1. Introduction
Radar observations play a vital role in today’s modern society [
1,
2,
3]. In particular, Synthetic Aperture Radar (SAR) can achieve high-resolution microwave imaging, which is seldom affected by weather and environment. Furthermore, SAR has great cloud-penetrating capability [
4,
5]. These advantages over visible optical imaging systems facilitate SAR becoming an ideal detector for high-definition, high-resolution and wide-area imagery [
6,
7]. In recent years, the demand for remote sensing observations has been steadily increasing, so that there is huge growth of the SAR imagery data. Therefore, current research focuses on how to detect the objects of interest in large amounts of SAR images.
In the past few years, SAR technology has been widely used in the field of remote sensing [
8,
9,
10], especially in the detection of ground targets [
11]. However, with the increase in resolution of SAR satellites, wide-area high-resolution SAR images have generated massive amounts of data, posing challenges for real-time target detection. This is particularly true in the field of military reconnaissance, where there is a high demand for time-sensitive surveillance [
12] and reconnaissance. Although the resolution of satellite-borne SAR is able to reach 1 m, detection of small vehicles, such as those 5 m long and 1 m wide, is still of great difficulty. In contrast, detection of large trucks and military vehicles is relatively easier.
On one hand, advanced image processing and analysis algorithms, such as deep-learning-based target detection methods [
13], can be used to improve detection performance. Deep learning techniques such as Convolutional Neural Networks (CNNs) have shown strong performance in target detection tasks in recent years. On the other hand, efficient performance is particularly important in airborne SAR systems as it can provide critical information for time-sensitive reconnaissance tasks, thereby providing valuable support for decision-makers. In order to resolve the contradiction between slow processing speed of wide-area SAR images and the demand for fast detection of time-sensitive targets, researchers are dedicated to developing more efficient detection methods. To meet the requirements for efficient performance, existing algorithms need to be optimized to reduce computational complexity and redundant calculations. This can be achieved through targeted design of lightweight neural network architectures or adoption of integrated model frameworks.
In summary, resolving the contradiction between the slow processing speed of wide-area SAR images and the demand for fast detection of time-sensitive targets is of great significance for the development of the remote sensing field. By continuously improving and optimizing detection algorithms to increase the processing speed and target detection performance of SAR images, it is hoped that stronger support can be provided for real-time reconnaissance tasks, further promoting the widespread application of remote sensing technology in both military and civilian fields.
Vehicle target detection in SAR images faces many challenges, including targets of different scales and orientations, complex backgrounds and noise [
14,
15], and the similarity in texture between vehicle targets and other ground objects due to the SAR imaging mechanism [
16]. Firstly, targets of different scales and orientations may exhibit different features and shapes in SAR images, requiring the detection algorithm to have strong scale adaptability. To solve this problem, multi-scale feature extraction and fusion methods can be used to better capture and distinguish targets of different scales. Secondly, complex backgrounds and noise have a significant impact on the accuracy of SAR vehicle target detection. The features of ground objects in complex backgrounds may interfere with vehicle targets, making it difficult for the detection algorithm to accurately identify targets. To reduce this impact, image preprocessing, feature selection and denoising methods can be used to reduce the interference of complex backgrounds and noise on detection results. In addition, due to the characteristics of the SAR imaging mechanism, the texture of vehicle targets and other ground objects in SAR images may be similar, making target detection more difficult. To address this challenge, more robust feature descriptors and deep-learning-based target detection methods can be introduced to improve the ability to distinguish targets from backgrounds. In summary, to address the challenges faced by vehicle target detection in SAR images, researchers need to consider a variety of techniques and methods to improve the accuracy and robustness of detection. By continuously improving and optimizing detection algorithms, it is hoped that efficient and accurate vehicle target detection in SAR images can be achieved under complex background and diverse target conditions.
The traditional method for target detection in SAR images is the CFAR detection method [
17,
18,
19]. However, there are many limitations to using this method. For example, it assumes that the background clutter follows a Gaussian distribution and requires a significant difference in intensity between the target and the background clutter. These limitations make the CFAR detection method [
20] perform well in simple scenarios but perform poorly in SAR image target detection tasks with complex backgrounds.
To address the issue of real-time detection, the YOLO [
21,
22,
23,
24] and SSD [
25] frameworks were developed. They achieved an integrated approach to object detection, eliminating the need to extract regions of interest. All feature extraction, detection and recognition are performed through a single neural network. However, since the target vehicles in SAR images are small, the SSD algorithm does not perform well in detecting small targets. In contrast, the YOLO series of algorithms has been continuously developed in recent years.
YOLOv5 and YOLOX [
26] are two object detection models based on the YOLO series, each with its own characteristics, suitable for different application scenarios and requirements. YOLOX is an improvement over YOLOv3, introducing a decoupled head structure, and using the anchor free anchor box method, as well as SimOTA optimal transport and other sample-matching strategies. Its advantages are high performance, and that it can achieve end-to-end detection, and its disadvantage is that the model is larger and requires more computing resources. YOLOv5 is an improvement over YOLOv4 [
24], using Focus layer, CSPDarknet53 as the backbone network, SPPF as the neck, SiLU [
27] activation function, Mosaic, Copy paste [
28] and other data augmentation methods. Its advantages are fast speed, lightweight model and support for multiple backend inference, and its disadvantage is that the detection head has not changed much, as it still uses an anchor-based method. It not only has a more sophisticated network structure but also incorporates many advanced technologies in the field of deep learning, enabling it to surpass many other algorithms in terms of detection accuracy and speed. YOLOv5 and YOLOX have similar performance on the COCO benchmark [
29], whereas YOLOv5 has a greater advantage in the trade-off of speed and performance. Therefore, we have chosen YOLOv5 as the basic detection model for vehicle target detection in SAR images under complex scenarios. It employs a convolutional neural network to automatically extract intricate features from complex SAR images, avoiding the difficulty of selecting manual features.
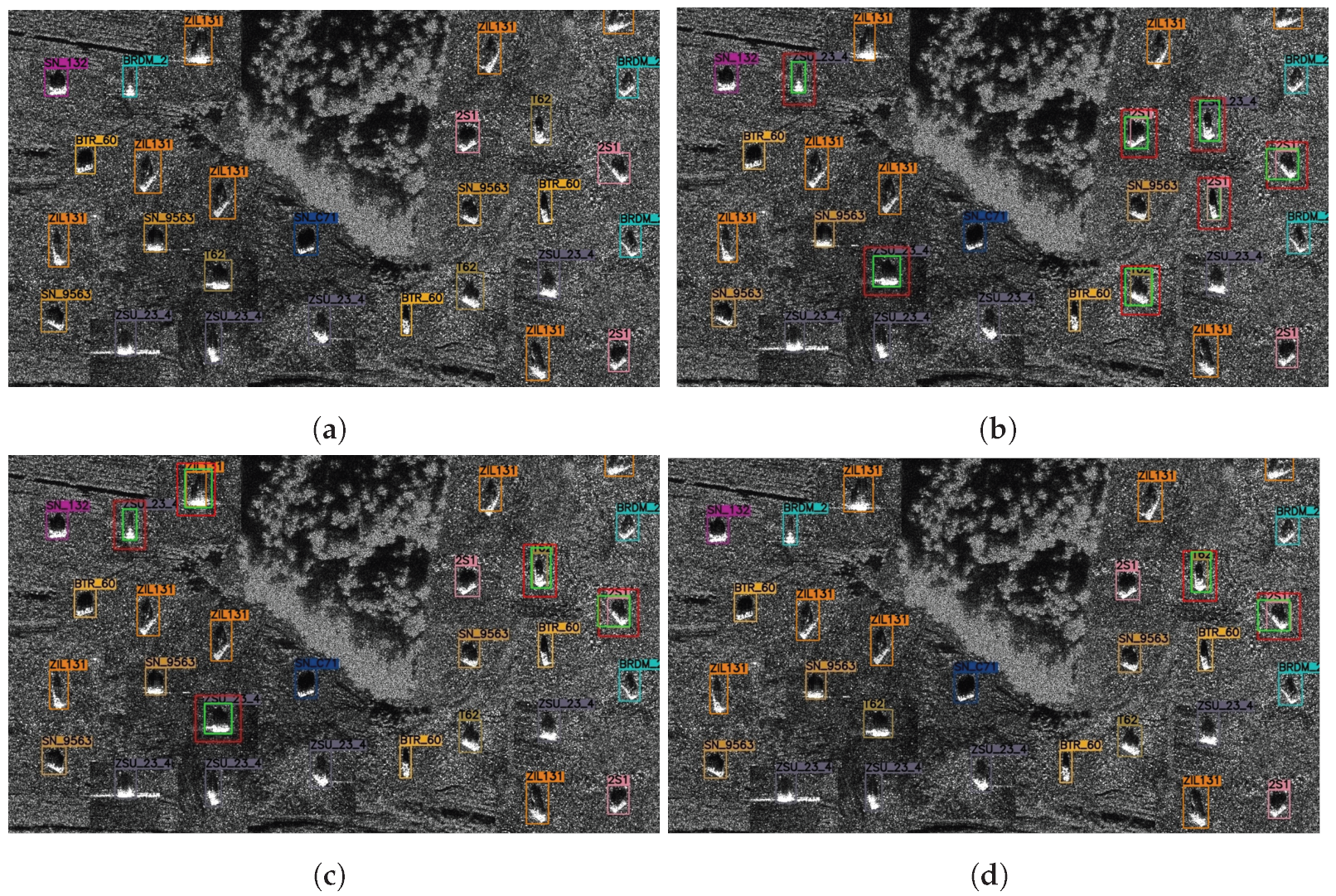
In wide-area SAR image vehicle target detection, a significant issue is the extremely uneven spatial distribution of targets within the SAR image. Most of the area in the image to be tested does not contain vehicle targets, and vehicle targets are often concentrated in scattered small areas. For example, in a wide-area image of 3274 × 2510 (as
Figure 1), vehicle targets are only concentrated in a very small area. For the wide-area SAR image, sliding-window detection of the image is most common method. For detection methods based on convolutional neural networks (CNNs), a sliding window approach is typically used to perform detection on the entire image. However, due to the uneven distribution of vehicle targets, during target detection, a large amount of computational resources and time will be wasted on detecting areas without targets. This results in a large amount of redundant computation, greatly reducing the computational efficiency of the target detection model. Moreover, it is worth noting that moving vehicles could cause defocusing in SAR images, which could not only severely affect detection performance, but also introduces additional complexities to the detection task due to the need to account for motion blur and potential object distortion. As for wide-area SAR image vehicle target detection, existing datasets [
30,
31] are mainly focused on static vehicles in remote sensing reconnaissance tasks. Therefore, our approach follows this direction and specifically is designed for stationary vehicles.
To overcome this challenge, we propose a two-stage vehicle target detection method to improve detection efficiency and reduce unnecessary computational overhead. Due to the scattering characteristics of SAR radar and the presence of speckle noise, SAR images may be affected by various noises, which makes the targets easily confused with the background noise. To address this problem, we introduce a new attention mechanism, the CAM module, into the FPN [
32] network to effectively fuse the visual features of different scales. By fully utilizing the contextual information, the interference of background noise is suppressed. Meanwhile, since the category prediction, location information and confidence score have different distributions, coupling them in one detection head will lead to slow convergence and performance degradation. As for the classical scenes of the reconnaissance task, the landform of background regions has a very similar visual appearance to vehicle targets in SAR imagery. The original coupled heads from YOLOv5 would be confronted with the difficulty of discriminating the background landform with foreground targets. To resolve this confusion issue, decoupled detection heads derived from YOLOX are adopted to separately predict the category, location and confidence, thus accelerating the model convergence speed and improving the detection accuracy.
Considering the uneven spatial distribution of vehicle targets in reconnaissance scenarios, we first use background patches for auxiliary supervision of the detection model to enhance its discrimination ability and recall rate for foreground and background. Secondly, we use our model’s foreground–background distinction mechanism to achieve a coarse judgment ability, which is used to optimize the subsequent detection process. By judging the overall category of image patches, we can avoid false positives caused by local noise and only perform detection operations on foreground image patches. On the basis of improving the detection efficiency, the model accuracy is further improved. In addition, the YOLOv5-based detection algorithm requires a large amount of data support to train a model with good detection performance, while there are not as many SAR open datasets as optical images, let alone SAR images containing vehicle targets. Therefore, adding background patches without targets to the training set can make better use of the dataset information, reduce the model’s requirement for the number of training samples and improve the model’s convergence speed.
2. Methods
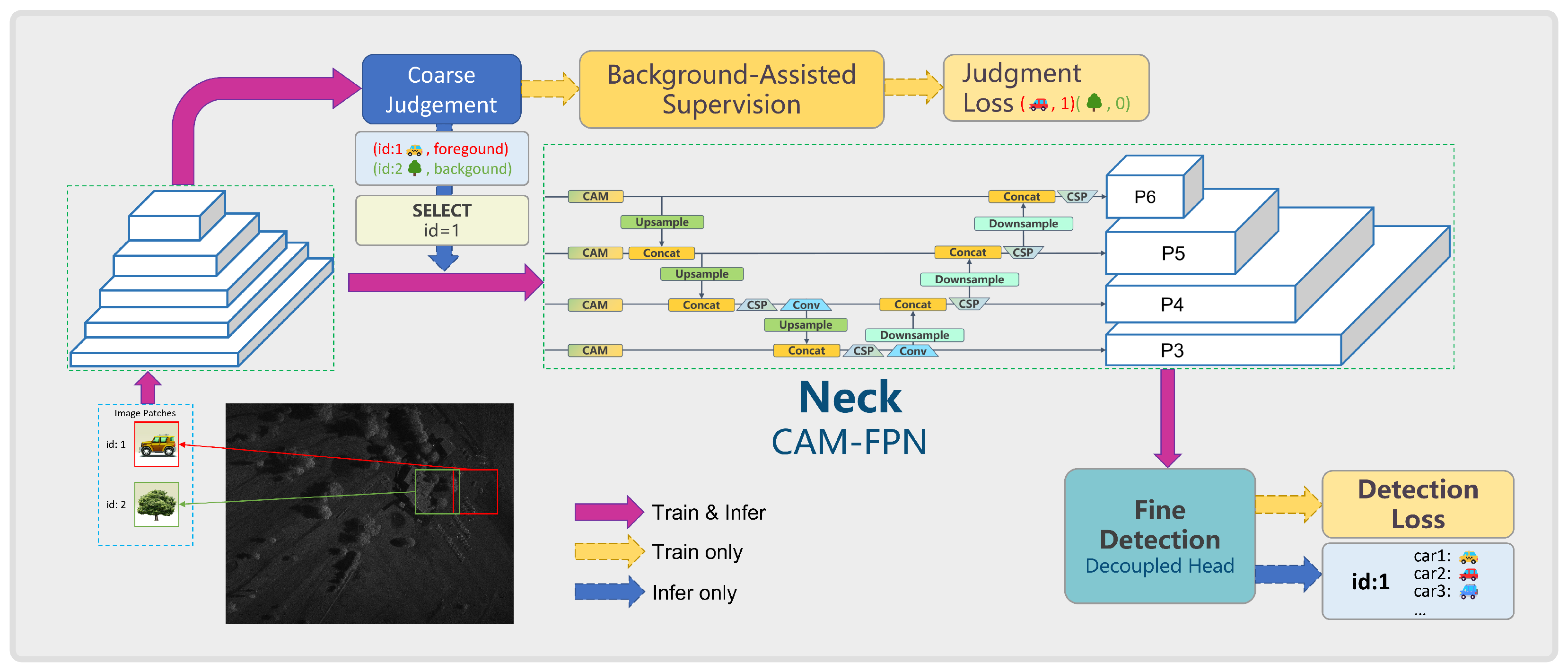
As for wide-area SAR images, the regions containing vehicle targets only account for a small portion of the entire image, whereas others belong to the background. If a patch category can be determined, it will undoubtedly save computational effort to perform target detection only on the foreground. Therefore, we propose a vehicle detection model based on a coarse-to-fine paradigm, specifically, a coarse-to-fine detection YOLO-based method with CAM Attention, named CF-YOLO. For the input patches, we first determine whether they are foreground or background, and only perform detection on foreground patches.
The proposed coarse-to-fine paradigm still involves using a sliding window to generate patches for subsequent detection, and a certain ratio of overlap is set during the sliding window process. During the detection phase, only foreground patches are subjected to detection, while background patches are not processed further in the subsequent detection operations.
The model structure proposed in this section is shown in
Figure 2 and consist of two parts: coarse judgment for foreground and background patches, and fine detection exclusively for positive patches. The coarse judgment branch determines whether the input image is a foreground or background patch. If the input image is a background patch, the detection branch is skipped; if the input image is a foreground patch, it is sent to the detection branch for vehicle target detection. The detection network and classification (judgment) network share a common feature extraction backbone. This backbone sharing can not only reduce the parameters of the whole model, compared to the independent frameworks using two different networks, but also can improve the inference speed if the judgment results can be used to optimize the detection process. Furthermore, the judgment task of fore/background will provide more abundant knowledge to the backbone to resist noise interference. In this structure, the feature extraction backbone adopts the CSPDarkNet structure of YOLOv5.
2.1. Coarse Judgment with Assisted Supervision
Due to the uneven spatial distribution of vehicle targets in reconnaissance SAR images, a foreground–background discrimination ability will facilitate subsequent detection optimization. Specifically, during the inference stage, the model first performs a coarse judgment on the image patches for foreground and background categories. Based on the discrimination results, detection is performed on the foreground image patches, while background image patches do not require detection. By performing an overall judgment on the image patch categories, false alarms and mis-detections caused by local noise in the background image patches can be avoided. In this way, by utilizing the global image’s contextual semantics, the model’s detection accuracy is further improved while enhancing detection efficiency.
Therefore, we include background images without targets into the detection model’s training as an auxiliary supervision for the foreground–background discrimination task, thereby further improving the model’s recall rate.
2.1.1. Coarse Judgment and Optimization
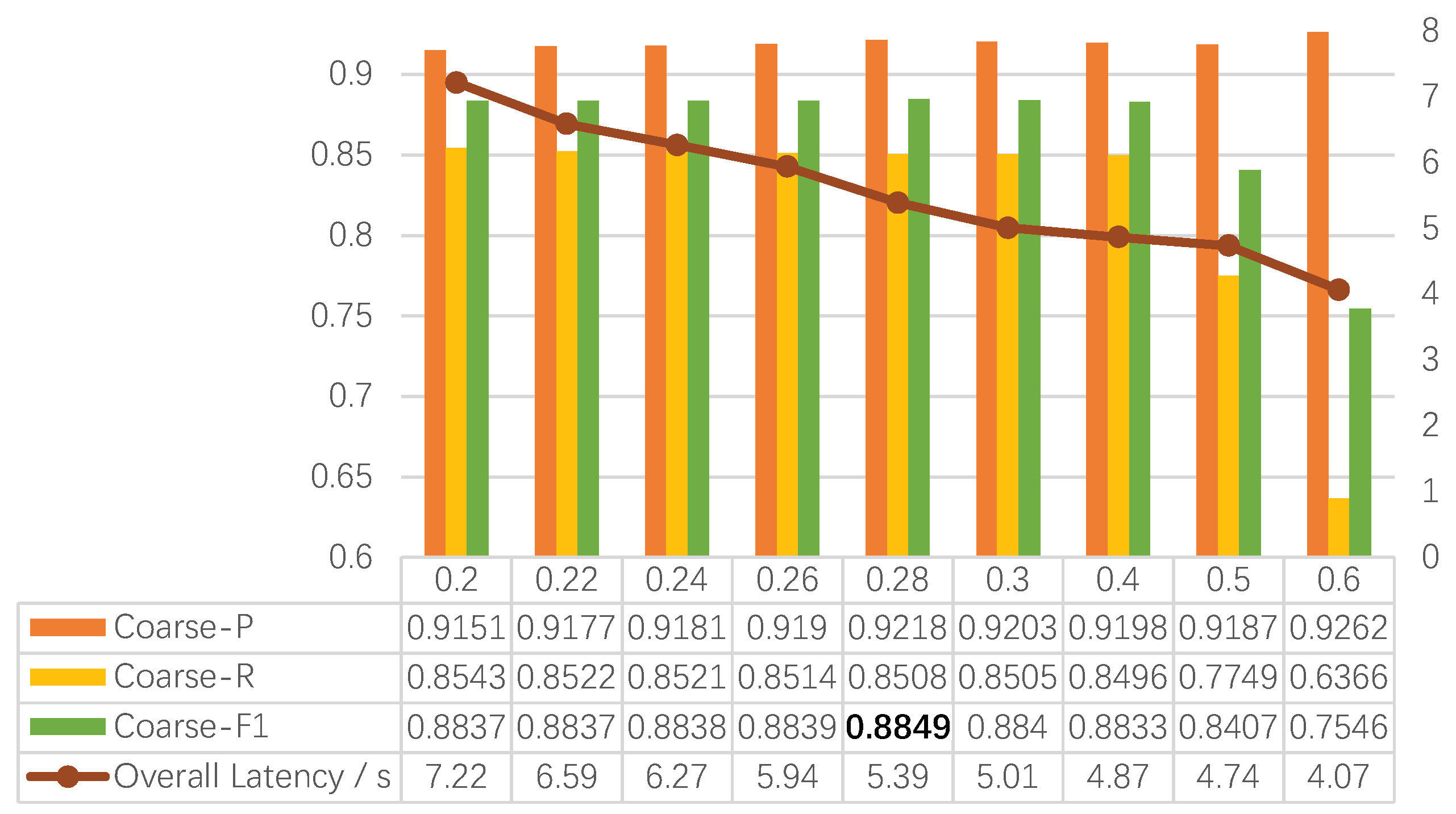
First, load a large-scale SAR image and use an overlapping sliding window approach to crop it into -sized images for input into the model. Then, extract features through the backbone and input the feature maps into the coarse decision branch to determine whether there are targets, obtaining positive patch indices. Use the foreground patch indices obtained from the classification branch to find the corresponding foreground feature maps. Send the corresponding feature maps into the feature map queue. If the number of feature maps in the queue is greater than the predefined value (equivalent to batch size in model training and inference), then take the first bs feature maps from the queue and send them into the detection branch for detection. Process the detection results appropriately to obtain the corresponding results.
Generally, wide-area images are sliced into smaller pieces using a sliding window approach, resulting in hundreds of smaller images, which is far more than the maximum number of images a GPU can process at once. While during inference, most of the image patches do not contain any targets, the number of remaining images is often very few. After a batch of images goes through the classification branch, only the feature maps of the small number of remaining foreground patches will be sent to the detection branch for detection after each batch of images is classified; this can further improve detection efficiency, so that our detection method can reasonably utilize computational resources.
2.1.2. Judgment-Assisted Supervision
For background patch input, the model will still perform forward propagation. When the forward propagation features reach the coarse judgment module, it determines whether the current image has annotation information. If there are box annotations, it is a foreground patch. Otherwise, it is a background patch. We treat this coarse judgment as a classification task of discriminating the foreground from background. This learning process can provide supplementary knowledge to the backbone, as a judgment-assisted supervision. Specifically, the classification loss of the positive and negative within a training batch,
is defined as follows:
where
and
are the numbers of foreground and background patches respectively;
is the Cross Entropy loss function [
33];
is the hyperparameter for balancing foreground and background losses.
2.2. CAM and Improved Feature Pyramid Network
Due to the scattering characteristics of SAR, its imagery may be affected by various types of noises (such as scattering and speckle). Reconnaissance scenes typically contain complex terrain and feature characteristics, and these background objects may generate texture features similar to those of the target vehicles, making it extremely easy for the target features to be confused with background noise.
Attention mechanism, as a mechanism for the brain to process images entering the human eye, plays a significant role in the human visual system. When an image enters the eye, this mechanism allows the visual system to selectively focus on salient regions, ignoring non-essential or targetless areas, essentially concentrating on areas of interest [
34]. This mechanism enables the acquisition of more detailed information from the focused regions without wasting effort on useless and distracting information. However, the attention module used in this chapter is different from those introduced earlier. SE modules [
35,
36] generally use max pooling or average pooling to process channels, which results in the loss of object location information, crucial for capturing target structures in computer vision tasks. CBAM [
37] aims to exploit object location information by reducing the channel dimensions of input feature maps, but its use of convolutional operations, which can only capture local relationships for spatial attention, fails to build dependencies between distant pixels in feature maps [
38]. While the non-local network addresses CBAM’s issue, it usually has a large computational load and is often used in large-scale networks.
2.2.1. CAM Attention Layer
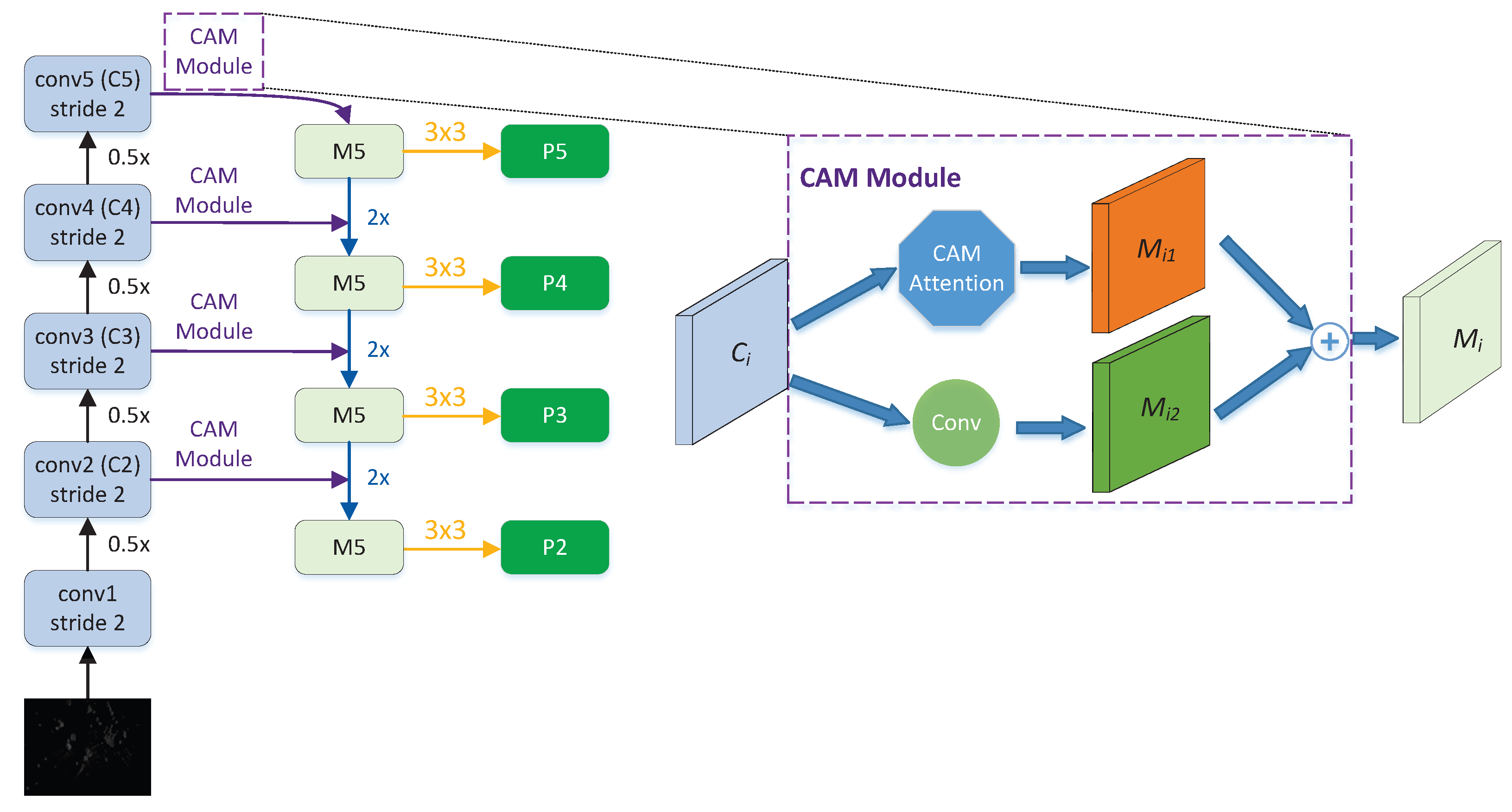
To address the issue of target features being easily confused with background noise, we propose a new attention mechanism—the CAM module—and incorporate it into the FPN network to effectively fuse visual features at different scales. By fully utilizing contextual information, the interference of background noise can be suppressed. Therefore, taking into account the advantages and disadvantages of existing methods, the attention mechanism adopted in this chapter is different from those mentioned above, and its structure is shown in
Figure 3.
CAM is aimed at improving the feature representation ability of any intermediate feature map in the network. For a given feature map tensor of an intermediate layer in a convolutional neural network,
CAM can maintain the size of the feature map, ensuring the output and input feature map are identical in size as
To encode the target location information accurately and capture the attention of the input feature along the height and width directions, CAM applies adaptive global average pooling on the input feature map
in both width and height directions, obtaining two feature maps
and
. Their dimensions are
and
, respectively, indicating the features of
along the width and height directions. Among them, the value of the
c-th channel of
at width
w is
Similarly, the value at the height of
h for the
c-th channel of
is
By applying the above two equations, we obtain a global receptive field and a precise representation of the object positions. These two transformations allow our CAM attention module to capture large-scale dependencies along one spatial direction, while preserving the position information along another spatial direction. This facilitates the network to locate the objects of interest more accurately.
In order to extract the attention map from horizontal and vertical direction separately, firstly,
is transposed to obtain a feature map with a dimension of
. Then, concatenate it with
along the spatial dimension (height or width) to obtain a feature map
with a dimension of
. Next, apply a
convolutional layer to
, reducing the feature channels by a factor of
r. Thus, the dimension of the feature map after convolution becomes
. Finally, perform batch normalization on the feature map, and then apply a non-linear operation as
where
x is the input feature map. The overall transformation can be described by the following formula:
where [∗] denotes the concatenation operation on the spatial dimension of feature maps;
T denotes the transpose operation; Conv2d denotes the convolution operation; BN is the batch normalization operation;
R is the nonlinear transformation function.
By applying the F transformation, we obtain the intermediate feature map
f with the dimension of
. Then, we split
f along the spatial dimension into two independent feature maps
and
, which have the dimensions of
and
, respectively. At this point, we need to transpose
, so that its dimension becomes
. Next, we perform the
convolution operation on these two feature maps separately, making the channel number of the convolved feature maps the same as that of the input feature map
X, that is, the dimensions of the convolved feature maps are
and
, respectively. Finally, we apply the nonlinear transformation to the two convolved feature maps. Here, we use a simple sigmoid transformation as the nonlinear transformation. The transformed feature maps are denoted as
and
, respectively, and we have the following formula:
where Split denotes the operation of splitting
f along the spatial dimension into two feature maps, namely,
and
;
denotes the nonlinear transformation sigmoid, which is used to activate the feature maps after convolution.
After the transformations of Equations (
4), (
5) and (
7)–(
10), the initial input feature map
X obtains two attention weight maps
and
along the spatial dimension. Then, the output of CAM can be expressed as:
2.2.2. CAM-FPN: Improved FPN Network with CAM Module
For CNN-based object detection models, the backbone network extracts visual features from different scales, while the FPN network fuses features from different scales to generate feature maps for targets of various sizes. However, noise from background interference is also mixed in. In order to enable the model to adaptively suppress background noise interference, we incorporate the CAM module into the FPN network. This allows the model to adaptively filter meaningful semantic features and suppress irrelevant noise interference, thereby further enhancing the model’s feature extraction capabilities and making it more robust to unrelated noise.
The insertion position of the CAM attention module in the network, as described above, is shown in
Figure 4. For the last feature map C5 generated by the feature extraction module, it passes through the CAM module to obtain the feature map M51, and simultaneously goes through a convolution operation to obtain the feature map M52. The corresponding elements of M51 and M52 are added together to obtain the fused high-level feature map M5.
2.3. Decoupled Detection Head
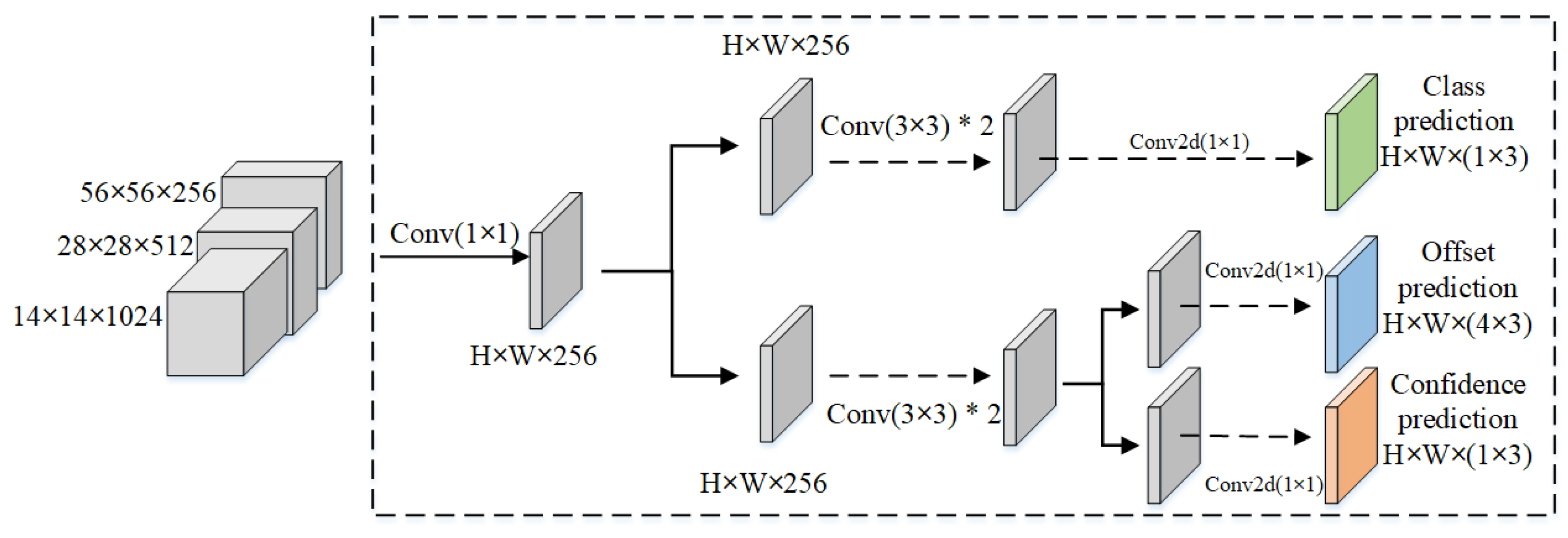
In traditional detection heads, the output channel number is changed for each feature layer through convolution, making the output channel number , where na represents the preset anchor boxes per point, 1 indicates the predicted target confidence, 4 represents the four coordinate offsets (center point xy, height-width wh), and nc represents the probability for each category. This traditional approach completes the classification and localization tasks through a single convolution.
However, classification and localization tasks have different focus points when it comes to the features extracted by the backbone. Classification is more concerned with how similar the extracted features are to existing categories [
39]. Localization, on the other hand, focuses more on the deviation from the ground truth box (GTBox) coordinates in order to adjust the bounding box parameters. Therefore, completing both localization and recognition tasks on the same feature map might not yield good results [
40].
Specifically, in order to have distinct distributions for category prediction, location information and confidence scores, coupling them in a single detection head may lead to slow convergence and reduced performance due to inconsistent distributions. Here, we adopt the approach used in YOLOX, which decouples the detection head to separately predict categories, locations, and confidence scores, thereby accelerating model convergence and improving detection accuracy.
Therefore, in this section, we choose the decoupled detection head, the structure of which is shown in
Figure 5.
4. Conclusions
In this paper, we propose a vehicle target detection model in the coarse-to-fine paradigm, targeting wide-area SAR images. Firstly, the coarse judgment module performs foreground and background classification on the sliding windowed patch, and then the fine detection branch only conducts forward operations on the feature maps of foreground. This can avoid wasteful detection of non-target areas and improve processing speed. Then, we build the detection model with proposed the CAM attention module to improve the model’s fine-grained recognition ability for vehicle targets. Furthermore, we use a decoupled detection head to improve the model’s localization ability for targets. Our framework also utilizes background area information and enhances the model’s detection performance by supervising the model’s judgment loss for the classification of foreground and background patches. We also used a data synthesis method to construct a wide-area SAR image dataset containing 10 types of vehicle targets and uses sliding window overlapping cropping and data augmentation methods to construct a training dataset containing more than 13,000 images. Through comparative experiments, we compared the detection and recognition performance of models with different modules, and benchmarked our algorithm with other typical end-to-end models, demonstrating its superiority. Extensive experimental results show that our method effectively improves detection accuracy and speed, and verifies the feasibility and efficiency of the model.
When determining the presence of targets in partitioned SAR image patches, we find that the first few layers of the backbone network, such as the first three layers, may be sufficient for this task. Therefore, in future work, we plan to further optimize the coarse detection branch of the target detection model by connecting it to the third layer of the backbone network, reducing computation and increasing inference speed. Additionally, we will investigate new feature extraction techniques and attention mechanisms to address complex SAR image scenes and further improve detection accuracy and speed. We will also explore the application of this target detection method in other remote sensing fields, such as ocean monitoring, forestry and agriculture.

 and
and 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}