
GF-Detection: Fusion with GAN of Infrared and Visible Images for Vehicle Detection at Nighttime


Abstract
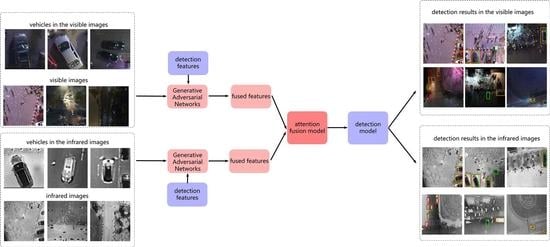
:
1. Introduction
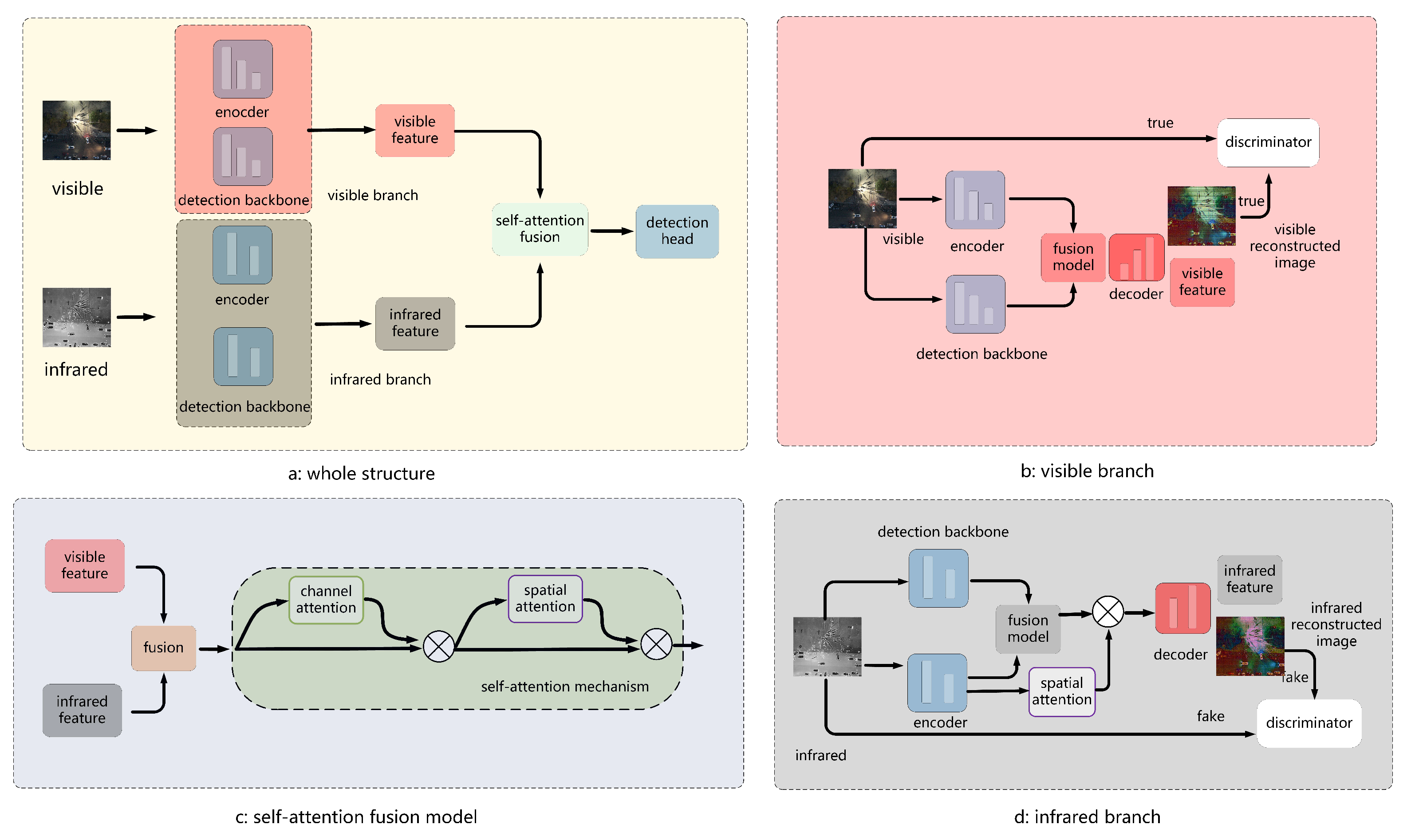
- Aiming to fuse the visible and infrared images effectively besides the feature extraction by convolutions, Generative Adversarial Networks (GAN) is introduced into the fusion model for vehicle detection at nighttime. Image fusion is conducted via the image reconstruction.Visible and infrared branch are included, and each branch contains a GAN for image fusion. Visible branch transfers the visible images to the infrared images via GAN and infrared branch converts the infrared images to the visible images via GAN. Compared with other fusion models without GAN, fusion models with GAN could exploit more features for image fusion.
- In order to enhance the detection features in reconstructed images, detection features are added to the GAN module. The detection features optimize the image generation directly. Two detection features extracted from the visible and infrared images are added into the generator of the GAN. Compared with the detection branches, the detection features are more effective for vehicle detection without extra burden introduced.
- To extract features of the visible and infrared images with different characters, various structures of the visible branch and infrared branch are designed in the subbranch. Many convolution layers exist in the encoder, detection backbone and decoder in the visible branch, while a few convolution layers exist in the encoder, detection backbone and decoder in the infrared branch. The different feature extraction strategies are suitable for the feature extraction of different source images.
- In order to improve the fusion performance with limited augment of complexity, a self-attention fusion model is employed as the second fusion model. With the channel and spatial attention map learned from the fusion features, more effective fusion features are exploited for vehicle detection tasks. Self-attention fusion model behind the visible and infrared branches could enhance the fusion performance with few parameters increased.
- A vehicle dataset containing paired infrared and visible images at nighttime are collected and labeled as a vehicle dataset for the fusion study of infrared and visible images.
2. Related Works
2.1. Vehicle Datasets in Nighttime
2.2. Vehicle Detection in Nighttime
2.3. GAN for Image Fusion of Infrared and Visible Images
3. Method
3.1. Visible Branch
3.2. Infrared Branch
3.3. Self-Attention Fusion Model
3.4. Detection Model
3.5. Total Loss Function
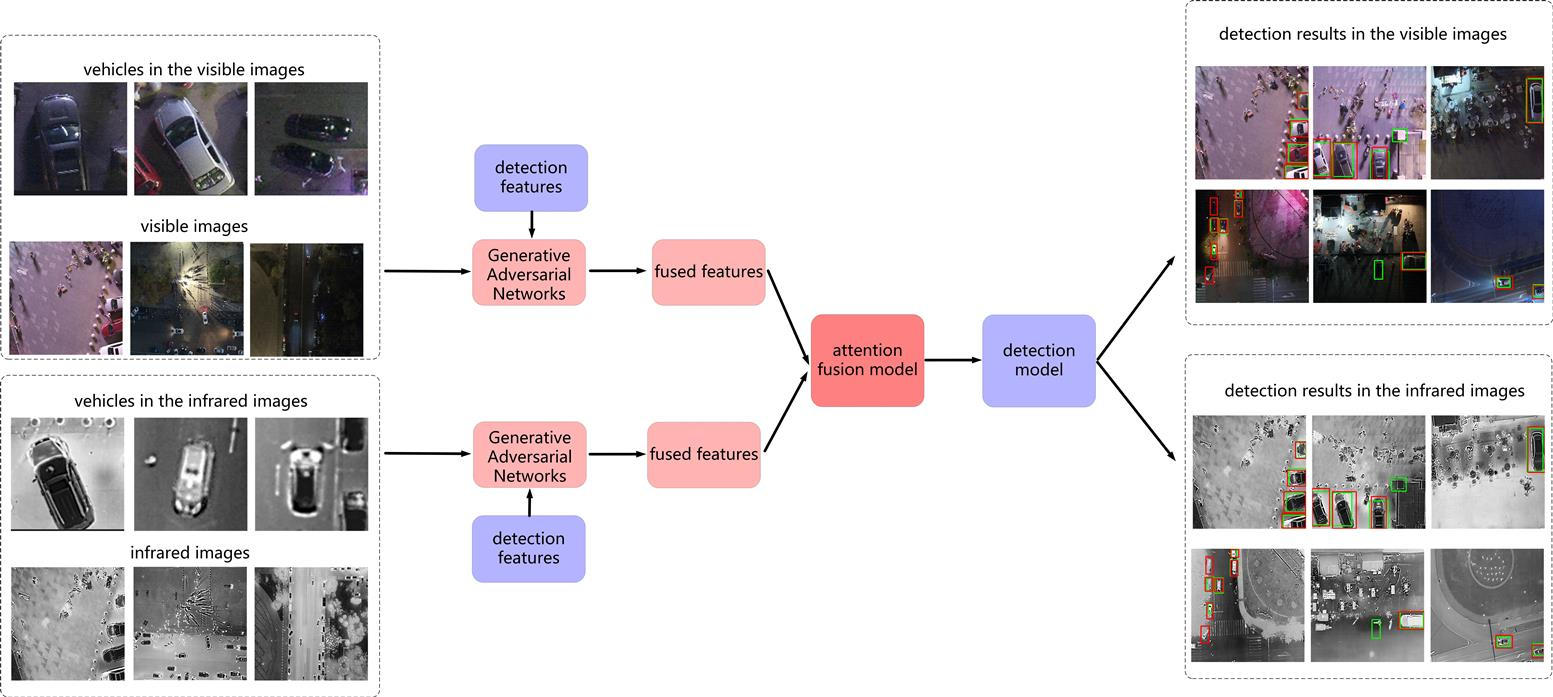
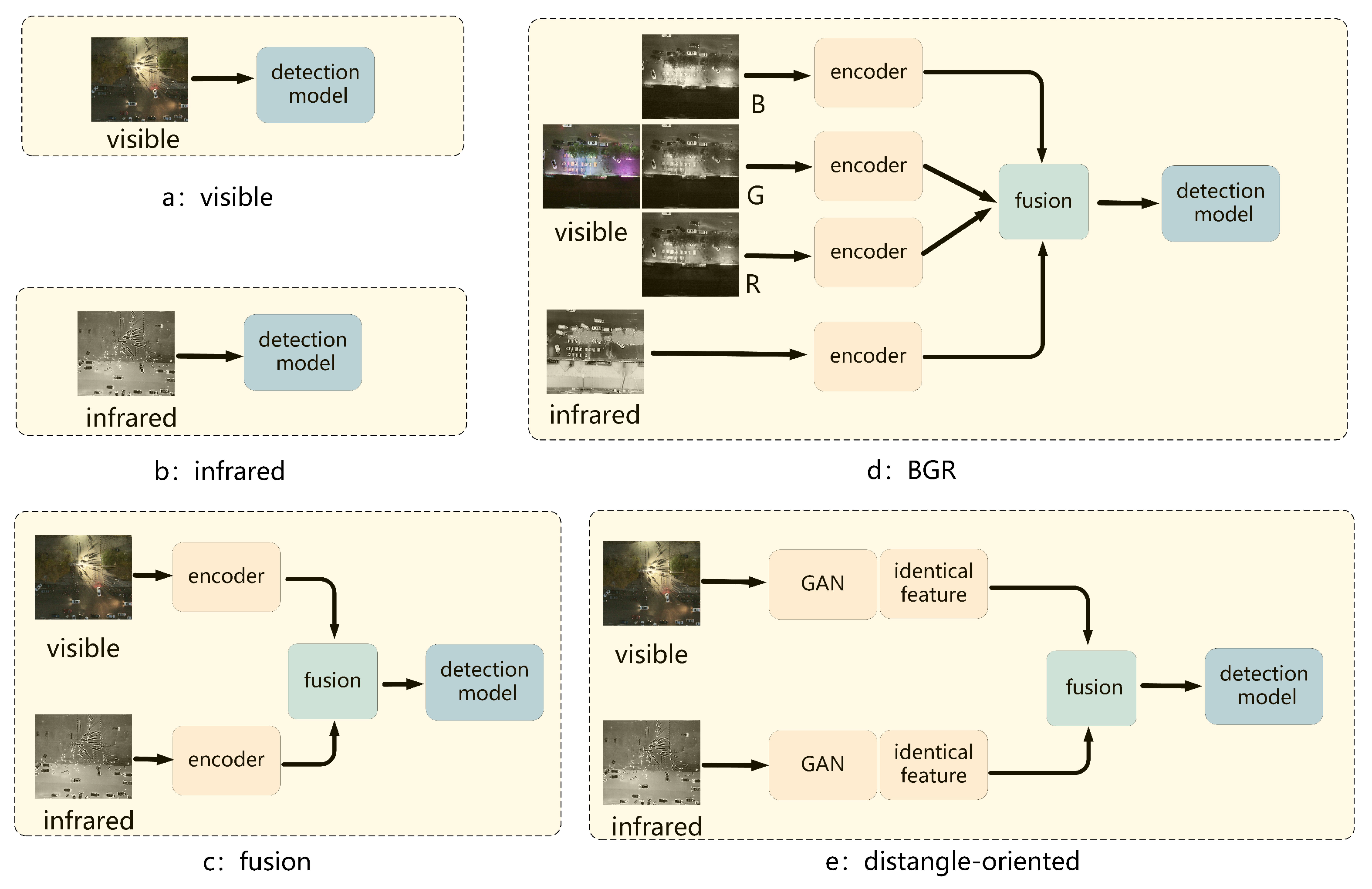
4. Experiment and Discussion
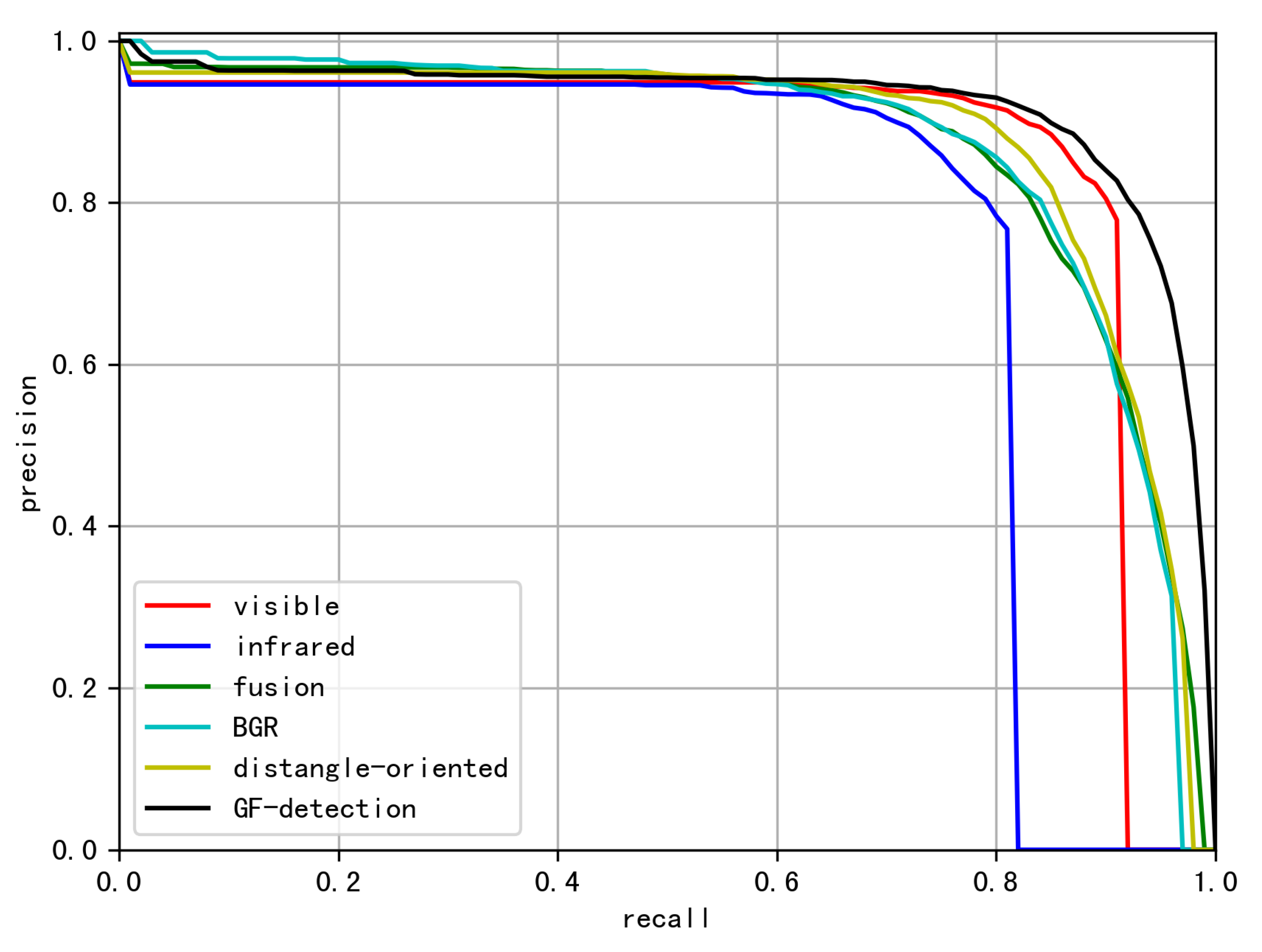
4.1. Experiments on RGBT-Vehicle
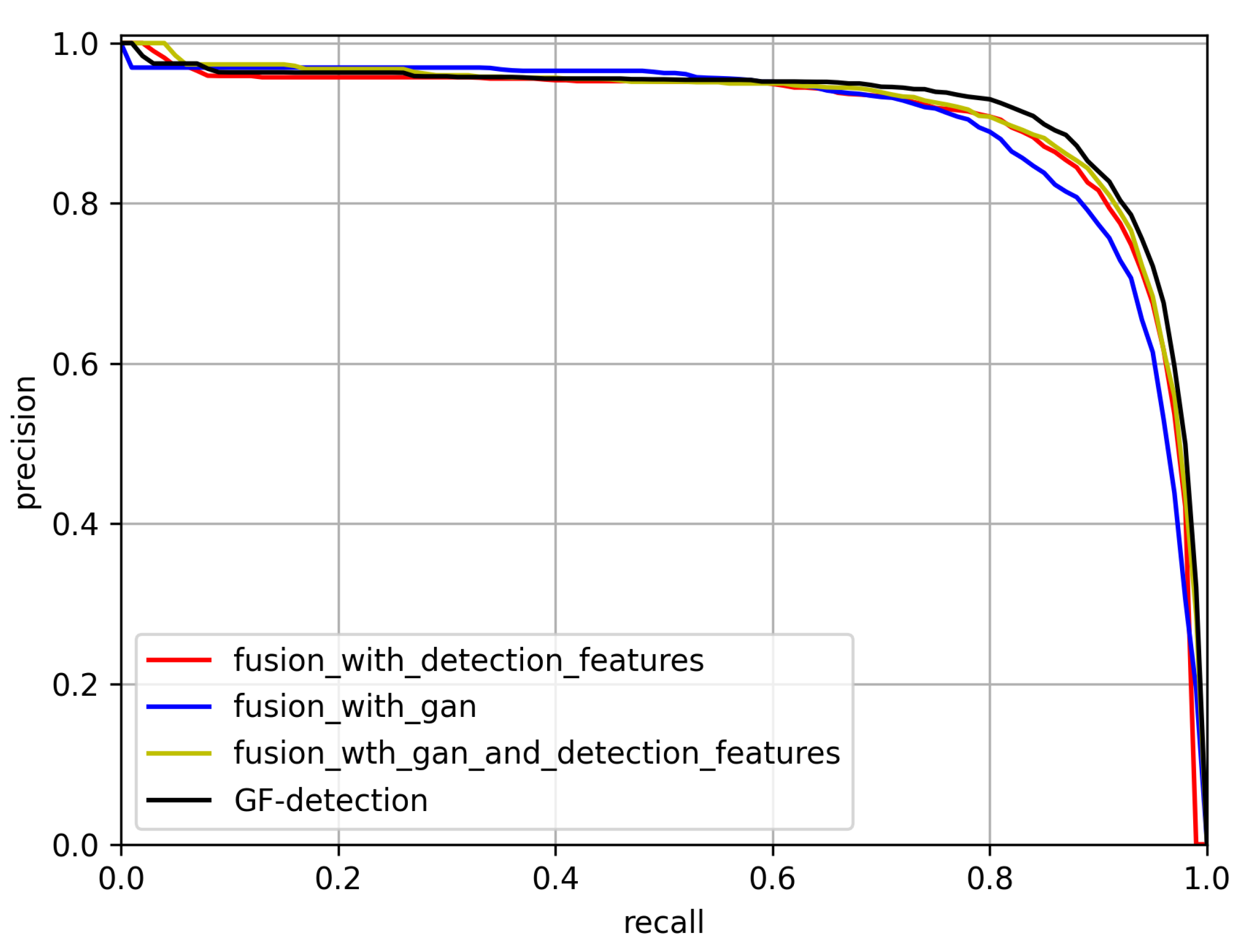
4.2. Ablation Study
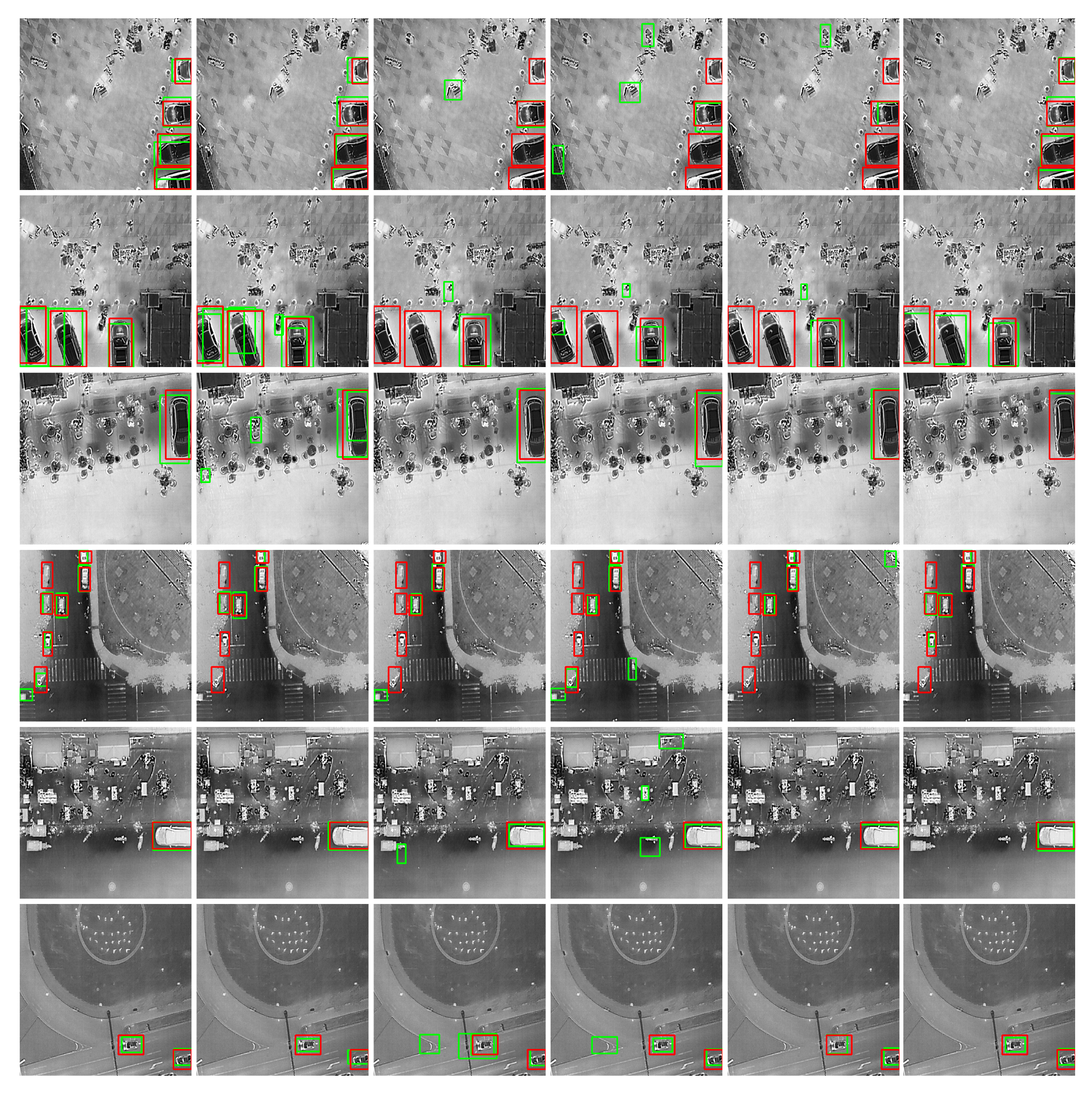
4.3. Images Reconstructed by GAN
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| GAN | Generative Adversarial Networks |
| GF-detection | fusion model with GAN for vehicle detection task |
| IoU | intersection over Union |
| PR-Curve | precision and recall curve |
References
- Lin, T.; Rivano, H.; Le Mouël, F. A survey of smart parking solutions. IEEE Trans. Intell. Transp. Syst. 2017, 18, 3229–3253. [Google Scholar] [CrossRef] [Green Version]
- Peng, H.; Zhang, Y.; Yang, S.; Song, B. Battlefield image situational awareness application based on deep learning. IEEE Intell. Syst. 2019, 35, 36–43. [Google Scholar] [CrossRef]
- Mandal, M.; Shah, M.; Meena, P.; Devi, S.; Vipparthi, S.K. AVDNet: A Small-Sized Vehicle Detection Network for Aerial Visual Data. IEEE Geosci. Remote Sens. Lett. 2020, 17, 494–498. [Google Scholar] [CrossRef] [Green Version]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef] [Green Version]
- Bozcan, I.; Kayacan, E. Au-air: A multi-modal unmanned aerial vehicle dataset for low altitude traffic surveillance. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 8504–8510. [Google Scholar]
- Liu, X.; Yang, T.; Li, J. Real-time ground vehicle detection in aerial infrared imagery based on convolutional neural network. Electronics 2018, 7, 78. [Google Scholar] [CrossRef] [Green Version]
- Shaniya, P.; Jati, G.; Alhamidi, M.R.; Caesarendra, W.; Jatmiko, W. YOLOv4 RGBT Human Detection on Unmanned Aerial Vehicle Perspective. In Proceedings of the 2021 6th International Workshop on Big Data and Information Security (IWBIS), Depok, Indonesia, 23–25 October 2021; pp. 41–46. [Google Scholar]
- Xu, H.; Wang, X.; Ma, J. DRF: Disentangled representation for visible and infrared image fusion. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Chen, J.; Li, X.; Luo, L.; Mei, X.; Ma, J. Infrared and visible image fusion based on target-enhanced multiscale transform decomposition. Inf. Sci. 2020, 508, 64–78. [Google Scholar] [CrossRef]
- Deng, C.; Liu, X.; Chanussot, J.; Xu, Y.; Zhao, B. Towards perceptual image fusion: A novel two-layer framework. Inf. Fusion 2020, 57, 102–114. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 October 2018; pp. 3–19. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems (NIPS); MIT Press Direct: Cambridge, MA, USA, 2014; Volume 27. [Google Scholar]
- Bhattacharjee, D.; Kim, S.; Vizier, G.; Salzmann, M. Dunit: Detection-based unsupervised image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4787–4796. [Google Scholar]
- Ma, S.; Fu, J.; Chen, C.W.; Mei, T. Da-gan: Instance-level image translation by deep attention generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5657–5666. [Google Scholar]
- Teutsch, M.; Muller, T.; Huber, M.; Beyerer, J. Low resolution person detection with a moving thermal infrared camera by hot spot classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 209–216. [Google Scholar]
- Ellmauthaler, A.; Pagliari, C.L.; da Silva, E.A.; Gois, J.N.; Neves, S.R. A visible-light and infrared video database for performance evaluation of video/image fusion methods. Multidimens. Syst. Signal Process. 2019, 30, 119–143. [Google Scholar] [CrossRef]
- Zhang, X.; Ye, P.; Xiao, G. VIFB: A visible and infrared image fusion benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 104–105. [Google Scholar]
- Chen, Y.; Shin, H. Multispectral image fusion based pedestrian detection using a multilayer fused deconvolutional single-shot detector. J. Opt. Soc. Am. A 2020, 37, 768–779. [Google Scholar] [CrossRef] [PubMed]
- Ding, L.; Wang, Y.; Laganière, R.; Huang, D.; Luo, X.; Zhang, H. A robust and fast multispectral pedestrian detection deep network. Knowl.-Based Syst. 2021, 227, 106990. [Google Scholar] [CrossRef]
- Takumi, K.; Watanabe, K.; Ha, Q.; Tejero-De-Pablos, A.; Ushiku, Y.; Harada, T. Multispectral object detection for autonomous vehicles. In Proceedings of the on Thematic Workshops of ACM Multimedia 2017, Mountain View, CA, USA, 23–27 October 2017; pp. 35–43. [Google Scholar]
- Xiao, X.; Wang, B.; Miao, L.; Li, L.; Zhou, Z.; Ma, J.; Dong, D. Infrared and visible image object detection via focused feature enhancement and cascaded semantic extension. Remote Sens. 2021, 13, 2538. [Google Scholar] [CrossRef]
- Zhang, Y.; Yin, Z.; Nie, L.; Huang, S. Attention based multi-layer fusion of multispectral images for pedestrian detection. IEEE Access 2020, 8, 165071–165084. [Google Scholar] [CrossRef]
- Li, C.; Song, D.; Tong, R.; Tang, M. Illumination-aware faster R-CNN for robust multispectral pedestrian detection. Pattern Recognit. 2019, 85, 161–171. [Google Scholar] [CrossRef] [Green Version]
- Guan, D.; Cao, Y.; Yang, J.; Cao, Y.; Yang, M.Y. Fusion of multispectral data through illumination-aware deep neural networks for pedestrian detection. Inf. Fusion 2019, 50, 148–157. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Li, J.; Huo, H.; Li, C.; Wang, R.; Feng, Q. AttentionFGAN: Infrared and visible image fusion using attention-based generative adversarial networks. IEEE Trans. Multimed. 2020, 23, 1383–1396. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Xu, M.; Zhang, H.; Xiao, G. STDFusionNet: An infrared and visible image fusion network based on salient target detection. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Submodule | Parameters |
|---|---|---|
| generator | encoder | Conv(1,3,7,2,0)+maxpooling, |
| Conv(3,64,4,2,1)+BatchNorm2d, | ||
| Conv(64,128,4,2,1)+BatchNorm2d, | ||
| Conv(128,256,4,2,1)+BatchNorm2d, | ||
| Conv(256,512,4,2,1)+BatchNorm2d | ||
| decoder | Convtranspose(512,256,4,2,1)+BatchNorm2d, | |
| Convtranspose(256,128,4,2,1)+BatchNorm2d, | ||
| Convtranspose(128,64,4,2,1)+BatchNorm2d, | ||
| Convtranspose(64,3,4,2,1)+BatchNorm2d, | ||
| uppooling | ||
| discriminator | encoder | Conv(3,64,7,2,0)+maxpooling, |
| Conv(64,128,4,2,1)+BatchNorm2d+LeakyReLU, | ||
| Conv(128,256,4,2,1)+BatchNorm2d+LeakyReLU, | ||
| Conv(256,512,4,2,1)+BatchNorm2d+LeakyReLU, | ||
| FC(204800,4096) | ||
| fusion | encoder | Conv(3,64,7,2,0)+maxpooling, |
| Conv(64,256, 7,2,0)+BatchNorm2d+LeakyReLU, | ||
| Conv(256,512, 7,2,0)+BatchNorm2d+LeakyReLU, | ||
| Conv(512,1024, 7,2,0)+BatchNorm2d+LeakyReLU, | ||
| Conv(1024,2048,7,2,0)+BatchNorm2d+LeakyReLU | ||
| fusion | Conv(512,512, 3,1,1)+BatchNorm2d+LeakyReLU, | |
| Conv(1024,1024,3,1,1)+BatchNorm2d+LeakyReLU, | ||
| Conv(2048,2048,3,1,1)+BatchNorm2d+LeakyReLU | ||
| decoder | Convtranspose(2048,1024,3,2,1)+BatchNorm2d+LeakyReLU, | |
| Convtranspose(1024,512,4,2,1)+BatchNorm2d+LeakyReLU, | ||
| Convtranspose(512,256,4,2,1)+BatchNorm2d+LeakyReLU, | ||
| Convtranspose(256,64,4,2,1)+BatchNorm2d+LeakyReLU, | ||
| Convtranspose(64,3,4,2,1)+BatchNorm2d+LeakyReLU, | ||
| uppooling | ||
| Self-attention fusion model | channel attention model | AdaptiveAvgPool2d+FC(512,32)+LeakyReLU+ Conv(32,512,1,1) |
| AdaptiveMaxPool2d+FC(512,32)+LeakyReLU+ Conv(32,512,1,1)+Sigmoid() | ||
| spatial attention model | torch.mean+torch.max+Conv(2,1,7,1,1)+Sigmoid() | |
| RetinaNet | RetinaNet with ResNet(50) | |
| Fusion Model | Precision | Recall | F1 |
|---|---|---|---|
| visible | 71.0 | 81.0 | 75.6 |
| infrared | 60.2 | 72.4 | 65.8 |
| fusion | 81.3 | 92.6 | 86.5 |
| BGR | 81.0 | 90.4 | 85.4 |
| distangle-oriented | 82.9 | 92.3 | 87.3 |
| GF-detection(ours) | 86.7 | 94.4 | 90.3 |
| Fusion Model | Precision | Recall | F1 |
|---|---|---|---|
| fusion with detection features | 84.6 | 92.3 | 86.5 |
| fusion with GAN | 85.1 | 94.0 | 89.3 |
| fusion with GAN and detection features | 86.0 | 94.4 | 90.0 |
| GF-detection (ours) | 86.7 | 94.4 | 90.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, P.; Tian, T.; Zhao, T.; Li, L.; Zhang, N.; Tian, J. GF-Detection: Fusion with GAN of Infrared and Visible Images for Vehicle Detection at Nighttime. Remote Sens. 2022, 14, 2771. https://doi.org/10.3390/rs14122771
Gao P, Tian T, Zhao T, Li L, Zhang N, Tian J. GF-Detection: Fusion with GAN of Infrared and Visible Images for Vehicle Detection at Nighttime. Remote Sensing. 2022; 14(12):2771. https://doi.org/10.3390/rs14122771
Chicago/Turabian StyleGao, Peng, Tian Tian, Tianming Zhao, Linfeng Li, Nan Zhang, and Jinwen Tian. 2022. "GF-Detection: Fusion with GAN of Infrared and Visible Images for Vehicle Detection at Nighttime" Remote Sensing 14, no. 12: 2771. https://doi.org/10.3390/rs14122771