1. Introduction
One of significant problems in urban areas is a growing number of traffic-related emissions [
1], which may harm air quality and impact human health. Among air pollution emitted by vehicles are volatile organic compounds (NMVOC), particulate matter (PM), sulfur oxides (SOx), nitrogen oxides (NOx), ammonia (
), non-methane volatile organic compounds (NMVOC) and others [
2].
From a technical point of view, the process of pollution monitoring is a relatively straightforward task. It needs a sensor network installed in a given area. Particular sensors in such a network operate in parallel, measuring levels of selected pollutants and other relevant parameters. After optional data processing, the sensors send the readings to a base station for further processing. On the basis of gathered data, the base station creates a pollution map, actualized within specified time intervals. Such solutions are already offered on the market by several companies, which include Airly [
3], LookO2 [
4] and Luftdaten [
5].
A substantially different problem to the one described above comes with the ability to reliably predict future pollutant levels over a given time horizon. Such information is particularly crucial for city users who are potentially the most affected by air pollution (cyclists, pedestrians, etc.). Based on a map containing short-time predictions of pollutant levels, they can appropriately plan their way through the city.
In this paper, we present a concept of an air pollution monitoring system with the possibility of predicting pollution levels in a specific time horizon. What is new in our work is how wireless sensors equipped with on-board hardware-implemented ANNs obtain training datasets that are adapted to local environment conditions in the place of installation of particular sensors. In this work, we also deal with the issue of an effective implementation of a hardware ANN used for prediction. For this purpose, we have proposed such modifications to the learning algorithm that allows for the use of much simpler (basic) arithmetic operations that allow for a significant reduction in the computational complexity of the ANN.
The paper is organized as follows. The next section is devoted to state-of-the-art analysis of related topics. After that, we highlight problems that may affect prediction quality. As we observe, the prediction results may substantially differ even for similar values of the weather conditions frequently used. This is influenced by local conditions in particular locations in cities (microclimate, urban development, etc.). For this reason, in the following section we present a novel approach to the configuration of the ANN, in which the learning datasets are completed locally in particular areas of the city. This is a significant difference from what is being proposed in comparison with other state-of-the-art works. As a result, the ANNs, being components of intelligent wireless sensors, do not need to communicate with the base station during the learning process. The following section is devoted to solutions facilitating the implementation of the BP ANN in a specialized low-power application-specific integrated circuit (ASIC). To make this possible, mathematical formulas typically used in such a network were transformed accordingly. As a result, the overall learning process is limited to relatively simple arithmetic operations. Finally, conclusions are drawn in the last section.
2. Related Works
The problem of predicting future pollutant levels is one of the issues that is gaining in importance, as shown by the literature. A lot of work in this area has been devoted to the use of artificial intelligence (AI) solutions, in most cases ANNs, in solving this problem [
6,
7]. They include, for example, support vector machines [
8], fuzzy logic [
9,
10], deterministic models, multiple linear regression [
11], and hidden Markov models [
12]. However, the statistical approaches require a large quantity of measurement data under various atmospheric conditions, so in this case they present some limitations. In aiming to overcome these limitations, ANNs [
13] can be used along with statistical methods [
13]. There has been a growing interest in recent years in the use of ANNs in predicting and forecasting air pollution. Examples of state-of-the art studies in this area are summarized in
Table 1, with explanations of the used abbreviations provided in
Table 2. We discuss selected works from this table in subsequent sections of this paper, while describing our proposed concept.
The comparative analysis outlined in
Table 1 demonstrates that learning data used to train ANNs for prediction purposes in most cases are composed of major meteorological factors, such as temperature (T), relative humidity (RH), wind speed (WD) and direction (WD), as well as selected levels of air pollution factors (typically
). In reality, various other factors related to urban development in cities play a crucial role. In [
14], for example, selected factors related to local urban conditions such as, for example, street width (SW) and building height (BW) were included in the learning dataset.
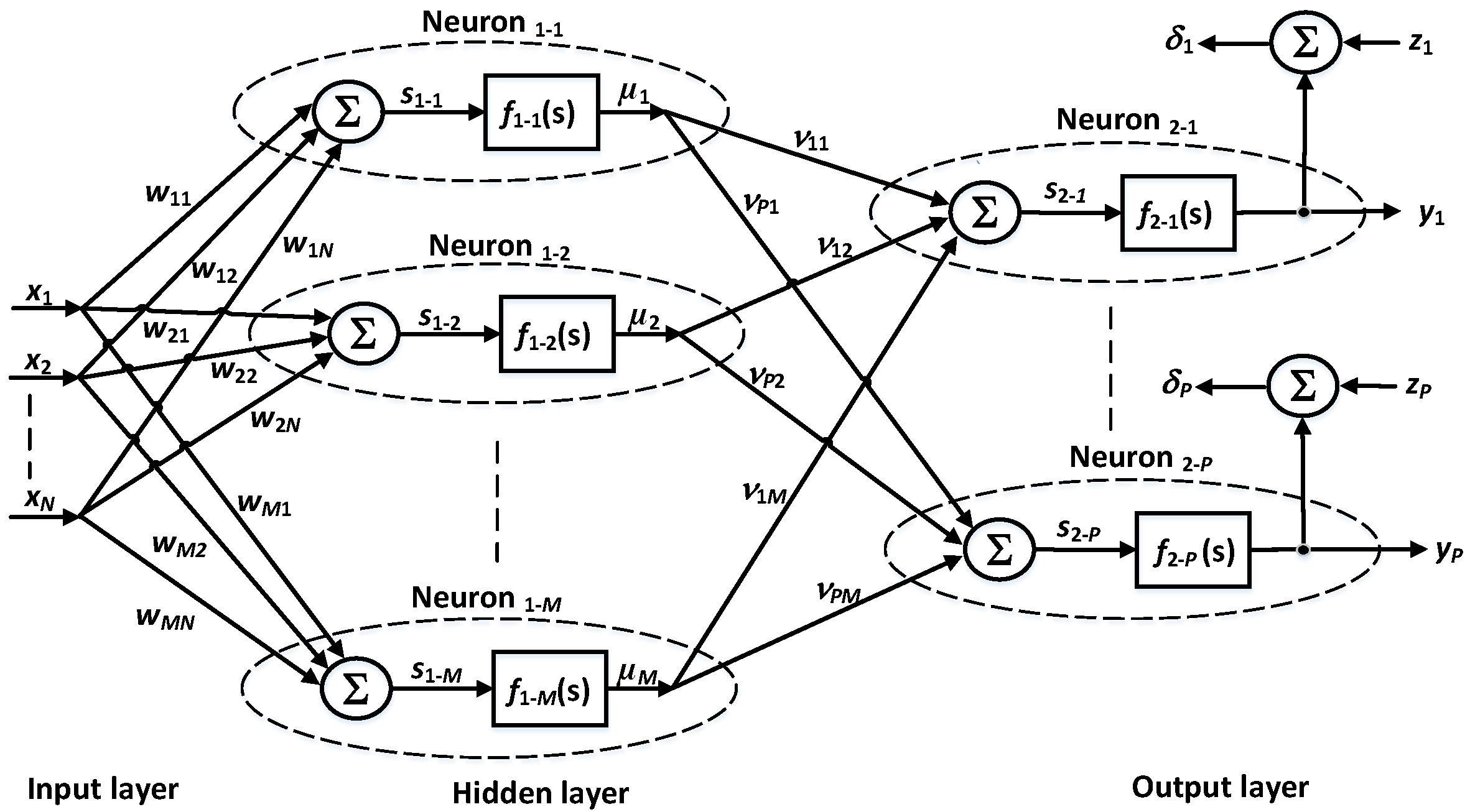
Hardware Implementation of the ANN
A review of the state-of-the art literature shows that multilayer backpropagation (BP) ANNs offer popular solutions for prediction problems. In the problem addressed in this paper, the amount of input data for such ANNs is relatively small and varies between 4 and 15, depending on the described solution. At the same time, the network should output one or several computed signals, each of which is a prediction of one type of pollution.
The BP learning algorithm is now new. One can also find its various hardware realizations, to mention only two of the newest ones [
26,
27]. In [
26], for example, an analog voltage-mode CMOS-memristive BP learning circuit is proposed and implemented in the TSMC CMOS 180 nm technology. The authors of this work paid attention to the realization of basic components used in this circuit, such as sigmoid and tangent activation function, multiplying circuit, an amplifier, and analog switches.
In [
27], nanoscale memristive devices have been used to support the design of the BP ANN. It is a hybrid CMOS-memristive convolutional computation system for on-chip learning. A modified backpropagation (BP) algorithm suitable for the proposed memristive neural networks is in this case applied to perform image convolution and recognition.
In our work, we propose another approach. Since the proposed BP architecture is going to become a component of a wireless sensor, a paramount feature is its implementation simplicity and strongly reduced energy consumption, so that the overall sensor does not require a complex power supply block. To make this possible, in our work, we propose such modifications to the learning algorithm so that it can be implemented using only elementary arithmetic operations.
3. Impact of Environmental Conditions on Prediction Results and Proposed Distributed Approach
When implementing the proposed system solution with the ability to predict changes in the level of pollution, the urban structure of the city should be also taken into account. There are many elements constituting a component of a given spatial arrangement of urbanized areas. From this article’s point of view, quite important are buildings and open areas. In cities, this depends, among other things, on dispersion conditions, i.e., spreading, taking into account various precipitation, temperature differences, or air mass movements. For example, large green spaces, such as parks or riverside boulevards, serve as “ventilating wedges”, contributing to the thinning of harmful substances in the air. Therefore, in these types of areas the level of pollution, temperature, or humidity will be different to the rest of the city. Wind speed may also be different, especially along watercourses; within such areas, there will also be other results of temperatures and humidity, which may affect the study of the level of pollution.
It is worth noticing that for similar values of T, RH, WS, WD, factors but for different environmental conditions, predicted pollution levels may differ significantly. Selected conditions that may affect the prediction process are briefly characterized below.
Geographical location of the city—is the factor related to the specificity of the place, which includes not only the structural arrangement, the nature of open spaces (especially green), but also the kind of microclimate of the place (climate zone), e.g., by the river or sea, etc. A tool such as a geographic information system (GIS) may prove helpful here.
Density and height of buildings,—also so-called aerodynamic roughness of the terrain, has a direct impact on ventilation abilities. The wind speed in the city is on average lower by 20% at night and 30% in the day. There may also be an increase in the wind speed in the city, which is the so-called tunnel effect (air flow in accordance with the street route).
The building dimensions are directly related to the exposure of the area to the sun (sunlight/shading), as well as the rate of heating and cooling. These are often the result of local traditions and climatic requirements.
The phenomenon of so-called urban heat islands—the air above the city center is warmer than outside the city, hence as it is lighter it rises and causes local pressure reduction, causing air suction from the areas surrounding the city. The formation of this phenomenon can be compounded by a large number of people and the emission of anthropogenic heat (other conditions will be e.g., in places of large crowds of people—e.g., at a stadium during a match, which will increase the air temperature); Here, the size and spatial structure of the city also matters, because low, not very compact buildings do not create urban heat islands.
However, equally important, in this context, seem to be such factors as the share of impervious surfaces, surface albedo, overall land use or the type and density of buildings, which may contribute to exacerbation or mitigation of the urban heat island phenomena.
Building geometry—is a factor that has an impact on the degree of inhibition of natural air movement in the city. This factor most strongly affects the nature of aerodynamic phenomena in cities, but it is difficult to predict and is associated with the scope of aerodynamics, and more precisely with fluid mechanics ((C)FD—(Computational) Fluid Dynamics). It can be assumed, however, that sudden gusts of wind in the city, in turn, occur e.g., in the vicinity of medium–high, high and high-rise buildings (at walls and in the corners of buildings);
Roads and streets—due to their function and the vehicles moving on them, are one of main sources of pollution, and also depend on the type of surface of the space (the problem of possible sealing of the ground).
Specificity of tightly built-up urban interiors—is also one of main factors influencing the pollution level. Streets or squares/courtyards, especially when the distance between buildings is less than 1.5 times their height, may be a phenomenon of air stagnation or air circulation without replacement. In such spaces, there are certainly other local conditions (on a micro scale—within e.g., places with residual odors, overheating in summer at high temperatures, etc.). This is regarding the so-called Local Climate Zones (LCZ), which were selected and developed for selected cities in Canada [
28]. These local climate zones set conditions on a small scale due to typically urban features, including the share of impermeable surfaces, surface albedo, general land use, or the type and density of buildings. They are affected by factors such as the exposure of the area to the sun (sunlight/shading), as well as the rate of heating and cooling.
All the factors described above change daily. They also change throughout the day, but also depend on the season. In some seasons, the relative temperature difference between the city center and its suburbs increases due to the heating of apartments. These changes also take place in different spaces (local zones) and have a different course. Buildings in the center are sometimes higher and denser (which is characteristic of the promoted “compact city”), and its organization and shape have a direct impact on local conditions and air quality [
29].
From the point of view of urban planning, the most important thing is to create healthy and comfortable living spaces. Due to many years of spatial development and the flourishing of transport (including individual transport), they are an excellent example of a living space with a rich cultural and economic offering, and at the same time with a deteriorating quality of life caused by harmful and onerous factors. These include smog (air pollution), noise, traffic jams, and shrinking green areas. Therefore, it is extremely important to counteract the aforementioned deterioration of living conditions in cities, especially regarding air quality.
The functions often arranged in a city and the transport network necessary for operation are among the main sources of air pollution in the city. However, the aforementioned development of buildings in so-called downtown contributes to the “stopping” of these harmful substances, additionally hindering their removal (blocking the ventilation of cities).
Currently, researchers focus most often on attempts to eliminate the sources of smog in cities. The most common is the reorganization of urban transport, restricting the movement of especially passenger cars, or informing citizens about the air quality in specific zones, encouraging them to be active outdoors or stay at home, respectively [
30]. Various, most often technological solutions (e.g., Intelligent Transport System, electric/biofuel vehicles, etc.) or legal solutions (bans, restrictions, penalties, etc.) serve this purpose. Considering the above problem, it is extremely important to take action on various levels of shaping and functioning of modern cities. Some of them require a longer time to implement (e.g., increasing the biologically active surface, planting trees, etc.). Other measures can be implemented in cities almost immediately, such as a proposed pollution prediction system monitored by a network of air sensors.
To sum up, within the structure of a modern city it is difficult to find a small group of representative urban zones, in which a model prediction process could be carried out. In practice, each sensor in the city responsible for prediction should be trained based on an individual dataset, consisting of a specific vector of the input signals as well as a desired response of the ANN. Current solutions are able to provide only average responses in a specific area. Taking this into account, in the next section we present a solution in which such individual training sets are created automatically, without the need to contact the base station of the wireless sensor network (WSN).
7. Discussion
7.1. Discussion of the Proposed Learning Method
In our work, we present investigation results of one of the important steps of a larger project that aims at building autonomous sensors with the function of the prediction of air pollution levels. The sensor itself is a complex device. For this reason, to make a final design successful, a prior design of its particular components is a mandatory phase. We already designed and tested most of these blocks as prototype chips. They include, for example, a low-power, low-chip-area analog-to-digital converter (ADC). We also designed an on-board algorithm, whose role is to control the timing of the wireless transmission of collected and processed data to a base station [
31]. In our previous work, we showed that the periods between consecutive data transmission sessions may be variable and dependent on the rate of signal change at the sensor input.
One of the more important aspects is the verification of the prediction process in a real environment. At this stage of the project, it is not yet possible to present such results, since full sensors are still at the development stage. However, at this stage we can rely on prediction results obtained by other research teams that have already explored predictions of air pollution using various ANNs, based on real-world data. In our work, we refer to these works, treating them as a starting point for the development of the proposed concepts.
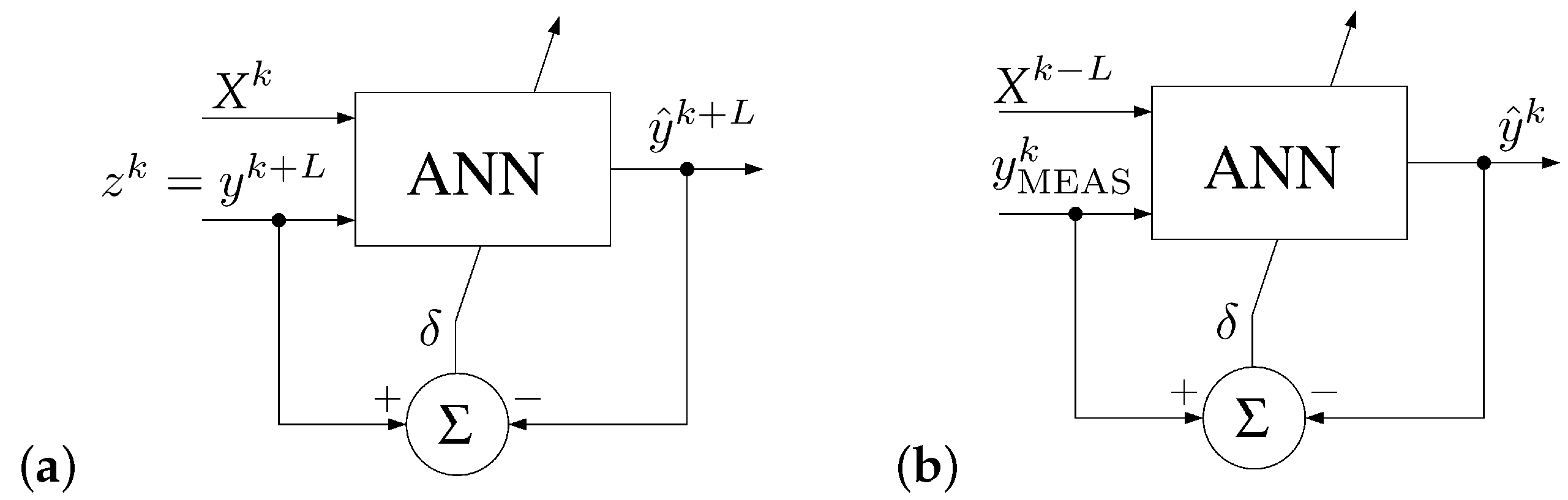
A general training scheme of the ANN is in the proposed case similar to that already reported in the literature. The key aspect of our concept, however, is the introduction of a time delay during the learning phase. Thanks to this, we do not have to create the training dataset in advance. In the conventional approach, it is necessary to prepare such training sets before starting the learning process. Such sets are composed of two groups of data. One of them is input factors that include, for example, quantities describing weather conditions as well as current pollutant levels. The second group provided to the inputs of the ANN is expected (predicted) values of pollution levels after a given time horizon. In other words, based on the input data collected at
, where
is the present moment of time, the ANN is going to find out what levels of pollution are expected in the future, at
, where
is an equivalent of variable
L in
Figure 2. The
is the time horizon for the prediction process.
In the case of the concept proposed by us, the moment of collecting the input data and the moment for which we determine the expected values are also separated by the time interval . As a result, the learning process itself is similar to the conventional approach. However, we have introduced a modification in which the network is trained based on data collected in the past, at the moment . These data are sampled and stored for given time intervals equal to a sampling period in the memory of the sensor device. At the inputs of the ANN, we also provide the expected value, but in this case this value is also measured by the sensor itself, at the time . To summarize:
In the conventional approach, one can show that .
In the proposed approach .
Thus, as can be seen in both cases, , which means that the learning process will be similar (only shifted in time), and therefore, at this stage of the project, in our opinion it is sufficient to rely on the results of tests carried out in a conventional manner by other teams.
Thanks to the introduced delay, the sensor itself can measure both the input values and the expected value, which is the key advantage here. This strongly simplifies the training process of all wireless sensors mounted in a given area of the city. Each sensor itself creates its own training set along with the expected values. In this way, the resultant training sets are fitted to conditions prevailing in particular points of the city. Additionally, during the training phase of the ANN, there is no need to provide an external training set to particular sensors via the base station. In this sense, the sensors may work as autonomous units. Since the communication with the base station may be limited in this phase, the consumed energy may also be reduced.
7.2. Results at the Model Level
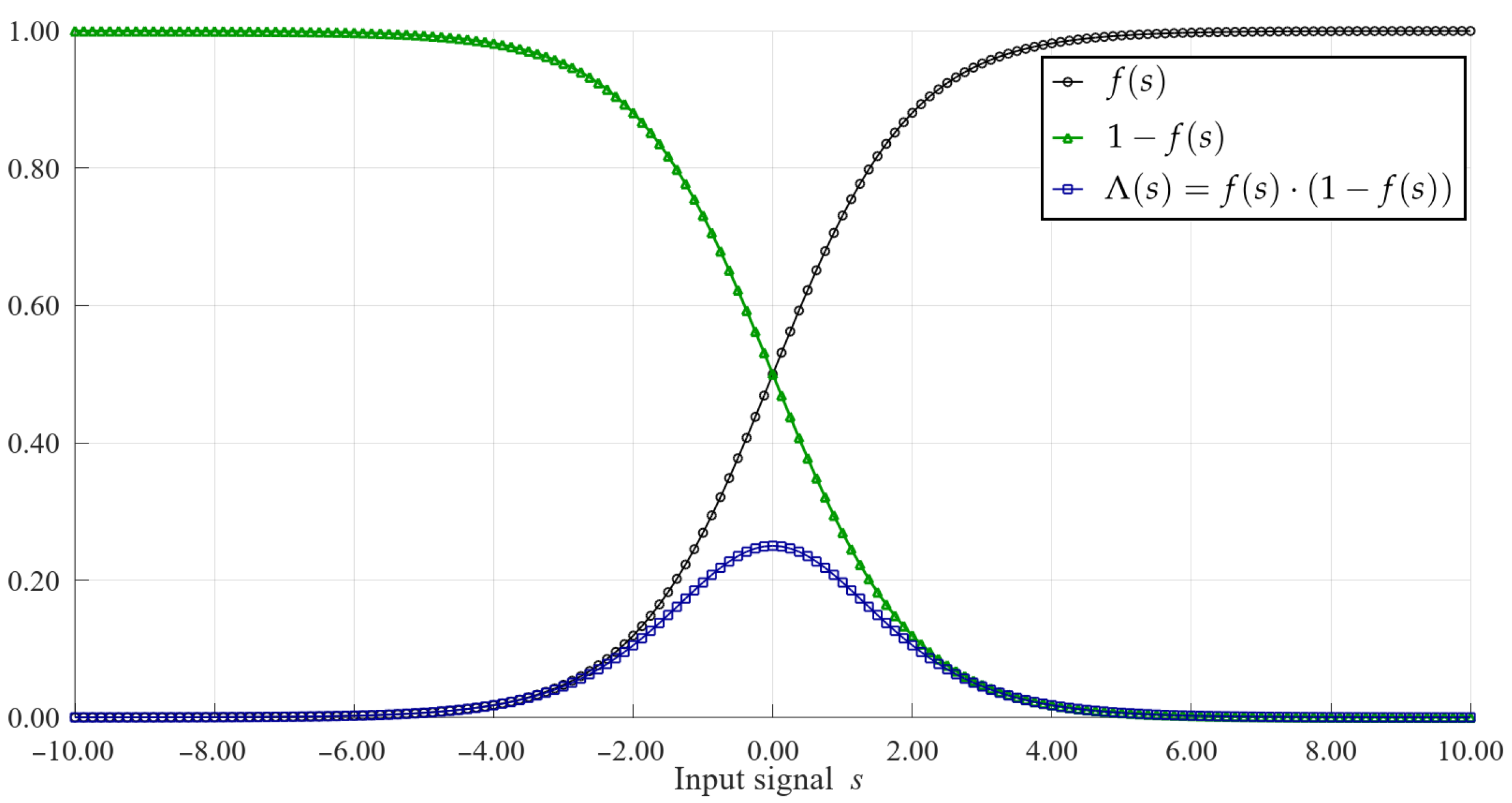
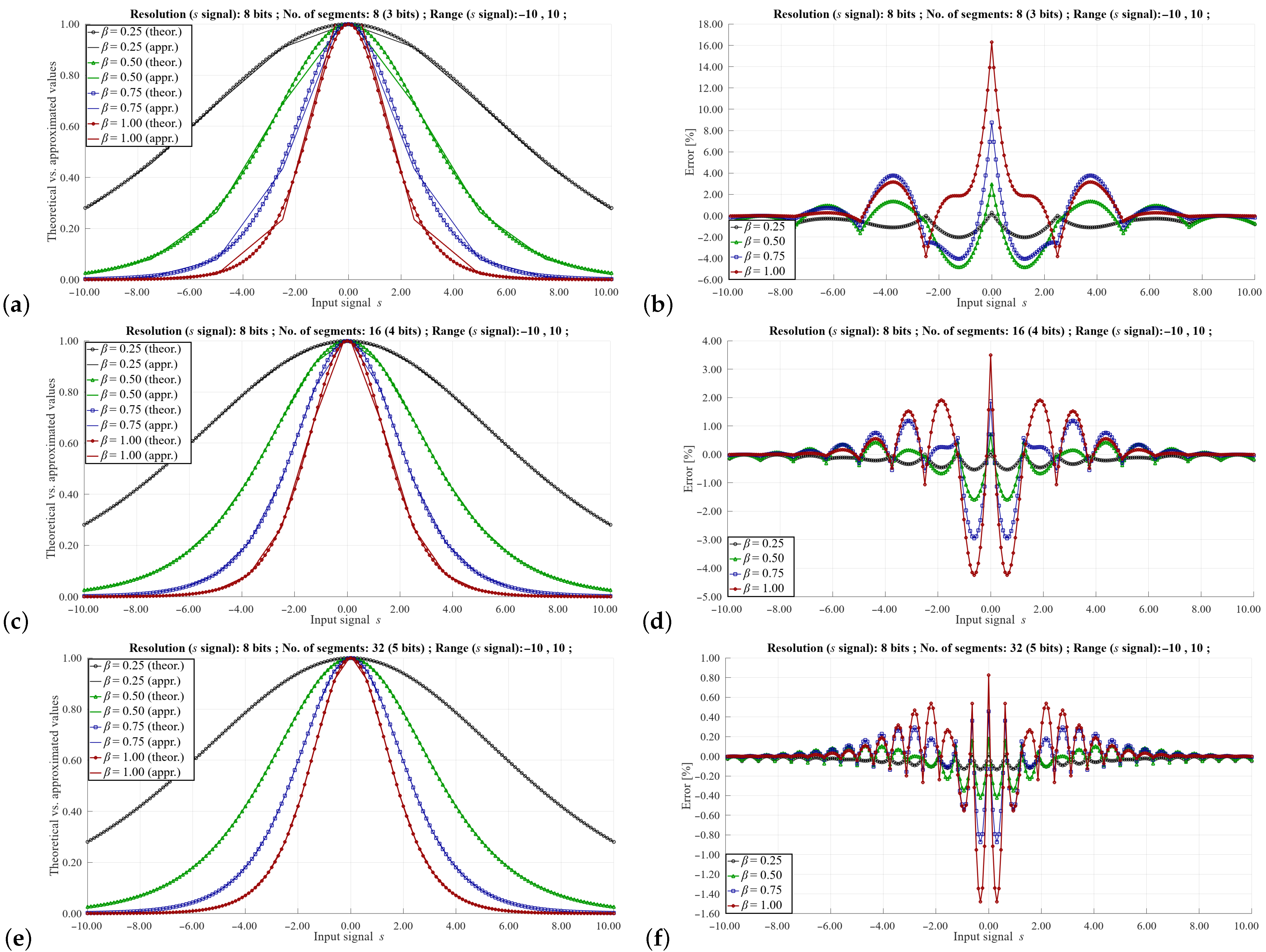
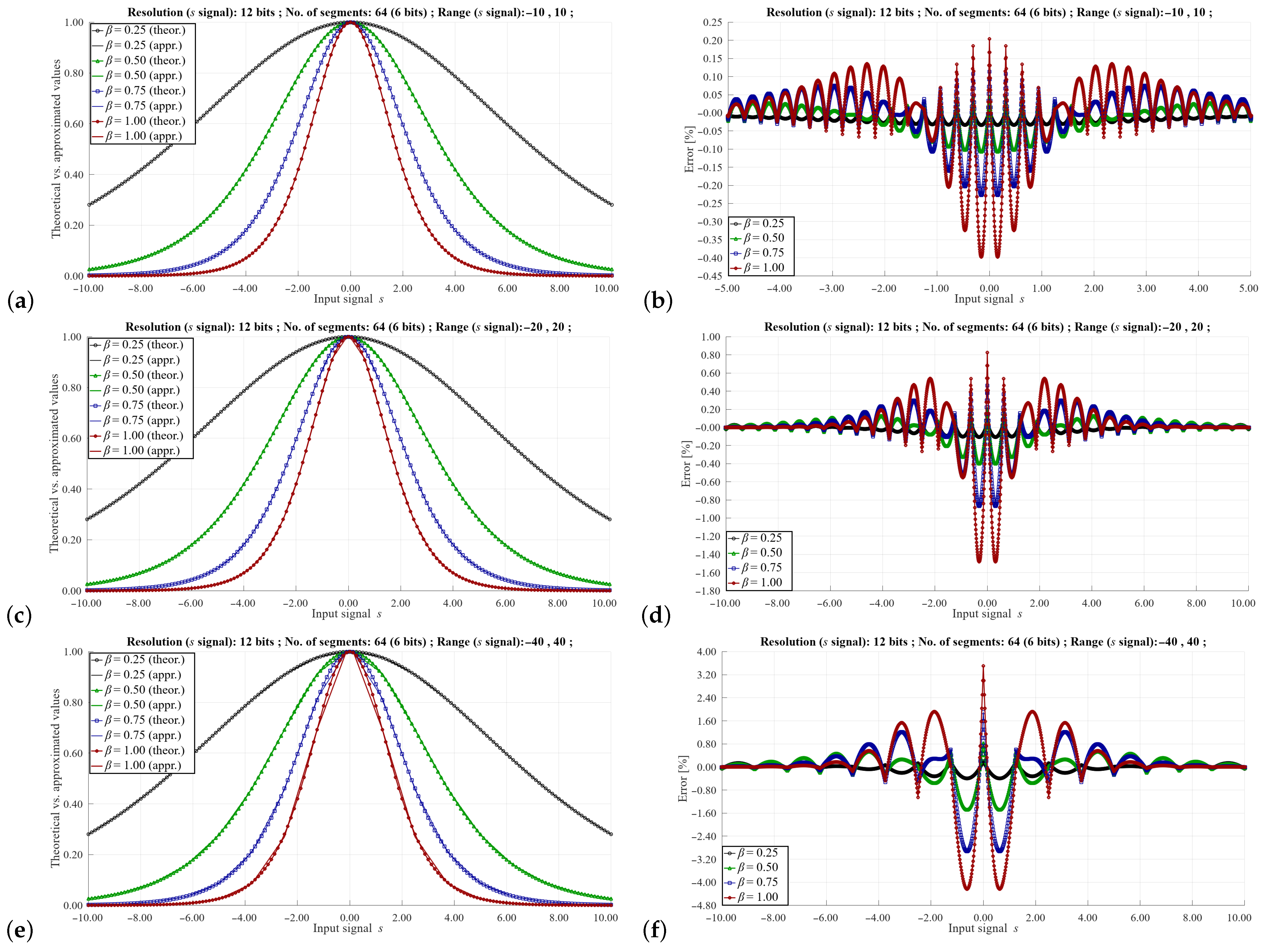
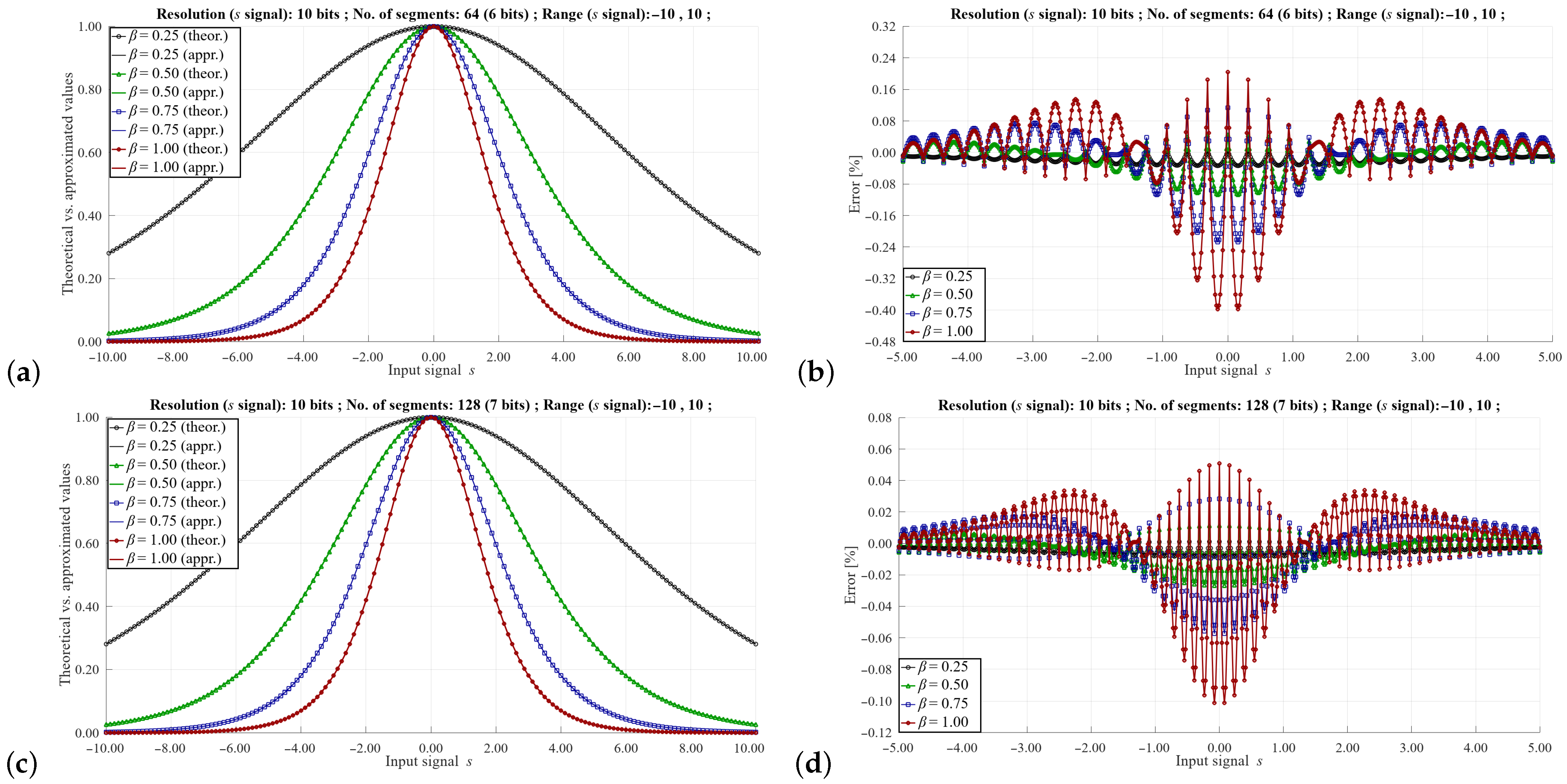
Figure 6,
Figure 7 and
Figure 8 show the approximation results for selected parameters described in the previous section. These parameters include the signal resolution
s, the range of this signal and the values of the masks
and
. As can be seen, the maximum value of the approximation error can vary to a large extent depending on these parameters. As would be expected, the highest error values occur with a small number of segments and a relatively large signal range of the
s signal. In such cases, the error can reach even a dozen %. However, such signal resolution values are not used in a real implementation of the training algorithm, as this would distort the learning process of the neural network. In practice, higher signal resolutions are used. For a larger number of segments and higher signal resolutions
s, it is possible to obtain a maximum error of 0.5–0.1%, which is sufficient to correctly reproduce the learning process of the ANN.
One of the advantages of the proposed solution is the ease of controlling the basic parameters of approximation using the values of masks
and
, as well as appropriately selected values of the slopes and the offsets stored in the LUT. Since the slope and offset values are fixed-point numbers, it is not possible to directly compare the approximation results with the theoretical values. For example, in the case shown in the
Figure 7, the value of the largest slope equals 255 (8 bits). Thus, to enable a direct comparison with the theoretical waveform, we have normalized the approximated waveforms to fit it to the theoretical case. In a real implementation, the normalization may be performed by a division operation, by a factor being one of the powers of 2, so a simple bit-shifting operation may be applied for this purpose.
Observation of the results shown in
Figure 7 lead to the conclusion that the range of the signal
s must be selected very carefully. If a larger signal resolution is required, one can apply a solution, in which the sizes of particular segments are not equal, being matched to the variability of the slope of the
function. In this case, to properly index the LUT, variable mask values are needed depending on the value of the signal
s.
Comparing the results shown in
Figure 7a,b and
Figure 8a,b, it can be seen that with a given value of the range of the signal
s and the same number of segments, the approximation errors are similar. This fact simplifies the programming of the LUT depending on the resolution of the
s signal. In this case, the values of the slopes and the offsets are the same.
7.3. Results at the Hardware Level
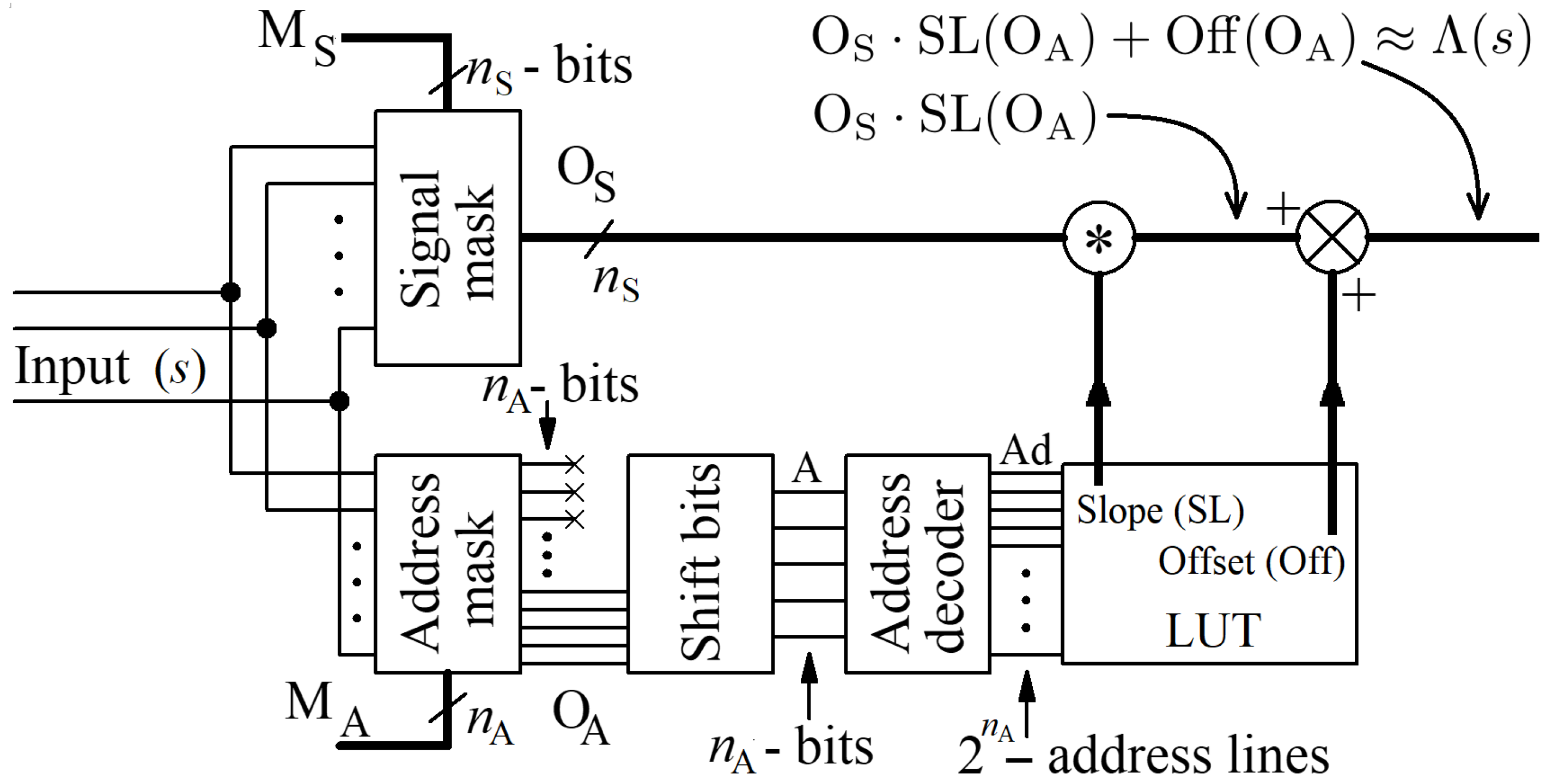
Figure 9 presents selected results at the transistor-level simulation of the proposed approximation circuit, shown in
Figure 4. The input value (6811) has been selected so that the proposed circuit operates near the worst conditions. In this case, both the slope and the offset have values close to maximum levels stored in the LUT. This makes the delay time shown also close to the worst-case scenario.
The circuit shown in
Figure 4 operates fully asynchronously. The asynchronous work is here understood in such a way that there is no need for an additional clock that sequences the computations at particular stages. After feeding the circuit with a new input signal sample, the result is ready after the time resulting only from delays introduced by particular digital elements and larger combination components. Thanks to this, several key features were achieved. They include simple structure, large data rate and low energy consumption per single signal sample.
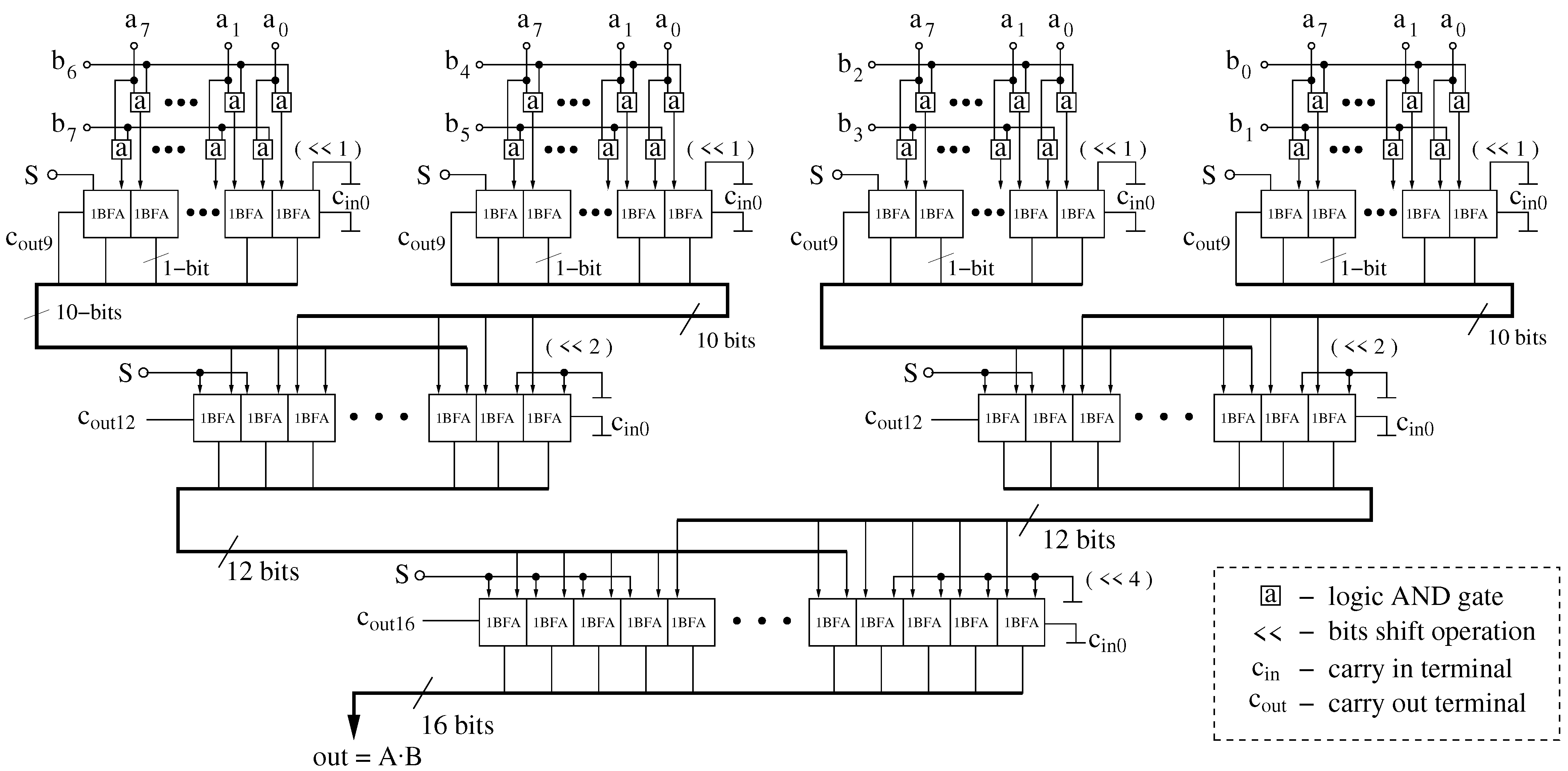
In the proposed circuit, in the first step, the input signal is divided into two components using the address and the signal masks (complementary to each other). The masks are built as a single layer of AND logic gates working in parallel. Thus, the masks introduce a delay not exceeding 0.1 ns in the CMOS 130 nm technology.
The multiplier block is built based on a binary tree consisting of asynchronous multi-bit full adders (MBFA). The delay introduced by this circuit depends, to a relatively small extent, on the resolution of the multiplied signals. When multiplying two 8-bit numbers, the tree consists of three asynchronous layers. If we increase the resolution to 16 bits then the number of layers only increases by one. As a result, the delay introduced by this block increases moderately with the resolution of the processed signals.
At the last stage of the signal processing chain, an additional summing circuit is used, whose structure depends on the resolution of the signals at the input of the multiplier. For the resolution of 8 and 16 bits, 17 and 33-bit MBFAs are used, respectively. One can also use a bit-shift block, to cut-off a given number of least significant bits (LSB), to normalize the signal at the output of the overall circuit.
The assessment of the circuit performance has been performed for the process, voltage and temperature (PVT) parameters, varying in a wide range. The temperature varied from −40 to 120
C. Supply voltage varied from 0.7 to 1.2 V. Additionally, the circuit was tested for slow, fast and typical transistor models. This method of verification, called the corner analysis, is a standard procedure, important in the case of commercial applications of the chip. The results shown in
Figure 9 are for the slow transistor models. Assuming a safety margin (e.g.,
), in the worst-case scenario, the maximum delay does not exceed 40 ns. As a result, the proposed approximation circuit of the
function can operate at a data rate of 25 M Samples/s (mega samples per second) for an example case of 14-bit input signals. For smaller signal resolutions, as well as in newer technologies, the data rate will substantially increase.
The complexity of the circuit shown in
Figure 4 strongly depends on the resolution of the numbers being multiplied. The total number of transistors in the circuit does not exceed 5000 or 12,000, for
and
-type multipliers, respectively. In the first case the multiplier consists of about 2300 transistors, while in the second case of about 9000 transistors. These numbers do not include the memory block, in which the LUT is stored. However, it is worth noting that the LUT is common for all
function estimation circuits working in parallel. As a result, its complexity is insignificant in the case of larger ANNs.
The selected value of 6811, for the results shown in
Figure 9, corresponds to a theoretical value of the
s signal of −1.6858, for the range of (−10, 10), while the obtained output signal to a theoretical value of 0.5251, after its normalization to 1.
7.4. Results for the Overall ANN
Taking into account the presented results for a single approximation function, it is possible to estimate the performance of the overall neural network. The analysis of the state-of-the-art works provided in
Table 2 shows that the number of neurons in the ANN used for prediction does not exceed 20 at all layers of the network. For example, in the most complex ANN reported in [
24], the number of neurons equals 15. The ANN in this case contains only one hidden layer.
Each neuron in the BP ANN contains only a single activation block, i.e., only one approximation function block proposed in this paper. Considering that all neurons operate in parallel, the estimated time to process a single training pattern does not exceed 200–300 ns, depending on the ANN configuration. These values contain times required to perform all arithmetic operations, including the multiplications shown in formulas above. This means that the neural network implemented in the CMOS 130 nm technology can operate at data rates of up to 3–5 M Samples/s. For the described application in the air pollution monitoring system, such data rates are not required. In this case, however, energy consumption is a more important parameter. Based on the obtained results, presented above, it can be assessed that an overall ANN consumes no more than 4–10 nJ of energy for a single iteration of the learning process.
8. Conclusions
The paper presents two aspects important from the point of view of implementing an efficient pollution monitoring system, with a function of predicting future pollutant levels.
One of them is the concept of a wireless sensor network, in which each of the air pollution sensors performs its own prediction of pollution levels based on locally measured environmental signals, independently of other sensors in the network. Thanks to this, particular sensors can adapt themselves to specific local conditions (a microclimate) in a given location of the city. This is one of the main advantages of the presented work. To the best of our knowledge, this proposed approach was not presented in other state-of-the-art works encountered in this area.
The second important aspect is the way of implementing the ANN used to predict pollution levels, as well as the way of obtaining data for the training process of the ANN. This applies especially to the reference signal, which in this case is also measured by the sensor itself. Thanks to this, it is not necessary to create the training set for each sensor separately and in advance. In the proposed solution, it is created automatically, and the ANN can be re-trained at any time when the conditions change. For example, a new tall building was built in the neighborhood that changed the wind parameters in the location in which the sensor has been mounted. In this case, the learning process can be restarted, so that the sensor autonomously adapts its parameters to the new ambient conditions.
The main components of the ANN that can be used in the described prediction procedure were implemented as parallel and asynchronous circuits in a prototype chip fabricated in the CMOS 130 nm technology.
We paid special attention to the simplicity of implementation of the learning algorithm. Through appropriate approximations, it was possible to use only simple arithmetic operations such as multiplication, addition and subtraction. This significantly simplifies the implementation of such a network in a low-power integrated circuit.
The presented investigation results are part of a larger project aimed at designing and implementing a new class of sensors for monitoring air pollution levels, along with the possibility of their prediction on a specific time horizon. Selected ideas and results in this area have been presented in our earlier work [
31]. In that paper, we focused on the development of a simple algorithm that enables monitoring current air conditions. We put special attention on hardware simplicity of the proposed solutions and reduction of energy consumption. In the present paper, however, we focus on the prediction abilities of future pollution levels. In future works under the framework of the above mentioned project, it is planned to calibrate the values of key parameters of the sensors based on data collected in real conditions.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}