

Crop Type Mapping Based on Polarization Information of Time Series Sentinel-1 Images Using Patch-Based Neural Network

Abstract
:1. Introduction
2. Study Area and Materials
2.1. Study Area
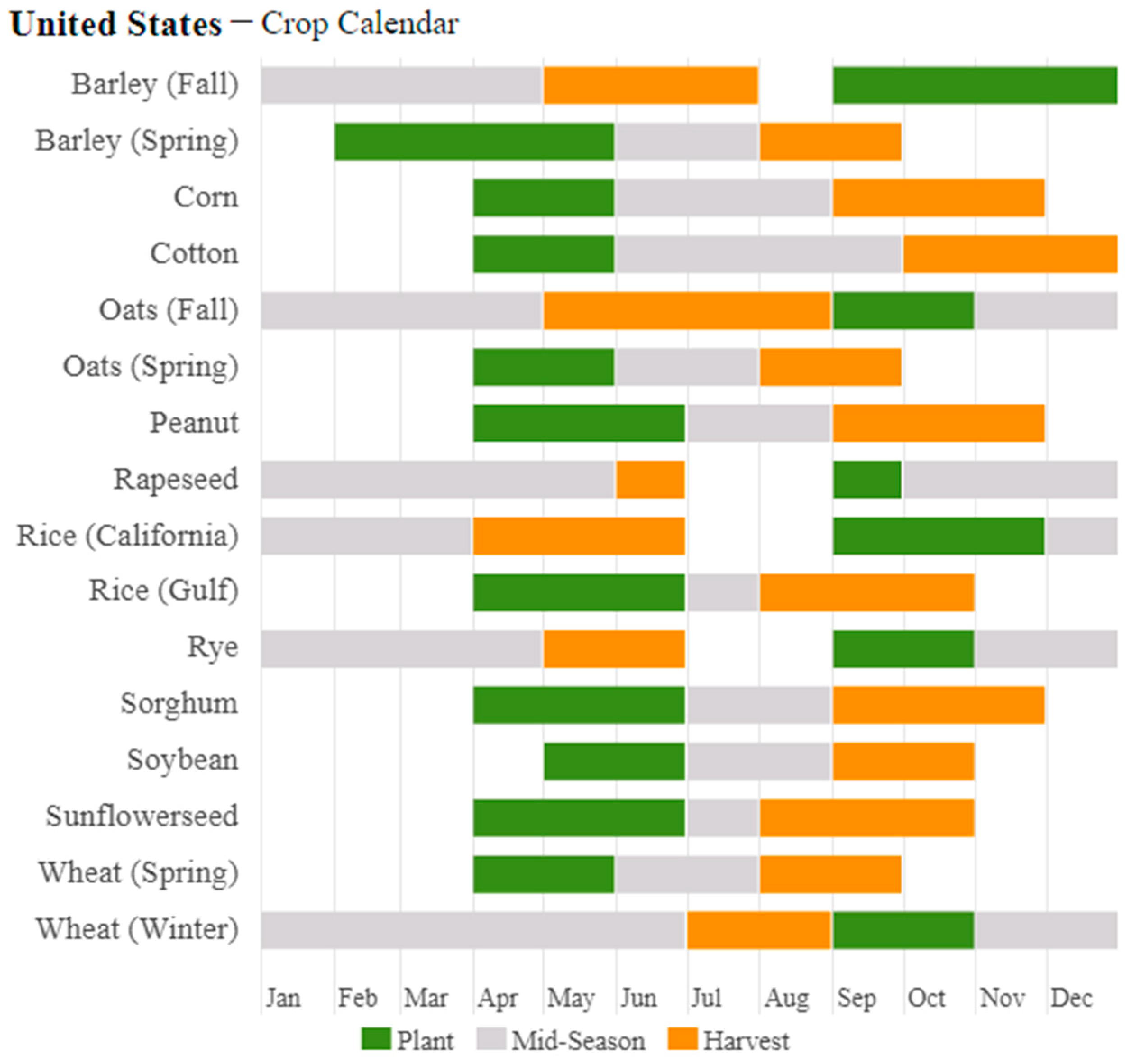
2.2. Sentinel-1
2.3. Cropland Data Layer
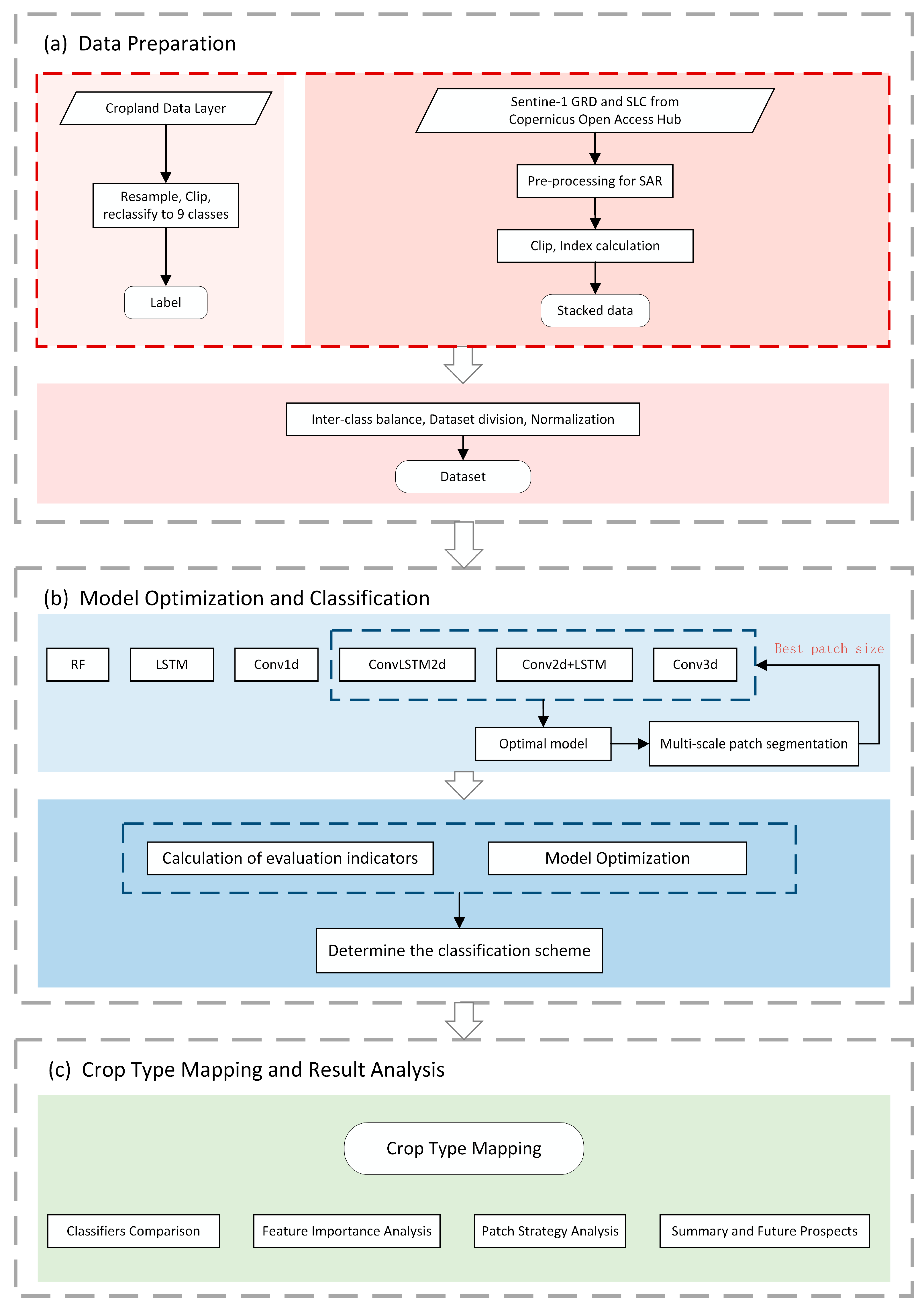
3. Methods
3.1. Data Preparation
- (1)
- Apply orbit file, to update more accurate track information;
- (2)
- Thermal noise removal;
- (3)
- Radiometric calibration, to transform digital number values to backscatter coefficient;
- (4)
- Multilooking (the study skipped this step as it was already applied in the GRD product and further reduction of spatial resolution was unnecessary);
- (5)
- Speckle filtering, to mitigate the speckle noise, a common phenomenon in coherent systems such as SAR, which arises from large and rough surfaces incompatible with the corresponding wavelength scale. In classification applications, it is essential to remove speckle noise. The refined Lee filter, an adaptive filter known for its excellent performance, was employed for this purpose;
- (6)
3.2. Classification
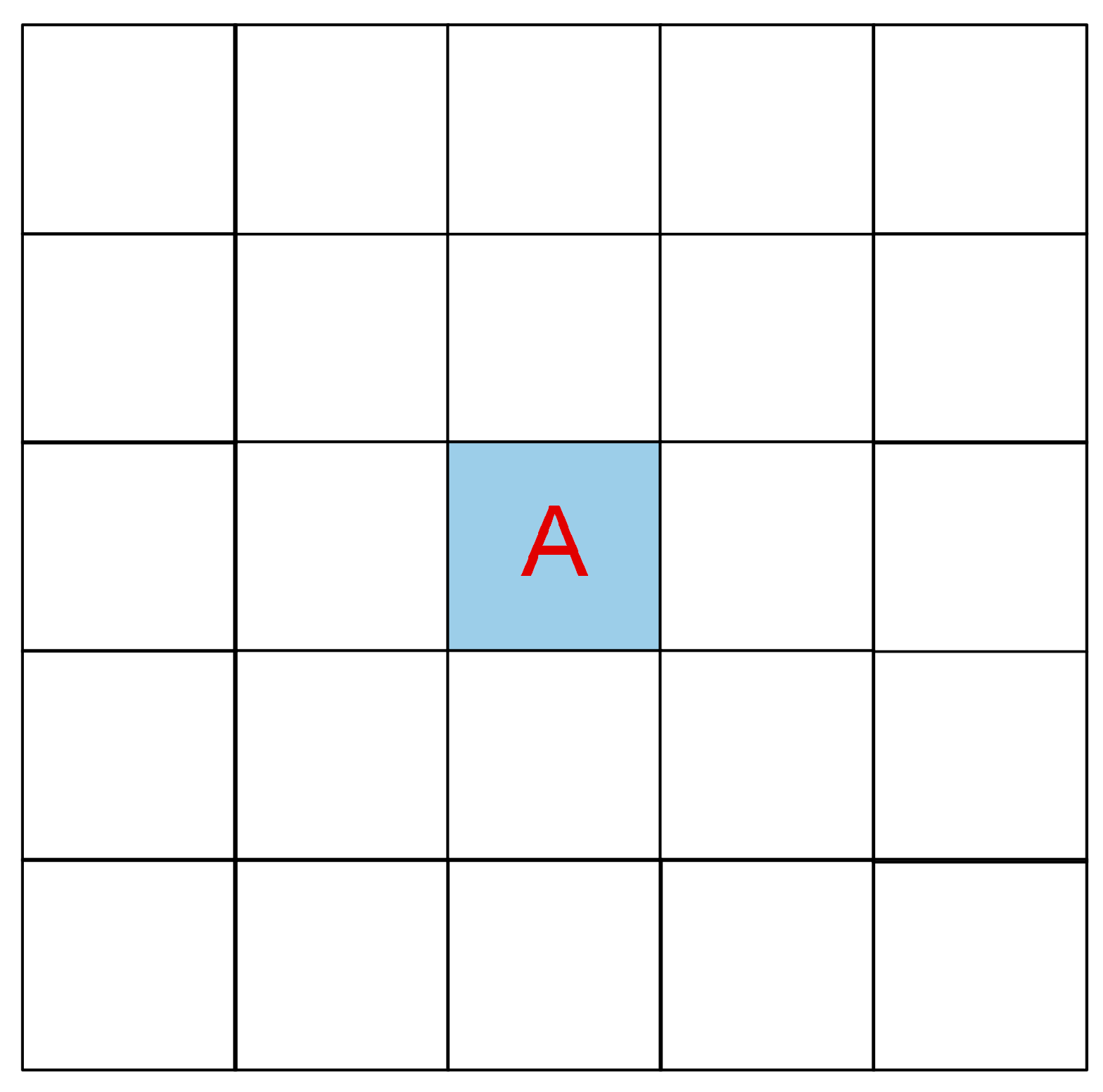
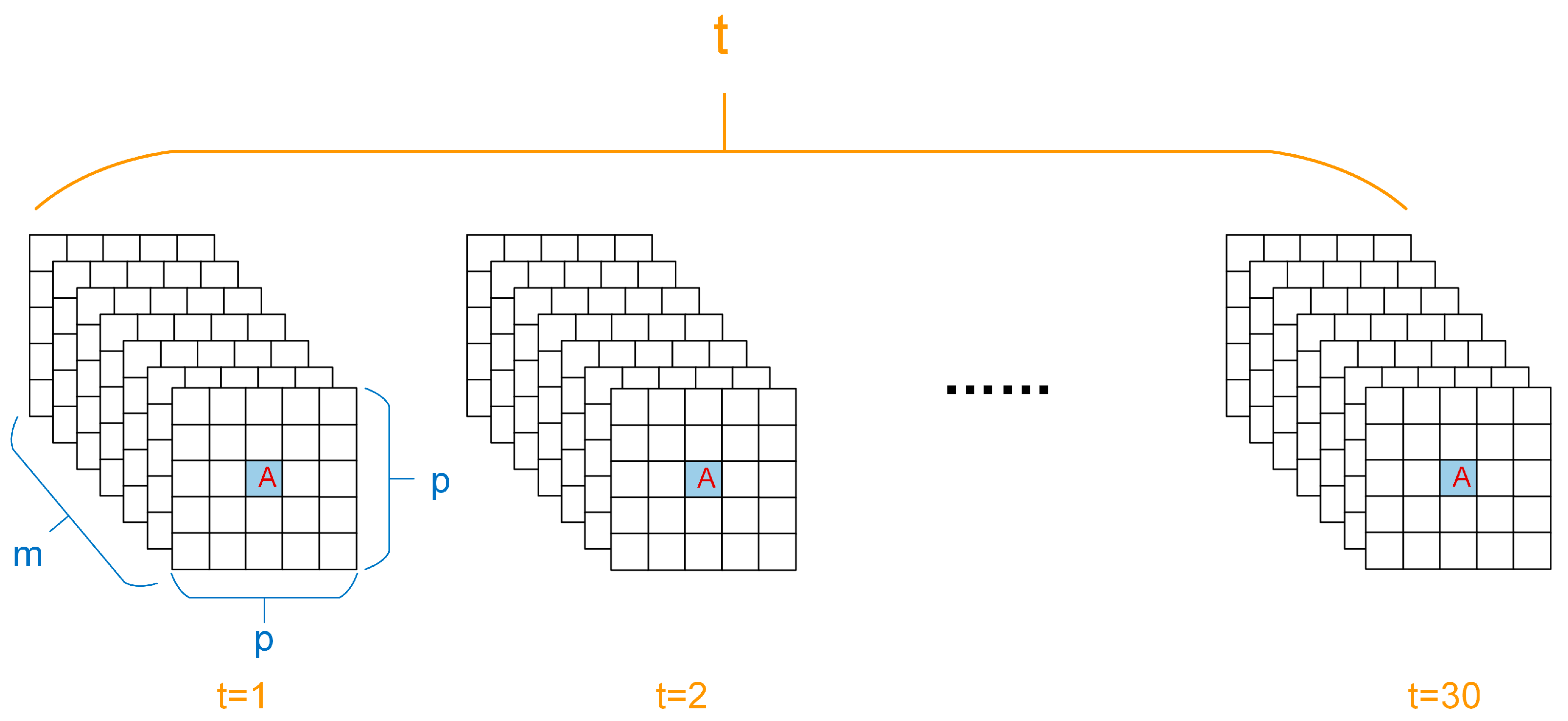
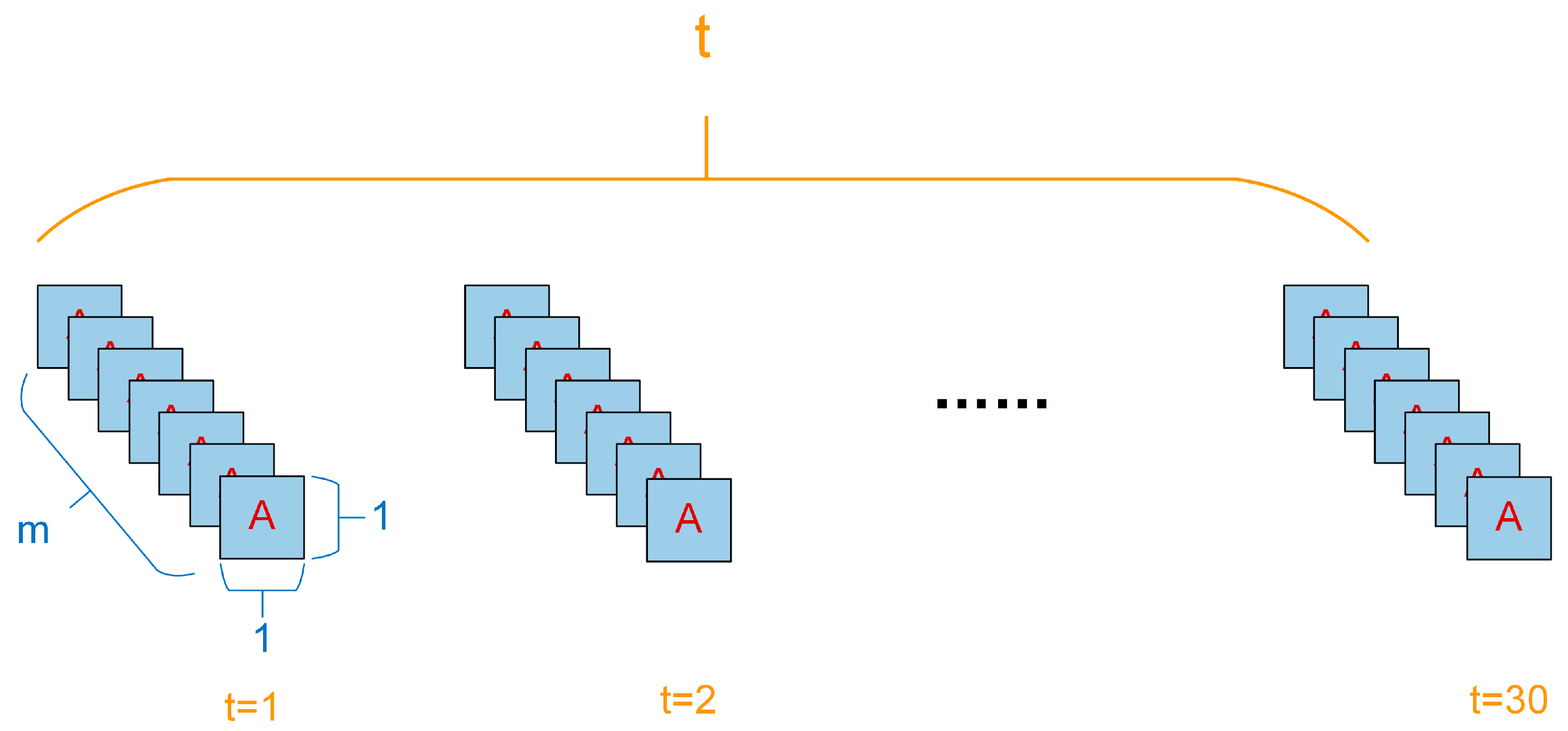
3.2.1. Patch-Based Strategy
3.2.2. Models for Comparison
3.3. Evaluation
3.4. Hardware Configuration and Software Environment
4. Results and Analysis
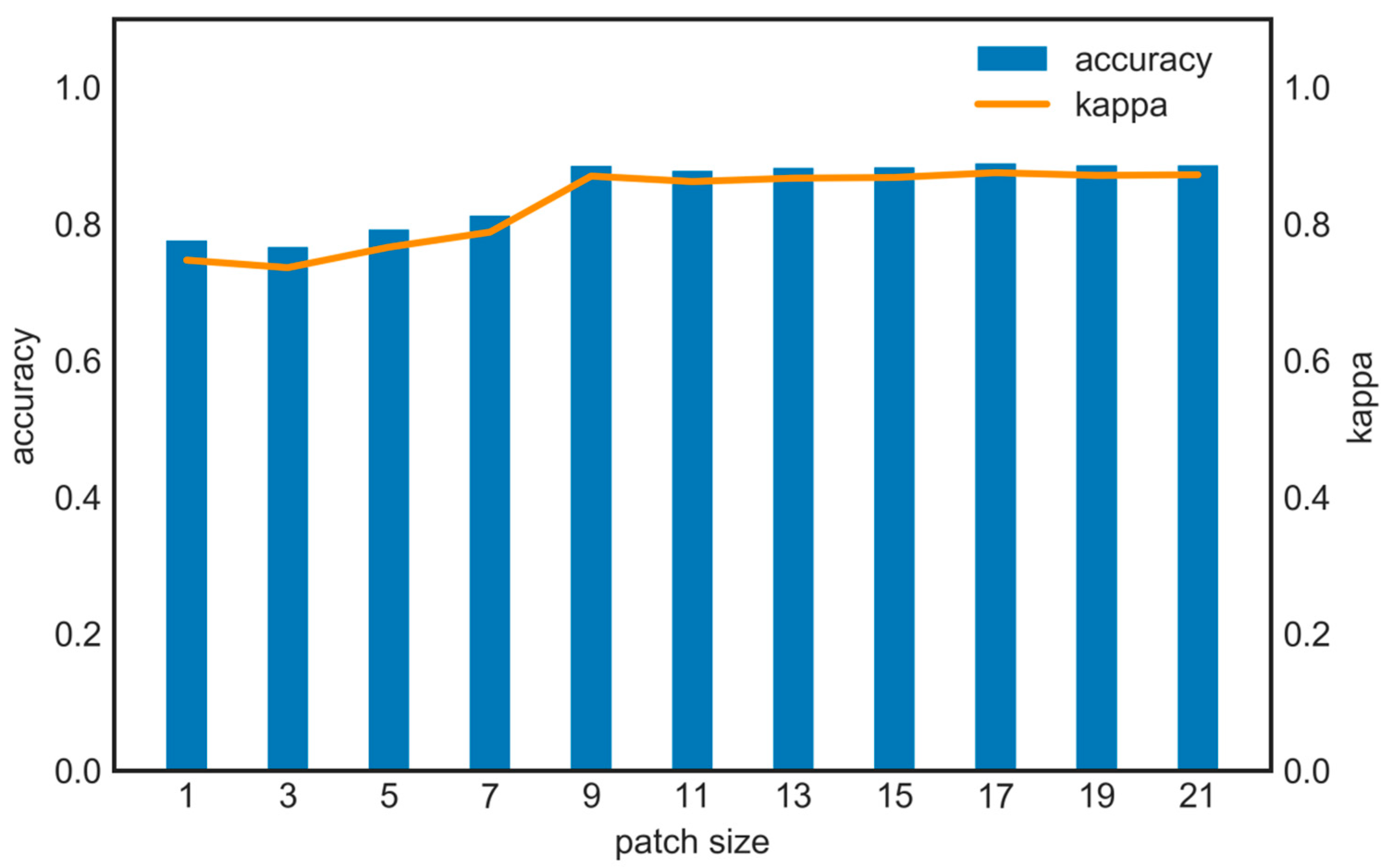
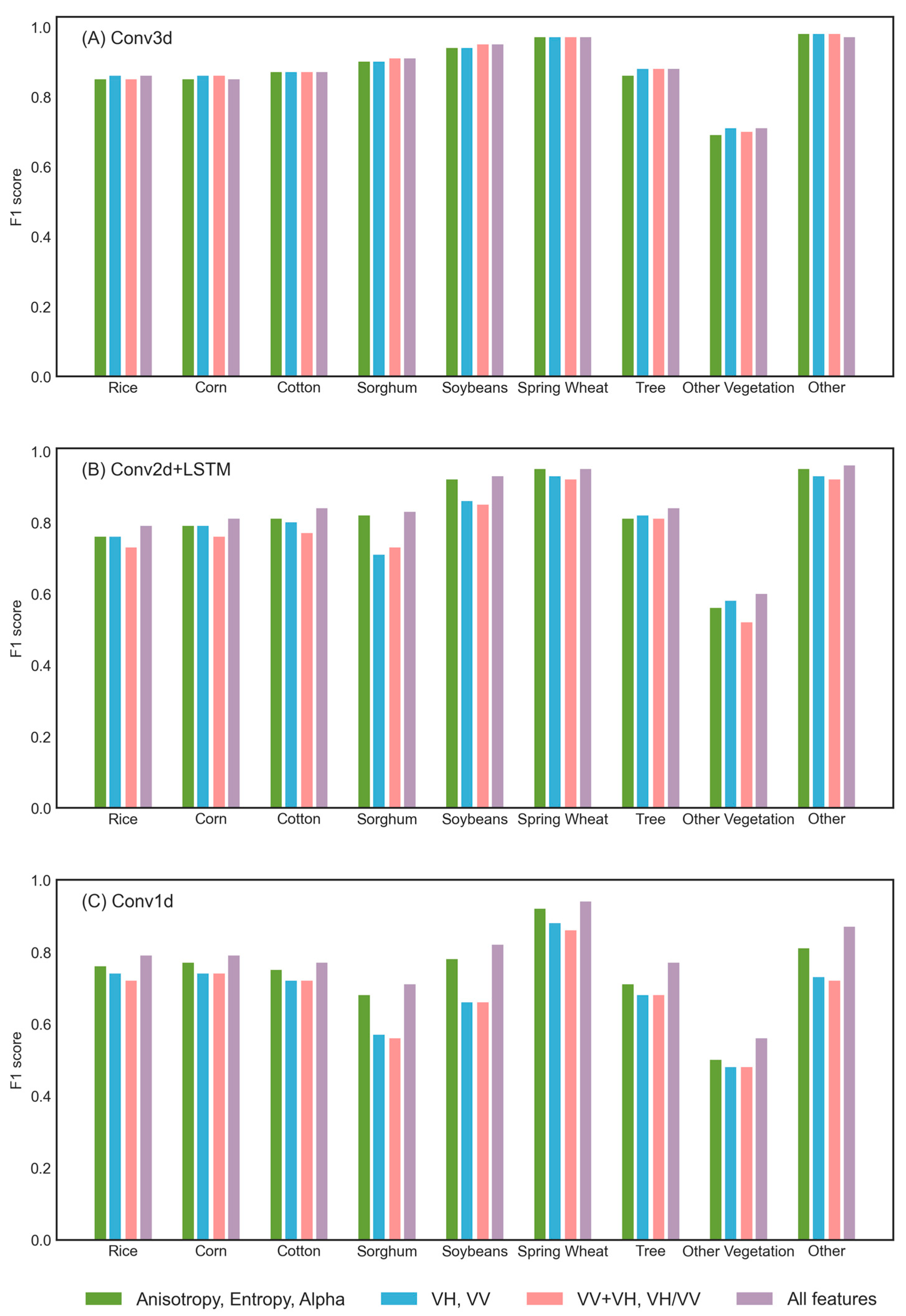
4.1. Patch-Based Strategy and Feature Importance Comparison
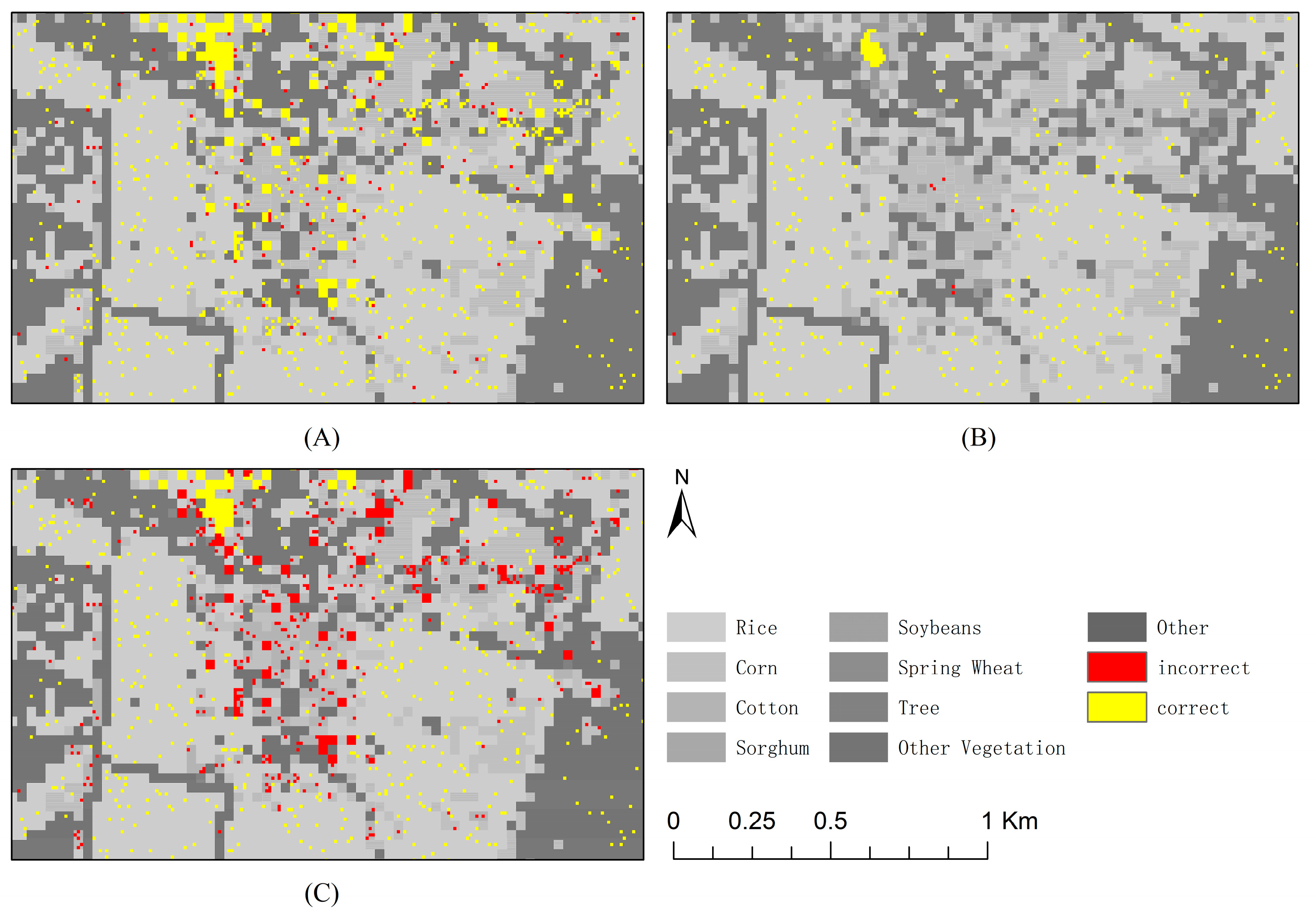
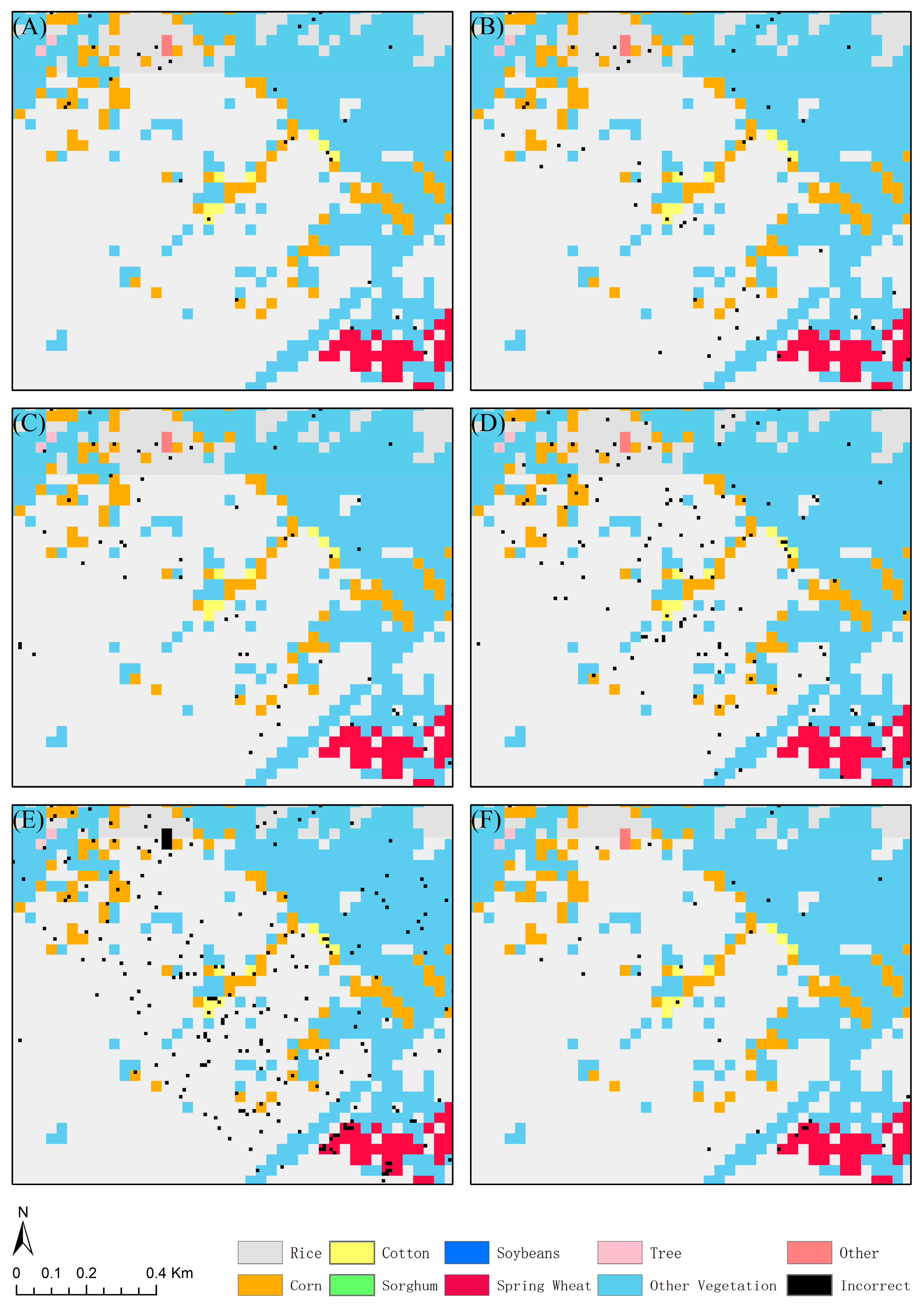
4.2. Comparison among Models
4.3. Classification Results for Each Crop Category
5. Discussion
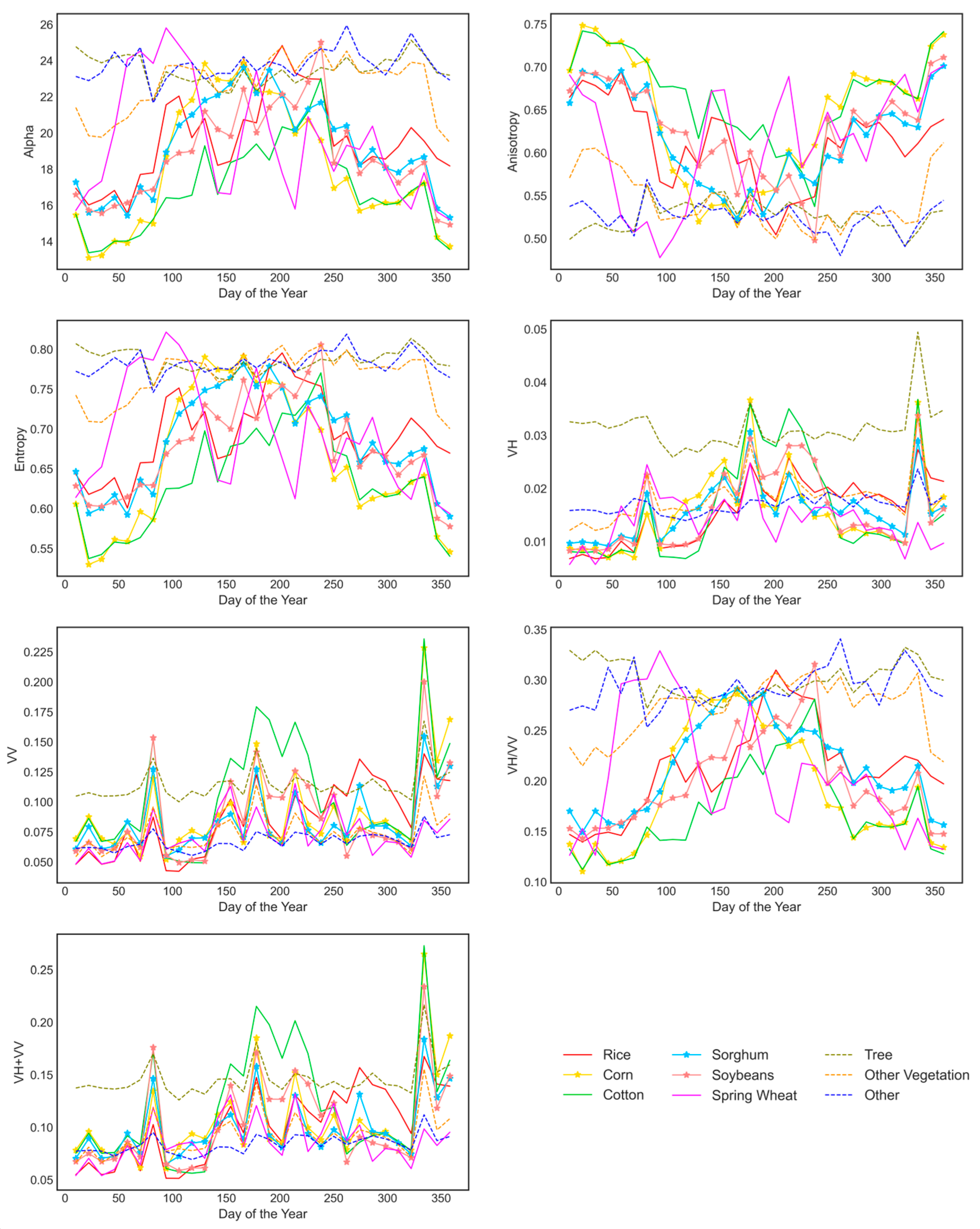
5.1. Analysis of Feature Importance
- The “Other” and “Tree” categories exhibit minimal fluctuations throughout the year, with each feature displaying distinct differences compared to other categories. This can be attributed to the high surface roughness of the “Tree” category, where the canopy, trunk and ground surface contribute to a complex multiple scattering mechanism. As a result, Anisotropy, Entropy, Alpha, and backscatter coefficients remain consistently high. In contrast, the “Other” category mainly comprises water and built-up areas, leading to stable scattering characteristics.
- “Rice”, “Spring Wheat”, and “Cotton” show differences in each feature. The backscatter coefficient is strongly influenced by water content and surface roughness. “Rice” demands frequent irrigation during its growing period, resulting in lower backscatter coefficients. Crops with significant vertical structure typically have higher horizontal polarization backscatter coefficients, “Spring Wheat” possesses a weaker vertical structure compared to “Cotton” and “Sorghum”, leading to lower backscatter coefficients. The polarization decomposition features vary with the changes in crop morphology. The Entropy and Alpha of “Spring Wheat” change earlier because of early sowing. With the increase in leaves, the surface scattering intensifies rapidly, enhancing polarization complexity and raising Entropy. During the late growth period, Entropy and Alpha do not decrease as rapidly as VH and VV. It is hypothesized that the wheat spike acts as a new scatterer, increasing randomness and leading to higher Entropy [44].
- The microwave scattering characteristics of “Corn”, “Sorghum,” and “Soybean” exhibit high similarity in the VH, VV, and VH + VV channels. However, distinctions are noticeable in their polarization decomposition features. During the early growth stage, “Corn” presents lower Entropy and Alpha values compared to “Sorghum” and “Soybean”. This discrepancy is likely attributed to the larger row and plant spacing in “Corn”, resulting in a higher contribution of soil information to the signal, thereby differentiating it from the other crops.
- In VH, VV, and VH + VV polarization channels, the “Other Vegetation” category tends to be easily confused with other categories due to its diverse constituents exhibiting mixed scattering characteristics. Nevertheless, distinctions in Anisotropy, Entropy, and Alpha are observed, which could be attributed to the consistently high complexity of this category throughout the growth period, resulting in elevated Entropy values.
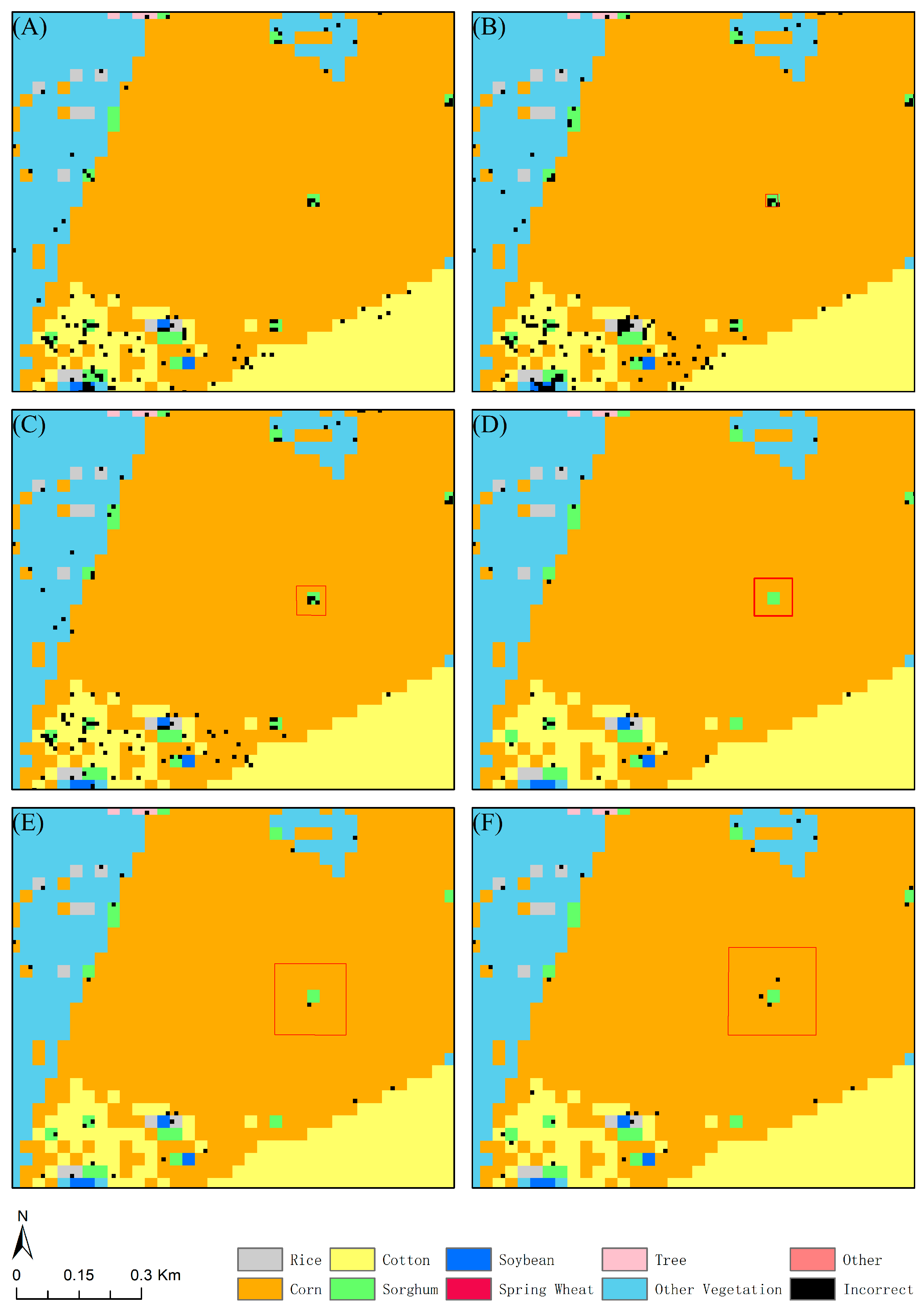
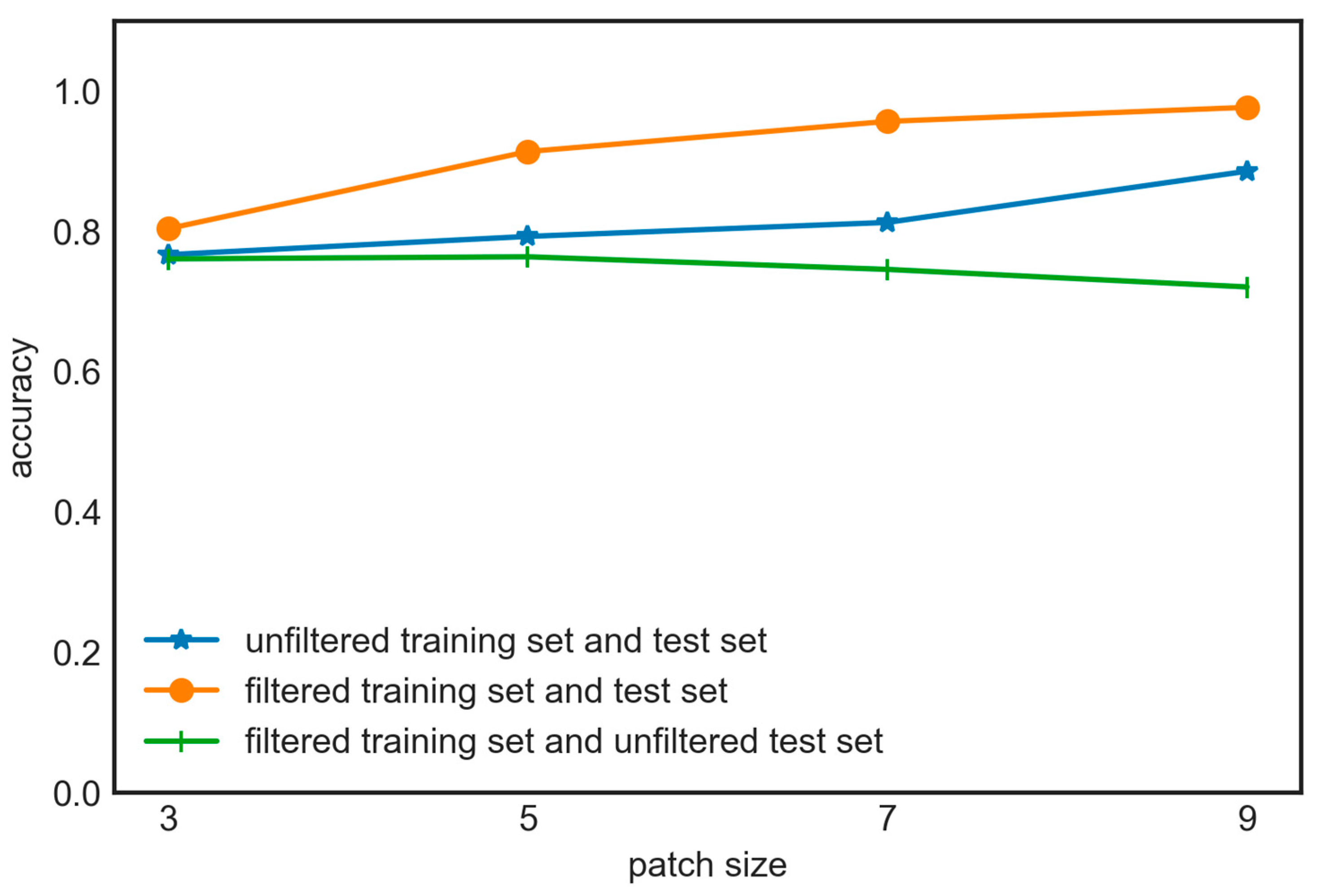
5.2. Influence of Patch Size and Dataset Filtering
- In the absence of a patch strategy, the classification model’s predictions exhibit substantial randomness due to the lack of consideration for the surrounding information.
- When employing smaller patch sizes, the coverage is limited, and the surrounding crops with a small area will occupy a relatively large proportion of the patch, increasing the spatial heterogeneity. It was found that the patch strategy proves effective when less than 50% of pixels within the patch differ from the central pixel’s category. However, when the ratio exceeds 87.5%, the patch strategy negatively impacts classification [45]. Meanwhile, smaller patches also contained limited spatial information, hindering the CNN’s ability to accurately discern crop-category distribution patterns in space. Therefore, smaller patch sizes may result in higher classification errors and increased randomness in model predictions.
- As the patch size increases, the influence of surrounding small-scale crops decreases, resulting in reduced spatial heterogeneity. This allows for the acquisition of more information on the distribution structure because of the broader coverage, ultimately enhancing the classification performance.
- When the patch is excessively large, it causes unnecessary computational resources consumption and introduces irrelevant information that could interfere with the classification process, leading to a slight decrease in accuracy. At the same time, an overly large patch may result in excessive smoothing, ignoring small or linearly distributed categories around patchy crop categories, affecting the precision and certainty of the boundaries [46].
5.3. Discussion of the Classification Performance of Each Model
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gella, G.W.; Bijker, W.; Belgiu, M. Mapping Crop Types in Complex Farming Areas Using SAR Imagery with Dynamic Time Warping. ISPRS J. Photogramm. Remote Sens. 2021, 175, 171–183. [Google Scholar] [CrossRef]
- Buckley, C.; Carney, P. The Potential to Reduce the Risk of Diffuse Pollution from Agriculture while Improving Economic Performance at Farm Level. Environ. Sci. Policy 2013, 25, 118–126. [Google Scholar] [CrossRef] [Green Version]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep Learning Classification of Land Cover and Crop Types Using Remote Sensing Data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Van Tricht, K.; Gobin, A.; Gilliams, S.; Piccard, I. Synergistic Use of Radar Sentinel-1 and Optical Sentinel-2 Imagery for Crop Mapping: A Case Study for Belgium. Remote Sens. 2018, 10, 1642. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Zhang, H. Inverse-Category-Frequency Based Supervised Term Weighting Schemes for Text Categorization. J. Inf. Sci. Eng. 2013, 29, 209–225. [Google Scholar]
- Turkoglu, M.O.; D’Aronco, S.; Perich, G.; Liebisch, F.; Streit, C.; Schindler, K.; Wegner, J.D. Crop Mapping from Image Time Series: Deep Learning with Multi-Scale Label Hierarchies. Remote Sens. Environ. 2021, 264, 112603. [Google Scholar] [CrossRef]
- Johnson, D.M.; Mueller, R. Pre- and within-Season Crop Type Classification Trained with Archival Land Cover Information. Remote Sens. Environ. 2021, 264, 112576. [Google Scholar] [CrossRef]
- Bargiel, D. A New Method for Crop Classification Combining Time Series of Radar Images and Crop Phenology Information. Remote Sens. Environ. 2017, 198, 369–383. [Google Scholar] [CrossRef]
- Guo, Y.; Jia, X.; Paull, D.; Benediktsson, J.A. Nomination-Favoured Opinion Pool for optical-SAR-synergistic Rice Mapping in Face of Weakened Flooding Signals. ISPRS J. Photogramm. Remote Sens. 2019, 155, 187–205. [Google Scholar] [CrossRef]
- Campbell, J.B.; Wynne, R.H. Introduction to Remote Sensing; Guilford Press: New York, NY, USA, 2011. [Google Scholar]
- Tufail, R.; Ahmad, A.; Javed, M.A.; Ahmad, S.R. A Machine Learning Approach for Accurate Crop Type Mapping Using Combined SAR and Optical Time Series Data. Adv. Space Res. 2022, 69, 331–346. [Google Scholar] [CrossRef]
- Cloude, S.R.; Pottier, E. A Review of Target Decomposition Theorems in Radar Polarimetry. IEEE Trans. Geosci. Remote Sens. 1996, 34, 498–518. [Google Scholar] [CrossRef]
- Cloude, S.R.; Pottier, E. An Entropy Based Classification Scheme for Land Applications of Polarimetric SAR. IEEE Trans. Geosci. Remote Sens. 1997, 35, 68–78. [Google Scholar] [CrossRef]
- Freeman, A.; Durden, S.L. A Three-Component Scattering Model for Polarimetric SAR Data. IEEE Trans. Geosci. Remote Sens. 1998, 36, 963–973. [Google Scholar] [CrossRef] [Green Version]
- Huynen, J.R. Phenomenological Theory of Radar Targets. Ph.D. Thesis, Faculty of Electrical Engineering, Mathematics and Computer Science, Delft, The Netherlands, 1970. [Google Scholar]
- Hoang, H.K.; Bernier, M.; Duchesne, S.; Tran, Y.M. Rice Mapping Using RADARSAT-2 Dual-And Quad-Pol Data in a Complex Land-Use Watershed: Cau River Basin (Vietnam). IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3082–3096. [Google Scholar] [CrossRef]
- Lopez-Sanchez, J.M.; Ballester-Berman, J.D.; Hajnsek, I. First Results of Rice Monitoring Practices in Spain by Means of Time Series of TerraSAR-X Dual-Pol Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2010, 4, 412–422. [Google Scholar] [CrossRef]
- Shao, Y.; Fan, X.; Liu, H.; Xiao, J.; Ross, S.; Brisco, B.; Brown, R.; Staples, G. Rice Monitoring and Production Estimation Using Multitemporal RADARSAT. Remote Sens. Environ. 2001, 76, 310–325. [Google Scholar] [CrossRef]
- Lasko, K.; Vadrevu, K.P.; Tran, V.T.; Justice, C. Mapping Double and Single Crop Paddy Rice with Sentinel-1A at Varying Spatial Scales and Polarizations in Hanoi, Vietnam. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 498–512. [Google Scholar] [CrossRef]
- Phan, A.; NHa, D.; DMan, C.; TNguyen, T.; QBui, H.; TNNguyen, T. Rapid Assessment of Flood Inundation and Damaged Rice Area in Red River Delta from Sentinel 1A Imagery. Remote Sens. 2019, 11, 2034. [Google Scholar] [CrossRef] [Green Version]
- Ndikumana, E.; Ho Tong Minh, D.; Baghdadi, N.; Courault, D.; Hossard, L. Deep Recurrent Neural Network for Agricultural Classification Using Multitemporal SAR Sentinel-1 for Camargue, France. Remote Sens. 2018, 10, 1217. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Lin, H.; Wang, G.; Sun, H.; Fu, J. Mapping Paddy Rice Using a Convolutional Neural Network (CNN) with Landsat 8 Datasets in the Dongting Lake Area, China. Remote Sens. 2018, 10, 1840. [Google Scholar] [CrossRef] [Green Version]
- Connor, J.T.; Martin, R.D.; Atlas, L.E. Recurrent Neural Networks and Robust Time Series Prediction. IEEE Trans. Neural Netw. 1994, 5, 240–254. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Mou, L.; Bruzzone, L.; Zhu, X.X. Learning Spectral-Spatial-Temporal Features Via a Recurrent Convolutional Neural Network for Change Detection in Multispectral Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 57, 924–935. [Google Scholar] [CrossRef] [Green Version]
- Qiao, M.; He, X.; Cheng, X.; Li, P.; Luo, H.; Zhang, L.; Tian, Z. Crop Yield Prediction from Multi-Spectral, Multi-Temporal Remotely Sensed Imagery Using Recurrent 3D Convolutional Neural Networks. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102436. [Google Scholar] [CrossRef]
- Sharma, A.; Liu, X.; Yang, X.; Shi, D. A Patch-Based Convolutional Neural Network for Remote Sensing Image Classification. Neural Netw. 2017, 95, 19–28. [Google Scholar] [CrossRef]
- Thorp, K.R.; Drajat, D. Deep Machine Learning with Sentinel Satellite Data to Map Paddy Rice Production Stages across West Java, Indonesia. Remote Sens. Environ. 2021, 265, 112679. [Google Scholar] [CrossRef]
- Kussul, N.; Lemoine, G.; Gallego, F.J.; Skakun, S.V.; Lavreniuk, M.; Shelestov, A.Y. Parcel-Based Crop Classification in Ukraine Using Landsat-8 Data and Sentinel-1A Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2500–2508. [Google Scholar] [CrossRef]
- Carranza-García, M.; García-Gutiérrez, J.; Riquelme, J.C. A Framework for Evaluating Land Use and Land Cover Classification Using Convolutional Neural Networks. Remote Sens. 2019, 11, 274. [Google Scholar] [CrossRef] [Green Version]
- Gillespie, T.J.; Brisco, B.; Brown, R.J.; Sofko, G.J. Radar Detection of a Dew Event in Wheat. Remote Sens. Environ. 1990, 33, 151–156. [Google Scholar] [CrossRef]
- Wei, P.; Chai, D.; Lin, T.; Tang, C.; Du, M.; Huang, J. Large-Scale Rice Mapping under Different Years Based on Time-Series Sentinel-1 Images Using Deep Semantic Segmentation Model. ISPRS J. Photogramm. Remote Sens. 2021, 174, 198–214. [Google Scholar] [CrossRef]
- Xu, J.; Zhu, Y.; Zhong, R.; Lin, Z.; Xu, J.; Jiang, H.; Huang, J.; Li, H.; Lin, T. DeepCropMapping: A Multi-Temporal Deep Learning Approach with Improved Spatial Generalizability for Dynamic Corn and Soybean Mapping. Remote Sens. Environ. 2020, 247, 111946. [Google Scholar] [CrossRef]
- Zhong, L.; Gong, P.; Biging, G.S. Efficient Corn and Soybean Mapping with Temporal Extendability: A Multi-Year Experiment Using Landsat Imagery. Remote Sens. Environ. 2014, 140, 1–13. [Google Scholar] [CrossRef]
- Filipponi, F. Sentinel-1 GRD Preprocessing Workflow. Proceedings 2019, 18, 11. [Google Scholar]
- Nasirzadehdizaji, R.; Balik Sanli, F.; Abdikan, S.; Cakir, Z.; Sekertekin, A.; Ustuner, M. Sensitivity Analysis of Multi-Temporal Sentinel-1 SAR Parameters to Crop Height and Canopy Coverage. Appl. Sci. 2019, 9, 655. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Ding, Q.; Luo, H.; Hui, B.; Chang, Z.; Zhang, J. Infrared Small Target Detection Based on an Image-Patch Tensor Model. Infrared Phys. Technol. 2019, 99, 55–63. [Google Scholar] [CrossRef]
- Kim, W.; Lee, D.; Kim, Y.; Kim, T.; Lee, H. Path Detection for Autonomous Traveling in Orchards Using Patch-Based CNN. Comput. Electron. Agric. 2020, 175, 105620. [Google Scholar] [CrossRef]
- Dietterich, T.G. An Experimental Comparison of Three Methods for Constructing Ensembles of Decision Trees: Bagging, Boosting and Randomization. Mach Learn. 1998, 32, 1–22. [Google Scholar]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in Vegetation Remote Sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Ji, S.; Zhang, C.; Xu, A.; Shi, Y.; Duan, Y. 3D Convolutional Neural Networks for Crop Classification with Multi-Temporal Remote Sensing Images. Remote Sens. 2018, 10, 75. [Google Scholar] [CrossRef] [Green Version]
- Zhang, B.; Zhao, L.; Zhang, X. Three-Dimensional Convolutional Neural Network Model for Tree Species Classification Using Airborne Hyperspectral Images. Remote Sens. Environ. 2020, 247, 111938. [Google Scholar] [CrossRef]
- Rußwurm, M.; Korner, M. Temporal Vegetation Modelling Using Long Short-Term Memory Networks for Crop Identification from Medium-Resolution Multi-Spectral Satellite Images. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.; Wong, W.; Woo, W. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28, 802–810. [Google Scholar]
- Ding, Y.P. Dryland Crop Classification and Acreage Estimation Based on Microwave Remote Sensing; Chinese Academy of Agricultural Science: Beijing, China, 2013. [Google Scholar]
- Song, H.; Kim, Y.; Kim, Y. A Patch-Based Light Convolutional Neural Network for Land-Cover Mapping Using Landsat-8 Images. Remote Sens. 2019, 11, 114. [Google Scholar] [CrossRef] [Green Version]
- Jiang, T.; Wang, X. Convolutional Neural Network for GF-2 Image Stand Type Classification. J. Beijing For. Univ. 2019, 41, 20–29. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories Used for Classification | Original Categories |
|---|---|
| Rice | Rice |
| Corn | Corn |
| Cotton | Cotton |
| Sorghum | Sorghum |
| Soybean | Soybean |
| Spring Wheat | Spring Wheat |
| Tree | Pecans, Peaches, Deciduous Forest, Evergreen Forest, Mixed Forest, Woody Wetlands, Olives |
| Other Vegetation | Sunflower, Winter Wheat, Rye, Oats, Millet, Canola, Alfalfa, Other Hay/Non Alfalfa, Dry Beans, Other Crops, Sugarcane, Watermelons, Onions, Peas, Herbs, Sod/Grass Seed, Fallow/Idle Cropland, Citrus, Barren, Shrubland, Grassland/Pasture, Herbaceous Wetlands, Triticale, Squash, Dbl Crop WinWht/Corn, Dbl Crop WinWht/Sorghum, Dbl Crop WinWht/Cotton, Cabbage, etc. |
| Other | Aquaculture, Open Water, Developed/High Intensity |
| Crop Categories | Sample Size before Balancing | Sample Size after Balancing | |||
|---|---|---|---|---|---|
| Training Set | Validation Set | Test Set | Count | ||
| Rice | 383,226 | 6844 | 2300 | 2197 | 11,341 |
| Corn | 394,467 | 6876 | 2284 | 2243 | 11,403 |
| Cotton | 127,878 | 7267 | 2404 | 2333 | 12,004 |
| Sorghum | 21,384 | 6394 | 2072 | 2178 | 10,644 |
| Soybean | 13,569 | 7531 | 2454 | 2456 | 12,441 |
| Spring Wheat | 25,110 | 7705 | 2483 | 2463 | 12,651 |
| Tree | 297,288 | 8792 | 2973 | 2832 | 14,597 |
| Other Vegetation | 1,139,072 | 6638 | 2233 | 2256 | 11,127 |
| Other | 12,006 | 6845 | 2296 | 2388 | 11,529 |
| Count | 2,414,000 | 64,892 | 21,499 | 21,346 | 107,737 |
| Model | Layers | Output Shape |
|---|---|---|
| Conv3d | Input | t × p × p × m |
| Conv3d | t × p × p × 32 | |
| Average Pooling | t × (p/2) × (p/2) × 32 | |
| Conv3d | t × (p/2) × (p/2) × 64 | |
| Average Pooling | t × (p/4) × (p/4) × 64 | |
| Conv3d | t × (p/4) × (p/4) × 128 | |
| Average Pooling | t × (p/8) × (p/8) × 128 | |
| Conv3d | t × (p/8) × (p/8) × 256 | |
| Average Pooling | t × (p/16) × (p/16) × 256 | |
| Flatten | 7680 | |
| Dense | n | |
| Conv1d | Input | t × m |
| Conv1d | t × 32 | |
| Conv1d | t × 64 | |
| Conv1d | t × 128 | |
| Conv1d | t × 256 | |
| Flatten | 7680 | |
| Dense | n |
| Model | Layers | Output Shape |
|---|---|---|
| Conv2d + LSTM | Input | t × p × p × m |
| Time-Distributed Conv2d | t × p × p × 32 | |
| Time-Distributed Max Pooling | t × (p/2) × (p/2) × 32 | |
| Time-Distributed Conv2d | t × (p/2) × (p/2) × 64 | |
| Time-Distributed Max Pooling | t × (p/4) × (p/4) × 64 | |
| Time-Distributed Conv2d | t × (p/4) × (p/4) × 128 | |
| Time-Distributed Max Pooling | t × (p/8) × (p/8) × 128 | |
| Time-Distributed Conv2d | t × (p/8) × (p/8) × 256 | |
| Time-Distributed Max Pooling | t × (p/16) × (p/16) × 256 | |
| Time-Distributed Flatten | t × 256 | |
| LSTM | t | |
| Dense | n | |
| ConvLSTM2d | Input | t × p × p × m |
| ConvLSTM2d | t × p × p × 32 | |
| Time-Distributed Max Pooling | t × (p/2) × (p/2) × 32 | |
| ConvLSTM2d | t × (p/2) × (p/2) × 64 | |
| Time-Distributed Max Pooling | t × (p/4) × (p/4) × 64 | |
| ConvLSTM2d | t × (p/4) × (p/4) × 128 | |
| Time-Distributed Max Pooling | t × (p/8) × (p/8) × 128 | |
| ConvLSTM2d | t × (p/8) × (p/8) × 256 | |
| Time-Distributed Max Pooling | t × (p/16) × (p/16) × 256 | |
| Flatten | 7680 | |
| Dense | n |
| Model | Input | Accuracy | Kappa |
|---|---|---|---|
| Conv3d | All features | 88.9% | 0.875 |
| Anisotropy, Entropy, Alpha | 88.4% | 0.870 | |
| VH, VV | 88.9% | 0.875 | |
| VV + VH, VH/VV | 88.9% | 0.874 | |
| Conv2d + LSTM | All features | 84.3% | 0.823 |
| Anisotropy, Entropy, Alpha | 82.4% | 0.802 | |
| VH, VV | 80.2% | 0.777 | |
| VV + VH, VH/VV | 78.5% | 0.758 | |
| Conv1d | All features | 78.2% | 0.754 |
| Anisotropy, Entropy, Alpha | 74.3% | 0.710 | |
| VH, VV | 68.8% | 0.648 | |
| VV + VH, VH/VV | 68.4% | 0.643 |
| Model | Accuracy | Kappa | Training Duration |
|---|---|---|---|
| Conv3d | 88.9% | 0.875 | 13 h |
| Conv2d + LSTM | 84.3% | 0.823 | 17 h |
| ConvLSTM2d | 85.5% | 0.837 | 13 h |
| LSTM | 68.7% | 0.647 | 35 h |
| Conv1d | 78.2% | 0.754 | 6 h |
| Random Forest | 81.3% | 0.790 | 0.13 h |
| Class Name | Predicted | Precision | Recall | F1-Score | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Rice | Corn | Cotton | Sorghum | Soybeans | Sprint Wheat | Tree | Other Vegetation | Other | Total | |||||
| Observed | Rice | 1832 | 50 | 47 | 35 | 24 | 32 | 27 | 125 | 25 | 2197 | 0.88 | 0.83 | 0.86 |
| Corn | 53 | 1865 | 51 | 72 | 23 | 10 | 64 | 93 | 12 | 2243 | 0.88 | 0.83 | 0.85 | |
| Cotton | 40 | 45 | 1983 | 62 | 119 | 8 | 11 | 60 | 5 | 2333 | 0.90 | 0.85 | 0.87 | |
| Sorghum | 10 | 36 | 21 | 2039 | 37 | 4 | 7 | 21 | 3 | 2178 | 0.88 | 0.94 | 0.91 | |
| Soybeans | 0 | 4 | 2 | 4 | 2444 | 0 | 0 | 0 | 2 | 2456 | 0.90 | 1.00 | 0.95 | |
| Sprint Wheat | 6 | 2 | 5 | 11 | 3 | 2430 | 0 | 6 | 0 | 2463 | 0.96 | 0.99 | 0.97 | |
| Tree | 18 | 28 | 15 | 25 | 15 | 0 | 2515 | 170 | 46 | 2832 | 0.87 | 0.89 | 0.88 | |
| Other Vegetation | 127 | 98 | 77 | 73 | 46 | 45 | 274 | 1494 | 22 | 2256 | 0.76 | 0.66 | 0.71 | |
| Other | 1 | 2 | 1 | 1 | 1 | 0 | 2 | 0 | 2380 | 2388 | 0.95 | 1.00 | 0.97 | |
| Total | 2087 | 2130 | 2202 | 2322 | 2712 | 2529 | 2900 | 1969 | 2495 | 21,346 | ||||
| Crop Categories | Without Filter Strategy | With Filter Strategy | ||||
|---|---|---|---|---|---|---|
| Training Set | Validation Set | Test Set | Training Set | Validation Set | Test Set | |
| Rice | 6844 | 2300 | 2197 | 7211 | 2442 | 2371 |
| Corn | 6876 | 2284 | 2243 | 9005 | 3049 | 2987 |
| Cotton | 7267 | 2404 | 2333 | 5009 | 1660 | 1619 |
| Sorghum | 6394 | 2072 | 2178 | 3546 | 1163 | 1180 |
| Soybean | 7531 | 2454 | 2456 | 2769 | 904 | 855 |
| Spring Wheat | 7705 | 2483 | 2463 | 5017 | 1588 | 1589 |
| Tree | 8792 | 2973 | 2832 | 6144 | 2087 | 2003 |
| Other Vegetation | 6638 | 2233 | 2256 | 5656 | 1912 | 1936 |
| Other | 6845 | 2296 | 2388 | 2072 | 689 | 706 |
| Count | 64,892 | 21,499 | 21,346 | 46,429 | 15,494 | 15,246 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Pu, X.; Shen, Z. Crop Type Mapping Based on Polarization Information of Time Series Sentinel-1 Images Using Patch-Based Neural Network. Remote Sens. 2023, 15, 3384. https://doi.org/10.3390/rs15133384
Liu Y, Pu X, Shen Z. Crop Type Mapping Based on Polarization Information of Time Series Sentinel-1 Images Using Patch-Based Neural Network. Remote Sensing. 2023; 15(13):3384. https://doi.org/10.3390/rs15133384
Chicago/Turabian StyleLiu, Yuying, Xuecong Pu, and Zhangquan Shen. 2023. "Crop Type Mapping Based on Polarization Information of Time Series Sentinel-1 Images Using Patch-Based Neural Network" Remote Sensing 15, no. 13: 3384. https://doi.org/10.3390/rs15133384