
Hyperspectral Image Classification Based on Two-Branch Spectral–Spatial-Feature Attention Network


Abstract
:
1. Introduction
2. Materials and Methods
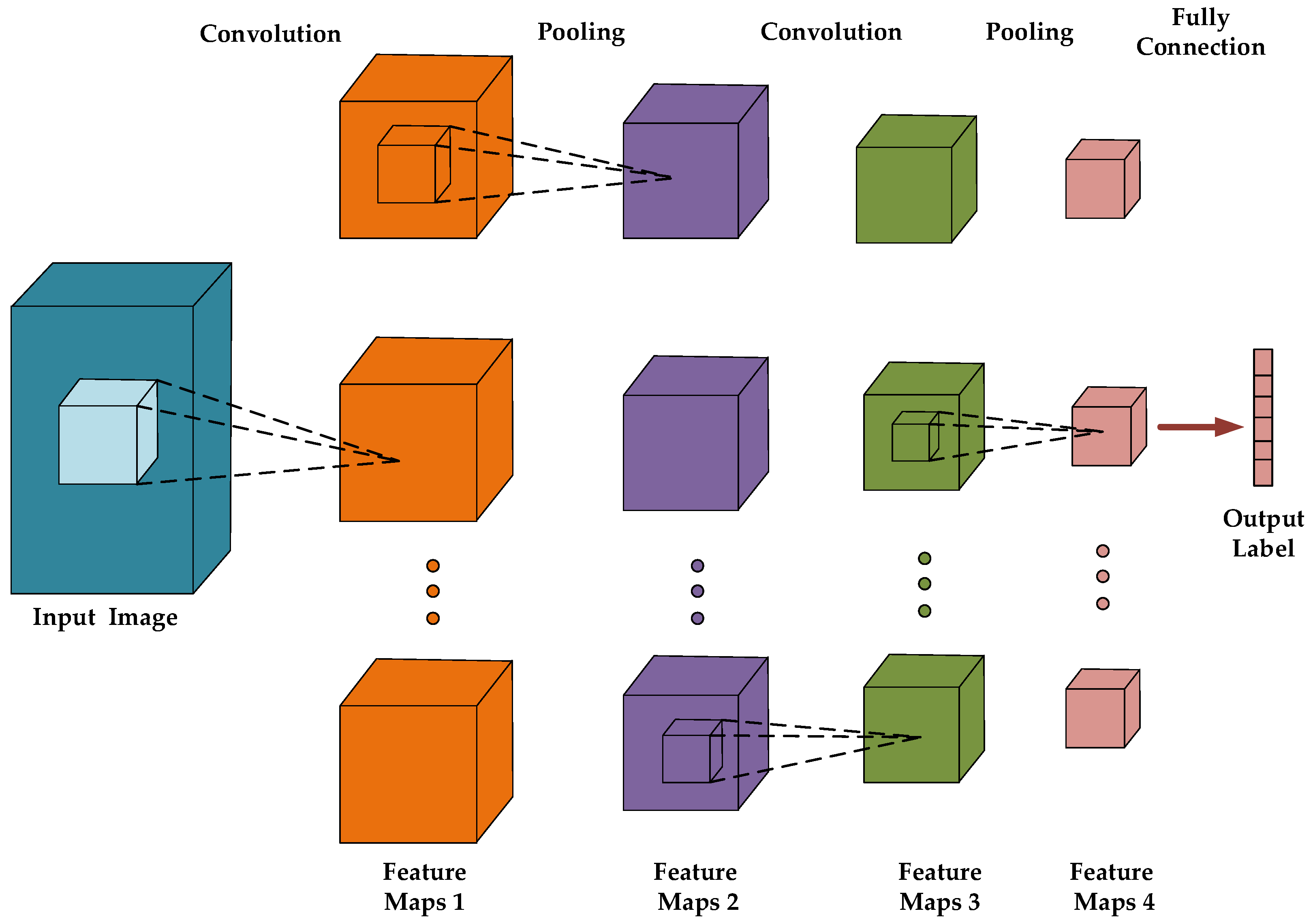
2.1. 2DCNN and 3DCNN
2.2. Attention Mechanism
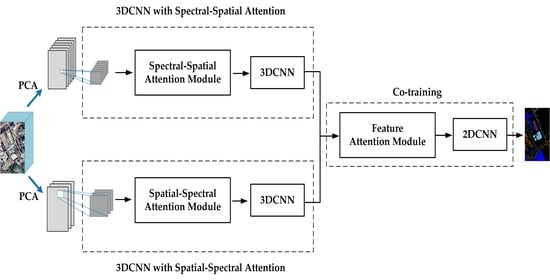
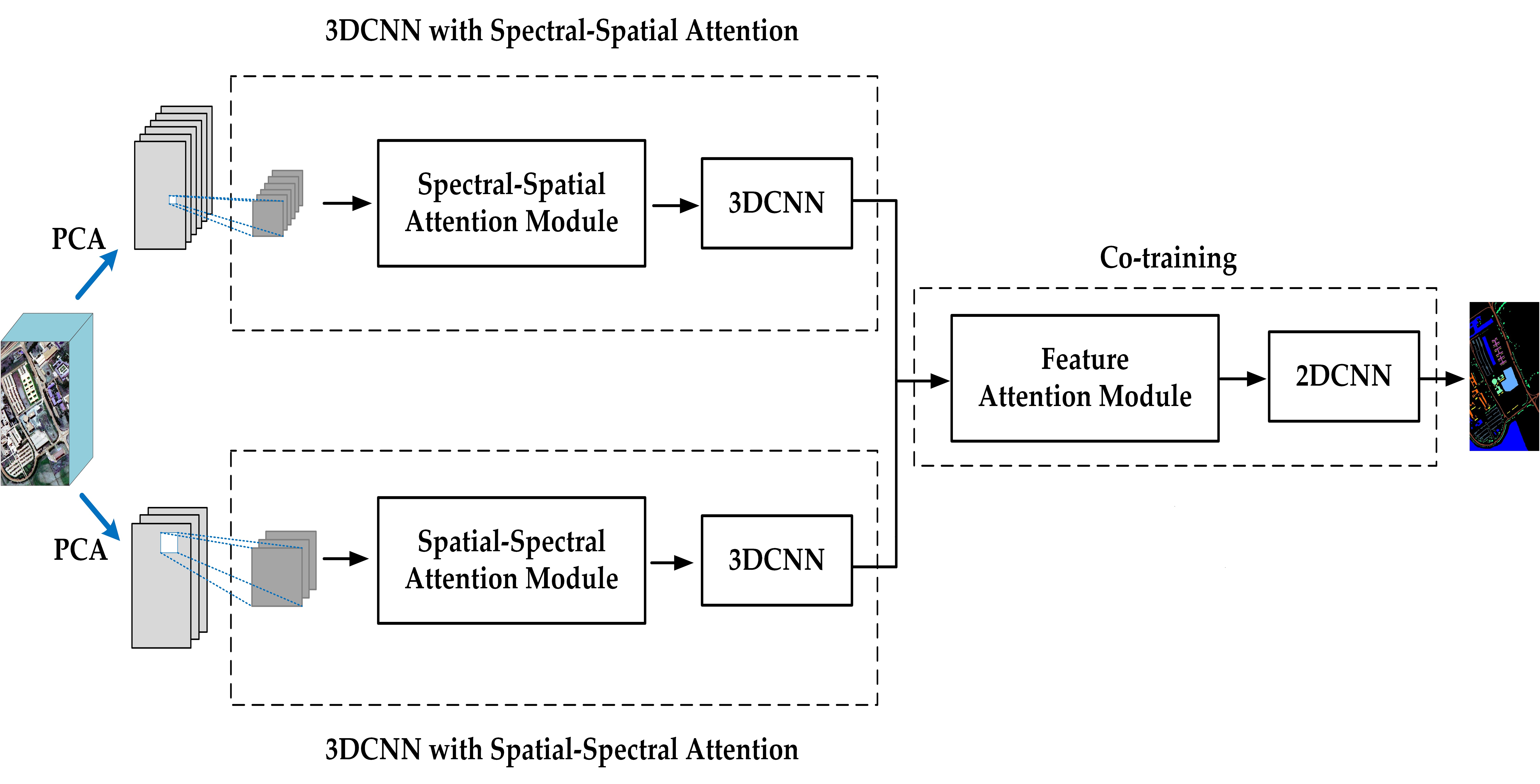
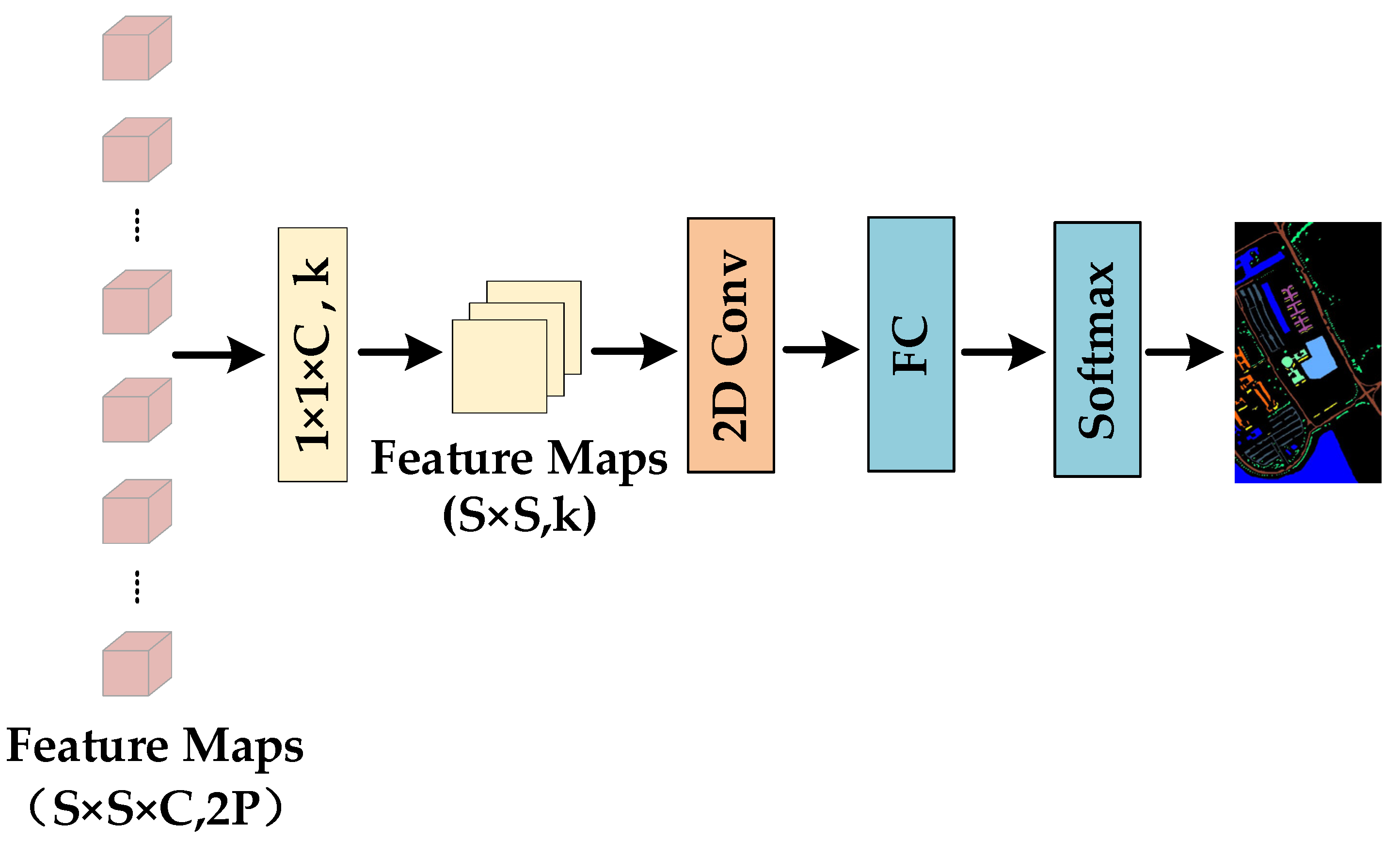
2.3. Proposed TSSFAN Method
2.3.1. Data Preprocessing
- (1)
- PCA is employed to reduce the spectral dimension of the original image and obtain two datasets with different spectral dimensions, where and .
- (2)
- Based on the two different spectral dimensions, the image with the larger spectral dimension selects a smaller spatial window to create an input 3D cube for each center pixel, while the image with the smaller spectral dimension selects a larger spatial window to create another input 3D cube for each center pixel, where Input_1 is denoted by and Input_2 is denoted by , respectively.
2.3.2. Two-Branch 3DCNN with Attention Modules
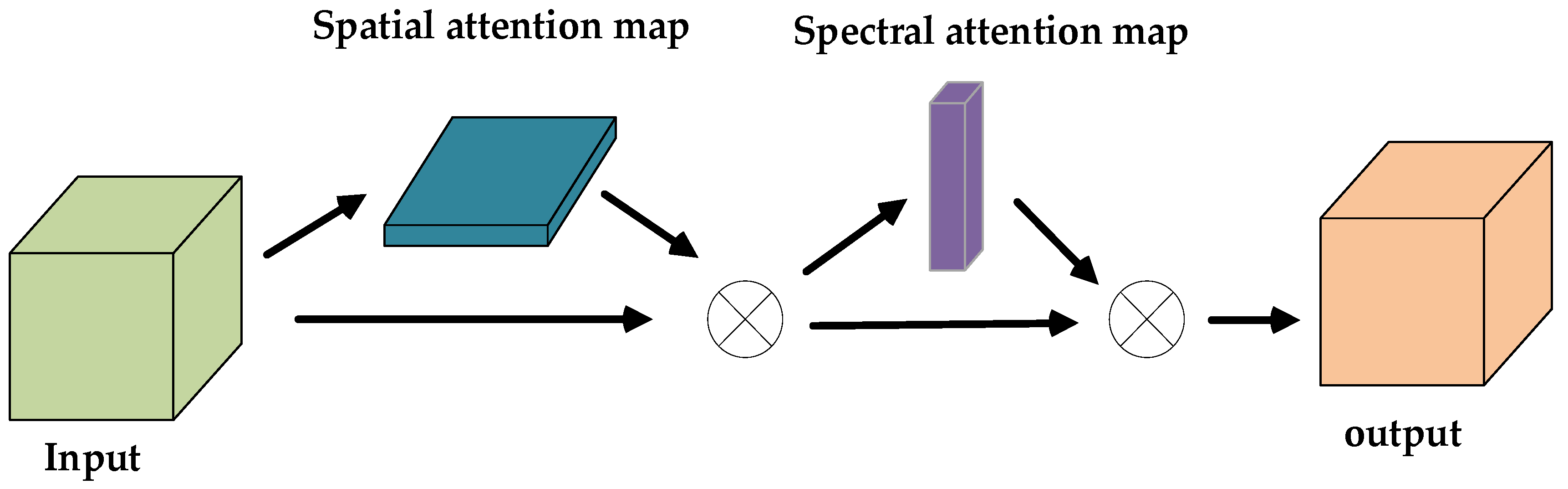
- 3DCNN with Spectral–Spatial Attention
- (a)
- Spectral attention map:
- (b)
- Spatial attention map:
- B.
- 3DCNN with Spatial–Spectral Attention
2.3.3. Feature Attention Module in the Co-Training Model
2.3.4. 2DCNN for Classification
3. Experimental Result and Analysis
3.1. Data Description
- (1)
- Indian Pines (IP): IP was acquired by a sensor on June 1992, in which the spatial size is 145 × 145 and the number of the spectral band is 224. Specifically, its spectral resolution is 10 nm. Moreover, the range of wavelength in IP is 0.4–2.5 μm. Additionally, sixteen categories are contained in IP, and only 200 effective bands in IP can be utilized because the 24 bands that could carry noise information are excluded.
- (2)
- University of Pavia (UP): UP is acquired by a sensor known as the ROSIS sensor, in which the spatial size is 610 × 340 and the number of the spectral band is 115. Moreover, the range of wavelength in UP is 0.43–0.86 μm. Specifically, nine categories are contained in UP with 42,776 labeled pixels. In the experiment, only 103 effective bands in UP can be utilized because the 12 bands that could carry noise information are excluded.
- (3)
- Salinas Scene (SA): SA is acquired by a hyperspectral sensor, in which the spatial size is 512 × 217 and the number of the spectral band is 224. Additionally, sixteen categories are contained in SA, and only 204 effective bands in SA can be utilized because the 20 bands that could carry noise information are excluded.
3.2. Experimental Configuration
3.3. Analysis of Parameters
- (1)
- Learning rate: During the gradient descent process of a deep-learning model, the weights are constantly updated. A few hyperparameters play an instrumental role in controlling this process properly, and one of them is the learning rate. The convergence capability and the convergence speed of the network can be productively regulated by a suitable learning rate. In our trials, the effect of the learning rate on the classification performance is tested, where the value of the learning rate is set to {0.00005,0.0001,0.0003,0.0005,0.001,0.003,0.005,0.008}. Figure 17 shows the experimental results.
- (2)
- Spectral dimension: Input-1 contains more spectral information and less spatial information. The spectral dimension in Input-1 determines how much spectral information is available to classify the pixels. We tested the impact of the spectral dimension in Input-1. In our experiments, the spectral dimension in Input-1 is set to {21,23,25,27,29,31,33} to capture sufficient spectral information. Figure 18 presents the experimental results.
- (3)
- Spatial size: Input-2 contains more spatial information and less spectral information. The spatial size in Input-2 determines how much spatial information is available to classify the pixels. We test the impact of the spatial size in Input-2. In our experiment, the spatial size is set as {25 × 25, 27 × 27, 29 × 29, 31 × 31, 33 × 33, 35 × 35, 37 × 37}. Figure 19 presents the experimental results.
3.4. Comparisons to the State-of-the-Art Methods
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Tao, C.; Wang, Y.J.; Cui, W.B.; Zou, B.; Zou, Z.R.; Tu, Y.L. A transferable spectroscopic diagnosis model for predicting arsenic contamination in soil. Sci. Total. Environ. 2019, 669, 964–972. [Google Scholar] [CrossRef] [PubMed]
- Ghamisi, P.; Plaza, J.; Chen, Y.S.; Li, J.; Plaza, A. Advanced Spectral Classifiers for Hyperspectral Images A review. IEEE Geosci. Remote. Sens. Mag. 2017, 5, 8–32. [Google Scholar] [CrossRef] [Green Version]
- Konig, M.; Birnbaum, G.; Oppelt, N. Mapping the Bathymetry of Melt Ponds on Arctic Sea Ice Using Hyperspectral Imagery. Remote Sens. 2020, 12, 2623. [Google Scholar] [CrossRef]
- Lu, B.; Dao, P.D.; Liu, J.G.; He, Y.H.; Shang, J.L. Recent Advances of Hyperspectral Imaging Technology and Applications in Agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar] [CrossRef]
- Aneece, I.; Thenkabail, P. Accuracies Achieved in Classifying Five Leading World Crop Types and their Growth Stages Using Optimal Earth Observing-1 Hyperion Hyperspectral Narrowbands on Google Earth Engine. Remote Sens. 2018, 10, 2027. [Google Scholar] [CrossRef] [Green Version]
- Gao, Q.S.; Lim, S.; Jia, X.P. Hyperspectral Image Classification Using Convolutional Neural Networks and Multiple Feature Learning. Remote Sens. 2018, 10, 299. [Google Scholar] [CrossRef] [Green Version]
- Zabalza, J.; Ren, J.C.; Zheng, J.B.; Han, J.W.; Zhao, H.M.; Li, S.T.; Marshall, S. Novel Two-Dimensional Singular Spectrum Analysis for Effective Feature Extraction and Data Classification in Hyperspectral Imaging. IEEE Trans. Geosci. Remote. Sens. 2015, 53, 4418–4433. [Google Scholar] [CrossRef] [Green Version]
- Du, B.; Zhao, R.; Zhang, L.P.; Zhang, L.F. A spectral-spatial based local summation anomaly detection method for hyperspectral images. Signal Process. 2016, 124, 115–131. [Google Scholar] [CrossRef]
- Zhang, L.F.; Zhang, L.P.; Du, B.; You, J.E.; Tao, D.C. Hyperspectral image unsupervised classification by robust manifold matrix factorization. Inf. Sci. 2019, 485, 154–169. [Google Scholar] [CrossRef]
- Li, W.; Wu, G.D.; Zhang, F.; Du, Q.A. Hyperspectral Image Classification Using Deep Pixel-Pair Features. IEEE Trans. Geosci. Remote. Sens. 2017, 55, 844–853. [Google Scholar] [CrossRef]
- Bitar, A.W.; Cheong, L.F.; Ovarlez, J.P. Sparse and Low-Rank Matrix Decomposition for Automatic Target Detection in Hyperspectral Imagery. IEEE Trans. Geosci. Remote. Sens. 2019, 57, 5239–5251. [Google Scholar] [CrossRef] [Green Version]
- Lu, X.Q.; Zheng, X.T.; Yuan, Y. Remote Sensing Scene Classification by Unsupervised Representation Learning. IEEE Trans. Geosci. Remote. Sens. 2017, 55, 5148–5157. [Google Scholar] [CrossRef]
- Masarczyk, W.; Glomb, P.; Grabowski, B.; Ostaszewski, M. Effective Training of Deep Convolutional Neural Networks for Hyperspectral Image Classification through Artificial Labeling. Remote Sens. 2020, 12, 2653. [Google Scholar] [CrossRef]
- Blanco, S.R.; Heras, D.B.; Arguello, F. Texture Extraction Techniques for the Classification of Vegetation Species in Hyperspectral Imagery: Bag of Words Approach Based on Superpixels. Remote Sens. 2020, 12, 2633. [Google Scholar] [CrossRef]
- Qamar, F.; Dobler, G. Pixel-Wise Classification of High-Resolution Ground-Based Urban Hyperspectral Images with Convolutional Neural Networks. Remote Sens. 2020, 12, 2540. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote. Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.P.; Zhang, L.F.; Du, B. Deep Learning for Remote Sensing Data A technical tutorial on the state of the art. IEEE Geosci. Remote. Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Liu, Z.; Tang, B.; He, X.F.; Qiu, Q.C.; Liu, F. Class-Specific Random Forest with Cross-Correlation Constraints for Spectral-Spatial Hyperspectral Image Classification. IEEE Geosci. Remote. Sens. Lett. 2017, 14, 257–261. [Google Scholar] [CrossRef]
- Bajpai, S.; Singh, H.V.; Kidwai, N.R. Feature Extraction & Classification of Hyperspectral Images using Singular Spectrum Analysis & Multinomial Logistic Regression Classifiers. In Proceedings of the 2017 International Conference on Multimedia, Signal Processing and Communication Technologies (IMPACT), Aligarh, India, 24–26 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 97–100. [Google Scholar]
- Li, W.; Chen, C.; Su, H.J.; Du, Q. Local Binary Patterns and Extreme Learning Machine for Hyperspectral Imagery Classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3681–3693. [Google Scholar] [CrossRef]
- Dalla Mura, M.; Villa, A.; Benediktsson, J.A.; Chanussot, J.; Bruzzone, L. Classification of Hyperspectral Images by Using Extended Morphological Attribute Profiles and Independent Component Analysis. IEEE Geosci. Remote Sens. Lett. 2011, 8, 542–546. [Google Scholar] [CrossRef] [Green Version]
- Cao, C.H.; Deng, L.; Duan, W.; Xiao, F.; Yang, W.C.; Hu, K. Hyperspectral image classification via compact-dictionary-based sparse representation. Multimed. Tools Appl. 2019, 78, 15011–15031. [Google Scholar] [CrossRef]
- Li, D.; Wang, Q.; Kong, F.Q. Adaptive kernel sparse representation based on multiple feature learning for hyperspectral image classification. Neurocomputing 2020, 400, 97–112. [Google Scholar] [CrossRef]
- Li, D.; Wang, Q.; Kong, F.Q. Superpixel-feature-based multiple kernel sparse representation for hyperspectral image classification. Signal Process. 2020, 176, 107682. [Google Scholar] [CrossRef]
- Yang, W.D.; Peng, J.T.; Sun, W.W.; Du, Q. Log-Euclidean Kernel-Based Joint Sparse Representation for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 5023–5034. [Google Scholar] [CrossRef]
- Li, S.T.; Song, W.W.; Fang, L.Y.; Chen, Y.S.; Ghamisi, P.; Benediktsson, J.A. Deep Learning for Hyperspectral Image Classification: An Overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- Mou, L.C.; Ghamisi, P.; Zhu, X.X. Deep Recurrent Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef] [Green Version]
- Wu, H.; Prasad, S. Convolutional Recurrent Neural Networks for Hyperspectral Data Classification. Remote Sens. 2017, 9, 298. [Google Scholar] [CrossRef] [Green Version]
- Fang, L.Y.; Liu, G.Y.; Li, S.T.; Ghamisi, P.; Benediktsson, J.A. Hyperspectral Image Classification with Squeeze Multibias Network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1291–1301. [Google Scholar] [CrossRef]
- Ding, C.; Li, Y.; Xia, Y.; Wei, W.; Zhang, L.; Zhang, Y.N. Convolutional Neural Networks Based Hyperspectral Image Classification Method with Adaptive Kernels. Remote Sens. 2017, 9, 618. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.S.; Lin, Z.H.; Zhao, X.; Wang, G.; Gu, Y.F. Deep Learning-Based Classification of Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Cheng, G.; Li, Z.P.; Han, J.W.; Yao, X.W.; Guo, L. Exploring Hierarchical Convolutional Features for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6712–6722. [Google Scholar] [CrossRef]
- Li, W.; Chen, C.; Zhang, M.M.; Li, H.C.; Du, Q. Data Augmentation for Hyperspectral Image Classification with Deep CNN. IEEE Geosci. Remote Sens. Lett. 2019, 16, 593–597. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Haut, J.M.; Fernandez-Beltran, R.; Plaza, J.; Plaza, A.; Li, J.; Pla, F. Capsule Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2145–2160. [Google Scholar] [CrossRef]
- Song, W.W.; Li, S.T.; Fang, L.Y.; Lu, T. Hyperspectral Image Classification with Deep Feature Fusion Network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3173–3184. [Google Scholar] [CrossRef]
- Chen, Y.S.; Zhao, X.; Jia, X.P. Spectral-Spatial Classification of Hyperspectral Data Based on Deep Belief Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2381–2392. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.Y.; Wei, L.; Zhang, F.; Li, H.C. Deep Convolutional Neural Networks for Hyperspectral Image Classification. J. Sens. 2015, 2015. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.S.; Jiang, H.L.; Li, C.Y.; Jia, X.P.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- Zhong, Z.L.; Li, J.; Luo, Z.M.; Chapman, M. Spectral-Spatial Residual Network for Hyperspectral Image Classification: A 3-D Deep Learning Framework. IEEE Trans. Geosci. Remote Sens. 2018, 56, 847–858. [Google Scholar] [CrossRef]
- Sellami, A.; Farah, M.; Farah, I.R.; Solaiman, B. Hyperspectral imagery classification based on semi-supervised 3-D deep neural network and adaptive band selection. Expert Syst. Appl. 2019, 129, 246–259. [Google Scholar] [CrossRef]
- Mei, X.G.; Pan, E.T.; Ma, Y.; Dai, X.B.; Huang, J.; Fan, F.; Du, Q.L.; Zheng, H.; Ma, J.Y. Spectral-Spatial Attention Networks for Hyperspectral Image Classification. Remote Sens. 2019, 11, 963. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Zhang, Y.; He, D.J.; Li, Y.X. Identification of Apple Leaf Diseases Based on Deep Convolutional Neural Networks. Symmetry 2018, 10, 11. [Google Scholar] [CrossRef] [Green Version]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the 2015 IEEE International Symposium on Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 4959–4962. [Google Scholar]
- Gu, J.X.; Wang, Z.H.; Kuen, J.; Ma, L.Y.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.X.; Wang, G.; Cai, J.F.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.A.; Xue, B.; Zhang, M.J.; Yen, G.G. Evolving Deep Convolutional Neural Networks for Image Classification. IEEE Trans. Evol. Comput. 2020, 24, 394–407. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.S.; Zhang, Y.J.; Huang, X.; Ma, J.Y. Learning Source-Invariant Deep Hashing Convolutional Neural Networks for Cross-Source Remote Sensing Image Retrieval. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6521–6536. [Google Scholar] [CrossRef]
- Ma, J.Y.; Yu, W.; Liang, P.W.; Li, C.; Jiang, J.J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Haut, J.M.; Fernandez-Beltran, R.; Plaza, J.; Plaza, A.J.; Pla, F. Deep Pyramidal Residual Networks for Spectral-Spatial Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 740–754. [Google Scholar] [CrossRef]
- Tian, T.; Li, C.; Xu, J.K.; Ma, J.Y. Urban Area Detection in Very High Resolution Remote Sensing Images Using Deep Convolutional Neural Networks. Sensors 2018, 18, 904. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.Y.; Yi, P.; Jiang, K.; Jiang, J.J.; Han, Z.; Lu, T.; Ma, J.Y. Multi-Memory Convolutional Neural Network for Video Super-Resolution. IEEE Trans. Image Process. 2019, 28, 2530–2544. [Google Scholar] [CrossRef] [PubMed]
- Karim, F.; Majumdar, S.; Darabi, H.; Chen, S. LSTM Fully Convolutional Networks for Time Series Classification. IEEE Access 2018, 6, 1662–1669. [Google Scholar] [CrossRef]
- Xu, Y.; Bao, Y.Q.; Chen, J.H.; Zuo, W.M.; Li, H. Surface fatigue crack identification in steel box girder of bridges by a deep fusion convolutional neural network based on consumer-grade camera images. Struct. Health Monit. Int. J. 2019, 18, 653–674. [Google Scholar] [CrossRef]
- Ma, X.L.; Dai, Z.; He, Z.B.; Ma, J.H.; Wang, Y.; Wang, Y.P. Learning Traffic as Images: A Deep Convolutional Neural Network for Large-Scale Transportation Network Speed Prediction. Sensors 2017, 17, 818. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ben Hamida, A.; Benoit, A.; Lambert, P.; Ben Amar, C. 3-D Deep Learning Approach for Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4420–4434. [Google Scholar] [CrossRef] [Green Version]
- Jingmei, L.; Zhenxin, X.; Jianli, L.; Jiaxiang, W. An Improved Human Action Recognition Method Based on 3D Convolutional Neural Network. In Advanced Hybrid Information Processing. ADHIP 2018. Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Liu, S., Yang, G., Eds.; Springer: Cham, Switzerland, 2019; Volume 279, pp. 37–46. [Google Scholar] [CrossRef]
- Liu, X.; Yang, X.D. Multi-stream with Deep Convolutional Neural Networks for Human Action Recognition in Videos. In Neural Information Processing. ICONIP 2018. Lecture Notes in Computer Science; Cheng, L., Leung, A.C.S., Ozawa, S., Eds.; Springer: Cham, Switzerland, 2018; Volume 11301, pp. 251–262. [Google Scholar]
- Saveliev, A.; Uzdiaev, M.; Dmitrii, M. Aggressive action recognition using 3D CNN architectures. In Proceedings of the 12th International Conference on Developments in eSystems Engineering 2019, Kazan, Russia, 7–10 October 2019; AlJumeily, D., Hind, J., Mustafina, J., AlHajj, A., Hussain, A., Magid, E., Tawfik, H., Eds.; IEEE: Piscataway, NJ, USA, 2019; pp. 890–895. [Google Scholar]
- Zhang, J.H.; Chen, L.; Tian, J. 3D Convolutional Neural Network for Action Recognition. In Computer Vision, Pt I; Yang, J., Hu, Q., Cheng, M.M., Wang, L., Liu, Q., Bai, X., Meng, D., Eds.; Springer: Singapore, 2017; Volume 771, pp. 600–607. [Google Scholar]
- Feng, S.Y.; Chen, T.Y.; Sun, H. Long Short-Term Memory Spatial Transformer Network. In Proceedings of the 2019 IEEE 8th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 24–26 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 239–242. [Google Scholar]
- Liang, L.; Cao, J.D.; Li, X.Y.; You, A.N. Improvement of Residual Attention Network for Image Classification. In Intelligence Science and Big Data Engineering. Visual Data Engineering. IScIDE 2019. Lecture Notes in Computer Science; Cui, Z., Pan, J., Zhang, S., Xiao, L., Yang, J., Eds.; Springer: Cham, Switzerland; New York, NY, USA, 2019; Volume 11935, pp. 529–539. [Google Scholar]
- Ling, H.F.; Wu, J.Y.; Huang, J.R.; Chen, J.Z.; Li, P. Attention-based convolutional neural network for deep face recognition. Multimed. Tools Appl. 2020, 79, 5595–5616. [Google Scholar] [CrossRef]
- Woo, S.H.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision-ECCV 2018, Part VII, Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: New York, NY, USA, 2018; Volume 11211, pp. 3–19. [Google Scholar]
- Zhong, X.; Gong, O.B.; Huang, W.X.; Li, L.; Xia, H.X. Squeeze-and-excitation wide residual networks in image classification. In Proceedings of the 2019 IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 395–399. [Google Scholar]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D-2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 277–281. [Google Scholar] [CrossRef] [Green Version]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Name | Training | Validation | Test | Total Samples |
|---|---|---|---|---|---|
| 1 | Alfalfa | 5 | 5 | 36 | 46 |
| 2 | Corn-notill | 143 | 143 | 1142 | 1428 |
| 3 | Corn-mintill | 83 | 83 | 664 | 830 |
| 4 | Corn | 24 | 24 | 189 | 237 |
| 5 | Grass-pasture | 48 | 48 | 387 | 483 |
| 6 | Grass-trees | 73 | 73 | 584 | 730 |
| 7 | Grass-pasture-mowed | 3 | 3 | 22 | 28 |
| 8 | Hay-windrowed | 48 | 48 | 382 | 478 |
| 9 | Oats | 2 | 2 | 16 | 20 |
| 10 | Soybean-notill | 97 | 97 | 778 | 972 |
| 11 | Soybean-mintill | 246 | 246 | 1963 | 2455 |
| 12 | Soybean-clean | 59 | 59 | 475 | 593 |
| 13 | Wheat | 21 | 21 | 163 | 205 |
| 14 | Woods | 127 | 127 | 1011 | 1265 |
| 15 | Buildings-Grass-Trees-Drives | 39 | 39 | 308 | 386 |
| 16 | Stone-Steel-Towers | 9 | 9 | 75 | 93 |
| Total | 1027 | 1027 | 8195 | 10,249 |
| Class | Name | Training | Validation | Test | Total Samples |
|---|---|---|---|---|---|
| 1 | Asphalt | 66 | 66 | 6499 | 6631 |
| 2 | Meadows | 186 | 186 | 18,277 | 18,649 |
| 3 | Gravel | 21 | 21 | 2057 | 2099 |
| 4 | Trees | 31 | 31 | 3002 | 3064 |
| 5 | Painted metal sheets | 13 | 13 | 1319 | 1345 |
| 6 | Bare Soil | 50 | 50 | 4929 | 5029 |
| 7 | Bitumen | 13 | 13 | 1304 | 1330 |
| 8 | Self-Blocking Bricks | 37 | 37 | 3608 | 3682 |
| 9 | Shadows | 9 | 9 | 929 | 947 |
| Total | 426 | 426 | 41,924 | 42,776 |
| Class | Name | Training | Validation | Test | Total Samples |
|---|---|---|---|---|---|
| 1 | Brocoli_green_weeds_1 | 20 | 20 | 1969 | 2009 |
| 2 | Brocoli_green_weeds_2 | 37 | 37 | 3652 | 3726 |
| 3 | Fallow | 20 | 20 | 1936 | 1976 |
| 4 | Fallow_rough_plow | 14 | 14 | 1366 | 1394 |
| 5 | Fallow_smooth | 27 | 27 | 2624 | 2678 |
| 6 | Stubble | 40 | 40 | 3879 | 3959 |
| 7 | Celery | 36 | 36 | 3507 | 3579 |
| 8 | Grapes_untrained | 113 | 113 | 11,045 | 11,271 |
| 9 | Soil_vinyard_develop | 62 | 62 | 6079 | 6203 |
| 10 | Corn_senesced_green_weeds | 33 | 33 | 3212 | 3278 |
| 11 | Lettuce_romaine_4wk | 11 | 11 | 1046 | 1068 |
| 12 | Lettuce_romaine_5wk | 19 | 19 | 1889 | 1927 |
| 13 | Lettuce_romaine_6wk | 9 | 9 | 898 | 916 |
| 14 | Lettuce_romaine_7wk | 11 | 11 | 1048 | 1070 |
| 15 | Vinyard_untrained | 73 | 73 | 7122 | 7268 |
| 16 | Vinyard_vertical_trellis | 18 | 18 | 1771 | 1807 |
| Total | 543 | 543 | 53,043 | 54,129 |
| Data | Learning Rate | Spectral Dimension (Input_1) | Spatial Size (Input_1) | Spectral Dimension (Input_2) | Spatial Size (Input_2) |
|---|---|---|---|---|---|
| IP | 0.001 | 27 | 9 | 9 | 33 |
| UP | 0.001 | 23 | 9 | 9 | 33 |
| SA | 0.001 | 27 | 9 | 9 | 33 |
| Class | SVM | 2DCNN | 3DCNN | SSRN | HybridSN | SSAN | TSSFAN |
|---|---|---|---|---|---|---|---|
| 1 | 0.00 | 81.71 | 99.92 | 98.70 | 95.12 | 92.68 | 100.00 |
| 2 | 27.62 | 93.69 | 95.10 | 95.83 | 95.95 | 95.18 | 96.45 |
| 3 | 9.77 | 97.86 | 99.06 | 99.87 | 97.99 | 99.33 | 99.67 |
| 4 | 7.04 | 94.13 | 98.12 | 96.94 | 97.18 | 98.76 | 97.03 |
| 5 | 63.79 | 98.50 | 97.70 | 97.81 | 100.00 | 99.95 | 99.00 |
| 6 | 94.06 | 98.32 | 98.17 | 98.70 | 98.93 | 98.48 | 99.29 |
| 7 | 0.00 | 94.07 | 96.00 | 99.96 | 96.01 | 98.00 | 100.00 |
| 8 | 99.30 | 99.53 | 99.53 | 100.00 | 99.30 | 99.10 | 99.85 |
| 9 | 0.00 | 61.11 | 83.33 | 88.88 | 77.78 | 94.44 | 89.81 |
| 10 | 25.80 | 97.43 | 98.06 | 98.97 | 98.17 | 98.51 | 98.80 |
| 11 | 91.35 | 98.26 | 99.50 | 99.25 | 98.96 | 99.01 | 99.24 |
| 12 | 50.46 | 94.94 | 94.76 | 95.60 | 98.13 | 97.38 | 95.47 |
| 13 | 69.56 | 96.49 | 98.38 | 99.73 | 97.84 | 99.46 | 99.55 |
| 14 | 95.21 | 98.90 | 99.12 | 99.90 | 99.74 | 99.91 | 99.81 |
| 15 | 47.55 | 97.69 | 97.12 | 97.55 | 99.14 | 99.42 | 99.61 |
| 16 | 88.09 | 91.67 | 95.24 | 96.43 | 78.57 | 95.24 | 97.22 |
| OA | 62.16 (0.58) | 97.1 (0.41) | 97.99 (0.22) | 98.44 (0.28) | 98.19 (0.15) | 98.49 (0.13) | 98.64 (0.13) |
| AA | 48.03 (0.67) | 93.38 (0.21) | 96.82 (0.30) | 97.76 (0.37) | 95.55 (0.24) | 97.81 (0.25) | 98.18 (0.31) |
| Kappa | 55.37 (0.39) | 96.69 (0.35) | 97.71 (0.11) | 98.22 (0.30) | 95.55 (0.18) | 98.28 (0.19) | 98.47 (0.17) |
| Class | SVM | 2DCNN | 3DCNN | SSRN | HybridSN | SSAN | TSSFAN |
|---|---|---|---|---|---|---|---|
| 1 | 89.47 | 84.50 | 94.76 | 96.89 | 95.03 | 95.52 | 97.40 |
| 2 | 94.13 | 98.95 | 99.46 | 99.94 | 99.77 | 99.98 | 99.91 |
| 3 | 22.90 | 59.31 | 95.33 | 94.08 | 90.42 | 92.60 | 95.82 |
| 4 | 82.36 | 70.94 | 81.40 | 90.66 | 87.83 | 95.15 | 92.41 |
| 5 | 99.24 | 95.27 | 99.25 | 99.67 | 97.30 | 99.27 | 99.94 |
| 6 | 34.27 | 92.49 | 95.82 | 97.00 | 99.92 | 99.95 | 99.75 |
| 7 | 0.08 | 75.06 | 89.37 | 82.71 | 99.32 | 97.87 | 98.47 |
| 8 | 77.94 | 69.46 | 82.52 | 94.63 | 96.84 | 89.78 | 95.25 |
| 9 | 40.19 | 41.08 | 69.80 | 95.97 | 74.07 | 99.47 | 97.55 |
| OA | 76.68 (0.47) | 87.32 (0.17) | 94.37 (0.22) | 97.07 (0.23) | 96.83 (0.12) | 97.56 (0.19) | 98.26 (0.14) |
| AA | 60.07 (0.40) | 76.34 (0.21) | 89.74 (0.19) | 94.61 (0.20) | 93.39 (0.26) | 96.62 (0.27) | 97.38 (0.28) |
| Kappa | 67.89 (0.28) | 83.01 (0.15) | 92.52 (0.14) | 94.61 (0.30) | 95.78 (0.16) | 96.76 (0.21) | 97.70 (0.23) |
| Class | SVM | 2DCNN | 3DCNN | SSRN | HybridSN | SSAN | TSSFAN |
|---|---|---|---|---|---|---|---|
| 1 | 97.33 | 95.85 | 98.99 | 92.88 | 99.39 | 99.45 | 99.41 |
| 2 | 97.70 | 96.88 | 99.81 | 99.27 | 99.90 | 100.00 | 100.00 |
| 3 | 77.24 | 91.00 | 97.03 | 99.84 | 99.59 | 99.95 | 99.97 |
| 4 | 57.97 | 83.98 | 94.64 | 96.93 | 95.38 | 99.99 | 99.96 |
| 5 | 98.90 | 89.68 | 99.55 | 97.68 | 98.32 | 99.70 | 98.37 |
| 6 | 99.20 | 97.23 | 99.77 | 99.49 | 99.66 | 99.95 | 99.97 |
| 7 | 99.54 | 98.68 | 98.90 | 99.46 | 99.81 | 99.94 | 99.87 |
| 8 | 70.09 | 97.89 | 95.86 | 98.50 | 99.45 | 96.98 | 97.24 |
| 9 | 99.67 | 98.62 | 100.00 | 99.95 | 99.89 | 99.99 | 99.99 |
| 10 | 89.30 | 96.33 | 97.32 | 97.65 | 98.91 | 98.64 | 99.56 |
| 11 | 89.68 | 87.22 | 94.32 | 97.69 | 98.04 | 99.62 | 99.30 |
| 12 | 93.71 | 90.85 | 79.19 | 91.68 | 95.07 | 99.58 | 100.00 |
| 13 | 63.83 | 79.65 | 93.38 | 97.61 | 87.10 | 96.69 | 98.66 |
| 14 | 96.78 | 91.88 | 97.17 | 96.98 | 98.17 | 99.15 | 98.41 |
| 15 | 75.20 | 90.41 | 99.78 | 98.62 | 97.44 | 97.23 | 98.65 |
| 16 | 97.65 | 97.37 | 96.25 | 99.12 | 99.72 | 95.92 | 98.82 |
| OA | 86.27 (0.64) | 94.81 (0.21) | 97.39 (0.11) | 98.29 (0.29) | 98.70 (0.16) | 98.64 (0.23) | 99.02 (0.12) |
| AA | 87.74 (0.42) | 92.71 (0.37) | 96.37 (0.41) | 97.70 (0.23) | 97.86 (0.33) | 98.92 (0.28) | 99.25 (0.05) |
| Kappa | 84.73 (0.51) | 94.21 (0.18) | 97.09 (0.23) | 98.1 (0.26) | 98.55 (0.20) | 98.48 (0.31) | 98.87 (0.16) |
| Data | 2DCNN | 3DCNN | TSSFAN | |||
|---|---|---|---|---|---|---|
| Training(s) | Testing(s) | Training(s) | Testing(s) | Training(s) | Testing(s) | |
| IP | 72.1 | 1.4 | 306.0 | 3.8 | 204.3 | 2.5 |
| UP | 45.4 | 2.2 | 177.6 | 11.4 | 110.3 | 4.3 |
| SA | 48.5 | 2.7 | 192.1 | 14.5 | 125.4 | 5.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, H.; Li, D.; Wang, Y.; Li, X.; Kong, F.; Wang, Q. Hyperspectral Image Classification Based on Two-Branch Spectral–Spatial-Feature Attention Network. Remote Sens. 2021, 13, 4262. https://doi.org/10.3390/rs13214262
Wu H, Li D, Wang Y, Li X, Kong F, Wang Q. Hyperspectral Image Classification Based on Two-Branch Spectral–Spatial-Feature Attention Network. Remote Sensing. 2021; 13(21):4262. https://doi.org/10.3390/rs13214262
Chicago/Turabian StyleWu, Hanjie, Dan Li, Yujian Wang, Xiaojun Li, Fanqiang Kong, and Qiang Wang. 2021. "Hyperspectral Image Classification Based on Two-Branch Spectral–Spatial-Feature Attention Network" Remote Sensing 13, no. 21: 4262. https://doi.org/10.3390/rs13214262