
SRTPN: Scale and Rotation Transform Prediction Net for Multimodal Remote Sensing Image Registration
 ,
,  , , and
, , and
Abstract
:1. Introduction
- (1)
- There are large-scale geometric distortions in remote sensing images acquired from different orientations (viewing angles) or different platforms (airborne remote sensing, spaceborne remote sensing), which makes it extremely difficult to characterize geometrically invariant features.
- (2)
- There are some structural changes between images acquired by different time phases or different sensors, resulting in poor consistency based on feature representations such as shape, contour, and region, making it difficult to achieve accurate registration.
- (1)
- To alleviate large scale differences between the reference and sensed images, a scale regression module with CNN feature extraction and FFT correlation is constructed, which could roughly recover the scale difference of input image pairs.
- (2)
- To improve the robustness to rotational changes, a rotation classification module is designed after recovering the scale changes. Combination of the two modules could eliminate significant geometric differences between image pairs, which is essential for accurate image registration.
- (3)
- Plenty of comparative experimental results show that our method outperforms related methods in registration accuracy on GoogleEarth, HRMRS, VIS-NIR and UAV datasets.
2. Related Works
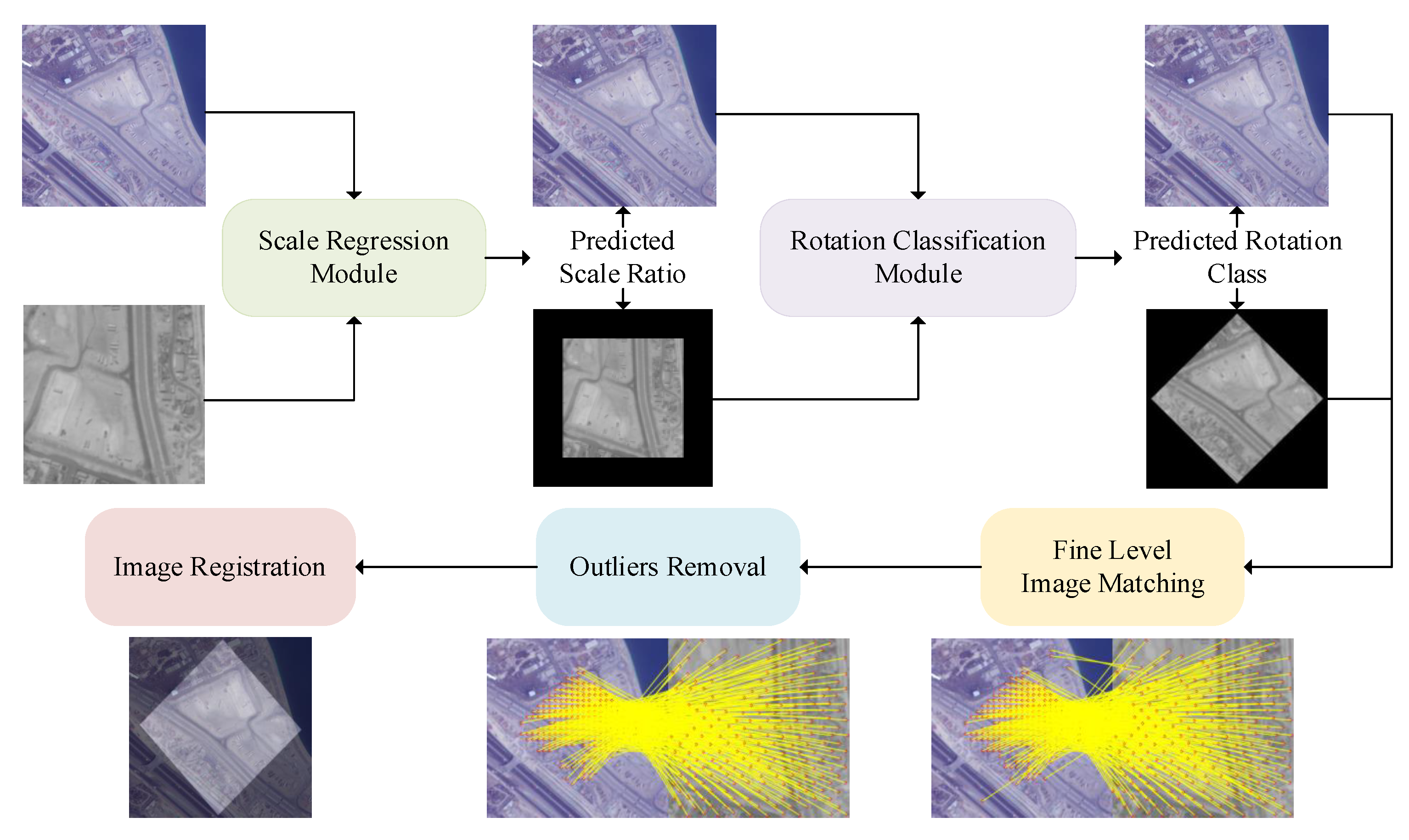
3. Method
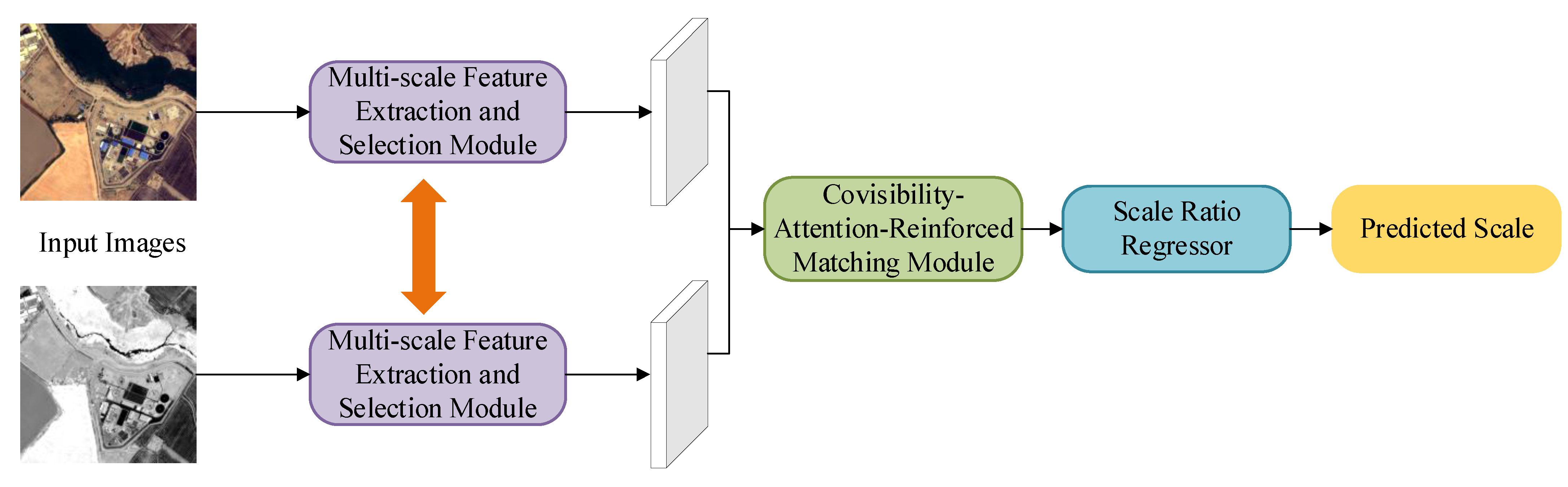
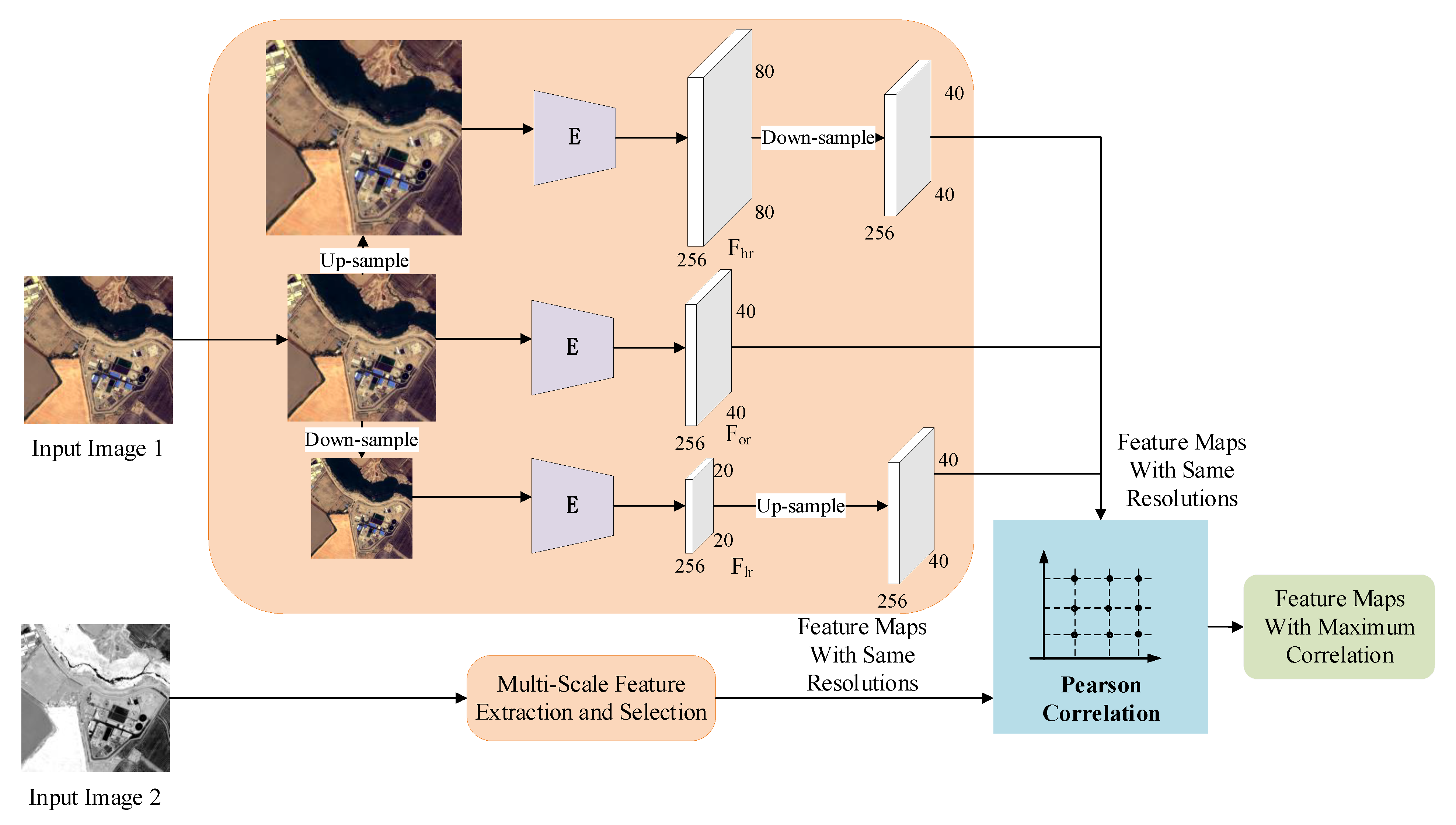
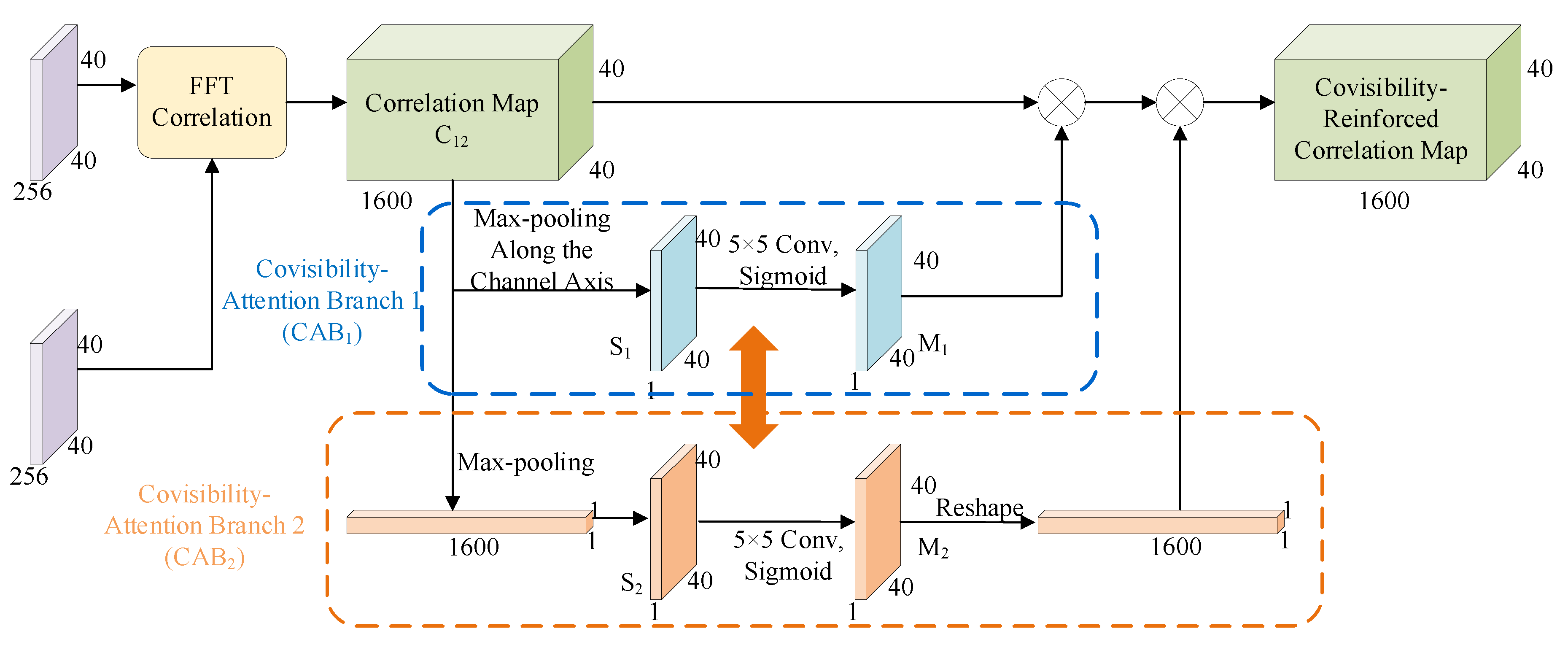
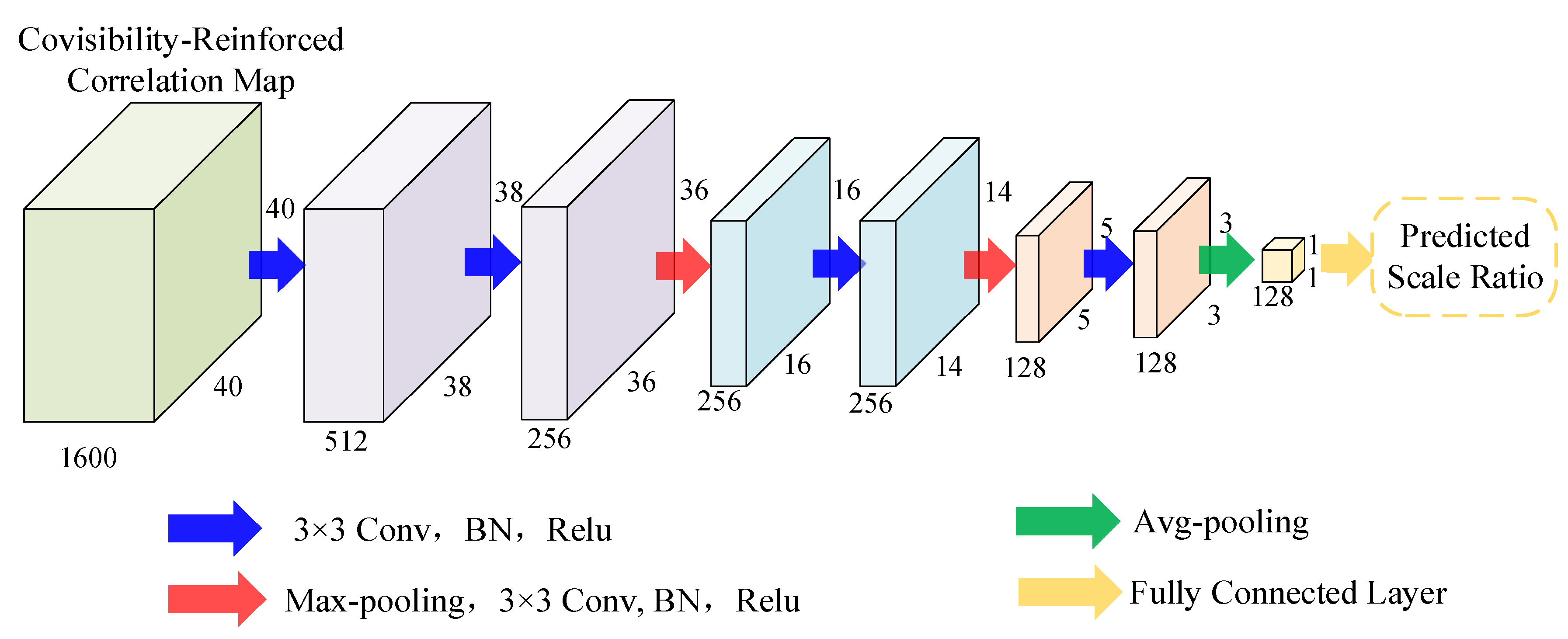
3.1. Scale Regression Module
3.1.1. Definitions
3.1.2. Scale Estimation Network
3.1.3. Dual Consistent Loss
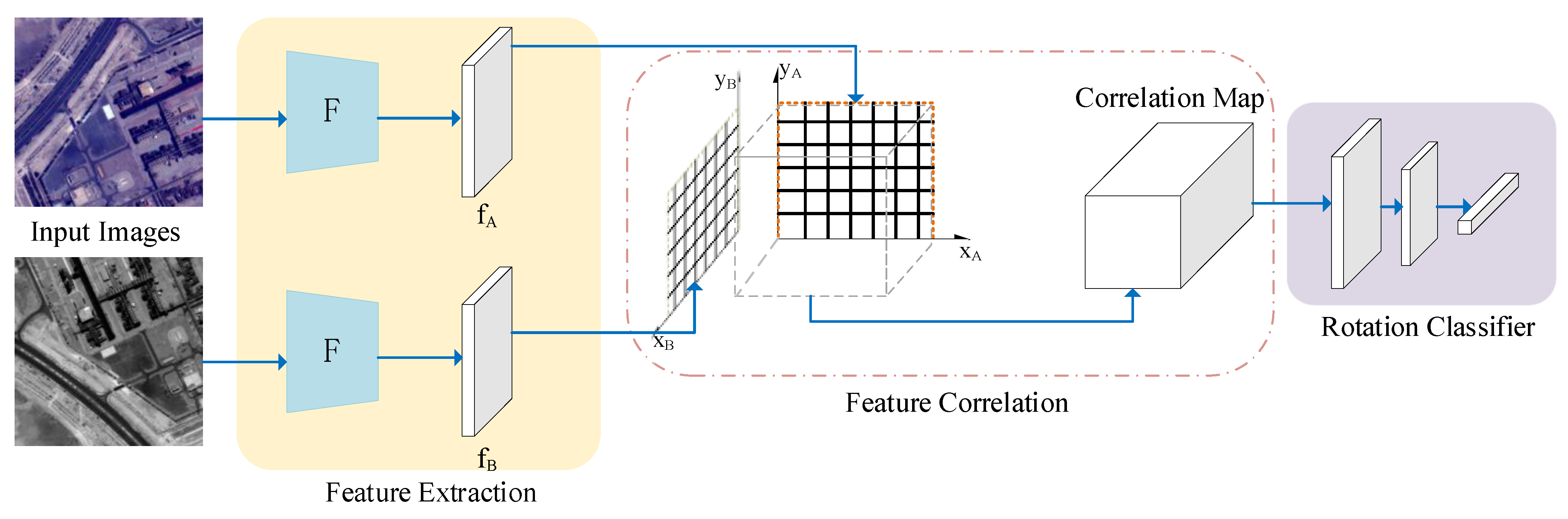
3.2. Rotation Classification Module
- (1)
- Feature Extraction. A pseudo Siamese neural network structure consisting of ResNet101 is utilized as the backbone of feature extraction, which could focus on the distinctive information of different modalities. Subsequently, the obtained features are L2-normalized to facilitate the following calculation of correlation matrix.
- (2)
- Feature Correlation. To measure the point-by-point correlation of two feature maps, this step calculates their correlation matrix, where each element represents similarity scores of the corresponding features. The details are consistent with (2) in Section 3.1.
- (3)
- Rotation Classifier. After the correlation matrix is given, we convert the rotation parameter regression problem into a rotation classification problem, which greatly simplifies the model training process. In this process, rotation parameters are divided into 8 categories in the range 0–360° at 30° intervals, which can be estimated by the rotation classifier containing two convolutional layers and one fully connected layer.
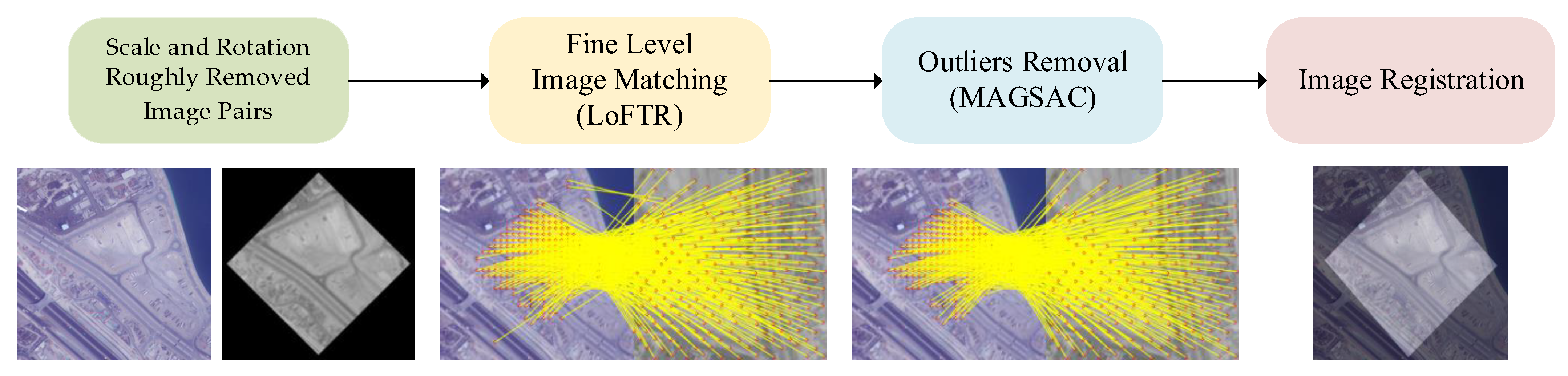
3.3. Fine-Level Image Matching and Registration
- (1)
- Given the superior performance of LoFTR in local-image feature matching, it has been adopted for the feature extraction and matching of image pairs where geometric transformations have been eliminated.
- (2)
- To purify the match results, MAGSAC [24] is used to remove the outliers.
- (3)
- The image transform matrix is calculated from the fine level matching pairs and the accurate image registration is achieved.
4. Experimental Results and Analysis
4.1. Datasets and Experiment Implementation Details
4.1.1. Datasets
- (a)
- Google Earth dataset [22]: The dataset contains 9042 image pairs with a size of pixels, and each of them is collected at the same location but at different times. In the experiment of our network, 8000 image pairs are applied to train the rotate classification module, 900 pairs are applied to validation and 142 pairs are allocated to testing phases.
- (b)
- HRMS dataset: The High-Resolution Multimodal Satellite remote sensing dataset is captured by Gaofen-14 satellite, which contains 1730 multispectral and panchromatic remote sensing image pairs with a size of pixels. In the experiment, 1500 pairs of images are applied to train of the scale regression module, 90 pairs are applied to validation and 140 pairs of images are assigned to the testing phases.
- (c)
- VIS-NIR dataset [27]: This dataset contains 319 pairs of visible and infrared image with a size of pixels, which mainly includes urban, village and coastal scenes. The contrast difference is the main change between the original image pairs. This dataset is only adopted in the testing phase of comparative experiments.
- (d)
- UAV dataset: The UAV dataset works only in testing phase and involves 87 image pairs. The aerial images are captured by DJI X5 with a size of pixels. The referenced remote sensing images are captured from Google Earth with different resolutions ranging from to . Before the comparative experiments, the image pairs of UAV dataset are uniformly resized to .
4.1.2. Data Processing
4.1.3. Implementation Detail and Evaluation Metrics
4.2. Geometric Deformation Resistance Experiments
4.2.1. Scale-Robustness Validation
4.2.2. Rotation Robustness Validation
4.2.3. Scale and Rotation Robustness Validation
4.3. Comparative Experiments
4.3.1. Comparison Result with ScaleNet
4.3.2. Comparison Result with SOTA methods
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zitová, B.; Flusser, J. Image Registration Methods: A Survey. Image Vis. Comput. 2003, 21, 977–1000. [Google Scholar] [CrossRef] [Green Version]
- Jiang, X.; Ma, J.; Xiao, G.; Shao, Z.; Guo, X. A Review of Multimodal Image Matching: Methods and Applications. Inf. Fusion 2021, 73, 22–71. [Google Scholar] [CrossRef]
- Zhao, Z.; Bai, H.; Zhang, J.; Zhang, Y.; Xu, S.; Lin, Z.; Timofte, R.; Gool, L.V. CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 5906–5916. [Google Scholar]
- Bai, X.; Hu, Z.; Zhu, X.; Huang, Q.; Chen, Y.; Fu, H.; Tai, C.-L. TransFusion: Robust LiDAR-Camera Fusion for 3D Object Detection with Transformers. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 1090–1099. [Google Scholar]
- Gedara Chaminda Bandara, W.; Gopalakrishnan Nair, N.; Patel, V.M. DDPM-CD: Remote Sensing Change Detection Using Denoising Diffusion Probabilistic Models. arXiv 2022, arXiv:2206.11892. [Google Scholar]
- Lin, M.; Yang, G.; Zhang, H. Transition Is a Process: Pair-to-Video Change Detection Networks for Very High Resolution Remote Sensing Images. IEEE Trans. Image Process. 2023, 32, 57–71. [Google Scholar] [CrossRef] [PubMed]
- Jiao, Y.; Jie, Z.; Chen, S.; Chen, J.; Ma, L.; Jiang, Y.-G. MSMDFusion: Fusing LiDAR and Camera at Multiple Scales with Multi-Depth Seeds for 3D Object Detection. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 21643–21652. [Google Scholar]
- Gupta, A.; Narayan, S.; Joseph, K.J.; Khan, S.; Khan, F.S.; Shah, M. OW-DETR: Open-World Detection Transformer. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 9225–9234. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Liu, X.; Xue, J.; Xu, X.; Lu, Z.; Liu, R.; Zhao, B.; Li, Y.; Miao, Q. Robust Multimodal Remote Sensing Image Registration Based on Local Statistical Frequency Information. Remote Sens. 2022, 14, 1051. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Barroso-Laguna, A.; Mikolajczyk, K. Key. Net: Keypoint Detection by Handcrafted and Learned Cnn Filters Revisited. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 698–711. [Google Scholar] [CrossRef] [PubMed]
- Rocco, I.; Arandjelović, R.; Sivic, J. Efficient Neighbourhood Consensus Networks via Submanifold Sparse Convolutions. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part IX 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 605–621. [Google Scholar]
- Rocco, I.; Cimpoi, M.; Arandjelović, R.; Torii, A.; Pajdla, T.; Sivic, J. Neighbourhood Consensus Networks. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Li, X.; Han, K.; Li, S.; Prisacariu, V. Dual-Resolution Correspondence Networks. Adv. Neural Inf. Process. Syst. 2020, 33, 17346–17357. [Google Scholar]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-Free Local Feature Matching with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 8922–8931. [Google Scholar]
- Sarlin, P.-E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperGlue: Learning Feature Matching with Graph Neural Networks. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4938–4947. [Google Scholar]
- Bokman, G.; Kahl, F. A Case for Using Rotation Invariant Features in State of the Art Feature Matchers. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 18–24 June 2022; pp. 5106–5115. [Google Scholar]
- Fu, Y.; Wu, Y. Scale-Net: Learning to Reduce Scale Differences for Large-Scale Invariant Image Matching. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 1335–1348. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Rocco, I.; Arandjelovic, R.; Sivic, J. Convolutional Neural Network Architecture for Geometric Matching. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6148–6157. [Google Scholar]
- Kim, D.-G.; Nam, W.-J.; Lee, S.-W. A Robust Matching Network for Gradually Estimating Geometric Transformation on Remote Sensing Imagery. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 3889–3894. [Google Scholar]
- Fang, Y.; Hu, J.; Du, C.; Liu, Z.; Zhang, L. SAR-Optical Image Matching by Integrating Siamese U-Net With FFT Correlation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Barath, D.; Noskova, J.; Ivashechkin, M.; Matas, J. MAGSAC++, a Fast, Reliable and Accurate Robust Estimator. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1301–1309. [Google Scholar]
- Mishkin, D.; Radenović, F.; Matas, J. Repeatability Is Not Enough: Learning Affine Regions via Discriminability. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11213, pp. 287–304. ISBN 978-3-030-01239-7. [Google Scholar]
- Park, J.-H.; Nam, W.-J.; Lee, S.-W. A Two-Stream Symmetric Network with Bidirectional Ensemble for Aerial Image Matching. Remote Sens. 2020, 12, 465. [Google Scholar] [CrossRef] [Green Version]
- Pielawski, N.; Wetzer, E.; Öfverstedt, J.; Lu, J.; Wählby, C.; Lindblad, J.; Sladoje, N. CoMIR: Contrastive Multimodal Image Representation for Registration. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; Curran Associates, Inc.: Nice, France, 2020; Volume 33, pp. 18433–18444. [Google Scholar]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Learning Rate | Batch Size | Epochs |
|---|---|---|---|
| Scale Regression Network | 3 × 10−4 | 2 | 28 |
| Rotation Classification Network | 4 × 10−4 | 8 | 10 |
| Datasets | CNNGeo | AffNet | Two-Stream Ensemble | SE2-LoFTR | OURS |
|---|---|---|---|---|---|
| Google Earth | 4/142 | 85/142 | 74/142 | 105/142 | 115/142 |
| HRMS | 11/140 | 95/140 | 35/140 | 78/140 | 88/140 |
| VIS-NIR | 20/319 | 199/319 | 96/319 | 238/319 | 255/319 |
| UAV | 4/87 | 30/87 | 45/87 | 41/87 | 55/87 |
| Datasets | CNNGeo | AffNet | Two-Stream Ensemble | SE2-LoFTR | OURS |
|---|---|---|---|---|---|
| Google Earth | 7 | 35 | 67 | 60 | 161 |
| HRMS | 61 | 79 | 58 | 107 | 240 |
| VIS-NIR | 22 | 49 | 61 | 122 | 262 |
| UAV | 28 | 22 | 45 | 51 | 73 |
| Datasets | CNNGeo | AffNet | Two-Stream Ensemble | SE2-LoFTR | OURS |
|---|---|---|---|---|---|
| Google Earth | 1.649 | 1.258 | 1.618 | 1.491 | 1.315 |
| HRMS | 1.649 | 1.093 | 1.561 | 1.390 | 1.086 |
| VIS-NIR | 1.584 | 1.026 | 1.572 | 1.372 | 1.038 |
| UAV | 1.551 | 1.451 | 1.568 | 1.514 | 1.505 |
| AVG_RMSE | 1.608 | 1.207 | 1.580 | 1.439 | 1.236 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Xu, X.; Zhang, X.; Miao, Q.; Wang, L.; Chang, L.; Liu, R. SRTPN: Scale and Rotation Transform Prediction Net for Multimodal Remote Sensing Image Registration. Remote Sens. 2023, 15, 3469. https://doi.org/10.3390/rs15143469
Liu X, Xu X, Zhang X, Miao Q, Wang L, Chang L, Liu R. SRTPN: Scale and Rotation Transform Prediction Net for Multimodal Remote Sensing Image Registration. Remote Sensing. 2023; 15(14):3469. https://doi.org/10.3390/rs15143469
Chicago/Turabian StyleLiu, Xiangzeng, Xueling Xu, Xiaodong Zhang, Qiguang Miao, Lei Wang, Liang Chang, and Ruyi Liu. 2023. "SRTPN: Scale and Rotation Transform Prediction Net for Multimodal Remote Sensing Image Registration" Remote Sensing 15, no. 14: 3469. https://doi.org/10.3390/rs15143469