
InTEn-LOAM: Intensity and Temporal Enhanced LiDAR Odometry and Mapping

Abstract
:1. Introduction
- We propose an efficient range-image-based feature extraction method that is able to adaptively extract features from the raw lazer scan and categorize them into four different types in real time.
- We propose a coarse-to-fine, model-free method for online dynamic object removal enabling the LO system to build a purely static map by removing all dynamic outliers in raw scans.
- We propose a novel intensity-based points registration algorithm that directly leverages reflectance measurements to align point clouds, and we introduce it into the LO framework to achieve jointly pose estimation utilizing both geometric and intensity information.
- Extensive experiments are conducted to evaluate the proposed system. Results show that InTEn-LOAM achieves similar or better accuracy in comparison with state-of-the-art LO systems and outperforms them in unstructured scenes with sparse geometric features.
2. Related Work
2.1. Point Cloud Registration and LiDAR Odometry
2.2. Fusion with Point Intensity
2.3. Dynamic Object Removal
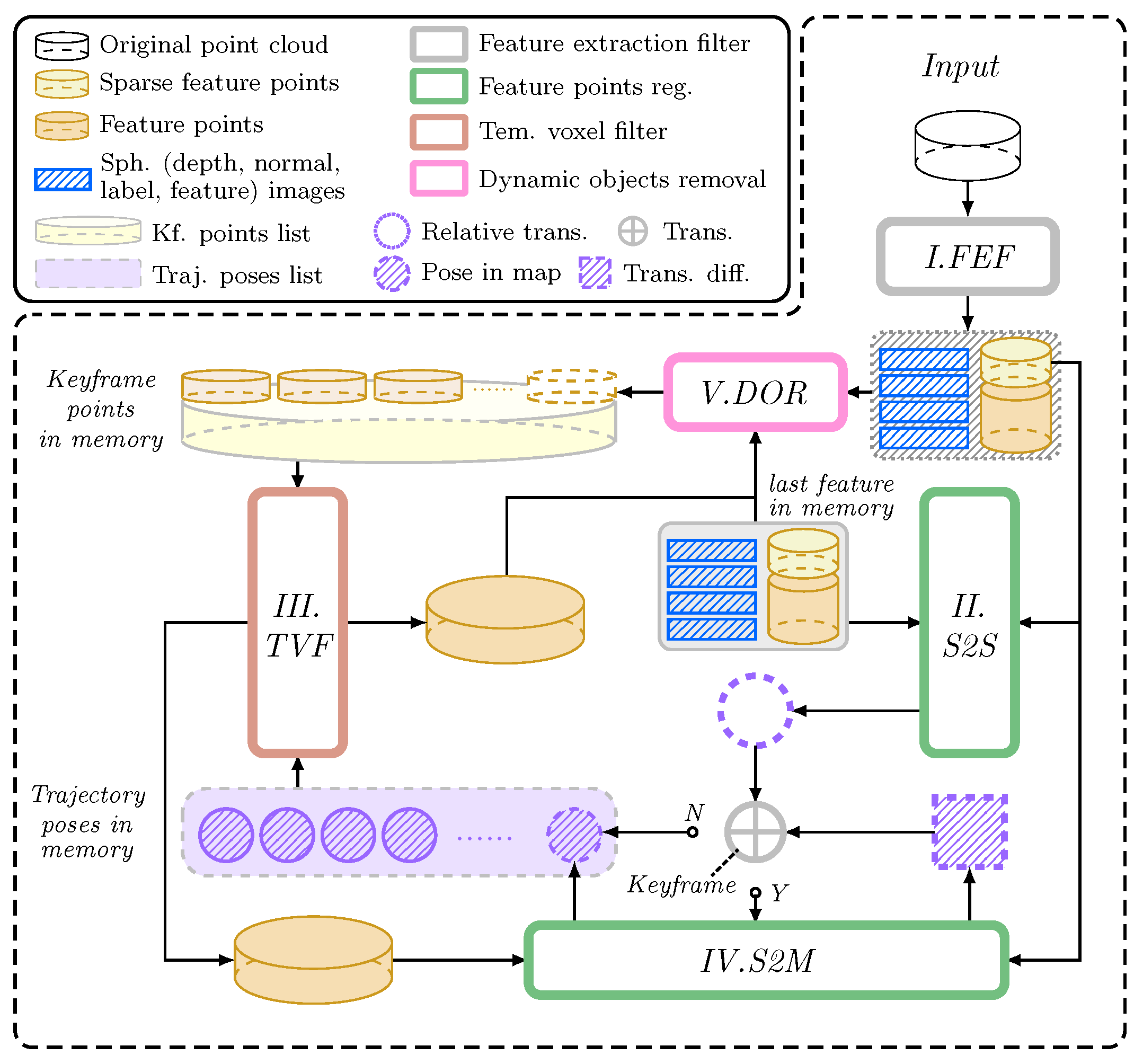
3. Materials and Methods
3.1. Feature Extraction Filter
3.1.1. Motion Compensation
3.1.2. Scan Preprocess
3.1.3. Feature Extraction
- Points correspond to pixels that meet and are categorized as .
- Points correspond to pixels that meet and are categorized as . In addition, points in pixels that meet and their neighbors are all included in to keep the local intensity gradient of reflector features.
- Points correspond to pixels that meet and are categorized as .
- Points correspond to pixels that meet and are categorized as .
3.2. Intensity-Based Scan Registration
3.2.1. B-Spline Intensity Surface Model
3.2.2. Observation Constraint
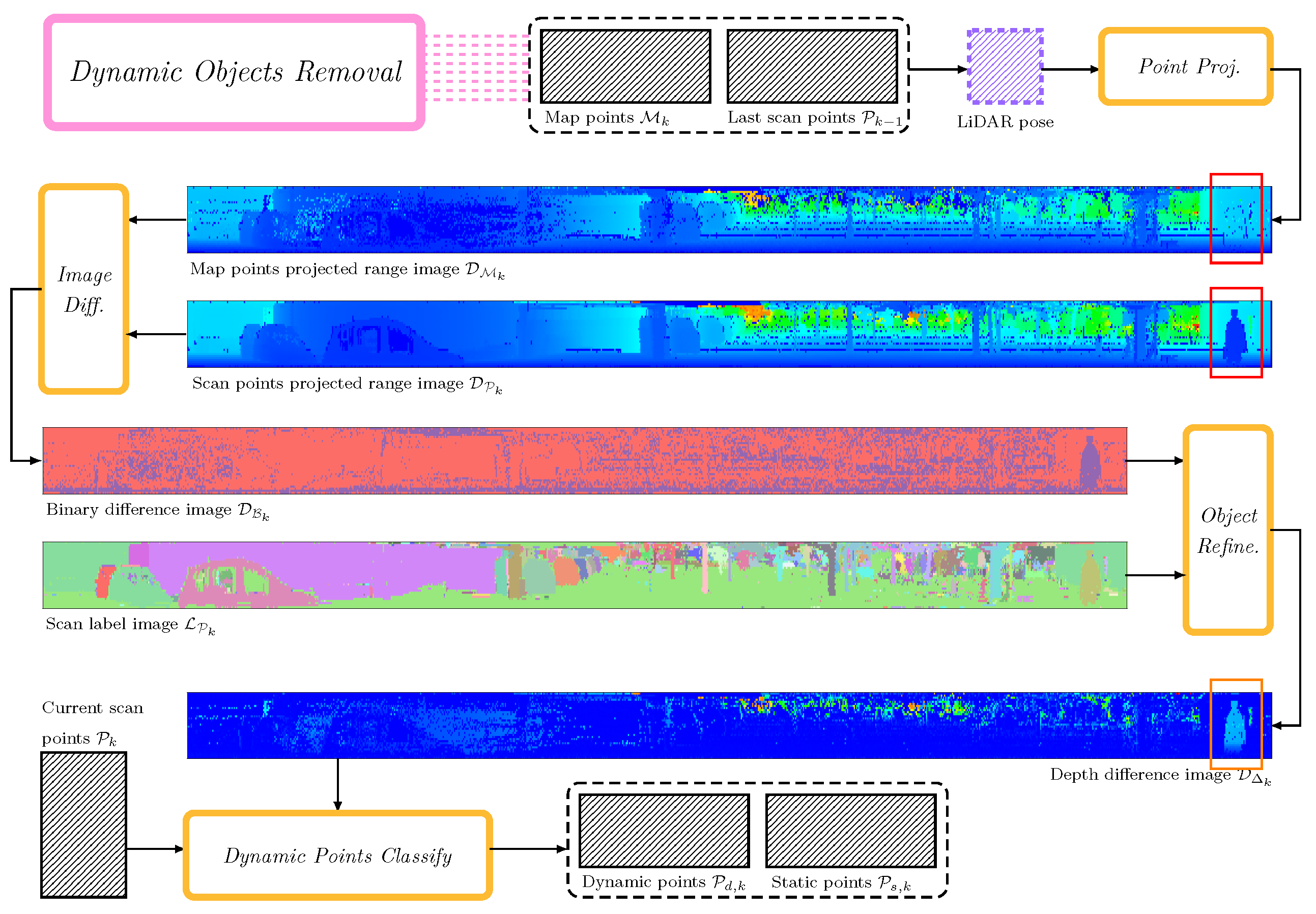
3.3. Dynamic Object Removal
3.3.1. Rendering Range Image for the Local Map
3.3.2. Temporal-Based Dynamic Points Searching
3.3.3. Dynamic Object Validation
3.3.4. Points Classification
3.4. LiDAR Odometry
| Algorithm 1: LiDAR Odometry |
 |
3.4.1. Constraint Model
3.4.2. Transformation Estimation
3.5. LiDAR Mapping
| Algorithm 2: LiDAR Mapping |
 |
3.5.1. Local Feature Map Construction
3.5.2. Mapping Update
4. Results
4.1. Functional module Experiments
4.1.1. Feature Extraction Test
4.1.2. Feature Ablation Test
4.1.3. Dynamic Object Removal
4.2. Pose Transform Estimation Accuracy
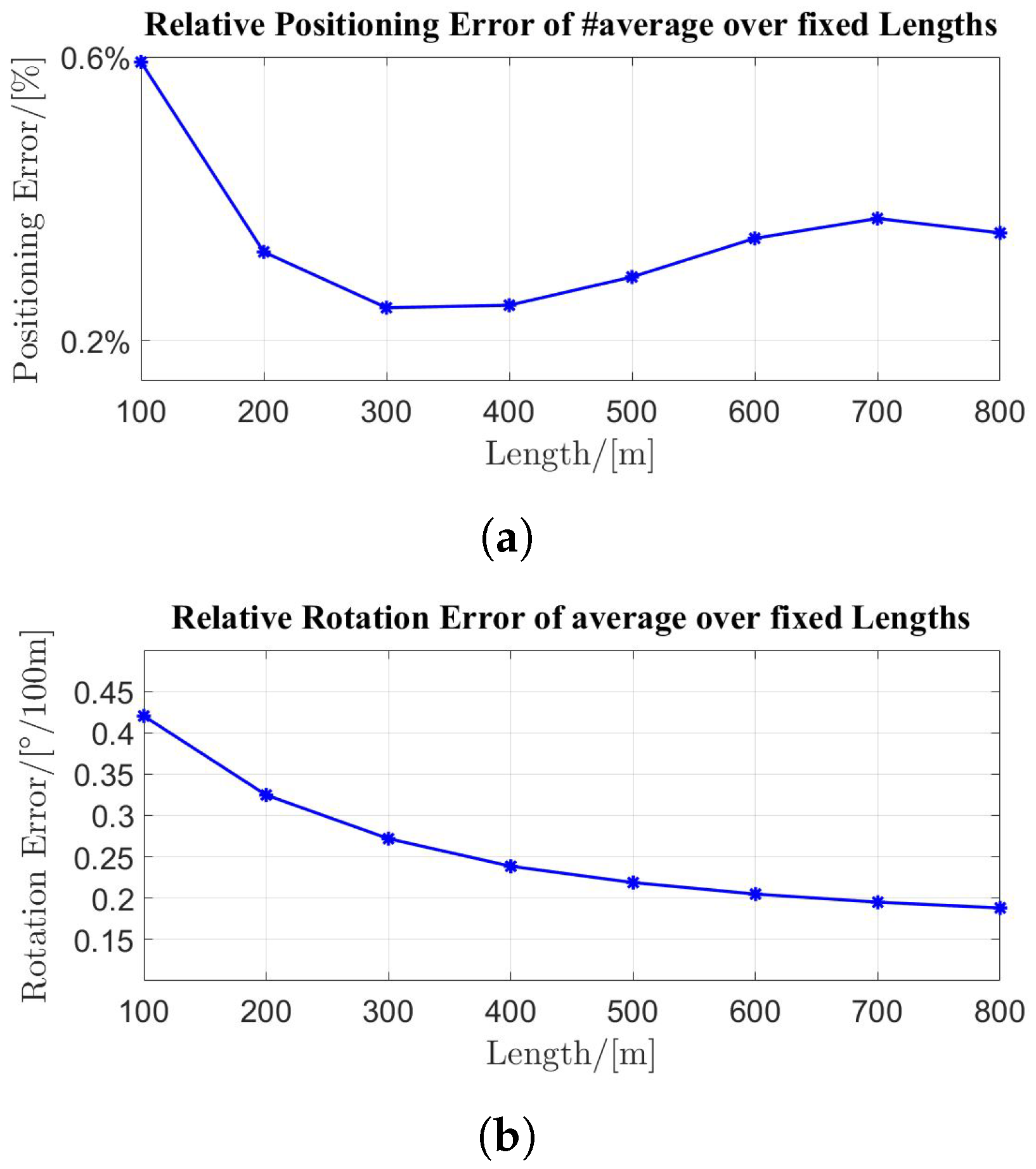
4.2.1. KITTI Dataset
4.2.2. Autonomous Driving Dataset
4.3. Point Cloud Map Quality
4.3.1. Large-Scale Urban Scenario
4.3.2. Long Straight Tunnel Scenario
5. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, S.; Li, G.; Wang, L.; Qin, Y. SLAM integrated mobile mapping system in complex urban environments. ISPRS J. Photogramm. Remote. Sens. 2020, 166, 316–332. [Google Scholar] [CrossRef]
- Ebadi, K.; Chang, Y.; Palieri, M.; Stephens, A.; Hatteland, A.; Heiden, E.; Thakur, A.; Funabiki, N.; Morrell, B.; Wood, S.; et al. LAMP: Large-scale autonomous mapping and positioning for exploration of perceptually-degraded subterranean environments. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 80–86. [Google Scholar]
- Filipenko, M.; Afanasyev, I. Comparison of various slam systems for mobile robot in an indoor environment. In Proceedings of the 2018 International Conference on Intelligent Systems (IS), Funchal, Portugal, 25–27 September 2018; pp. 400–407. [Google Scholar]
- Yang, S.; Zhu, X.; Nian, X.; Feng, L.; Qu, X.; Ma, T. A robust pose graph approach for city scale LiDAR mapping. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1175–1182. [Google Scholar]
- Milz, S.; Arbeiter, G.; Witt, C.; Abdallah, B.; Yogamani, S. Visual slam for automated driving: Exploring the applications of deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 247–257. [Google Scholar]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. ORB-SLAM3: An accurate open-source library for visual, visual-inertial and multi-map SLAM. arXiv 2020, arXiv:2007.11898. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. Vins-mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Singh, S. Low-drift and real-time LiDAR odometry and mapping. Auton. Robot. 2017, 41, 401–416. [Google Scholar] [CrossRef]
- Shan, T.; Englot, B. Lego-loam: Lightweight and ground-optimized LiDAR odometry and mapping on variable terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4758–4765. [Google Scholar]
- Behley, J.; Stachniss, C. Efficient Surfel-Based SLAM using 3D Laser Range Data in Urban Environments. Available online: http://www.roboticsproceedings.org/rss14/p16.pdf (accessed on 1 October 2022).
- Jiao, J.; Ye, H.; Zhu, Y.; Liu, M. Robust Odometry and Mapping for Multi-LiDAR Systems with Online Extrinsic Calibration. arXiv 2020, arXiv:2010.14294. [Google Scholar] [CrossRef]
- Zhou, B.; He, Y.; Qian, K.; Ma, X.; Li, X. S4-SLAM: A real-time 3D LiDAR SLAM system for ground/watersurface multi-scene outdoor applications. Auton. Robot. 2021, 45, 77–98. [Google Scholar] [CrossRef]
- Koide, K.; Miura, J.; Menegatti, E. A portable three-dimensional LiDAR-based system for long-term and wide-area people behavior measurement. Int. J. Adv. Robot. Syst. 2019, 16, 1729881419841532. [Google Scholar] [CrossRef]
- Zhao, S.; Fang, Z.; Li, H.; Scherer, S. A robust lazer-inertial odometry and mapping method for large-scale highway environments. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 1285–1292. [Google Scholar]
- Palieri, M.; Morrell, B.; Thakur, A.; Ebadi, K.; Nash, J.; Chatterjee, A.; Kanellakis, C.; Carlone, L.; Guaragnella, C.; Agha-mohammadi, A.a. LOCUS: A Multi-Sensor LiDAR-Centric Solution for High-Precision Odometry and 3D Mapping in Real-Time. IEEE Robot. Autom. Lett. 2020, 6, 421–428. [Google Scholar] [CrossRef]
- Shan, T.; Englot, B.; Meyers, D.; Wang, W.; Ratti, C.; Rus, D. Lio-sam: Tightly-coupled LiDAR inertial odometry via smoothing and mapping. arXiv 2020, arXiv:2007.00258. [Google Scholar]
- Qin, C.; Ye, H.; Pranata, C.E.; Han, J.; Zhang, S.; Liu, M. LINS: A LiDAR-Inertial State Estimator for Robust and Efficient Navigation. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 8899–8906. [Google Scholar]
- Lin, J.; Zheng, C.; Xu, W.; Zhang, F. R2LIVE: A Robust, Real-time, LiDAR-Inertial-Visual tightly-coupled state Estimator and mapping. arXiv 2021, arXiv:2102.12400. [Google Scholar]
- Li, K.; Li, M.; Hanebeck, U.D. Towards high-performance solid-state-LiDAR-inertial odometry and mapping. IEEE Robot. Autom. Lett. 2021, 6, 5167–5174. [Google Scholar] [CrossRef]
- Dubé, R.; Cramariuc, A.; Dugas, D.; Sommer, H.; Dymczyk, M.; Nieto, J.; Siegwart, R.; Cadena, C. SegMap: Segment-based mapping and localization using data-driven descriptors. Int. J. Robot. Res. 2020, 39, 339–355. [Google Scholar] [CrossRef]
- Droeschel, D.; Schwarz, M.; Behnke, S. Continuous mapping and localization for autonomous navigation in rough terrain using a 3D lazer scanner. Robot. Auton. Syst. 2017, 88, 104–115. [Google Scholar] [CrossRef]
- Ding, W.; Hou, S.; Gao, H.; Wan, G.; Song, S. LiDAR Inertial Odometry Aided Robust LiDAR Localization System in Changing City Scenes. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 4322–4328. [Google Scholar]
- Furukawa, T.; Dantanarayana, L.; Ziglar, J.; Ranasinghe, R.; Dissanayake, G. Fast global scan matching for high-speed vehicle navigation. In Proceedings of the 2015 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), San Diego, CA, USA, 14–16 September 2015; pp. 37–42. [Google Scholar]
- Zong, W.; Li, G.; Li, M.; Wang, L.; Li, S. A survey of lazer scan matching methods. Chin. Opt. 2018, 11, 914–930. [Google Scholar] [CrossRef]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast point feature histograms (FPFH) for 3D registration. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 3212–3217. [Google Scholar]
- Khoury, M.; Zhou, Q.Y.; Koltun, V. Learning compact geometric features. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 153–161. [Google Scholar]
- Pan, Y.; Xiao, P.; He, Y.; Shao, Z.; Li, Z. MULLS: Versatile LiDAR SLAM via Multi-metric Linear Least Square. arXiv 2021, arXiv:2102.03771. [Google Scholar]
- Yin, D.; Zhang, Q.; Liu, J.; Liang, X.; Wang, Y.; Maanpää, J.; Ma, H.; Hyyppä, J.; Chen, R. CAE-LO: LiDAR odometry leveraging fully unsupervised convolutional auto-encoder for interest point detection and feature description. arXiv 2020, arXiv:2001.01354. [Google Scholar]
- Besl, P.J.; McKay, N.D. Method for registration of 3-D shapes. In Sensor Fusion IV: Control Paradigms and Data Structures; International Society for Optics and Photonics: Bellingham, WA, USA, 1992; Volume 1611, pp. 586–606. [Google Scholar]
- Segal, A.; Haehnel, D.; Thrun, S. Generalized-icp. In Proceedings of the Robotics: Science and Systems, Seattle, WA, USA, 28 June–1 July 2009; Volume 2, p. 435. [Google Scholar]
- Yokozuka, M.; Koide, K.; Oishi, S.; Banno, A. LiTAMIN2: Ultra Light LiDAR-based SLAM using Geometric Approximation applied with KL-Divergence. arXiv 2021, arXiv:2103.00784. [Google Scholar]
- Moosmann, F.; Stiller, C. Velodyne slam. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (iv), Baden-Baden, Germany, 5–9 June 2011; pp. 393–398. [Google Scholar]
- Biber, P.; Straßer, W. The normal distributions transform: A new approach to lazer scan matching. In Proceedings of the 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2003) (Cat. No. 03CH37453), Las Vegas, NV, USA, 27–31 October 2003; Volume 3, pp. 2743–2748. [Google Scholar]
- Servos, J.; Waslander, S.L. Multi-Channel Generalized-ICP: A robust framework for multi-channel scan registration. Robot. Auton. Syst. 2017, 87, 247–257. [Google Scholar] [CrossRef] [Green Version]
- Khan, S.; Wollherr, D.; Buss, M. Modeling lazer intensities for simultaneous localization and mapping. IEEE Robot. Autom. Lett. 2016, 1, 692–699. [Google Scholar] [CrossRef]
- Wang, H.; Wang, C.; Xie, L. Intensity-SLAM: Intensity Assisted Localization and Mapping for Large Scale Environment. IEEE Robot. Autom. Lett. 2021, 6, 1715–1721. [Google Scholar] [CrossRef]
- Lu, W.; Wan, G.; Zhou, Y.; Fu, X.; Yuan, P.; Song, S. Deepvcp: An end-to-end deep neural network for point cloud registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 12–21. [Google Scholar]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep learning for 3d point clouds: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4338–4364. [Google Scholar] [CrossRef] [PubMed]
- Yoon, D.; Tang, T.; Barfoot, T. Mapless online detection of dynamic objects in 3d LiDAR. In Proceedings of the 2019 16th Conference on Computer and Robot Vision (CRV), Kingston, QC, Canada, 29–31 May 2019; pp. 113–120. [Google Scholar]
- Dewan, A.; Caselitz, T.; Tipaldi, G.D.; Burgard, W. Motion-based detection and tracking in 3d LiDAR scans. In Proceedings of the 2016 IEEE international conference on robotics and automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 4508–4513. [Google Scholar]
- Kim, G.; Kim, A. Remove, then Revert: Static Point cloud Map Construction using Multiresolution Range Images. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE/RSJ, Las Vegas, NV, USA, 24 October 2020–24 January 2021. [Google Scholar]
- Himmelsbach, M.; Hundelshausen, F.V.; Wuensche, H.J. Fast segmentation of 3D point clouds for ground vehicles. In Proceedings of the 2010 IEEE Intelligent Vehicles Symposium, La Jolla, CA, USA, 21–24 June 2010; pp. 560–565. [Google Scholar]
- Bogoslavskyi, I.; Stachniss, C. Efficient online segmentation for sparse 3d lazer scans. PFG–J. Photogramm. Remote. Sens. Geoinf. Sci. 2017, 85, 41–52. [Google Scholar]
- Sommer, C.; Usenko, V.; Schubert, D.; Demmel, N.; Cremers, D. Efficient derivative computation for cumulative B-splines on Lie groups. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11148–11156. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | #00U | #01H | #02C | #03C | #04C | #05C | #06U | #07U | #08U | #09C | #10C | Avg. | Time [s]/Frame |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LOAM | 0.78/- | 1.43/- | 0.92/- | 0.86/- | 0.71/- | 0.57/- | 0.65/- | 0.63/- | 1.12/- | 0.77/- | 0.79/- | 0.84/- | 0.10 |
| IMLS-SLAM | 0.50/- | 0.82/- | 0.53/- | 0.68/- | 0.33/- | 0.32/- | 0.33/- | 0.33/- | 0.80/- | 0.55/- | 0.53/- | 0.57/- | 1.25 |
| MC2SLAM | 0.51/- | 0.79/- | 0.54/- | 0.65/- | 0.44/- | 0.27/- | 0.31/- | 0.34/- | 0.84/- | 0.46/- | 0.52/- | 0.56/- | 0.10 |
| SuMa | 0.70/0.30 | 1.70/0.50 | 1.10/0.40 | 0.70/0.50 | 0.40/0.30 | 0.40/0.20 | 0.50/0.30 | 0.70/0.60 | 1.00/0.40 | 0.50/0.30 | 0.70/0.30 | 0.70/0.30 | 0.07 |
| LO-Net | 0.78/0.42 | 1.42/0.40 | 1.01/0.45 | 0.73/0.59 | 0.56/0.54 | 0.62/0.35 | 0.55/0.35 | 0.56/0.45 | 1.08/0.43 | 0.77/0.38 | 0.92/0.41 | 0.83/0.42 | 0.10 |
| MULLS-LO | 0.51/0.18 | 0.62/0.09 | 0.55/0.17 | 0.61/0.22 | 0.35/0.08 | 0.28/0.17 | 0.24/0.11 | 0.29/0.18 | 0.80/0.25 | 0.49/0.15 | 0.61/0.19 | 0.49/0.16 | 0.08 |
| InTEn-LOAM | 0.51/0.21 | 0.63/0.35 | 0.54/0.28 | 0.63/0.33 | 0.37/0.31 | 0.36/0.25 | 0.24/0.11 | 0.34/0.31 | 0.71/0.29 | 0.48/0.19 | 0.45/0.21 | 0.54/0.26 | 0.09 |
| Method | Positioning Error (m) | Heading Error | ||
|---|---|---|---|---|
| x | y | Horizontal | Yaw | |
| LOAM | 29.478 | 18.220 | 34.654 | 1.586 |
| HDL-Graph-SLAM | 119.756 | 75.368 | 141.498 | 2.408 |
| MULLS-LO | 4.133 | 5.705 | 7.043 | 1.403 |
| InTEn-LOAM | 1.851 | 1.917 | 2.664 | 0.476 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Tian, B.; Zhu, X.; Gui, J.; Yao, W.; Li, G. InTEn-LOAM: Intensity and Temporal Enhanced LiDAR Odometry and Mapping. Remote Sens. 2023, 15, 242. https://doi.org/10.3390/rs15010242
Li S, Tian B, Zhu X, Gui J, Yao W, Li G. InTEn-LOAM: Intensity and Temporal Enhanced LiDAR Odometry and Mapping. Remote Sensing. 2023; 15(1):242. https://doi.org/10.3390/rs15010242
Chicago/Turabian StyleLi, Shuaixin, Bin Tian, Xiaozhou Zhu, Jianjun Gui, Wen Yao, and Guangyun Li. 2023. "InTEn-LOAM: Intensity and Temporal Enhanced LiDAR Odometry and Mapping" Remote Sensing 15, no. 1: 242. https://doi.org/10.3390/rs15010242