1. Introduction
Compared with fixed surveillance cameras on the ground, cameras on UAV are easy to deploy and have a wider field of view. With the development of deep learning, UAV are tightly integrated with computer vision technology, making UAV less dependent on manual control and more intelligent, efficient, and convenient, widely used in smart agriculture [
1], rescue search [
2], and smart cities [
3]. Object detection is not only a fundamental task in computer vision, but also a core problem in UAV applications.
Deep-learning-based object detectors currently are classified into two categories: one is the two-stage object detector, which includes the R-CNN [
4], Fast-RCNN [
5], mask R-CNN [
6], etc. The R-CNN method, established by Girshick et al., is the first two-stage object detection algorithm that generates object candidate regions, then extracts features using a convolutional neural network, and applies a support vector machines classifier for classification. Mask R-CNN adds another parallel branch for pixel-level object instance segmentation. It detects not only the bounding box of an object but also the exact pixel containing the object. Another strategy is the single-stage object detector, consisting of anchor-based networks and anchor-free networks. The anchor-based networks include YOLO [
7] and SSD [
8]. This type of algorithm considers object detection to be a regression problem, forgoing the phase to generate proposal boxes and reduce computation and time consumption. SSD is the first single-stage detector that is mapping the equivalent to a current two-stage detector while maintaining real-time speed. Joseph et al. proposed YOLO in 2015, which transforms the detection problem into a regression problem. YOLO reduces the computational cost by dropping the step of generating proposal frames, but the model is not highly effective at detecting small objects due to using only the last layer of feature maps. YOLOv2 [
9] and YOLOv3 [
10] replace GoogLeNet [
11] as the backbone with darknet-19 and darknet-53, respectively, and use global average pooling and Batch Normalization (BN) [
12] to improve network convergence. YOLOv4 [
13] uses Complete Intersection over Union (CIoU) [
14] loss for prediction frame filtering to improve the convergence of the model. YOLOv5 [
15] uses a Feature Pyramid Network (FPN) [
16] and Pixel Aggregation Network (PAN) [
17] structure in the neck network. Due to the lighter model size, its accuracy is comparable to YOLOv4, but its speed is better. Moreover, anchor-free networks such as NanoDet [
18]. NanoDet is a single-stage anchor-free object detection model that removes all convolutions from the PAN, and the generalized focal loss removes the center-ness branch. Thus, a lightweight model is achieved while maintaining high accuracy, thus achieving a lightweight model while maintaining high accuracy.
Although these object detectors perform well, these detectors typically focus on detection in general scenarios rather than aerial images, which is considerably different from general scenes.
Figure 1 shows the detected objects of the general scenarios dataset MS COCO [
19] and the aerial images dataset VisDrone-DET2021 [
20]. There are considerably more small objects in the VisDrone-DET2021 dataset compared with MS COCO. “Small” here does not mean that the actual instance size is small, but rather the small scale of the objects in the image. Large objects have rich features and are easier to learn by neural networks, while small objects will lose part of their features during downsampling. The network is not able to learn sufficient small object features, resulting in a poor network fit to small objects, and therefore directly applying the common detectors to aerial images is not extremely effective.
To solve this problem, many scholars have proposed their solutions. Yang et al. [
21] proposed a Cluster Detection network for numerous small objects and uneven distribution of objects in aerial images. The network uses the methods of region clustering, slice detection, and scale adaptation to improve the running speed and small object detection rate of the two-stage object detector on high-resolution aerial images. Wu et al. [
22] proposed an object detector that fuses feature extraction, enhancement strategy, image pyramid network, and feature learning strategy. Pang et al. [
23] proposed a Tiny-Net approach to object detection. Images can be processed in 29.4 s in a convolutional neural network consisting of a backbone Tiny-Net, an intermediate global attention block, a final classifier, and a detector. Tiny-Net is a lightweight residual structure that supports fast and powerful feature extraction from the input. In 2020, Cui et al. [
24] proposed a context-aware module that can improve the recognition accuracy of small objects by using contextual information. YOLO-ACN [
25] introduced an attention mechanism in the channel and spatial dimensions of each residual block to focus on small objects. The CIoU loss is employed to achieve accurate bounding box regression. Xu et al. [
26] resulted in more accurate information in the predicted boxes by locating a quadrilateral to represent an object by learning the offsets of four points on a non-rotating rectangle. However, as the detection model requires angular information acquisition, it requires additional computational parameters, which are computationally expensive.
There are real-time and lightweight requirements for the application scenario of aerial image object detectors. Generally speaking, the computational resources of UAV platforms are limited, and a significant increase in the detection accuracy of the model would be at the expense of detection speed, which is a serious blow to real-time performance. Conversely, an over-emphasis on speed results in a significant loss of detection accuracy. Therefore, it is essential to balance the relationship between accuracy and speed. Considering the impact of the model on the detection speed, the faster single-stage object detector is more suitable for the UAV platforms, and the YOLOv5 detection method is finally selected. Regarding how to improve the efficiency of the object detector in aerial images, this study mainly focuses on the following two aspects: (1) reduce the size of the detector model through lightweight design and (2) improve the detection accuracy of small objects.
In consideration of the above discussion, in this paper, we design a lightweight object detector for aerial images, named YOLO-UAVlite. The main contributions of this study are recapitulated as follows:
The SCSA module is proposed by modifying the spatial and coordinate attention modules and combining their advantages to capture not only location information and channel information, but also spatial information. The module enhances the object representation and enables the model to locate the object area accurately. We design a lightweight backbone network, SCSAshufflenet, based on SCSA and ES to improve feature extraction and increase detection accuracy. Benefiting from the lightweight design, the model parameters are decreased.
A lightweight Slim-BiFPN structure is proposed to replace the original FPN. We design new convolutional blocks to reduce the number of convolutional layers, and decrease the computational complexity and parameter quantity of the detector, improving the efficiency of object detection.
The bounding box regression loss calculation model is modified to obtain higher quality boxes, which speeds up the convergence of the model and improves the positioning effect.
The remainder of this study is organized as follows:
Section 2 reviews related works about lightweight neural networks, attention mechanisms, and ghost convolution. Details of the proposed model are presented in
Section 3.
Section 4 presents the implementation details of the experiments, giving the results and discussion of ablation and comparison experiments. Finally, the conclusions are given in
Section 5.
3. Proposed Method
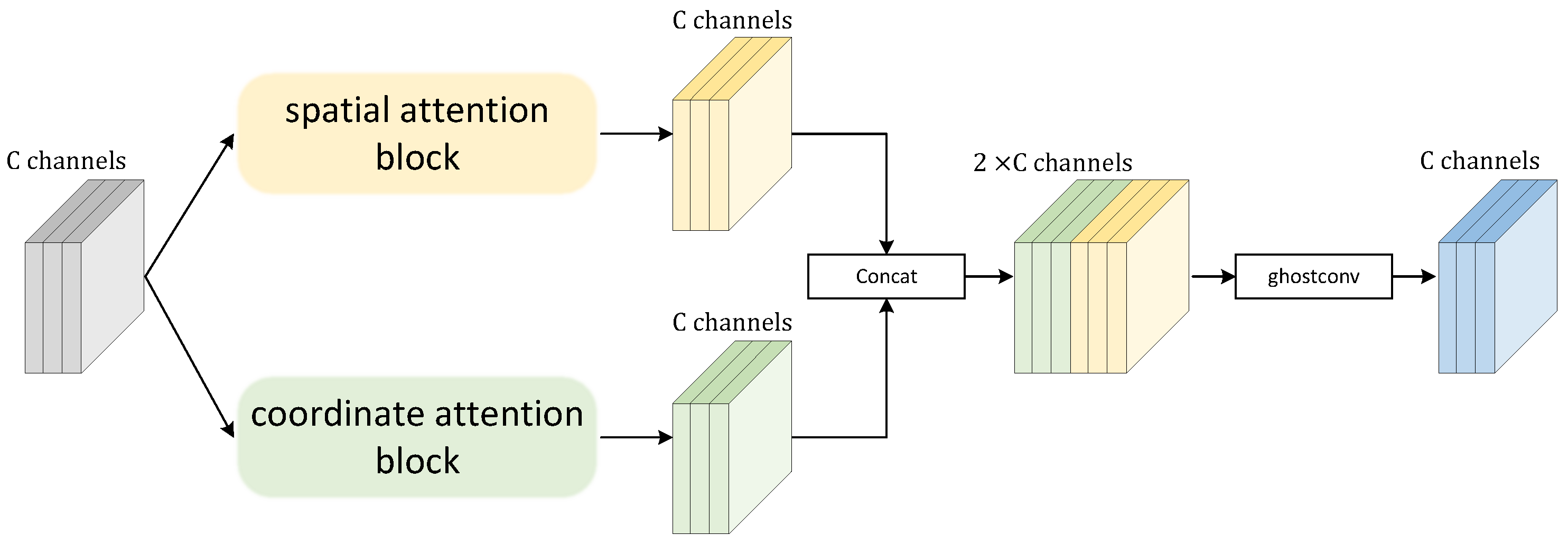
The overall structure of our YOLO-UAVlite detector is based on the YOLOv5-N object detector. We propose a novel attention module SCSA and add it to the ES module, which generates a lightweight backbone network SCSAshufflenet to enhance the feature extraction capability of the backbone network. Then, in the neck network, an improved feature pyramid model, called Slim-BiFPN, is proposed to reduce the model parameters and loss of information during the feature fusion process. Finally, we modify the loss function to obtain higher quality bounding boxes.
Figure 3 shows the structure of the YOLO-UAVlite detector, and
Table 1 summarizes the main parameters.
As can be seen in
Figure 3 and
Table 1, the
size color image is first fed into the backbone, where it is downsampled by several convolutional layers and pooling layers. The first layer of the backbone is the CBH module, consisting of a convolutional layer, a BN layer, and a Hard Swish [
36] activation function layer, aimed at reducing the computational effort of the model and accelerating the training speed. The ES Block extracts feature maps of different sizes by convolutional downsampling, and the attention mechanism strengthens object representation. The Spatial Pyramid Pooling-Fast (SPPF) module aims to convert arbitrary-sized feature maps into fixed-sized feature vectors, which can expand the receptive field. Extract abstract features from images of sizes
,
and
. Then, the extracted features are fed into the neck, where the Slim-BiFPN approach is used for feature fusion. Low-level features contain more positional, detailed information, but are less semantic and more noisy due to the fewer convolutions they undergo. High-level features have more semantic information and are less sensitive to detail. By fusing three different levels of features, the advantages of multiple features are complemented to obtain more robust and accurate recognition results. Finally, there are three output tensors in the head for large, medium, and small object detection.
3.1. SCSAshufflenet Backbone
The backbone network extracts feature maps of different sizes by adopting multiple convolutions and pooling from the input image. To avoid using too numerous convolutional layers and pooling layers, which will cause model parameters to be redundant, we propose the SCSAshufflenet backbone network to replace the original backbone network, which is composed of ES and SCSA. The ES removes some convolutional layers and reduces the model parameters. At the same time, the SCSA makes the backbone pay more attention to the features of small object objects and assigns more weights to small object features during the downsampling process, in order to obtain richer small object features. The SCSA and ES will be described in detail below, respectively.
3.1.1. Spatial-Coordinate Self-Attention
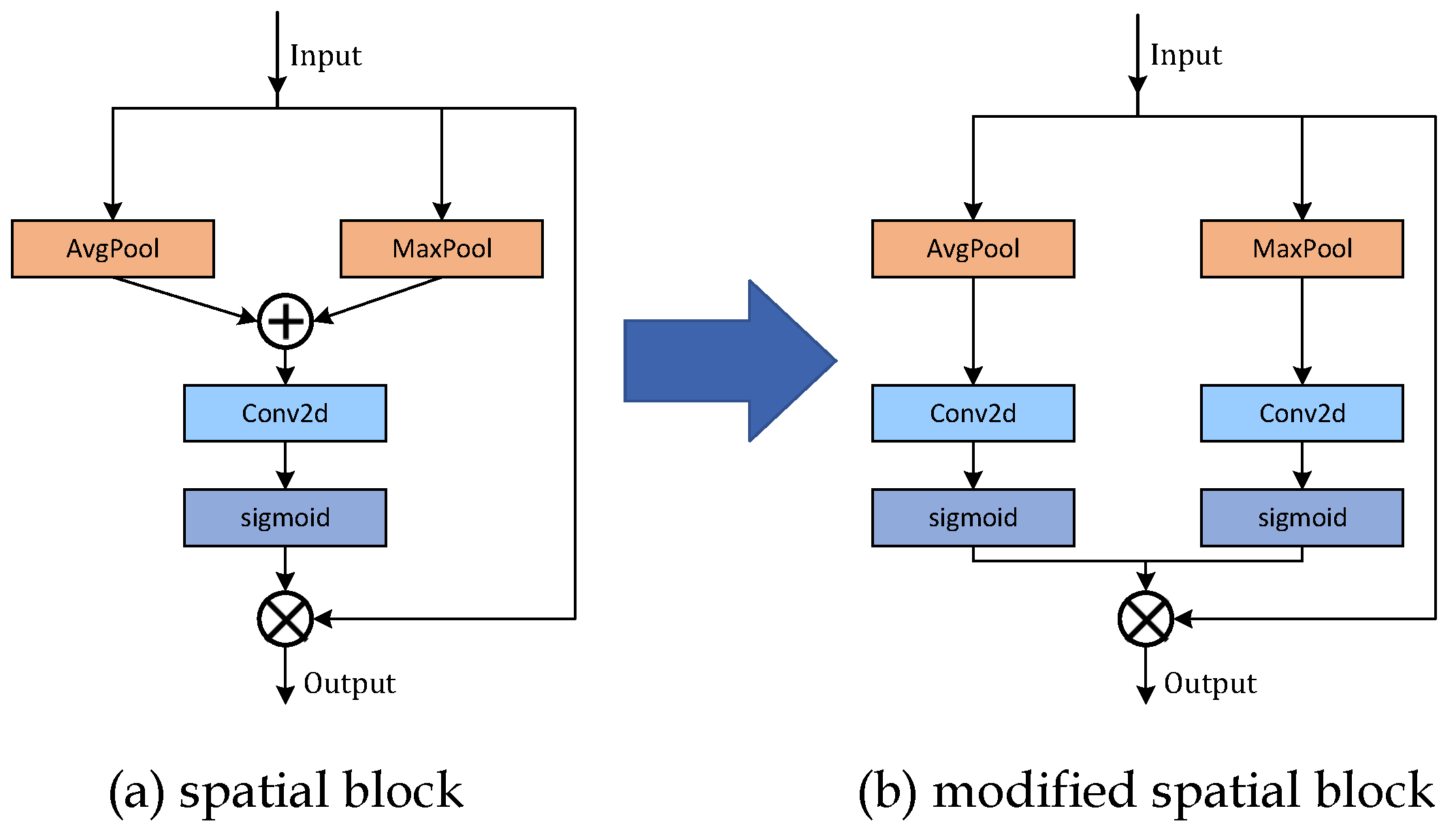
To improve the model’s ability to extract useful features, we modify the spatial attention and coordinate attention and combine them to form new attention which integrates spatial, location, and channel information to capture the interrelationships between different types of information. As shown in
Figure 4, our SCSA consists of two blocks: a spatial attention block and a coordinate attention block.
As can be seen in
Figure 5, we modified the spatial attention block in CBAM by convolving the MaxPool branch and the AvgPool branch, respectively, and then using the activation function on them to obtain two different focus points. Compared with the original attention module, more spatial feature information can be obtained. The final spatial attention block output feature map is formulated by multiplying these weights with the initial input feature map, as follows:
Here, and X denote the spatial attention block output feature map and input feature map, respectively. ⊗ denotes the element-wise multiplication, is the sigmoid activation function. represents a convolution operation with the filter size of . and represent the average pooling operation and the max-pooling operation, respectively.
Coordinate attention decomposes the channel attention into two one-dimensional features and integration of features along both
X and
Y spatial directions, and efficiently integrates spatial coordinate information into the generated attention map. We modify the coordinate attention to make the feature map have different receptive fields through convolution, further enhancing the interdependence between the location information and channel relations.
Figure 6 shows the structure of the modified coordinate attention block. Specifically, for the input feature map
X (
C ×
H ×
W), we obtain different receptive fields after the ghostconv module, so as to learn high dimensional features, and then fuse with the original input to obtain
O. For the feature map
O (
C ×
H ×
W), the pooled with dimensions (
) and (
) are used to augment the horizontal and vertical features of each channel, respectively. Therefore, the output of the
cth channel with width
W and height
H can be written, respectively, as follows:
where
and
are the output and the input of the
cth channel, respectively.
H and
W denote the height and width of the input feature maps, respectively. Next, the two feature maps
and
are concatenated, and the concatenated feature map is reduced by the
convolution operation, yielding
where
is the intermediate feature map of spatial information in the horizontal and vertical directions,
denotes the nonlinear activation function, and
represents the
convolution operation. Then,
f is divided into two separate tensors
and
, as shown in the following formula:
where
r is the reduction radio.
and
are transformed by two
convolutions to the same number of channels as
O, thus yielding the following:
Here,
and
are the attention weights in the
H and
W directions, respectively.
is the sigmoid function, and
represents the
convolution operation. For input
O, we establish long-distance connections to provide information flow between different layers and improve the ability of feature information to communicate across layers, yielding
where
represents ghostconv operation. The final coordinate attention block output feature map is computed as:
The spatial attention and coordinate attention feature map are concatenated and reduced the dimension of the concatenation result by
convolution. The output of the SCSA module can be formulated as follows:
where
and
denote the spatial attention block feature map and the coordinate attention block feature map, respectively.
is a concatenation operation. The proposed SCSA module integrates spatial information, location information, and channel information, and has better positioning capability for dense aerial imagery, thereby improving the detector accuracy. In this study, the SCSA module is added to ES. Benefiting from the partnership with the SCSA module, the backbone network is still lightweight but more object-focused. It is worth noting that, when the network is deep and the feature maps are small, using the attention mechanism to force the extraction of some features may lose some meaningful feature information. Therefore, as shown in
Figure 3, the SCSA module is applied to L3 and L6, but not L9 in the backbone network.
3.1.2. Enhanced ShuffleNet
The original backbone network darknet-53 of YOLOv5-N has 53 layers. The structure of the BottleneckCSP module in the backbone network is computationally complex, and the inference time on hardware devices with limited computational resources cannot meet the application requirements. Therefore, we replace darknet-53 with ES. As shown in
Figure 7, ES is divided into two types of channels, with the ES Block_1 outputting the same number of channels and the ES Block_2 increasing the number of channels. Due to the addition of the channel split module at the beginning of the ES Block_1, the input feature map is split into two branches, each with half the number of channels. Compared with the standard convolution, ghost block has smaller parameters and less computation and generates more feature maps, thereby reducing the weight parameters. The SE block is good at weighing the network channels and obtaining better features. After convolution, the two branches are concatenated. When the stride is 2, the input feature map is sent to the two branches for convolution, and the feature map becomes half the size of the initial input feature map, which is output after concatenation and convolution. The final output feature map is twice as many channels as the initial input feature map.
3.2. Slim-BiFPN
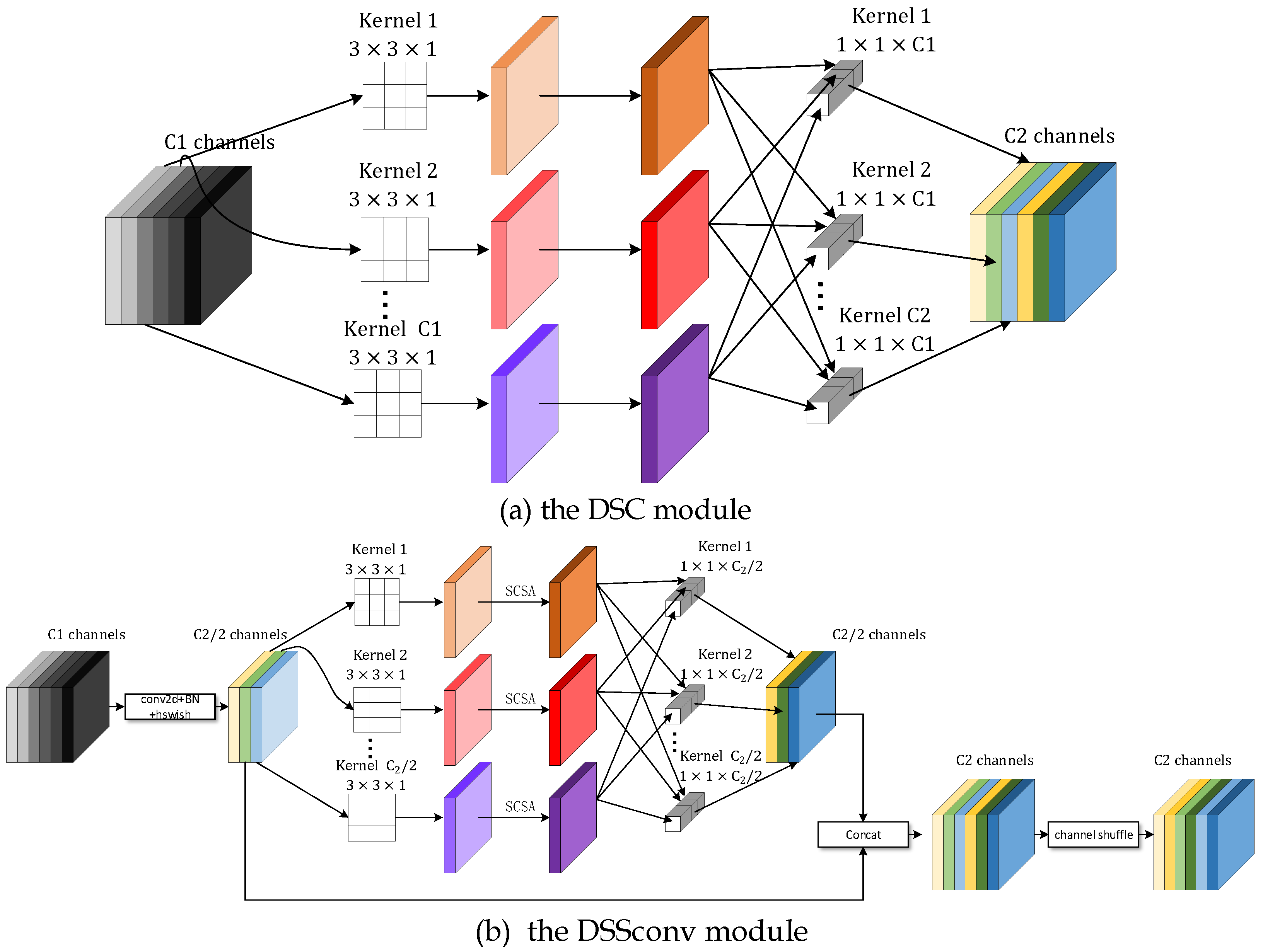
The original YOLOv5 adopts the FPN structure on the neck for feature extraction and fusion. Small object features will lose some information after the low-pass filtering effect of the multiple convolution operation. Moreover, the original convolutional block parameters are redundant, which is not conducive to model lightweight. The proposed lighter Slim-BiFPN replaces the FPN, and the DSC layer is used to replace the original YOLOv5-N convolutional block, reducing the number of convolutional kernels and shrinking the size of the convolutional kernels, resulting in a significant reduction in the number of parameters. Simultaneously, the SCSA is introduced into the convolutional block to adjust the feature map weights during upsampling and reduce the feature loss. Specifically, we construct new modules, called DSSconv and DSSCSP. Therefore, we propose Slim-BiFPN based on BIFPN and construct new SCSAconv and SCSACSP modules, The former reduces the computational cost and parameters, and speeds up inference by replacing the original convolutional block with depthwise convolution (DWconv) and pointwise convolution (PWconv) parts, while the latter uses stacked SCSA to enhance multi-scale feature fusion to reduce non-gradient feature loss to ensure that sufficient features are extracted.
3.2.1. DSSconv
For standard convolution, assuming that the input feature map
,
C denotes the number of channels of the input feature map, and
H and
W denote the height and width of the input feature map, respectively. The output feature map is computed as:
where
denotes the output feature map, and
represents the
convolution operation.
denotes the number of channels of the output feature map, and
and
denote the width and height of the output feature map, respectively. Therefore, the parameters required for the standard convolution are calculated as follows:
Compared with standard convolution, the DSC can effectively reduce the model parameters and computational effort, and the difference in results from standard convolution is minimal. The DSC module is divided into two processes: channel-by-channel two-dimensional depthwise convolution DWconv in the depth direction, then followed by a
pointwise convolution to compress and expand the channels to achieve the effect of standard convolution. Specifically, in the DWconv operation, the channels and convolution kernels correspond one-to-one, meaning that a convolution kernel has only one channel, the number of convolution kernels is the same as the number of the previous layer channels, the convolution kernel shape is
, and the feature map shape changes from
to
. Therefore, the parameters required for the DWconv module are calculated as follows:
Then, the PWconv operation is employed in the feature map after the DWconv module. The number of convolution kernels is the same as the number of output channels, and the convolution kernel shape is
. The feature map shape changes from
to
. Therefore, the parameters required for the PWconv module are calculated as follows:
The ratio of parameters required for the DSC module relative to the standard convolution module can be calculated as follows:
It can be seen that the number of DSC module parameters is times that of standard convolution from the results. In this paper, , so the number of Slim-BiFPN parameters can be reduced by replacing standard convolution with DSC.
However, the channel information of the feature map is separated during the DSC module, which reduces the feature extraction ability of the network. Therefore, the channel shuffle operation is adopted to communicate information between the two branches. Inspired by Mobilenetv3 [
36], we introduce the SCSA module in the DSC to adjust the weight of each channel, aiming to improve the balanced feature map. We refer to this modified convolutional module as DSSconv, and
Figure 8 shows the structure of the DSSconv module. Specifically, the input features are reduced to half of the final output channel number by the CONV module (conv2d+ BN+Hard Swish activation function); then, a DWconv operation with a
convolution kernel is applied. Next, after the features are adjusted by the SCSA module with the weights of each channel, the new features are then generated by the
PWconv module. Finally, the feature maps are concatenated with the initial CONV feature map, and a channel shuffle module is used to exchange feature information on different channels.
3.2.2. DSSCSP
In the original FPN structure, the BottleneckCSP module is used to learn the feature map, but too many convolutions in the BottleneckCSP may lead to a loss of features and redundant parameters. Therefore, we propose DSSCSP instead of BottleneckCSP.
Figure 3 shows the structure of the DSSCSP. Specifically, the initial feature map of DSSCSP is input to two branches, the first branch learns features via CONV and stacked SCSA, and the second branch directly learns features via CONV module. Finally, the output feature maps from the two branches are concatenated together and output through a single CONV module. We do not use DSSconv in the DSSCSP, although this will reduce the model parameters, but will significantly deepen the network layer of Slim-BIFPN and significantly increase the inference time.
3.3. Optimization of Loss Function
The loss function of YOLOv5 mainly consists of confidence loss, classification loss, and bounding box loss. In the original YOLOv5, regression prediction of the bounding box by using the CIoU function is defined as follows:
where
b and
denote the center points of the predicted box and ground truth box, respectively.
represents the Euclidean distance between
b and
, and
c represents the diagonal length of the smallest rectangle covering
b and
.
denotes the trade-off parameter, and
is used to measure the consistency of the aspect ratio between
b and
, which are defined as follows:
where
and
represent the width and height of the ground truth box, respectively.
w and
h represent the width and height of the predicted box, respectively.
IoU [
37] introduces parameter
into the original IoU parameters to adjust the performance. The
CIoU is defined as follows:
There are numerous small objects in the aerial images. The smaller the object, the closer the predicted box’s center point is to the ground truth box, and thus the loss will be significantly lower than that of the large object when calculating the loss, which is not conducive to the calculation of the loss of small objects. In this paper, by increasing the Euclidean distance between the predicted box and ground truth box, amplifying the loss weight of large and medium objects, and expanding the difference, optimize the loss calculation for small objects. The
is the parameter that boosts the loss value and gradient of the high IoU object, thus improving the regression effect of the box and accelerating convergence. Through experimentation, we found that the best results are obtained when
is 3, so in our work,
= 3. Finally, the IoU loss function in this paper is defined as follows:
4. Experiment Results and Discussion
4.1. Dataset
All the experiments are conducted on the public object detection benchmark VisDrone-DET2021. The dataset is mainly marked with ground humans and daily vehicles, which are captured by UAV at different shooting angles and heights, consists of 8899 images and 382,005 labels, of which 6471 images are used for training and 548 images for validation. There are 10 categories in the dataset, namely pedestrian, person, car, van, bus, truck, motor, bicycle, awning-tricycle, and tricycle.
4.2. Evaluation Criteria
Mean Average Precision (mAP) is used to measure accuracy, which is the average of the various types of accuracy in the dataset, by plotting a curve against accuracy and recall, and the area of the curve against the coordinate axis is the AP value. The Precision, Recall, AP, and mAP are calculated respectively as follows:
where True Positive (TP) is the number of positive samples being correctly classified, False Positive (FP) is the number of negative samples being incorrectly classified, and False Negative (FN) is the number of positive samples being incorrectly classified.
n indicates the total number of detection categories.
In this study, we follow the evaluation protocol of MS COCO dataset, including mAP (IoU threshold average), mAP0.50 (IoU threshold mAP), and mAP0.75 (IoU threshold mAP). Three criteria are also included, namely AP-s, AP-m, and AP-l, corresponding to small, medium, and large scale AP results, respectively. The higher the mAP and the AP value, the better the detection effect of the object detector. The size of the model is evaluated in terms of the number of parameters, and the fewer the parameters, the lighter the detector. Frames per second (fps) is used for the real-time efficiency evaluation, to ensure similarity to real-world usage scenarios, and our calculation section includes post-processing, such as input/output and non-maximum suppression. The larger the fps, the better the real-time efficiency of the detector.
4.3. Implementation Details
Our YOLO-UAVlite detector is based on the deep learning framework of PyTorch, and the experimental code is based on the improvement of the YOLOv5 project version 6.1 of ultralytics. We choose adaptive moment estimation (Adam) as the optimizer. The batch size, momentum, and weight decay are set to 16, 0.937, and 0.0005, respectively. To avoid the loss value being too large to affect the stability of convergence at the beginning of training, we first run three epochs of warm-up training. During warm-up, the momentum of the optimizer is set to 0.8. After warm-up training, the learning rate is decayed adopting a cosine annealing function, where the initial learning rate and the minimum learning rate are set to 0.001 and 0.00001, respectively. Finally, we train the model for 300 epochs. When loading the data, all image resolution is uniformly adjusted to , and data preprocessing adopts mosaic data augmentation. All experimental algorithms in this paper are migrated implementations of the official model, trained from scratch for 300 epochs starting from batch size 16, with the remaining hyperparameters as the default.
The operating environment for all experimental algorithms is as follows: the CPU is Intel i9-10900K, the GPU is NVIDIA GeForce RTX 3090 (24GB), and the Operating System is Windows 64-bit. The frameworks are Python 3.7.0, PyTorch 1.11.0, and CUDA 11.3.
4.4. Results and Discussion
4.4.1. Ablation Experiments
To verify the effectiveness of the three improved methods, we conducted ablation experiments. As shown in
Table 2 and
Figure 9, the results of the ablation experiments show that each method achieves some improvement. Based on the baseline model YOLOv5-N, we propose SCSAshufflenet as the backbone, replacing the original FPN with Slim-BiFPN, and modifying the loss function. The detection results are shown in
Figure 10, where it can be seen that each of the improvement methods improves the detection accuracy. The ablation experiments were conducted with the same training configuration for a fair comparison.
To verify the feasibility of the SCSAshufflenet backbone, YOLOv5-N was selected as a baseline architecture, and the original backbone darknet-53 is replaced with SCSAshufflenet. As can be seen from rows 1 and 2 of
Table 2, compared with the YOLOv5-N, the model parameters are reduced by 6.2% after setting SCSAshufflenet to the backbone, while the mAP0.50 is increased by 10.2 percentage points. The AP results at small, medium, and large scales achieve gains, and the smaller the object, the more significant the improvement. Considering the distribution of object sizes in aerial images where small scales dominate, the proposed SCSAshufflenet strategy achieves the desired effect.
To demonstrate the role of Slim-FPN, we replace the original the FPN with Slim-FPN and leave the rest of the model unchanged. As can be seen from rows 1 and 2 of
Table 2, after replacing FPN with Slim-BiFPN, the model parametric count drops from 1.77 m to 1.28 m, reducing the number of parameters by 27.6%. At the same time, the fps is increased by 17.3, indicating that the real-time performance of the model has also been improved. In addition, the accuracy of the model with various types of AP values is slightly improved. The mAP0.50 improved from 25.7% to 26.1%, and the AP-s and the AP-m improved by 0.3% and 0.1%, respectively. As described in
Section 3.2, Slim-BiFPN uses a lighter DSSconv with fewer model parameters, and DSSCSP reduces feature loss, especially for small object features, which explains why the highest improvement in AP values is observed for small objects.
Modifying the loss function usually only affects the training process, but does not or rarely does not affect the inference time of the network. In this paper, we use the new loss function to obtain a higher-quality box. Rows 1 and 4 of
Table 2 showed that, after using the new loss function, we were able to achieve gains of 0.7%, 0.9%, and 2.0% in mAP0.50, mAP, and mAP0.75, respectively. The fps has changed slightly from 72.0 to 71.6.
To verify the interplay of various aspects of improvement, we replaced both SCSAshufflenet and Slim-BiFPN into YOLOv5-N, and as can be seen in rows 1 and 5 of
Table 2, both AP values improved and all model parameters decreased compared with the original YOLOv5-N. Interestingly, by comparing rows 2, 3, and 5, we find that using SCSAshufflenet or Slim-BiFPN alone does not balance accuracy and speed. When using SCSAshufflenet alone, the model parameter count remains at a high level, and the fps decreases significantly, although the mAP0.50 increases from 25.7% to 35.9%. Similarly, when using Slim-BiFPN alone, the model lightness is improved, but the mAP0.50 and other AP values are not significantly increased. This confirms what was mentioned in
Section 3—that the model accuracy improvement is mainly due to the SCSAshufflenet backbone, while the lightness is mainly due to Slim-BiFPN.
Finally, all the improvements are applied to verify the enhancement of each part compared to the benchmark model YOLOv5-N in all aspects and to verify the balance between accuracy and lightness. As can be seen from rows 1 and 6 of
Table 2, the simultaneous use of the three improvements results in greater enhancements in both accuracy and lightness than the use of one of the improvements alone, achieving a balance between accuracy and speed trade-offs and achieving higher accuracy on UAV platforms with limited computational resources.
4.4.2. Comparisons with State-of-the-Art in Aerial Images Detection
To further validate the performance of the proposed YOLO-UAVlite in aerial images, the YOLO-UAVlite is compared with other lightweight detectors on the VisDrone-DET2021 dataset. The compared detectors are the anchors-free detector NanoDet-M-1.5X, PP-PicoDet-M [
30], YOLOv6-N [
38] and YOLOv7-Tiny [
39], and the anchors-based detectors are YOLOv3-Tiny [
10], YOLOv4-Tiny [
13], YOLOv5-N, YOLOv5-S, and YOLOv5-Lites-S [
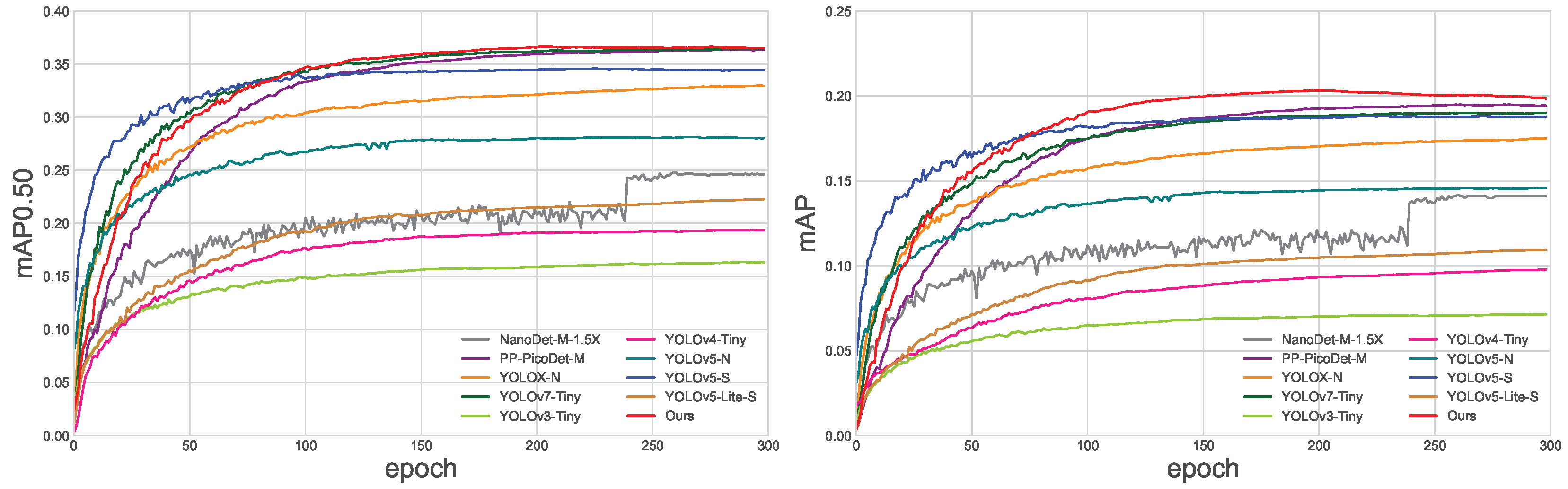
40]. We did not choose a two-stage detector due to its large parameters and relatively slow detection speed compared to lightweight detector, which cannot be deployed to UAV. Therefore, there is no comparison between the two-stage detector and the lightweight detector in the aerial image scenario. To effectively compare the performance of the proposed algorithms, the training environments and datasets are exactly the same for all algorithms. The comparison results between YOLO-UAVlite and the other algorithms are shown in
Figure 11.
Table 3 records the performance comparison of YOLO-UAVlite with other state-of-the-art methods.
For the VisDrone-DET2021 dataset, our YOLO-UAVlite achieves 36.6% mAP0.50 with 1.41 m model parameters. As shown in
Figure 12, the proposed method outperforms all the compared models, achieving state-of-the-art detection accuracy with the least amount of model parameters. From these two indicators, it can be seen that YOLO-UAVlite is easier to deploy on UAV platforms and achieves higher accuracy and better detection results. Compared with the baseline architecture YOLOv5-N, the proposed model reduces the number of parameters by 25.8%, while the mAP0.50 is increased by 10.9%; in particular, the detection effect of small objects is considerably increased, and AP-s is 1.9 times larger than YOLOv5-N. Compared with the larger YOLOv5-S, the number of parameters is only one-fifth that of YOLOv5-S, and the mAP0.50 is 3.7% higher. Compared with YOLOv3-Tiny, YOLOv4-Tiny, and YOLOv5 Lite-S, the proposed model achieves the highest performance scores in terms of mAP0.50, mAP, mAP0.75, and small, medium, and large scale AP values, while minimizing the number of model parameters. Compared with the anchor-free detectors NanoDet-M-1.5X and YOLOv6-N, the mAP0.50 shows an increase of 11.8% and a decrease of 7.6%, respectively, and the parameters are greatly reduced by 32.2% and 67.2%, respectively. YOLO-UAVlite has slightly higher mAP0.50 than PP-PicoDet-M and YOLOv7-Tiny, but the number of model parameters of YOLO-UAVlite is 65.6% of PP-PicoDet-M and 22.8% of YOLOv7-Tiny, respectively.
By comparing our model with the AP-s, AP-m, and AP-l for each model, we found that the Ap-s lead is the highest, indicating that our model gains are mainly from small-scale objectives. Although the AP-l of our method is lower than that of YOLOv5-S and YOLOv7-Tiny, the recognition accuracies for small-scale objects and medium-scale objects are 12.9% and 29.3%, respectively, which are significantly higher than other methods, proving that our YOLO-UAVlite detector has advantages in aerial image scenes with a large number of small objects. In addition, we also investigate the computational cost of the proposed and compared methods. Compared with the baseline YOLOv5-N, the model inference speed is decreased by 8.7 fps, but the accuracy of each scale is considerably increased. The fastest detector is YOLOv6-N, which reaches 127.3 fps. Although the proposed YOLO-UAVlite model drops to 63.3 fps, it still meets the speed requirements on the UAV platforms. This shows that our proposed YOLO-UAVlite has elevated accuracy for multi-scale object detection and achieves better accuracy and performance trade-off.
To adequately illustrate the applicability of our model to different image scenes, we present object detection results under typical scene conditions. The test results are shown in the figure. As shown in
Figure 13, the overall detection rate of YOLO-UAVlite is higher than that of the other detectors, especially in the long-distence view, where it can still correctly detect more objects. As can be seen from
Figure 14, our YOLO-UAVlite can detect the actual objects more accurately in the object cluster with high overlap, with fewer overlapping boxes and lower false alarms than the comparison detectors.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}