
Synergistic Use of Geospatial Data for Water Body Extraction from Sentinel-1 Images for Operational Flood Monitoring across Southeast Asia Using Deep Neural Networks

 , and
, and
Abstract
:
1. Introduction
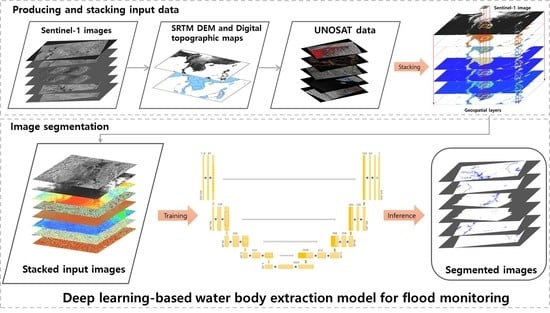
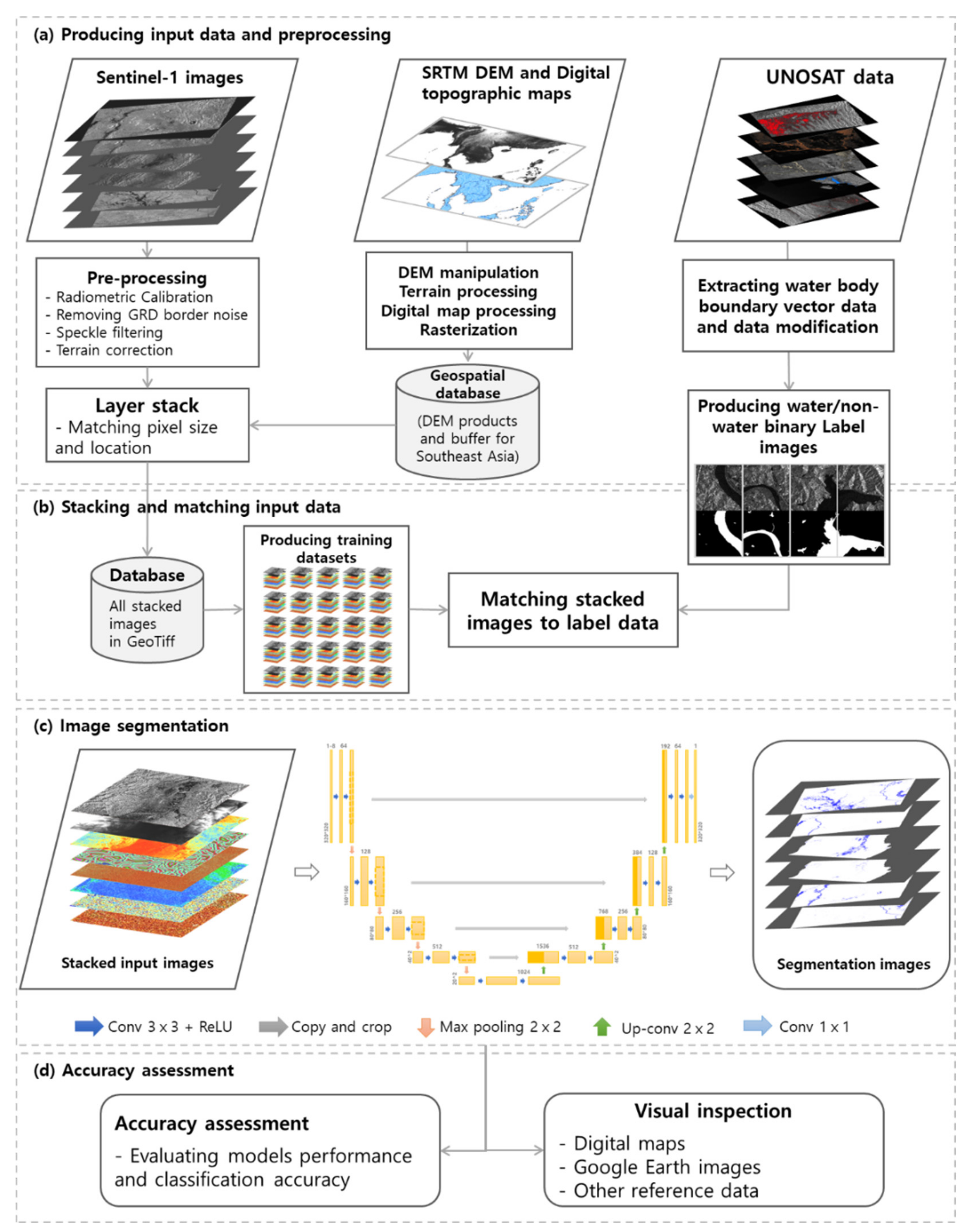
2. Producing Input Data and Geospatial Database
2.1. Pre-Processing and Modification of Input Data
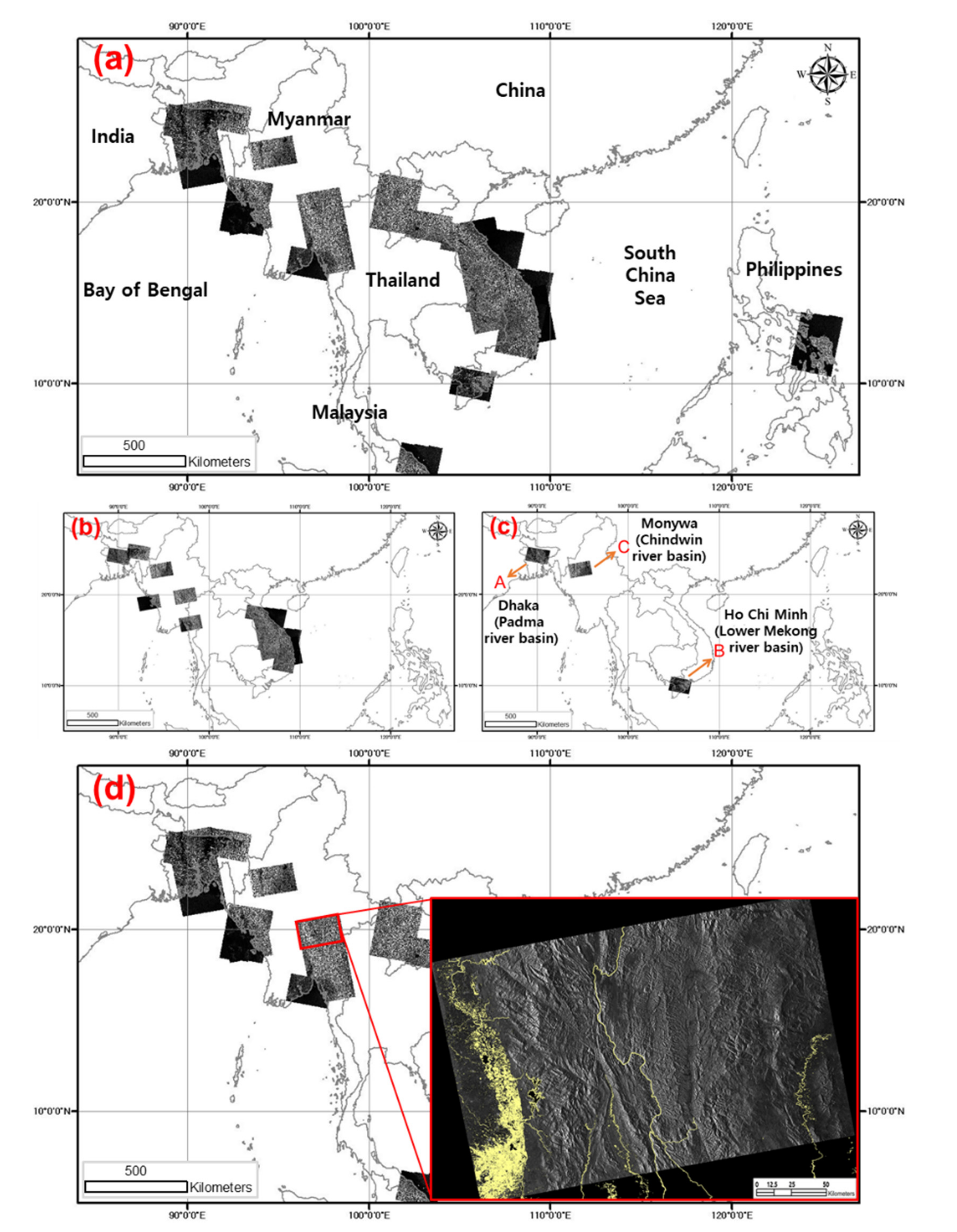
2.1.1. Sentinel-1 and Ground Truth Data for the Southeast Asia Region
2.1.2. Data Modification and Producing Label Data
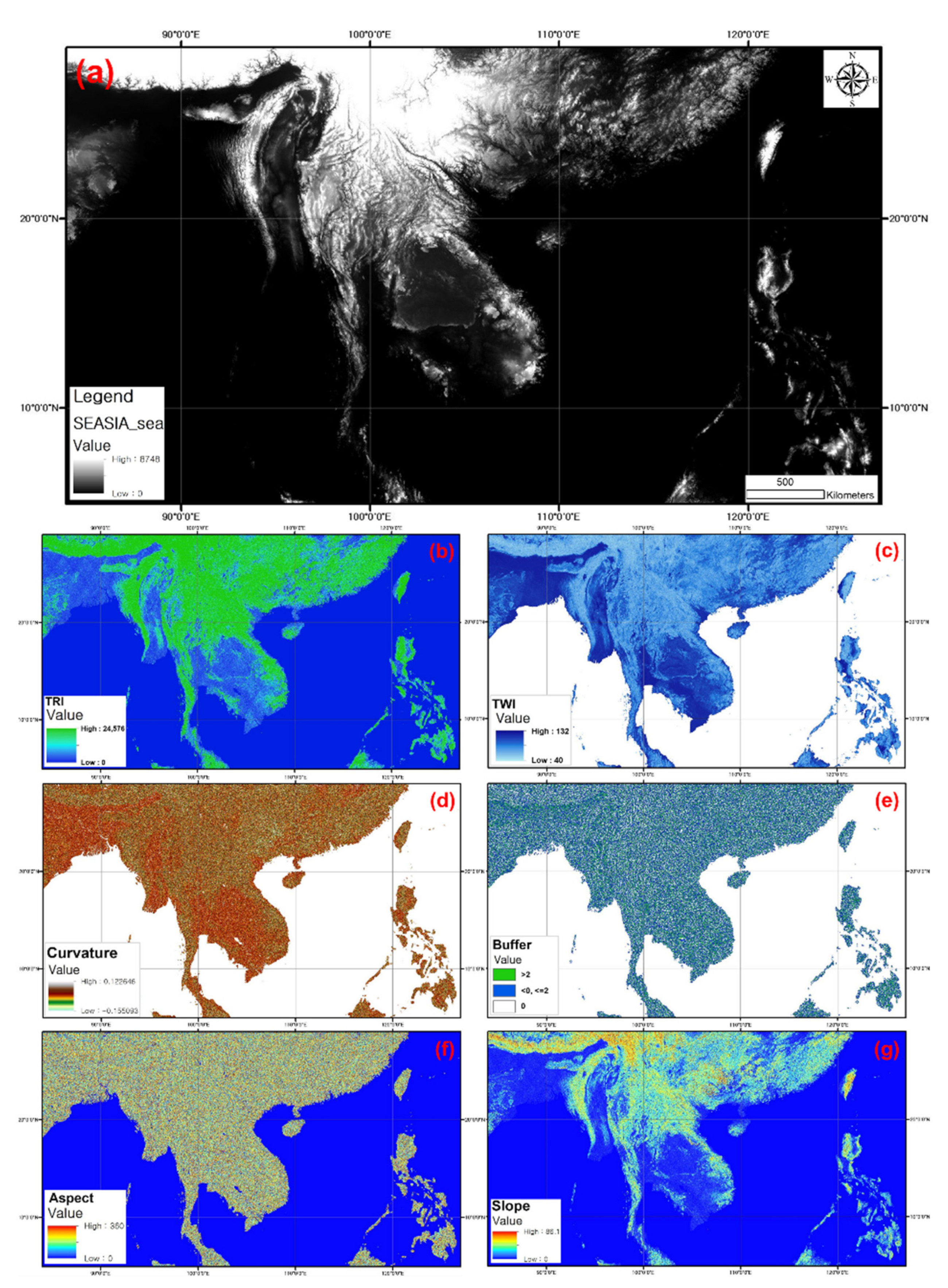
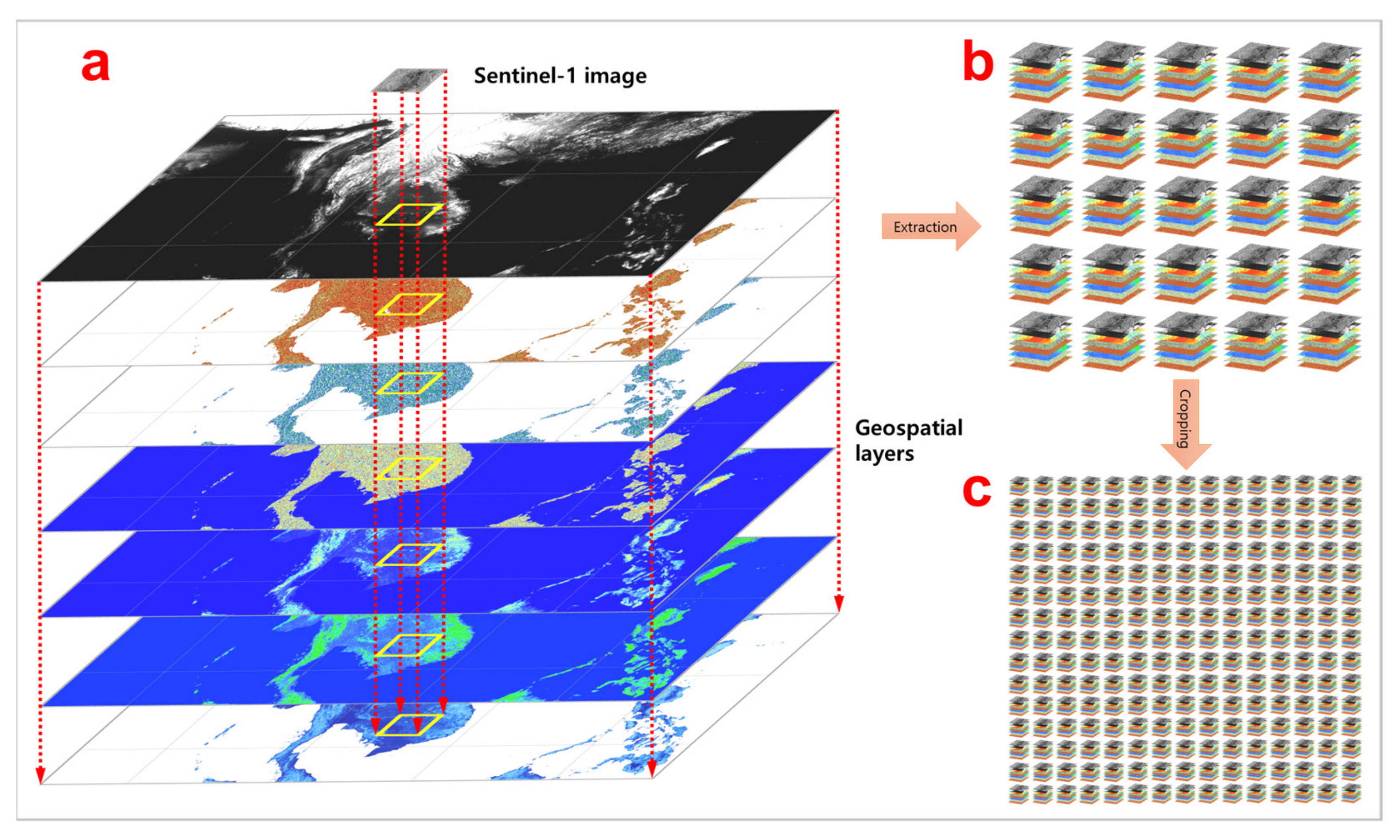
2.1.3. Building a Geospatial Database
3. Development of a Deep Learning-Based Water Body Extraction Model
3.1. Deep Learning-Based Water Body Extraction Model for Operational Flood Monitoring
3.1.1. Customisation and Optimisation of the Deep Neural Network
3.1.2. Stacking Input Data for Matching Layers and Normalisation
3.1.3. Model Training
3.1.4. Inference
3.2. Accuracy Assessment
4. Results
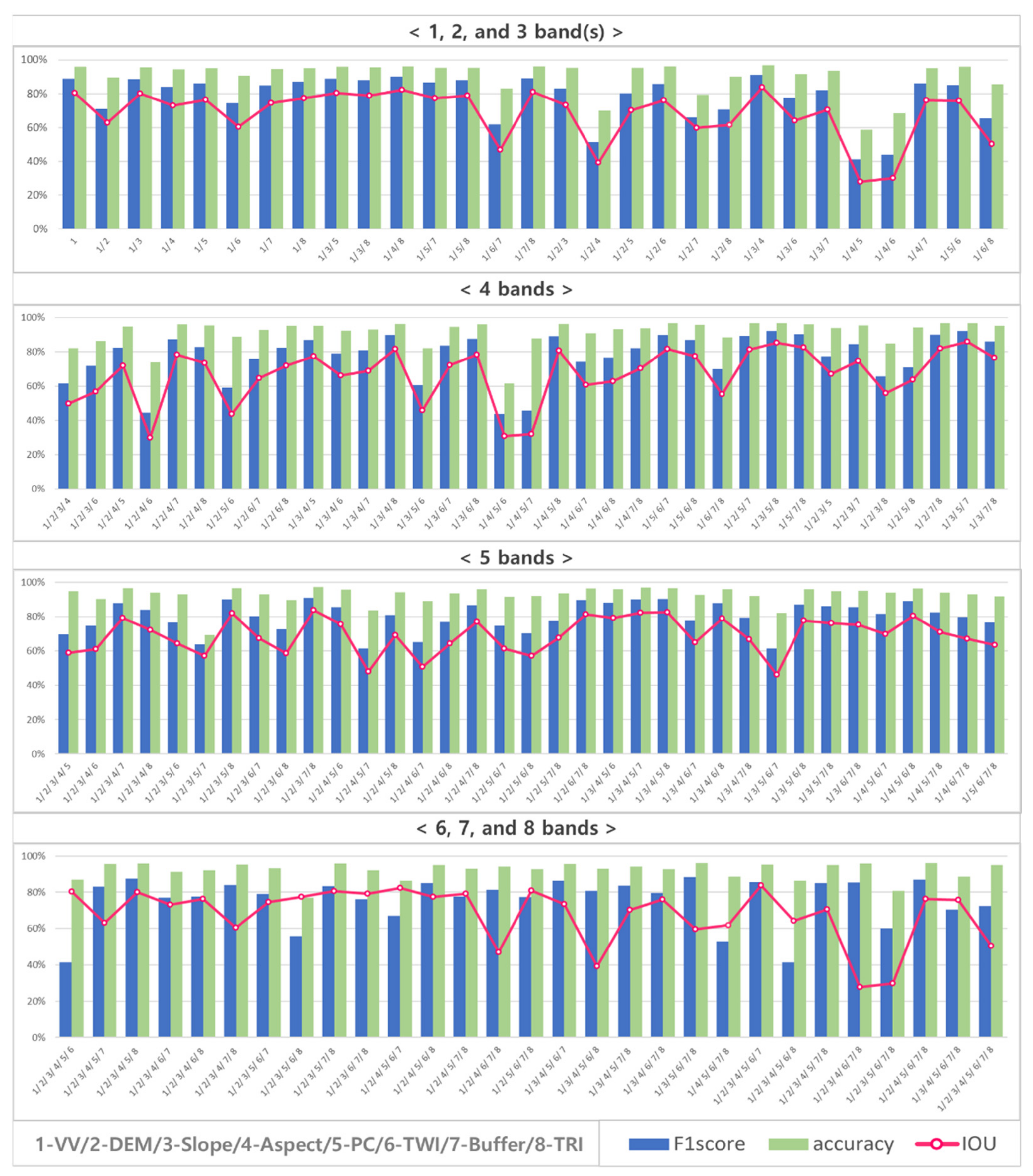
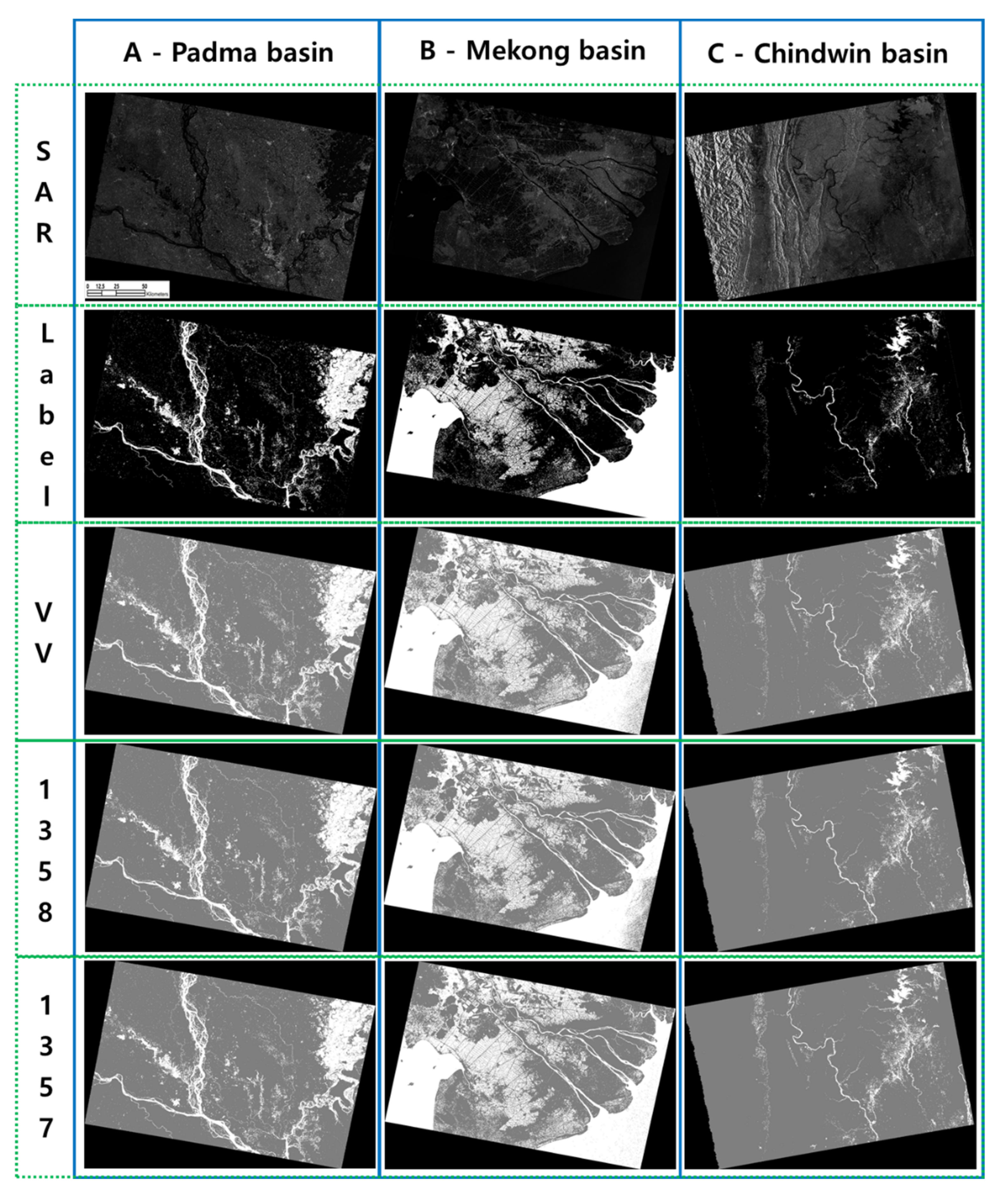
4.1. Segmentation Results and Improved Cases
4.2. Improvement in Inference Accuracy of the Three Cases
5. Discussion
5.1. Visual Interpretation
5.2. Training and Inference Time for Water Body Extraction
5.3. Summary and General Discussion
5.4. Novelty, Limitations, and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Schumann, G.J.-P.; Moller, D.K. Microwave Remote Sensing of Flood Inundation. Phys. Chem. Earth 2015, 83, 84–95. [Google Scholar] [CrossRef]
- Tien Bui, D.; Hoang, N.D.; Martínez-Álvarez, F.; Ngo, P.T.T.; Hoa, P.V.; Pham, T.D.; Samui, P.; Costache, R. A Novel Deep Learning Neural Network Approach for Predicting Flash Flood Susceptibility: A Case Study at a High Frequency Tropical Storm Area. Sci. Total Environ. 2020, 701, 134413. [Google Scholar] [CrossRef] [PubMed]
- Yilmaz, K.K.; Adler, R.F.; Tian, Y.; Hong, Y.; Pierce, H.F. Evaluation of a Satellite-Based Global Flood Monitoring System . Int. J. Remote Sens. 2010, 31, 3763–3782. [Google Scholar] [CrossRef]
- Guha-Sapir, D.; Vos, F.; Below, R.; Ponserre, S. Annual Disaster Statistical Review 2011: The Numbers and Trends; Centre for Research on the Epidemiology of Disasters (CRED): Brussels, Belgium, 2012. [Google Scholar]
- Sheng, Y.; Gong, P.; Xiao, Q. Quantitative Dynamic Flood Monitoring with NOAA AVHRR. Int. J. Remote Sens. 2001, 22, 1709–1724. [Google Scholar] [CrossRef]
- Voigt, S.; Giulio-Tonolo, F.; Lyons, J.; Kuˇcera, J.; Jones, B.; Schneiderhan, T.; Platzeck, G.; Kaku, K.; Hazarika, M.K.; Czaran, L.; et al. Global Trends in Satellite-Based Emergency Mapping. Science 2016, 353, 247–252. [Google Scholar] [CrossRef] [PubMed]
- Brivio, P.A.; Colombo, R.; Maggi, M.; Tomasoni, R. Integration of Remote Sensing Data and GIS for Accurate Mapping of Flooded Areas. Int. J. Remote Sens. 2002, 23, 429–441. [Google Scholar] [CrossRef]
- Changnon, S.A. Assessment of Flood Losses in the United States. J. Contemp. Water Res. Educ. 2008, 138, 38–44. [Google Scholar] [CrossRef]
- Shen, X.; Wang, D.; Mao, K.; Anagnostou, E.; Hong, Y. Inundation Extent Mapping by Synthetic Aperture Radar: A Review. Remote Sens. 2019, 11, 879. [Google Scholar] [CrossRef] [Green Version]
- Hess, L.L.; Melack, J.M.; Filoso, S.; Wang, Y. Delineation of Inundated Area and Vegetation along the Amazon Floodplain with the SIR-C Synthetic Aperture Radar. IEEE Trans. Geosci. Remote Sens. 1995, 33, 896–904. [Google Scholar] [CrossRef] [Green Version]
- Hahmann, T.; Martinis, S.; Twele, A.; Roth, A.; Buchroithner, M. Extraction of Water and Flood Areas from SAR data. In Proceedings of the 7th European Conference on Synthetic Aperture Radar, Friedrichshafen, Germany, 2–5 June 2008; pp. 1–4. [Google Scholar]
- Manavalan, R. SAR Image Analysis Techniques for Flood Area Mapping-Literature Survey. Earth Sci. Inform. 2017, 10, 1–14. [Google Scholar] [CrossRef]
- Tsyganskaya, V.; Martinis, S.; Marzahn, P.; Ludwig, R. SAR-based Detection of Flooded Vegetation—A Review of Characteristics and Approaches. Int. J. Remote Sens. 2018, 39, 2255–2293. [Google Scholar] [CrossRef]
- Greifeneder, F.; Wagner, W.; Sabel, D.; Naeimi, V. Suitability of SAR Imagery for Automatic Flood Mapping in the Lower Mekong Basin. Int. J. Remote Sens. 2014, 35, 2857–2874. [Google Scholar] [CrossRef]
- Pulvirenti, L.; Pierdicca, N.; Chini, M.; Guerriero, L. An Algorithm for Operational Flood Mapping from Synthetic Aperture Radar (SAR) Data Based on the Fuzzy Logic. Nat. Hazards Earth Syst. Sci. 2011, 11, 529–540. [Google Scholar] [CrossRef] [Green Version]
- Martinis, S.; Kuenzer, C.; Wendleder, A.; Huth, J.; Twele, A.; Roth, A.; Dech, S. Comparing Four Operational SAR-based Water and Flood Detection Approaches. Int. J. Remote Sens. 2015, 36, 3519–3543. [Google Scholar] [CrossRef]
- Kang, W.; Xiang, Y.; Wang, F.; Wan, L.; You, H. Flood Detection in Gaofen-3 SAR Images via Fully Convolutional Networks. Sensors 2018, 18, 2915. [Google Scholar] [CrossRef] [Green Version]
- Zhang, P.; Chen, L.; Li, Z.; Xing, J.; Xing, X.; Yuan, Z. Automatic Extraction of Water and Shadow from SAR Images Based on a Multi-resolution Dense Encoder and Decoder Network. Sensors 2019, 19, 3576. [Google Scholar] [CrossRef] [Green Version]
- Refice, A.; Capolongo, D.; Pasquariello, G.; D’Addabbo, A.; Bovenga, F.; Nutricato, R.; Lovergine, F.P.; Pietranera, L. SAR and InSAR for Flood Monitoring: Examples with COSMO-SkyMed Data. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2014, 7, 2711–2722. [Google Scholar] [CrossRef]
- D’Addabbo, A.; Refice, A.; Pasquariello, G.; Lovergine, F.P.; Capolongo, D.; Manfreda, S. A Bayesian Network for Flood Detection Combining SAR Imagery and Ancillary Data. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3612–3625. [Google Scholar] [CrossRef]
- Feng, M.; Sexton, J.O.; Channan, S.; Townshend, J.R. A Global, High-Resolution (30-m) Inland Water Body Dataset for 2000: First Results of a Topographic–Spectral Classification Algorithm. Int. J. Digit. Earth 2016, 9, 113–133. [Google Scholar] [CrossRef] [Green Version]
- Pekel, J.F.; Cottam, A.; Gorelick, N.; Belward, A.S. High-Resolution Mapping of Global Surface Water and its Long-Term Changes. Nature 2016, 540, 418–422. [Google Scholar] [CrossRef] [PubMed]
- Bates, B.C.; Kundzewicz, Z.W.; Wu, S.; Palutikof, J.P. Climate Change and Water: Technical Paper of the Intergovernmental Panel on Climate Change; IPCC Secretariat: Geneva, Switzerland, 2009; p. 210. [Google Scholar]
- Kundzewicz, Z.W.; Kanae, S.; Seneviratne, S.I.; Handmer, J.; Nicholls, N.; Peduzzi, P.; Mechler, R.; Bouwer, L.M.; Arnell, N.; Mach, K.; et al. Flood Risk and Climate Change: Global and Regional Perspectives. Hydrol. Sci. J. 2013, 59, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Fawaz, H.I.; Lucas, B.; Forestier, G.; Pelletier, C.; Schmidt, D.F.; Weber, J.; Webb, G.I.; Idoumghar, L.; Muller, P.A.; Petitjean, F. InceptionTime: Finding AlexNet for Time Series Classification. arXiv 2019, arXiv:1909.04939. [Google Scholar]
- Pashaei, M.; Kamangir, H.; Starek, M.J.; Tissot, P. Review and Evaluation of Deep Learning Architectures for Efficient Land Cover Mapping with UAS Hyper-spatial Imagery: A Case Study over a Wetland. Remote Sens. 2020, 12, 959. [Google Scholar] [CrossRef] [Green Version]
- Ngo, P.T.T.; Hoang, N.D.; Pradhan, B.; Nguyen, Q.K.; Tran, X.T.; Nguyen, Q.M.; Nguyen, V.N.; Samui, P.; Tien Bui, D. A Novel Hybrid Swarm Optimized Multilayer Neural Network for Spatial Prediction of Flash Floods in Tropical Areas Using Sentinel-1 SAR Imagery and Geospatial Data. Sensors 2018, 18, 3704. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wieland, M.; Martinis, S. A Modular Processing Chain for Automated Flood Monitoring from Multi-Spectral Satellite Data. Remote Sens. 2019, 11, 2330. [Google Scholar] [CrossRef] [Green Version]
- UNOSAT. UNOSAT Flood Dataset. 2019. Available online: http://floods.unosat.org/geoportal/catalog/main/home.page (accessed on 7 September 2020).
- Nemni, E.; Bullock, J.; Belabbes, S.; Bromley, L. Fully Convolutional Neural Network for Rapid Flood Segmentation in Synthetic Aperture Radar Imagery. Remote Sens. 2020, 12, 2532. [Google Scholar] [CrossRef]
- Twele, A.; Cao, W.; Plank, S.; Martinis, S. Sentinel-1-based Flood Mapping: A Fully Automated Processing Chain. Int. J. Remote Sens. 2016, 37, 2990–3004. [Google Scholar] [CrossRef]
- Tzavella, K.; Fekete, A.; Fiedrich, F. Opportunities Provided by Geographic Information Systems and Volunteered Geographic Information for a Timely Emergency Response during Flood Events in Cologne, Germany. Nat. Hazards. 2018, 91, 29–57. [Google Scholar] [CrossRef]
- Kia, M.B.; Pirasteh, S.; Pradhan, B.; Mahmud, A.R.; Sulaiman, W.N.A.; Moradi, A. An Artificial Neural Network Model for Flood Simulation Using GIS: Johor River Basin, Malaysia. Environ. Earth Sci. 2012, 67, 251–264. [Google Scholar] [CrossRef]
- Stefanidis, S.; Stathis, D. Assessment of Flood Hazard Based on Natural and Anthropogenic Factors Using Analytic Hierarchy Process (AHP). Nat. Hazards 2013, 68, 569–585. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flood Susceptibility Mapping Using a Novel Ensemble Weights-of-evidence and Support Vector Machine Models in GIS. J. Hydrol. 2014, 512, 332–343. [Google Scholar] [CrossRef]
- Al-Juaidi, A.E.; Nassar, A.M.; Al-Juaidi, O.E. Evaluation of Flood Susceptibility Mapping Using Logistic Regression and GIS Conditioning Factors. Arab. J. Geosci. 2018, 11, 765. [Google Scholar] [CrossRef]
- Pradhan, B. Flood Susceptible Mapping and Risk Area Delineation Using Logistic Regression, GIS and Remote Sensing. J. Spat. Hydrol. 2010, 9, 1–18. [Google Scholar]
- Riley, S.J.; DeGloria, S.D.; Elliot, R. Index that Quantifies Topographic Heterogeneity. Intermt. J. Sci. 1999, 5, 23–27. [Google Scholar]
- Tarboton, D.G. A New Method for the Determination of Flow Directions and Upslope Areas in Grid Digital Elevation Models. Water Resour. Res. 1997, 33, 309–319. [Google Scholar] [CrossRef] [Green Version]
- Beven, K.J.; Kirkby, M.J. A Physically Based, Variable Contributing Area Model of Basin Hydrology. Hydrol. Sci. J. 1979, 24, 43–69. [Google Scholar]
- Sörensen, R.; Zinko, U.; Seibert, J. On the Calculation of the Topographic Wetness Index: Evaluation of Different Methods Based on Field Observations. Hydrol. Earth Syst. Sci. 2006, 10, 101–112. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Wurm, M.; Stark, T.; Zhu, X.X.; Weigand, M.; Taubenböck, H. Semantic Segmentation of Slums in Satellite Images Using Transfer Learning on Fully Convolutional Neural Networks. ISPRS J. Photogramm. Remote Sens. 2019, 150, 59–69. [Google Scholar] [CrossRef]
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Wang, S.; Chen, W.; Xie, S.M.; Azzari, G.; Lobell, D.B. Weakly Supervised Deep Learning for Segmentation of Remote Sensing Imagery. Remote Sens. 2020, 12, 207. [Google Scholar] [CrossRef] [Green Version]
- Du, L.; McCarty, G.W.; Zhang, X.; Lang, M.W.; Vanderhoof, M.K.; Li, X.; Huang, C.; Lee, S.; Zou, Z. Mapping Forested Wetland Inundation in the Delmarva Peninsula, USA Using Deep Convolutional Neural Networks. Remote Sens. 2020, 12, 644. [Google Scholar] [CrossRef] [Green Version]
- Yang, M.D.; Tseng, H.H.; Hsu, Y.C.; Tsai, H.P. Semantic Segmentation Using Deep Learning with Vegetation Indices for Rice Lodging Identification in Multi-date UAV Visible Images. Remote Sens. 2020, 12, 633. [Google Scholar] [CrossRef] [Green Version]
- Goutte, C.; Gaussier, E. A Probabilistic Interpretation of Precision, Recall and F-score, with Implication for Evaluation. In Proceedings of the European Conference on Information Retrieval, Santiago de Compostela, Spain, 21–23 March 2005; pp. 345–359. [Google Scholar]
- Golik, P.; Doetsch, P.; Ney, H.; Cross-Entropy, vs. Squared Error Training: A Theoretical and Experimental Comparison. In Proceedings of the Interspeech, Lyon, France, 25–29 August 2013; pp. 1756–1760. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Satellite | Type/Mode | Acquisition Time (UTC) | Product ID | Usage |
|---|---|---|---|---|---|
| 1 | Sentinel-1A | GRDH/IW | 30 June 2016 23:55:28–23:55:53 | 0126A4_AB04 | Inference |
| 2 | Sentinel-1A | GRDH/IW | 7 November 2017 22:45:31–22:45:56 | 0206FC_1842 | Inference |
| 3 | Sentinel-1A | GRDH/IW | 18 July 2015 11:47:20–11:47:45 | 00942A_517D | Inference |
| 4 | Sentinel-1A | GRDH/IW | 30 July 2017 11:04:20–11:04:45 | 01DA46_8ADC | Training |
| 5 | Sentinel-1A | GRDH/IW | 15 June 2018 23:47:18–23:47:43 | 026C2D_EC7F | Training |
| 6 | Sentinel-1A | GRDH/IW | 25 July 2018 11:04:26–11:04:51 | 027D94_F52C | Training |
| 7 | Sentinel-1A | GRDH/IW | 11 July 2015 11:54:34–11:54:59 | 009133_64FC | Training |
| 8 | Sentinel-1A | GRDH/IW | 6 August 2015 11:37:30–11:37:55 | 009BED_DE92 | Training |
| 9 | Sentinel-1A | GRDH/IW | 11 August 2015 11:47:21–11:47:46 | 009DE4_C4E2 | Training |
| 10 | Sentinel-1A | GRDH/IW | 6 August 2015 11:37:55–11:38:20 | 009BED_FB1C | Training |
| 11 | Sentinel-1A | GRDH/IW | 24 July 2016 23:55:29–23:55:54 | 013213_0790 | Training |
| 12 | Sentinel-1A | GRDH/IW | 12 October 2016 22:51:27–22:51:52 | 015847_FB42 | Training |
| 13 | Sentinel-1A | GRDH/IW | 29 July 2018 22:44:19–22:44:44 | 027F8D_B944 | Training |
| 14 | Sentinel-1A | GRDH/IW | 13 July 2018 11:04:25–11:04:50 | 02780D_7D6F | Training |
| 15 | Sentinel-1A | GRDH/IW | 13 December 2016 22:36:07–22:36:32 | 01747F_68A3 | Training |
| 16 | Sentinel-1A | GRDH/IW | 1 December 2016 22:36:08–22:36:33 | 016EE9_2752 | Training |
| Layer Order | Layer Name | Pixel Size (m) | Resampled Pixel Size (m) | Value Range | Normalised Value Range |
|---|---|---|---|---|---|
| 1 | Sentinel-1 data (VV) | 10 | 10 | 0–1 | 0–1 |
| 2 | SRTM Digital Elevation Model (DEM) | 30 | 10 | 0–8220 | 0–1 (0, 0.2, 0.4, 0.6, 0.8, 1) |
| 3 | Slope | 30 | 10 | 0–86.1 | 0–1 |
| 4 | Aspect | 30 | 10 | 0–360 | 0–1 |
| 5 | Profile Curvature (PC) | 30 | 10 | −0.155093–0.122646 | 0–1 (0, 0.5, 1) |
| 6 | Terrain Wetness Index (TWI) | 500 | 10 | 40–132 | 0–1 (0, 0.2, 0.4, 0.6, 0.8, 1) |
| 7 | Distance from water (Buffer) | 30 | 10 | 0–3 | 0–1 (0, 0.5, 1) |
| 8 | Terrain Ruggedness Index (TRI) | 30 | 10 | 0–24,576 | 0–1 (0, 0.2, 0.4, 0.6, 0.8, 1) |
| Hyper-Parameters for the Deep Neural Network | |
|---|---|
| Kernel size (upsampling/output) | 3 × 3/2 × 2 |
| stride/padding | 1 × 1/same |
| Maxpooling | 2 × 2 |
| Activation function | RELU/sigmoid (output layer) |
| Learning rate/decay rate | Adadelta optimizer 1/0.95 |
| Validation frequency | Every 20 iterations |
| Epoch/iteration | 1000/170 per epoch |
| Early stopping | Validation criterion (No improvement of loss for five epochs) |
| Batch size | 16 |
| Patch size/channels | 320 × 320/1–8 |
| Pair numbers/Water body rate | 4326/0.1–0.9 |
| Confusion Matrix for Pixel-Wise Evaluation | |||
|---|---|---|---|
| Predicted Class | Water | Non-Water | |
| Label Class | |||
| Water | True Positive (TP) | False Negative (FN) | |
| Non-water | False Positive (FP) | True Negative (TN) | |
| Formulas for Accuracy Assessment of Output Images | |||
| Overall accuracy (OA) | |||
| Precision | |||
| Recall | |||
| Intersection over union (IOU) | |||
| F1 Score | |||
| Band Combination | Training | Inference (Averaged) | |||||
|---|---|---|---|---|---|---|---|
| Loss | Accuracy | IOU | F1 Score | Accuracy | IOU | F1 Score | |
| 1 (VV) | 0.1398 | 94.91 | 87.83 | 93.52 | 95.77 | 80.35 | 88.85 |
| 134 | 0.1727 | 92.90 | 82.40 | 90.35 | 96.84 | 83.65 | 90.95 |
| 135 | 0.1280 | 95.06 | 88.02 | 93.63 | 95.81 | 80.41 | 88.89 |
| 148 | 0.1553 | 93.81 | 84.99 | 91.88 | 96.25 | 82.17 | 90.06 |
| 178 | 0.1414 | 94.55 | 87.21 | 93.17 | 96.08 | 80.89 | 89.19 |
| 1257 | 0.1653 | 93.32 | 83.29 | 90.89 | 96.87 | 81.58 | 89.49 |
| 1278 | 0.1659 | 92.87 | 82.02 | 90.12 | 96.75 | 82.09 | 89.95 |
| 1348 | 0.2095 | 91.50 | 79.09 | 88.32 | 96.35 | 81.71 | 89.81 |
| 1357 | 0.1458 | 94.49 | 86.76 | 92.91 | 96.89 | 85.85 | 92.31 |
| 1358 | 0.1682 | 93.18 | 82.82 | 90.60 | 96.73 | 85.42 | 92.08 |
| 1458 | 0.1596 | 93.78 | 84.46 | 91.58 | 96.35 | 80.96 | 89.19 |
| 1567 | 0.2331 | 90.94 | 77.79 | 87.51 | 96.83 | 81.68 | 89.74 |
| 1578 | 0.1216 | 95.06 | 87.79 | 93.50 | 96.23 | 82.58 | 90.28 |
| 12358 | 0.1446 | 94.14 | 85.69 | 92.30 | 96.64 | 82.02 | 89.87 |
| 12378 | 0.1489 | 94.26 | 86.17 | 92.57 | 97.12 | 83.65 | 90.86 |
| 12678 | 0.2186 | 91.33 | 78.17 | 87.75 | 96.32 | 81.29 | 89.57 |
| 13457 | 0.2086 | 91.12 | 77.64 | 87.41 | 96.88 | 82.21 | 90.04 |
| 13458 | 0.1463 | 94.06 | 85.86 | 92.39 | 96.68 | 82.69 | 90.32 |
| 14568 | 0.1701 | 93.08 | 82.96 | 90.69 | 96.33 | 80.49 | 88.96 |
| Band Combination | Inference (Averaged) | Scenes | Differences | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | IOU | F1 Score | A | B | C | A−VV | B−VV | C−VV | |
| 1 (VV) | 95.77 | 81.79 | 98.07 | 80.35 | 88.85 | 90.69 | 94.40 | 81.44 | 0.00 | 0.00 | 0.00 |
| 134 | 96.84 | 89.05 | 93.05 | 83.65 | 90.95 | 92.89 | 94.70 | 85.25 | 2.20 | 0.30 | 3.80 |
| 135 | 95.81 | 82.25 | 97.52 | 80.41 | 88.89 | 90.66 | 94.37 | 81.64 | −0.03 | −0.03 | 0.19 |
| 148 | 96.25 | 85.13 | 95.93 | 82.17 | 90.06 | 91.69 | 94.13 | 84.36 | 1.00 | −0.27 | 2.91 |
| 178 | 96.08 | 82.79 | 97.39 | 80.89 | 89.19 | 91.61 | 94.15 | 81.80 | 0.92 | −0.25 | 0.36 |
| 1257 | 96.87 | 88.09 | 91.11 | 81.58 | 89.49 | 93.50 | 94.67 | 80.29 | 2.81 | 0.27 | −1.15 |
| 1278 | 96.75 | 92.35 | 87.72 | 82.09 | 89.95 | 92.51 | 94.33 | 82.99 | 1.82 | −0.07 | 1.55 |
| 1348 | 96.35 | 88.77 | 90.98 | 81.71 | 89.81 | 92.90 | 91.94 | 84.60 | 2.20 | −2.46 | 3.16 |
| 1357 | 96.89 | 88.43 | 96.80 | 85.85 | 92.31 | 92.79 | 95.53 | 88.61 | 2.10 | 1.13 | 7.17 |
| 1358 | 96.73 | 90.14 | 94.27 | 85.42 | 92.08 | 91.97 | 95.15 | 89.12 | 1.27 | 0.75 | 7.68 |
| 1458 | 96.35 | 84.72 | 94.58 | 80.96 | 89.19 | 94.03 | 92.48 | 81.05 | 3.33 | −1.92 | −0.39 |
| 1567 | 96.83 | 91.85 | 87.84 | 81.68 | 89.74 | 92.26 | 93.59 | 83.35 | 1.57 | −0.81 | 1.91 |
| 1578 | 96.23 | 84.79 | 97.11 | 82.58 | 90.28 | 91.32 | 95.11 | 84.40 | 0.63 | 0.72 | 2.96 |
| 12358 | 96.64 | 87.36 | 93.29 | 82.02 | 89.87 | 94.64 | 92.55 | 82.41 | 3.95 | −1.85 | 0.97 |
| 12378 | 97.12 | 87.71 | 94.66 | 83.65 | 90.86 | 94.95 | 93.99 | 83.65 | 4.25 | −0.41 | 2.21 |
| 12678 | 96.32 | 88.31 | 90.89 | 81.29 | 89.57 | 92.06 | 92.00 | 84.66 | 1.36 | −2.39 | 3.22 |
| 13457 | 96.88 | 90.67 | 89.52 | 82.21 | 90.04 | 93.30 | 93.45 | 83.36 | 2.60 | −0.94 | 1.92 |
| 13458 | 96.68 | 86.11 | 95.22 | 82.69 | 90.32 | 94.39 | 93.09 | 83.47 | 3.70 | −1.31 | 2.02 |
| 14568 | 96.33 | 84.88 | 93.67 | 80.49 | 88.96 | 92.62 | 92.62 | 81.63 | 1.92 | −1.77 | 0.19 |
| No. of Band(s) | Band Combination | Train Time (s) | Inference Time (s) |
|---|---|---|---|
| 1 | 1 (VV) | 1404.95 | 302.20 |
| 3 | 134 | 1425.92 | 659.20 |
| 135 | 767.90 | 751.94 | |
| 148 | 1323.38 | 602.16 | |
| 178 | 516.57 | 496.22 | |
| average | 1008.44 | 627.38 | |
| 4 | 1257 | 833.97 | 1029.08 |
| 1278 | 1020.84 | 802.68 | |
| 1348 | 1146.71 | 701.48 | |
| 1357 | 621.58 | 738.80 | |
| 1358 | 590.25 | 847.41 | |
| 1458 | 1317.86 | 726.23 | |
| 1567 | 1064.65 | 872.16 | |
| 1578 | 1571.38 | 1131.64 | |
| average | 1020.91 | 856.19 | |
| 5 | 12358 | 874.71 | 914.28 |
| 12378 | 1182.14 | 995.53 | |
| 12678 | 655.49 | 866.57 | |
| 13457 | 1503.43 | 865.67 | |
| 13458 | 1552.98 | 1060.59 | |
| 14568 | 1134.72 | 1356.82 | |
| average | 1150.58 | 1009.91 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Kim, H.; Jeon, H.; Jeong, S.-H.; Song, J.; Vadivel, S.K.P.; Kim, D.-j. Synergistic Use of Geospatial Data for Water Body Extraction from Sentinel-1 Images for Operational Flood Monitoring across Southeast Asia Using Deep Neural Networks. Remote Sens. 2021, 13, 4759. https://doi.org/10.3390/rs13234759
Kim J, Kim H, Jeon H, Jeong S-H, Song J, Vadivel SKP, Kim D-j. Synergistic Use of Geospatial Data for Water Body Extraction from Sentinel-1 Images for Operational Flood Monitoring across Southeast Asia Using Deep Neural Networks. Remote Sensing. 2021; 13(23):4759. https://doi.org/10.3390/rs13234759
Chicago/Turabian StyleKim, Junwoo, Hwisong Kim, Hyungyun Jeon, Seung-Hwan Jeong, Juyoung Song, Suresh Krishnan Palanisamy Vadivel, and Duk-jin Kim. 2021. "Synergistic Use of Geospatial Data for Water Body Extraction from Sentinel-1 Images for Operational Flood Monitoring across Southeast Asia Using Deep Neural Networks" Remote Sensing 13, no. 23: 4759. https://doi.org/10.3390/rs13234759