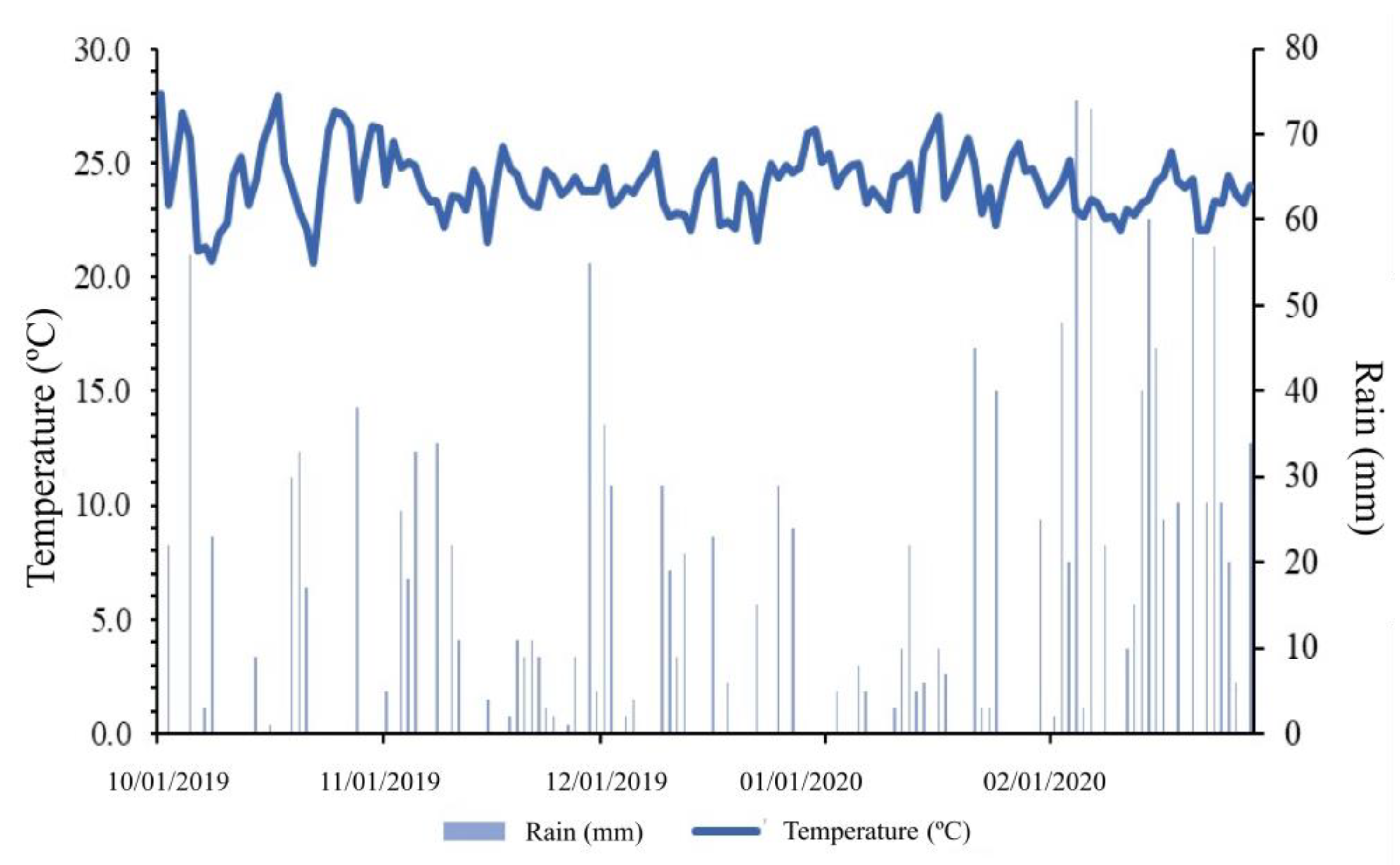
2.1. Conducting the Experiment
2.2. Acquisition and Processing of Multispectral Images
2.3. Obtaining Nutritional Data
2.4. Statistical Analysis
2.5. Machine Learning Models
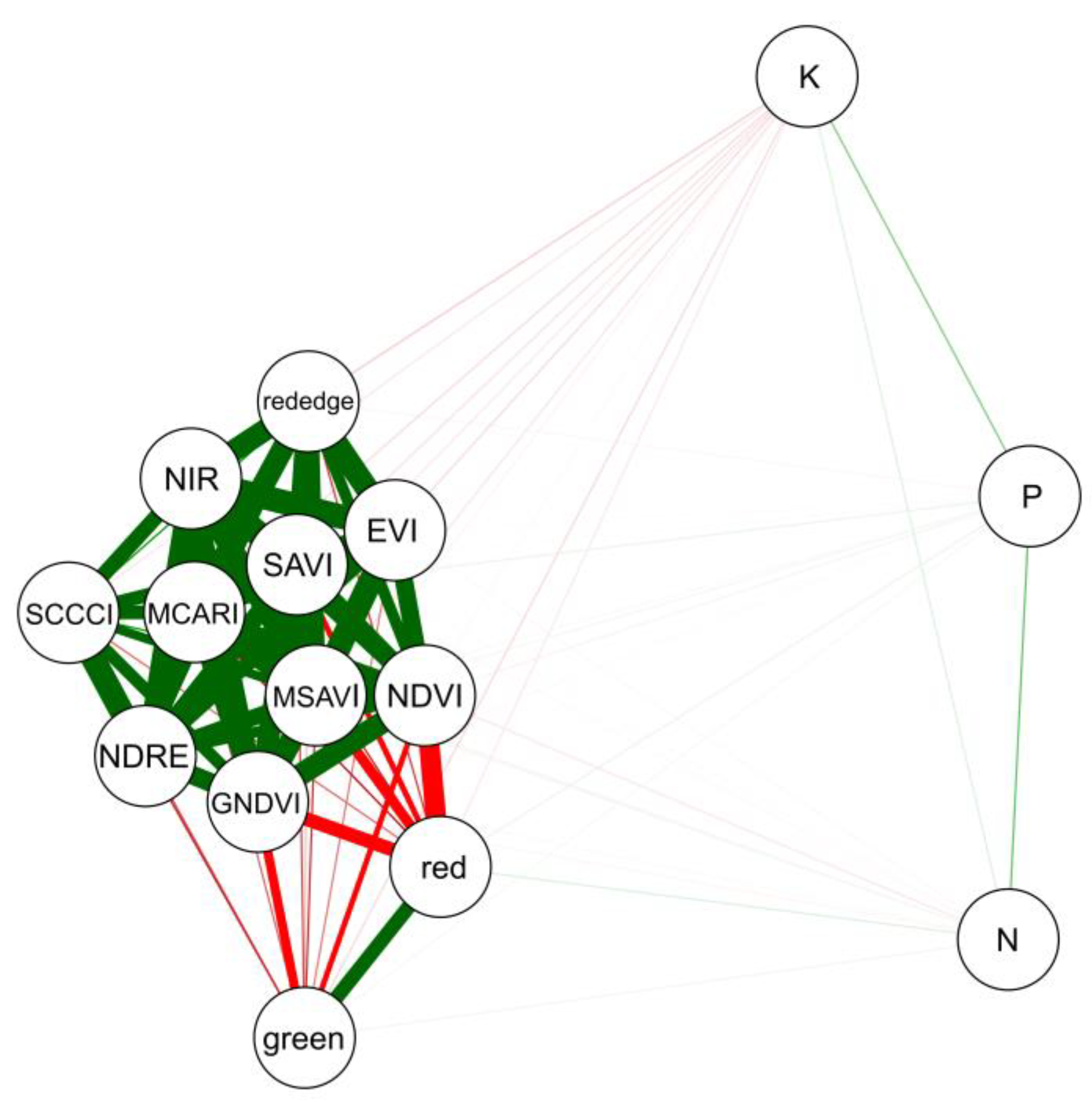
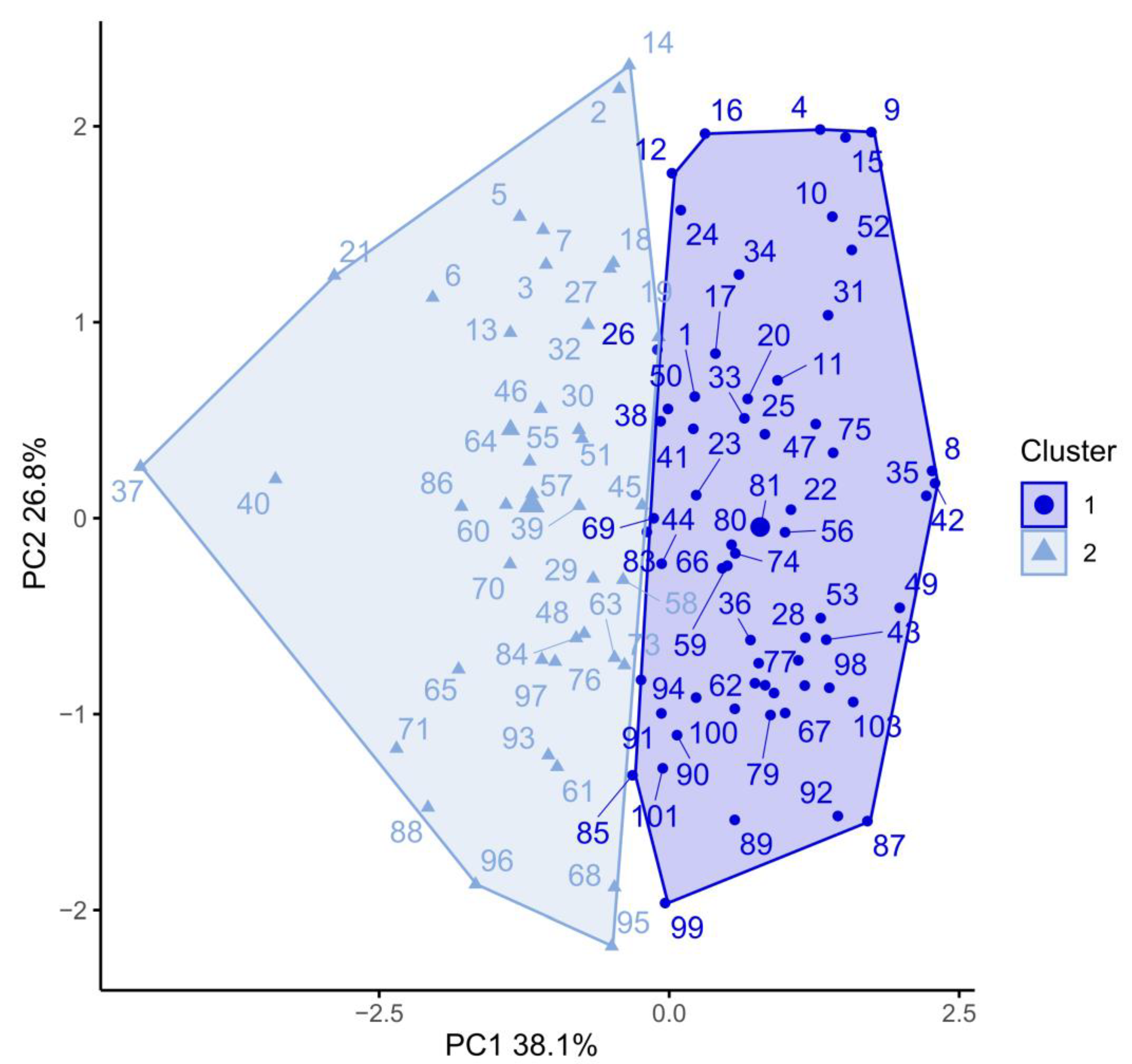
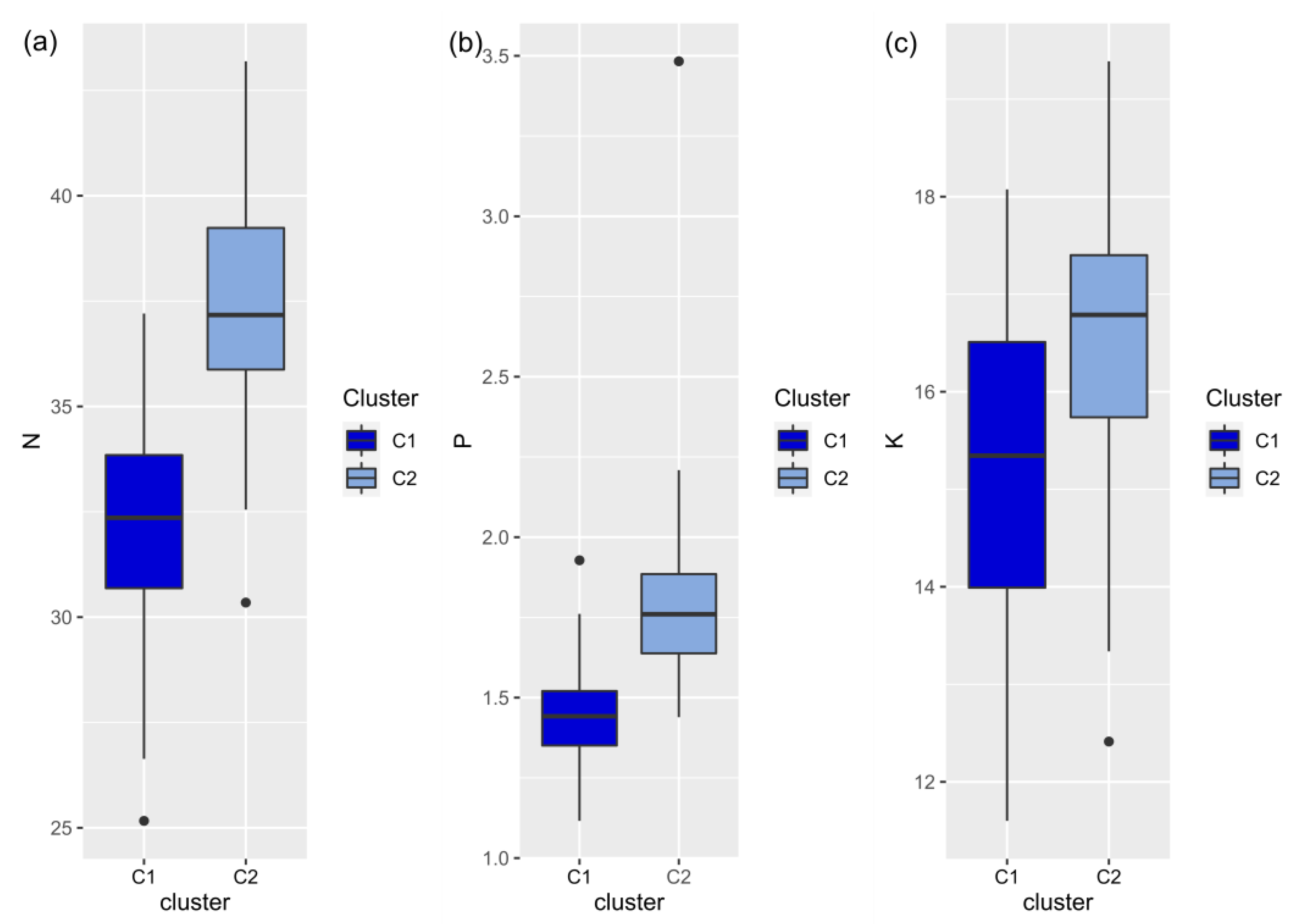
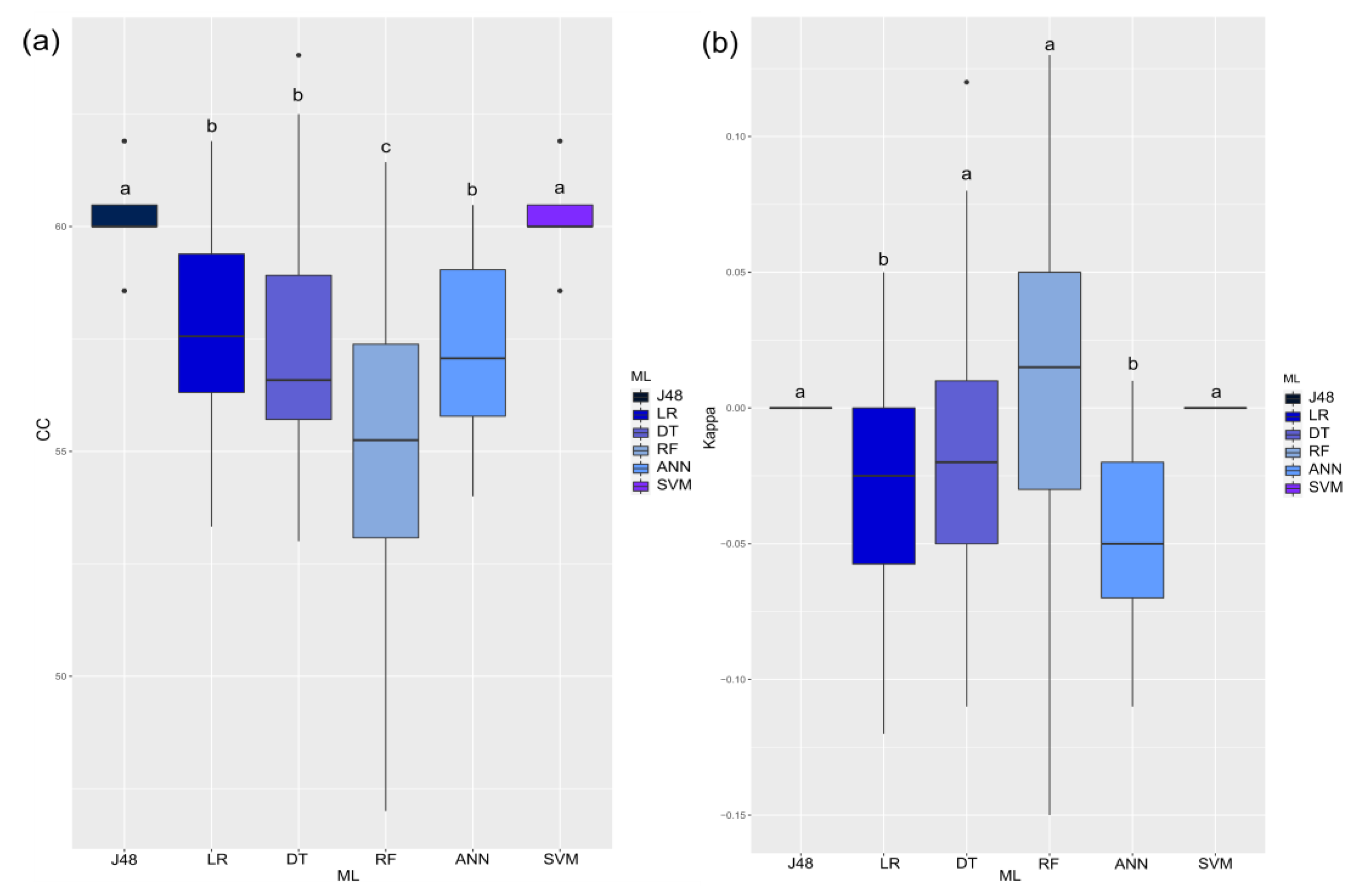
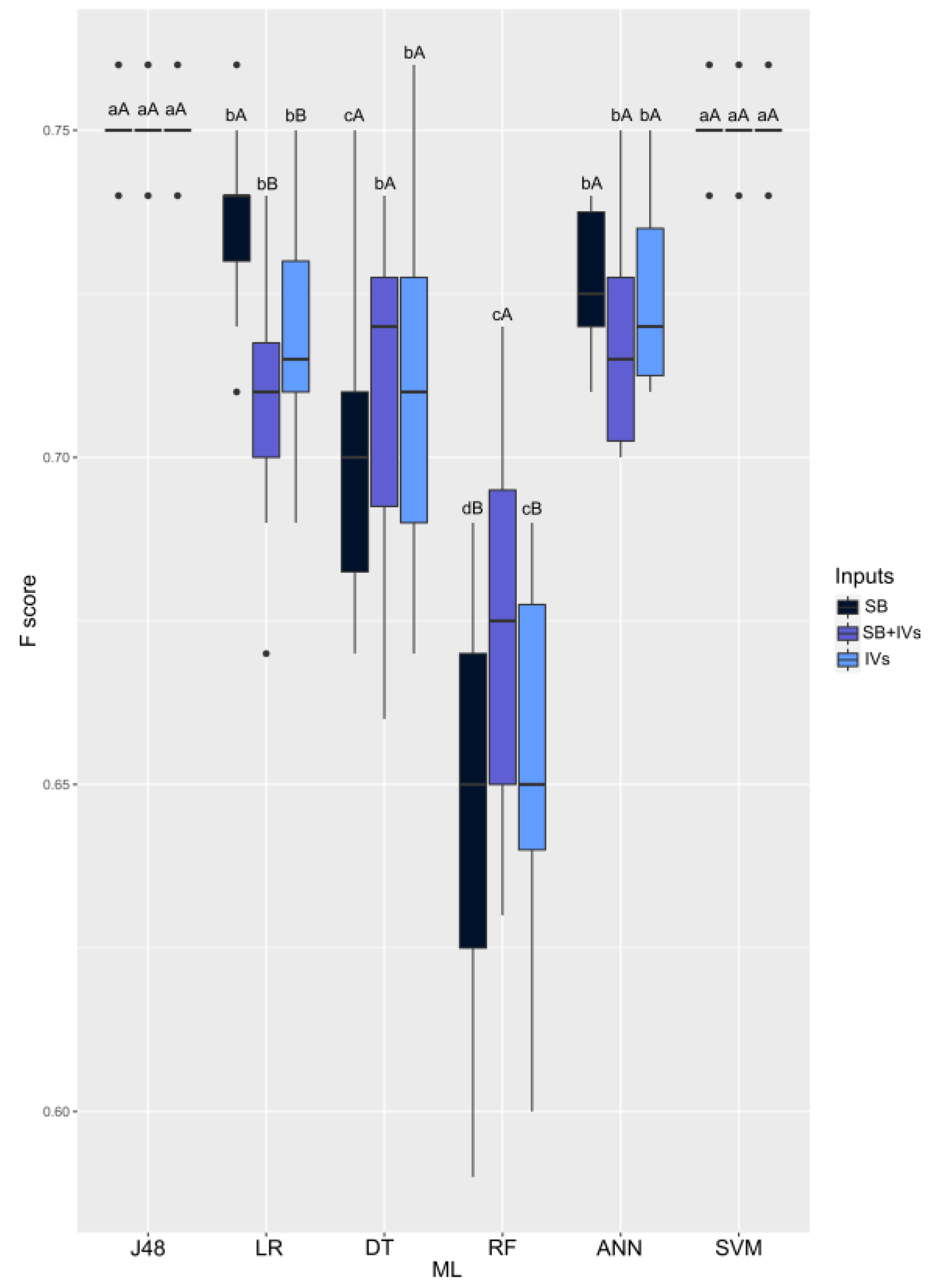
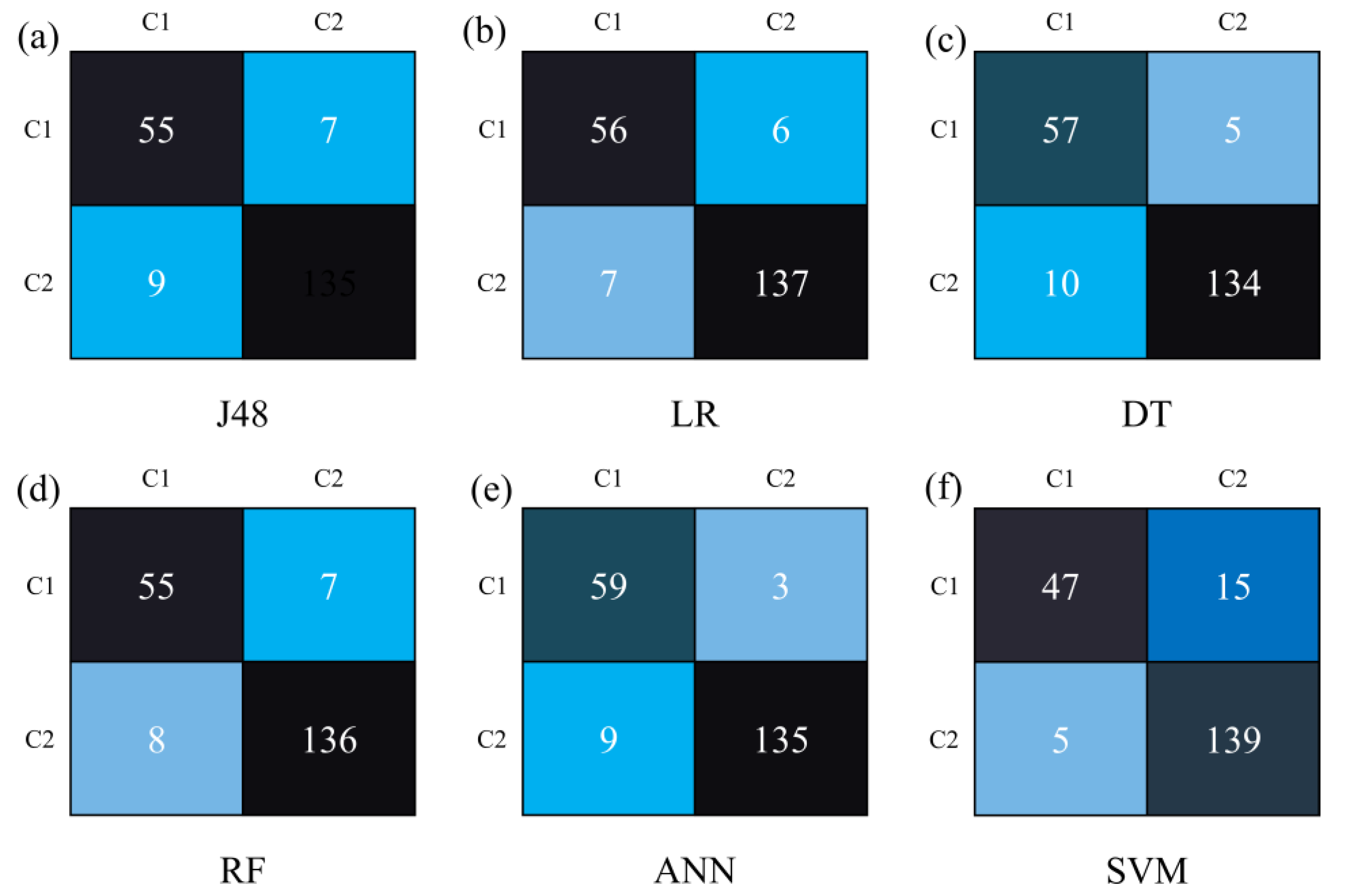
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lynch, J.P. Root Phenes That Reduce the Metabolic Costs of Soil Exploration: Opportunities for 21st Century Agriculture. Plant Cell Environ. 2015, 38, 1775–1784. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Mou, H.; Zhou, J.; Zhou, J.; Ye, H.; Nguyen, H.T. Development of an Automated Plant Phenotyping System for Evaluation of Salt Tolerance in Soybean. Comput. Electron. Agric. 2021, 182, 106001. [Google Scholar] [CrossRef]
- Der Yang, M.; Tseng, H.H.; Hsu, Y.C.; Yang, C.Y.; Lai, M.H.; Wu, D.H. A UAV Open Dataset of Rice Paddies for Deep Learning Practice. Remote Sens. 2021, 13, 1358. [Google Scholar] [CrossRef]
- Panday, U.S.; Pratihast, A.K.; Aryal, J.; Kayastha, R.B. A Review on Drone-Based Data Solutions for Cereal Crops. Drones 2020, 4, 41. [Google Scholar] [CrossRef]
- Guo, Y.; Chen, S.; Li, X.; Cunha, M.; Jayavelu, S.; Cammarano, D.; Fu, Y. Machine Learning-Based Approaches for Predicting SPAD Values of Maize Using Multi-Spectral Images. Remote Sens 2022, 14, 1337. [Google Scholar] [CrossRef]
- Everaerts, J. The Use of Unmanned Aerial Vehicles (UAVs) for Remote Sensing and Mapping. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2008, 37, 1187–1192. [Google Scholar]
- Ling, B.; Goodin, D.G.; Raynor, E.J.; Joern, A. Hyperspectral Analysis of Leaf Pigments and Nutritional Elements in Tallgrass Prairie Vegetation. Front Plant. Sci. 2019, 10, 142. [Google Scholar] [CrossRef] [Green Version]
- Moreno, R.; Corona, F.; Lendasse, A.; Graña, M.; Galvão, L.S. Extreme Learning Machines for Soybean Classification in Remote Sensing Hyperspectral Images. Neurocomputing 2014, 128, 207–216. [Google Scholar] [CrossRef]
- Mahajan, G.R.; Das, B.; Murgaokar, D.; Herrmann, I.; Berger, K.; Sahoo, R.N.; Patel, K.; Desai, A.; Morajkar, S.; Kulkarni, R.M. Monitoring the Foliar Nutrients Status of Mango Using Spectroscopy-Based Spectral Indices and PLSR-Combined Machine Learning Models. Remote Sens. 2021, 13, 641. [Google Scholar] [CrossRef]
- O’Connell, J.L.; Byrd, K.B.; Kelly, M. Remotely-Sensed Indicators of N-Related Biomass Allocation in Schoenoplectus Acutus. PLoS ONE 2014, 9, e90870. [Google Scholar] [CrossRef]
- Osco, L.P.; Marques Ramos, A.P.; Saito Moriya, É.A.; de Souza, M.; Marcato Junior, J.; Matsubara, E.T.; Imai, N.N.; Creste, J.E. Improvement of Leaf Nitrogen Content Inference in Valencia-Orange Trees Applying Spectral Analysis Algorithms in UAV Mounted-Sensor Images. Int. J. Appl. Earth Obs. Geoinf. 2019, 83, 101907. [Google Scholar] [CrossRef]
- Hawkesford, M.; Horst, W.; Kichey, T.; Lambers, H.; Schjoerring, J.; Møller, I.S.; White, P. Chapter 6—Functions of Macronutrients. In Marschner’s Mineral Nutrition of Higher Plants (Third Edition); Marschner, P., Ed.; Academic Press: San Diego, CA, USA, 2012; pp. 135–189. ISBN 978-0-12-384905-2. [Google Scholar]
- Mukherjee, S.; Laskar, S. Vis–NIR-Based Optical Sensor System for Estimation of Primary Nutrients in Soil. J. Opt. 2019, 48, 87–103. [Google Scholar] [CrossRef]
- Amirruddin, A.D.; Muharam, F.M.; Ismail, M.H.; Tan, N.P.; Ismail, M.F. Hyperspectral Spectroscopy and Imbalance Data Approaches for Classification of Oil Palm’s Macronutrients Observed from Frond 9 and 17. Comput. Electron. Agric. 2020, 178, 105768. [Google Scholar] [CrossRef]
- Pham, B.T.; Tien Bui, D.; Prakash, I.; Dholakia, M.B. Hybrid Integration of Multilayer Perceptron Neural Networks and Machine Learning Ensembles for Landslide Susceptibility Assessment at Himalayan Area (India) Using GIS. Catena 2017, 149, 52–63. [Google Scholar] [CrossRef]
- Camps-Valls, G. Machine Learning in Remote Sensing Data Processing. In Proceedings of the 2009 IEEE International Workshop on Machine Learning for Signal Processing, Grenoble, France, 1–4 September 2009; pp. 1–6. [Google Scholar]
- de Medeiros, A.D.; Capobiango, N.P.; da Silva, J.M.; da Silva, L.J.; da Silva, C.B.; dos Santos Dias, D.C.F. Interactive Machine Learning for Soybean Seed and Seedling Quality Classification. Sci. Rep. 2020, 10, 11267. [Google Scholar] [CrossRef] [PubMed]
- Orusa, T.; Cammareri, D.; Borgogno Mondino, E. A Scalable Earth Observation Service to Map Land Cover in Geomorphological Complex Areas beyond the Dynamic World: An Application in Aosta Valley (NW Italy). Appl. Sci. 2023, 13, 390. [Google Scholar] [CrossRef]
- Barbedo, J.G.A. Detection of Nutrition Deficiencies in Plants Using Proximal Images and Machine Learning: A Review. Comput. Electron. Agric. 2019, 162, 482–492. [Google Scholar] [CrossRef]
- Gava, R.; Santana, D.C.; Cotrim, M.F.; Rossi, F.S.; Teodoro, L.P.R.; da Silva Junior, C.A.; Teodoro, P.E. Soybean Cultivars Identification Using Remotely Sensed Image and Machine Learning Models. Sustainability 2022, 14, 7125. [Google Scholar] [CrossRef]
- Da Silva Junior, C.A.; Teodoro, P.E.; Teodoro, L.P.R.; Della-Silva, J.L.; Shiratsuchi, L.S.; Baio, F.H.R.; Boechat, C.L.; Capristo-Silva, G.F. Is It Possible to Detect Boron Deficiency in Eucalyptus Using Hyper and Multispectral Sensors? Infrared Phys. Technol. 2021, 116, 103810. [Google Scholar] [CrossRef]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring Vegetation Systems in the Great Plains with ERTS. NASA Spec. Publ. 1974, 351, 309. [Google Scholar]
- Gitelson, A.A.; Kaufman, Y.J.; Merzlyak, M.N. Use of a Green Channel in Remote Sensing of Global Vegetation from EOS-MODIS. Remote Sens. Environ. 1996, 58, 289–298. [Google Scholar] [CrossRef]
- Huete, A.R. A Soil-Adjusted Vegetation Index (SAVI). Remote Sens. Environ. 1988, 25, 295–309. [Google Scholar] [CrossRef]
- Qi, J.; Chehbouni, A.; Huete, A.R.; Kerr, Y.H.; Sorooshian, S. A Modified Soil Adjusted Vegetation Index. Remote Sens. Environ. 1994, 48, 119–126. [Google Scholar] [CrossRef]
- Daughtry, C.S.T.; Walthall, C.L.; Kim, M.S.; de Colstoun, E.B.; McMurtrey Iii, J.E. Estimating Corn Leaf Chlorophyll Concentration from Leaf and Canopy Reflectance. Remote Sens. Environ. 2000, 74, 229–239. [Google Scholar] [CrossRef]
- Huete, A.R.; Liu, H.Q.; Batchily, K.V.; van Leeuwen, W. A Comparison of Vegetation Indices over a Global Set of TM Images for EOS-MODIS. Remote Sens. Environ. 1997, 59, 440–451. [Google Scholar] [CrossRef]
- Raper, T.B.; Varco, J.J. Canopy-Scale Wavelength and Vegetative Index Sensitivities to Cotton Growth Parameters and Nitrogen Status. Precis. Agric. 2015, 16, 62–76. [Google Scholar] [CrossRef] [Green Version]
- Bataglia, O.C.; Teixeira, J.P.F.; Furlani, P.R.; Furlani, A.M.C.; Gallo, J.R. Métodos de Análise Química de Plantas; IAC: Campinas, Brasil, 1978; Volume 87. [Google Scholar]
- Bhering, L.L. Rbio: A Tool for Biometric and Statistical Analysis Using the R Platform. Crop. Breed. Appl. Biotechnol. 2017, 17, 187–190. [Google Scholar] [CrossRef] [Green Version]
- Team, R.C. R: A Language and Environment for Statistical Computing. Comput. Sci. Rev. 2013, 201, 1–12. [Google Scholar]
- Quinlan, J.R. C4. 5: Programming for Machine Learning. Morgan Kauffmann 1993, 38, 49. [Google Scholar]
- Štepanovský, M.; Ibrová, A.; Buk, Z.; Velemínská, J. Novel Age Estimation Model Based on Development of Permanent Teeth Compared with Classical Approach and Other Modern Data Mining Methods. Forensic. Sci. Int. 2017, 279, 72–82. [Google Scholar] [CrossRef]
- Al Snousy, M.B.; El-Deeb, H.M.; Badran, K.; Al Khlil, I.A. Suite of Decision Tree-Based Classification Algorithms on Cancer Gene Expression Data. Egypt. Inform. J. 2011, 12, 73–82. [Google Scholar] [CrossRef] [Green Version]
- Belgiu, M.; Drăguţ, L. Random Forest in Remote Sensing: A Review of Applications and Future Directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Egmont-Petersen, M.; de Ridder, D.; Handels, H. Image Processing with Neural Networks—A Review. Pattern. Recognit. 2002, 35, 2279–2301. [Google Scholar] [CrossRef]
- Nalepa, J.; Kawulok, M. Selecting Training Sets for Support Vector Machines: A Review. Artif. Intell. Rev. 2019, 52, 857–900. [Google Scholar] [CrossRef] [Green Version]
- Scott, A.J.; Knott, M. A Cluster Analysis Method for Grouping Means in the Analysis of Variance. Biometrics 1974, 30, 507–512. [Google Scholar] [CrossRef] [Green Version]
- Osco, L.P.; Ramos, A.P.M.; Faita Pinheiro, M.M.; Moriya, É.A.S.; Imai, N.N.; Estrabis, N.; Ianczyk, F.; de Araújo, F.F.; Liesenberg, V.; Jorge, L.A.d.A. A Machine Learning Framework to Predict Nutrient Content in Valencia-Orange Leaf Hyperspectral Measurements. Remote Sens. 2020, 12, 906. [Google Scholar] [CrossRef] [Green Version]
- Chaney, R.L. Breeding Soybeans to Prevent Mineral Deficiencies or Toxicities. In World Soybean Research Conference III: Proceedings, Ames, IA, 12–17 August 1984; CRC Press: Boca Raton, FL, USA, 2022; pp. 453–459. [Google Scholar]
- Khechba, K.; Laamrani, A.; Dhiba, D.; Misbah, K.; Chehbouni, A. Monitoring and Analyzing Yield Gap in Africa through Soil Attribute Best Management Using Remote Sensing Approaches: A Review. Remote Sens. 2021, 13. [Google Scholar] [CrossRef]
- Peng, X.; Chen, D.; Zhou, Z.; Zhang, Z.; Xu, C.; Zha, Q.; Wang, F.; Hu, X. Prediction of the Nitrogen, Phosphorus and Potassium Contents in Grape Leaves at Different Growth Stages Based on UAV Multispectral Remote Sensing. Remote Sens. 2022, 14, 2659. [Google Scholar] [CrossRef]
- Soba, D.; Shu, T.; Runion, G.B.; Prior, S.A.; Fritschi, F.B.; Aranjuelo, I.; Sanz-Saez, A. Effects of Elevated [CO2] on Photosynthesis and Seed Yield Parameters in Two Soybean Genotypes with Contrasting Water Use Efficiency. Environ. Exp. Bot 2020, 178, 104154. [Google Scholar] [CrossRef]
- Xiong, R.; Liu, S.; Considine, M.J.; Siddique, K.H.M.; Lam, H.-M.; Chen, Y. Root System Architecture, Physiological and Transcriptional Traits of Soybean (Glycine Max L.) in Response to Water Deficit: A Review. Physiol. Plant 2021, 172, 405–418. [Google Scholar] [CrossRef]
- Rossi Neto, J.; de Souza, Z.M.; de Medeiros Oliveira, S.R.; Kölln, O.T.; Ferreira, D.A.; Carvalho, J.L.N.; Braunbeck, O.A.; Franco, H.C.J. Use of the Decision Tree Technique to Estimate Sugarcane Productivity Under Edaphoclimatic Conditions. Sugar Tech. 2017, 19, 662–668. [Google Scholar] [CrossRef]
- Vieira, M.A.; Formaggio, A.R.; Rennó, C.D.; Atzberger, C.; Aguiar, D.A.; Mello, M.P. Object Based Image Analysis and Data Mining Applied to a Remotely Sensed Landsat Time-Series to Map Sugarcane over Large Areas. Remote Sens. Environ. 2012, 123, 553–562. [Google Scholar] [CrossRef]
- Bigdeli, B.; Samadzadegan, F.; Reinartz, P. A Multiple SVM System for Classification of Hyperspectral Remote Sensing Data. J. Indian Soc. Remote Sens. 2013, 41, 763–776. [Google Scholar] [CrossRef] [Green Version]
- Okwuashi, O.; Ndehedehe, C.E. Deep Support Vector Machine for Hyperspectral Image Classification. Pattern. Recognit. 2020, 103, 107298. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support Vector Machines in Remote Sensing: A Review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Braga, P.; Crusiol, L.G.T.; Nanni, M.R.; Caranhato, A.L.H.; Fuhrmann, M.B.; Nepomuceno, A.L.; Neumaier, N.; Farias, J.R.B.; Koltun, A.; Gonçalves, L.S.A.; et al. Vegetation Indices and NIR-SWIR Spectral Bands as a Phenotyping Tool for Water Status Determination in Soybean. Precis. Agric. 2021, 22, 249–266. [Google Scholar] [CrossRef]
- Bian, C.; Shi, H.; Wu, S.; Zhang, K.; Wei, M.; Zhao, Y.; Sun, Y.; Zhuang, H.; Zhang, X.; Chen, S. Prediction of Field-Scale Wheat Yield Using Machine Learning Method and Multi-Spectral UAV Data. Remote Sens. 2022, 14, 1474. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Vegetation Index | Equation | Ref. |
|---|---|---|---|
| NDVI | Normalized difference vegetation index | [22] | |
| NDRE | Normalized difference red-edge index | [23] | |
| GNDVI | Green normalized difference vegetation index | [23] | |
| SAVI | Soil-adjusted vegetation index | [24] | |
| MSAVI | Modified soil-adjusted vegetation index | [25] | |
| MCARI | Modified chlorophyll absorption in reflectance index | [26] | |
| EVI | Enhanced vegetation index | [27] | |
| SCCCI | Simplified canopy chlorophyll content index | [28] |
| Abbreviation | Classification Model | Reference |
|---|---|---|
| J48 | J48 decision tree algorithm | [32] |
| LR | Logistic regression | [33] |
| DT | REPTree decision tree algorithm | [34] |
| RF | Random forest | [35] |
| ANN | Multilayer perceptron artificial neural network (ANN) | [36] |
| SVM | Support vector machine | [37] |
| SV | DF | CC | F-score | Kappa |
|---|---|---|---|---|
| Inputs | 2 | 0.295 | 0.0000205 | 0.00127 |
| ML | 5 | 117.276 * | 0.0354062 * | 0.013478 * |
| Inputs *ML | 10 | 5.766 | 0.0008566 * | 0.001641 |
| Residual | 162 | 4.98488 | 0.0003958 | 0.00168691 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Santana, D.C.; Teixeira Filho, M.C.M.; da Silva, M.R.; Chagas, P.H.M.d.; de Oliveira, J.L.G.; Baio, F.H.R.; Campos, C.N.S.; Teodoro, L.P.R.; da Silva Junior, C.A.; Teodoro, P.E.; et al. Machine Learning in the Classification of Soybean Genotypes for Primary Macronutrients’ Content Using UAV–Multispectral Sensor. Remote Sens. 2023, 15, 1457. https://doi.org/10.3390/rs15051457
Santana DC, Teixeira Filho MCM, da Silva MR, Chagas PHMd, de Oliveira JLG, Baio FHR, Campos CNS, Teodoro LPR, da Silva Junior CA, Teodoro PE, et al. Machine Learning in the Classification of Soybean Genotypes for Primary Macronutrients’ Content Using UAV–Multispectral Sensor. Remote Sensing. 2023; 15(5):1457. https://doi.org/10.3390/rs15051457
Chicago/Turabian StyleSantana, Dthenifer Cordeiro, Marcelo Carvalho Minhoto Teixeira Filho, Marcelo Rinaldi da Silva, Paulo Henrique Menezes das Chagas, João Lucas Gouveia de Oliveira, Fábio Henrique Rojo Baio, Cid Naudi Silva Campos, Larissa Pereira Ribeiro Teodoro, Carlos Antonio da Silva Junior, Paulo Eduardo Teodoro, and et al. 2023. "Machine Learning in the Classification of Soybean Genotypes for Primary Macronutrients’ Content Using UAV–Multispectral Sensor" Remote Sensing 15, no. 5: 1457. https://doi.org/10.3390/rs15051457