

Ore-Waste Discrimination Using Supervised and Unsupervised Classification of Hyperspectral Images


Abstract
:1. Introduction
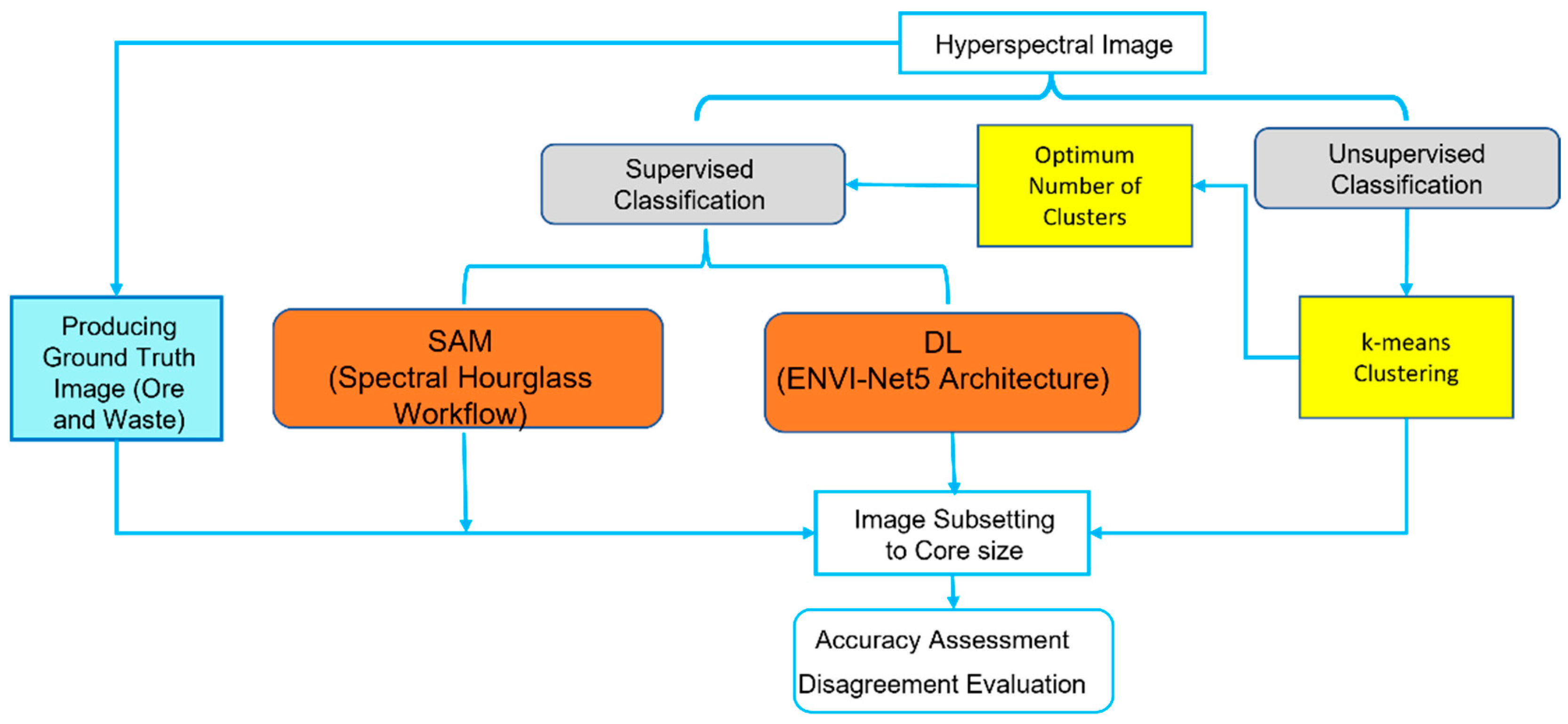
2. Materials and Methods
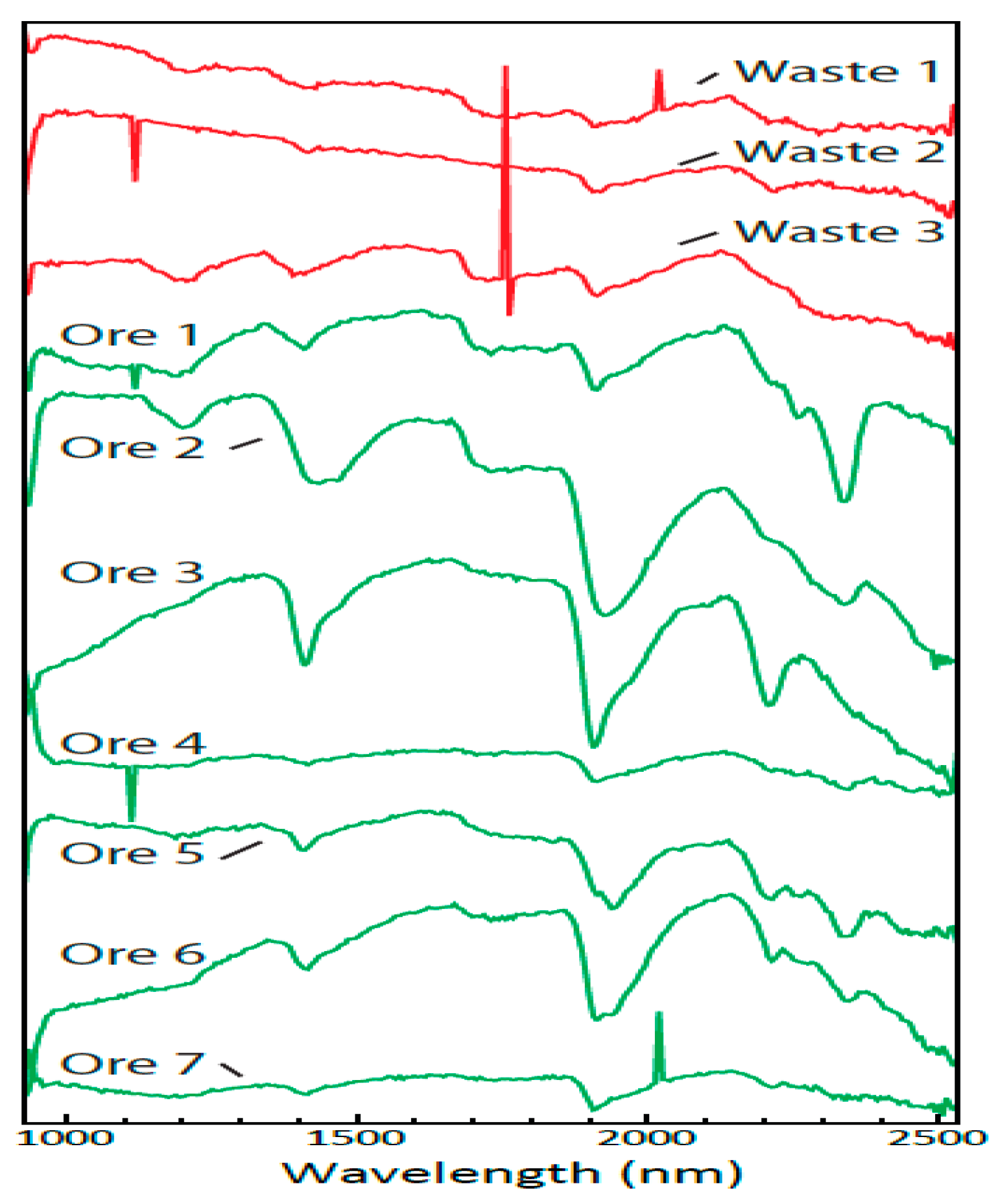
2.1. Dataset
2.2. Methodology
2.2.1. Spectral Angle Mapper
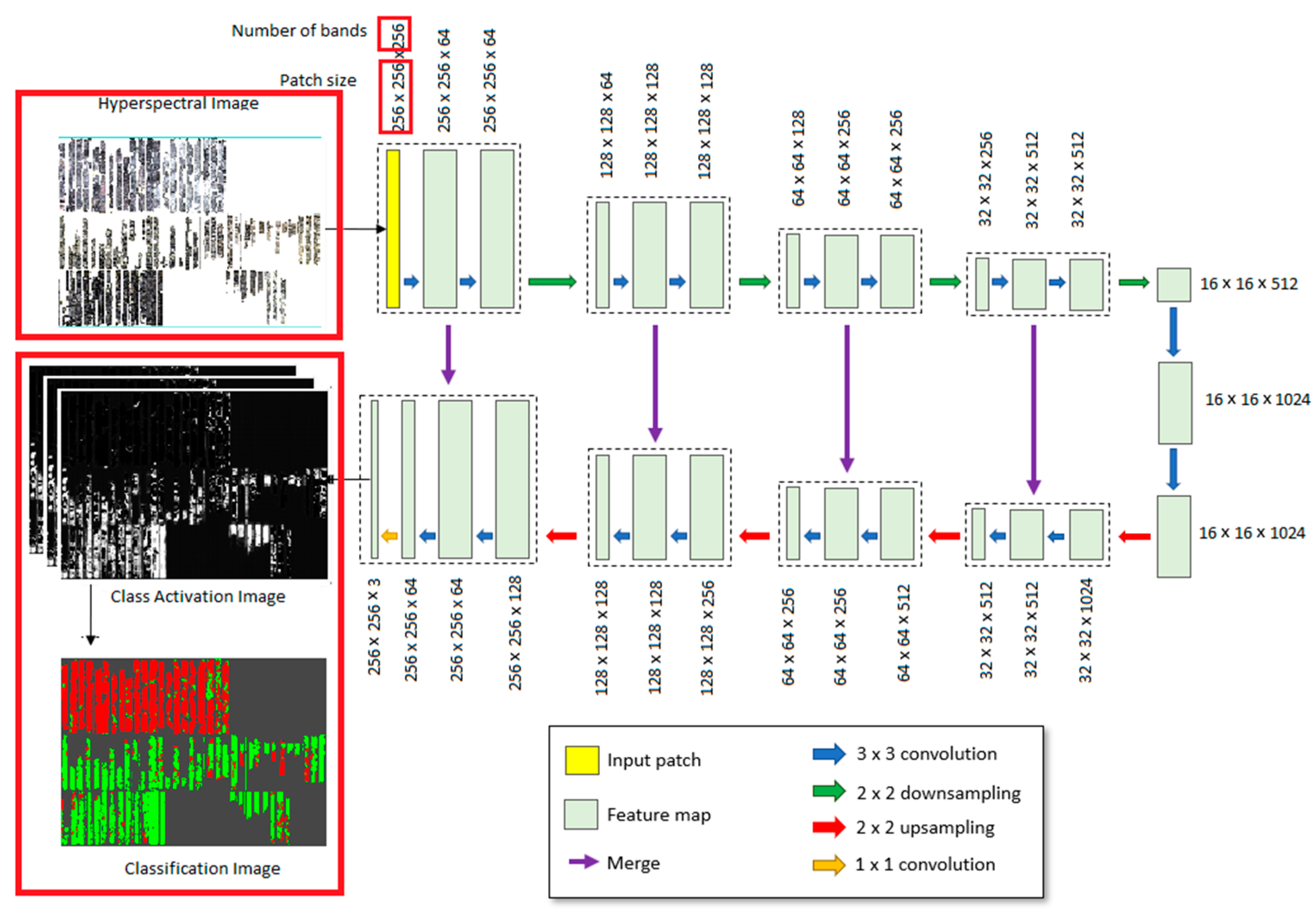
2.2.2. Deep Learning
2.2.3. K-Means
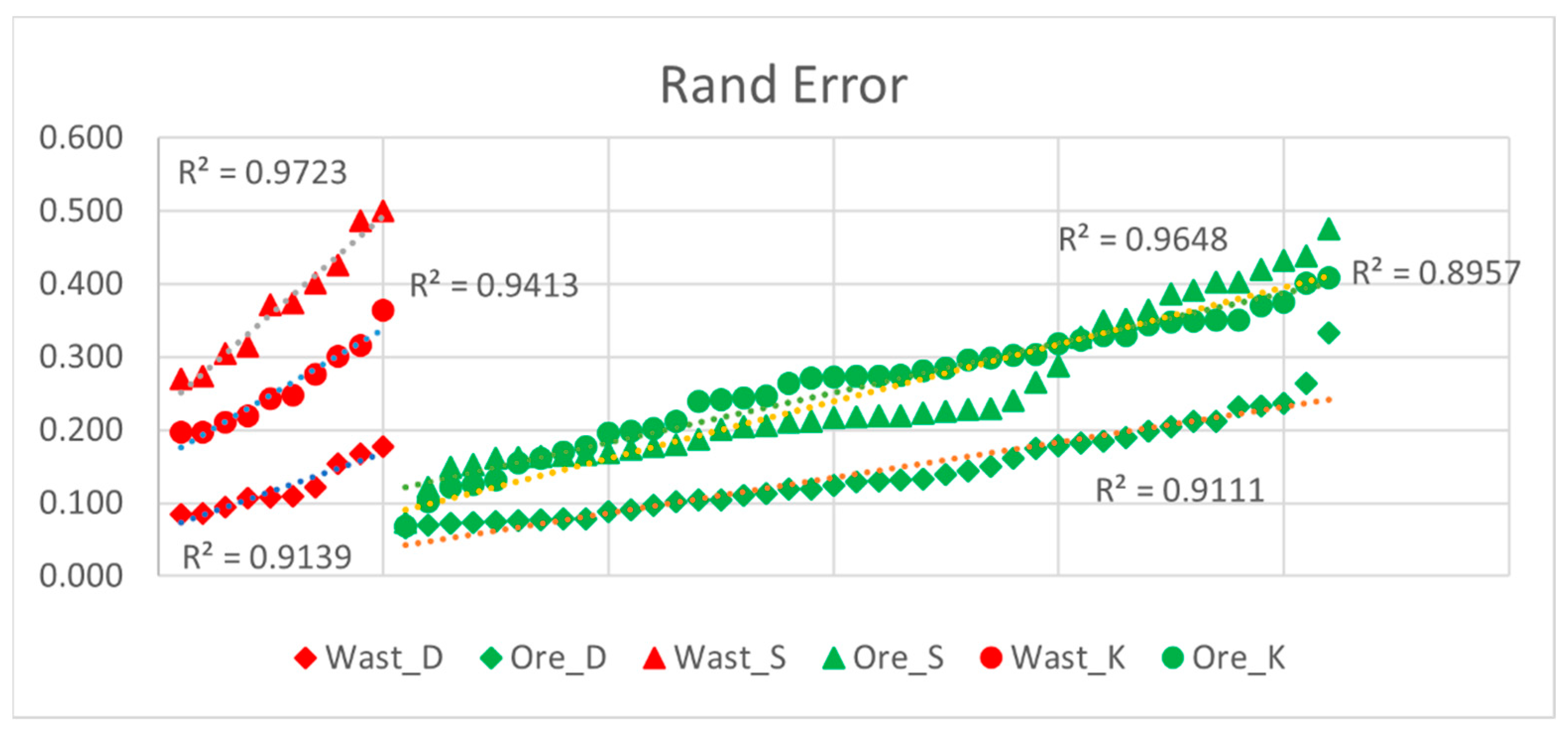
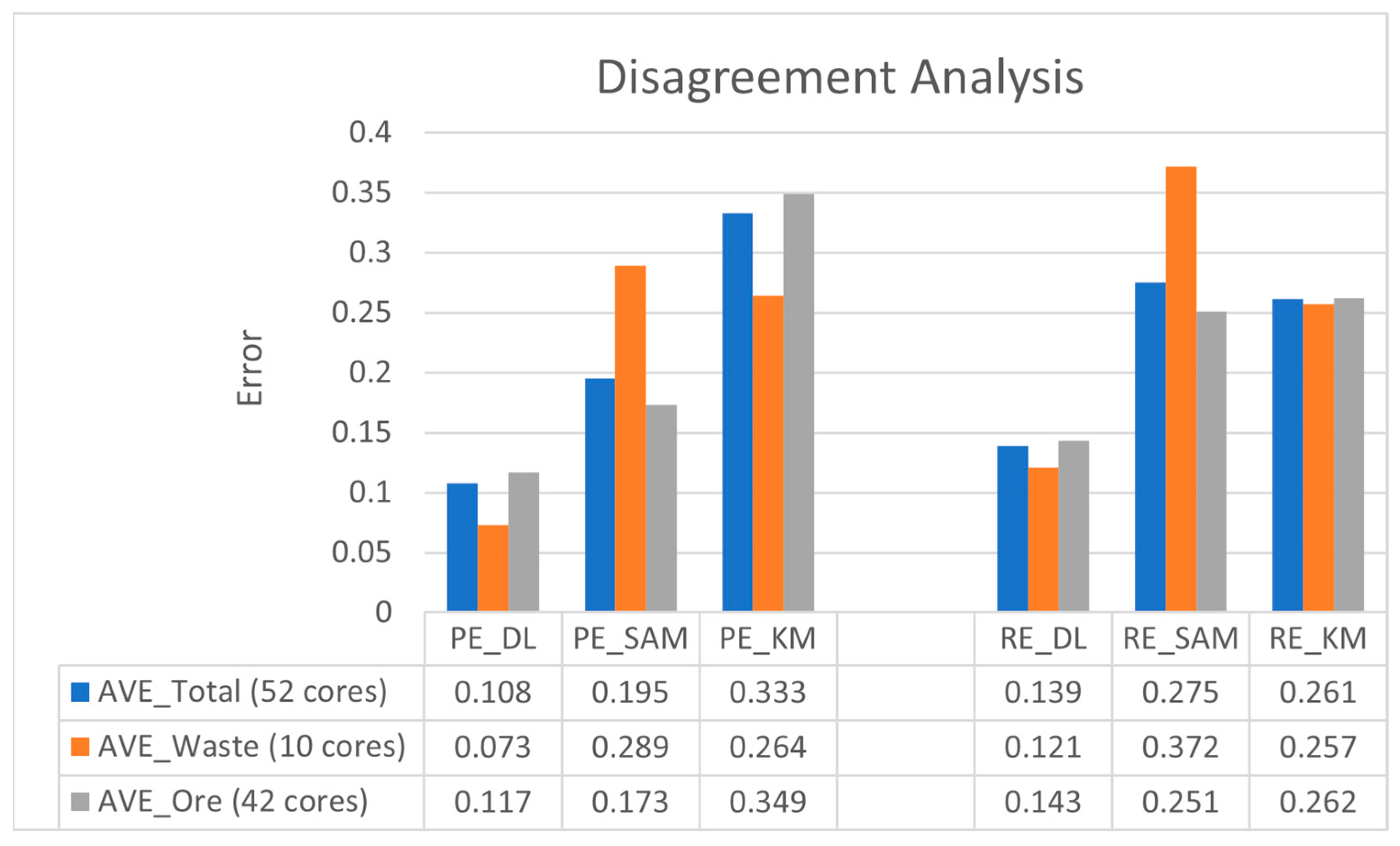
2.2.4. Accuracy Assessment and Disagreement Analysis
- a, the number of pairs of pixels in L that are in the same object in A and in the same object in B (i.e., they have the same label)
- b, the number of pairs of pixels in L that are in different objects in A and in different objects in B (i.e., they have different labels) [41].
3. Results
3.1. Spectral Angle Mapper Classification
3.2. Deep Learning Classification
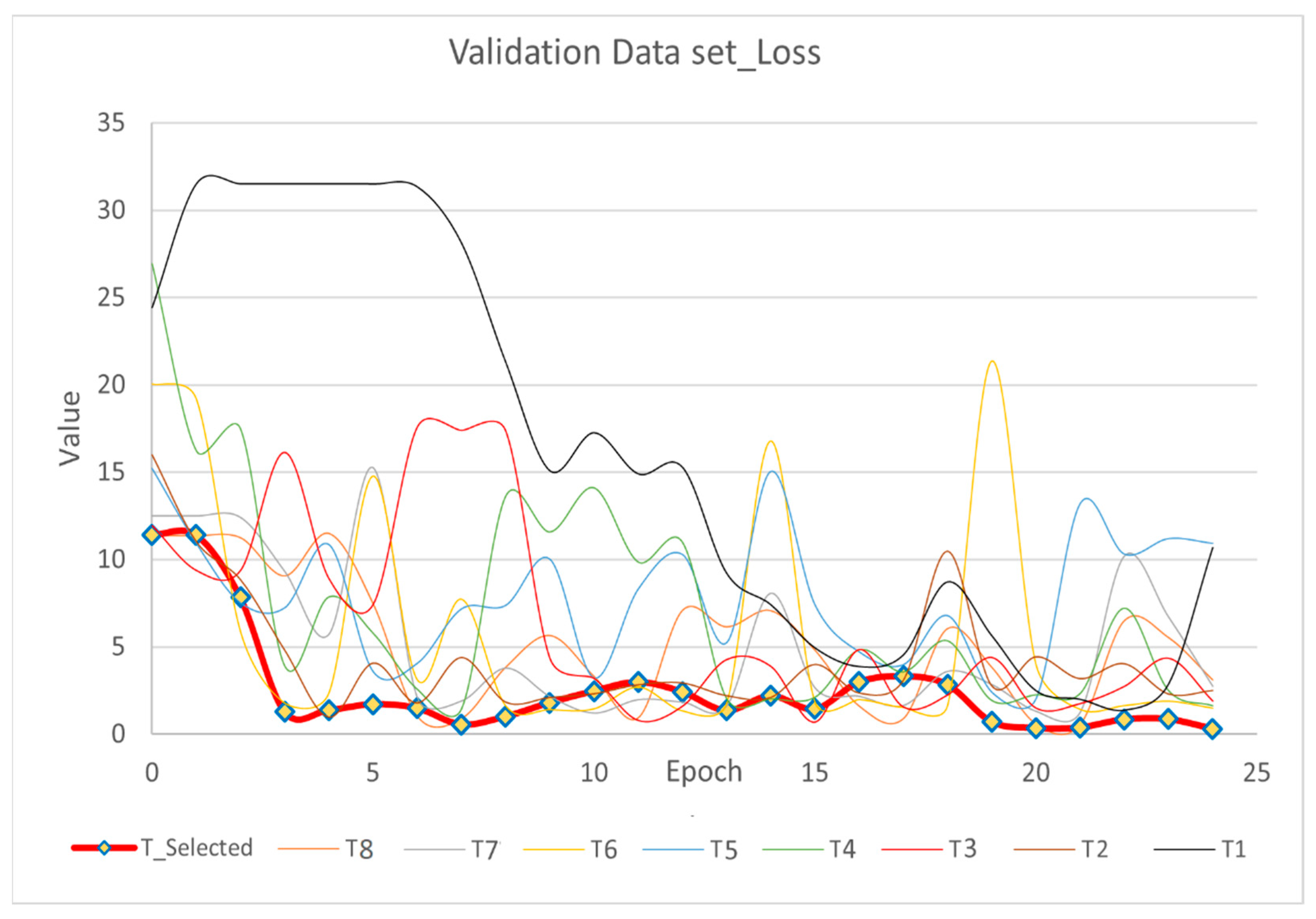
3.2.1. Model Training and Validation
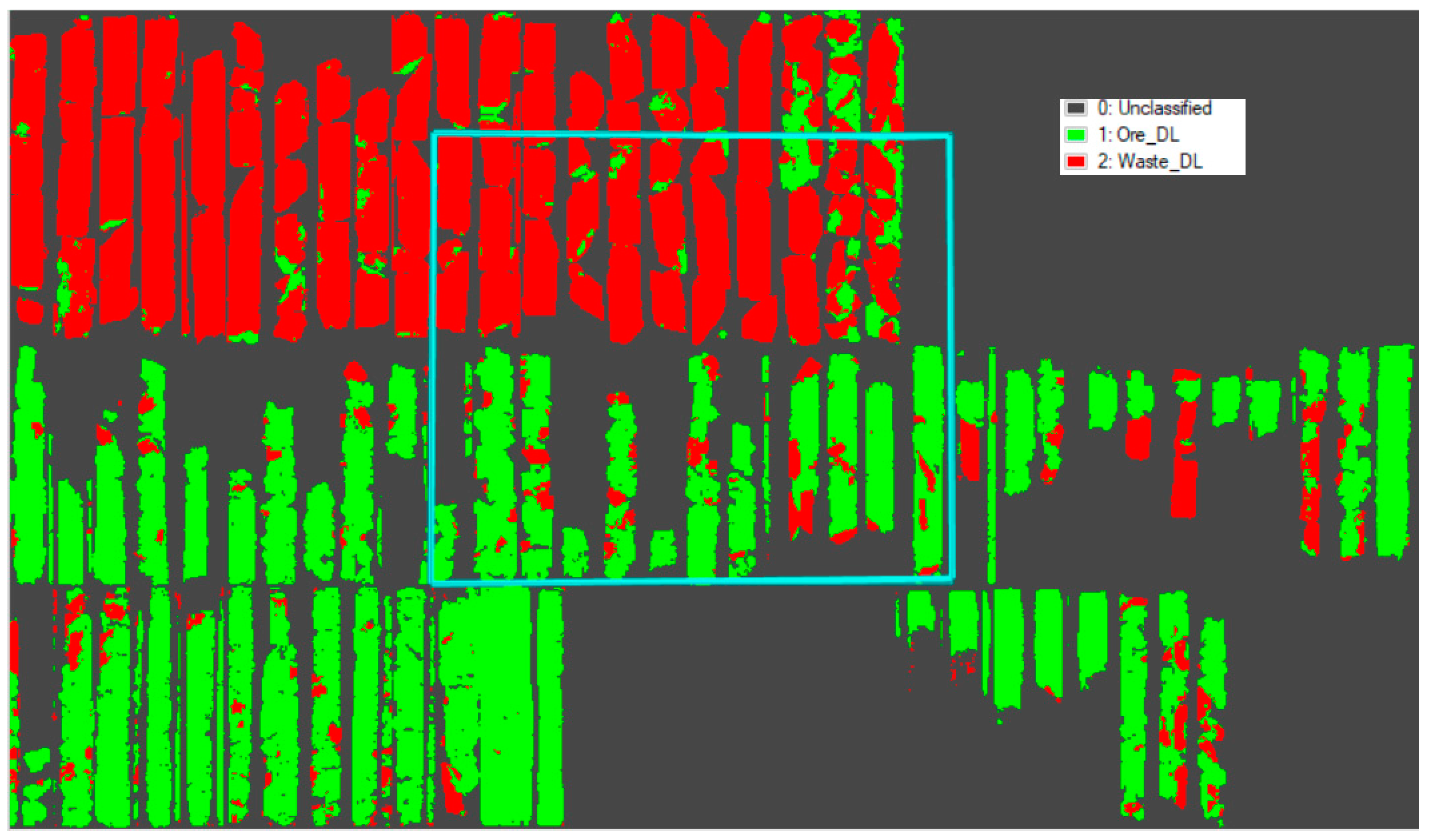
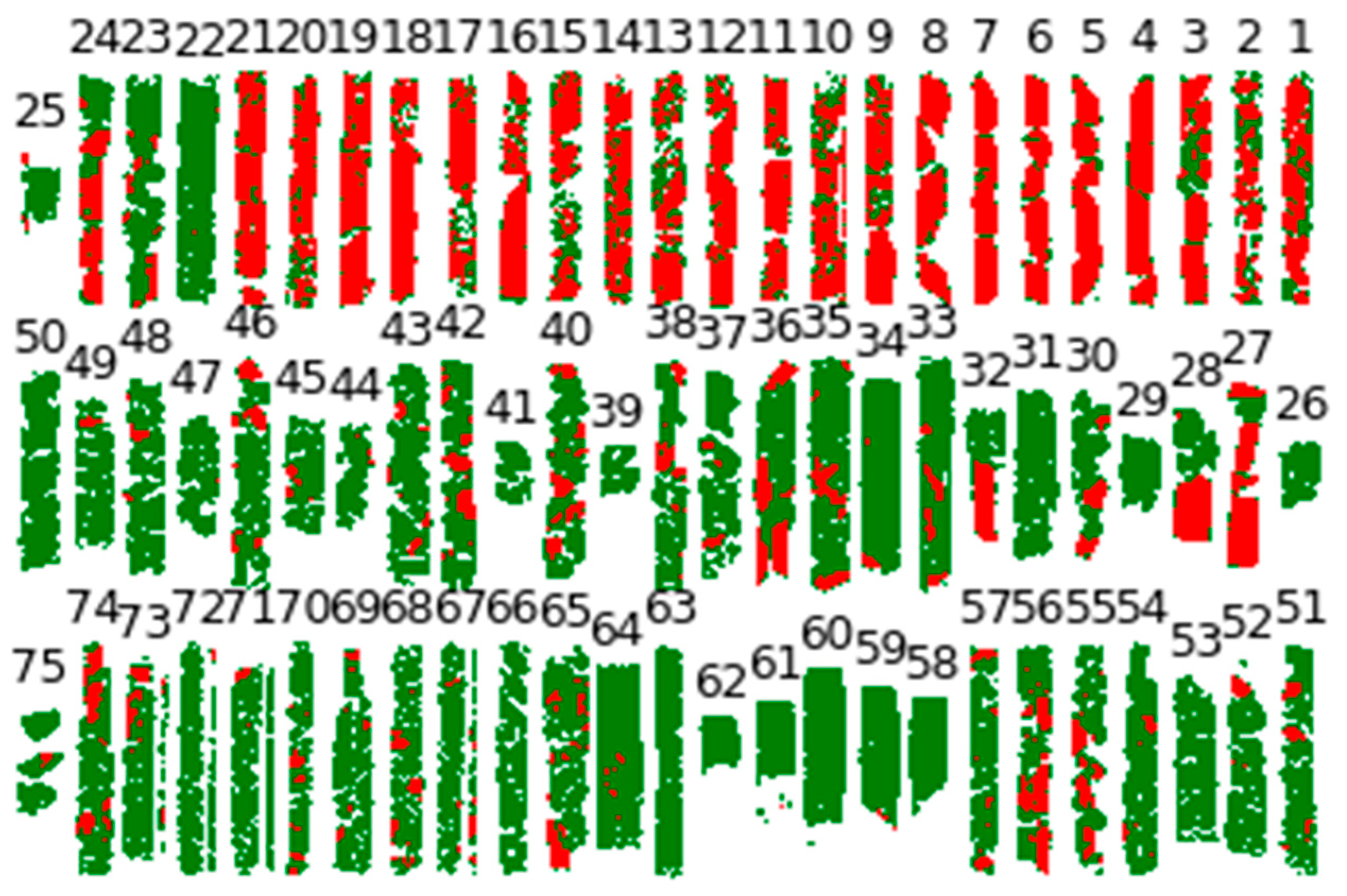
3.2.2. Image Classification
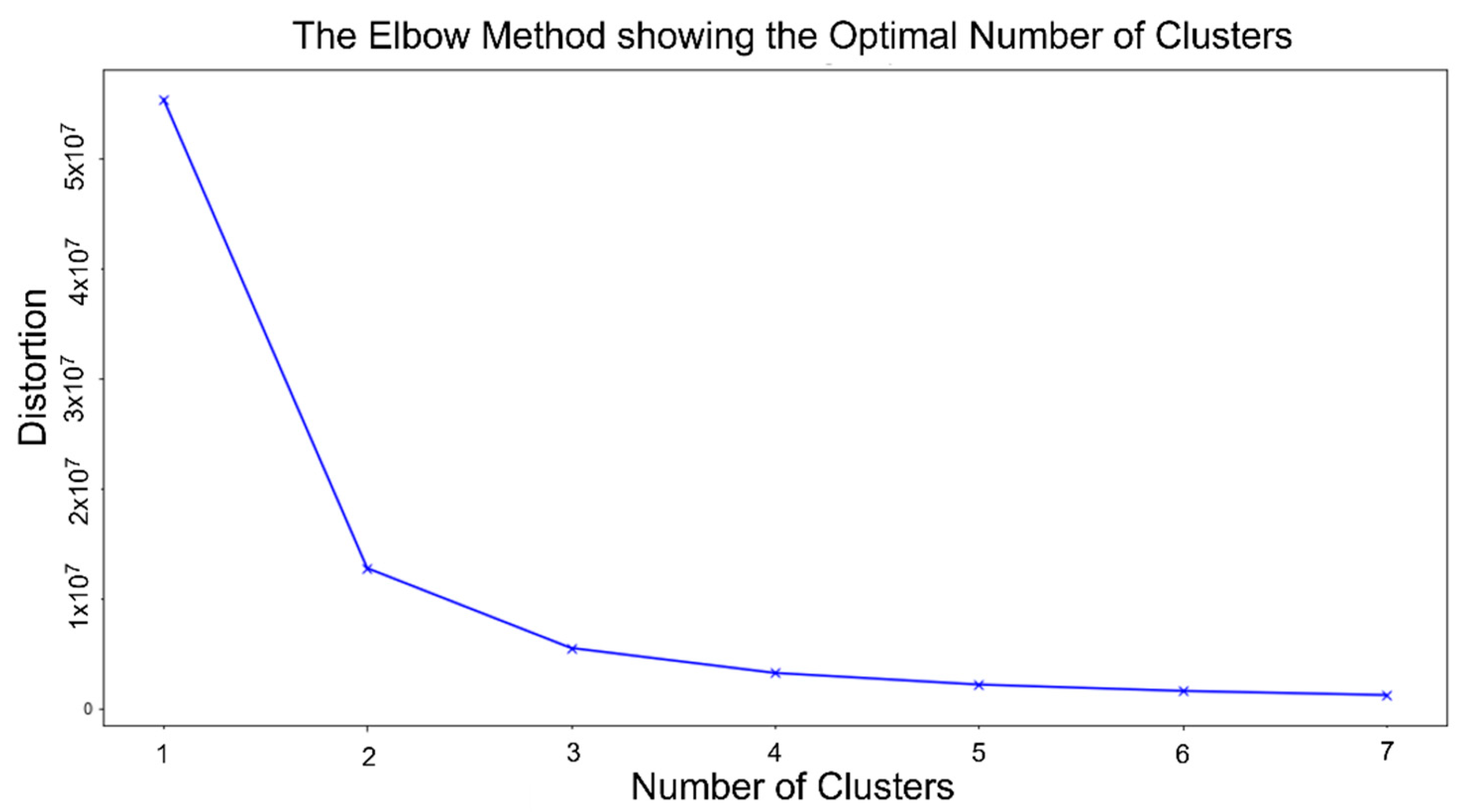
3.3. K-Means Clustering and Determining the Number of Clusters
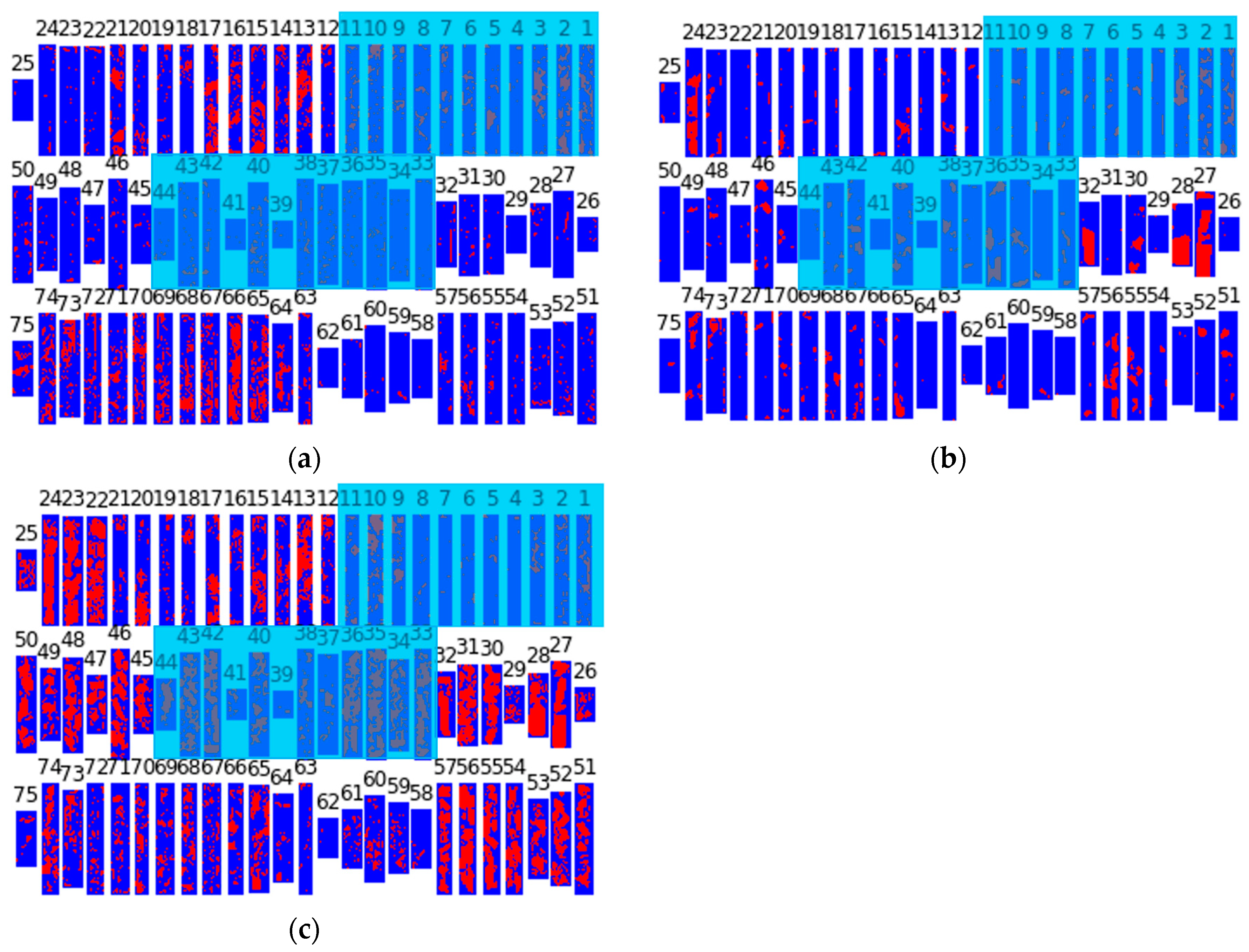
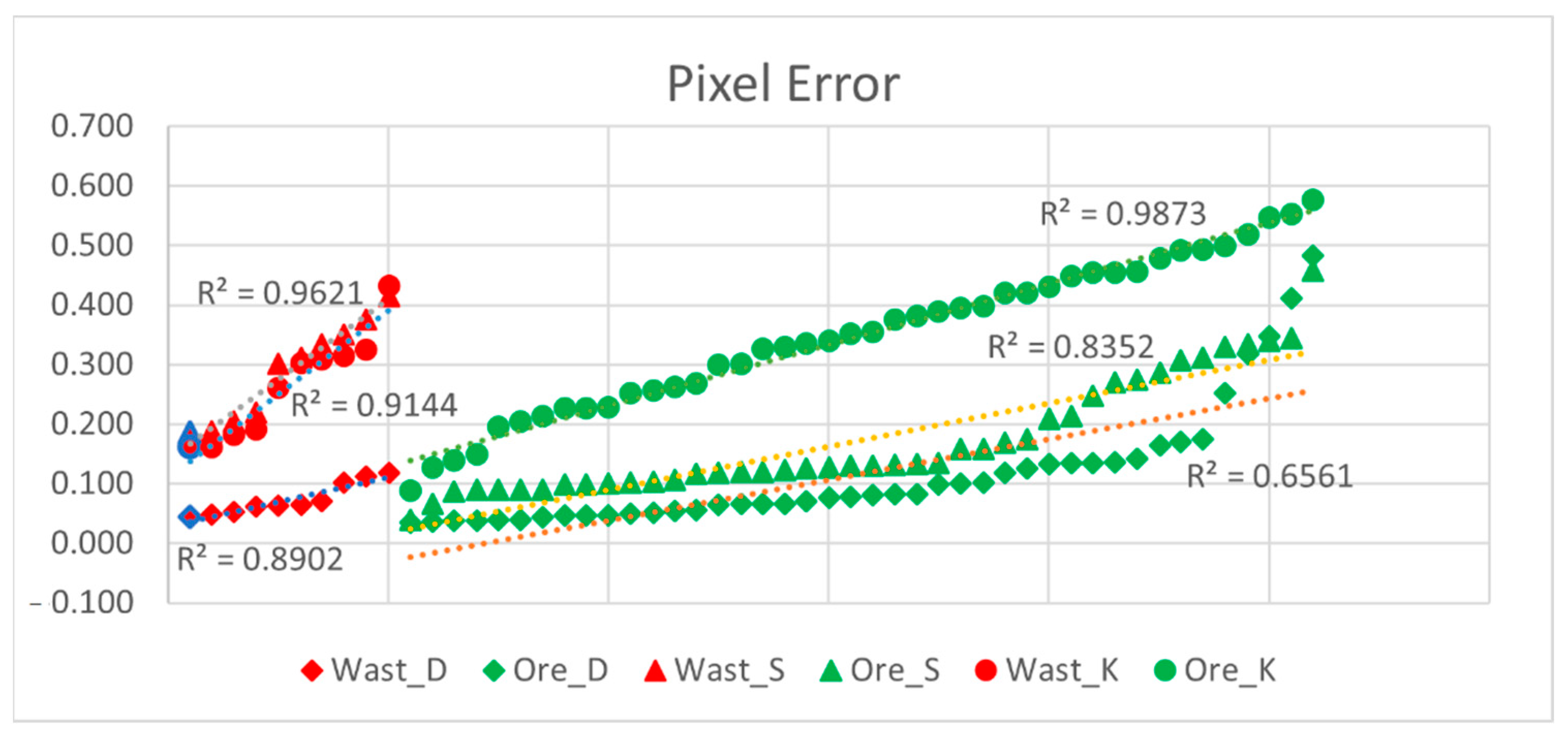
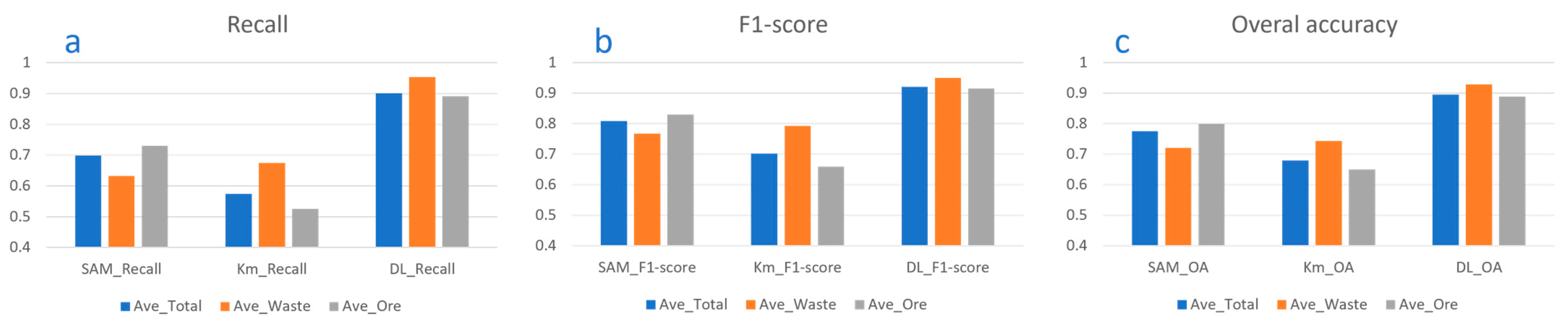
3.4. Comparing Model Performance
3.5. Ensemble Image
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Benndorf, J.; Buxton, M.W.N. Sensor-Based Real-Time Resource Model Reconciliation for Improved Mine Production Control—A Conceptual Framework. Min. Technol. 2016, 125, 54–64. [Google Scholar] [CrossRef] [Green Version]
- Christoffersen, P.; Esmaeili, K.; Rivard, B.; Feng, J.; Osinski, G. Developing Spectral Ore-Waste Discrimination Methods: A Case Study at the El Gallo Silver Deposit, Mexico. In Proceedings of the AME Roundup, Vancouver, BC, Canada, 20–23 January 2020. [Google Scholar]
- Ohadi, B.; Esmaeili, K. Statistical Analysis of Blast-Induced Rock Movement- A Case Study at Detour Lake Mine. In Proceedings of the CIM Conference, Montreal, QC, Canada, 30 April–3 May 2017. [Google Scholar]
- van der Meer, F.D.; van der Werff, H.M.A.; van Ruitenbeek, F.J.A.; Hecker, C.A.; Bakker, W.H.; Noomen, M.F.; van der Meijde, M.; Carranza, E.J.M.; de Smeth, J.B.; Woldai, T. Multi- and Hyperspectral Geologic Remote Sensing: A Review. Int. J. Appl. Earth Obs. Geoinf. 2012, 14, 112–128. [Google Scholar] [CrossRef]
- Samanta, B.; Manna, B.; Chakravarty, D.; Dutta, D. Assessment of Hyperspectral Sampling Based Analysis Technique for Copper Grade Estimation at a Concentrator Plant. J. Powder Metall. Min. 2017, 6, 184. [Google Scholar] [CrossRef]
- Abdolmaleki, M.; Fathianpour, N.; Tabaei, M. Evaluating the Performance of the Wavelet Transform in Extracting Spectral Alteration Features from Hyperspectral Images. Int. J. Remote Sens. 2018, 39, 6076–6094. [Google Scholar] [CrossRef]
- Wills, B.A.; Finch, J.A. Sensor-Based Ore Sorting. In Wills’ Mineral Processing Technology; Elsevier: Amsterdam, The Netherlands, 2016; pp. 409–416. [Google Scholar]
- Buxton, M.W.N.; Benndorf, J. The Use of Sensor Derived Data in Optimization along the Mine-Value-Chain. In Proceedings of the 15th international ISM Congress, Aachen, Germany, 16–20 September 2013; pp. 324–336. [Google Scholar]
- Dalm, M.; Buxton, M.W.N.; van Ruitenbeek, F.J.A. Ore–Waste Discrimination in Epithermal Deposits Using Near-Infrared to Short-Wavelength Infrared (NIR-SWIR) Hyperspectral Imagery. Math. Geosci. 2019, 51, 849–875. [Google Scholar] [CrossRef] [Green Version]
- Bamford, T.; Esmaeili, K.; Schoellig, A.P. A Deep Learning Approach for Rock Fragmentation Analysis. Int. J. Rock Mech. Min. Sci. 2021, 145, 104839. [Google Scholar] [CrossRef]
- Tang, M.; Esmaeili, K. Heap Leach Pad Surface Moisture Monitoring Using Drone-Based Aerial Images and Convolutional Neural Networks: A Case Study at the El Gallo Mine, Mexico. Remote Sens. 2021, 13, 1420. [Google Scholar] [CrossRef]
- Ohadi, B.; Sun, X.; Esmaieli, K.; Consens, M.P. Predicting Blast-Induced Outcomes Using Random Forest Models of Multi-Year Blasting Data from an Open Pit Mine. Bull. Eng. Geol. Environ. 2020, 79, 329–343. [Google Scholar] [CrossRef]
- Cracknell, M.J.; Reading, A.M. Geological Mapping Using Remote Sensing Data: A Comparison of Five Machine Learning Algorithms, Their Response to Variations in the Spatial Distribution of Training Data and the Use of Explicit Spatial Information. Comput. Geosci. 2014, 63, 22–33. [Google Scholar] [CrossRef] [Green Version]
- Beretta, F.; Rodrigues, A.L.; Peroni, R.L.; Costa, J.F.C.L. Automated Lithological Classification Using UAV and Machine Learning on an Open Cast Mine. Appl. Earth Sci. 2019, 128, 79–88. [Google Scholar] [CrossRef]
- Barton, I.F.; Gabriel, M.J.; Lyons-Baral, J.; Barton, M.D.; Duplessis, L.; Roberts, C. Extending Geometallurgy to the Mine Scale with Hyperspectral Imaging: A Pilot Study Using Drone- and Ground-Based Scanning. Min. Met. Explor. 2021, 38, 799–818. [Google Scholar] [CrossRef]
- Choros, K.A.; Job, A.T.; Edgar, M.L.; Austin, K.J.; McAree, P.R. Can Hyperspectral Imaging and Neural Network Classification Be Used for Ore Grade Discrimination at the Point of Excavation? Sensors 2022, 22, 2687. [Google Scholar] [CrossRef] [PubMed]
- Sinaice, B.B.; Owada, N.; Ikeda, H.; Toriya, H.; Bagai, Z.; Shemang, E.; Adachi, T.; Kawamura, Y. Spectral Angle Mapping and AI Methods Applied in Automatic Identification of Placer Deposit Magnetite Using Multispectral Camera Mounted on UAV. Minerals 2022, 12, 268. [Google Scholar] [CrossRef]
- Petropoulos, G.P.; Vadrevu, K.P.; Xanthopoulos, G.; Karantounias, G.; Scholze, M. A Comparison of Spectral Angle Mapper and Artificial Neural Network Classifiers Combined with Landsat TM Imagery Analysis for Obtaining Burnt Area Mapping. Sensors 2010, 10, 1967–1985. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, Y.; Zhang, Z.; Liu, X.; Wang, L.; Xia, X. Ore Image Classification Based on Small Deep Learning Model: Evaluation and Optimization of Model Depth, Model Structure and Data Size. Min. Eng. 2021, 172, 107020. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3523–3542. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, X.; Yang, J.; Little, E.; Zhou, Y. Deep Learning-Based Method for SEM Image Segmentation in Mineral Characterization, an Example from Duvernay Shale Samples in Western Canada Sedimentary Basin. Comput. Geosci. 2020, 138, 104450. [Google Scholar] [CrossRef]
- Roy, A.G.; Navab, N.; Wachinger, C. Concurrent Spatial and Channel ’Squeeze & Excitation’ in Fully Convolutional Networks. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer International Publishing: Cham, Germany, 2018; pp. 421–429. [Google Scholar]
- Desta, F.; Buxton, M. Image and Point Data Fusion for Enhanced Discrimination of Ore and Waste in Mining. Minerals 2020, 10, 1110. [Google Scholar] [CrossRef]
- MacQueen, J.B. Some Methods for Classification and Analysis of Multivariate Observations. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability; Le Cam, L.M., Neyman, J., Eds.; University of California Press: Berkeley, CA, USA, 1967; pp. 281–297. [Google Scholar]
- Paoletti, M.E.; Haut, J.M.; Plaza, J.; Plaza, A. Deep Learning Classifiers for Hyperspectral Imaging: A Review. ISPRS J. Photogramm. Remote Sens. 2019, 158, 279–317. [Google Scholar] [CrossRef]
- Rangnekar, A.; Mokashi, N.; Ientilucci, E.J.; Kanan, C.; Hoffman, M.J. AeroRIT: A New Scene for Hyperspectral Image Analysis. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8116–8124. [Google Scholar] [CrossRef]
- Okada, N.; Maekawa, Y.; Owada, N.; Haga, K.; Shibayama, A.; Kawamura, Y. Automated Identification of Mineral Types and Grain Size Using Hyperspectral Imaging and Deep Learning for Mineral Processing. Minerals 2020, 10, 809. [Google Scholar] [CrossRef]
- Lypaczewski, P.; Rivard, B.; Gaillard, N.; Perrouty, S.; Piette-Lauzière, N.; Bérubé, C.L.; Linnen, R.L. Using Hyperspectral Imaging to Vector towards Mineralization at the Canadian Malartic Gold Deposit, Québec, Canada. Ore Geol. Rev. 2019, 111, 102945. [Google Scholar] [CrossRef]
- Nalepa, J.; Myller, M.; Kawulok, M. Validating Hyperspectral Image Segmentation. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1264–1268. [Google Scholar] [CrossRef] [Green Version]
- Abdolmaleki, M.; Tabaei, M.; Fathianpour, N.; Gorte, B.G.H. Selecting Optimum Base Wavelet for Extracting Spectral Alteration Features Associated with Porphyry Copper Mineralization Using Hyperspectral Images. Int. J. Appl. Earth Obs. Geoinf. 2017, 58, 134–144. [Google Scholar] [CrossRef]
- Lorenz, S.; Salehi, S.; Kirsch, M.; Zimmermann, R.; Unger, G.; Vest Sørensen, E.; Gloaguen, R. Radiometric Correction and 3D Integration of Long-Range Ground-Based Hyperspectral Imagery for Mineral Exploration of Vertical Outcrops. Remote Sens. 2018, 10, 176. [Google Scholar] [CrossRef] [Green Version]
- Kurz, T.H.; Buckley, S.J.; Howell, J.A. Close-Range Hyperspectral Imaging for Geological Field Studies: Workflow and Methods. Int. J. Remote Sens. 2013, 34, 1798–1822. [Google Scholar] [CrossRef]
- Kruse, F.A.; Lefkoff, A.B.; Boardman, J.W.; Heidebrecht, K.B.; Shapiro, A.T.; Barloon, P.J.; Goetz, A.F.H. The Spectral Image Processing System (SIPS)—Interactive Visualization and Analysis of Imaging Spectrometer Data. Remote Sens. Environ. 1993, 44, 145–163. [Google Scholar] [CrossRef]
- Fetai, B.; Račič, M.; Lisec, A. Deep Learning for Detection of Visible Land Boundaries from UAV Imagery. Remote Sens. 2021, 13, 2077. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- L3 Harris Geospatial Pixel Segmentation Training Background. Available online: https://www.l3harrisgeospatial.com/docs/PixelSegmentationTrainingBackground.html (accessed on 9 May 2022).
- Sood, V.; Tiwari, R.K.; Singh, S.; Kaur, R.; Parida, B.R. Glacier Boundary Mapping Using Deep Learning Classification over Bara Shigri Glacier in Western Himalayas. Sustainability 2022, 14, 13485. [Google Scholar] [CrossRef]
- Lv, Z.; Hu, Y.; Zhong, H.; Wu, J.; Li, B.; Zhao, H. Parallel K-Means Clustering of Remote Sensing Images Based on MapReduce. In Proceedings of the International Conference on Web Information Systems and Mining, Sanya, China, 23–24 October 2010; pp. 162–170. [Google Scholar]
- Liu, L.; Peng, Z.; Wu, H.; Jiao, H.; Yu, Y.; Zhao, J. Fast Identification of Urban Sprawl Based on K-Means Clustering with Population Density and Local Spatial Entropy. Sustainability 2018, 10, 2683. [Google Scholar] [CrossRef]
- Umargono, E.; Suseno, J.E.; Vincensius Gunawan, S.K. K-Means Clustering Optimization Using the Elbow Method and Early Centroid Determination Based-on Mean and Median. In Proceedings of the International Conferences on Information System and Technology, Cairo, Egypt, 24–26 March 2019; SCITEPRESS—Science and Technology Publications: Setubal, Portugal, 2019; pp. 234–240. [Google Scholar]
- Zhu, F.; Liu, Q.; Fu, Y.; Shen, B. Segmentation of Neuronal Structures Using SARSA (λ)-Based Boundary Amendment with Reinforced Gradient-Descent Curve Shape Fitting. PLoS ONE 2014, 9, e90873. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.-Y.; Wang, C.-K. BUILDING SEGMENTATION IN AGRICULTURAL LAND USING HIGH RESOLUTION SATELLITE IMAGERY BASED ON DEEP LEARNING APPROACH. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2021, XLIII-B3-2021, 587–594. [Google Scholar] [CrossRef]
- Zhang, P.; Xu, C.; Ma, S.; Shao, X.; Tian, Y.; Wen, B. Automatic Extraction of Seismic Landslides in Large Areas with Complex Environments Based on Deep Learning: An Example of the 2018 Iburi Earthquake, Japan. Remote Sens. 2020, 12, 3992. [Google Scholar] [CrossRef]
- Wolfe, J.D.; Black, S.R. Hyperspectral Analytics in ENVI Target. Detection and Spectral Mapping Methods; Harris Corporation: Melbourne, FL, USA, 2018. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training/Validation Split | 80% |
|---|---|
| Patch size | 256 × 256 Pixels |
| Number of Epochs | 25 |
| Patches per Image | 100 |
| Class Weight | 0–3 |
| Loss Weight | 0.5 |
| Optimizer | Stochastic Gradient Descent (SGD) |
| Momentum Coefficient | 0.99 |
| Patch Sampling Rate | 16 |
| PE | 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | (11) | (10) | (9) | (8) | (7) | (6) | (5) | (4) | (3) | (2) | (1) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DL_GT-ref | 0.10 | 0.35 | 0.13 | 0.04 | 0.06 | 0.10 | 0.06 | 0.05 | 0.04 | 0.06 | 0.12 | 0.05 | 0.11 | 0.07 | 0.05 | 0.10 | 0.06 | 0.09 | 0.07 | 0.10 | 0.07 | 0.07 | 0.23 | 0.29 | 0.27 |
| SAM_GT-ref | 0.09 | 0.10 | 0.09 | 0.13 | 0.35 | 0.22 | 0.19 | 0.18 | 0.41 | 0.30 | 0.33 | 0.31 | 0.38 | 0.21 | 0.28 | 0.31 | 0.23 | 0.17 | 0.22 | 0.21 | 0.20 | 0.12 | 0.30 | 0.37 | 0.35 |
| KM_GT-ref | 0.30 | 0.49 | 0.50 | 0.52 | 0.16 | 0.30 | 0.16 | 0.19 | 0.31 | 0.18 | 0.32 | 0.32 | 0.43 | 0.26 | 0.22 | 0.41 | 0.26 | 0.07 | 0.08 | 0.08 | 0.07 | 0.04 | 0.16 | 0.20 | 0.24 |
| 50 | 49 | 48 | 47 | 46 | 45 | (44) | (43) | (42) | (41) | (40) | (39) | (38) | (37) | (36) | (35) | (34) | (33) | 32 | 31 | 30 | 29 | 28 | 27 | 26 | |
| DL_GT-ref | 0.04 | 0.06 | 0.08 | 0.05 | 0.13 | 0.08 | 0.06 | 0.08 | 0.19 | 0.05 | 0.18 | 0.04 | 0.14 | 0.07 | 0.28 | 0.15 | 0.05 | 0.12 | 0.32 | 0.05 | 0.16 | 0.05 | 0.41 | 0.48 | 0.06 |
| SAM_GT-ref | 0.16 | 0.13 | 0.10 | 0.10 | 0.13 | 0.13 | 0.13 | 0.16 | 0.14 | 0.09 | 0.21 | 0.15 | 0.20 | 0.18 | 0.15 | 0.17 | 0.16 | 0.11 | 0.12 | 0.13 | 0.09 | 0.12 | 0.11 | 0.07 | 0.12 |
| KM_GT-ref | 0.40 | 0.33 | 0.45 | 0.40 | 0.45 | 0.39 | 0.33 | 0.46 | 0.50 | 0.18 | 0.33 | 0.09 | 0.25 | 0.17 | 0.51 | 0.56 | 0.45 | 0.53 | 0.42 | 0.55 | 0.46 | 0.30 | 0.58 | 0.49 | 0.35 |
| 75 | 74 | 73 | 72 | 71 | 70 | 69 | 68 | 67 | 66 | 65 | 64 | 63 | 62 | 61 | 60 | 59 | 58 | 57 | 56 | 55 | 54 | 53 | 52 | 51 | |
| DL_GT-ref | 0.05 | 0.18 | 0.13 | 0.07 | 0.08 | 0.12 | 0.08 | 0.14 | 0.13 | 0.07 | 0.14 | 0.04 | 0.05 | 0.04 | 0.08 | 0.04 | 0.05 | 0.03 | 0.10 | 0.25 | 0.17 | 0.07 | 0.04 | 0.07 | 0.10 |
| SAM_GT-ref | 0.21 | 0.31 | 0.31 | 0.25 | 0.28 | 0.34 | 0.29 | 0.33 | 0.34 | 0.46 | 0.33 | 0.27 | 0.21 | 0.10 | 0.12 | 0.09 | 0.10 | 0.04 | 0.16 | 0.17 | 0.12 | 0.09 | 0.17 | 0.13 | 0.13 |
| KM_GT-ref | 0.13 | 0.37 | 0.27 | 0.20 | 0.23 | 0.34 | 0.23 | 0.33 | 0.25 | 0.26 | 0.38 | 0.21 | 0.15 | 0.09 | 0.21 | 0.26 | 0.23 | 0.14 | 0.43 | 0.55 | 0.45 | 0.48 | 0.35 | 0.42 | 0.34 |
| RE | 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | (11) | (10) | (9) | (8) | (7) | (6) | (5) | (4) | (3) | (2) | (1) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DL_GT-ref | 0.15 | 0.23 | 0.16 | 0.07 | 0.11 | 0.15 | 0.11 | 0.09 | 0.08 | 0.11 | 0.17 | 0.09 | 0.18 | 0.12 | 0.09 | 0.16 | 0.10 | 0.13 | 0.12 | 0.15 | 0.12 | 0.12 | 0.27 | 0.26 | 0.30 |
| SAM_GT-ref | 0.16 | 0.17 | 0.15 | 0.23 | 0.37 | 0.31 | 0.27 | 0.27 | 0.50 | 0.37 | 0.40 | 0.43 | 0.49 | 0.30 | 0.36 | 0.43 | 0.35 | 0.19 | 0.26 | 0.24 | 0.21 | 0.17 | 0.30 | 0.27 | 0.36 |
| KM_GT-ref | 0.16 | 0.13 | 0.17 | 0.33 | 0.20 | 0.25 | 0.20 | 0.22 | 0.32 | 0.21 | 0.24 | 0.30 | 0.36 | 0.28 | 0.23 | 0.34 | 0.29 | 0.08 | 0.11 | 0.11 | 0.09 | 0.06 | 0.20 | 0.19 | 0.26 |
| 50 | 49 | 48 | 47 | 46 | 45 | (44) | (43) | (42) | (41) | (40) | (39) | (38) | (37) | (36) | (35) | (34) | (33) | 32 | 31 | 30 | 29 | 28 | 27 | 26 | |
| DL_GT-ref | 0.08 | 0.11 | 0.12 | 0.09 | 0.17 | 0.13 | 0.10 | 0.12 | 0.23 | 0.09 | 0.23 | 0.08 | 0.18 | 0.11 | 0.27 | 0.21 | 0.10 | 0.18 | 0.24 | 0.09 | 0.18 | 0.10 | 0.33 | 0.18 | 0.10 |
| SAM_GT-ref | 0.27 | 0.22 | 0.18 | 0.18 | 0.22 | 0.21 | 0.22 | 0.26 | 0.22 | 0.14 | 0.30 | 0.24 | 0.29 | 0.27 | 0.22 | 0.27 | 0.26 | 0.20 | 0.21 | 0.22 | 0.16 | 0.22 | 0.19 | 0.12 | 0.20 |
| KM_GT-ref | 0.35 | 0.35 | 0.30 | 0.28 | 0.27 | 0.30 | 0.21 | 0.32 | 0.25 | 0.19 | 0.29 | 0.14 | 0.25 | 0.19 | 0.25 | 0.35 | 0.37 | 0.34 | 0.20 | 0.33 | 0.12 | 0.27 | 0.20 | 0.07 | 0.25 |
| 75 | 74 | 73 | 72 | 71 | 70 | 69 | 68 | 67 | 66 | 65 | 64 | 63 | 62 | 61 | 60 | 59 | 58 | 57 | 56 | 55 | 54 | 53 | 52 | 51 | |
| DL_GT-ref | 0.07 | 0.23 | 0.20 | 0.12 | 0.13 | 0.19 | 0.13 | 0.21 | 0.21 | 0.13 | 0.20 | 0.07 | 0.10 | 0.08 | 0.12 | 0.07 | 0.08 | 0.07 | 0.14 | 0.26 | 0.19 | 0.11 | 0.08 | 0.10 | 0.14 |
| SAM_GT-ref | 0.23 | 0.39 | 0.39 | 0.35 | 0.36 | 0.44 | 0.35 | 0.42 | 0.43 | 0.48 | 0.40 | 0.40 | 0.33 | 0.16 | 0.20 | 0.16 | 0.17 | 0.07 | 0.24 | 0.23 | 0.17 | 0.15 | 0.29 | 0.21 | 0.22 |
| KM_GT-ref | 0.13 | 0.35 | 0.32 | 0.27 | 0.30 | 0.41 | 0.27 | 0.38 | 0.34 | 0.35 | 0.37 | 0.32 | 0.24 | 0.10 | 0.20 | 0.29 | 0.24 | 0.16 | 0.26 | 0.21 | 0.18 | 0.30 | 0.40 | 0.28 | 0.24 |
| Classification Report SAM | Classification Report k-Means | Classification Report DL | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | Accuracy | |||
| #18 Class Waste | 0.99 | 0.76 | 0.86 | 0.82 | #19 Class Waste | 0.98 | 0.8 | 0.88 | 0.84 | #17 Class Waste | 0.95 | 1 | 0.97 | 0.96 |
| #58 Class Ore | 0.98 | 0.96 | 0.97 | 0.96 | #62 Class Ore | 0.97 | 0.86 | 0.91 | 0.91 | #58 Class Ore | 0.95 | 0.99 | 0.97 | 0.97 |
| 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ore | 0.44 | 0.26 | 0.52 | 0.72 | 0.03 | 0.05 | 0.02 | 0.01 | 0.01 | 0.03 | 0.08 | 0.02 | 0.08 | 0.03 | 0.02 | 0.04 | 0.02 | 0.04 | 0.03 | 0.05 | 0.03 | 0.01 | 0.16 | 0.23 | 0.21 |
| Waste | 0.03 | 0.30 | 0.09 | 0.01 | 0.64 | 0.51 | 0.67 | 0.65 | 0.57 | 0.61 | 0.44 | 0.55 | 0.53 | 0.64 | 0.59 | 0.55 | 0.65 | 0.52 | 0.62 | 0.62 | 0.56 | 0.70 | 0.52 | 0.38 | 0.49 |
| Background | 0.53 | 0.44 | 0.39 | 0.26 | 0.33 | 0.43 | 0.31 | 0.34 | 0.42 | 0.36 | 0.49 | 0.43 | 0.39 | 0.33 | 0.39 | 0.41 | 0.33 | 0.44 | 0.34 | 0.32 | 0.41 | 0.29 | 0.31 | 0.39 | 0.29 |
| 50 | 49 | 48 | 47 | 46 | 45 | 44 | 43 | 42 | 41 | 40 | 39 | 38 | 37 | 36 | 35 | 34 | 33 | 32 | 31 | 30 | 29 | 28 | 27 | 26 | |
| Ore | 0.67 | 0.63 | 0.63 | 0.65 | 0.56 | 0.62 | 0.52 | 0.65 | 0.55 | 0.57 | 0.51 | 0.59 | 0.52 | 0.56 | 0.42 | 0.65 | 0.75 | 0.70 | 0.31 | 0.77 | 0.42 | 0.68 | 0.34 | 0.09 | 0.63 |
| Waste | 0.01 | 0.02 | 0.03 | 0.01 | 0.11 | 0.05 | 0.02 | 0.06 | 0.14 | 0.01 | 0.14 | 0.00 | 0.09 | 0.03 | 0.24 | 0.12 | 0.03 | 0.09 | 0.25 | 0.00 | 0.12 | 0.00 | 0.34 | 0.43 | 0.00 |
| Background | 0.32 | 0.34 | 0.33 | 0.34 | 0.33 | 0.33 | 0.46 | 0.29 | 0.31 | 0.42 | 0.35 | 0.41 | 0.39 | 0.40 | 0.33 | 0.23 | 0.22 | 0.21 | 0.44 | 0.23 | 0.46 | 0.32 | 0.32 | 0.48 | 0.37 |
| 75 | 74 | 73 | 72 | 71 | 70 | 69 | 68 | 67 | 66 | 65 | 64 | 63 | 62 | 61 | 60 | 59 | 58 | 57 | 56 | 55 | 54 | 53 | 52 | 51 | |
| Ore | 0.46 | 0.55 | 0.54 | 0.61 | 0.60 | 0.58 | 0.60 | 0.60 | 0.57 | 0.66 | 0.58 | 0.85 | 0.74 | 0.51 | 0.52 | 0.73 | 0.68 | 0.67 | 0.58 | 0.45 | 0.43 | 0.67 | 0.73 | 0.56 | 0.54 |
| Waste | 0.03 | 0.17 | 0.08 | 0.01 | 0.03 | 0.06 | 0.05 | 0.10 | 0.05 | 0.02 | 0.13 | 0.03 | 0.00 | 0.00 | 0.02 | 0.00 | 0.01 | 0.00 | 0.08 | 0.24 | 0.16 | 0.04 | 0.00 | 0.04 | 0.06 |
| Background | 0.51 | 0.29 | 0.38 | 0.37 | 0.37 | 0.35 | 0.35 | 0.30 | 0.38 | 0.33 | 0.29 | 0.13 | 0.25 | 0.49 | 0.46 | 0.26 | 0.31 | 0.33 | 0.34 | 0.31 | 0.42 | 0.29 | 0.26 | 0.40 | 0.40 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdolmaleki, M.; Consens, M.; Esmaeili, K. Ore-Waste Discrimination Using Supervised and Unsupervised Classification of Hyperspectral Images. Remote Sens. 2022, 14, 6386. https://doi.org/10.3390/rs14246386
Abdolmaleki M, Consens M, Esmaeili K. Ore-Waste Discrimination Using Supervised and Unsupervised Classification of Hyperspectral Images. Remote Sensing. 2022; 14(24):6386. https://doi.org/10.3390/rs14246386
Chicago/Turabian StyleAbdolmaleki, Mehdi, Mariano Consens, and Kamran Esmaeili. 2022. "Ore-Waste Discrimination Using Supervised and Unsupervised Classification of Hyperspectral Images" Remote Sensing 14, no. 24: 6386. https://doi.org/10.3390/rs14246386