

Motorcycle Detection and Collision Warning Using Monocular Images from a Vehicle


Abstract
:1. Introduction
- The exploitation of state-of-the-art deep learning methods for detecting and estimating the range of motorcycles from remote sensing data;
- The use of different data augmentation techniques, such as rotation, changing light, color space augmentation, mosaic images, and horizontal flip data augmentation, to improve performance in terms of motorcycle detection;
- The examination of the performance of eight variations of the YOLO algorithms for object detection in images acquired from a car;
- The proposal of the MD-TinyYOLOv4 algorithm, which uses data augmentation, K-means++ clustering to optimize anchor box predictions, training with the Mish activation function instead of current functions such as ReLU or Leaky-ReLU and the addition of a dense SPP (Spatial Pyramid Pooling) network to accurately extract more features for the better detection of motorcycles near cars;
- The evaluation of the performances of Monodepth1 and Monodepth2 using our dataset and refinement using a joint bilateral filter to generate a disparity map with better visual quality and range value estimation;
- The provision of sufficient visualization results in classifying the condition of a motorcycle in the image as a dangerous or normal situation.
2. Materials and Methods
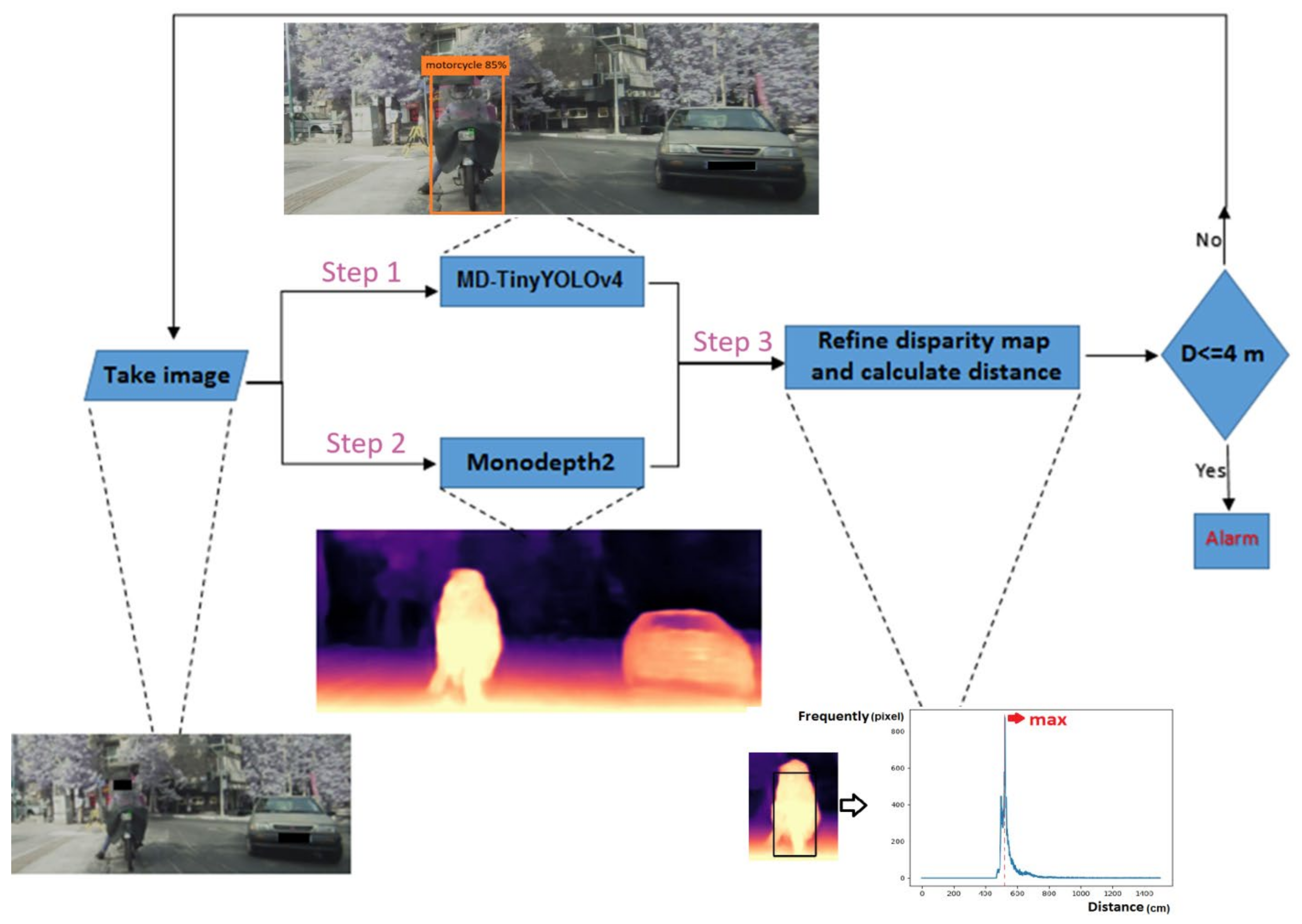
2.1. Motorcycle Detection with MD-TinyYOLOv4
2.2. Monodepth for Depth Estimation
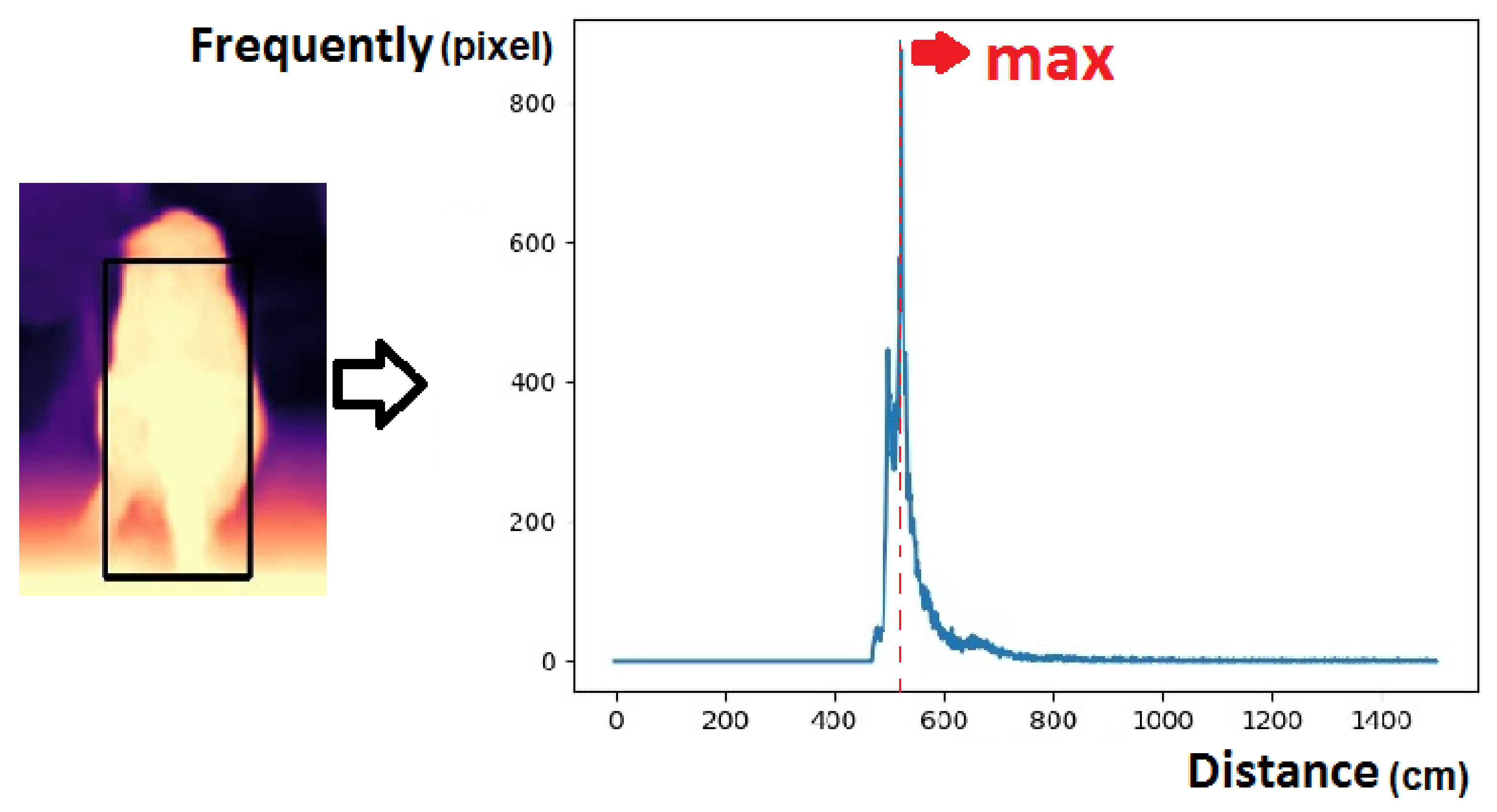
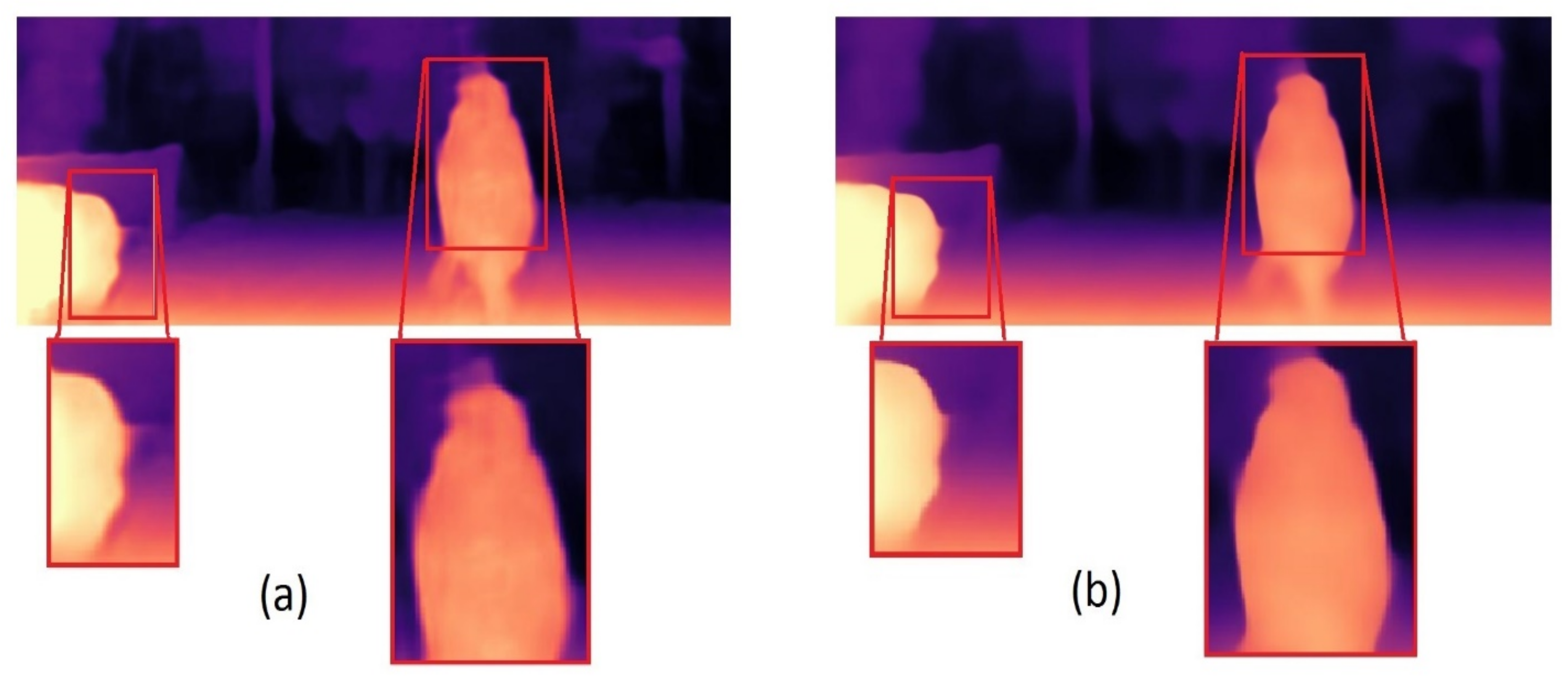
2.3. Disparity Map Refinement
2.4. Combining Bounding Boxes and Disparity Maps
2.5. Proposed Dataset
2.5.1. Dataset for Motorcycle Detection
2.5.2. Dataset for Motorcycle Range Estimation
3. Results
3.1. Evaluation Parameters
3.2. Evaluation Results
3.2.1. Proposed MD-TinyYOLOv4
3.2.2. Disparity and Depth Map Extracting
3.2.3. Evaluating the Proposed Algorithm at Different Distances and Conditions
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Markiewicz, P.; Długosz, M.; Skruch, P. Review of tracking and object detection systems for advanced driver assistance and autonomous driving applications with focus on vulnerable road users sensing. In Proceedings of the Polish Control Conference, Kraków, Poland, 18–21 June 2017; Springer: Cham, Switzerland, 2017; pp. 224–237. [Google Scholar]
- Pineda-Deom, D. Motorcycle Blind Spot Detection System and Rear Collision Alert Using Mechanically Aligned Radar. U.S. Patent 10,429,501, 1 October 2019. [Google Scholar]
- Anaya, J.J.; Ponz, A.; García, F.; Talavera, E. Motorcycle detection for ADAS through camera and V2V Communication, a comparative analysis of two modern technologies. Expert Syst. Appl. 2017, 77, 148–159. [Google Scholar] [CrossRef]
- De Raeve, N.; De Schepper, M.; Verhaevert, J.; Van Torre, P.; Rogier, H. A bluetooth-low-energy-based detection and warning system for vulnerable road users in the blind spot of vehicles. Sensors 2020, 20, 2727. [Google Scholar] [CrossRef] [PubMed]
- Gruyer, D.; Rahal, M.-C. Multi-Layer Laser Scanner Strategy for Obstacle Detection and Tracking. In Proceedings of the 2019 IEEE/ACS 16th International Conference on Computer Systems and Applications (AICCSA), Abu Dhabi, United Arab Emirates, 3–7 November 2019; IEEE: Piscataway, NJ, USA; pp. 1–8. [Google Scholar]
- Gong, D.-W.; Dai, X.; Chen, Y.; Wang, S.-F. Single-layer Laser Scanner-based Approach for a Transportation Participants Recognition Task. Lasers Eng. 2019, 43, 10–12. [Google Scholar]
- Kim, J.B. Efficient vehicle detection and distance estimation based on aggregated channel features and inverse perspective mapping from a single camera. Symmetry 2019, 11, 1205. [Google Scholar] [CrossRef]
- Haseeb, M.A.; Guan, J.; Ristic-Durrant, D.; Gräser, A. Disnet: A novel method for distance estimation from monocular camera. In Proceedings of the 10th Planning, Perception and Navigation for Intelligent Vehicles (PPNIV18), Madrid, Spain, 1 October 2018. [Google Scholar]
- Vajgl, M.; Hurtik, P.; Nejezchleba, T. Dist-YOLO: Fast Object Detection with Distance Estimation. Appl. Sci. 2022, 12, 1354. [Google Scholar] [CrossRef]
- Vishnu, C.; Singh, D.; Mohan, C.K.; Babu, S. Detection of motorcyclists without helmet in videos using convolutional neural network. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; IEEE: Piscataway, NJ, USA; pp. 3036–3041. [Google Scholar]
- Siebert, F.W.; Lin, H. Detecting motorcycle helmet use with deep learning. Accid. Anal. Prev. 2020, 134, 105319. [Google Scholar] [CrossRef]
- Sanchana, M.A.; Eliyas, S. Automated Motorcycle Helmet Detection Using The Combination of YOLO AND CNN. In Proceedings of the 2023 3rd International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 12–13 May 2023; IEEE: Piscataway, NJ, USA; pp. 75–77. [Google Scholar]
- Sridhar, P.; Jagadeeswari, M.; Sri, S.H.; Akshaya, N.; Haritha, J. Helmet violation detection using YOLO v2 deep learning framework. In Proceedings of the 2022 6th International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 28–30 April 2022; IEEE: Piscataway, NJ, USA; pp. 1207–1212. [Google Scholar]
- Mistry, J.; Misraa, A.K.; Agarwal, M.; Vyas, A.; Chudasama, V.M.; Upla, K.P. An automatic detection of helmeted and non-helmeted motorcyclist with license plate extraction using convolutional neural network. In Proceedings of the 2017 Seventh International Conference on Image Processing Theory, Tools and Applications (IPTA), Montreal, QC, Canada, 28 November–1 December 2017; IEEE: Piscataway, NJ, USA; pp. 1–6. [Google Scholar]
- Laroca, R.; Severo, E.; Zanlorensi, L.A.; Oliveira, L.S.; Gonçalves, G.R.; Schwartz, W.R.; Menotti, D. A robust real-time automatic license plate recognition based on the YOLO detector. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; IEEE: Piscataway, NJ, USA; pp. 1–10. [Google Scholar]
- Rao, Y.A.; Kumar, S.; Amaresh, H.; Chirag, H. Real-time speed estimation of vehicles from uncalibrated view-independent traffic cameras. In Proceedings of the TENCON 2015—2015 IEEE Region 10 Conference, Macao, China, 1–4 November 2015; IEEE: Piscataway, NJ, USA; pp. 1–6. [Google Scholar]
- Luvizon, D.C.; Nassu, B.T.; Minetto, R. A video-based system for vehicle speed measurement in urban roadways. IEEE Trans. Intell. Transp. Syst. 2016, 18, 1393–1404. [Google Scholar] [CrossRef]
- Chang, I.-C.; Yen, C.-E.; Song, Y.-J.; Chen, W.-R.; Kuo, X.-M.; Liao, P.-H.; Kuo, C.; Huang, Y.-F. An Effective YOLO-Based Proactive Blind Spot Warning System for Motorcycles. Electronics 2023, 12, 3310. [Google Scholar] [CrossRef]
- Strbac, B.; Gostovic, M.; Lukac, Z.; Samardzija, D. YOLO multi-camera object detection and distance estimation. In Proceedings of the 2020 Zooming Innovation in Consumer Technologies Conference (ZINC), Novi Sad, Serbia, 26–27 May 2020; IEEE: Piscataway, NJ, USA; pp. 26–30. [Google Scholar]
- Espinosa, J.E.; Velastin, S.A.; Branch, J.W. Motorcycle detection and classification in urban Scenarios using a model based on Faster R-CNN. arXiv 2018, arXiv:1808.02299. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; IEEE: Piscataway, NJ, USA; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Chen, Z.; Khemmar, R.; Decoux, B.; Atahouet, A.; Ertaud, J.-Y. Real Time Object Detection, Tracking, and Distance and Motion Estimation based on Deep Learning: Application to Smart Mobility. In Proceedings of the 2019 Eighth International Conference on Emerging Security Technologies (EST), Colchester, UK, 22–24 July 2019; IEEE: Piscataway, NJ, USA; pp. 1–6. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA; pp. 779–788. [Google Scholar]
- Jamtsho, Y.; Riyamongkol, P.; Waranusast, R. Real-time license plate detection for non-helmeted motorcyclist using YOLO. ICT Express 2021, 7, 104–109. [Google Scholar] [CrossRef]
- Kumar, A.; Kalia, A.; Verma, K.; Sharma, A.; Kaushal, M. Scaling up face masks detection with YOLO on a novel dataset. Optik 2021, 239, 166744. [Google Scholar] [CrossRef]
- Kumar, A.; Kalia, A.; Kalia, A. ETL-YOLO v4: A face mask detection algorithm in era of COVID-19 pandemic. Optik 2022, 259, 169051. [Google Scholar] [CrossRef] [PubMed]
- Chen, R.-C. Automatic License Plate Recognition via sliding-window darknet-YOLO deep learning. Image Vis. Comput. 2019, 87, 47–56. [Google Scholar]
- Rani, E. LittleYOLO-SPP: A delicate real-time vehicle detection algorithm. Optik 2021, 225, 165818. [Google Scholar]
- Yi, Z.; Yongliang, S.; Jun, Z. An improved tiny-yolov3 pedestrian detection algorithm. Optik 2019, 183, 17–23. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Bhujbal, A.; Mane, D. Vehicle Type Classification Using Deep Learning. In Proceedings of the International Conference on Soft Computing and Signal Processing, Hyderabad, India, 21–22 June 2019; pp. 279–290. [Google Scholar]
- Mahto, P.; Garg, P.; Seth, P.; Panda, J. Refining Yolov4 for Vehicle Detection. Int. J. Adv. Res. Eng. Technol. 2020, 11, 409–419. [Google Scholar]
- Thuan, D. Evolution of yolo Algorithm and yolov5: The State-of-the-Art Object Detection Algorithm. Bachelor’s Thesis, Oulu University, Oulu, Finland, 2021. [Google Scholar]
- Huang, Y.; Zhang, H. A Safety Vehicle Detection Mechanism Based on YOLOv5. In Proceedings of the 2021 IEEE 6th International Conference on Smart Cloud (SmartCloud), Newark, NJ, USA, 6–8 November 2021; IEEE: Piscataway, NJ, USA; pp. 1–6. [Google Scholar]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo Algorithm Developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Fanthony, I.V.; Husin, Z.; Hikmarika, H.; Dwijayanti, S.; Suprapto, B.Y. YOLO Algorithm-Based Surrounding Object Identification on Autonomous Electric Vehicle. In Proceedings of the 2021 8th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), Semarang, Indonesia, 20–21 October 2021; IEEE: Piscataway, NJ, USA; pp. 151–156. [Google Scholar]
- Chen, Y.-C.; Su, T.-F.; Lai, S.-H. Integrated vehicle and lane detection with distance estimation. In Proceedings of the Computer Vision ACCV 2014 Workshops, Singapore, 1–2 November 2014; pp. 473–485. [Google Scholar]
- Xing, Y.; Lv, C.; Chen, L.; Wang, H.; Wang, H.; Cao, D.; Velenis, E.; Wang, F.-Y. Advances in vision-based lane detection: Algorithms, integration, assessment, and perspectives on ACP-based parallel vision. IEEE/CAA J. Autom. Sin. 2018, 5, 645–661. [Google Scholar] [CrossRef]
- Kang, C.; Heo, S.W. Intelligent safety information gathering system using a smart blackbox. In Proceedings of the 2017 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 8–10 January 2017; IEEE: Piscataway, NJ, USA; pp. 229–230. [Google Scholar]
- Mahmoud, N.; Cirauqui, I.; Hostettler, A.; Doignon, C.; Soler, L.; Marescaux, J.; Montiel, J.M.M. ORBSLAM-based endoscope tracking and 3D reconstruction. In Proceedings of the International Workshop on Computer-Assisted and Robotic Endoscopy, Athens, Greece, 17 October 2017; pp. 72–83. [Google Scholar]
- Schonberger, J.L.; Frahm, J.-M. Structure-from-motion revisited. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Smith, M.W.; Carrivick, J.L.; Quincey, D.J. Structure from motion photogrammetry in physical geography. Prog. Phys. Geogr. 2016, 40, 247–275. [Google Scholar] [CrossRef]
- Chwa, D.; Dani, A.P.; Dixon, W.E. Range and motion estimation of a monocular camera using static and moving objects. IEEE Trans. Control Syst. Technol. 2015, 24, 1174–1183. [Google Scholar] [CrossRef]
- Ummenhofer, B.; Zhou, H.; Uhrig, J.; Mayer, N.; Ilg, E.; Dosovitskiy, A.; Brox, T. Demon: Depth and motion network for learning monocular stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5038–5047. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 270–279. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2366–2374. [Google Scholar]
- Lee, S.; Han, K.; Park, S.; Yang, X. Vehicle Distance Estimation from a Monocular Camera for Advanced Driver Assistance Systems. Symmetry 2022, 14, 2657. [Google Scholar] [CrossRef]
- Arabi, S.; Sharma, A.; Reyes, M.; Hamann, C.; Peek-Asa, C. Farm vehicle following distance estimation using deep learning and monocular camera images. Sensors 2022, 22, 2736. [Google Scholar] [CrossRef] [PubMed]
- Mahjourian, R.; Wicke, M.; Angelova, A. Unsupervised learning of depth and ego-motion from monocular video using 3D geometric constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5667–5675. [Google Scholar]
- Garg, R.; Bg, V.K.; Carneiro, G.; Reid, I. Unsupervised cnn for single view depth estimation: Geometry to the rescue. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 740–756. [Google Scholar]
- Liang, H.; Ma, Z.; Zhang, Q. Self-supervised object distance estimation using a monocular camera. Sensors 2022, 22, 2936. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Bardozzo, F.; Collins, T.; Forgione, A.; Hostettler, A.; Tagliaferri, R. StaSiS-Net: A stacked and siamese disparity estimation network for depth reconstruction in modern 3D laparoscopy. Med. Image Anal. 2022, 77, 102380. [Google Scholar] [CrossRef]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G.J. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3828–3838. [Google Scholar]
- Recasens, D.; Lamarca, J.; Fácil, J.M.; Montiel, J.; Civera, J. Endo-Depth-and-Motion: Reconstruction and tracking in endoscopic videos using depth networks and photometric constraints. IEEE Robot. Autom. Lett. 2021, 6, 7225–7232. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Du, L.; Chen, X.; Pei, Z.; Zhang, D.; Liu, B.; Chen, W. Improved Real-Time Traffic Obstacle Detection and Classification Method Applied in Intelligent and Connected Vehicles in Mixed Traffic Environment. J. Adv. Transp. 2022, 2022, 2259113. [Google Scholar] [CrossRef]
- Sammut, C.; Webb, G.I. Encyclopedia of Machine Learning; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. k-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, Society for Industrial and Applied Mathematics, New Orleans, LA, USA, 7–9 January 2007. [Google Scholar]
- Ahmed, F.; Tarlow, D.; Batra, D. Optimizing expected intersection-over-union with candidate-constrained CRFs. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1850–1858. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Misra, D. Mish: A self regularized non-monotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; p. 3. [Google Scholar]
- Marreiros, A.C.; Daunizeau, J.; Kiebel, S.J.; Friston, K.J. Population dynamics: Variance and the sigmoid activation function. Neuroimage 2008, 42, 147–157. [Google Scholar] [CrossRef]
- Sowmya, V.; Radha, R. Heavy-vehicle detection based on YOLOv4 featuring data augmentation and transfer-learning techniques. J. Phys. Conf. Ser. 2021, 1911, 012029. [Google Scholar]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss functions for image restoration with neural networks. IEEE Trans. Comput. Imaging 2016, 3, 47–57. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Heise, P.; Klose, S.; Jensen, B.; Knoll, A. Pm-huber: Patchmatch with huber regularization for stereo matching. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2360–2367. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Dijk, T.V.; Croon, G.D. How do neural networks see depth in single images? In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2183–2191. [Google Scholar]
- Yu, H.; Zhao, L.; Wang, H. Image denoising using trivariate shrinkage filter in the wavelet domain and joint bilateral filter in the spatial domain. IEEE Trans. Image Process. 2009, 18, 2364–2369. [Google Scholar] [PubMed]
- Kopf, J.; Cohen, M.F.; Lischinski, D.; Uyttendaele, M. Joint bilateral upsampling. ACM Trans. Graph. 2007, 26, 96-es. [Google Scholar] [CrossRef]
- Labelimg Annotation Tool. Available online: https://github.com/heartexlabs/labelImg.git (accessed on 1 June 2020).
- MYNT EYE D SDK Documentation 1.8.0. Available online: https://mynt-eye-d-sdk.readthedocs.io/_/downloads/en/latest/pdf/ (accessed on 7 November 2019).
- Prashanthi, S.K.; Kesanapalli, S.A.; Simmhan, Y. Characterizing the performance of accelerated Jetson edge devices for training deep learning models. Proc. ACM Meas. Anal. Comput. Syst. 2022, 6, 1–26. [Google Scholar]
- Biglari, A.; Tang, W. A Review of Embedded Machine Learning Based on Hardware, Application, and Sensing Scheme. Sensors 2023, 23, 2131. [Google Scholar] [CrossRef] [PubMed]
- Deigmoeller, J.; Einecke, N.; Fuchs, O.; Janssen, H. Road Surface Scanning using Stereo Cameras for Motorcycles. In Proceedings of the VISIGRAPP (5: VISAPP), Valletta, Malta, 27–29 February 2020; pp. 549–554. [Google Scholar]
- Shine, L.; Jiji, C.V. Automated detection of helmet on motorcyclists from traffic surveillance videos: A comparative analysis using hand-crafted features and CNN. Multimed. Tools Appl. 2020, 79, 14179–14199. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Camera | Specifications | Parameters |
|---|---|---|
 Mynt-Eye D1000-IR-120/Color | Resolution | 640 × 480 px |
| Pixel size | 3.75 µm | |
| Baseline | 120 mm | |
| Focal Length | 2.45 mm | |
| Visual Angle | D:121° H:105° V:58° | |
| Radial distortion parameters * | k1 = −0.3066, k2 = 0.00861 | |
| Tangential distortion parameters * | p1 = −0.0003, p2 = 0.0015 |
| Version | Precision | Recall | F1 Score | Motorcycle Position | Time Forecast | |
|---|---|---|---|---|---|---|
| Close | Far | |||||
| YOLOv1 | 0.64 | 0.53 | 0.579 | ✓ | × | 40 FPS |
| YOLOv2 | 0.67 | 0.61 | 0.63 | ✓ | × | 40 FPS |
| SSD512 | 0.68 | 0.66 | 0.60 | ✓ | × | 28 |
| SSD300 | 0.71 | 0.78 | 0.77 | ✓ | × | 25 |
| YOLOv3 | 0.69 | 0.75 | 0.77 | ✓ | × | 30 FPS |
| YOLOv4 | 0.75 | 0.79 | 0.79 | ✓ | ✓ | 35 FPS |
| Tiny-YOLOv1 | 0.3 | 0.43 | 0.35 | ✓ | × | 120 FPS |
| Tiny-YOLOv2 | 0.45 | 0.48 | 0.46 | ✓ | × | 200 FPS |
| Tiny-YOLOv3 | 0.60 | 0.59 | 0.63 | ✓ | × | 220 FPS |
| Tiny-YOLOv4 | 0.7 | 0.6 | 0.64 | ✓ | ✓ | 240 FPS |
| MD-TinyYOLOv4 | 0.81 | 0.79 | 0.79 | ✓ | ✓ | 240 FPS |
| Disparity Map Model | Disparity Filter | Pretrained Weight | Distance RMSE (m) | Runtime |
|---|---|---|---|---|
| Monodepth1 | None | ImageNet | 0.8346 | 35 fps or 0.028 s |
| Joint bilateral filter | 0.7739 | |||
| Monodepth1 | None | KITTI | 0.4756 | 35 fps or 0.028 s |
| Joint bilateral filter | 0.416 | |||
| Monodepth2 | None | ImageNet | 0.6868 | 45 fps or 0.022 s |
| Joint bilateral filter | 0.6061 | |||
| Monodepth2 | None | KITTI | 0.3620 | 45 fps or 0.022 s |
| Joint bilateral filter | 0.323 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shabestari, Z.B.; Hosseininaveh, A.; Remondino, F. Motorcycle Detection and Collision Warning Using Monocular Images from a Vehicle. Remote Sens. 2023, 15, 5548. https://doi.org/10.3390/rs15235548
Shabestari ZB, Hosseininaveh A, Remondino F. Motorcycle Detection and Collision Warning Using Monocular Images from a Vehicle. Remote Sensing. 2023; 15(23):5548. https://doi.org/10.3390/rs15235548
Chicago/Turabian StyleShabestari, Zahra Badamchi, Ali Hosseininaveh, and Fabio Remondino. 2023. "Motorcycle Detection and Collision Warning Using Monocular Images from a Vehicle" Remote Sensing 15, no. 23: 5548. https://doi.org/10.3390/rs15235548