

Frequency Agile Anti-Interference Technology Based on Reinforcement Learning Using Long Short-Term Memory and Multi-Layer Historical Information Observation
Abstract
:
1. Introduction
- 1.
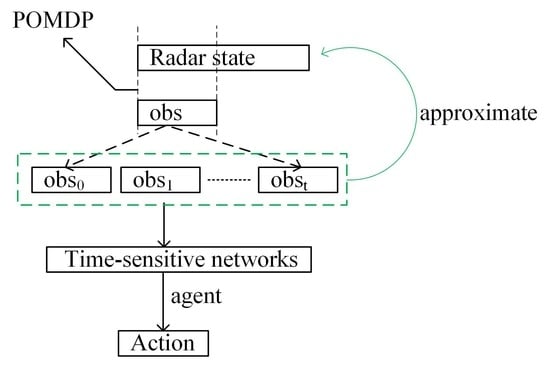
- The process of radar frequency hopping against the jammer is constructed as a POMDP, and the partially observable problem is solved by using a radar history observation sequence.
- 2.
- It has been proven that the time-sensitive network has more advantages than the FFN in terms of extracting information from the radar observation sequence.
- 3.
- Optimizing the reward design of the agent helps the reinforcement learning model with LSTM to achieve faster convergence. In a POMDP, the agent relies on historical observations, and each layer of actions and rewards in the observation sequence will impact the agent’s decision. Therefore, the agent’s reward after taking action should not be independent (i.e., the reward design in the MDP is only related to the action of this round), but should rather reflect the connection between the decisions. Therefore, we optimized the reward function to speed up the learning speed of the agent to resist the jammer in sweep mode.
- 4.
- Extensive experiments were carried out to prove the method.
2. System Model
2.1. The Signal Model of the Radar
2.2. The Model of the Jammer
3. Interaction Model
3.1. Special Features of Radar Anti-Jamming
- A set of states S. Let st represent the state of the agent at time t.
- A set of actions A. Let at represent the action made by the agent at time t.
- State transition probability:
- Immediate reward function:

3.2. Parameter Design for Reinforcement Learning
- States: During the process of radar anti-interference, the radar perceives the environment by receiving echo signals and utilizes historical observations to infer the true state, enabling it to make appropriate anti-interference decisions. To address this partially observable problem, we define the input state of the intelligent agent as follows:
- Actions: Actions reflect the agent’s decision-making process. In a CPI, the radar can hop frequencies on any PRI pulse to evade interference. We state that the agent can choose one of the L frequencies in the carrier frequency space as their hopping object.
- Reward Function: Rewards are used to evaluate the value of the radar agent’s decisions, and the feedback can guide the agent in their learning in the future. Considering the characteristics of the sweep mode, we define the reward function as follows:
3.3. Deep Reinforcement Learning
3.4. The Process between the Radar and Jammer
| Algorithm 1: The Process between the Radar and Jammer. |
| INITIALIZE. H: replay-buffer; ω: network-parameters INITIALIZE. ω−: copy of ω; N−: target update cycle INITIALIZE. Operating parameters of radars and jammers. for each CPI do Initialize the radar observation matrix as the initial state of the agent for each pulse do Choose according to the greedy algorithm The jammer emits jamming in sweep mode According to st and at, obtain st+1, rt+1 Store transition (st, at, rt+1, st+1) in H st ← st+1 end for Sample minibatch data from H randomly Obtain Calculate TD learning target yj Update network parameters with Update the greedy parameters Replace target parameters ω− ← ω every N− steps end for |
4. Results
4.1. The Performance of Radar Adaptive Frequency Hopping
4.2. The Effects of a Time-Sensitive Network
4.3. The Effects of Reward
4.4. The Influence of the Number of Observation Layers
4.5. Comparison of Method
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Skolnik, M.I. Radar Handbook; McGraw-Hill Education: Berkshire, UK, 2008. [Google Scholar]
- Li, Y.; Huang, T.; Xu, X.; Liu, Y.; Wang, L.; Eldar, Y.C. Phase transitions in frequency agile radar using compressed sensing. IEEE Trans. Signal Process. 2021, 69, 4801–4818. [Google Scholar] [CrossRef]
- Qin, Z.; Zhou, X.; Zhang, L.; Gao, Y.; Liang, Y.-C.; Li, G.Y. 20 years of evolution from cognitive to intelligent communications. IEEE Trans. Cogn. Commun. Netw. 2019, 6, 6–20. [Google Scholar] [CrossRef]
- Krishnamurthy, V.; Angley, D.; Evans, R.; Moran, B. Identifying cognitive radars-inverse reinforcement learning using revealed preferences. IEEE Trans. Signal Process. 2020, 68, 4529–4542. [Google Scholar] [CrossRef]
- Wang, L.; Peng, J.; Xie, Z.; Zhang, Y. Optimal jamming frequency selection for cognitive jammer based on reinforcement learning. In Proceedings of the 2019 IEEE 2nd International Conference on Information Communication and Signal Processing (ICICSP), Weihai, China, 28–30 September 2019; pp. 39–43. [Google Scholar]
- Apfeld, S.; Charlish, A.; Ascheid, G. Modelling, learning and prediction of complex radar emitter behaviour. In Proceedings of the 2019 18th IEEE International Conference On Machine Learning And Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 305–310. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Watkins, C.J.C.H. Learning from Delayed Rewards. Ph.D. Thesis, Cambridge University, Cambridge, UK, 1989. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 387–395. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International Conference on Machine Learning, Jinan, China, 19–21 May 2018; pp. 1861–1870. [Google Scholar]
- Ak, S.; Brüggenwirth, S. Avoiding interference in multi-emitter environments: A reinforcement learning approach. In Proceedings of the 2020 17th European Radar Conference (EuRAD), Utrecht, The Netherlands, 13–15 January 2021; pp. 262–265. [Google Scholar]
- Zheng, Z.; Li, W.; Zou, K. Airborne Radar Anti-Jamming Waveform Design Based on Deep Reinforcement Learning. Sensors 2022, 22, 8689. [Google Scholar] [CrossRef] [PubMed]
- Liu, K.; Lu, X.; Xiao, L.; Xu, L. Learning based energy efficient radar power control against deceptive jamming. In Proceedings of the GLOBECOM 2020-2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Yi, W.; Yuan, Y. Reinforcement learning-based joint adaptive frequency hopping and pulse-width allocation for radar anti-jamming. In Proceedings of the 2020 IEEE Radar Conference (RadarConf20), Florence, Italy, 21–25 September 2020; pp. 1–6. [Google Scholar]
- Yi, W.; Varshney, P.K. Adaptation of Frequency Hopping Interval for Radar Anti-Jamming Based on Reinforcement Learning. IEEE Trans. Veh. Technol. 2022, 71, 12434–12449. [Google Scholar]
- Ak, S.; Brüggenwirth, S. Avoiding jammers: A reinforcement learning approach. In Proceedings of the 2020 IEEE International Radar Conference (RADAR), Washington, DC, USA, 28–30 April 2020; pp. 321–326. [Google Scholar]
- Li, K.; Jiu, B.; Liu, H.; Liang, S. Reinforcement learning based anti-jamming frequency hopping strategies design for cognitive radar. In Proceedings of the 2018 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Qingdao, China, 14–16 September 2018; pp. 1–5. [Google Scholar]
- Jiang, W.; Ren, Y.; Wang, Y. Improving anti-jamming decision-making strategies for cognitive radar via multi-agent deep reinforcement learning. Digit. Signal Process. 2023, 135, 103952. [Google Scholar] [CrossRef]
- Geng, J.; Jiu, B.; Li, K.; Zhao, Y.; Liu, H.; Li, H. Radar and Jammer Intelligent Game under Jamming Power Dynamic Allocation. Remote Sens. 2023, 15, 581. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Cassandra, A.R. Planning and acting in partially observable stochastic domains. Artif. Intell. 1998, 101, 99–134. [Google Scholar] [CrossRef]
- Hausknecht, M.; Stone, P. Deep recurrent q-learning for partially observable mdps. In Proceedings of the 2015 AAAI Fall Symposium Series, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Li, K.; Jiu, B.; Wang, P.; Liu, H.; Shi, Y. Radar active antagonism through deep reinforcement learning: A Way to address the challenge of mainlobe jamming. Signal Process. 2021, 186, 108130. [Google Scholar] [CrossRef]
- Li, N.-J.; Zhang, Y.-T. A survey of radar ECM and ECCM. IEEE Trans. Aerosp. Electron. Syst. 1995, 31, 1110–1120. [Google Scholar]
- Axelsson, S.R. Analysis of random step frequency radar and comparison with experiments. IEEE Trans. Geosci. Remote Sens. 2007, 45, 890–904. [Google Scholar] [CrossRef]
- Antonik, P.; Wicks, M.C.; Griffiths, H.D.; Baker, C.J. Frequency diverse array radars. In Proceedings of the 2006 IEEE Conference on Radar, Verona, NY, USA, 24–27 April 2006; p. 3. [Google Scholar]
- An, P.; Shang, Z.; Yan, S.; Wang, D. Design Method Of Frequency-Agile Radar Frequency Hopping Sequence Based On CNN Network And Chaotic Sequence. In Proceedings of the 2022 International Conference on Big Data, Information and Computer Network (BDICN), Sanya, China, 20–22 January 2022; pp. 702–707. [Google Scholar]
- Wei-Feng, Z.; Xin-Ling, G.; Jian-Peng, Z. Instantaneous Frequency Measurement Interferometer by the Phase Comparison Method. Sci. Technol. Vis. 2016, 299, 301. (In Chinese) [Google Scholar] [CrossRef]
- Liu, N.; Dong, Y.; Wang, G.; Ding, H.; Huang, Y.; Guan, J.; Chen, X.; He, Y. Sea-detecting X-band Radar and Data Acquisition Program. J. Radars 2019, 8, 656. (In English) [Google Scholar] [CrossRef]
- Free, D.; Norwood, M.; House, A. Electronic Warfare in the Information Age; Artech House Inc.: Norwood, MA, USA, 1999. [Google Scholar]
- Golomb, S.W.; Gong, G. Signal Design for Good Correlation: For Wireless Communication, Cryptography, and Radar; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Rubinstein, R.Y.; Kroese, D.P. Simulation and the Monte Carlo Method; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Chowdhary, K.; Chowdhary, K. Natural language processing. Fundam. Artif. Intell. 2020, 603–649. [Google Scholar] [CrossRef]
- Geng, J.; Jiu, B.; Li, K.; Zhao, Y.; Liu, H. Reinforcement Learning Based Radar Anti-Jamming Strategy Design against a Non-Stationary Jammer. In Proceedings of the 2022 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Xi’an, China, 25–27 October 2022; pp. 1–5. [Google Scholar]
- Li, K.; Jiu, B.; Liu, H. Deep q-network based anti-jamming strategy design for frequency agile radar. In Proceedings of the 2019 International Radar Conference (RADAR), Toulon, France, 23–27 September 2019; pp. 1–5. [Google Scholar]
- Marcum, J. A statistical theory of target detection by pulsed radar. IRE Trans. Inf. Theory 1960, 6, 59–267. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Input Size | Output Size |
|---|---|---|
| LSTM | ||
| Flatten | ||
| FC |
| Parameter | Value |
|---|---|
| Episodes | 500 |
| Number of pulses in a CPI | 64 |
| Discount rate | 0.98 |
| Learning rate | 0.001 |
| -greedy increment | 0.1 |
| Target update | 10 |
| Buffer size | 2048 |
| Minimal size | 512 |
| Batch size | 64 |
| Parameter | Value |
|---|---|
| Number of frequencies L | 100 |
| Hopping cost c | 1 |
| Mtran | 2 |
| Mint | 20 |
| Historical observation layers | 3 |
| 5 | |
| 0.2 | |
| 0.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, W.; Guo, S.; Cong, X.; Sheng, W.; Yan, J.; Chen, J. Frequency Agile Anti-Interference Technology Based on Reinforcement Learning Using Long Short-Term Memory and Multi-Layer Historical Information Observation. Remote Sens. 2023, 15, 5467. https://doi.org/10.3390/rs15235467
Shi W, Guo S, Cong X, Sheng W, Yan J, Chen J. Frequency Agile Anti-Interference Technology Based on Reinforcement Learning Using Long Short-Term Memory and Multi-Layer Historical Information Observation. Remote Sensing. 2023; 15(23):5467. https://doi.org/10.3390/rs15235467
Chicago/Turabian StyleShi, Weihao, Shanhong Guo, Xiaoyu Cong, Weixing Sheng, Jing Yan, and Jinkun Chen. 2023. "Frequency Agile Anti-Interference Technology Based on Reinforcement Learning Using Long Short-Term Memory and Multi-Layer Historical Information Observation" Remote Sensing 15, no. 23: 5467. https://doi.org/10.3390/rs15235467