
ECAP-YOLO: Efficient Channel Attention Pyramid YOLO for Small Object Detection in Aerial Image



Abstract
:1. Introduction
2. Related Work
2.1. YOLO Series
2.2. Attention Module
3. Proposed Methods
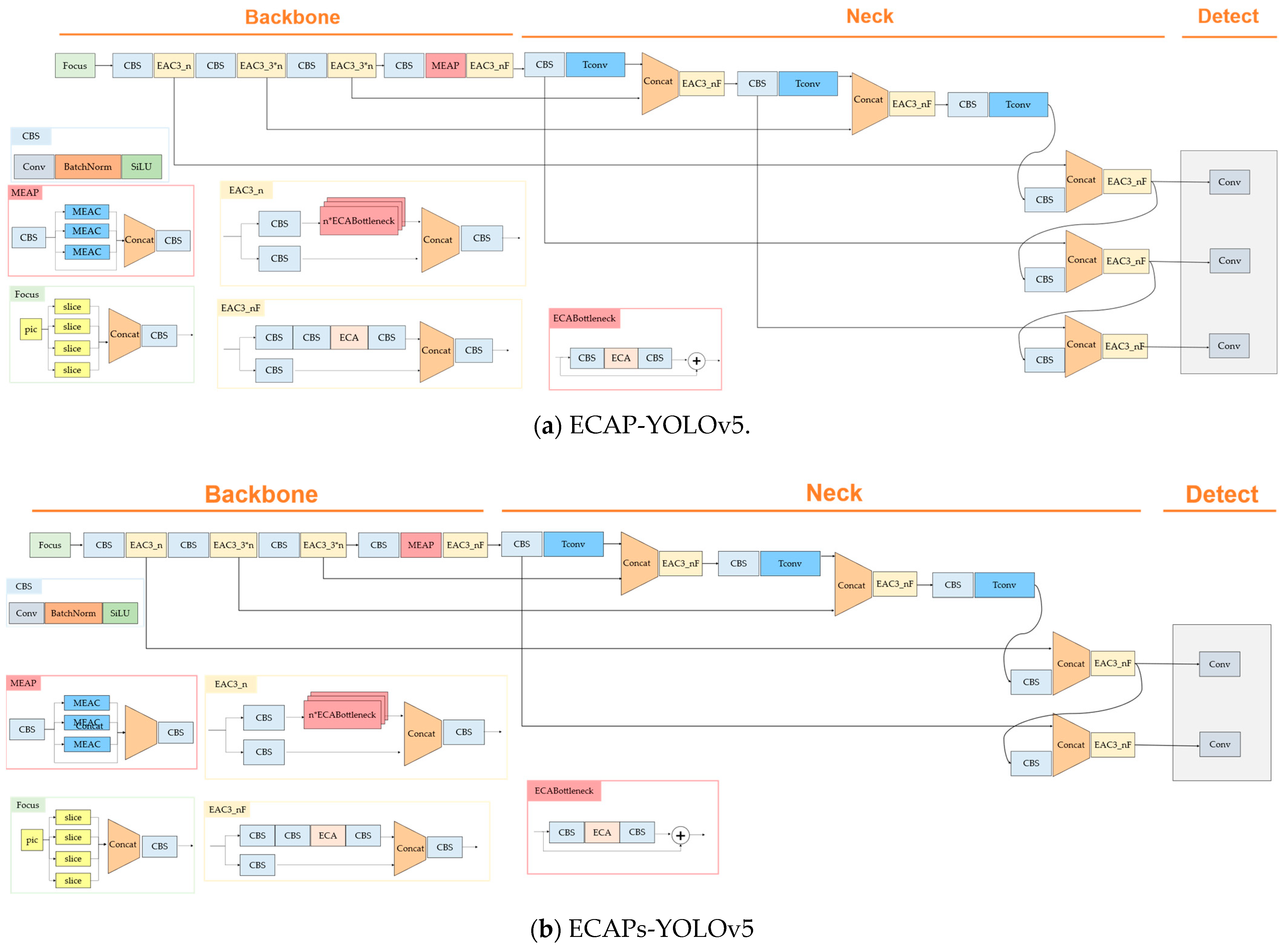
3.1. Proposed Method Overview
3.2. Using Transposed Convolution
3.3. Efficient Channel Attention Applied
3.4. Efficient Channel Attention Pyramid
3.5. Change Detect Layer
4. Experimental Results and Discussion
4.1. VEDAI Dataset
4.2. xView Dataset
4.3. DOTA Dataset
4.4. Arirang Dataset
4.5. Discussion
5. Conclusions and Future Works
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2020), Washington, DC, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Doll, Z.; Lawrence, C. Microsoft coco: Common objects in context. In Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 1–6 September 2014. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef] [Green Version]
- Lam, D.; Kuzma, R.; McGee, K.; Dooley, S.; Laielli, M.; Klaric, M.; Bulatov, Y.; McCord, B. Xview: Objects in context in overhead imagery. arXiv 2018, arXiv:1802.07856. [Google Scholar]
- Arirang Satellite Image AI Object Detection Contest. Available online: https://dacon.io/competitions/open/235644/overview/description (accessed on 25 June 2021).
- Wang, Q.L.; Wu, B.G.; Zhu, P.F.; Li, P.H.; Zuo, W.M.; Hu, Q.H. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Dumoulin, V.; Visin, F. A guide to convolution arithmetic for deep learning. arXiv 2016, arXiv:1603.07285. [Google Scholar]
- Rukundo, O.; Cao, H. Nearest neighbor value interpolation. arXiv 2012, arXiv:1211.1768. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Zhang, Z.; Sabuncu, M.R. Generalized cross entropy loss for training deep neural networks with noisy labels. In Proceedings of the 32nd Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Zhang, Z.; He, T.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of freebies for training object detection neural networks. arXiv 2019, arXiv:1902.04103. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Yao, Z.; Cao, Y.; Zheng, S.; Huang, G.; Lin, S. Cross-iteration batch normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 12331–12340. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y. You only learn one representation: Unified network for multiple tasks. arXiv 2021, arXiv:2105.04206. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision (%) | Recall (%) | F1-Score | mAP50 | mAP50:95 |
|---|---|---|---|---|---|
| YOLOv5l | 50.3 | 64.4 | 56.5 | 52.5 | 27.6 |
| YOLOv5l + 1 more Layer + XS, S, L, XL detect | 60.1 | 51.4 | 55.4 | 51.4 | 29.5 |
| YOLOv5l + 1 more Layer + XS, S, L detect | 63.3 | 53.4 | 57.9 | 55.5 | 29.8 |
| YOLOV5l + 1 more Layer + XS, S detect | 62.0 | 52.8 | 57.0 | 52.8 | 26.8 |
| Model | Precision (%) | Recall (%) | F1-Score (%) | mAP50 (%) | mAP50:95(%) |
|---|---|---|---|---|---|
| YOLOv5l | 50.3 | 64.4 | 56.5 | 52.5 | 27.6 |
| YOLOv5l + EAC31 | 66.6 | 46.5 | 54.8 | 51.4 | 28.2 |
| YOLOv5l + EAC32 | 61.7 | 55.8 | 58.6 | 56.3 | 33.1 |
| YOLOv5l + EAC33 | 57.6 | 55.9 | 56.7 | 52.9 | 28.7 |
| YOLOv5l + EAC34 | 73.0 | 49.9 | 59.27 | 56.4 | 29.5 |
| Model | Precision (%) | Recall (%) | F1-Score (%) | mAP50 (%) | mAP50:95 (%) |
|---|---|---|---|---|---|
| YOLOv5l | 50.3 | 64.4 | 56.5 | 52.5 | 27.6 |
| YOLOv5l + EAP | 59.2 | 57.9 | 58.5 | 56.0 | 31.5 |
| YOLOv5l + AEAP | 53.5 | 63.9 | 58.2 | 56.2 | 31.2 |
| YOLOv5l + AEAP2 | 61.0 | 54.1 | 57.34 | 54.0 | 30.8 |
| YOLOv5l + MEAP | 65.2 | 51.9 | 58.0 | 54.2 | 29.6 |
| Model | Precision (%) | Recall (%) | F1-Score (%) | mAP50 (%) | mAP50:95 (%) |
|---|---|---|---|---|---|
| YOLOv5l | 50.3 | 64.4 | 56.5 | 52.5 | 27.6 |
| YOLOv5x | 64.0 | 52.7 | 57.8 | 55.9 | 30.8 |
| YOLOv5l + Tconv | 65.4 | 52.1 | 58.0 | 56.8 | 31.9 |
| ECAPs-YOLOv5l (EAP) | 63 | 47.7 | 54.3 | 52.6 | 29.4 |
| ECAPs-YOLOv5l (AEAP) | 62.8 | 60.1 | 61.4 | 55.8 | 32.4 |
| ECAPs-YOLOv5l | 64.6 | 51.4 | 57.2 | 56 | 31.5 |
| ECAP-YOLOv5l | 71.6 | 52.9 | 60.8 | 58.7 | 34.5 |
| Model | All (%) | Cars (%) | Trucks (%) | Pickups (%) | Tractors (%) | Campers (%) | Boats (%) | Vans (%) | Planes (%) | Other (%) |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5l | 52.5 | 79.5 | 43.3 | 66.2 | 63.2 | 53.3 | 26.4 | 45.1 | 63.4 | 32.1 |
| YOLOv5x | 55.9 | 83.6 | 59.4 | 67.6 | 62.8 | 49.8 | 24.3 | 53.5 | 61.5 | 40.7 |
| YOLOv5l + Tconv | 56.8 | 83.6 | 50.1 | 67.3 | 56.2 | 53.4 | 31.7 | 54.7 | 78.5 | 36.0 |
| ECAPs-YOLOv5l (EAP) | 52.6 | 83.8 | 34.3 | 74.1 | 47.2 | 52.9 | 33.7 | 30.2 | 92.0 | 25.4 |
| ECAPs-YOLOv5l (AEAP) | 55.8 | 86.7 | 30 | 75.6 | 72 | 61.3 | 25.3 | 54.7 | 75.9 | 20.8 |
| ECAPs-YOLOv5l | 56 | 85.5 | 40.4 | 74.8 | 61.8 | 54.7 | 32.7 | 39.8 | 90.1 | 23.9 |
| ECAP-YOLOv5l | 58.7 | 85.6 | 52 | 77 | 62.7 | 50.3 | 35 | 47.8 | 91 | 27.2 |
| Model | Precision (%) | Recall (%) | F1-Score (%) | mAP50 (%) | mAP 50:95 (%) | GFLOPs | Parameters (M) |
|---|---|---|---|---|---|---|---|
| YOLOv5l | 50.3 | 64.4 | 56.5 | 52.5 | 27.6 | 115.6 | 47.0 |
| YOLOv5x | 64.0 | 52.7 | 57.8 | 55.9 | 30.8 | 219.0 | 87.7 |
| YOLOR_CSP | 20.2 | 47.2 | 28.3 | 31.4 | 19.5 | 120.637 | 52.9 |
| YOLOR_CSP_x | 23.9 | 56.1 | 33.5 | 34.7 | 21.1 | 222.43 | 99.7 |
| YOLOX-l | 28.7 | 49.1 | 36.2 | 55.6 | 28.8 | 155.6 | 54.2 |
| YOLOX-x | 21.22 | 59.9 | 31.3 | 53.4 | 26.6 | 281.9 | 99.1 |
| ECAPs-YOLOv5l | 64.6 | 51.4 | 57.2 | 56 | 31.5 | 122.1 | 33.6 |
| ECAP-YOLOv5l | 71.6 | 52.9 | 60.8 | 58.7 | 34.5 | 132.4 | 36.8 |
| Model | Precision (%) | Recall (%) | F1-Score (%) | mAP50 (%) | mAP 50:95 (%) |
|---|---|---|---|---|---|
| YOLOv5l | 76.8 | 70.4 | 73.5 | 73.9 | 29.2 |
| YOLOv5x | 78.5 | 74.5 | 76.4 | 79.3 | 31.9 |
| ECAP-YOLOv5l | 82.0 | 78.5 | 80.2 | 81.9 | 34.6 |
| ECAPs-YOLOv5l | 83.0 | 78.8 | 80.8 | 83.3 | 35.9 |
| Model | Precision (%) | Recall (%) | F1-Score (%) | mAP50 (%) | mAP 50:95 (%) |
|---|---|---|---|---|---|
| YOLOv5l | 85.2 | 70.3 | 77.0 | 77.2 | 49.3 |
| YOLOv5x | 82.7 | 74.8 | 78.6 | 79.8 | 50.1 |
| ECAP-YOLOv5l | 80.3 | 79.3 | 79.8 | 81.5 | 52.0 |
| ECAPs-YOLOv5l | 78.8 | 79 | 78.9 | 81.1 | 51.4 |
| Model | Class | Precision (%) | Recall (%) | F1-Score (%) | mAP50 (%) | mAP 50:95 (%) |
|---|---|---|---|---|---|---|
| YOLOv5l | Car | 71.8 | 65.5 | 68.5 | 68.6 | 36.8 |
| Ship | 93.7 | 83.2 | 88.1 | 90.9 | 65.2 | |
| YOLOv5x | Car | 77.4 | 57.5 | 65.9 | 63.7 | 34.4 |
| Ship | 93.0 | 83.2 | 87.8 | 90.7 | 64.2 | |
| ECAP-YOLOv5l | Car | 65.7 | 75.1 | 70.1 | 71.6 | 38.7 |
| Ship | 94.9 | 83.5 | 88.8 | 91.4 | 65.4 | |
| ECAPs-YOLOv5l | Car | 63.6 | 76.0 | 69.2 | 71.3 | 38.3 |
| Ship | 93.9 | 81.9 | 87.5 | 90.9 | 64.5 |
| Small Cars | Trucks | Small Ships | Trains | Buses | Military Aircrafts | Oil Tankers | Others |
|---|---|---|---|---|---|---|---|
| 86,305 | 19,011 | 13,107 | 5123 | 3840 | 937 | 868 | 953 |
| Civilians | Aircrafts | Large Ships | Cranes | Helipads | Roundabouts | Bridges | Dams |
| 424 | 306 | 260 | 135 | 1131 | 93 | 40 | 3 |
| Model | Precision (%) | Recall (%) | F1-Score (%) | mAP50 (%) | mAP50:95 (%) |
|---|---|---|---|---|---|
| YOLOv5l | 65.6 | 45.7 | 53.9 | 42.8 | 15.2 |
| YOLOv5x | 66.0 | 47.2 | 55.0 | 43.8 | 15.7 |
| ECAP-YOLOv5l | 72.9 | 47.7 | 57.7 | 47.6 | 17.6 |
| ECAPs-YOLOv5l | 68.9 | 49.3 | 57.5 | 47.2 | 17.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.; Jeong, J.; Kim, S. ECAP-YOLO: Efficient Channel Attention Pyramid YOLO for Small Object Detection in Aerial Image. Remote Sens. 2021, 13, 4851. https://doi.org/10.3390/rs13234851
Kim M, Jeong J, Kim S. ECAP-YOLO: Efficient Channel Attention Pyramid YOLO for Small Object Detection in Aerial Image. Remote Sensing. 2021; 13(23):4851. https://doi.org/10.3390/rs13234851
Chicago/Turabian StyleKim, Munhyeong, Jongmin Jeong, and Sungho Kim. 2021. "ECAP-YOLO: Efficient Channel Attention Pyramid YOLO for Small Object Detection in Aerial Image" Remote Sensing 13, no. 23: 4851. https://doi.org/10.3390/rs13234851