1. Introduction
With the continuous development of the economy and society, buildings have become important carriers supporting human activities. More people are living in city areas as urbanization progresses [
1]. As the basic structural unit of construction and human activities, buildings are the key elements that support citizens’ living, working, recreation, and other social activities. The diversity of building function type (BFT) is a significant indicator of the evolution of urban civilization, and its rational planning is crucial for human well-being. In recent years, BFT has attracted widespread academic attention in multiple fields, such as urban planning, disaster assessment, and environmental monitoring [
2,
3]. However, the acquisition of BFT traditionally requires researchers to investigate a site in person or distribute lengthy questionnaire reports, which are expensive, time-consuming, slow to update, and difficult to implement in large areas. Therefore, some methods that are low cost, easier to use, and can be applied to large areas are crucial for BFT acquisition.
In recent years, studies of BFT identification have mostly used remote sensing or social sensing data [
4]. Remote sensing data are mainly acquired from space-borne/airborne/ground-based (street view) remote sensors, while social sensing data are commonly obtained from people’s or vehicles’ portable sensors, such as smartphones or smart wearables. These two types of data collect information on city or village areas from different perspectives through remote sensors or human sensors and generate BFT products from physical or human points of view, respectively, according to different application purposes. The methods that solely use one type or a combination of data are widely used for BFT identification with promising results [
4,
5,
6]. However, few studies have directly linked BFT identification with mobile signaling (MS) data to produce BFT products driven by population dynamics. In this study, we aim to explore the potential of MS data to construct the relationship between population dynamics at diurnal and daily scales and BFT. In addition, as few studies have used MS data alone to identify large-scale BFTs, in this study, remote sensing data from Sentinel-2 (S2) are used for comparison to prove the feasibility and advancement of the proposed MS-based method.
In addition to the data being used, the identification method is another important component of BFT classification research. With the rapid development of artificial intelligence and computer technology, machine learning methods have been used in a wide range of applications, such as urban function classification [
7], disaster detection [
8,
9], and risk assessment [
10]. As the demand for data analytics continues to grow in the big data era, how to carry out deep analyses of complex and diverse data based on machine learning and use information more efficiently has become the main direction of machine learning research in the current big data environment. In terms of mathematical functions, the classification task is to obtain an objective function (
f) by learning to map each attribute set (
x) to a predefined class label (
y), that is, we obtain a classification model (i.e., obtain a function between sample attributes and class labels) based on some known samples (including attributes and class labels), and then classify the sample data containing only attributes by this objective function. This is the most commonly used classification scenario for machine learning and the basic principle for BFT classification in this study, i.e., constructing a function between the time-series attributes of the population and the BFT based on some known samples to identify the BFT.
In this framework, the proposed approach introduces OpenStreetMap (OSM) data, and the street view of Gaode Map as the real BFT reference data to build a random forest (RF) classification model based on the proposed population dynamics-oriented BFT classification framework. This work focuses on the classification of buildings according to the given BFT classification scheme. Through an accurate evaluation and comparison with remote sensing data methods, we demonstrate that MS data can be used to identify different functional types of urban buildings with reasonable accuracy. To this end, the potential of MS data to reflect population dynamics is discussed, and qualitative and quantitative evaluations are performed for several MS indicators to select the optimal metrics for the BFT classification model. Then, the classification results and their applications are described in detail.
The innovative contributions of this study are mainly in two areas. First, based on the time-series information, this is the first attempt to use a special type of social sensing MS data in urban BFT identification. As compared with other types of social sensing data, MS data have the advantages of full spatial coverage and a high penetration rate, which provide an effective database for large-scale BFT mapping. The high penetration rate of mobile devices results in MS data that reflect human dynamics at a high temporal resolution. The high temporal resolution time-series information used for BFT identification is the key point as compared with other social sensing-based methods. As compared with traditional widely used satellite remote sensing data, MS data have the advantages of being intrinsically more useful for BFT identification, as population spatial and temporal dynamic variations reviewed by MS data are more correlated with BFT than geometric or spectral features in remote sensing images. Second, the building function classification scheme proposed in this study is driven by population dynamics at diurnal and daily scales. Considering that the MS data are directly correlated with population spatial and temporal dynamics, which are mostly determined by BFTs, the building function classification scheme is proposed, and BFT is estimated based on population dynamics shown as time-series MS data on two days (workday and weekend). Committed to referencing and improving the original classification scheme, we have created a building function classification product based on population dynamics variation patterns. In the era of exploding population growth, this BFT product is of great importance in urban planning, management, and emergency response.
This paper is structured as follows: In
Section 2, we review previous work related to the addressed topics; in
Section 3, we describe the study area and data used in this study are provided; the data preprocessing and RF model construction are described in
Section 4; the results are presented in
Section 5; in
Section 6, we discuss the results; and in
Section 7, we provide the conclusions of this study.
2. Previous Work
This study aims to develop a new approach to identify BFT in terms of population dynamics, which has significant implications for urban planning and management. In this section, we review the latest techniques related to the identification of the urban functions, focusing on the data and methods developed for urban BFT identification, and discuss in detail the significance of MS data for the indication of population dynamics and investigate the mechanisms of its role in BFT mapping over a large scale and its potential applications. In addition, the application of machine learning is briefly discussed in relation to the research objectives of this paper.
The urban system is composed of different forms of functional areas, which Jane et al. has described as “organized complexity” [
11]. Rodrigue et al. argued that there were two ways of defining urban land use: One definition focused on the forms and patterns of land use and was called formal land use; the other definition was based on a spatial socioeconomic description and was called functional land use [
12,
13]. The latter definition had a stronger population dependency and a higher level of dynamic variation than the former definition. Due to its high relevance to population dynamics, researchers have become increasingly interested in urban functional identification.
Currently, the two mainstream ways of identifying urban functional types are remote sensing and social sensing-based methods. Remote sensing-based methods typically use features extracted from remote sensing images, such as geometric, spectral, and texture features, to estimate urban functions [
14,
15]. Since the 1960s, remote sensing-based methods have been considered to be efficient for the identification of various terrestrial features. Improvements in sensors’ spatial, radiometric, and spectral properties have led to an era of high-quality optical images [
16,
17]. High-resolution remote sensing imagery provides rich and detailed image information that greatly facilitates large-scale environmental monitoring [
18]. The prolonged study history and abundant archive data provide considerable convenience for land use/cover classification [
19,
20,
21] and damage assessment and evaluation applications [
22]. With the continuous development of industrialization and urbanization, most human activities have become concentrated in buildings. Thus, in recent years, more studies have turned their attention to BFT identification based on remote sensing images. Belgiu et al. extracted building types from airborne laser scanner data by implementing object-based image analysis method [
23]. Xie et al. successfully classified three BFTs from high spatial resolution images using extended multiresolution segmentation and soft classification based on backpropagation networks [
5]. Hoffmann et al. used aerial and street view images to classify urban BFTs into four categories, with an overall accuracy (OA) of 76% [
17].
However, since large area satellite remote sensing is generally a vertical observation, only information on the roofs of buildings can be obtained. Note that most buildings are constructed from limited types of materials and shapes, and buildings with abundant functional types can be confused in spectral or geometric domains. Thus, remote sensing images often have difficulty reflecting detailed information about BFT due to the limitations of the remote sensing imaging mechanism [
24]. Therefore, remote sensing-based methods are usually used for urban functional area identification rather than building function identification [
4].
With the enrichment of data resources and progress in processing techniques, social sensing-based methods have become another important branch for BFT identification. Different from remote sensing-based methods, current social sensing-based methods commonly use population dynamics to infer BFT. Social sensing data include taxi trajectories, points of interest (POI)s, social media data, data from WeChat and Weibo, and call detail records. These new datasets contain rich information on urban human activities and interactions [
25,
26]. Currently, there is growing literature using social sensing data for urban building functional mapping. Zhong et al. established a two-step framework making use of the spatial relationships between trips, stops, and buildings to infer building functions [
13]. Niu et al. integrated multisource big data (WeChat, taxi trajectories, POIs, and building footprint data) to infer building functions in Guangzhou, China [
2]. Zhang et al. proposed a data-driven approach that used station-based public bicycle rental records together with POI data in Hangzhou, China, to identify urban functional zones [
27]. However, the data used in those studies have some obvious limitations: heterogeneous spatial sampling and relatively low sampling rates. For example, taxi trajectory, public transportation, and bike-sharing data are denser and more effective in large cities, but there are few data available in suburbs or villages. POI data are distributed mainly in densely populated areas and are more inclined to shopping, retail or central business districts, while residential areas are rare. Although WeChat, Twitter, and Weibo data have enormous numbers of users, the spatial and temporal resolutions are too coarse for BFT identification by analyzing the diurnal variations in population dynamics.
Considering these issues, in many studies, attempts have been made to infer building functions using multiple sources of big data. An increasing number of studies have combined remote sensing images with social sensing data for BFT identification, such as POI data [
28], Twitter text messages [
29], and geospatial data [
30]. The combined use of multisource data has indeed enhanced the understanding and identification of urban functions. Gong et al. reported a nationwide land use map using data fusion of 10-meter satellite images, OSM data, nighttime lights, POIs, and Tencent data, and this result marked the beginning of a new approach to collaborative urban land use mapping over large areas [
31]. However, for BFT identification, the fusion of multiple data would undoubtedly increase the workload and greatly increase the cost of mapping, and there are always limitations in large-scale applications. In addition, while multiple sources of data offer unprecedented opportunities for urban research, they also come with the problem that multiple sources of data may not fit well with each other [
32]. For example, a park building in the center of a city may have sparse POIs but high-density taxi trajectories or geotagged social media content. This situation may cause misclassification of the BFT. The semantic bias of multiple data makes it difficult to unify the judgement criteria, and a combination of techniques is undoubtedly needed to solve this problem.
To address these limitations, emerging social sensing data, i.e., MS data, have attracted considerable attention from geoscience scholars. MS refers to the protocol control signals sent between a device and the network, which are used in mobile communication systems to transmit user information and ensure proper communication. These signals include data such as the numbers of active communication stations (Station), online mobile devices (Gid), active Wi-Fi hotspots (Wifimac), and connected devices in wireless networks (Loginmac) [
33]. As of 2020, the penetration rate of mobile devices in China reached 112.91 per 100 people. The advantages of wide coverage, near real-time observation, and relatively high sample rate make it possible to use MS data for human activity-related studies. González et al. studied data from nearly 100,000 anonymous mobile device users and revealed persistent patterns in the statistical properties of human mobility [
34]. Similarly, Song et al. highlighted the remarkable predictability of human activities, and argued that it was possible to predict a user’s dynamics with 93% accuracy using mobile phone data alone [
35]. As compared with other social sensing data datasets, MS data offer several advantages in urban functional identification: (1) high penetration rate, (2) broad spatial coverage, and (3) rich information on human activities (high temporal resolution). Currently, these data have been applied to many areas, such as land use/land cover identification [
7], service radius assessment of public facilities [
36], and earthquake emergency response and rescue [
37,
38]. To date, few studies have tried to use MS data for urban BFT identification, even considering the significant correlations of MS data with variations in population dynamics.
Notably, previous social sensing data-based methods have focused on applying population spatial dynamics for BFT identification, and temporal information has not been well used. Montgomery et al. noted that the urban area should be an open space that harbors high-density human daily activities [
39,
40]. Rodrigue et al. defined these daily activities as routine activities performed during a 24-h day [
12], and previous studies have shown that individuals usually had stable mobility patterns [
41,
42,
43,
44]. These studies have demonstrated the potential of using population temporal dynamics to infer different BFTs. Thus, in this paper, we aim to study the possibility of using time-series MS data for BFT identification.
Given the reliable performance of machine learning methods on classification problems, some BFT classification methods have been proposed based on artificial neural networks [
45], convolutional neural networks [
46], as well as random forest [
7] and support vector machine [
47,
48] algorithms. The ability of machine learning methods to automatically learn high-level features from large amounts of data provides an effective reference for the classification of urban buildings. The RF classification algorithm is a decision tree-based machine learning algorithm [
49]. Numerous theoretical and empirical studies have demonstrated that the RF algorithm has high prediction accuracy and good tolerance for outliers and noise and is not prone to overfitting [
50]. The algorithm has been widely used in various fields for its excellent classification performance. Thus, in this study, we attempt to apply MS data based on the RF algorithm for BFT identification.
Considering these issues, we attempt to use time-series MS data to infer BFT, and therefore, propose a new BFT classification method based on information about urban functions reflected by patterns of population dynamics, with the technical support of RF machine learning methods. We believe that the classification product generated by our research is an innovative product at the population dynamics level and has important implications for urban planning and emergency management.
6. Discussion
Buildings are the most basic units of urban planning and generally correspond to different patterns of population dynamics. Correct BFT identification is ver significant for all urban applications with humans as the most important part. MS data, as emerging social sensing data acquired directly by human sensors, can help to identify detailed building functions on a large scale due to its wide spatial coverage and high temporal resolution.
This study shows the potential of using MS data to study diurnal variations in population dynamics for BFT identification with a spatial resolution of 150 m. As people are required to actively send messages to be recorded, POIs, taxi trajectories, social chat user density, and Twitter text messages commonly have low sample rates. For example, Twitter text messages require people to post a Twitter feed to be recorded. In contrast, MS has a higher sampling rate, as MS records can be recorded as long as mobile devices are being used. Thus, the MS data can reasonably represent human activities with wide spatial coverage and high temporal resolution. However, for diverse MS indicators, such as Station, Gid, Wifimac, and Loginmac, few references are available to understand which indicator can be effectively applied to BFT prediction. Most studies have described such data in general terms, such as phone location signal data [
66] or mobile phone records [
37], without specifying the specific indicators used. Pang et al. first compared the changes in these four indicators before and after earthquakes, and the results showed that Wifimac and Loginmac had better performance in the rapid determination of earthquake impact fields [
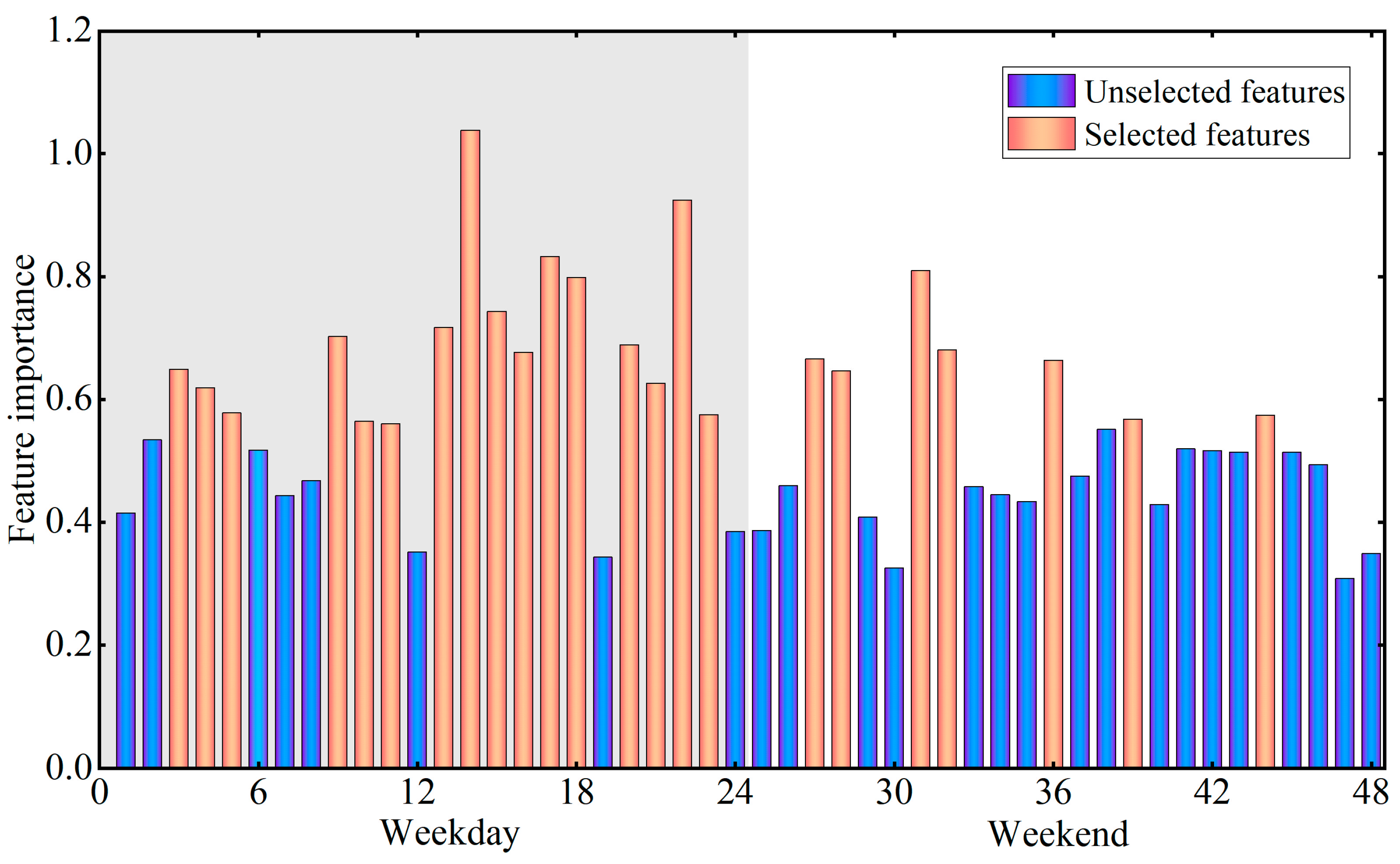
33], which was indicative of earthquake emergency response and rescue. However, few studies have compared the performance of these indicators for BFT classification. This study proposed a combined qualitative and quantitative approach to compare the performances of the indicators in different dimensions. The results show that the best performing indicator for BFT classification is Gid, which may be closely related to its flexibility, portability, and wide distribution.
Additionally, based on the existing building classification, this study proposed a BFT classification scheme of five classes driven by different population dynamics. This classification scheme is useful for human activity-driven urban management or natural/anthropogenic disaster emergency responses. Although previous studies have considered the ability of call detail records to reflect the variations in population dynamics [
7], they did not consider this new pattern of change-driven functional classification and still followed the traditional classification scheme, resulting in low classification accuracy.
In addition, unlike other studies that have commonly applied population size variations as metrics, this study argues that the absolute population size is always influenced by multiple factors in addition to BFT (such as epidemic control or regional development level) and is not stable, making it less general for large-scale BFT mapping. Therefore, this study normalized the MS data when exploring the potential of MS to identify BFT. The purpose of this step was to explore the BFT information reflected by its population dynamics variation patterns on each study unit basis. This identification model, which relies on population dynamics variation patterns within buildings rather than population size variations, is more stable and can be more readily generalized to large-scale BFT mapping applications.
In this study, traditional remote sensing methods were used for a comparison to verify the feasibility of MS data for BFT classification. As seen in
Figure 15, the overall classification accuracy of MS data is higher in this classification framework. In addition, in the functional classification of actual urban buildings, the differentiation of special categories, such as
E and
H, is difficult for remote sensing data, while MS data, with its sensitive detection capability, can be used for BFT identification in the case of extremely uneven urban distributions. This is attributed to the detection mechanism of remote sensing and social sensing data. Remote sensing detection mainly perceives the physical environment based on remote sensing signals obtained from different remote sensing sensors, while social sensing detection directly perceives the socioeconomic environment based on the dynamic behavioral patterns of a population obtained from human sensors. Therefore, as compared with the S2 data-based method, the MS data-based method is more suitable for the BFT classification framework oriented to population dynamics in this study.
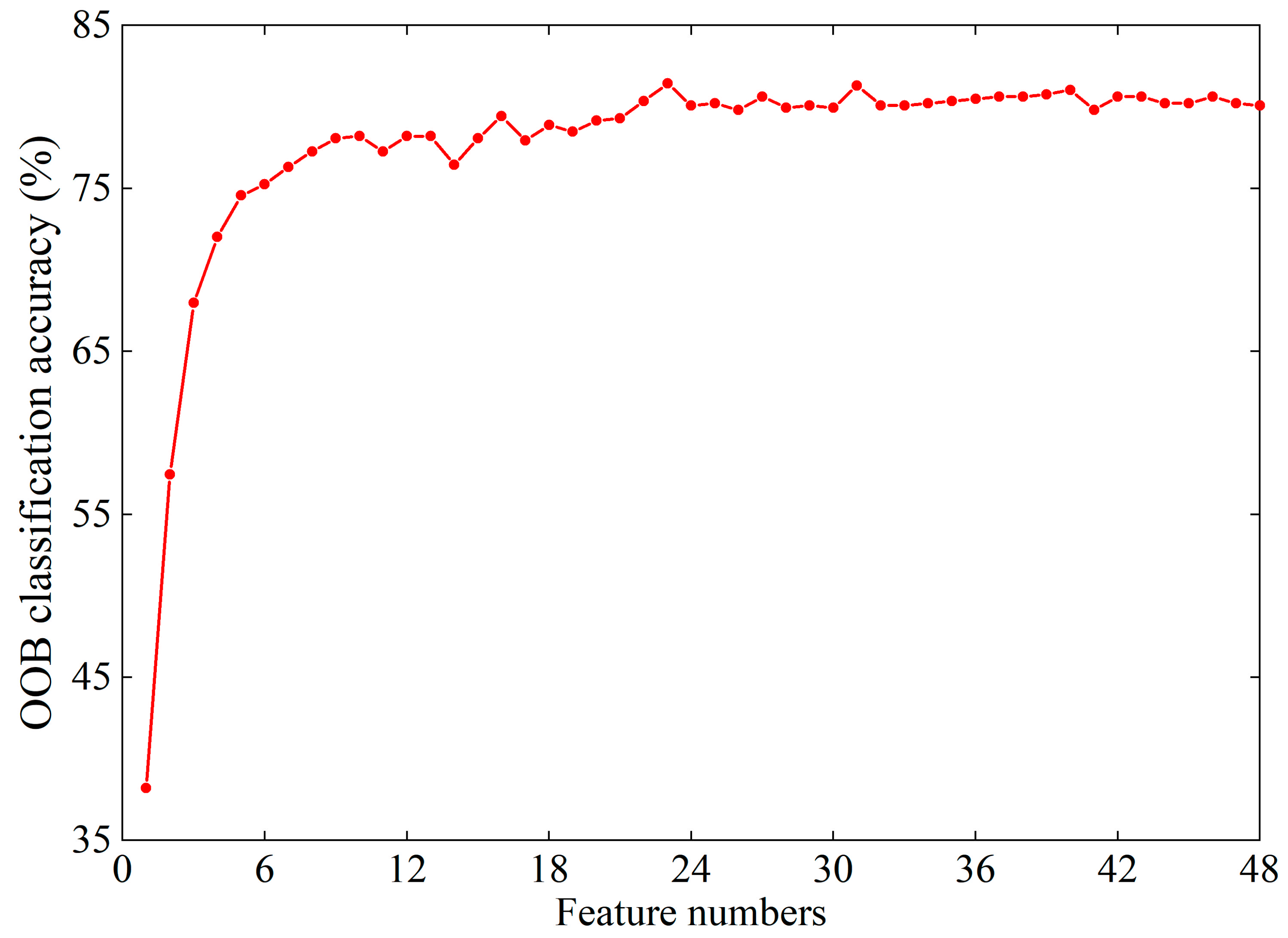
There are also some limitations that will be addressed in future work. First, although the resolution of Geohash7 data at 150 m meets the requirement of functional agglomeration of most buildings and ensures the richness of information within the grid, there are still mixed grids due to the complex distribution of urban buildings that leads to some buildings being misclassified as the dominant BFT within the grid. A spatial resolution of 150 m makes it impossible to differentiate the buildings of different BFTs with dimensions of tens of meters. There are cases where a building is segmented into several nearby Geohash grids. In further studies, we plan to use more refined data to estimate BFT. Second, although the overall classification accuracy of the model is as high as 85%, the classification accuracies of buildings in BFT’s E and H are low. This is mainly due to the small proportion of these two BFTs in the building function layout. Namely, there are indeed more R-type buildings than E- or H-type buildings in actual urban or village areas. Although some E- and H-type buildings (with classification accuracies of 65% and 50%, respectively) can be identified from the extremely heterogeneous urban layout based on the circadian rhythm variation in MS activity, a more sensitive classification method deserves further exploration.
In the future, we plan to apply this method to more cities and to integrate other data sources to use multidisciplinary knowledge to infer BFT more accurately. The practical application of inferred BFTs for earthquake emergency response is one of our next key research directions.
7. Conclusions
Along with the continuous development of urbanization, buildings have become the basic unit to support human activities. The BFT is a key parameter that determines the population distribution at both spatial and temporal scales, as well as green space planning, shelter construction, etc. In recent years, remote sensing- and social sensing-based methods have been proposed for BFT identification at different spatial scales of regions, blocks, or buildings. This study investigated the potential of using MS data for BFT identification with an RF model.
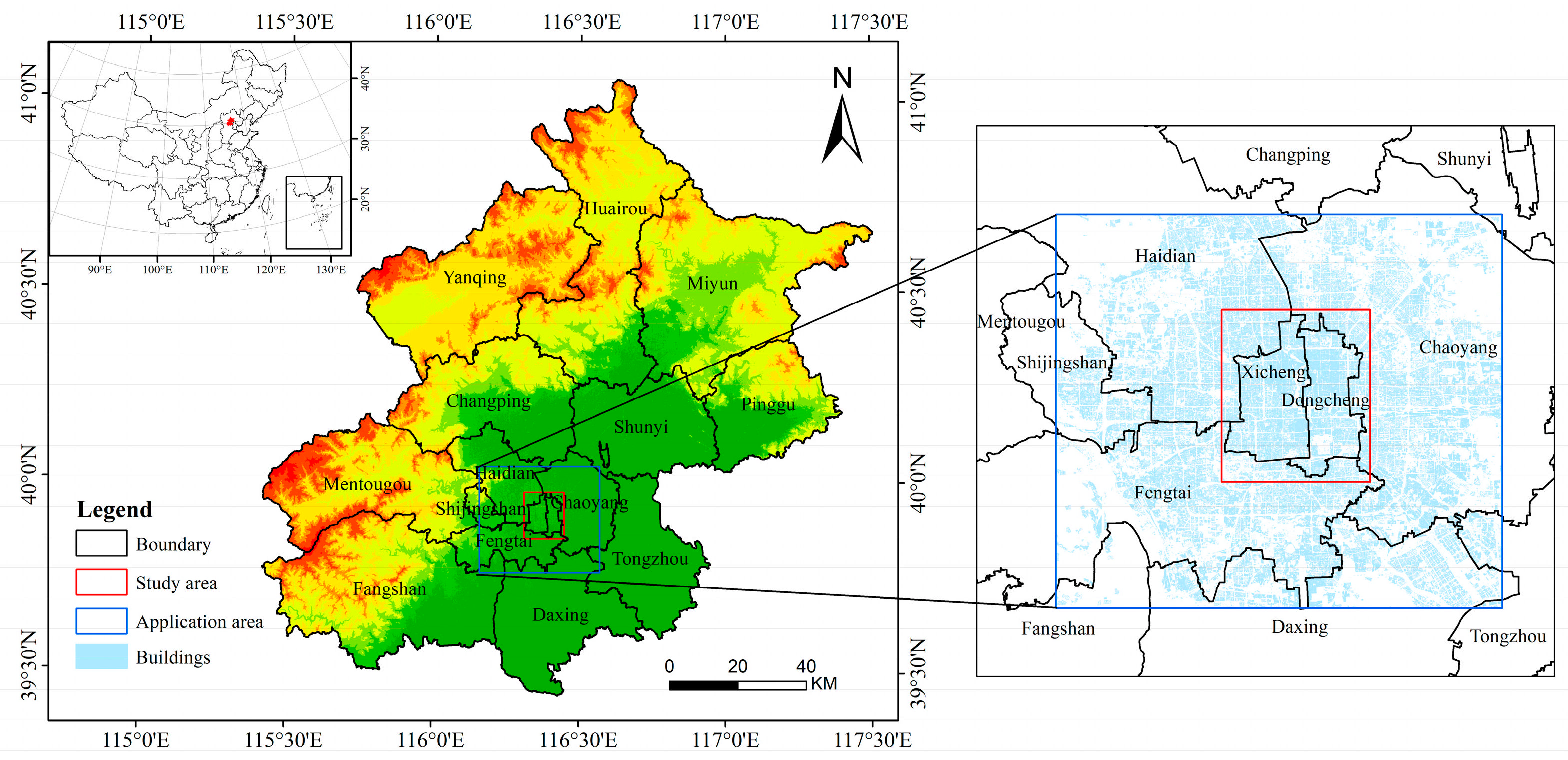
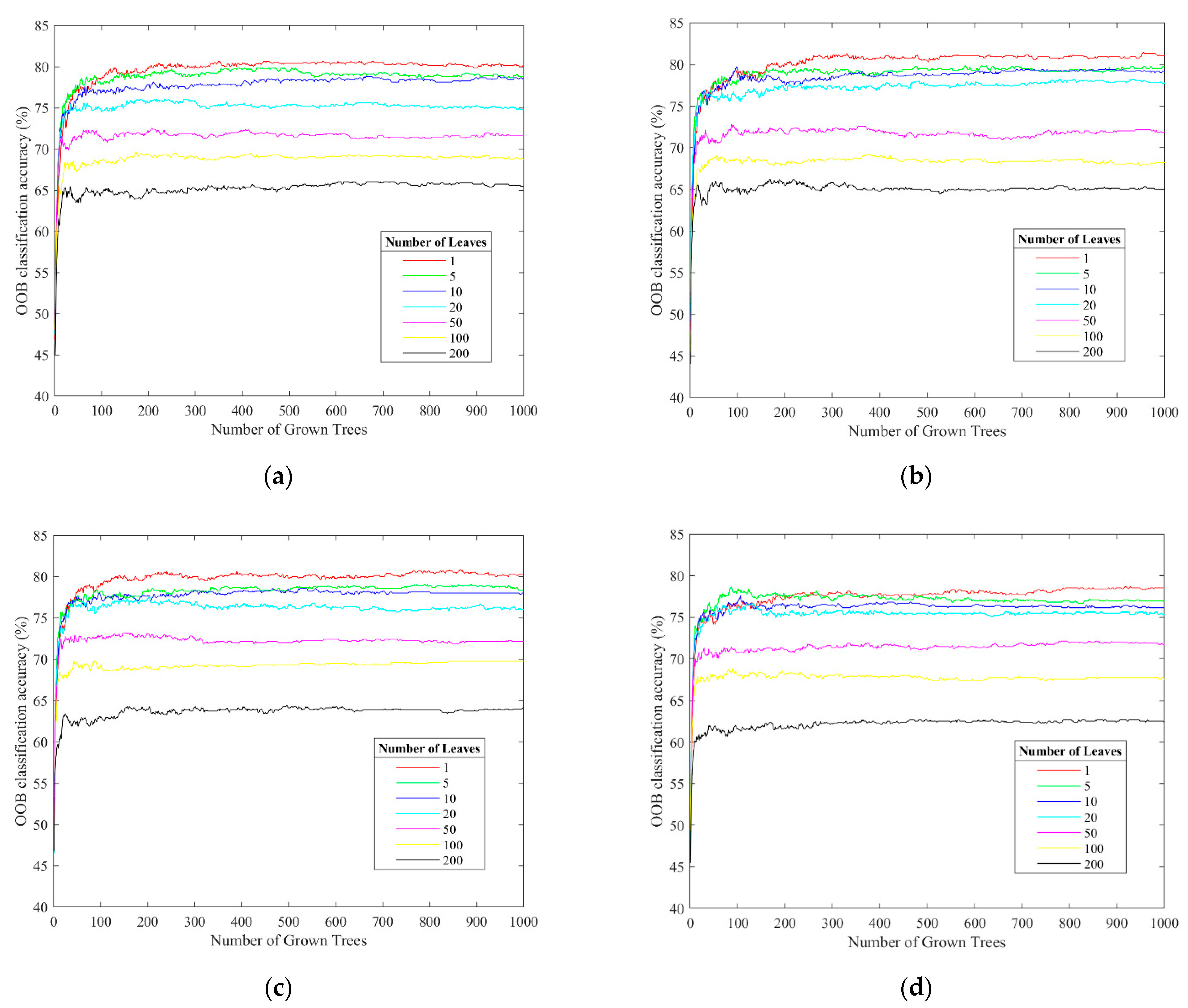
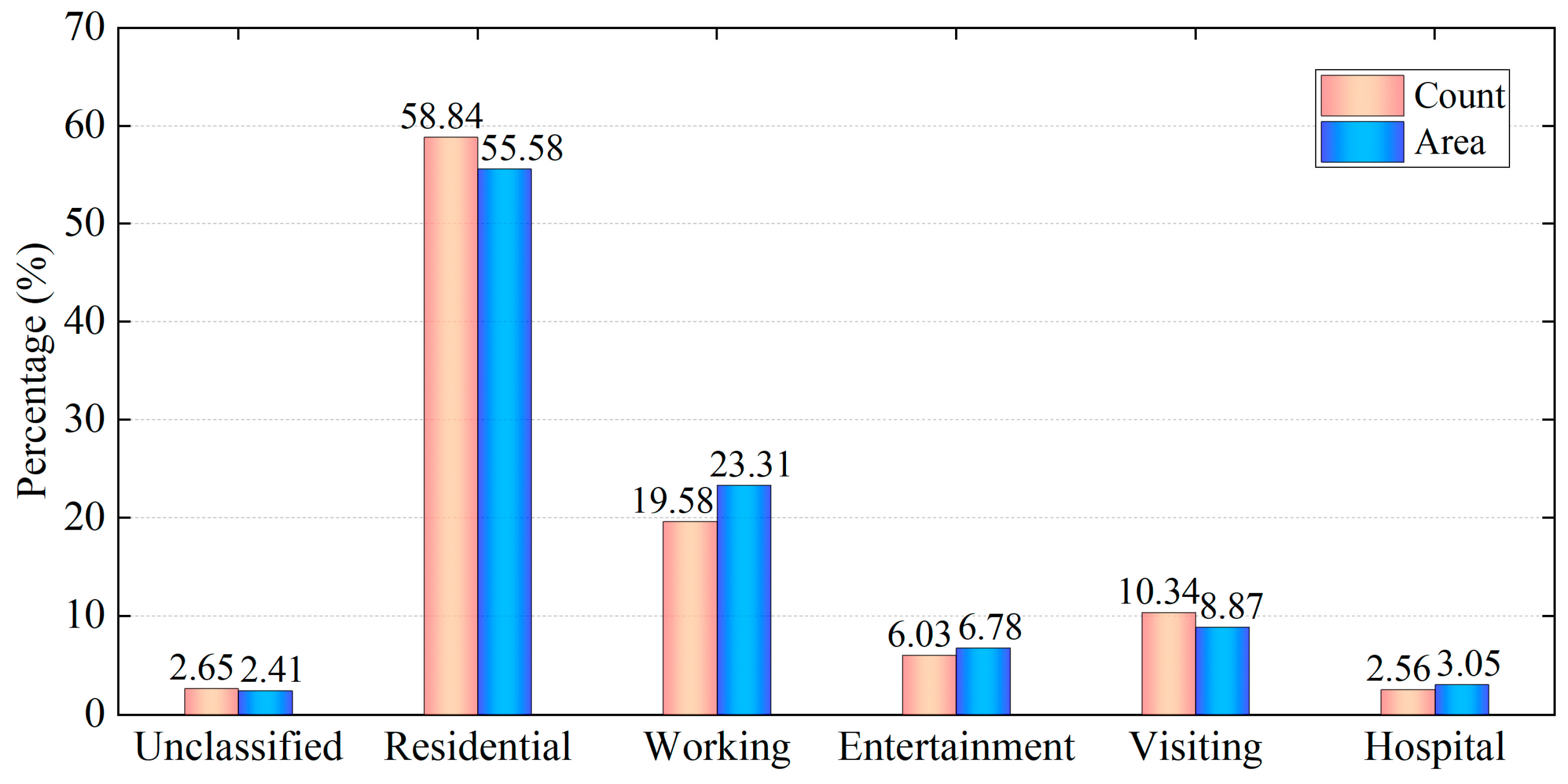
The building footprint layer and the corresponding BFT data from OSM are taken as references for BFT identification model construction. As some of the buildings are ignored in OSM, the buildings are filled in with the help of the street view of Gaode Map. Then, 750 samples are acquired from the study area of Beijing, with all the samples classified into five BFTs based on their population dynamics variation patterns: residential, working, entertainment, visiting, and hospital. Four types of MS data are considered: Station, Gid, Wifimac, and Loginmac. After comparing the prediction performance, Gid is used for BFT prediction. The RF model considering different parameters of leaf numbers and tree numbers is also used for BFT identification. Taking 70% of the total sample as the training set and the remaining 30% as the test set, the MS data-constructed RF model (MS-RF) has an overall classification accuracy of 84.89% with a leaf number of 1 and tree number of 500. To verify the feasibility of the proposed method, remote sensing data from Sentinel-2 are used for comparison. The classification accuracies of the MS-RF model exceed those of the S2-RF model for all five BFTs. When applying the constructed MS-RF model to the central areas of Beijing Dongcheng and Xicheng Districts, the final detection rate is 97.35%. Later, the model is applied to a larger area of Beijing within the 5th Ring Road, and the overall detection rate reaches 94.74%.
This is the first attempt to use MS data independently for BFT identification. As compared with traditional widely used satellite remote sensing data, time-series MS data have the advantages of being intrinsically more useful for BFT identification, as population spatial and temporal dynamic variations reviewed by MS data are more correlated with BFT than geometric or spectral features in remote sensing images. As compared with other types of social sensing data applying spatial information, the time-series information represented by diurnal and daily (weekday/weekend) patterns in population dynamics is used for BFT identification. In this paper, we validate the feasibility and superiority of using MS data for BFT identification and we provide new ideas for the functional mapping of large-scale urban/village buildings using humanities-based big data. The classification products generated by this study greatly reflect the population dynamics, which has important implications for urban management and risk assessment, such as earthquake emergency rescue, prevention and control of COVID-19, and traffic control.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}