
Self-Supervised Learning for Scene Classification in Remote Sensing: Current State of the Art and Perspectives


Abstract
:1. Introduction
2. Background
2.1. Scene Classification
2.2. Self-Supervised Methods
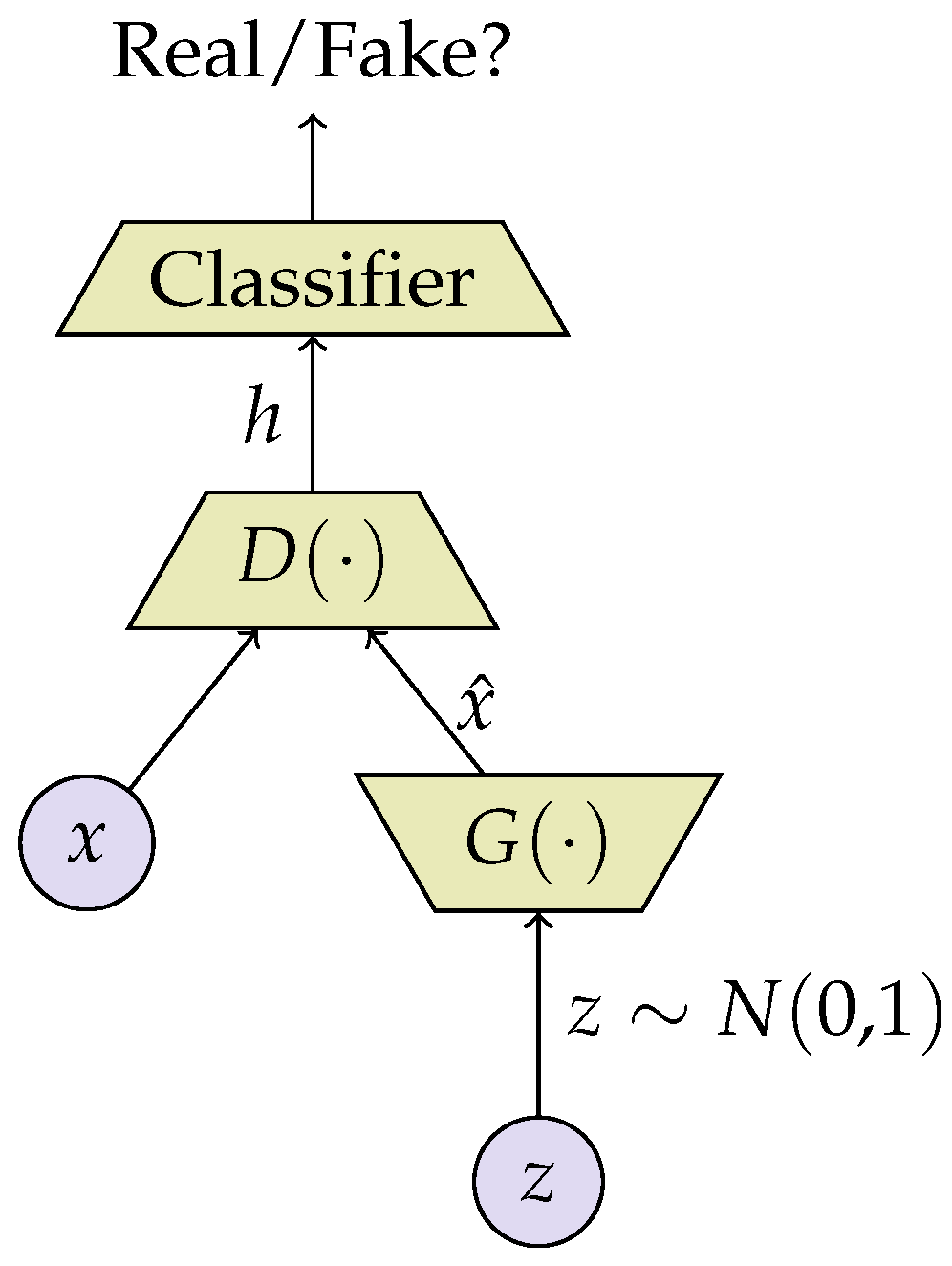
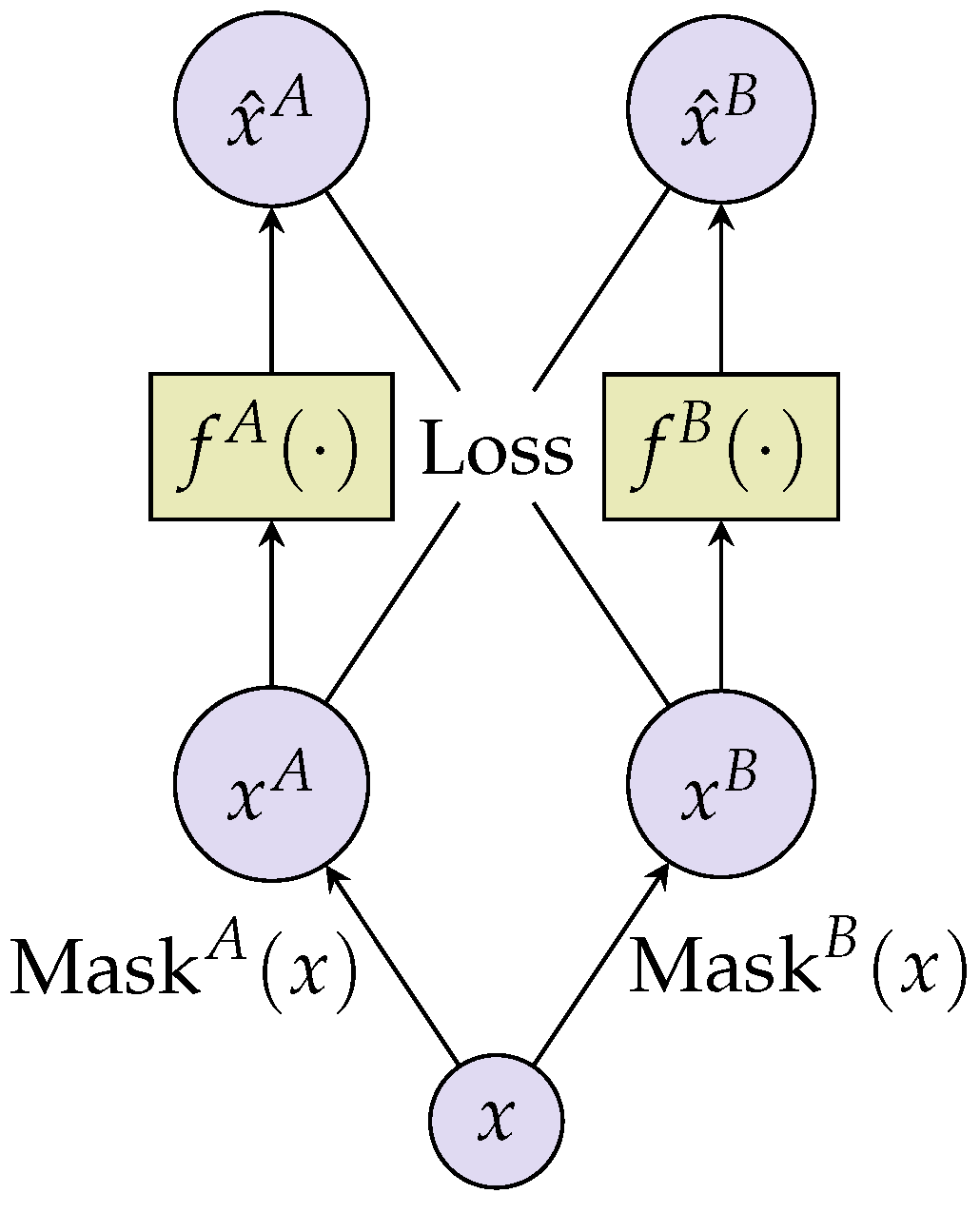
2.2.1. Generative
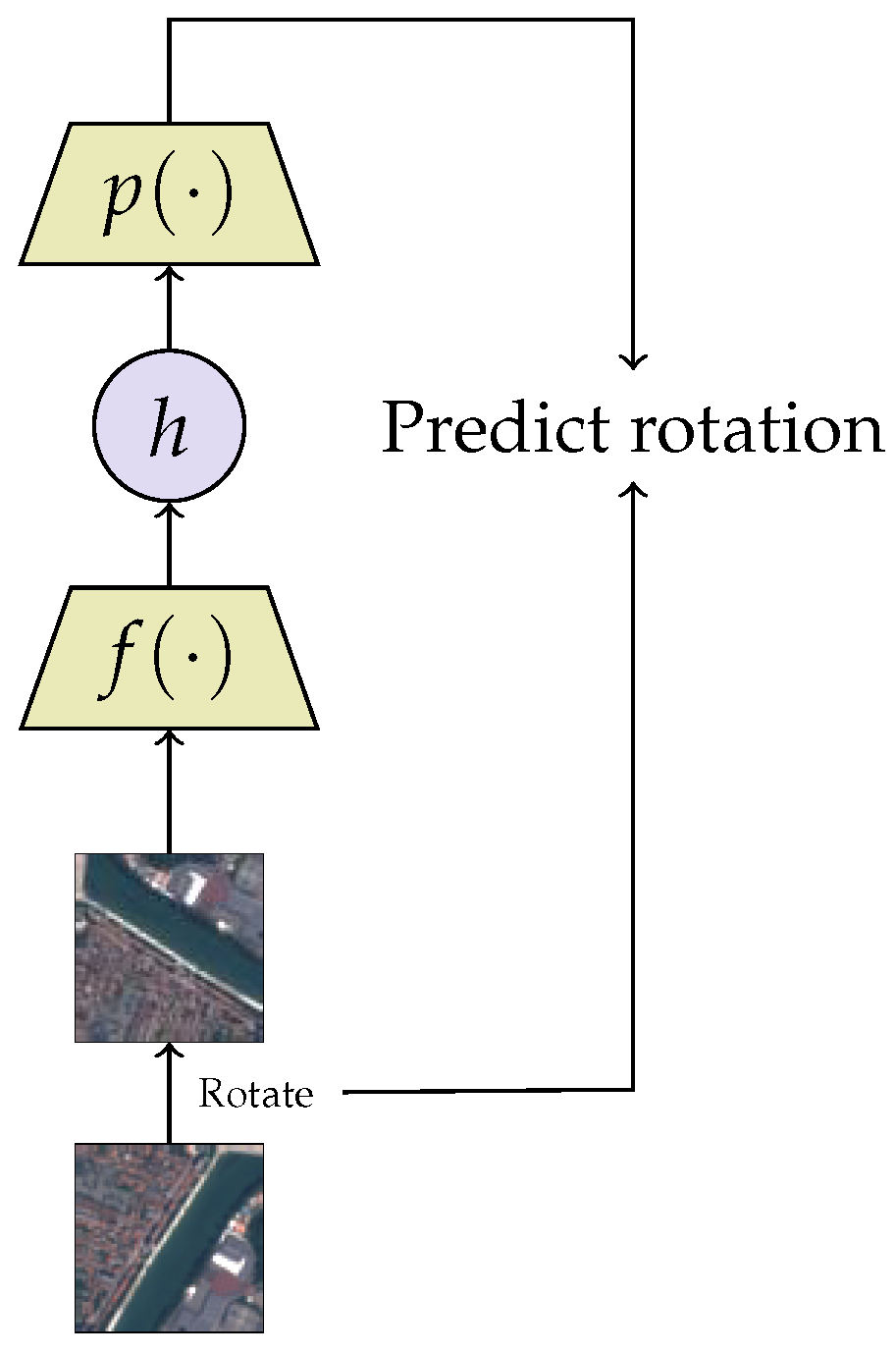
2.2.2. Predictive
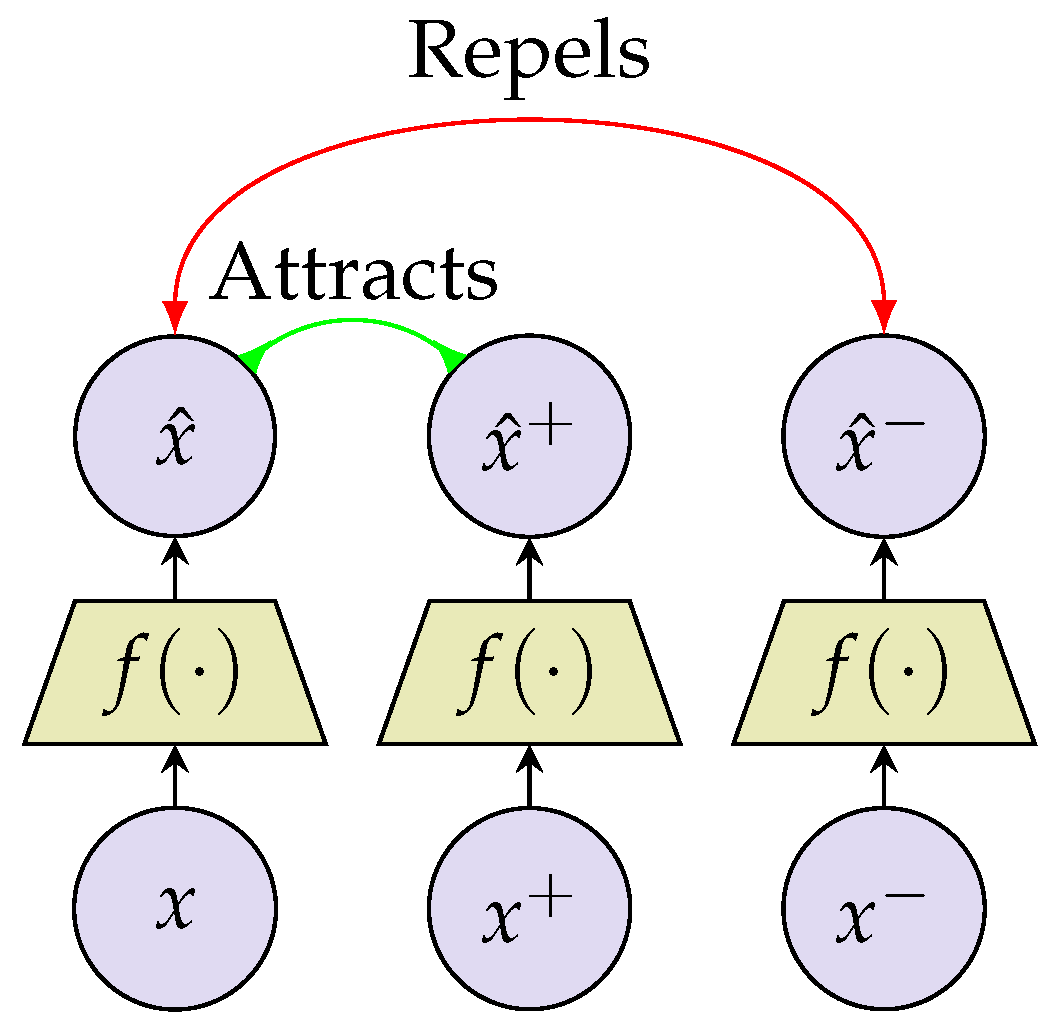
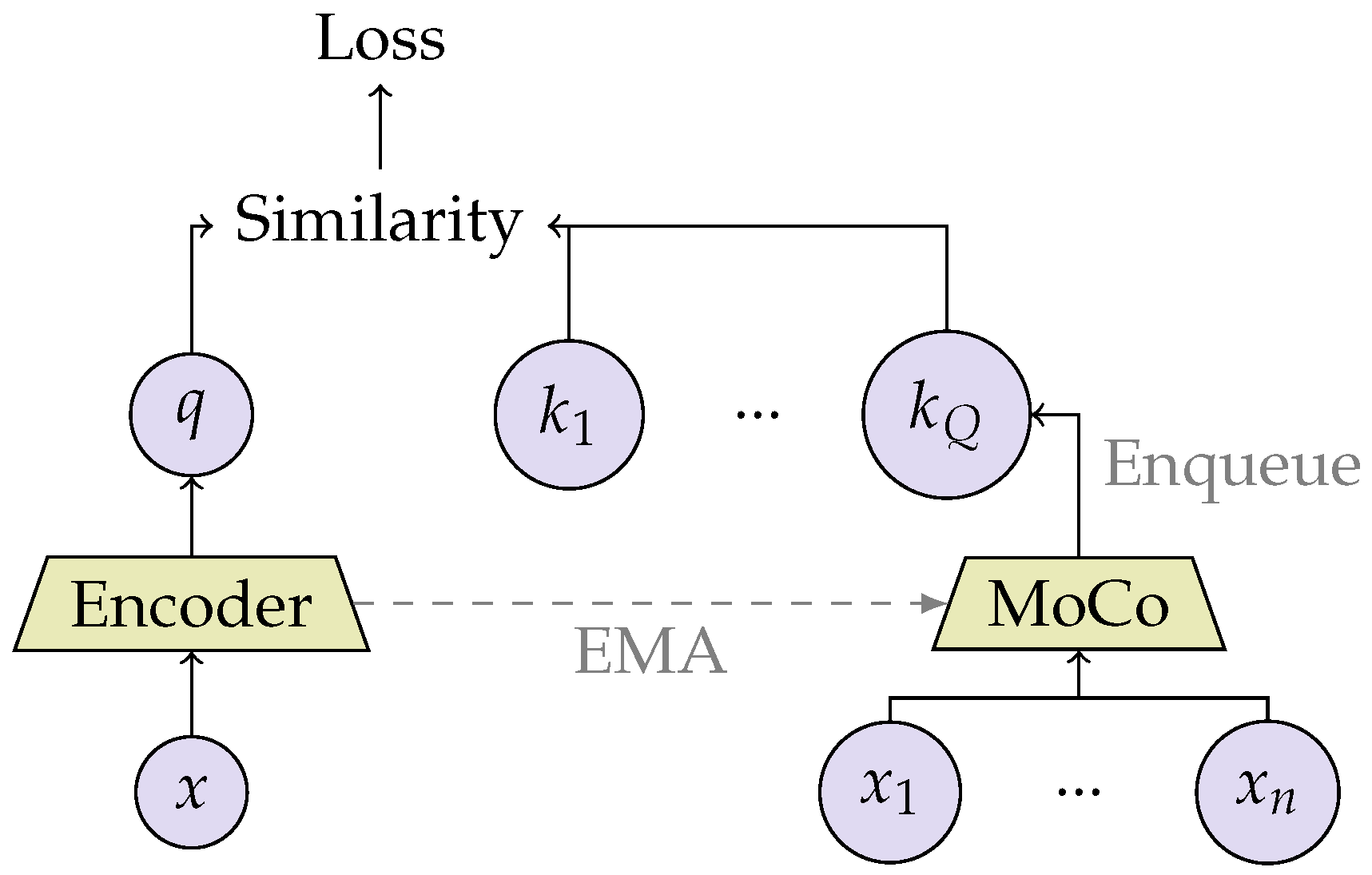
2.2.3. Contrastive
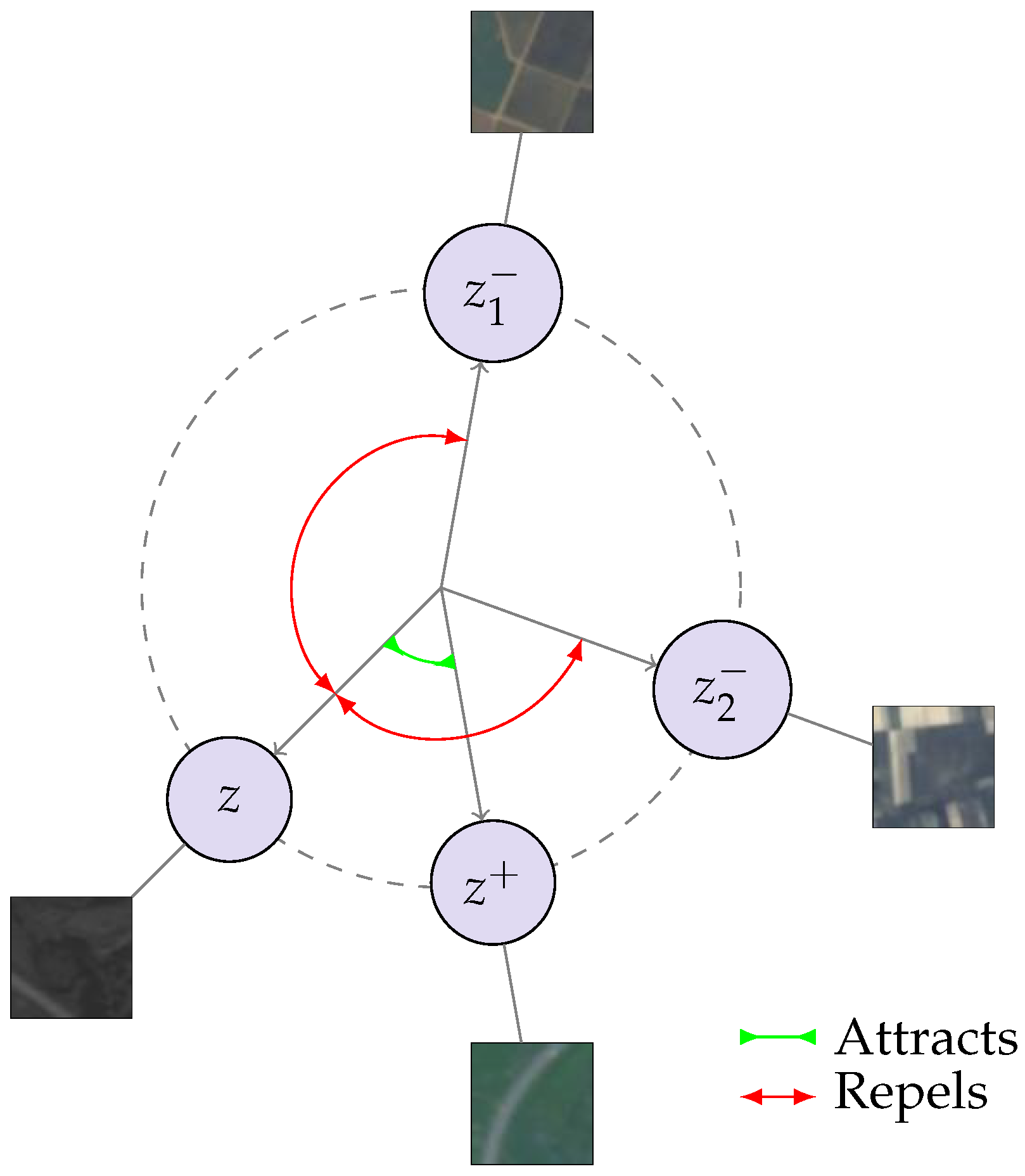
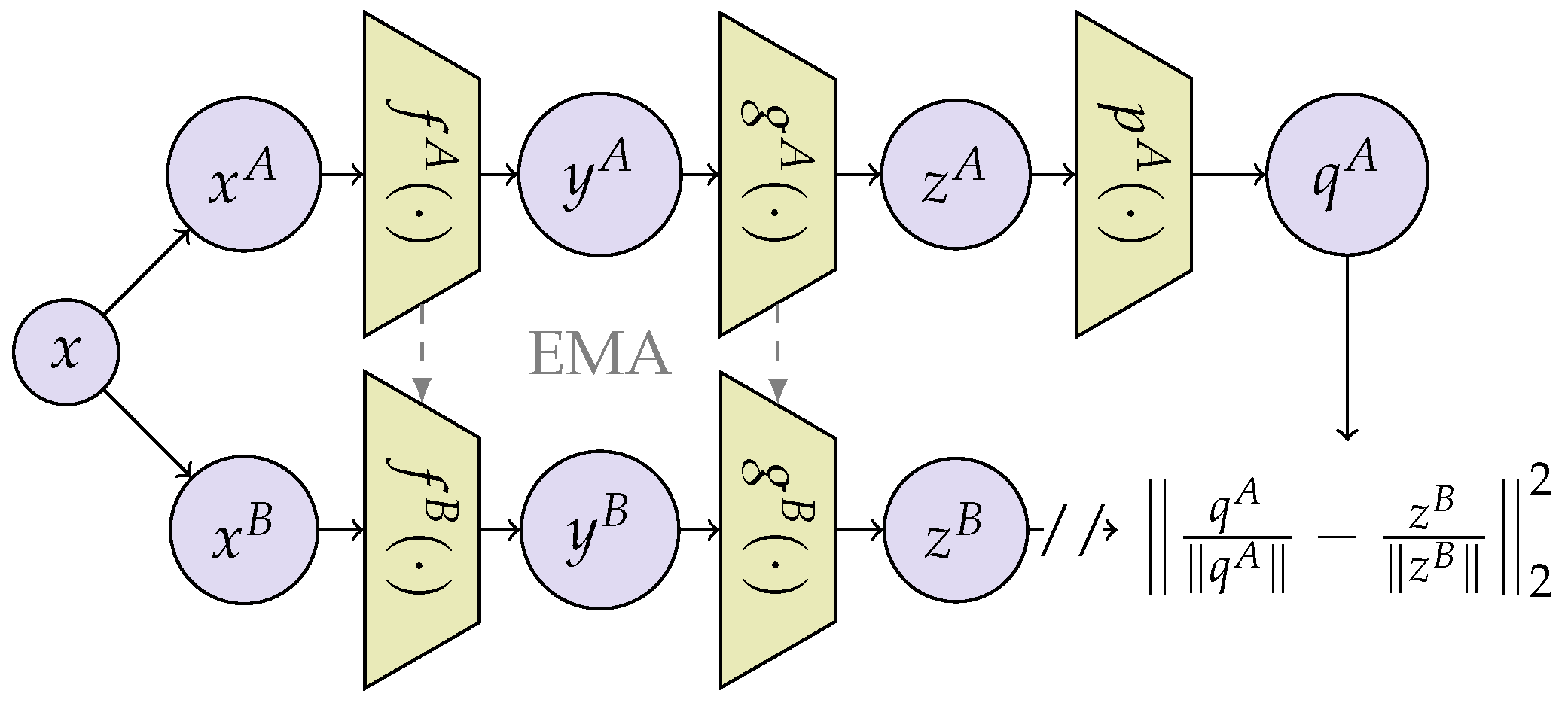
2.2.4. Non-Contrastive
3. Self-Supervised Remote Sensing Scene Classification
3.1. Generative
3.2. Predictive
3.3. Contrastive
3.4. Non-Contrastive
3.5. Summary
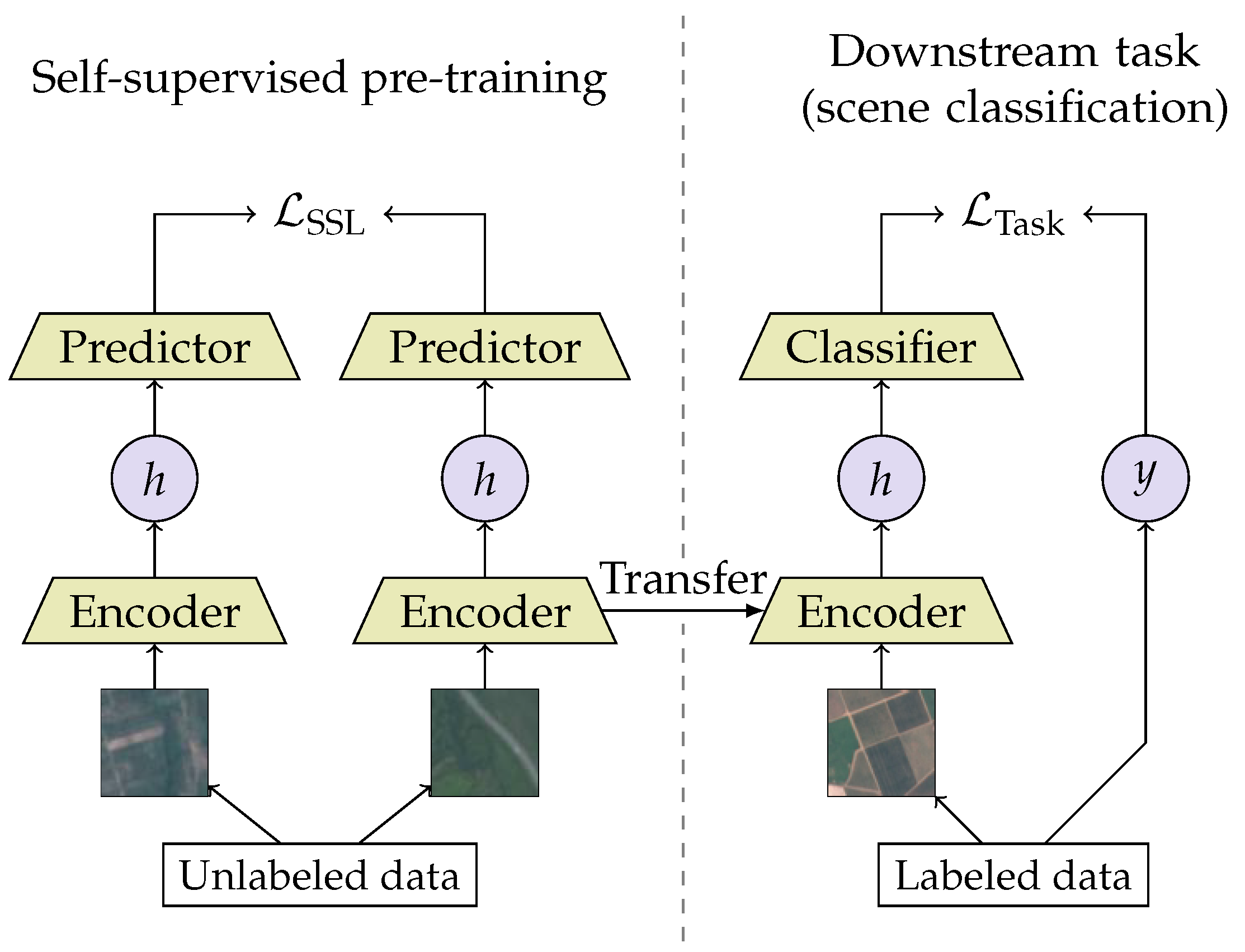
4. Experimental Study
4.1. Datasets
4.2. Experimental Setup
4.3. Evaluation of the Representations
5. Discussion
5.1. The Role of Augmentations
5.2. Transfer of Pre-Trained Models to Other Datasets
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Huh, M.; Agrawal, P.; Efros, A.A. What makes ImageNet good for transfer learning? arXiv 2016, arXiv:1608.08614. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote Sensing Image Scene Classification: Benchmark and State of the Art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G.S. Remote sensing image scene classification meets deep learning: Challenges, methods, benchmarks, and opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar] [CrossRef]
- Lowe, D. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Corfu, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Sivic; Zisserman. Video Google: A text retrieval approach to object matching in videos. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Washington, DC, USA, 13–16 October 2003; Volume 2, pp. 1470–1477. [Google Scholar]
- Sánchez, J.; Perronnin, F.; Mensink, T.; Verbeek, J. Image classification with the fisher vector: Theory and practice. Int. J. Comput. Vis. 2013, 105, 222–245. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Neumann, M.; Pinto, A.S.; Zhai, X.; Houlsby, N. Training general representations for remote sensing using in-domain knowledge. In Proceedings of the IGARSS 2020-2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 6730–6733. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010. [Google Scholar]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A Benchmark Dataset for Performance Evaluation of Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Li, H.; Dou, X.; Tao, C.; Wu, Z.; Chen, J.; Peng, J.; Deng, M.; Zhao, L. RSI-CB: A large-scale remote sensing image classification benchmark using crowdsourced data. Sensors 2020, 20, 1594. [Google Scholar] [CrossRef] [PubMed]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef]
- Sumbul, G.; Charfuelan, M.; Demir, B.; Markl, V. Bigearthnet: A large-scale benchmark archive for remote sensing image understanding. In Proceedings of the IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 5901–5904. [Google Scholar]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s optical high-resolution mission for GMES operational services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling laws for neural language models. arXiv 2020, arXiv:2001.08361. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Qi, G.J.; Luo, J. Small data challenges in big data era: A survey of recent progress on unsupervised and semi-supervised methods. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2168–2187. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4037–4058. [Google Scholar] [CrossRef]
- Ohri, K.; Kumar, M. Review on self-supervised image recognition using deep neural networks. Knowl. Based Syst. 2021, 224, 107090. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, F.; Hou, Z.; Mian, L.; Wang, Z.; Zhang, J.; Tang, J. Self-supervised learning: Generative or contrastive. IEEE Trans. Knowl. Data Eng. 2021. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 18–24 July 2008; pp. 1096–1103. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2014, arXiv:1312.6114. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked Autoencoders Are Scalable Vision Learners. arXiv 2021, arXiv:2111.06377. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K., Eds.; Curran Associates, Inc.: Montreal, QC, Canada, 2014; Volume 27. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Doersch, C.; Gupta, A.; Efros, A.A. Unsupervised Visual Representation Learning by Context Prediction. In Proceedings of the International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful Image Colorization. In Proceedings of the European Conference on Computer Vision ECCV, Munich, Germany, 8–14 September 2016. [Google Scholar]
- Gidaris, S.; Singh, P.; Komodakis, N. Unsupervised representation learning by predicting image rotations. arXiv 2018, arXiv:1803.07728. [Google Scholar]
- Noroozi, M.; Favaro, P. Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles. In Proceedings of the European Conference on Computer Vision ECCV, Munich, Germany, 8–14 September 2016. [Google Scholar]
- Dosovitskiy, A.; Springenberg, J.T.; Riedmiller, M.; Brox, T. Discriminative unsupervised feature learning with convolutional neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 766–774. [Google Scholar] [CrossRef] [PubMed]
- Jing, L.; Vincent, P.; LeCun, Y.; Tian, Y. Understanding dimensional collapse in contrastive self-supervised learning. arXiv 2021, arXiv:2110.09348. [Google Scholar]
- Dong, X.; Shen, J. Triplet Loss in Siamese Network for Object Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wu, Z.; Xiong, Y.; Yu, S.X.; Lin, D. Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3733–3742. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning PMLR, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 9726–9735. [Google Scholar] [CrossRef]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. Adv. Neural Inf. Process. Syst. 2020, 33, 9912–9924. [Google Scholar]
- Peyré, G.; Cuturi, M. Computational optimal transport: With applications to data science. Found. Trends Mach. Learn. 2019, 11, 355–607. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, R.; Shen, C.; Kong, T.; Li, L. Dense contrastive learning for self-supervised visual pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3024–3033. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.025312. [Google Scholar]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15750–15758. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 9650–9660. [Google Scholar]
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow twins: Self-supervised learning via redundancy reduction. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 12310–12320. [Google Scholar]
- Saxe, A.M.; Bansal, Y.; Dapello, J.; Advani, M.; Kolchinsky, A.; Tracey, B.D.; Cox, D.D. On the information bottleneck theory of deep learning. J. Stat. Mech. Theory Exp. 2019, 2019, 124020. [Google Scholar] [CrossRef]
- Bardes, A.; Ponce, J.; LeCun, Y. VICReg: Variance-Invariance-Covariance Regularization For Self-Supervised Learning. arXiv 2022, arXiv:2105.04906. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.222.9220&rep=rep1&type=pdf (accessed on 20 July 2022).
- Lin, D.; Fu, K.; Wang, Y.; Xu, G.; Sun, X. MARTA GANs: Unsupervised Representation Learning for Remote Sensing Image Classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2092–2096. [Google Scholar] [CrossRef]
- Penatti, O.A.; Nogueira, K.; Dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 44–51. [Google Scholar]
- Stojnić, V.; Risojević, V. Evaluation of Split-Brain Autoencoders for High-Resolution Remote Sensing Scene Classification. In Proceedings of the 2018 International Symposium ELMAR, Zadar, Croatia, 16–19 September 2018; pp. 67–70. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A. Split-brain autoencoders: Unsupervised learning by cross-channel prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1058–1067. [Google Scholar]
- Tao, C.; Qi, J.; Lu, W.; Wang, H.; Li, H. Remote sensing image scene classification with self-supervised paradigm under limited labeled samples. IEEE Geosci. Remote. Sens. Lett. 2020, 19, 8004005. [Google Scholar] [CrossRef]
- Zhao, Z.; Luo, Z.; Li, J.; Chen, C.; Piao, Y. When self-supervised learning meets scene classification: Remote sensing scene classification based on a multitask learning framework. Remote Sens. 2020, 12, 3276. [Google Scholar] [CrossRef]
- Xia, G.S.; Yang, W.; Delon, J.; Gousseau, Y.; Sun, H.; Maître, H. Structural high-resolution satellite image indexing. In Proceedings of the ISPRS TC VII Symposium-100 Years ISPRS, Vienna, Austria, 5–7 July 2010; Volume 38, pp. 298–303. [Google Scholar]
- Yuan, Y.; Lin, L. Self-Supervised Pretraining of Transformers for Satellite Image Time Series Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 474–487. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Jean, N.; Wang, S.; Samar, A.; Azzari, G.; Lobell, D.; Ermon, S. Tile2vec: Unsupervised representation learning for spatially distributed data. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 3967–3974. [Google Scholar]
- Boryan, C.; Yang, Z.; Mueller, R.; Craig, M. Monitoring US agriculture: The US department of agriculture, national agricultural statistics service, cropland data layer program. Geocarto Int. 2011, 26, 341–358. [Google Scholar] [CrossRef]
- Jung, H.; Jeon, T. Self-supervised learning with randomised layers for remote sensing. Electron. Lett. 2021, 57, 249–251. [Google Scholar] [CrossRef]
- Stojnic, V.; Risojevic, V. Self-Supervised Learning of Remote Sensing Scene Representations Using Contrastive Multiview Coding. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021; pp. 1182–1191. [Google Scholar] [CrossRef]
- Ayush, K.; Uzkent, B.; Meng, C.; Tanmay, K.; Burke, M.; Lobell, D.; Ermon, S. Geography-aware self-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 10181–10190. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved baselines with momentum contrastive learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Mañas, O.; Lacoste, A.; Giró-i Nieto, X.; Vazquez, D.; Rodríguez, P. Seasonal Contrast: Unsupervised Pre-Training from Uncurated Remote Sensing Data. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 10 March 2021; pp. 9394–9403. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A.; Gousseau, Y. Urban change detection for multi-spectral earth observation using convolutional neural networks. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 2115–2118. [Google Scholar]
- Jung, H.; Oh, Y.; Jeong, S.; Lee, C.; Jeon, T. Contrastive Self-Supervised Learning With Smoothed Representation for Remote Sensing. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8010105. [Google Scholar] [CrossRef]
- Lam, D.; Kuzma, R.; McGee, K.; Dooley, S.; Laielli, M.; Klaric, M.; Bulatov, Y.; McCord, B. xview: Objects in context in overhead imagery. arXiv 2018, arXiv:1802.07856. [Google Scholar]
- Tao, C.; Qia, J.; Zhang, G.; Zhu, Q.; Lu, W.; Li, H. TOV: The Original Vision Model for Optical Remote Sensing Image Understanding via Self-supervised Learning. arXiv 2022, arXiv:2204.04716. [Google Scholar]
- Miller, G.A. WordNet: An Electronic Lexical Database; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. PatternNet: A benchmark dataset for performance evaluation of remote sensing image retrieval. ISPRS J. Photogramm. Remote Sens. 2018, 145, 197–209. [Google Scholar] [CrossRef]
- Scheibenreif, L.; Mommert, M.; Borth, D. Contrastive self-supervised data fusion for satellite imagery. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, 3, 705–711. [Google Scholar] [CrossRef]
- Ebel, P.; Meraner, A.; Schmitt, M.; Zhu, X.X. Multisensor Data Fusion for Cloud Removal in Global and All-Season Sentinel-2 Imagery. IEEE Trans. Geosci. Remote. Sens. 2020, 59, 5866–5878. [Google Scholar] [CrossRef]
- Yokoya, N.; Ghamisi, P.; Hansch, R.; Schmitt, M. Report on the 2020 IEEE GRSS data fusion contest-global land cover mapping with weak supervision [technical committees]. IEEE Geosci. Remote Sens. Mag. 2020, 8, 134–137. [Google Scholar] [CrossRef]
- Windsor, R.; Jamaludin, A.; Kadir, T.; Zisserman, A. Self-supervised multi-modal alignment for whole body medical imaging. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; Springer: Berlin, Germany, 2021; pp. 90–101. [Google Scholar]
- Scheibenreif, L.; Hanna, J.; Mommert, M.; Borth, D. Self-Supervised Vision Transformers for Land-Cover Segmentation and Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 1422–1431. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Huang, H.; Mou, Z.; Li, Y.; Li, Q.; Chen, J.; Li, H. Spatial-temporal Invariant Contrastive Learning for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6509805. [Google Scholar] [CrossRef]
- Perrot, M.; Courty, N.; Flamary, R.; Habrard, A. Mapping estimation for discrete optimal transport. Adv. Neural Inf. Process. Syst. 2016, 29, 4204–4212. [Google Scholar]
- Rubner, Y.; Tomasi, C.; Guibas, L. A metric for distributions with applications to image databases. In Proceedings of the Sixth International Conference on Computer Vision (IEEE Cat. No.98CH36271), Bombay, India, 7 January 1998; pp. 59–66. [Google Scholar]
- Zheng, X.; Kellenberger, B.; Gong, R.; Hajnsek, I.; Tuia, D. Self-Supervised Pretraining and Controlled Augmentation Improve Rare Wildlife Recognition in UAV Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 732–741. [Google Scholar]
- Wang, X.; Liu, Z.; Yu, S.X. Unsupervised Feature Learning by Cross-Level Instance-Group Discrimination. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 20–25 June 2021; pp. 12581–12590. [Google Scholar] [CrossRef]
- Kellenberger, B.; Marcos, D.; Tuia, D. Detecting mammals in UAV images: Best practices to address a substantially imbalanced dataset with deep learning. Remote Sens. Environ. 2018, 216, 139–153. [Google Scholar] [CrossRef]
- Güldenring, R.; Nalpantidis, L. Self-supervised contrastive learning on agricultural images. Comput. Electron. Agric. 2021, 191, 106510. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar] [CrossRef]
- Olsen, A.; Konovalov, D.A.; Philippa, B.; Ridd, P.; Wood, J.C.; Johns, J.; Banks, W.; Girgenti, B.; Kenny, O.; Whinney, J.; et al. DeepWeeds: A multiclass weed species image dataset for deep learning. Sci. Rep. 2019, 9, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Chiu, M.T.; Xu, X.; Wei, Y.; Huang, Z.; Schwing, A.G.; Brunner, R.; Khachatrian, H.; Karapetyan, H.; Dozier, I.; Rose, G.; et al. Agriculture-vision: A large aerial image database for agricultural pattern analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2828–2838. [Google Scholar]
- Risojević, V.; Stojnić, V. The role of pre-training in high-resolution remote sensing scene classification. arXiv 2021, arXiv:2111.03690. [Google Scholar]
- Guo, D.; Xia, Y.; Luo, X. Self-supervised GANs with similarity loss for remote sensing image scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2508–2521. [Google Scholar] [CrossRef]
- Chen, T.; Zhai, X.; Ritter, M.; Lucic, M.; Houlsby, N. Self-supervised gans via auxiliary rotation loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 12154–12163. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 7354–7363. [Google Scholar]
- Jain, P.; Schoen-Phelan, B.; Ross, R. Self-Supervised Learning for Invariant Representations from Multi-Spectral and SAR Images. arXiv 2022, arXiv:2205.02049. [Google Scholar]
- Wang, Y.; Albrecht, C.M.; Zhu, X.X. Self-supervised Vision Transformers for Joint SAR-optical Representation Learning. arXiv 2022, arXiv:2204.05381. [Google Scholar]
- Sumbul, G.; De Wall, A.; Kreuziger, T.; Marcelino, F.; Costa, H.; Benevides, P.; Caetano, M.; Demir, B.; Markl, V. BigEarthNet-MM: A Large-Scale, Multimodal, Multilabel Benchmark Archive for Remote Sensing Image Classification and Retrieval [Software and Datasets]. IEEE Geosci. Remote Sens. Mag. 2021, 9, 174–180. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Jiang, Z.; Chen, T.; Chen, T.; Wang, Z. Robust pre-training by adversarial contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 16199–16210. [Google Scholar]
- Kim, M.; Tack, J.; Hwang, S.J. Adversarial self-supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 2983–2994. [Google Scholar]
- Xu, Y.; Sun, H.; Chen, J.; Lei, L.; Kuang, G.; Ji, K. Robust remote sensing scene classification by adversarial self-supervised learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4936–4939. [Google Scholar]
- Patel, C.; Sharma, S.; Gulshan, V. Evaluating Self and Semi-Supervised Methods for Remote Sensing Segmentation Tasks. arXiv 2021, arXiv:2111.10079. [Google Scholar]
- Wang, Y.; Albrecht, C.M.; Braham, N.A.A.; Mou, L.; Zhu, X.X. Self-supervised Learning in Remote Sensing: A Review. arXiv 2022, arXiv:2206.13188. [Google Scholar]
- Neumann, M.; Pinto, A.S.; Zhai, X.; Houlsby, N. In-domain representation learning for remote sensing. arXiv 2019, arXiv:1911.06721. [Google Scholar]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Nevada, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2015; pp. 448–456. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Hinton, G.E.; Roweis, S. Stochastic neighbor embedding. Adv. Neural Inf. Process. Syst. 2002, 15, 857–864. [Google Scholar]
- Shen, K.; Jones, R.; Kumar, A.; Xie, S.M.; HaoChen, J.Z.; Ma, T.; Liang, P. Connect, Not Collapse: Explaining Contrastive Learning for Unsupervised Domain Adaptation. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Category | Dataset | Main Contributions |
|---|---|---|---|
| Lin et al. 2017 [52] | Generative | UC-Merced, Brazilian Coffee Scenes | 🟉 Propose the MARTA-GANs to extract multi-level features from the discriminator and aggregate them by concatenation. 🟉 Enhance the quality of fake samples from the generator and improve the classification performance with a low number of parameters in a semi-supervised approach. |
| Stojnić and Risojević 2018 [54] | Generative | Resisc-45, AID | 🟉 Successfully apply split-brain autoencoders [55] on remote sensing images. 🟉 Split the input data in two different non-overlapping subsets of data channels and learn the relationship between data channels. |
| Tao et al. 2020 [56] | Predictive Contrastive | Resisc-45, AID, EuroSAT | 🟉 Evaluate different predictive pretext tasks on remote sensing datasets including image inpainting and relative position prediction. 🟉 Promote the contrastive instance-level discrimination approach which provides better performance than predictive methods. |
| Zhao et al. 2020 [57] | Predictive | Resisc-45, AID, WHU-RS19, UC-Merced | 🟉 Propose a multitask learning model with a mixup loss to combine rotation predictive approach with supervised training strategy. 🟉 Promote a potential of combining different self-supervised objectives as auxiliary loss in a fully-supervised framework to improve classification performance. |
| Yuan and Lin 2021 [59] | Predictive | Sentinel-2 time series | 🟉 Propose a self-supervised learning method SITS-BERT for image time series based on the natural language pre-training method BERT [60]. 🟉 Improve the learning of spectral–temporal representations related to land over contents from time series images. |
| Jean et al. 2019 [62] | Contrastive | NAIP, CDL | 🟉 Propose the Tile2Vec method based on triplet loss to extract image-level representation. 🟉 Exploit the geographical information to obtain the positive and negative samples within contrastive learning. |
| Jung and Jeon 2021 [64] | Contrastive | NAIP, CDL | 🟉 Reformulate the triplet loss as a binary cross-entropy instead of a metric learning-based similarity objective 🟉 Propose to use randomized layers (sampled from the centered Gaussian distribution at each epoch) to improve the quality of representations with respect to Tile2Vec. |
| Stojnić and Risojević 2021 [65] | Contrastive | Resisc-45, BigEarthNet, NWPU-WHR10 | 🟉 Propose a contrastive multiview coding framework with a data-splitting scheme based on different image channels per branch. 🟉 Leverage the contrastive loss to align positive pairs and produce consistent representations across multiple image channels. |
| Ayush et al. 2021 [66] | Contrastive Predictive | NAIP, fMoW, xView | 🟉 Generate augmented views by using image captures taken at different timestamps at the same location (geography-aware). 🟉 Propose a novel self-supervised pretext task, namely, geolocation classification, to maximize the prediction score of the right location cluster. |
| Mañas et al. 2021 [68] | Contrastive | BigEarthNet, EuroSAT, OSDC | 🟉 Leverage the location and temporal metadata present in Sentinel-2 data to create augmented views. 🟉 Create different predictor branches invariant to different augmentations, respectively, geographical location, temporal augmentation, and both. |
| Jung et al. 2021 [70] | Contrastive | Resisc-45, UC-Merced, EuroSAT, CDL | 🟉 Create positive pairs by sampling geographically-near patches and averaging their representations to obtain a smoothed representation. 🟉 Outperform three benchmark methods: SimCLR, MoCo-v2, and Tile2Vec, in most test scenarios. |
| Tao et al. 2022 [72] | Contrastive | AID, PatternNet, UC-Merced, EuroSAT, etc. | 🟉 Create two large-scale unlabeled datasets (TOV-NI and TOV-RS) used for pre-training label-free and task-independent SSL. 🟉 Pre-train the self-supervised TOV model first on TOV-NI to learn low-level visual features on natural scenes, then on TOV-RS to learn specific high-level representations of remote sensing scene. Outperform SimCLR and MoCo-v2. |
| Scheibenreif et al. 2022 [75] | Contrastive | Sen12MS, EuroSAT, DFC2020, | 🟉 Exploit the contrastive self-supervised approach to perform multimodal SAR–optical fusion for land-cover scene classification. 🟉 Propose the augmentation-free SSL framework, namely, Dual-SimCLR, with positive pairs of SAR/optical patches at the same geolocation. |
| Scheibenreif et al. 2022 [79] | Contrastive | SEN12MS, DFC2020 | 🟉 Develop transformer-based SSL framework to perform multimodal land-cover classification and segmentation. 🟉 Promote the high potential of transformer architectures within SSL paradigms for remote sensing applications. |
| Huang et al. 2022 [81] | Contrastive | Resisc-45, AID, EuroSAT, PatternNet | 🟉 Develop a spatial–temporal-invariant contrastive learning method with the idea that representations invariant to color histogram changes are more robust in downstream tasks. 🟉 Generate augmented views of images across the temporal dimension using optimal transport to transfer the color histograms from one image to another. |
| Zheng et al. 2021 [84] | Contrastive | KWD | 🟉 Explore self-supervised pre-training to tackle the challenging task of wildlife recognition using UAV imagery. 🟉 Develop a model combining the cross-level discrimination with the momentum contrast encoders, and propose extra geometric augmentations. |
| Güldenring and Lazaros 2021 [87] | Contrastive | DeepWeeds, Aerial Farmland | 🟉 Investigate the potential of self-supervised learning applied to agricultural images. 🟉 Provide a detailed experimentation on different weight initialization strategies for fine-tuning on agricultural images and confirm the potential of SSL in this applied field. |
| Risojević and Stojnić 2021 [91] | Contrastive | MLRSNet, Resisc-45, PatternNet, AID, UC-Merced | 🟉 Investigate and compare the performance of self-supervised SwAV model against other weight initialization strategies for remote sensing scene classification. 🟉 Figure out that the ImageNet initialization could be combined with the self-supervised pre-training on the target domain to achieve even better performance. |
| Guo et al. 2021 [92] | Non-contrastive Generative | Resisc-45, AID | 🟉 Develop a novel self-supervised GAN framework by exploiting the gated self-attention module as well as the non-contrastive BYOL approach. 🟉 Leverage the use of non-contrastive joint-embedding learning with a similarity loss instead of an auxiliary rotation-based loss to strengthen the GAN discriminator. |
| Jain et al. 2022 [95] | Non-contrastive | EuroSAT, Sen12MS | 🟉 Leverage the non-contrastive BYOL method to learn joint representations from multi-spectral and SAR images. 🟉 Use optical multi-spectral bands in BYOL’s online encoder and the polarimetric SAR channels in its momentum encoder. |
| Wang et al. 2022 [96] | Non-contrastive | BigEarthNet-MM | 🟉 Explore DINO paradigm with transformer backbones for optical–SAR joint representation learning in remote sensing. 🟉 Propose an augmentation which randomly masks either multi-spectral or polarimetric SAR channels. |
| Xu et al. 2021 [101] | Non-contrastive | Resisc-45 | 🟉 Investigate the adversarial SSL in the context of scene classification using the BYOL approach. 🟉 Train an encoder in a self-supervised manner using adversarial attacks to create positive pairs. |
| Table/Figure | Method | Dataset | Description |
|---|---|---|---|
| Table 3 | SimCLR, MoCo-v2, BYOL, Barlow twins | Resisc-45, EuroSAT | Compare classification performance of different SSL frameworks with the random initialization and the ImageNet supervised approach using the linear classification protocol with frozen pre-trained weights. |
| Table 4 | SimCLR, MoCo-v2, BYOL, Barlow twins | Resisc-45, EuroSAT | Compare classification performance of different SSL frameworks with the random initialization and the ImageNet supervised approach using the fine-tuning evaluation protocol with different percentage of training samples. |
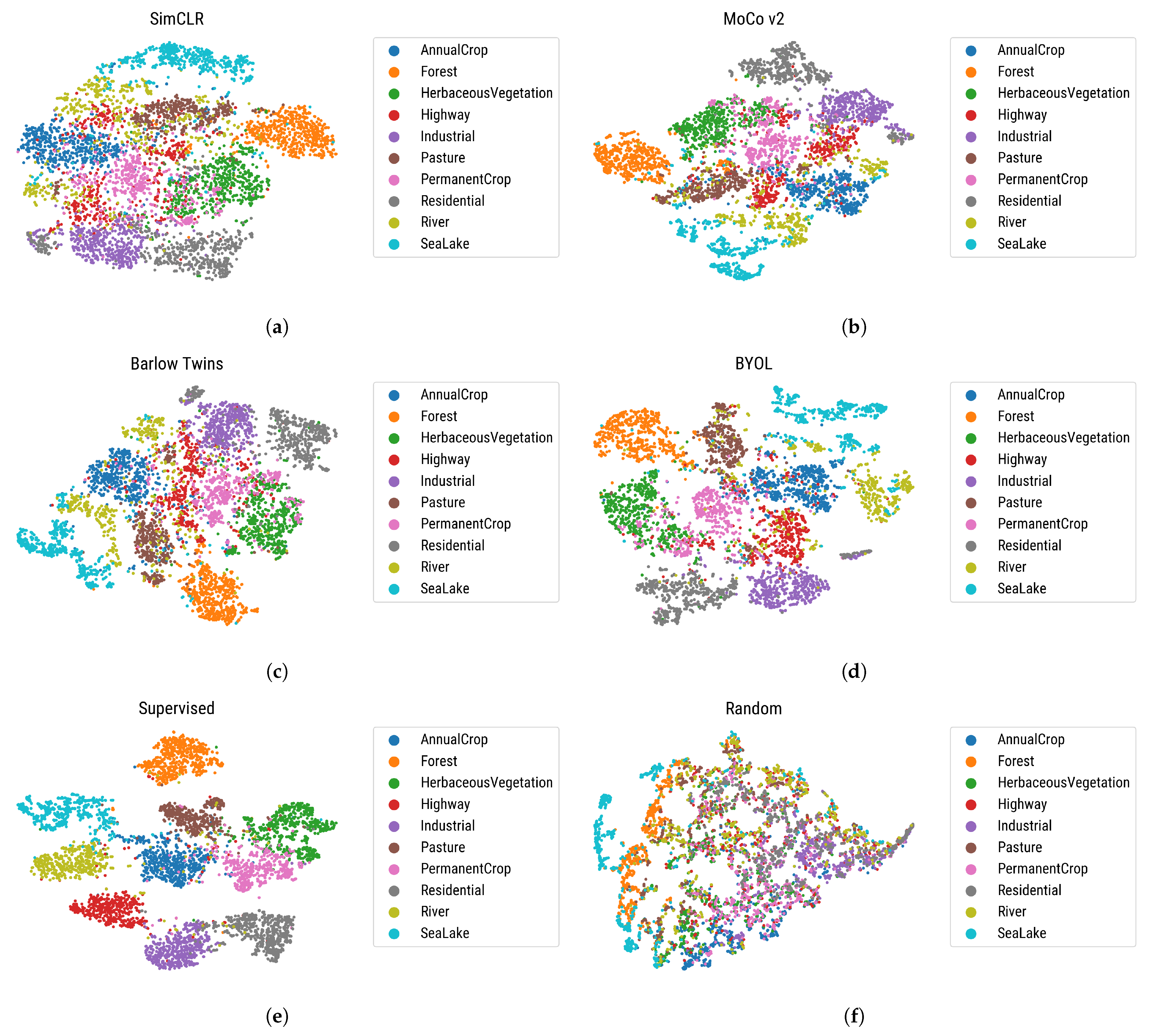
| Figure 12 | SimCLR, MoCo-v2, BYOL, Barlow twins | EuroSAT | Visualize the pre-trained feature representations of different methods using t-SNE technique. |
| Table 5 | SimCLR, BYOL | Resisc-45, EuroSAT | Evaluate the individual impact of each commonly-used augmentation strategy in joint-embedding methods. |
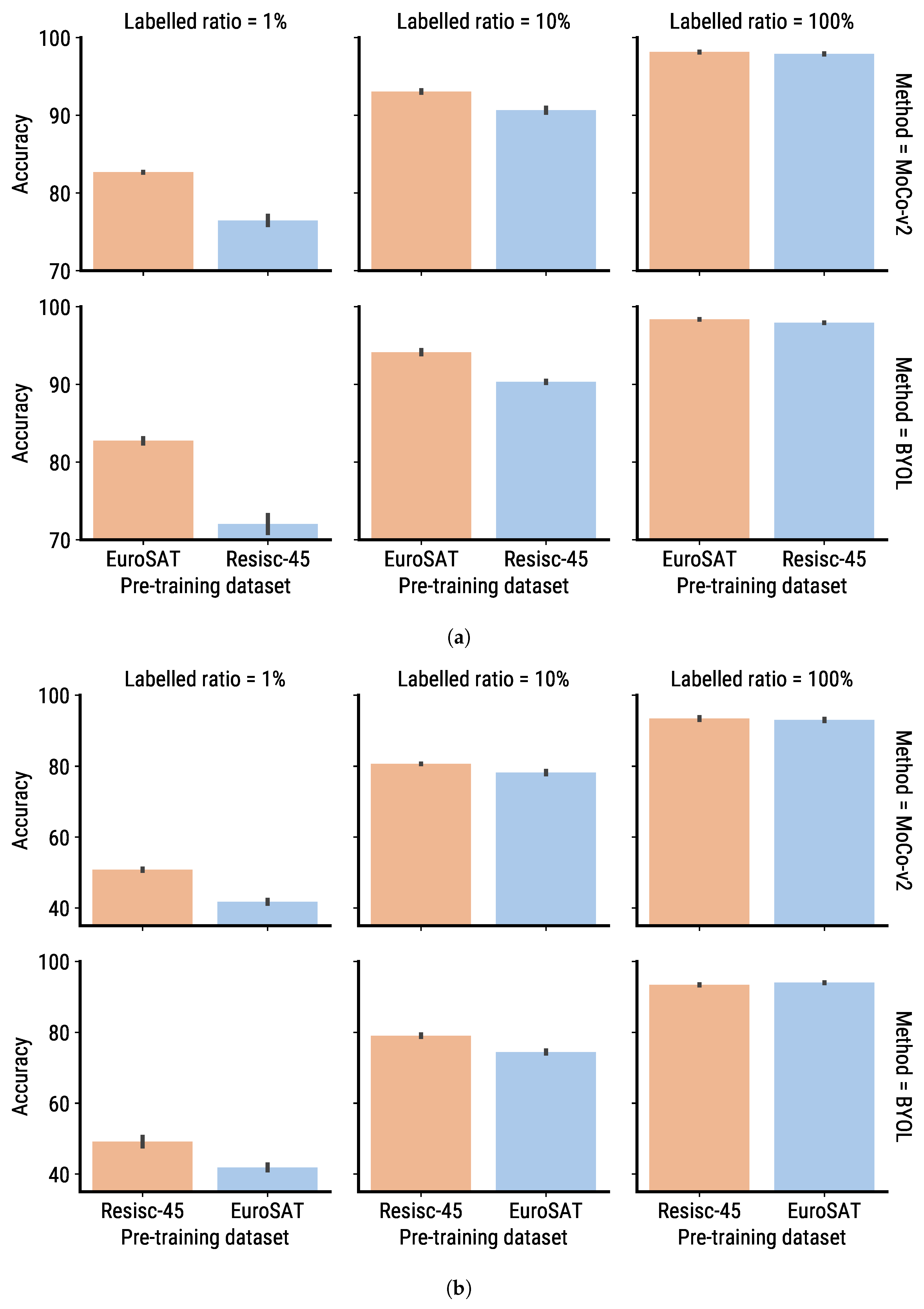
| Figure 13 | MoCo-v2, BYOL | Resisc-45, EuroSAT | Compare the fine-tuning performance using pre-trained SSL models in two scenarios where the target dataset is the same as or different to the pre-training dataset. |
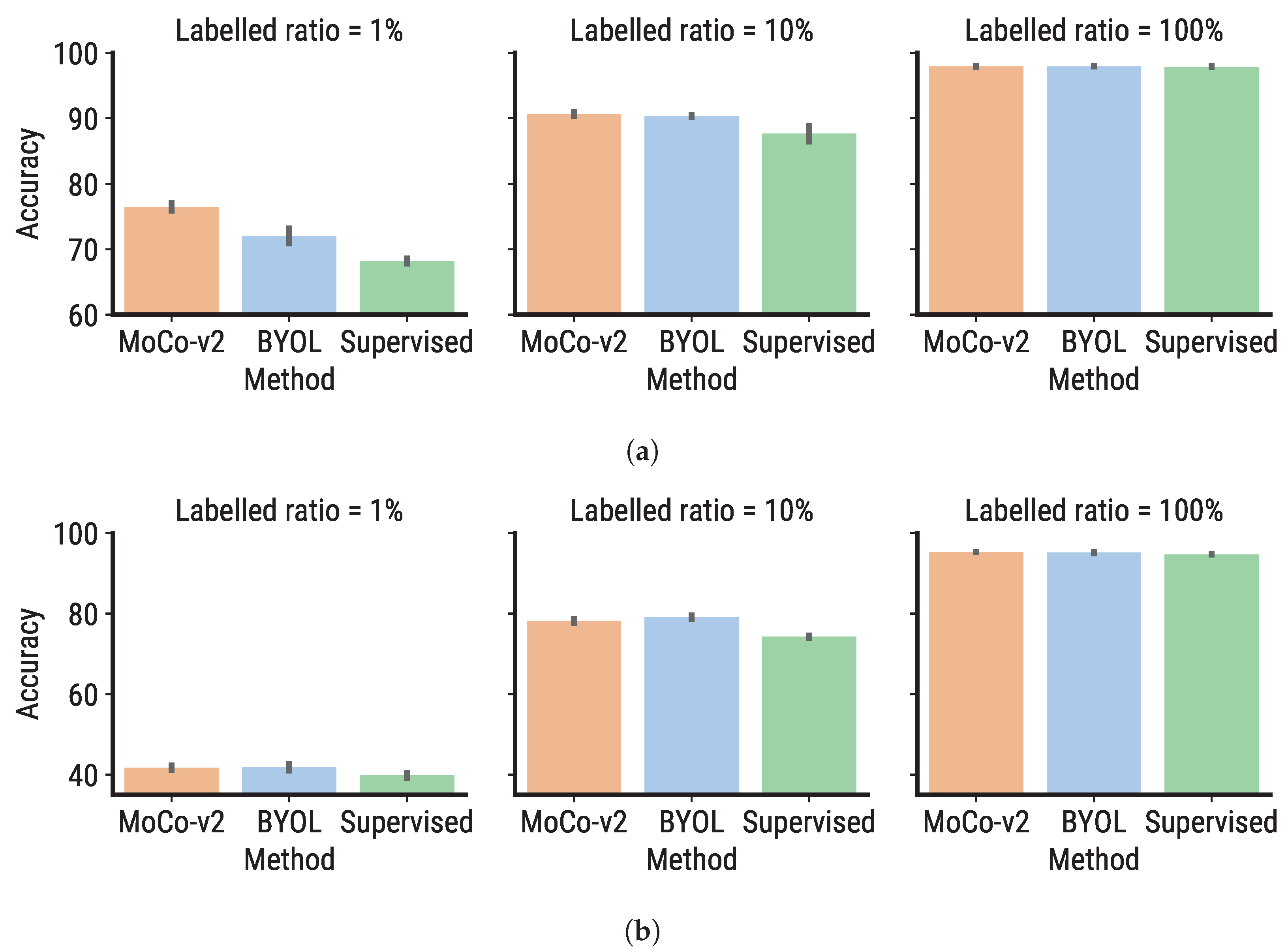
| Figure 14 | MoCo-v2, BYOL | Resisc-45, EuroSAT | Compare the fine-tuning performance of supervised and self-supervised pre-trained models in a transfer learning scenario. |
| Pre-Training Method | Resisc-45 | EuroSAT | ||
|---|---|---|---|---|
| Acc. | Acc. | |||
| Random initialization | 45.65 ± 0.84 | 43.43 ± 0.89 | 63.48 ± 0.16 | 59.33 ± 0.19 |
| ImageNet supervised | 90.32 ± 0.00 | 89.93 ± 0.00 | 94.46 ± 0.00 | 93.84 ± 0.00 |
| SimCLR [39] | 82.55 ± 0.68 | 81.84 ± 0.71 | 92.59 ± 0.05 | 91.76 ± 0.05 |
| MoCo-v2 [67] | 85.37 ± 0.15 | 84.78 ± 0.15 | 93.78 ± 0.07 | 93.08 ± 0.08 |
| BYOL [44] | 85.13 ± 0.07 | 84.52 ± 0.31 | 94.92 ± 0.12 | 94.34 ± 0.13 |
| Barlow Twins [48] | 83.14 ± 0.30 | 82.44 ± 0.31 | 95.59 ± 0.17 | 95.08 ± 0.19 |
| Pre-Training Method | Resisc-45 | EuroSAT | ||||
|---|---|---|---|---|---|---|
| 1% | 10% | 100% | 1% | 10% | 100% | |
| Random initialization | 32.39 ± 0.69 | 67.68 ± 0.39 | 91.05 ± 0.32 | 53.64 ± 0.38 | 76.76 ± 0.67 | 96.49 ± 0.03 |
| ImageNet supervised | 58.79 ± 0.29 | 89.27 ± 0.28 | 96.75 ± 0.03 | 85.62 ± 0.21 | 95.43 ± 0.11 | 98.70 ± 0.02 |
| SimCLR [39] | 41.14 ± 0.94 | 78.22 ± 0.25 | 93.01 ± 0.32 | 77.46 ± 0.38 | 92.04 ± 0.15 | 97.62 ± 0.05 |
| MoCo-v2 [67] | 50.83 ± 0.39 | 80.71 ± 0.16 | 93.45 ± 0.38 | 82.67 ± 0.06 | 93.06 ± 0.18 | 98.15 ± 0.07 |
| BYOL [44] | 49.30 ± 1.64 | 78.92 ± 0.11 | 93.39 ± 0.20 | 82.74 ± 0.43 | 94.15 ± 0.35 | 98.36 ± 0.04 |
| Barlow Twins [48] | 42.85 ± 1.25 | 73.42 ± 0.94 | 95.03 ± 0.26 | 81.60 ± 0.41 | 93.14 ± 0.12 | 96.52 ± 0.10 |
| Pre-Training Method | Augmentations | Resisc-45 | EuroSAT | |||||
|---|---|---|---|---|---|---|---|---|
| Gray Scale | Color Jitter | Flip | Crop | Acc. | Impr. | Acc. | Impr. | |
| SimCLR [39] | ✓ | 46.14 | - | 50.52 | - | |||
| ✓ | ✓ | 60.71 | +14.60 | 61.50 | +10.98 | |||
| ✓ | ✓ | ✓ | 67.79 | +7.07 | 65.94 | +4.44 | ||
| ✓ | ✓ | ✓ | ✓ | 83.05 | +15.27 | 91.52 | +25.57 | |
| BYOL [44] | ✓ | 40.74 | - | 61.52 | - | |||
| ✓ | ✓ | 45.41 | +4.67 | 64.19 | +2.67 | |||
| ✓ | ✓ | ✓ | 54.08 | +8.67 | 77.24 | +13.06 | ||
| ✓ | ✓ | ✓ | ✓ | 85.40 | +31.31 | 94.54 | +17.30 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Berg, P.; Pham, M.-T.; Courty, N. Self-Supervised Learning for Scene Classification in Remote Sensing: Current State of the Art and Perspectives. Remote Sens. 2022, 14, 3995. https://doi.org/10.3390/rs14163995
Berg P, Pham M-T, Courty N. Self-Supervised Learning for Scene Classification in Remote Sensing: Current State of the Art and Perspectives. Remote Sensing. 2022; 14(16):3995. https://doi.org/10.3390/rs14163995
Chicago/Turabian StyleBerg, Paul, Minh-Tan Pham, and Nicolas Courty. 2022. "Self-Supervised Learning for Scene Classification in Remote Sensing: Current State of the Art and Perspectives" Remote Sensing 14, no. 16: 3995. https://doi.org/10.3390/rs14163995