

HCFPN: Hierarchical Contextual Feature-Preserved Network for Remote Sensing Scene Classification

Abstract
:1. Introduction
- To efficiently integrate the benefits of CNN and ViT to extract both local high-level semantic features and global contextual features, an RSSC network called HCFPN is proposed. In addition, HRRS scenes can be comprehensively exploited and aggregated for the local high-level semantic features and global contextual features.
- To describe the correlations of multilevel convolutional features and merge them to generate a more discriminative representation, the global long-term contextual features of the multilevel convolutional features are captured through a multiheaded self-attention, and then the correlations between them are further explored through multiheaded cross-level attention.
- Extensive experiments are carried out on two public benchmark datasets, and the superior outcomes illustrate that our proposed HCFPN works effectively in RSSC.
2. Related Works
2.1. CNN-Based Methods for RSSC
2.2. Attention-Based Methods for RSSC
3. Proposed Method
3.1. Hierarchical Feature Extraction Module
3.2. Contextual Feature Preserved Module
3.3. Category Score Average Module
4. Experiment
4.1. Experiment Datasets
- AID is an aerial scene classification dataset released by Wuhan University, consisting of a total of 10,000 images. It contains 30 categories of scene images, of which each category has approximately 220–420 images. Furthermore, the pixel size of each image is approximately , with spatial resolution varying from approximately 0.5 m to 8 m. Figure 4 presents a sample of each class in this dataset. Figure 4 displays several samples from this dataset.
- WH-MAVS is a multi-task and multi-temporal dataset with dual phase, 2014 and 2016. It is based on Google Earth’s large-scale mosaic RGB images with the spatial size of pixels. The dataset spans 2608 km2 of the major city of Wuhan, Hubei Province, China. It comprises 23,567 labeled patch pairings with one-to-one geographical correlation between 2014 and 2016. Each patch pairing is pixels in size and has a spatial resolution of 1.2 m. The WH-MAVS comprises 14 categories, as follows: commercial, water, administration, agricultural, transportation, industrial, green space, residential 1, residential 2, residential 3, road, bare land, parking lot, and playground. The total number of samples in each category ranged from 126 to 5850, showing that the dataset has a substantial sample unbalanced issue. For RSSC, the data from the 2016 time phase are used to conduct the experiment. Figure 5 displays several samples from this dataset.
4.2. Dataset Settings and Evaluation Metrics
4.3. Experimental Settings
4.4. Experimental Results
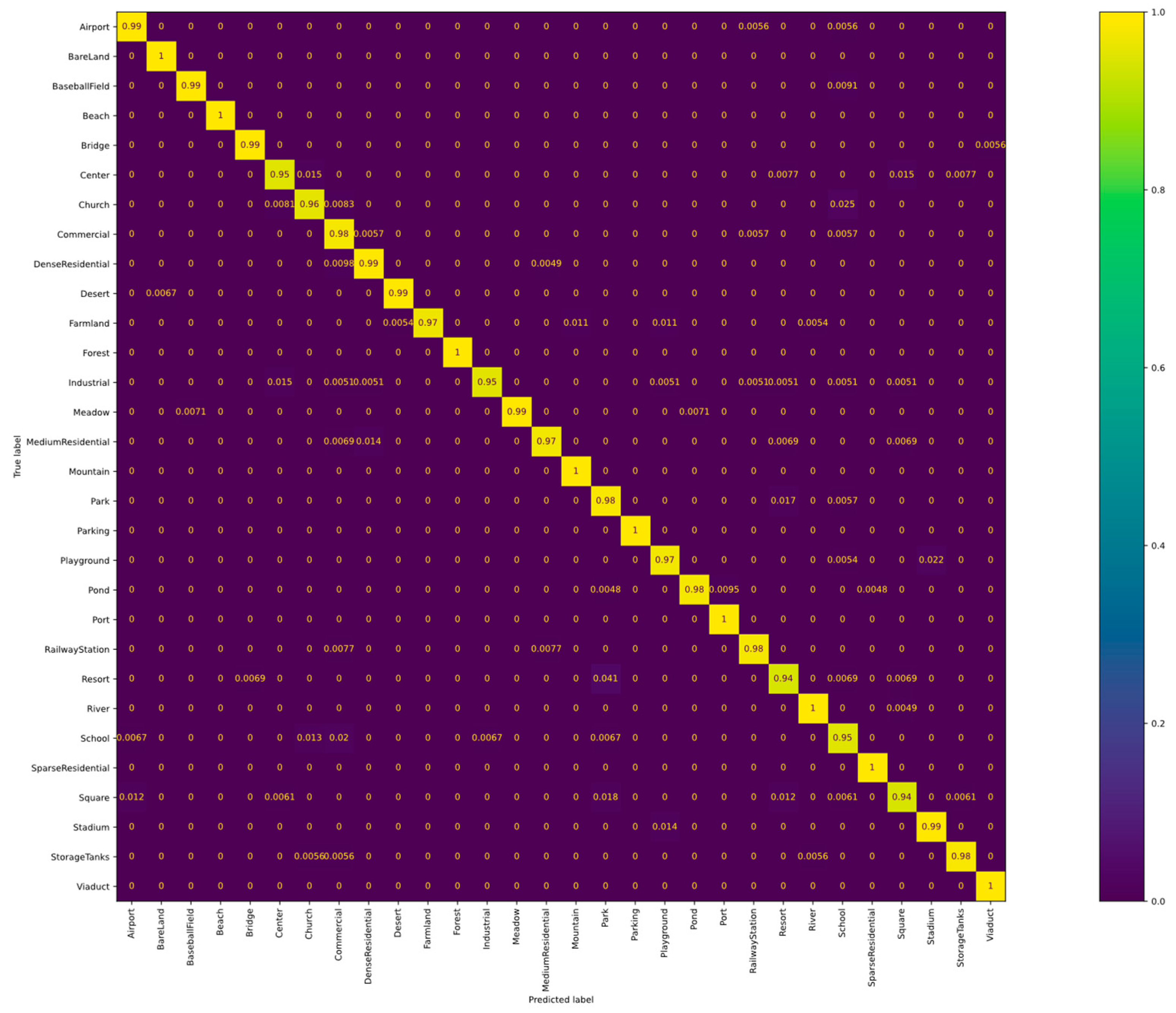
- Results on AID dataset: Comparative experiments using different advanced approaches in RSSC are conducted. The results of the comparative experiments using four proportions of training samples are displayed in Table 1 and Table 2. The proportions of the training set for comparative experiments are set to 5%, 10%, 20%, and 50%. ACNet [47], ARCNet [45], FACNN [38], and EAM [46] are utilized to compare with the proposed HCFPN. Among all the advanced approaches, the proposed HCFPN performs best in all the proportions of the training set. ACNet and ARCNet perform incredibly poorly with a few training examples. Moreover, our proposed algorithm outperforms the ACNet and ARCNet by 50.95% and 11.54%, respectively, in the case of 5% training sample ratio.Furthermore, Figure 6 shows the CM of our HCFPN on the AID dataset using 50% training samples. The classification accuracy of 21 out of the 30 categories is over 98%. These encouraging outcomes are yet another demonstration of the potency of our proposed approach.
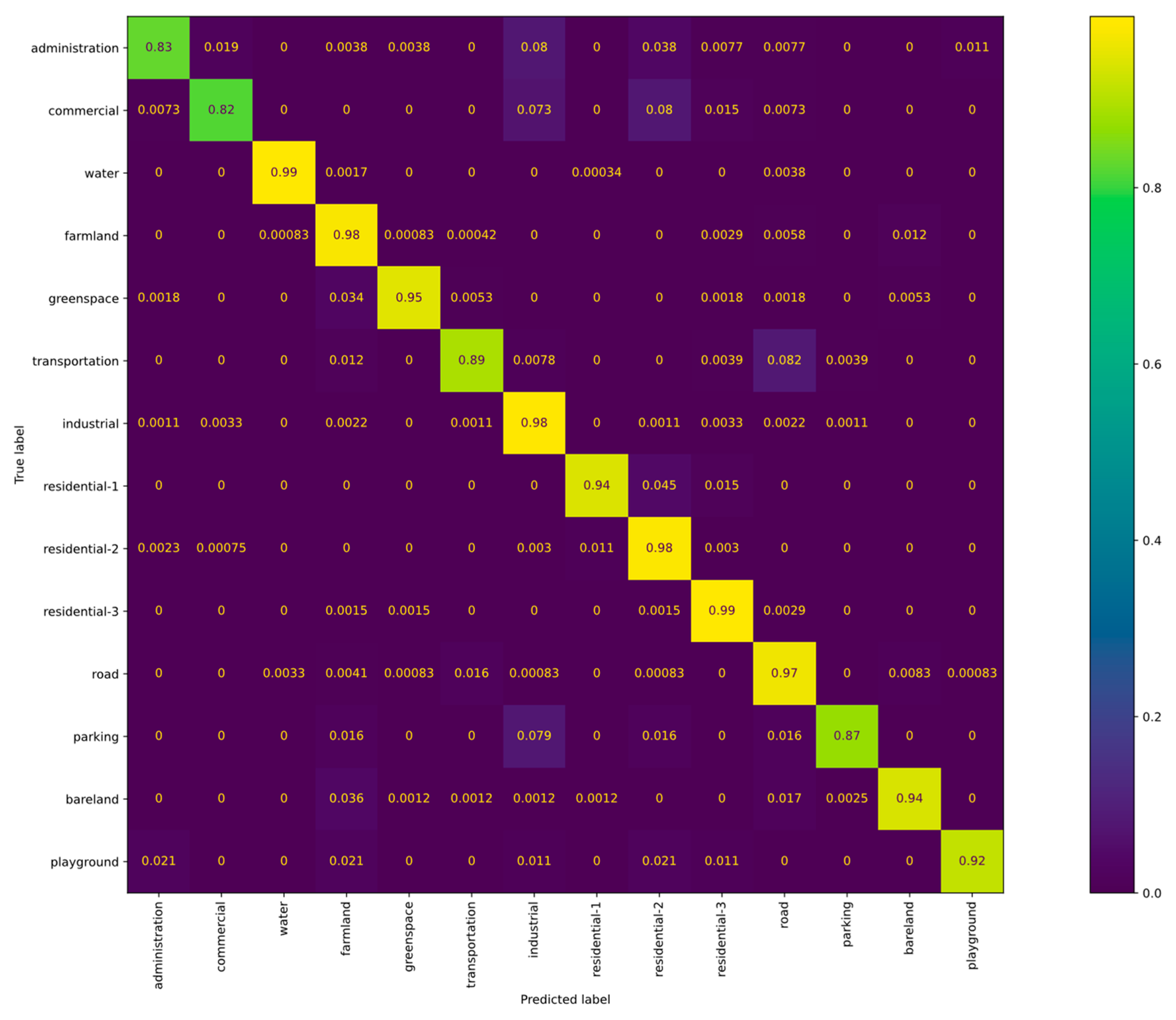
- WH-MAVS dataset: Comparative experiments using different advanced approaches in RSSC are conducted. The results of the comparative experiments using four proportions of training samples are displayed in Table 3 and Table 4. The proportions of the training set for comparative experiments are set to 5%, 10%, 20%, and 50%. ACNet [47], ARCNet [45], FACNN [38], and EAM [46] are utilized to compare with the proposed HCFPN. Among all the advanced approaches, our HCFPN still outperforms other comparison methods, but the performance improvement of our proposed HCFPN is limited relative to the second-best method. When the proportion of the training samples is less than 5%, the accuracy of our HCFPN is still significantly higher than that of the ACNet and ARCNet by 6.75% and 3.28%, respectively.
4.5. Ablation Study
4.6. Computational and Time Complexity Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, L.; Zhang, L. Artificial intelligence for remote sensing data analysis: A review of challenges and opportunities. IEEE Geosci. Remote Sens. Mag. 2022, 10, 270–294. [Google Scholar] [CrossRef]
- Tong, X.-Y.; Xia, G.-S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef] [Green Version]
- Mei, S.; Chen, X.; Zhang, Y.; Li, J.; Plaza, A. Accelerating convolutional neural network-based hyperspectral image classification by step activation quantization. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–12. [Google Scholar] [CrossRef]
- Yao, X.; Han, J.; Cheng, G.; Qian, X.; Guo, L. Semantic annotation of high-resolution satellite images via weakly supervised learning. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3660–3671. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Gamba, P. Human settlements: A global challenge for EO data processing and interpretation. Proc. IEEE Inst. Electr. Electron. Eng. 2012, 101, 570–581. [Google Scholar] [CrossRef]
- Li, D.; Wang, M.; Dong, Z.; Shen, X.; Shi, L. Earth observation brain (EOB): An intelligent earth observation system. Geo Spat. Inf. Sci. 2017, 20, 134–140. [Google Scholar] [CrossRef] [Green Version]
- Sheng, G.; Yang, W.; Xu, T.; Sun, H. High-resolution satellite scene classification using a sparse coding based multiple feature combination. Int. J. Remote Sens. 2012, 33, 2395–2412. [Google Scholar] [CrossRef]
- Tang, X.; Jiao, L.; Emery, W.J.; Liu, F.; Zhang, D. Two-stage reranking for remote sensing image retrieval. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5798–5817. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhong, Y.; Zhang, L.; Li, D. Scene classification based on the fully sparse semantic topic model. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5525–5538. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhong, Y.; Zhang, L.; Li, D. Adaptive deep sparse semantic modeling framework for high spatial resolution image scene classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6180–6195. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhong, Y.; Wu, S.; Zhang, L.; Li, D. Scene classification based on the sparse homogeneous–heterogeneous topic feature model. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2689–2703. [Google Scholar] [CrossRef]
- Sun, H.; Li, S.; Zheng, X.; Lu, X. Remote sensing scene classification by gated bidirectional network. IEEE Trans. Geosci. Remote Sens. 2019, 58, 82–96. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Comparing SIFT descriptors and Gabor texture features for classification of remote sensed imagery. In Proceedings of the 2008 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 1852–1855. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Bhagavathy, S.; Manjunath, B.S. Modeling and detection of geospatial objects using texture motifs. IEEE Trans. Geosci. Remote Sens. 2006, 44, 3706–3715. [Google Scholar] [CrossRef]
- Liu, C.; Ma, J.; Tang, X.; Liu, F.; Zhang, X.; Jiao, L. Deep hash learning for remote sensing image retrieval. IEEE Trans. Geosci. Remote Sens. 2020, 59, 3420–3443. [Google Scholar] [CrossRef]
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G.-S. Remote sensing image scene classification meets deep learning: Challenges, methods, benchmarks, and opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Li, M.; Lei, L.; Sun, Y.; Li, X.; Kuang, G. A cross-layer nonlocal network for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Cheng, G.; Sun, X.; Li, K.; Guo, L.; Han, J. Perturbation-seeking generative adversarial networks: A defense framework for remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–11. [Google Scholar] [CrossRef]
- Tang, X.; Yang, Y.; Ma, J.; Cheung, Y.-M.; Liu, C.; Liu, F.; Zhang, X.; Jiao, L. Meta-hashing for remote sensing image retrieval. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–19. [Google Scholar] [CrossRef]
- Tang, X.; Lin, W.; Ma, J.; Zhang, X.; Liu, F.; Jiao, L. Class-Level Prototype Guided Multiscale Feature Learning for Remote Sensing Scene Classification With Limited Labels. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ding, Y.; Zhao, X.; Zhang, Z.; Cai, W.; Yang, N.; Zhan, Y. Semi-supervised locality preserving dense graph neural network with ARMA filters and context-aware learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–12. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Z.; Zhao, X.; Cai, W.; Yang, N.; Hu, H.; Huang, X.; Cao, Y.; Cai, W. Unsupervised self-correlated learning smoothy enhanced locality preserving graph convolution embedding clustering for hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Z.; Zhao, X.; Cai, Y.; Li, S.; Deng, B.; Cai, W. Self-supervised locality preserving low-pass graph convolutional embedding for large-scale hyperspectral image clustering. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Z.; Zhao, X.; Hong, D.; Li, W.; Cai, W.; Zhan, Y. AF2GNN: Graph convolution with adaptive filters and aggregator fusion for hyperspectral image classification. Inf. Sci. 2022, 602, 201–219. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Z.; Zhao, X.; Hong, D.; Cai, W.; Yu, C.; Yang, N.; Cai, W. Multi-feature fusion: Graph neural network and CNN combining for hyperspectral image classification. Neurocomputing 2022, 501, 246–257. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Ma, J.; Li, M.; Tang, X.; Zhang, X.; Liu, F.; Jiao, L. Homo–Heterogenous Transformer Learning Framework for RS Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 2223–2239. [Google Scholar] [CrossRef]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision transformers for remote sensing image classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Deng, P.; Xu, K.; Huang, H. When CNNs meet vision transformer: A joint framework for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Xu, K.; Deng, P.; Huang, H. Vision transformer: An excellent teacher for guiding small networks in remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Li, W.; Wang, Z.; Wang, Y.; Wu, J.; Wang, J.; Jia, Y.; Gui, G. Classification of high-spatial-resolution remote sensing scenes method using transfer learning and deep convolutional neural network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1986–1995. [Google Scholar] [CrossRef]
- Zhang, Y.; Zheng, X.; Yuan, Y.; Lu, X. Attribute-cooperated convolutional neural network for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8358–8371. [Google Scholar] [CrossRef]
- Lu, X.; Sun, H.; Zheng, X. A feature aggregation convolutional neural network for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7894–7906. [Google Scholar] [CrossRef]
- Wang, G.; Fan, B.; Xiang, S.; Pan, C. Aggregating rich hierarchical features for scene classification in remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4104–4115. [Google Scholar] [CrossRef]
- Zheng, Z.; Zheng, L.; Yang, Y. A discriminatively learned cnn embedding for person reidentification. ACM Trans. Multimedia Comput. Commun. Appl. 2017, 14, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Gong, Z.; Zhong, P.; Yu, Y.; Hu, W. Diversity-promoting deep structural metric learning for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 56, 371–390. [Google Scholar] [CrossRef]
- Liu, X.; Zhou, Y.; Zhao, J.; Yao, R.; Liu, B.; Zheng, Y. Siamese convolutional neural networks for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1200–1204. [Google Scholar] [CrossRef]
- Han, W.; Wang, L.; Feng, R.; Gao, L.; Chen, X.; Deng, Z.; Chen, J.; Liu, P. Sample generation based on a supervised Wasserstein Generative Adversarial Network for high-resolution remote-sensing scene classification. Inf. Sci. 2020, 539, 177–194. [Google Scholar] [CrossRef]
- Ma, A.; Yu, N.; Zheng, Z.; Zhong, Y.; Zhang, L. A Supervised Progressive Growing Generative Adversarial Network for Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1155–1167. [Google Scholar] [CrossRef]
- Zhao, Z.; Li, J.; Luo, Z.; Li, J.; Chen, C. Remote sensing image scene classification based on an enhanced attention module. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1926–1930. [Google Scholar] [CrossRef]
- Tang, X.; Ma, Q.; Zhang, X.; Liu, F.; Ma, J.; Jiao, L. Attention consistent network for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2030–2045. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Sun, Z.; Cao, S.; Yang, Y.; Kitani, K.M. Rethinking transformer-based set prediction for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3611–3620. [Google Scholar]
- Lv, P.; Wu, W.; Zhong, Y.; Du, F.; Zhang, L. SCViT: A Spatial-Channel Feature Preserving Vision Transformer for Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Tan, X.; Xiao, Z.; Zhu, J.; Wan, Q.; Wang, K.; Li, D. Transformer-Driven Semantic Relation Inference for Multilabel Classification of High-Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1884–1901. [Google Scholar] [CrossRef]
- Wang, Q.; Huang, W.; Xiong, Z.; Li, X. Looking closer at the scene: Multiscale representation learning for remote sensing image scene classification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 33, 1414–1428. [Google Scholar] [CrossRef]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Xia, G.-S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Yuan, J.; Ru, L.; Wang, S.; Wu, C. WH-MAVS: A Novel Dataset and Deep Learning Benchmark for Multiple Land Use and Land Cover Applications. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1575–1590. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| OA (%) | ||
|---|---|---|
| Methods | Training with 5% Samples | Training with 10% Samples |
| ACNet [47] | 31.68 ± 6.75 | 55.80 ± 4.98 |
| ARCNet [45] | 71.09 ± 0.70 | 79.34 ± 1.02 |
| FACNN [38] | 82.00 ± 0.16 | 87.21 ± 0.32 |
| EAM [46] | 81.28 ± 1.49 | 88.17 ± 0.41 |
| HCFPN (Ours) | 82.63 ± 0.93 | 89.16 ± 0.56 |
| OA (%) | ||
|---|---|---|
| Methods | Training with 20% Samples | Training with 50% Samples |
| ACNet [47] | 79.40 ± 0.56 | 89.03 ± 0.27 |
| ARCNet [45] | 87.31 ± 0.78 | 91.92 ± 0.84 |
| FACNN [38] | 91.56 ± 0.20 | 94.60 ± 0.33 |
| EAM [46] | 92.24 ± 0.32 | 95.25 ± 0.40 |
| HCFPN (Ours) | 93.04 ±0.20 | 96.02 ±0.24 |
| OA (%) | ||
|---|---|---|
| Methods | Training with 5% Samples | Training with 10% Samples |
| ACNet [47] | 83.45 ± 0.75 | 86.05 ± 0.78 |
| ARCNet [45] | 86.92 ± 0.25 | 90.39 ± 0.29 |
| FACNN [38] | 89.90 ± 0.29 | 91.42 ± 0.40 |
| EAM [46] | 90.17 ± 0.30 | 92.22 ± 0.13 |
| HCFPN (Ours) | 90.20 ± 0.07 | 92.33 ± 0.17 |
| OA (%) | ||
|---|---|---|
| Methods | Training with 20% Samples | Training with 50% Samples |
| ACNet [47] | 90.40 ± 0.20 | 91.20 ± 0.74 |
| ARCNet [45] | 91.91 ± 1.32 | 94.28 ± 0.11 |
| FACNN [38] | 93.04 ± 0.14 | 94.24 ± 0.09 |
| EAM [46] | 93.50 ± 0.18 | 94.56 ± 0.42 |
| HCFPN (Ours) | 93.57 ± 0.21 | 94.60 ± 0.03 |
| ResNet34 | Contextual Feature Preserved Module | Label Smoothing | OA (%) | |
|---|---|---|---|---|
| 1 | ✓ | 91.02 ± 0.15 | ||
| 2 | ✓ | ✓ | 91.37 ± 0.18 | |
| 3 | ✓ | ✓ | 92.04 ± 0.19 | |
| 4 | ✓ | ✓ | ✓ | 92.33 ± 0.17 |
| ACNet | ARCNet | FACNN | EAM | HCFPN | |
|---|---|---|---|---|---|
| FLOPs |
| ACNet | ARCNet | FACNN | EAM | HCFPN | |
|---|---|---|---|---|---|
| AID | 1.167 | 0.545 | 0.554 | 0.601 | 1.091 |
| WH-MAVS | 0.499 | 0.207 | 0.220 | 0.284 | 0.385 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, J.; Wang, S. HCFPN: Hierarchical Contextual Feature-Preserved Network for Remote Sensing Scene Classification. Remote Sens. 2023, 15, 810. https://doi.org/10.3390/rs15030810
Yuan J, Wang S. HCFPN: Hierarchical Contextual Feature-Preserved Network for Remote Sensing Scene Classification. Remote Sensing. 2023; 15(3):810. https://doi.org/10.3390/rs15030810
Chicago/Turabian StyleYuan, Jingwen, and Shugen Wang. 2023. "HCFPN: Hierarchical Contextual Feature-Preserved Network for Remote Sensing Scene Classification" Remote Sensing 15, no. 3: 810. https://doi.org/10.3390/rs15030810