1. Introduction
Remote sensing images are one of the data sources for observing the earth’s surface [
1,
2], which is helpful for obtaining rich surface information. The aim of change detection is to compare the scene differences of multiple sets of images, obtained at different times, for the same scene [
3]. Change detection has been applied in lots of fields, such as disaster monitoring [
4], land cover detection [
5], environmental detection [
6], source exploration [
7] and urban expansion [
8].
A variety of change detection approaches are mainly based on the pixel-level statistical methods [
9]. Using the independent pixels as detection units, the pixel spectral change information can be analyzed pixel by pixel. The traditional change detection methods can be categorized as the image arithmetic-based methods, the image transformation-based methods and the classification methods. The image arithmetic-based methods classify each pixel in the image directly. These methods usually use the algebraic operation-based methods to calculate the pixel values of images and classify the pixels in the difference map by setting the appropriate thresholds [
10]. Jackson et al. proposed an image regression method [
11] that calculated the index formed by the linear combination of the image in space and multiplied the target pixel point by point to obtain the changed spectrum. Todd et al. proposed an image quantitative method [
12] in which the previous moment image data were divided by the next moment image data. The low ratios indicated areas where land use and land cover had changed. Ferraris et al. proposed a method to deal with different data sources [
13], which fused optical images with different spaces and resolutions. Two images were predicted through the degradation of the fused images, and the decision rules were implemented to identify the changes. Although the image arithmetic-based methods are easy and simple, it is difficult to obtain the integral information of the images. The image transformation-based methods suppress the relevant information and highlight the changing information through statistics and the conversion of the images. The main idea is to apply the principal component analysis (PCA) [
14] method to analyze and transform the bi-temporal images. Saha et al. proposed a convolutional neural network (CNN)-based network to transform images from the different image sources to the same domain in an unsupervised manner [
15]. The change regions were detected through deep feature change vectors. Celik et al. proposed an unsupervised algorithm using the K-means clustering [
16] and PCA. The K-means clustering was utilized to obtain the mean feature vectors, the PCA was applied to extract the difference feature vectors of the difference image’s non-overlapping blocks. By calculating the minimum Euclidean distance between the mean feature vectors and the difference feature vectors, the change detection map could be achieved. The image arithmetic-based methods and the image transformation-based methods only consider the spectral information of remote sensing images, where other image features are ignored. Regarding this problem, taxonomy was proposed on the basis of the compound classification method [
17] and the post-classification comparison method [
18,
19], where the prior knowledge was required to train the classifier. The post-classification is the commonly used supervised approach. By using a classifier to classify the bi-temporal images, it can compare the obtained feature maps according to the corresponding positions and then obtain the changed areas. The post-classification method can obtain better change detection results, but the whole process is complex and they are sensitive to the classification results [
14] and depend on the performance of the classifier [
20].
In recent years, CNN has attracted extensive attention in remote sensing [
21,
22]. The deep features of images can be effectively extracted by CNN. Its ability to generalize the deep features is conducive to detecting changing areas. Liu et al. proposed LGPNet, which was based on the global and local pyramid change detection network [
23]. The global and local feature pyramid modules captured the building objects of different scales from multiple angles, which was helpful for avoiding missing building objects of different sizes and shapes. Daudt et al. proposed two fully convolutional siamese networks [
24]. FC-Siam-Conc output the results after fusing the features obtained by skip connections. Through skip connections, the decoder of the FC-Siam-Diff output the absolute value of the difference. They fused the image difference and the image stitching features during training and showed a fast speed and good performance in change detection. Peng et al. proposed the NestedUNet model [
25], where the depth monitoring module was used to catch imperceptible changes in complex scenes. Zhang et al. proposed DSIFN, which was a deep siamese supervised fusion network [
26]. In DSIFN, the deep features of dual time images were extracted by the VGG net [
27], and the change detection branch enhanced the bi-temporal image features obtained from the VGG net by using spatial and channel attention modules. Fang et al. proposed the SNUNet [
28], which was based on the NestedUNet and siamese network. A densely connected approach improved the problem of position information loss in deep networks, and a special channel attention module was applied to enhance the image features. Chen et al. proposed the double attentive siamese network (DASNet) [
29] by utilizing the attention mechanisms to obtain the long-range correlations of images. The feature representations of the change map were obtained finally. Chen et al. proposed BiT, which was a transformer-based change detection network [
30]. The transformer module was used to obtain long-range context in two-phase images. Shi et al. proposed DSAMNet, which was a deeply supervised attention metric network [
31]. A deep metric module was used to learn the changing features, and a convolutional attention module was utilized to provide the discriminative features. Hou et al. proposed HRNet, which was based on the high-resolution triplet network and used a triple-input network to learn the two-phase image features [
32]. The HRNet designed a dynamic inception module that enriched the multi-scale information of the extracted image features. We proposed a deep siamese network with contextual transformer (DSNCoT) [
33], which used a contextual transformer module to enhance the representation power of feature extractors.
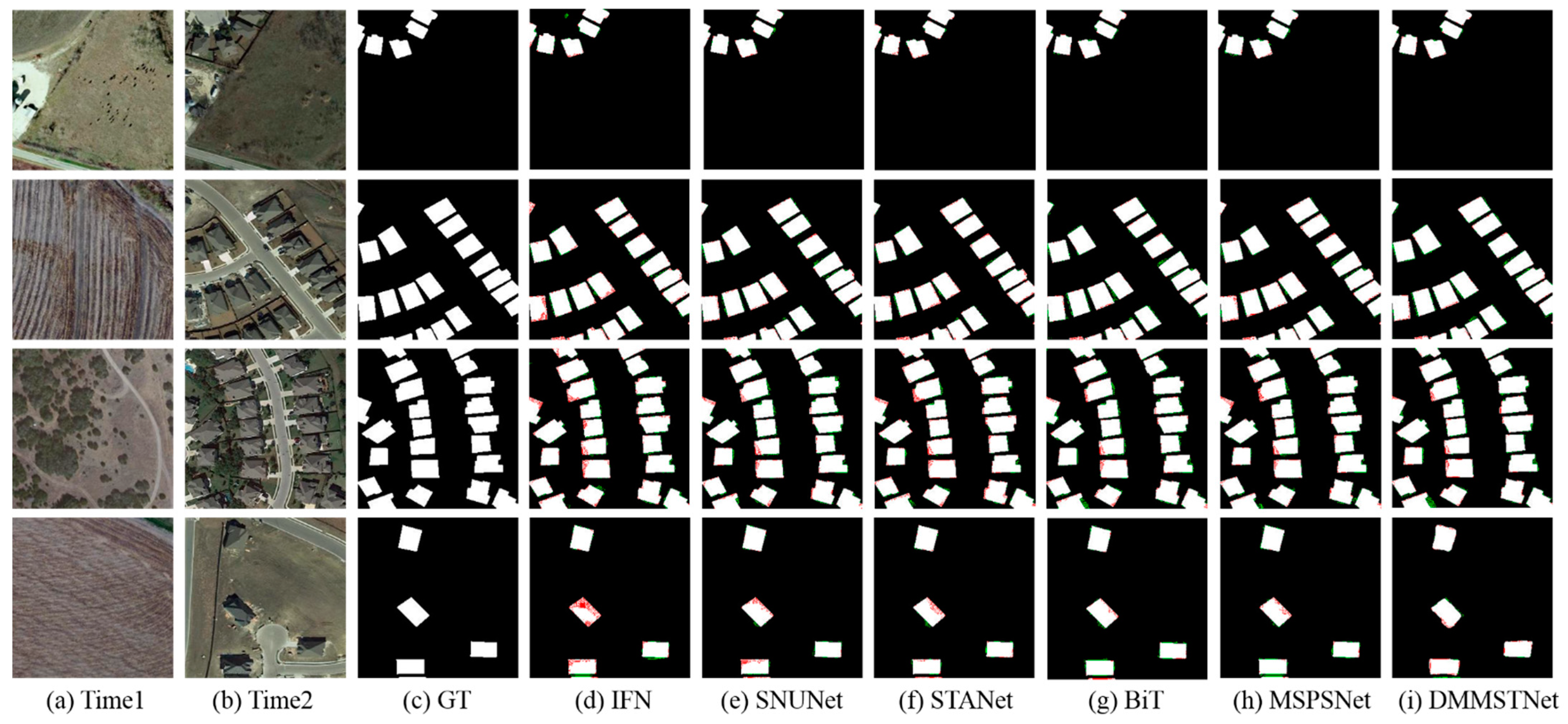
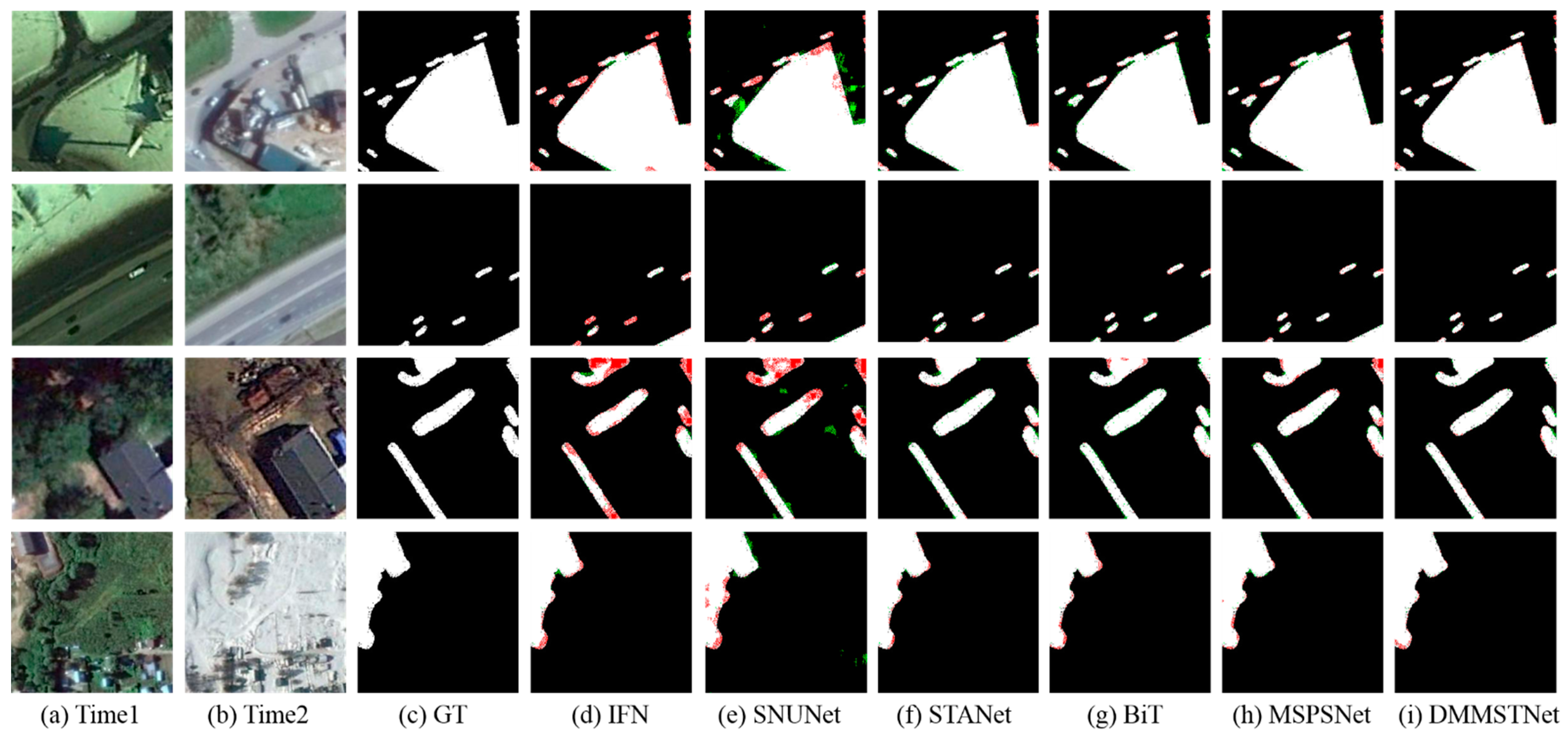
Although the deep learning-based techniques can accomplish a good performance in change detection, there are still some problems. With the advancement of imaging technology, remote sensing images have rich semantic information and high resolution. However, many algorithms underutilize the rich semantic information in high resolution images. Moreover, because of the interference of the shooting angles, climatic factors and lighting effects, it is difficult to distinguish spurious changes. The two-phase remote sensing images contain detected objects of different sizes. It is not considered how to identify objects of different sizes correctly in many change detection approaches. In addition, the two-phase optical remote sensing images include both the rich spatial information and the information interaction among the channels. Many algorithms do not make the most of the channel information and ignore the information interaction among the channels. They try to obtain the feature-represented change graphs by introducing the modules with the attention mechanisms after the feature extractor. The abilities to advance the encoder and the feature extractor are ignored.
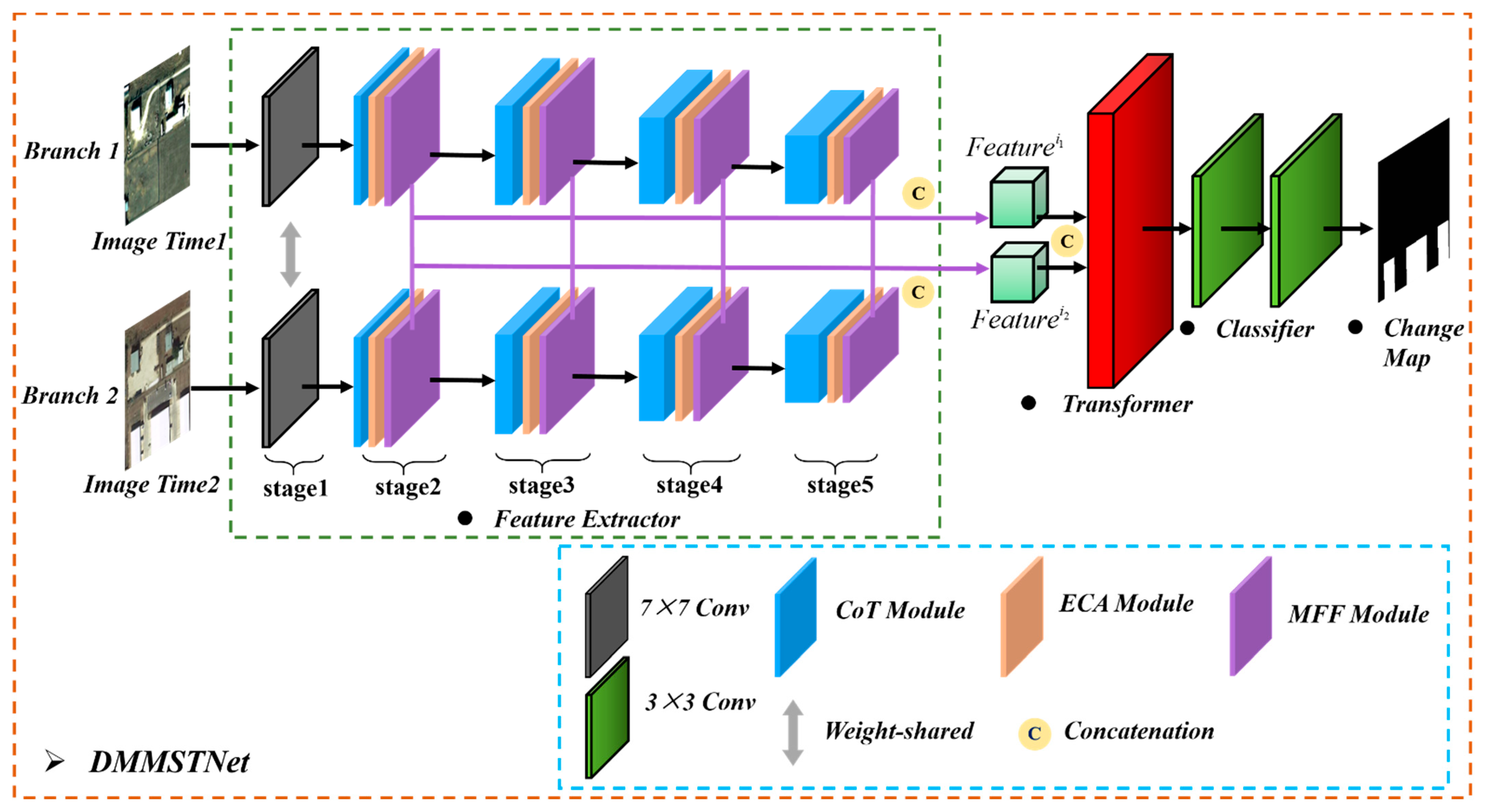
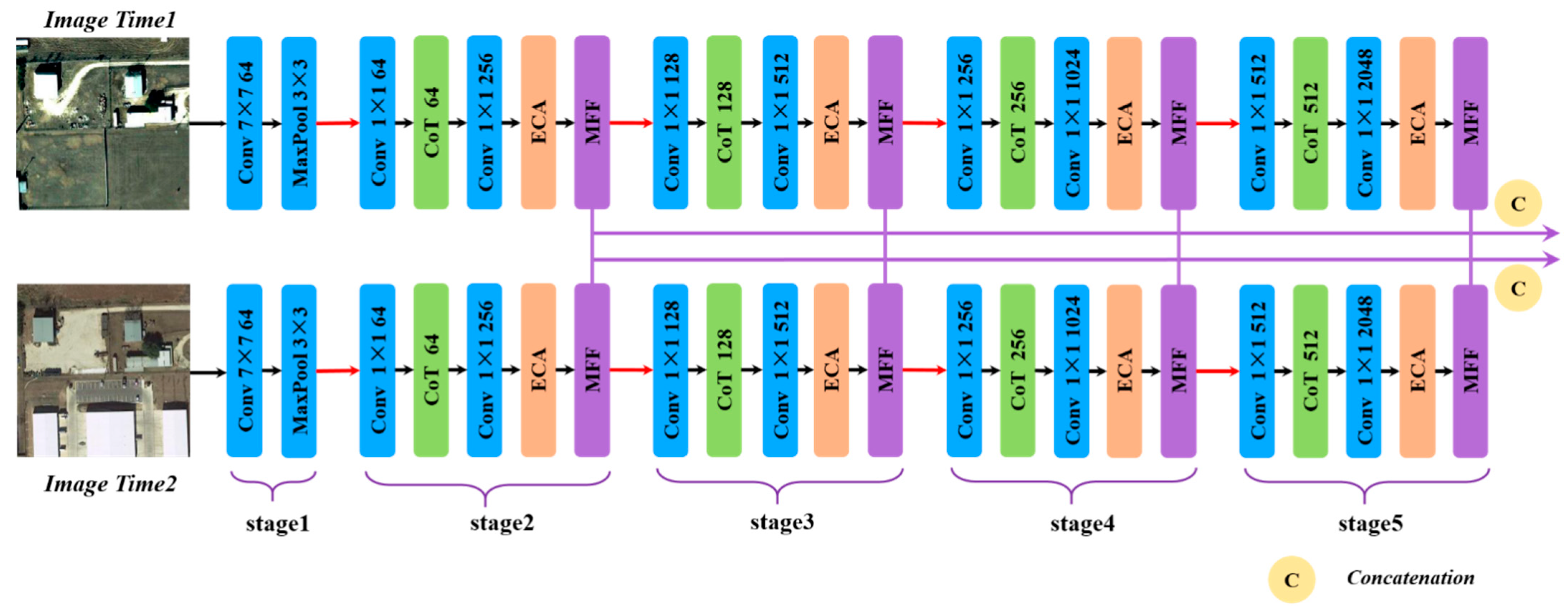
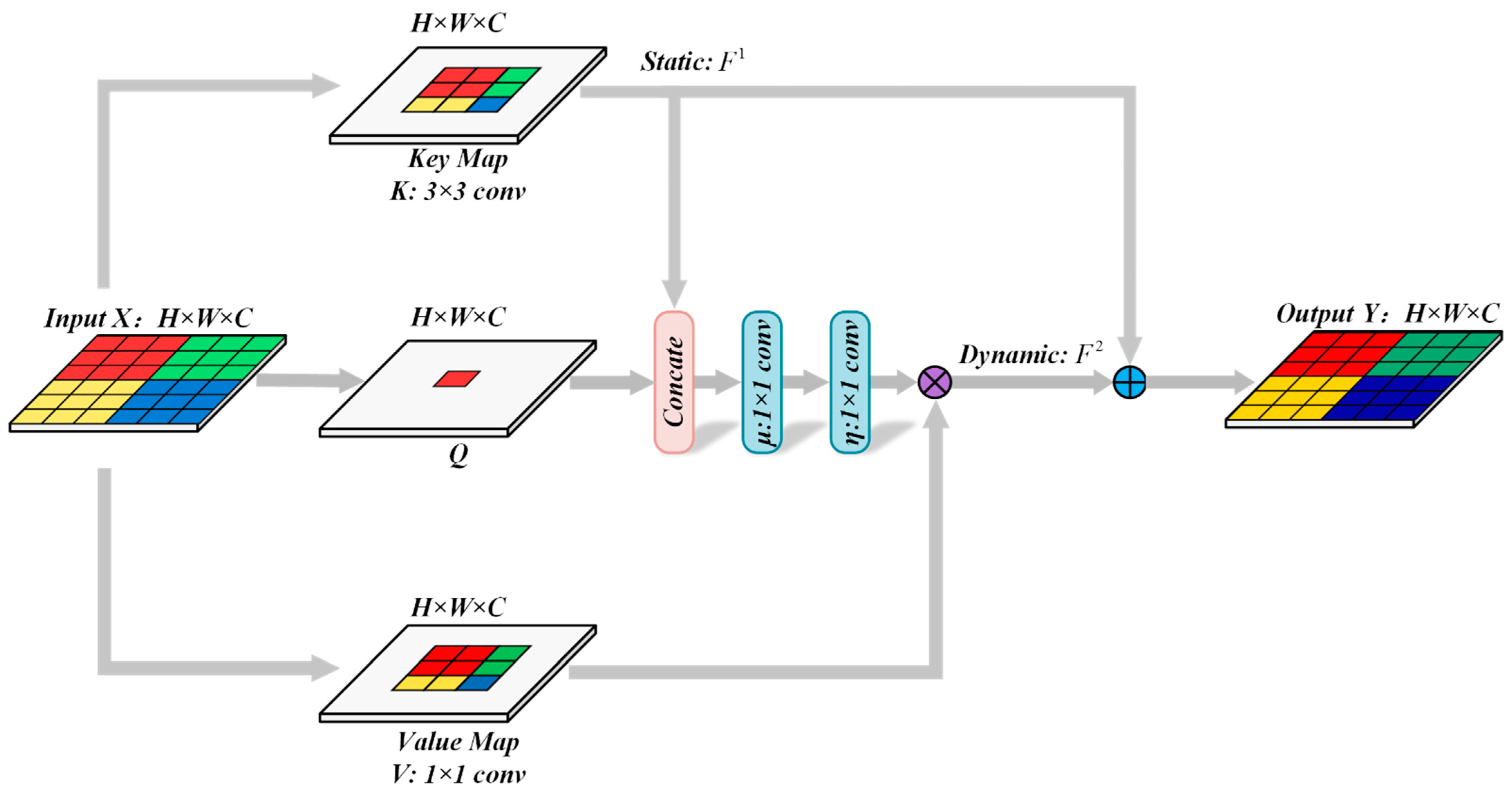
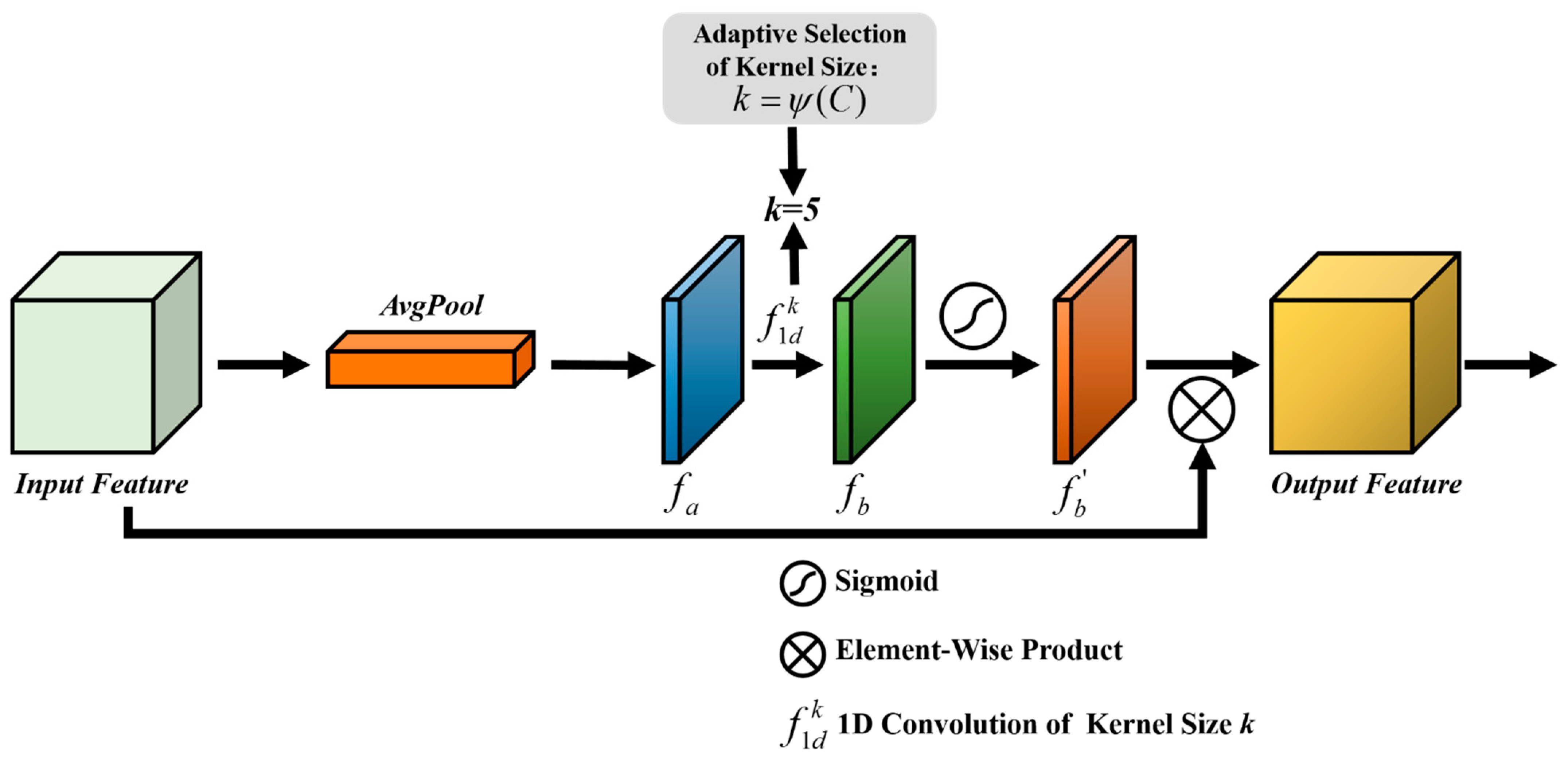
Addressing the above problems, a deep multi-scale multi-attention siamese transformer network (DMMSTNet) is proposed in this study. In the feature extractor, a special context transformer module (CoT) [
34] is present to concern the global information of the two-phase images. The CoT module combines convolution and self-attention, which can improve the spatial representation ability of the feature extractor. To make the most out of the channel information of the two-phase images, the feature extractor applies a lightly efficient channel attention module (ECA) [
35] to improve the performance. The ECA module aggregates the information interaction between the image channels through average pooling and one-dimensional convolution, which can enhance the channel representation ability of the feature extractor. Furthermore, a multi-scale fusion module (MFF) is proposed, which consists of the deformable convolutions with different sizes. These deformable convolution kernels can recognize the detected objects of different sizes. Finally, a transformer [
36] is applied to obtain the refined image features obtained by the feature extractor. The transformer module can aggregate the global information interaction of the image pixels. The transformer decoder uses the output features of the feature extractor as the query, and the output tokens of the transformer encoder is used as the key and value. The major contributions of this study can be summarized as follows:
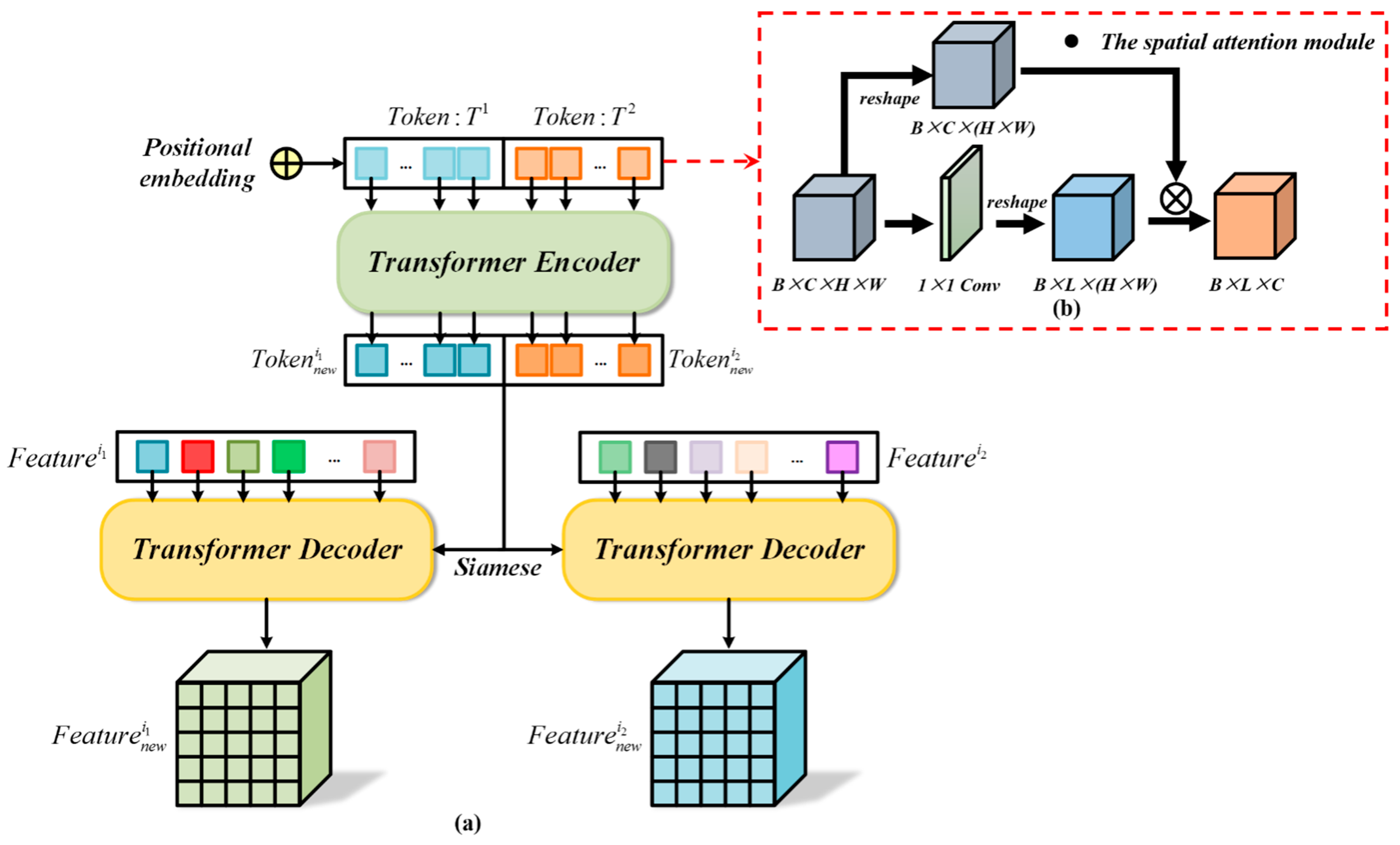
The DMMSTNet is based on the multi-scale contextual transformer and the channel attention. It takes full advantage of remote sensing images’ rich spatial, channel and semantic information. The DMMSTNet incorporates the CoT module into the siamese feature extractor to acquire rich global spatial image features. The CoT module is a hybrid module that combines the advantages of self-attention and convolution. It calculates the attention score of each pixel in a 3 × 3 grid to generate a self-attention matrix, and the gained matrix is used to multiply the input to obtain the attention relationship.
The ECA is embedded in the feature extractor to concern the information correlation among the channels in this study. The channel attention aims to establish the correlation among the different channels and acquire the significance of each channel features automatically. The important channel features can be strengthened, and the unimportant features can be suppressed. Obtaining the information correlation among the channels of images is helpful for boosting the performance of the feature extractor.
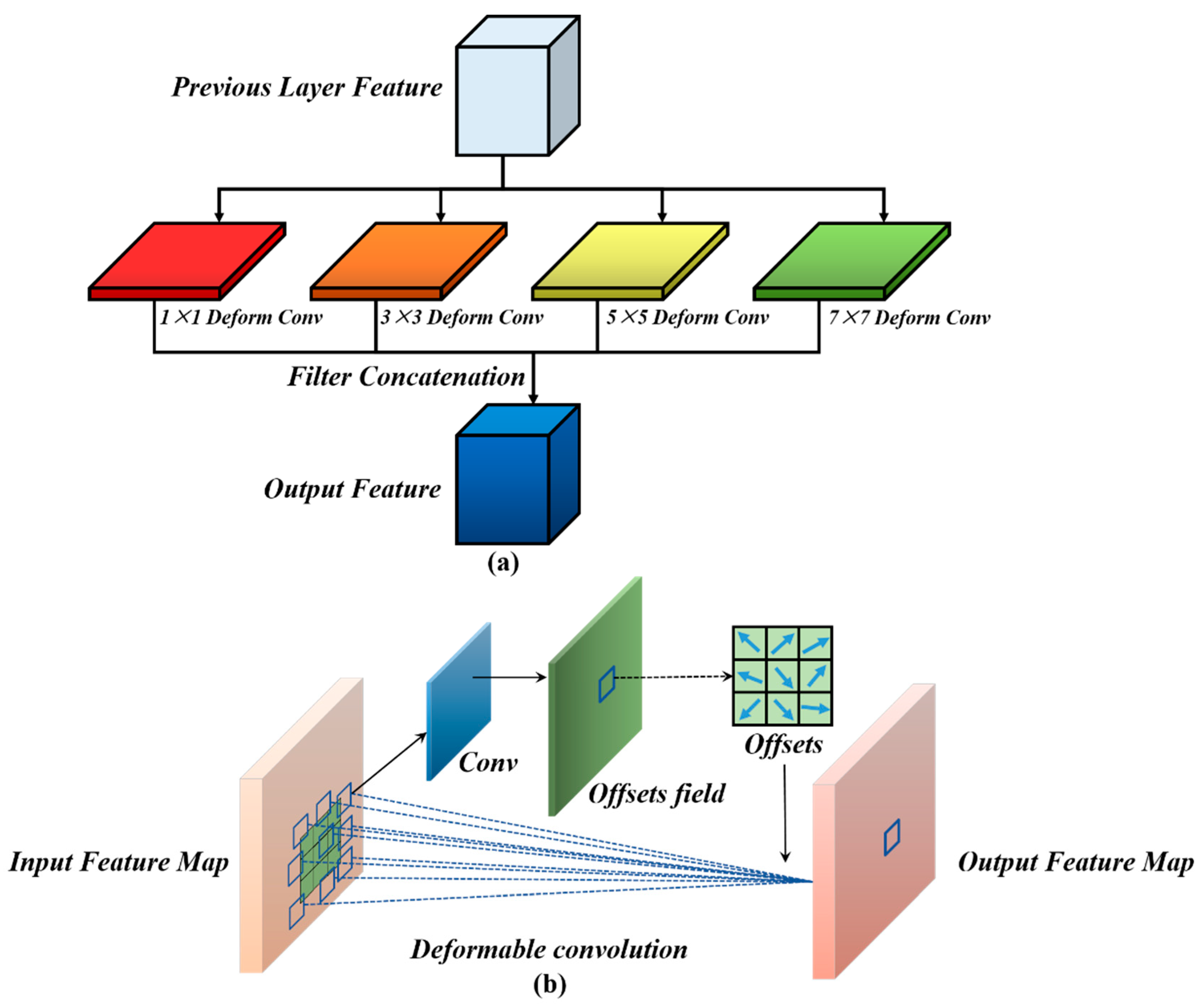
The MFF module is proposed in this study. Background objects of different sizes and shapes usually have different receptive field requirements. The semantic information of the different layers needs to be fused while identifying background objects of different sizes. The multi-scale feature representation of the images can be extracted, and the different levels of semantic information can be fused by the MFF. Then, the MFF can obtain the receptive fields of different sizes. The ground objects in remote sensing images have different sizes. The MFF module can obtain ground objects of different sizes, which shows the effectiveness of the change detection.
The rest of this study is organized as follows. The related work is introduced in
Section 2. The proposed DMMSTNet will be described in
Section 3. The experimental results will be presented and analyzed in
Section 4. The conclusion and future work is provided in
Section 5.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}