
Dual-View Hyperspectral Anomaly Detection via Spatial Consistency and Spectral Unmixing

Abstract
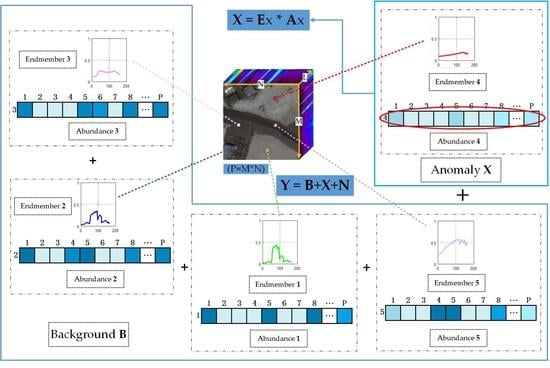
:
1. Introduction
- (1)
- A dual-view anomaly detection method via spatial consistency and spectral unmixing from the pixel level and subpixel level is presented, which makes full use of the local and global information in the HSI.
- (2)
- Taking the characteristics of the HSI into account, a novel manifold-based sparse spectral unmixing algorithm is put forward.
- (3)
- This paper proposes, for the first time, that the difference between the anomaly and background mainly comes from the difference of endmembers based on the subpixel level analysis.
2. Theoretical Background
3. Dual-View Anomaly Hyperspectral Detection via Spatial Consistency and Spectral Unmixing
3.1. Pixel Level Anomaly Detection via Spatial Consistency
- (a)
- The center pixel is the anomaly, and the neighbor pixels are the background. The SAD values are all large, and the center pixel with a large sum of SAD values is deemed as the anomaly pixel.
- (b)
- The center pixel is the anomaly, and the neighbor pixels contain a small number of anomalies. However, most neighbor pixels are still the background. Thus, most of the SAD values are large, and the center pixel with a large sum of SAD values is also detected as the anomaly.
- (c)
- The center pixel is the background, and the neighbor pixels are the background. The SAD values are all small, which illustrates the similarity of the center pixel to its neighbors. The center pixel with a small sum of SAD values is viewed as the background.
- (d)
- The center pixel is the background, and the neighbor pixels contain a small number of anomalies. Most of the neighbor pixels are the background, and the corresponding SAD values are small. The center pixel with a small sum of SAD values is detected as the background.
3.2. Subpixel Level Anomaly Detection via Spectral Unmixing
3.2.1. Manifold-Constrained Sparse Spectral Unmixing
3.2.2. Subpixel Level Anomaly Detection
3.3. Fusion for Pixel and Subpixel Levels Anomaly Detection
4. Experiments Results
4.1. Data Set
4.2. Comparison Methods and Performance Metrics
4.3. Anomaly Detection Performance
4.4. Parameter Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Stein, A.D.W.J.; Beaven, S.G.; Hoff, L.E.; Winter, E.M.; Schaum, A.P.; Stocker, A.D. Anomaly detection from hyperspectral imagery. IEEE Signal Process. Mag. 2002, 19, 58–69. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Zhang, J.; Li, C.; Cheng, C.; Jiao, L.; Zhou, H. Hybrid unmixing based on adaptive region segmentation for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3861–3875. [Google Scholar] [CrossRef] [Green Version]
- Kang, X.; Zhang, X.; Li, S.; Li, K.; Li, J.; Benediktsson, J.A. Hyperspectral anomaly detection with attribute edge-preserving filters. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5600–5611. [Google Scholar] [CrossRef]
- Zhang, X.; Song, Q.; Liu, R.; Wang, W.; Jiao, L. Modified co-training with spectral spatial views for semi-supervised hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2014, 7, 2044–2055. [Google Scholar] [CrossRef]
- Zhang, X.; Gao, Z.; Jiao, L.; Zhou, H. Multifeature hyperspectral image classification with local nonlocal spatial information via Markovrom field in semantic space. IEEE Trans. Geosci. Remote Sens. 2018, 56, 1409–1424. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Zhang, X.; Jiao, L. Sparse nonnegative matrix factorization for hyperspectral unmixing based on endmember independence spatial weighted abundance. Remote Sensing. 2021, 13, 2348. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, Y.; Zhang, J.; Wu, P.; Jiao, L. Hyperspectral unmixing via deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1755–1759. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- Roy, S.K.; Deria, A.; Shah, C.; Haut, J.M.; Du, Q.; Plaza, A. Spectral-spatial morphological attention transformer for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5503615. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, Z.; Li, J.; Plaza, A.; Wei, Z. Anomaly detection in hyperspectral images based on low-rank sparse representation. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1990–2000. [Google Scholar] [CrossRef]
- Huyan, N.; Zhang, X.; Zhou, H.; Jiao, L. Hyperspectral anomaly detection via background potential anomaly dictionaries construction. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2263–2276. [Google Scholar] [CrossRef] [Green Version]
- Shang, X.; Song, M.; Wang, Y.; Yu, C.; Yu, H.; Li, F.; Chang, C.-I. Target-constrained interference-minimized selection for hyperspectral target detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6044–6064. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, X.; Wang, F.; Song, M.; Yu, C. Meta-learning based hyperspectral target detection using siamese network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5527913. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, X.; Tang, X.; Chen, P.; Jiao, L. Sketch-based region adaptive sparse unmixing applied to hyperspectral image. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8840–8856. [Google Scholar] [CrossRef]
- Cheng, T.; Wang, B. Total variation sparsity regularized decomposition model with union dictionary for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1472–1486. [Google Scholar] [CrossRef]
- Lv, C.; Shen, F.; Zhang, Z.; Zhang, F. Review of image anomaly detection. Acta Autom. Sin. 2022, 48, 1402–1428. [Google Scholar]
- Reed, I.S.; Yu, X. Adaptive multiple-band CFAR detection of an optical pattern with unknown spectral distribution. IEEE Trans. Acoust. Speech Signal Process. 1990, 38, 1760–1770. [Google Scholar] [CrossRef]
- Molero, J.M.; Garzón, E.M.; García, I.; Plaza, A. Analysis and optimizations of global and local versions of the RX algorithm for anomaly detection in hyperspectral data. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2013, 6, 801–814. [Google Scholar] [CrossRef]
- Guo, Q.; Zhang, B.; Ran, Q.; Gao, L.; Li, J.; Plaza, A. Weighted-RXD and linear filter-based RXD: Improving background statistics estimation for anomaly detection in hyperspectral imagery. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2014, 7, 2351–2366. [Google Scholar] [CrossRef]
- Kwon, H.; Nasrabadi, N.M. Kernel RX-algorithm: A nonlinear anomaly detector for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2005, 43, 388–397. [Google Scholar] [CrossRef]
- Zhou, J.; Kwan, C.; Ayhan, B.; Eismann, M.T. A novel cluster kernel RX algorithm for anomaly change detection using hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6497–6504. [Google Scholar] [CrossRef]
- Khazai, S.; Safari, A.; Mojaradi, B.; Homayouni, S. An approach for subpixel anomaly detection in hyperspectral images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 769–778. [Google Scholar] [CrossRef]
- Schweizer, S.M.; Moura, J.M.F. Hyperspectral imagery: Clutter adaptation in anomaly detection. IEEE Trans. Inf. Theory 2000, 46, 1855–1871. [Google Scholar] [CrossRef] [Green Version]
- Su, H.; Wu, Z.; Zhang, H.; Du, Q. Hyperspectral anomaly detection: A survey. IEEE Geosci. Remote Sens. Mag. 2022, 10, 64–90. [Google Scholar] [CrossRef]
- Olkopf, B.S.; Williamson, R.; Smola, A.; Shawe-Taylor, J.; Platt, J. Support vector method for novelty detection. Adv. Neural Inf. Process. Syst. 2000, 12, 582–588. [Google Scholar]
- Banerjee, A.; Burlina, P.; Diehl, C. A support vector method for anomaly detection in hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2282–2291. [Google Scholar] [CrossRef]
- Carlotto, M.J. A cluster-based approach for detecting man-made objects and changes in imagery. IEEE Trans. Geosci. Remote Sens. 2005, 43, 374–387. [Google Scholar] [CrossRef]
- Hytla, P.C.; Hardie, R.C.; Eismann, M.T.; Meola, J. Anomaly detection in hyperspectral imagery: Comparison of methods using diurnal and seasonal data. J. Appl. Remote Sens. 2009, 3, 033546. [Google Scholar] [CrossRef]
- Li, J.; Zhang, H.; Zhang, L.; Ma, L. Hyperspectral anomaly detection by the use of background joint sparse representation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2523–2533. [Google Scholar] [CrossRef]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. In Proceedings of the ACM Sigmod International Conference on Management of Data, Dallas, TX, USA, 15–18 May 2000; ACM: New York, NY, USA, 2000. [Google Scholar]
- Nowak-Brzezińska, A.; Horyń, C. Outliers in rules—The comparision of LOF, COF and KMEANS algorithms. Procedia Comput. Sci. 2020, 176, 1420–1429. [Google Scholar] [CrossRef]
- Lin, S.; Zhang, M.; Cheng, X.; Zhou, K.; Zhao, S.; Wang, H. Hyperspectral anomaly detection via sparse representation and collaborative representation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 946–961. [Google Scholar] [CrossRef]
- Li, W.; Du, Q. Collaborative representation for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1463–1474. [Google Scholar] [CrossRef]
- Su, H.; Wu, Z.; Du, Q.; Du, P. Hyperspectral anomaly detection using collaborative representation with outlier removal. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2018, 11, 5029–5038. [Google Scholar] [CrossRef]
- Pang, G.; Shen, C.; Cao, L.; Anton, V. Deep learning for anomaly detection: A review. ACM Comput. Surv. 2022, 54, 1–38. [Google Scholar] [CrossRef]
- Li, W.; Wu, G.; Du, Q. Transferred deep learning for anomaly detection in hyperspectral imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 597–601. [Google Scholar] [CrossRef]
- Song, S.; Zhou, H.; Yang, Y.; Song, J. Hyperspectral anomaly detection via convolutional neural network and low rank with density-based clustering. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3637–3649. [Google Scholar] [CrossRef]
- Li, K.; Ling, Q.; Wang, Y.; Cai, Y.; Qin, Y.; Lin, Z.; An, W. Spectral difference guided graph attention autoencoder for hyperspectral anomaly detection. IEEE Trans. Instrum. Meas. 2023, 72, 5001817. [Google Scholar] [CrossRef]
- Wang, L.; Wang, X.; Vizziello, A.; Gamba, P. RSAAE: Residual self-attention-based autoencoder for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5510614. [Google Scholar] [CrossRef]
- Qu, Y.; Wang, W.; Guo, R.; Ayhan, B.; Kwan, C.; Vance, S.; Qi, H. Hyperspectral anomaly detection through spectral unmixing and dictionary-based low-rank decomposition. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4391–4405. [Google Scholar] [CrossRef]
- Huang, Z.; Fang, L.; Li, S. Subpixel-pixel-superpixel guided fusion for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5998–6007. [Google Scholar] [CrossRef]
- Erdinç, A.; Aksoy, S. Anomaly detection with sparse unmixing and Gaussian mixture modeling of hyperspectral images. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 5035–5038. [Google Scholar]
- Zhang, X.; Li, C.; Zhang, J.; Chen, Q.; Feng, J.; Jiao, L.; Zhou, H. Hyperspectral unmixing via low-rank representation with space consistency constraint and spectral library pruning. Remote Sens. 2018, 10, 339. [Google Scholar] [CrossRef] [Green Version]
- Qian, Y.; Jia, S.; Zhou, J.; Robles-Kelly, A. Hyperspectral unmixing via L1/2 sparsity-constrained nonnegative matrix factorization. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4282–4297. [Google Scholar] [CrossRef] [Green Version]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by nonnegative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef]
- Fang, H.; Li, A.; Xu, H.; Wang, T. Sparsity-constrained deep nonnegative matrix factorization for hyperspectral unmixing. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1105–1109. [Google Scholar] [CrossRef]
- Rajabi, R.; Ghassemian, H. Spectral unmixing of hyperspectral imagery using multilayer NMF. IEEE Geosci. Remote Sens. Lett. 2015, 12, 38–42. [Google Scholar] [CrossRef] [Green Version]
- Lu, X.; Wu, H.; Yuan, Y.; Yan, P.; Li, X. Manifold regularized sparse NMF for hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2815–2826. [Google Scholar] [CrossRef]
- Cai, D.; He, X.; Han, J. Document clustering using locality preserving indexing. IEEE Trans. Knowl. Data Eng. 2005, 17, 1624–1637. [Google Scholar] [CrossRef] [Green Version]
- Du, B.; Zhao, R.; Zhang, L.; Zhang, L. A spectral-spatial based local summation anomaly detection method for hyperspectral images. Signal Process. 2016, 124, 115–131. [Google Scholar] [CrossRef]
- Zhang, Y.; Du, B.; Zhang, L. Regularization framework for target detection in hyperspectral imagery. IEEE Geosci. Remote Sens. Lett. 2014, 11, 313–317. [Google Scholar] [CrossRef]
- Zhao, R.; Du, B.; Zhang, L. Hyperspectral anomaly detection via a sparsity score estimation framework. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3208–3222. [Google Scholar] [CrossRef]
- Ma, L.; Crawford, M.M.; Tian, J. Local manifold learning based k-nearest-neighbor for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2010, 48, 4099–4109. [Google Scholar] [CrossRef]
- Liu, X.; Tanaka, M.; Okutomi, M. Single-image noise level estimation for blind denoising. IEEE Trans. Image Process. 2013, 22, 5226–5237. [Google Scholar] [CrossRef]
- Xing, Y.; Gomez, R.B. Hyperspectral image analysis using ENVI (environment for visualizing images). Proc. SPIE 2001, 4383, 79–87. [Google Scholar]
- Kerekes, J. Receiver operating characteristic curve confidence intervals and regions. IEEE Geosci. Remote Sens. Lett. 2008, 5, 251–255. [Google Scholar] [CrossRef] [Green Version]
- Bioucas-Dias, J.M.; Nascimento, J.M.P. Hyperspectral subspace identification. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2435–2445. [Google Scholar] [CrossRef] [Green Version]
- Nascimento, J.M.P.; Dias, J.M.B. Vertex component analysis: A fast algorithm to unmix hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 898–910. [Google Scholar] [CrossRef] [Green Version]
- Heinz, D.C.; Chang, C.-I. Fully constrained least squares linear spectral mixture analysis method for material quantification in hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2001, 39, 529–545. [Google Scholar] [CrossRef] [Green Version]
- He, W.; Zhang, H.; Zhang, L. Total variation regularized reweighted sparse nonnegative matrix factorization for hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3909–3921. [Google Scholar] [CrossRef]
- Tong, L.; Zhou, J.; Li, X.; Qian, Y.; Gao, Y. Region-based structure preserving nonnegative matrix factorization for hyperspectral unmixing. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2017, 10, 1575–1588. [Google Scholar] [CrossRef] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | GRX | LRX | OCSVM | CRD | ADLR | DVAD | |
|---|---|---|---|---|---|---|---|
| San Diego | AUC | 0.9055 | 0.7624 | 0.8888 | 0.9587 | 0.9577 | 0.9847 |
| Time(s) | 1.24 | 33.59 | 1691.02 | 45.92 | 1667.23 | 47.15 | |
| HYDICE | AUC | 0.9857 | 0.9605 | 0.6738 | 0.9935 | 0.9335 | 0.9880 |
| Time(s) | 0.07 | 22.37 | 168.70 | 24.56 | 5897.29 | 27.50 | |
| Texas | AUC | 0.9910 | 0.9827 | 0.8743 | 0.9890 | 0.9641 | 0.9950 |
| Time(s) | 0.09 | 38.67 | 365.16 | 48.22 | 3858.96 | 21.62 | |
| Urban | AUC | 0.9934 | 0.9224 | 0.7861 | 0.9387 | 0.9711 | 0.9980 |
| Time(s) | 0.12 | 41.23 | 993.76 | 45.08 | 35.80 | 13.17 | |
| Data Set | Win | 1 | 3 | 5 | |
|---|---|---|---|---|---|
| Wout | |||||
| San Diego | 7 | 0.9923 | 0.9920 | 0.9910 | |
| 9 | 0.9930 | 0.9932 | 0.9928 | ||
| 11 | 0.9932 | 0.9933 | 0.9934 | ||
| HYDICE | 3 | 0.9050 | - | - | |
| 7 | 0.8407 | 0.8344 | 0.7893 | ||
| 9 | 0.8184 | 0.8188 | 0.7913 | ||
| Texas | 7 | 0.9651 | 0.9690 | 0.9675 | |
| 9 | 0.9617 | 0.9660 | 0.9674 | ||
| 11 | 0.9551 | 0.9587 | 0.9633 | ||
| Urban | 7 | 0.9044 | 0.9030 | 0.8968 | |
| 9 | 0.9079 | 0.9121 | 0.9068 | ||
| 11 | 0.9059 | 0.9108 | 0.9127 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Zhang, X.; Jiao, L. Dual-View Hyperspectral Anomaly Detection via Spatial Consistency and Spectral Unmixing. Remote Sens. 2023, 15, 3330. https://doi.org/10.3390/rs15133330
Zhang J, Zhang X, Jiao L. Dual-View Hyperspectral Anomaly Detection via Spatial Consistency and Spectral Unmixing. Remote Sensing. 2023; 15(13):3330. https://doi.org/10.3390/rs15133330
Chicago/Turabian StyleZhang, Jingyan, Xiangrong Zhang, and Licheng Jiao. 2023. "Dual-View Hyperspectral Anomaly Detection via Spatial Consistency and Spectral Unmixing" Remote Sensing 15, no. 13: 3330. https://doi.org/10.3390/rs15133330