1. Introduction
Lake surface water temperature (LSWT) is one of the important indicators of lake ecosystems. Some research on global warming reported the LSWT of global lakes shows a general warming trend, and this trend is expected to continue in the future [
1,
2,
3]. Warming surface water temperatures would reduce the ice cover and shorten the lake’s icing period. The decrease of ice cover and the increase of LSWT would change the mixing regimes of the lake and further affect the exchange of nutrients and oxygen [
4]. In addition, changes in LSWT would affect lake water quality, according to the previous study [
5]. This series of changes will have a serious impact on the lake’s ecological environment, affect lake biodiversity, and bring ecological and economic impacts to human society. Therefore, it is crucial to accurately predict future changes in LSWT. However, changes in LSWT is the result of the interaction of multiple climate variables [
6], and complex nonlinear relationships exist between climate variables and LSWT, which poses difficulties for accurate prediction. We established a new deep learning model to mine the nonlinear dynamics in the prediction of LSWT to achieve more accurate prediction results and applied the model to the prediction of lake surface water temperature of Qinghai Lake.
Currently, the main statistical-related methods for predicting LSWT can be divided into three categories: hybrid physical-statistical models, traditional statistical models, and machine learning models. Firstly, the physically-statistically based Air2water model [
7,
8,
9,
10,
11], is a very popular model and has achieved the best results of several studies [
12,
13]. It is a simple and accurate model based on the volume-integrated heat balance equation, and using only air temperature as an input [
14]. Secondly, traditional statistics-based regression models are also frequently used in the prediction of LSWT [
15,
16,
17]. Thirdly, machine learning algorithms have flourished in recent years and are also commonly used to solve water temperature predictions in lakes and rivers [
18], such as Random Forests, M5Tree models [
12], and Multi-Layer perceptron (MLP) [
12,
13,
19,
20]. To further improve the accuracy, researchers have combined various machine learning models to form new frameworks [
21], or combining MLP with wavelet variation [
13,
22,
23], which is commonly used to improve the accuracy of hydrologic time series analysis [
24]. In addition, lake model is the main method to simulate lake water temperature. For example, the Freshwater Lake model (FLlake) [
25] is a commonly used one-dimensional lake model which can simulate the thermal behavior and vertical temperature structure of lake surface at different depths. In this model, the lake is divided into a mixed layer and a thermocline layer according to thermal structure, and the thermocline temperature profile is parameterized based on self-similarity theory [
26]. Recent studies have conducted sensitivity experiments and calibration on Qinghai Lake to improve the accuracy of lake temperature simulation by FLlake model [
27].
Deep learning shows a stronger ability to handle large data and complex problems than traditional methods. LSWT prediction is essentially a time series prediction problem. There are many deep learning models for time series prediction that have been applied to various domains. The classical model of time series prediction problem in deep learning is Recurrent Neural Network (RNN) [
28], which can capture the pattern of data changes over time well. However, the RNN has difficulty in learning the long-term dependencies of time series. Then, the Long Short-Term Memory network (LSTM) model alleviates this problem to some extent [
29]. In the weighted average temperature prediction problem, LSTM achieved better prediction results than RNN in the experiment [
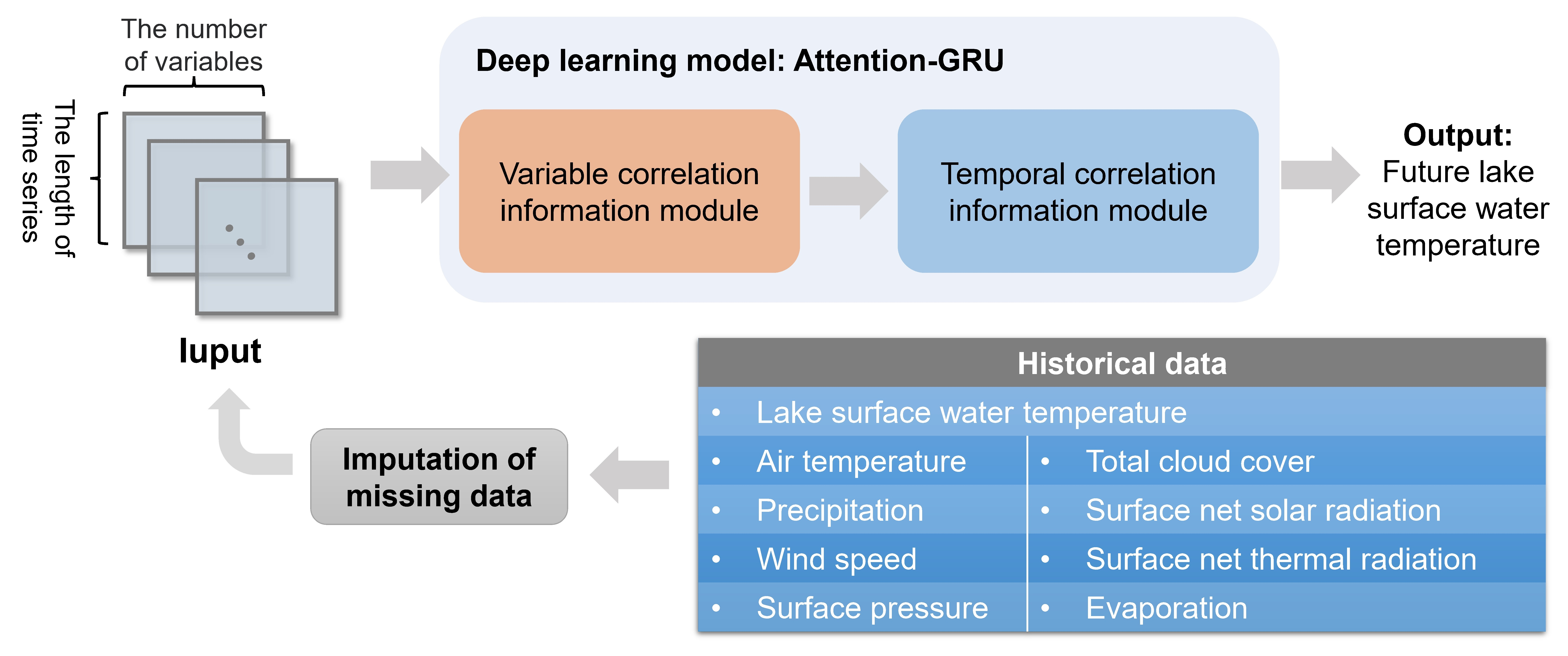
30]. Subsequently, the Gated Recurrent Unit (GRU) model further improves the LSTM, which achieves similar results with fewer model parameters [
31]. Another structure in deep learning, the Attention mechanism [
31,
32], has been the focus of many researchers. In the prediction of ocean surface temperature, a model incorporating the Attention mechanism in the GRU encoder–decoder structure was applied [
33]. With the development of the Attention mechanism, the Transformer model was proposed and has become one of the most popular deep learning models, while the Self-Attention mechanism [
34] was also proposed. The GTN [
35] model uses the Self-Attention mechanism to construct a two-tower Transformer model, which effectively extracts time-related and channel-related features in multivariate time series, respectively.
The Air2water model uses only air temperature as a direct input. However, air temperature is the main factor affecting surface water temperature in lakes, not the only factor [
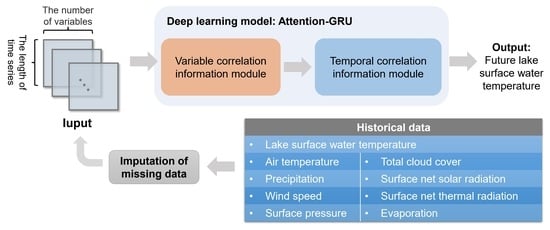
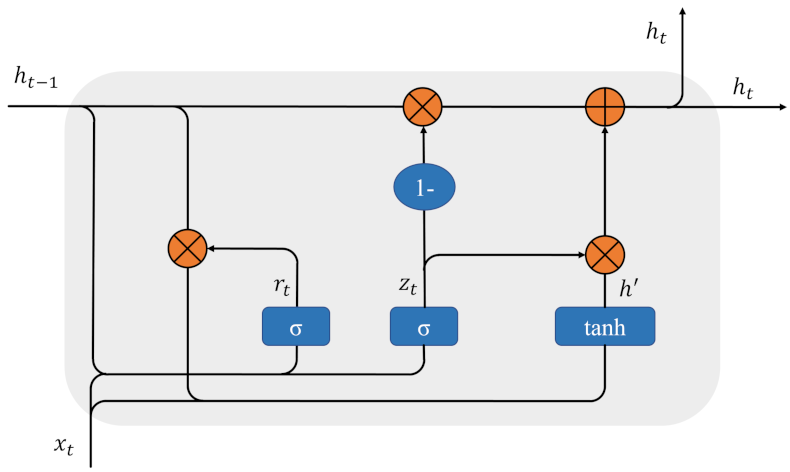
36]. This allows the Air2water model to discard some information that affects the variability of lake surface water temperature. Fortunately, we have access to many satellite observations and meteorological station data, through which we can obtain more information on climate variables. How to construct the model to extract effective features from the data is the key. Given the superiority of deep learning in extracting effective features from complex nonlinear relationships compared with traditional statistical methods, we would construct a new deep learning model for predicting LSWT to obtain more accurate prediction results. The interaction of climate variables and temporal autocorrelation are the two main aspects that contribute to the variation of LSWT. It is crucial to effectively extract data features from both aspects using deep learning models. Inspired by the GTN model [
35], the information in the multivariate time series is divided into two parts: variable correlation information and temporal correlation information, and the feature extraction module is constructed separately. In the variable correlation information module, the Self-attention mechanism is used to extract the key variable features. In the module of temporal correlation information, the GRU model is used to capture the changing laws of time series. The two modules are combined to form the Attention-GRU model. To verify the validity of the model, we apply the proposed model to a case study of lake surface water temperature prediction in Qinghai Lake and compare it with seven benchmark models. Qinghai Lake is the largest inland lake in China, which plays an irreplaceable role in regulating climate and maintaining the ecological balance in the northwestern part of the Qinghai–Tibet Plateau. The prediction of lake surface water temperature in Qinghai Lake is of great significance for protecting ecological environment. However, due to the complex physical processes that are difficult to describe accurately there is still a space for improvement in the prediction of lake surface water temperature of Qinghai Lake. We build a deep learning model to make full use of the large amount of information, explore the non-linear relationships among different climate variables and try to to improve the prediction by mining the dynamical system behind the data. Meanwhile, by calculating the partial correlation coefficient, the influencing factors of the LSWT in Qinghai Lake are discussed in the
Section 5.1. The main contributions are as follows:
- (1)
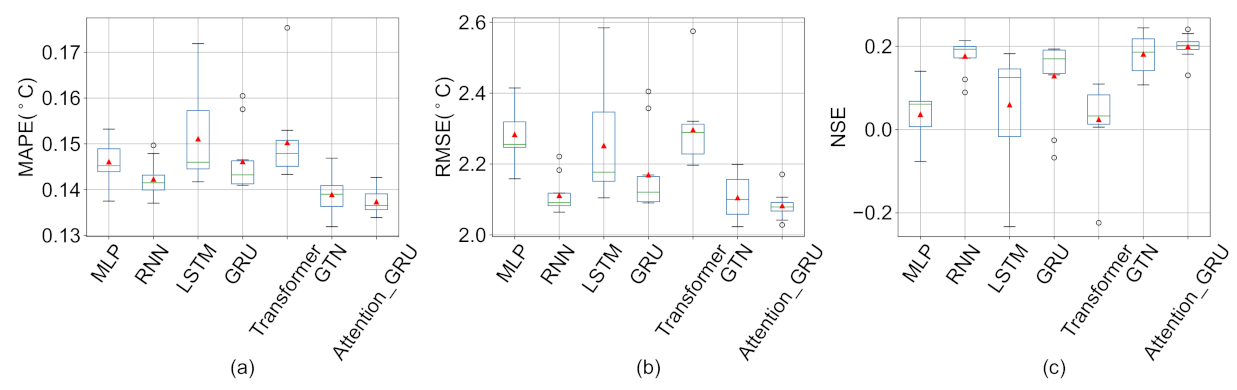
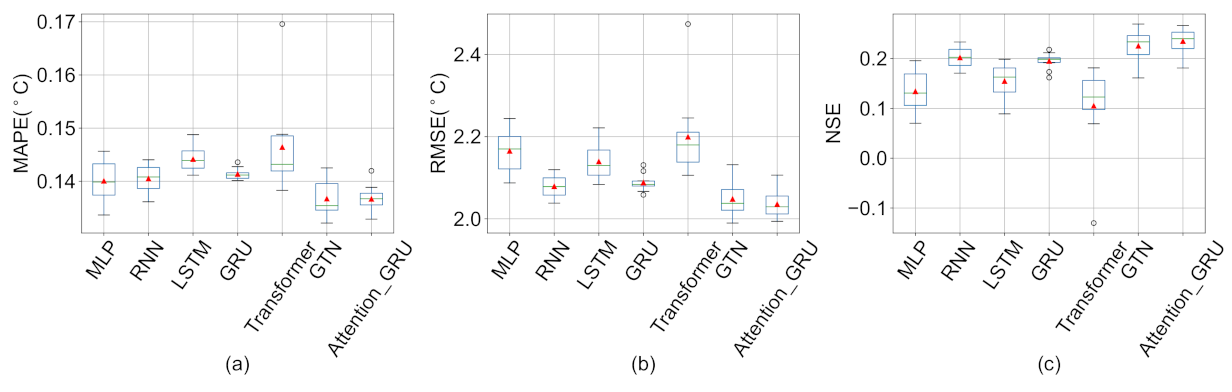
A novel deep learning model (Attention-GRU) for surface water temperature prediction is established. The proposed model outperforms the Air2water model in surface water temperature prediction for Qinghai Lake and achieves the best prediction results, which indicates that the proposed model can mine the nonlinear dynamics of the research problem.
- (2)
We show the results of ten experiments with each deep learning model, indicating that the results of the proposed model are relatively stable, and through ablation experiments, we verify the effectiveness of the proposed model structure.
- (3)
By calculating the partial correlation coefficient, the influencing factors of surface water temperature in Qinghai Lake were analyzed. Climate variables have direct or indirect effects on the surface water temperature of Qinghai Lake in different degrees, and the dominant factor is air temperature.
- (4)
There are a lot of missing values in the LSWT data of Qinghai Lake, and we used six common missing value imputation methods to fill in the missing data. By comparing the filling effects of different missing value imputation methods, the validity of the proposed model on multiple data sets is verified, and the dependence of deep learning models on data quality is shown.
The rest of the paper is organized as follows.
Section 2 presents the model framework and describes the theoretical knowledge of the model in detail. We present the application of the proposed model in
Section 3, including the introduction of data sources and description of the experimental procedure.
Section 4 analysis of the experimental results. In
Section 5, we analyze the factors influencing the LSWT; the impact of the missing value imputation method on the prediction model; the limitations and future work of the proposed model. Finally,
Section 6 summarizes the whole paper.


















{kind=link}
{kind=link}
{kind=link}
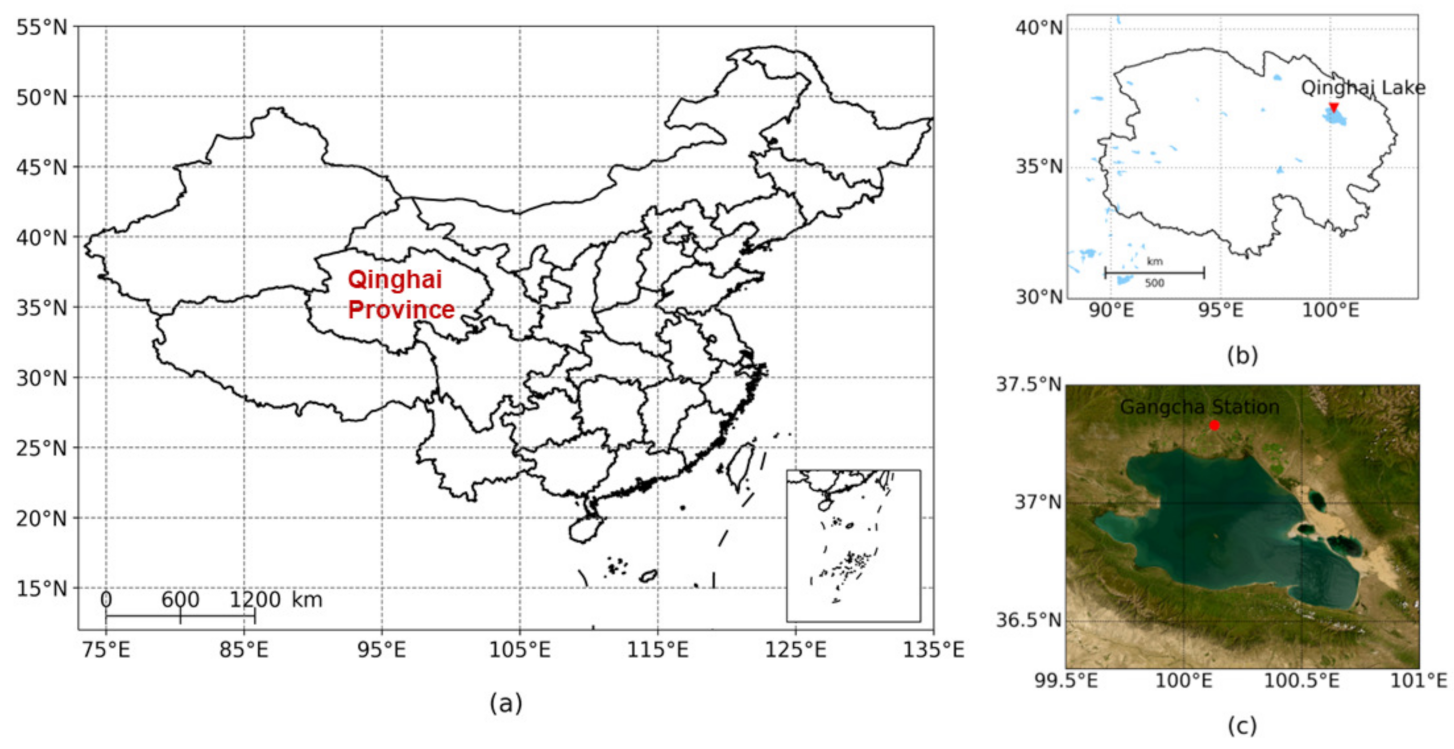{kind=link}
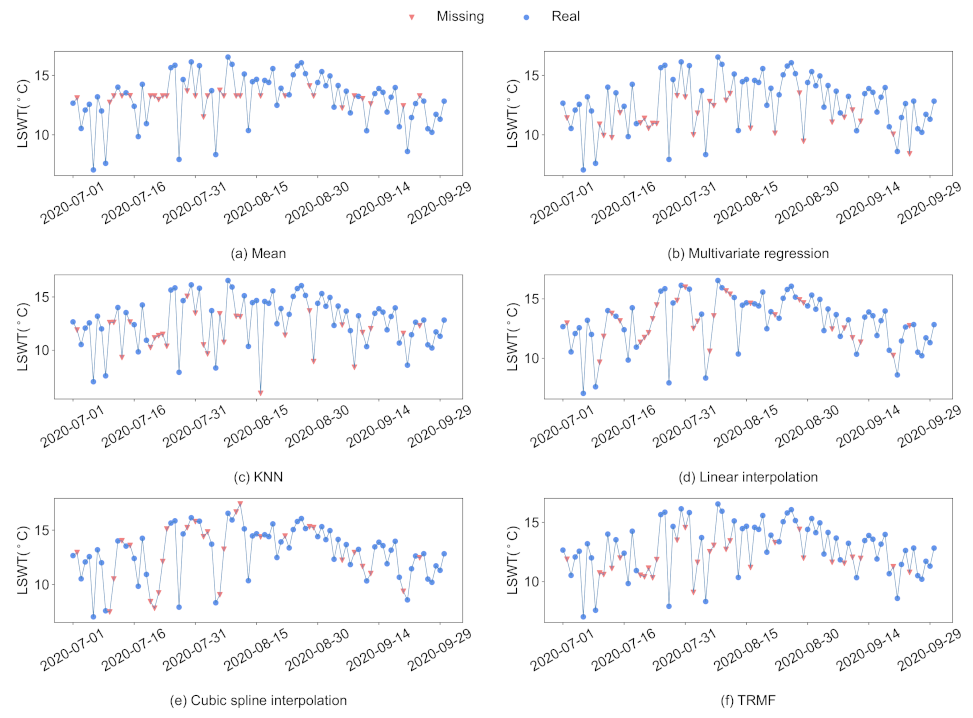{kind=link}
{kind=link}
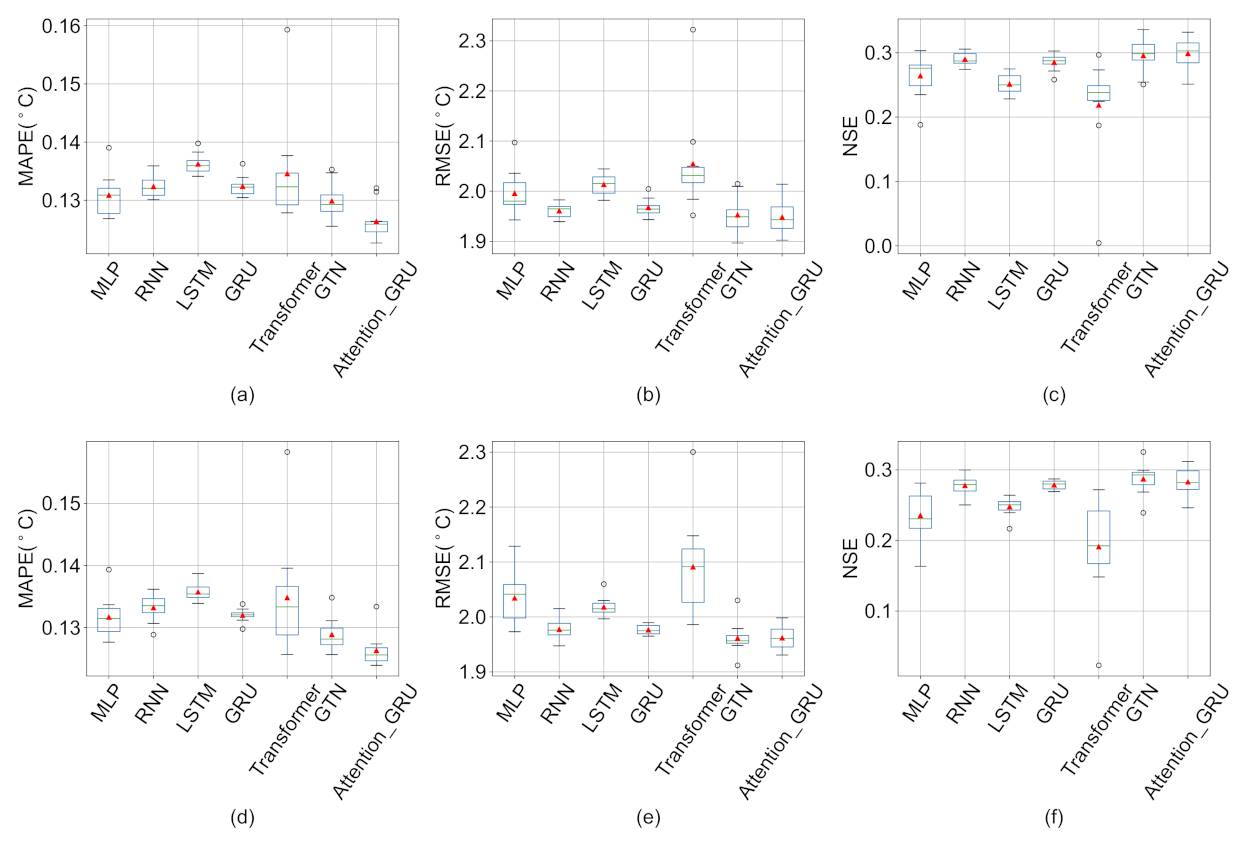{kind=link}
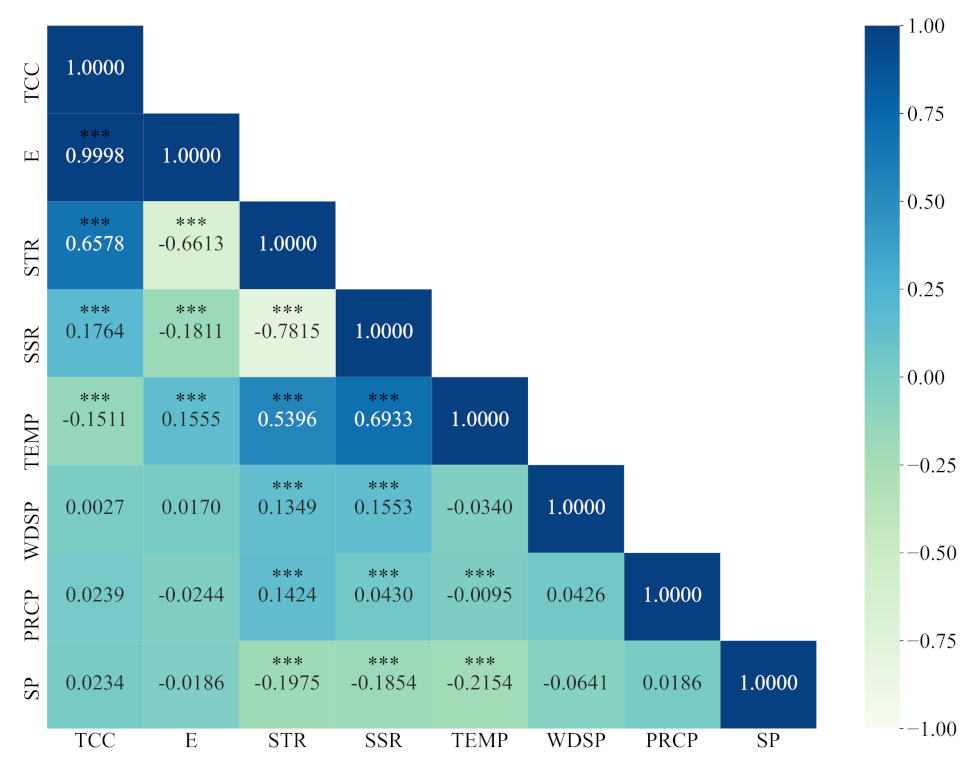{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}