
Evaluating the Ability to Use Contextual Features Derived from Multi-Scale Satellite Imagery to Map Spatial Patterns of Urban Attributes and Population Distributions


Abstract
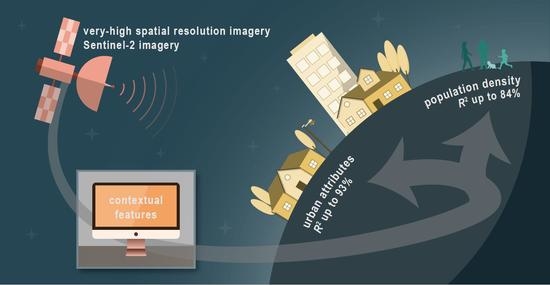
:
1. Introduction
1.1. Population Estimation Techniques
1.2. Spatial Features and Remote Sensing
- What do contextual features derived from VHSR imagery represent in the human-modified landscape?
- How do these representations of the landscape change as the spatial resolution of the satellite imagery changes (from VHSR imagery to Sentinel-2 imagery)?
- How do contextual features derived from Sentinel-2 relate to population density based on census data?
- To what extent can a population density model be built based on contextual features to allow for the dasymetric mapping of population density in multiple countries?
2. Materials and Methods
2.1. Study Areas
2.1.1. Accra, Ghana
2.1.2. Belize
2.1.3. Sri Lanka
2.2. Data Acquisition
2.2.1. Multispectral Satellite Imagery
2.2.2. Urban Attributes
2.2.3. Population
2.3. Data Processing
2.3.1. Contextual Features
2.3.2. Urban Attributes
2.3.3. Population Density
2.4. Data Preparation
2.5. Model Building
2.5.1. Elastic Net Regularized Regression
2.5.2. Random Forest Regression
3. Results
3.1. Human-Modified Landscape and Very-High-Spatial-Resolution Imagery Contextual Features
3.2. Human-Modified Landscape and Imagery Spatial Resolution
3.3. Human-Modified Landscape and Sentinel-2 Imagery Contextual Features
3.4. Population Density and Sentinel-2 Contextual Features
4. Discussion
4.1. Human-Modified Landscape and Very-High-Spatial-Resolution Imagery Contextual Features
4.2. Human-Modified Landscape and Imagery Spatial Resolution
4.3. Human-Modified Landscape and Sentinel-2 Imagery Contextual Features
4.4. Population Density and Sentinel-2 Contextual Features
4.5. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Population Division, Department of Economic and Social Affairs, United Nations. World Urbanization Prospects; The 2018 Revision (ST/ESA/SER.A/420); United Nations: New York, NY, USA, 2019; ISBN 978-92-1-148319-2. [Google Scholar]
- Curtis, K.J.; Schneider, A. Understanding the demographic implications of climate change: Estimates of localized population predictions under future scenarios of sea-level rise. Popul. Environ. 2011, 33, 28–54. [Google Scholar] [CrossRef]
- Linard, C.; Tatem, A.J. Large-scale spatial population databases in infectious disease research. Int. J. Health Geogr. 2012, 11, 7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marandola, E.; Hogan, D.J. Vulnerabilities and risks in population and environment studies. Popul. Environ. 2006, 28, 83–112. [Google Scholar] [CrossRef]
- National Research Council. Tools and Methods for Estimating Populations at Risk from Natural Disasters and Complex Humanitarian Crises; The National Academies Press: Washington, DC, USA, 2007; ISBN 978-0-309-10354-1. [Google Scholar]
- Noji, E.K. Estimating population size in emergencies. Bull. World Health Organ. 2005, 83, 164. [Google Scholar]
- Pal, A.; Graettinger, A.J.; Triche, M.H. Emergency Evacuation Modeling Based on Geographical Information System Data. In Proceedings of the Transportation Research Board 82nd Annual Meeting, Washington, DC, USA, 12–16 January 2003; pp. 1–16. [Google Scholar]
- Tatem, A.J. Mapping the denominator: Spatial demography in the measurement of progress. Int. Health 2014, 6, 153–155. [Google Scholar] [CrossRef] [Green Version]
- Benn, H.P. Bus Route Evaluation Standards; National Academy Press: Washington, DC, USA, 1995; ISBN 978-0-309-05855-1. [Google Scholar]
- Clogg, C.C.; Massagli, M.P.; Eliason, S.R. Population undercount and social science research. Soc. Indic. Res. 1989, 21, 559–598. [Google Scholar] [CrossRef]
- Guiteras, R.; Levinsohn, J.; Mobarak, A.M. Demand Estimation with Strategic Complementarities: Sanitation in Bangladesh; CEPR Discussion Paper No. DP13498; Centre for Economic Policy Research: London, UK, 2019; Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3328509 (accessed on 16 February 2020).
- Schirm, A.L.; Preston, S.H. Census undercount adjustment and the quality of geographic population distributions. J. Am. Stat. Assoc. 1987, 82, 965–978. [Google Scholar] [CrossRef]
- United Nations. Principles and Recommendations for Population and Housing Censuses (Revision 3); United Nations: New York, NY, USA, 2017; ISBN 978-92-1-161597-5. [Google Scholar]
- Luo, W.; Wang, F. Measures of spatial accessibility to health care in a GIS environment: Synthesis and a case study in the Chicago region. Environ. Plan. B Plan. Des. 2003, 30, 865–884. [Google Scholar] [CrossRef] [Green Version]
- Plane, D.A.; Rogerson, P.A. The Geographical Analysis of Population with Applications to Planning and Business; John Wiley & Sons, Inc.: New York, NY, USA, 1994; ISBN 978-047-151-014-7. [Google Scholar]
- Tayman, J.; Pol, L. Retail site selection and geographic information systems. J. Appl. Bus. Res. 1995, 11, 46–54. [Google Scholar] [CrossRef]
- Carr, D.L. Proximate population factors and deforestation in tropical agricultural frontiers. Popul. Environ. 2004, 25, 585–612. [Google Scholar] [CrossRef] [Green Version]
- De Sherbinin, A.; Carr, D.; Cassels, S.; Jiang, L. Population and environment. Annu. Rev. Environ. Resour. 2007, 32, 345–373. [Google Scholar] [CrossRef] [PubMed]
- Wardrop, N.A.; Jochem, W.C.; Bird, T.J.; Chamberlain, H.R.; Clarke, D.; Kerr, D.; Bengtsson, L.; Juran, S.; Seaman, V.; Tatem, A.J. Spatially Disaggregated Population Estimates in the Absence of National Population and Housing Census Data. Proc. Natl. Acad. Sci. USA 2018, 115, 3529–3537. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jia, P.; Qiu, Y.; Gaughan, A.E. A fine-scale spatial population distribution on the high-resolution gridded population surface and application in Alachua County, Florida. Appl. Geogr. 2014, 50, 99–107. [Google Scholar] [CrossRef]
- Mennis, J. Dasymetric mapping for estimating population in small areas. Geogr. Compass 2009, 3, 727–745. [Google Scholar] [CrossRef]
- Zandbergen, P.A.; Ignizio, D.A. Comparison of dasymetric mapping techniques for small-area population estimates. Cartogr. Geogr. Inf. Sci. 2010, 37, 199–214. [Google Scholar] [CrossRef]
- Holt, J.B.; Lo, C.P.; Hodler, T.W. Dasymetric estimation of population density and areal interpolation of census data. Cartogr. Geogr. Inf. Sci. 2004, 31, 103–121. [Google Scholar] [CrossRef]
- Tatem, A.J.; Noor, A.M.; von Hagen, C.; Di Gregorio, A.; Hay, S.I. High resolution population maps for low income nations: Combining land cover and census in East Africa. PLoS ONE 2007, 2, e1298. [Google Scholar] [CrossRef]
- Ye, Y.; Wamukoya, M.; Ezeh, A.; Emina, J.B.O.; Sankoh, O. Health and demographic surveillance systems: A step towards full civil registration and vital statistics system in sub-Sahara Africa? BMC Public Health 2012, 12, 741. [Google Scholar] [CrossRef] [Green Version]
- Zhu, H.; Li, Y.; Liu, Z.; Fu, B. Estimating the population distribution in a county area in China based on impervious surfaces. Photogramm. Eng. Remote Sens. 2015, 81, 155–163. [Google Scholar] [CrossRef]
- Wu, S.-S.; Qiu, X.; Wang, L. Population estimation methods in GIS and remote sensing: A review. GIsci. Remote Sens. 2005, 42, 80–96. [Google Scholar] [CrossRef]
- Li, G.; Weng, Q. Fine-scale population estimation: How Landsat ETM+ imagery can improve population distribution mapping. Can. J. Remote Sens. 2010, 36, 155–165. [Google Scholar] [CrossRef]
- Karume, K.; Schmidt, C.; Kundert, K.; Bagula, M.E.; Safina, B.F.; Schomacker, R.; Ganza, D.; Azanga, O.; Nfundiko, C.; Karume, N.; et al. Use of remote sensing for population number determination. Open Access J. Sci. Technol. 2017, 5, 101227. [Google Scholar] [CrossRef] [PubMed]
- Nagle, N.N.; Buttenfield, B.P.; Leyk, S.; Spielman, S. Dasymetric modeling and uncertainty. Ann. Assoc. Am. Geogr. 2014, 104, 80–95. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Peng, Z.; Wu, H.; Jiao, H.; Yu, Y. Exploring urban spatial feature with dasymetric mapping based on mobile phone data and LUR-2SFCAe method. Sustainability 2018, 10, 2432. [Google Scholar] [CrossRef] [Green Version]
- Engstrom, R.; Newhouse, D.; Soundararajan, V. Estimating small-area population density in Sri Lanka using surveys and geo-spatial data. PLoS ONE 2020, 15, e0237063. [Google Scholar] [CrossRef]
- Hersh, J.; Engstrom, R.; Mann, M. Open data for algorithms: Mapping poverty in Belize using open satellite derived features and machine learning. Inf. Technol. Dev. 2020, 27, 263–292. [Google Scholar] [CrossRef]
- Li, G.; Weng, Q. Using Landsat ETM+ imagery to measure population density in Indianapolis, Indiana, USA. Photogramm. Eng. Remote Sens. 2005, 71, 947–958. [Google Scholar] [CrossRef] [Green Version]
- Azar, D.; Graesser, J.; Engstrom, R.; Comenetz, J.; Leddy, R.M.; Schechtman, N.G.; Andrews, T. Spatial refinement of census population distribution using remotely sensed estimates of impervious surfaces in Haiti. Int. J. Remote Sens. 2010, 31, 5635–5655. [Google Scholar] [CrossRef]
- Freire, S.; Kemper, T.; Pesaresi, M.; Florczyk, A.; Syrris, V. Combining GHSL and GPW to Improve Global Population Mapping. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 2541–2543. [Google Scholar]
- Li, L.; Lu, D. Mapping population density distribution at multiple scales in Zhejiang Province using Landsat Thematic Mapper and census data. Int. J. Remote Sens. 2016, 37, 4243–4260. [Google Scholar] [CrossRef]
- Wu, C.; Murray, A.T. Population estimation using Landsat Enhanced Thematic Mapper imagery. Geogr. Anal. 2007, 39, 26–43. [Google Scholar] [CrossRef]
- Calka, B.; Bielecka, E.; Zdunkiewicz, K. Redistribution population data across a regular spatial grid according to buildings characteristics. Geod. Cartogr. 2016, 65, 149–162. [Google Scholar] [CrossRef]
- Silván-Cárdenas, J.L.; Wang, L.; Rogerson, P.; Wu, C.; Feng, T.; Kamphaus, B.D. Assessing fine-spatial-resolution remote sensing for small-area population estimation. Int. J. Remote Sens. 2010, 31, 5605–5634. [Google Scholar] [CrossRef]
- Tomás, L.; Fonseca, L.; Almeida, C.; Leonardi, F.; Pereira, M. Urban population estimation based on residential buildings volume using IKONOS-2 images and LIDAR data. Int. J. Remote Sens. 2016, 37, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Joseph, M.; Wang, L.; Wang, F. Using Landsat imagery and census data for urban population density modeling in Port-au-Prince, Haiti. GIsci. Remote Sens. 2012, 49, 228–250. [Google Scholar] [CrossRef]
- Anderson, S.J.; Tuttle, B.T.; Powell, R.L.; Sutton, P.C. Characterizing relationships between population density and nighttime imagery for Denver, Colorado: Issues of scale and representation. Int. J. Remote Sens. 2010, 31, 5733–5746. [Google Scholar] [CrossRef]
- Chen, X.; Nordhaus, W. A test of the new VIIRS lights data set: Population and economic output in Africa. Remote Sens. 2015, 7, 4937–4947. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Chen, Y.; Li, Y. The random forest-based method of fine-resolution population spatialization by using the International Space Station nighttime photography and social sensing data. Remote Sens. 2018, 10, 1650. [Google Scholar] [CrossRef] [Green Version]
- Lo, C.P. Modeling the population of China using DMSP Operational Linescan System nighttime data. Photogramm. Eng. Remote Sens. 2001, 67, 1037–1047. [Google Scholar]
- Azar, D.; Engstrom, R.; Graesser, J.; Comenetz, J. Generation of fine-scale population layers using multi-resolution satellite imagery and geospatial data. Remote Sens. Environ. 2013, 130, 219–232. [Google Scholar] [CrossRef]
- Bagan, H.; Yamagata, Y. Analysis of urban growth and estimating population density using satellite images of nighttime lights and land-use and population data. GIsci. Remote Sens. 2015, 52, 765–780. [Google Scholar] [CrossRef]
- Li, X.; Zhou, W. Dasymetric mapping of urban population in China based on radiance corrected DMSP-OLS nighttime light and land cover data. Sci. Total Environ. 2018, 643, 1248–1256. [Google Scholar] [CrossRef]
- Stevens, F.R.; Gaughan, A.E.; Linard, C.; Tatem, A.J. Disaggregating census data for population mapping using random forests with remotely-sensed and ancillary data. PLoS ONE 2015, 10, e0107042. [Google Scholar] [CrossRef] [Green Version]
- Bayram, U.; Can, G.; Duzgun, S.; Yalabik, N. Evaluation of Textural Features for Multispectral Images. In Image and Signal Processing for Remote Sensing XVII, Proceedings of the SPIE Remote Sensing, Prague, Czech Republic, 26 October 2011; SPIE: Prague, Czech Republic, 2011; Volume 8180, pp. 81800I-1–81800I-14. [Google Scholar]
- Sandborn, A.; Engstrom, R.N. Determining the relationship between census data and spatial features derived from high-resolution imagery in Accra, Ghana. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1970–1977. [Google Scholar] [CrossRef]
- Puissant, A.; Hirsch, J.; Weber, C. The utility of texture analysis to improve per-pixel classification for high to very high spatial resolution imagery. Int. J. Remote Sens. 2005, 26, 733–745. [Google Scholar] [CrossRef]
- Abeigne Ella, L.P.; van den Bergh, F.; van Wyk, B.J.; van Wyk, M.A. A Comparison of Texture Feature Algorithms for Urban Settlement Classification. In Proceedings of the IGARSS 2008—2008 IEEE International Geoscience and Remote Sensing Symposium, Boston, MA, USA, 7–11 July 2008; pp. III-1308–III-1311. [Google Scholar]
- Zhang, Q.; Wang, J.; Gong, P.; Shi, P. Study of urban spatial patterns from SPOT panchromatic imagery using textural analysis. Int. J. Remote Sens. 2003, 24, 4137–4160. [Google Scholar] [CrossRef]
- Graesser, J.; Cheriyadat, A.; Vatsavai, R.R.; Chandola, V.; Long, J.; Bright, E. Image based characterization of formal and informal neighborhoods in an urban landscape. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1164–1176. [Google Scholar] [CrossRef]
- Engstrom, R.; Sandborn, A.; Yu, Q.; Burgdorfer, J.; Stow, D.; Weeks, J.; Graesser, J. Mapping Slums using Spatial Features in Accra, Ghana. In Proceedings of the 2015 Joint Urban Remote Sensing Event (JURSE), Lausanne, Switzerland, 30 March–1 April 2015; pp. 1–4. [Google Scholar]
- Engstrom, R.; Harrison, R.; Mann, M.; Fletcher, A. Evaluating the Relationship between Contextual Features Derived from Very High Spatial Resolution Imagery and Urban Attributes: A Case Study in Sri Lanka. In Proceedings of the 2019 Joint Urban Remote Sensing Event (JURSE), Vannes, France, 22–24 May 2019; pp. 1–4. [Google Scholar]
- Engstrom, R.; Hersh, J.; Newhouse, D. Poverty from Space: Using High-Resolution Satellite Imagery for Estimating Economic Well-Being (English); (Working Paper No. WPS8284); World Bank Group: Washington, DC, USA, 2017; Available online: http://documents.worldbank.org/curated/en/610771513691888412/pdf/WPS8284.pdf (accessed on 14 April 2019).
- Engstrom, R.; Newhouse, D.; Haldavanekar, V.; Copenhaver, A.; Hersh, J. The Relationship between Spatial and Spectral Features Derived from High Spatial Resolution Satellite Data and Urban Poverty in Colombo, Sri Lanka. In Proceedings of the 2017 Joint Urban Remote Sensing Event (JURSE), Dubai, United Arab Emirates, 6–8 March 2017; pp. 1–4. [Google Scholar]
- Wang, L.; Wu, C. Population estimation using remote sensing and GIS technologies. Int. J. Remote Sens. 2010, 31, 5569–5570. [Google Scholar] [CrossRef]
- Tiecke, T.G.; Liu, X.; Zhang, A.; Gros, A.; Li, N.; Yetman, G.; Kilic, T.; Murray, S.; Blankespoor, B.; Prydz, E.B.; et al. Mapping the world population one building at a time. arXiv 2017, arXiv:1712.05839. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Ghana Statistical Service. [dataset] Ghana Census and Shapefile. 2010. Available online: https://statsghana.gov.gh (accessed on 5 January 2020).
- Statistical Institute of Belize. [dataset] Belize Census and Shapefile. 2010. Available online: http://sib.org.bz (accessed on 5 January 2020).
- Department of Census and Statistics. [dataset] Sri Lanka Census and Shapefile. 2012. Available online: http://www.map.statistics.gov.lk (accessed on 5 January 2020).
- DIVA-GIS. [dataset] (n.d.) Country Administrative Areas Shapefiles. Available online: https://diva-gis.org/gdata (accessed on 5 January 2020).
- Natural Earth. [dataset] Admin 0—Countries. 2018. Available online: https://www.naturalearthdata.com/downloads/10m-cultural-vectors/10m-admin-0-countries/ (accessed on 5 January 2020).
- Ghana Statistical Service. 2010 Population & Housing Census—District Analytical Report: La Dade-Kotopon Municipality; Ghana Statistical Service: Accra, Ghana, 2014. Available online: https://www2.statsghana.gov.gh/docfiles/2010_District_Report/Greater%20Accra/LA%20DADEkotopon.pdf (accessed on 20 February 2021).
- Ghana Statistical Service. 2010 Population & Housing Census—District Analytical Report: Accra Metropolitan; Ghana Statistical Service: Accra, Ghana, 2014. Available online: https://new-ndpc-static1.s3.amazonaws.com/CACHES/PUBLICATIONS/2016/06/06/AMA.pdf (accessed on 20 February 2021).
- Ghana Statistical Service. 2010 Population & Housing Census—District Analytical Report: Ledzokuku-Krowor Municipality; Ghana Statistical Service: Accra, Ghana, 2014. Available online: https://www2.statsghana.gov.gh/docfiles/2010_District_Report/Greater%20Accra/LEKMA.pdf (accessed on 20 February 2021).
- Kwankye, S.O.; Cofie, E. Ghana’s population policy implementation: Past, present and future. Etude Popul. Afr. 2015, 29, 1734–1748. [Google Scholar] [CrossRef] [Green Version]
- Owusu, G.; Afutu-Kotey, R.L. Poor urban communities and municipal interface in Ghana: A case study of Accra and Sekondi-Takoradi Metropolis. Afr. Stud. Q. 2010, 12, 1–16. [Google Scholar]
- Akubia, J.E.K.; Bruns, A. Unravelling the frontiers of urban growth: Spatio-temporal dynamics of land-use change and urban expansion in Greater Accra Metropolitan Area, Ghana. Land 2019, 8, 131. [Google Scholar] [CrossRef] [Green Version]
- Armah, F.A.; Odoi, J.O.; Yengoh, G.T.; Obiri, S.; Yawson, D.O.; Afrifa, E.K.A. Food security and climate change in drought-sensitive savanna zones of Ghana. Mitig. Adapt. Strateg. Glob. Chang. 2011, 16, 291–306. [Google Scholar] [CrossRef]
- Owusu, G. Coping with Urban Sprawl: A Critical Discussion of the Urban Containment Strategy in a Developing Country City, Accra. In Proceedings of the Cities to Be Tamed? Standards and Alternatives in the Transformation of the Urban South, Milan, Italy, 15–17 November 2012; Planum: Rome, Italy, 2013; Volume 1, pp. 1–17. [Google Scholar]
- Stow, D.A.; Weeks, J.R.; Toure, S.; Coulter, L.L.; Lippitt, C.D.; Ashcroft, E. Urban vegetation cover and vegetation change in Accra, Ghana: Connection to housing quality. Prof. Geogr. 2013, 65, 451–465. [Google Scholar] [CrossRef] [Green Version]
- Teye, J. Urbanization and Migration in Africa; Population Division, Department of Economic and Social Affairs, United Nations: New York, NY, USA, 2018; Available online: https://www.un.org/en/development/desa/population/events/pdf/expert/28/EGM_Joseph_Teye.pdf (accessed on 2 February 2021).
- Statistical Institute of Belize. Abstract of Statistics 2013; Statistical Institute of Belize: Belmopan, Belize, 2013. Available online: https://sib.org.bz/wp-content/uploads/2017/05/2013_Abstract_of_Statistics.pdf (accessed on 27 January 2020).
- Statistical Institute of Belize. Compendium of Statistics—2015; Statistical Institute of Belize: Belmopan, Belize, 2015. Available online: https://sib.org.bz/wp-content/uploads/2015_Abstract_of_Statistics.pdf (accessed on 27 January 2020).
- Day, M.J. Landscape and environment in Belize: An introduction. Caribb. Geogr. 2013, 13, 3–13. [Google Scholar]
- World Bank Group. Belize Housing Policy: Diagnosis and Guidelines for Action; Report No. 62906—BZ; World Bank Group: Washington, DC, USA, 2011; Available online: https://collaboration.worldbank.org/content/usergenerated/asi/cloud/attachments/sites/collaboration-for-development/en/groups/affordable-housing-ksb-c4d/documents/jcr:content/content/primary/blog/belize_housing_polic-jAIQ/Belize%20Housing%20Policy%20Diagnosis%20and%20guidelines%20for%20action.pdf (accessed on 28 January 2020).
- World Bank Group. [dataset] World Development Indicators. 2019. Available online: https://databank.worldbank.org/source/world-development-indicators (accessed on 18 March 2020).
- Munoz, I.; Gibson, D.V. Belize: Decoding the Census; IC2 Institute: Austin, TX, USA, 2015; Available online: https://repositories.lib.utexas.edu/bitstream/handle/2152/47365/munoz-2015-belize-decoding-the-census.pdf (accessed on 11 November 2019).
- Jackiewicz, E.L.; Govdyak, O. Diversity of lifestyle: A view from Belize. Yearb. Assoc. Pac. Coast Geogr. 2015, 77, 18–39. [Google Scholar] [CrossRef]
- Department of Census and Statistics. Census of Population and Housing: Sri Lanka 2012; Department of Census and Statistics: Battaramulla, Sri Lanka, 2012. Available online: http://www.statistics.gov.lk/PopHouSat/CPH2011/index.php?fileName=SriLanka&gp=Activities&tpl=3 (accessed on 2 February 2020).
- Department of Census and Statistics. Housing Tables; Department of Census and Statistics: Battaramulla, Sri Lanka, 2015. Available online: http://www.statistics.gov.lk/PopHouSat/CPH2011/Pages/Activities/Reports/Finalhousing.pdf (accessed on 2 February 2020).
- Ministry of Housing and Construction. Housing and Sustainable Urban Development in Sri Lanka—National Report for the Third United Nations Conference on Human Settlements Habitat III; Ministry of Housing and Construction of the Government of Democratic Socialist Republic of Sri Lanka: Battaramulla, Sri Lanka, 2016. Available online: https://uploads.habitat3.org/hb3/Sri-Lanka-(Final-in-English).pdf (accessed on 14 January 2020).
- World Bank Group. Leveraging Urbanization in Sri Lanka. Available online: https://www.worldbank.org/en/country/srilanka/brief/leveraging-urbanization-sri-lanka (accessed on 4 February 2020).
- DigitalGlobe. [Dataset] WorldView-2 Imagery of Colombo. 2010. Available online: https://discover.digitalglobe.com (accessed on 4 February 2020).
- DigitalGlobe. [Dataset] WorldView-2 Imagery of Kurunegala. 2012. Available online: https://discover.digitalglobe.com (accessed on 4 February 2020).
- DigitalGlobe. [Dataset] GeoEye-1 Imagery of Batticaloa and Negombo. 2010. Available online: https://discover.digitalglobe.com (accessed on 4 February 2020).
- European Space Agency. [dataset] Sentinel-2 Imagery of Belize and Sri Lanka. 2018. Available online: https://developers.google.com/earth-engine/datasets/catalog/COPERNICUS_S2 (accessed on 27 August 2018).
- European Space Agency. [dataset] Sentinel-2 Imagery of Accra. 2020. Available online: https://developers.google.com/earth-engine/datasets/catalog/COPERNICUS_S2 (accessed on 2 July 2021).
- OpenStreetMap. [Dataset] Buildings and Roads Shapefile. 2019. Available online: https://www.openstreetmap.org (accessed on 20 August 2019).
- OpenStreetMap. [Dataset] Buildings and Roads Shapefile. 2020. Available online: https://www.openstreetmap.org (accessed on 25 June 2020).
- OpenStreetMap. About OpenStreetMap. Available online: https://wiki.openstreetmap.org/wiki/About_OpenStreetMap (accessed on 3 May 2021).
- Graesser, J. SpFeas. Available online: https://github.com/jgrss/spfeas (accessed on 5 March 2019).
- Jensen, J.R. Introductory Digital Image Processing: A Remote Sensing Perspective, 2nd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 1996; ISBN 978-013-205-840-7. [Google Scholar]
- King, M. Fourier transform. In Statistics for Process Control Engineers: A Practical Approach; John Wiley & Sons Ltd.: Hoboken, NJ, USA, 2017; pp. 305–313. ISBN 978-111-938-350-5. [Google Scholar]
- Couteron, P. Quantifying change in patterned semi-arid vegetation by Fourier analysis of digitized aerial photographs. Int. J. Remote Sens. 2002, 23, 3407–3425. [Google Scholar] [CrossRef]
- Chen, C.; Zhou, L.; Guo, J.; Li, W.; Su, H.; Guo, F. Gabor-Filtering-Based Completed Local Binary Patterns for Land-Use Scene Classification. In Proceedings of the 2015 IEEE International Conference on Multimedia Big Data, Beijing, China, 20–22 April 2015; pp. 324–329. [Google Scholar]
- Li, W.; Du, Q. Gabor-filtering-based nearest regularized subspace for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1012–1022. [Google Scholar] [CrossRef]
- Yang, K.; Li, M.; Liu, Y.; Cheng, L.; Huang, Q.; Chen, Y. River detection in remotely sensed imagery using Gabor filtering and path opening. Remote Sens. 2015, 7, 8779–8802. [Google Scholar] [CrossRef] [Green Version]
- Bianconi, F.; Fernández, A. Evaluation of the effects of Gabor filter parameters on texture classification. Pattern Recognit. 2007, 40, 3325–3335. [Google Scholar] [CrossRef] [Green Version]
- Rajadell, O.; García-Sevilla, P.; Pla, F. Spectral-spatial pixel characterization using Gabor filters for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2013, 10, 860–864. [Google Scholar] [CrossRef] [Green Version]
- Risojević, V.; Momić, S.; Babić, Z. Gabor descriptors for aerial image classification. In Adaptive and Natural Computing Algorithms; Dobnikar, A., Lotrič, U., Šter, B., Eds.; Springer: Heidelberg, Germany, 2011; Volume 6594, pp. 51–60. ISBN 978-3-642-20266-7. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Torrione, P.A.; Morton, K.D.; Sakaguchi, R.; Collins, L.M. Histograms of oriented gradients for landmine detection in ground-penetrating RADAR data. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1539–1550. [Google Scholar] [CrossRef]
- Lee, K.L.; Mokji, M.M. Automatic Target Detection in GPR Images Using Histogram of Oriented Gradients (HOG). In Proceedings of the 2014 2nd International Conference on Electronic Design (ICED), Penang, Malaysia, 19–21 August 2014; pp. 181–186. [Google Scholar]
- Lei, Z.; Fang, T.; Li, D. Histogram of oriented gradient detector with color-invariant gradients in Gaussian color space. Opt. Eng. 2010, 49, 109701. [Google Scholar] [CrossRef]
- Myint, S.W.; Mesev, V.; Lam, N. Urban textural analysis from remote sensor data: Lacunarity measurements based on the differential box counting method. Geogr. Anal. 2006, 38, 371–390. [Google Scholar] [CrossRef]
- Quan, Y.; Xu, Y.; Sun, Y.; Luo, Y. Lacunarity Analysis on Image Patterns for Texture Classification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 160–167. [Google Scholar]
- Henebry, G.M.; Kux, H.J.H. Lacunarity as a texture measure for SAR imagery. Int. J. Remote Sens. 1995, 16, 565–571. [Google Scholar] [CrossRef]
- Plotnick, R.E.; Gardner, R.H.; Hargrove, W.W.; Prestegaard, K.; Perlmutter, M. Lacunarity analysis: A general technique for the analysis of spatial patterns. Phys. Rev. E 1996, 53, 5461–5468. [Google Scholar] [CrossRef] [Green Version]
- Dong, P. Test of a new lacunarity estimation method for image texture analysis. Int. J. Remote Sens. 2000, 21, 3369–3373. [Google Scholar] [CrossRef]
- Burns, J.B.; Hanson, A.R.; Riseman, E.M. Extracting straight lines. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 425–455. [Google Scholar] [CrossRef]
- Ünsalan, C. Gradient-magnitude-based support regions in structural land use classification. IEEE Geosci. Remote Sens. Lett. 2006, 3, 546–550. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikäinen, M.; Mäenpää, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Guo, Z.; Zhang, L.; Zhang, D. A completed modeling of local binary pattern operator for texture classification. IEEE Trans. Image Process. 2010, 19, 1657–1663. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, D.; Shan, C.; Ardabilian, M.; Wang, Y.; Chen, L. Local binary patterns and its application to facial image analysis: A survey. IEEE Trans. Syst. Man Cybern. C Appl. Rev. 2011, 41, 765–781. [Google Scholar] [CrossRef] [Green Version]
- Zhao, G.; Ahonen, T.; Matas, J.; Pietikäinen, M. Rotation-invariant image and video description with local binary pattern features. IEEE Trans. Image Process. 2012, 21, 1465–1477. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Chen, C.; Su, H.; Du, Q. Local binary patterns and extreme learning machine for hyperspectral imagery classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3681–3693. [Google Scholar] [CrossRef]
- Bolstad, P. GIS Fundamentals: A First Text on Geographic Information Systems, 5th ed.; XanEdu: Acton, MA, USA, 2016; ISBN 978-150-669-587-7. [Google Scholar]
- Fung, T.; Siu, W. Environmental quality and its changes, an analysis using NDVI. Int. J. Remote Sens. 2000, 21, 1011–1024. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An Efficient Alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Kulkarni, A.V.; Jagtap, J.S.; Harpale, V.K. Object recognition with ORB and its implementation on FPGA. Int. J. Adv. Comput. Res. 2013, 3, 156–162. [Google Scholar]
- Wu, S.; Fan, Y.; Zheng, S.; Yang, H. Object Tracking Based on ORB and Temporal-Spacial Constraint. In Proceedings of the 2012 IEEE Fifth International Conference on Advanced Computational Intelligence (ICACI), Nanjing, China, 18–20 October 2012; pp. 597–600. [Google Scholar]
- Lei, Y.; Yu, Z.; Gong, Y. An improved ORB algorithm of extracting and matching features. IJSIP 2015, 8, 117–126. [Google Scholar] [CrossRef] [Green Version]
- Wang, R.; Zhang, W.; Shi, Y.; Wang, X.; Cao, W. GA-ORB: A new efficient feature extraction algorithm for multispectral images based on geometric algebra. IEEE Access 2019, 7, 71235–71244. [Google Scholar] [CrossRef]
- Xu, J.; Chang, H.-W.; Yang, S.; Wang, M. Fast feature-based video stabilization without accumulative global motion estimation. IEEE Trans. Consum. Electron. 2012, 58, 993–999. [Google Scholar] [CrossRef]
- Pham, T.H.; Tran, P.; Lam, S.-K. High-throughput and area-optimized architecture for rBRIEF feature extraction. IEEE Trans. Very Large Scale Integr. VLSI Syst. 2019, 27, 747–756. [Google Scholar] [CrossRef]
- Pesaresi, M.; Gerhardinger, A. Improved textural built-up presence index for automatic recognition of human settlements in arid regions with scattered vegetation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 16–26. [Google Scholar] [CrossRef]
- Pesaresi, M.; Gerhardinger, A.; Kayitakire, F. A robust built-up area presence index by anisotropic rotation-invariant textural measure. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2008, 1, 180–192. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L.; Li, P. Classification and extraction of spatial features in urban areas using high-resolution multispectral imagery. IEEE Geosci. Remote Sens. Lett. 2007, 4, 260–264. [Google Scholar] [CrossRef]
- Sghaier, M.O.; Foucher, S.; Lepage, R. River extraction from high-resolution SAR images combining a structural feature set and mathematical morphology. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1025–1038. [Google Scholar] [CrossRef]
- Esri. [dataset] World Imagery Basemap. 2021. Available online: https://www.arcgis.com/home/item.html?id=10df2279f9684e4a9f6a7f08febac2a9 (accessed on 27 April 2021).
- Ramm, F. OpenStreetMap Data in Layered GIS Format; Geofabrik: Karlsruhe, Germany, 2019; Available online: https://download.geofabrik.de/osm-data-in-gis-formats-free.pdf (accessed on 30 July 2019).
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B Stat. Methodol. 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: New York, NY, USA, 2013; Volume 103, ISBN 978-1-4614-7137-0. [Google Scholar]
- Hans, C. Elastic net regression modeling with the orthant normal prior. J. Am. Stat. Assoc. 2011, 106, 1383–1393. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. sklearn.linear_model.ElasticNetCV. Available online: https://scikit-learn.org/0.21/modules/generated/sklearn.linear_model.ElasticNetCV.html (accessed on 2 April 2019).
- Zou, H.; Hastie, T. Regularization and Variable Selection via the Elastic Net. Available online: https://web.stanford.edu/~hastie/TALKS/enet_talk.pdf (accessed on 4 March 2020).
- Schreiber-Gregory, D.N. Regulation Techniques for Multicollinearity: Lasso, Ridge, and Elastic Nets. In Proceedings of the Western Users of SAS Software 2018, Sacramento, CA, USA, 5–7 September 2018; pp. 1–23. [Google Scholar]
- Schreiber-Gregory, D.N. Ridge regression and multicollinearity: An in-depth review. Model Assist. Stat. Appl. 2018, 13, 359–365. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. sklearn.ensemble.RandomForestRegressor. Available online: https://scikit-learn.org/0.21/modules/generated/sklearn.ensemble.RandomForestRegressor.html (accessed on 15 July 2019).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. sklearn.model_selection.GridSearchCV. Available online: https://scikit-learn.org/0.21/modules/generated/sklearn.model_selection.GridSearchCV.html (accessed on 15 July 2019).
- Woodcock, C.E.; Strahler, A.H. The factor of scale in remote sensing. Remote Sens. Environ. 1987, 21, 311–332. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Question | Independent Variables | Dependent Variable | Area(s) |
|---|---|---|---|
| 1 | Contextual features (very-high spatial resolution) | Urban attributes (OpenStreetMap) |
|
| 2 | Contextual features (Sentinel-2) | Urban attributes (OpenStreetMap) |
|
| 3 & 4 | Contextual features (Sentinel-2) | Population density (census) |
|
| Study Area | Census Units | Minimum | Mean | Maximum |
|---|---|---|---|---|
| Accra 1 | 2403 | 0.0019 km2 | 0.09 km2 | 6.75 km2 |
| Belize 2 | 723 | 0.01 km2 | 52.70 km2 | 5345.56 km2 |
| Sri Lanka 3 | 14,021 | 0.04 km2 | 4.69 km2 | 562.64 km2 |
| Area | OpenStreetMap Road Class 1 | Two-Way Road 1 | One-Way Road 1 |
|---|---|---|---|
| Accra, Ghana | trunk | 20.00 m | 10.00 m |
| trunk link | 10.00 m | 5.00 m | |
| primary | 10.00 m | 8.00 m | |
| primary link unclassified | 8.00 m | 5.00 m | |
| residential | 7.00 m | 7.00 m | |
| secondary | 8.00 m | 8.00 m | |
| tertiary | 10.00 m | 5.00 m | |
| cycleway track secondary link tertiary link service | 5.00 m | 5.00 m | |
| path track grade3 | 3.00 m | 3.00 m | |
| footway | 4.00 m | 4.00 m | |
| pedestrian | 3.50 m | 3.50 m | |
| (other) | 0 m | 0 m | |
| Belize | primary primary link | 13.00 m | 6.50 m |
| secondary secondary link | 10.00 m | 5.00 m | |
| tertiary tertiary link | 7.50 m | 3.75 m | |
| living street residential service track track grade1 track grade2 track grade3 track grade4 track grade5 unclassified | 5.00 m | 5.00 m | |
| cycleway footway path pedestrian | 4.00 m | 4.00 m | |
| (other) | 0 m | 0 m | |
| Sri Lanka | motorway motorway link trunk trunk link primary primary link | 15.00 m | 7.50 m |
| secondary secondary link | 10.50 m | 5.25 m | |
| tertiary tertiary link cycleway footway living street path pedestrian residential service track track grade3 track grade5 unclassified unknown | 4.25 m | 4.25 m | |
| (other) | 0 m | 0 m |
| Parameter a | Description of Purpose a | Value(s) |
|---|---|---|
| max_iter | maximum iterations | 1e8 |
| alphas | constraint | 0.0005, 0.001, 0.01, 0.03, 0.05, 0.1 |
| l1_ratio | the ratio between and penalties | 0.1, 0.5, 0.7, 0.9, 0.95, 0.99, 1 |
| verbose | verbosity | False |
| cv | cross-validation splitting strategy | 5 |
| selection | random coefficient updated each iteration | random |
| fit_intercept | calculate intercept if data not centered | False |
| Parameter 1 | Description of Purpose 1 | Value(s) |
|---|---|---|
| n_estimators | number of trees in forest | [see Table 6] |
| min_samples_leaf | minimum number of samples at leaf node | [see Table 6] |
| max_features | maximum number of features to be considered during split | [see Table 6] |
| Parameter 1 | Description of Purpose 1 | Value(s) |
|---|---|---|
| param_grid | parameters used for cross-validation | n_estimators: 200, 300, 500, 700, 900, 1000 min_samples_leaf: 1, 2, 5, 10, 25 max_features: auto, sqrt, log2, 0.33, 0.20, 0.10, None |
| cv | cross-validation splitting strategy | 5 |
| scoring | method to evaluate predictions against test set | neg_mean_squared_error |
| Urban Attribute | Very-High-Spatial-Resolution Imagery | Sentinel-2 Imagery | ||||
|---|---|---|---|---|---|---|
| In-Sample R2 | Out-of-Sample R2 | Mean Square Error | In-Sample R2 | Out-of-Sample R2 | Mean Square Error | |
| building area | 0.82 | 0.43 | 0.50 | 0.85 | 0.60 | 0.35 |
| building count | 0.77 | 0.51 | 0.46 | 0.69 | 0.46 | 0.50 |
| building density | 0.94 | 0.85 | 0.14 | 0.78 | 0.59 | 0.39 |
| road area | 0.93 | 0.77 | 0.22 | 0.83 | 0.76 | 0.23 |
| road length | 0.94 | 0.78 | 0.22 | 0.87 | 0.80 | 0.19 |
| road density | 0.86 | 0.75 | 0.24 | 0.71 | 0.62 | 0.37 |
| built-up area | 0.95 | 0.75 | 0.23 | 0.86 | 0.69 | 0.28 |
| built-up percent | 0.91 | 0.83 | 0.16 | 0.85 | 0.77 | 0.22 |
| Urban Attribute | Very-High-Spatial-Resolution Imagery | Sentinel-2 Imagery | ||||
|---|---|---|---|---|---|---|
| In-Sample R2 | Out-of-Sample R2 | Mean Square Error | In-Sample R2 | Out-of-Sample R2 | Mean Square Error | |
| building area | 0.90 | 0.63 | 0.39 | 0.86 | 0.52 | 0.50 |
| building count | 0.91 | 0.51 | 0.48 | 0.83 | 0.47 | 0.52 |
| building density | 0.98 | 0.82 | 0.16 | 0.97 | 0.74 | 0.24 |
| road area | 0.97 | 0.81 | 0.18 | 0.97 | 0.82 | 0.17 |
| road length | 0.97 | 0.83 | 0.17 | 0.96 | 0.84 | 0.15 |
| road density | 0.96 | 0.73 | 0.26 | 0.93 | 0.64 | 0.35 |
| built-up area | 0.93 | 0.70 | 0.33 | 0.90 | 0.66 | 0.35 |
| built-up percent | 0.97 | 0.80 | 0.18 | 0.97 | 0.78 | 0.20 |
| Urban Attribute | Elastic Net Regularization | Random Forest | ||||
|---|---|---|---|---|---|---|
| In-Sample R2 | Out-of-Sample R2 | Mean Square Error | In-Sample R2 | Out-of-Sample R2 | Mean Square Error | |
| building area | 0.91 | 0.41 | 0.17 | 0.92 | 0.49 | 0.47 |
| building count | 0.44 | -0.06 | 0.95 | 0.81 | 0.35 | 0.62 |
| building density | 0.50 | 0.36 | 0.63 | 0.92 | 0.48 | 0.51 |
| road area | 0.98 | 0.70 | 0.11 | 0.91 | 0.59 | 0.53 |
| road length | 0.98 | 0.68 | 0.14 | 0.91 | 0.59 | 0.54 |
| road density | 0.12 | 0.02 | 0.93 | 0.83 | 0.12 | 0.84 |
| built-up area | 0.97 | 0.59 | 0.08 | 0.91 | 0.65 | 0.49 |
| built-up percent | 0.84 | 0.78 | 0.22 | 0.97 | 0.80 | 0.20 |
| Urban Attribute | Elastic Net Regularization | Random Forest | ||||
|---|---|---|---|---|---|---|
| In-Sample R2 | Out-of-Sample R2 | Mean Square Error | In-Sample R2 | Out-of-Sample R2 | Mean Square Error | |
| building area | 0.72 | 0.59 | 0.41 | 0.92 | 0.56 | 0.46 |
| building count | 0.57 | 0.44 | 0.56 | 0.91 | 0.44 | 0.58 |
| building density | 0.83 | 0.71 | 0.28 | 0.97 | 0.81 | 0.18 |
| road area | 0.75 | 0.51 | 0.45 | 0.95 | 0.69 | 0.30 |
| road length | 0.77 | 0.53 | 0.44 | 0.96 | 0.71 | 0.27 |
| road density | 0.77 | 0.69 | 0.29 | 0.96 | 0.76 | 0.23 |
| built-up area | 0.73 | 0.42 | 0.55 | 0.95 | 0.67 | 0.34 |
| built-up percent | 0.88 | 0.81 | 0.18 | 0.98 | 0.86 | 0.13 |
| Urban Attribute | Elastic Net Regularization | Random Forest | ||||
|---|---|---|---|---|---|---|
| In-Sample R2 | Out-of-Sample R2 | Mean Square Error | In-Sample R2 | Out-of-Sample R2 | Mean Square Error | |
| building area | 0.75 | 0.62 | 0.39 | 0.94 | 0.74 | 0.28 |
| building count | 0.74 | 0.55 | 0.45 | 0.95 | 0.75 | 0.26 |
| building density | 0.75 | 0.71 | 0.30 | 0.97 | 0.78 | 0.22 |
| road area | 0.82 | 0.53 | 0.46 | 0.95 | 0.78 | 0.23 |
| road length | 0.83 | 0.60 | 0.40 | 0.97 | 0.82 | 0.19 |
| road density | 0.42 | 0.34 | 0.66 | 0.90 | 0.45 | 0.55 |
| built-up area | 0.83 | 0.62 | 0.37 | 0.97 | 0.81 | 0.20 |
| built-up percent | 0.93 | 0.90 | 0.10 | 0.99 | 0.93 | 0.07 |
| Study Area | Elastic Net Regularization | Random Forest | ||||
|---|---|---|---|---|---|---|
| In-Sample R2 | Out-of-Sample R2 | Mean Square Error | In-Sample R2 | Out-of-Sample R2 | Mean Square Error | |
| Accra | 0.61 | 0.57 | 0.43 | 0.95 | 0.74 | 0.26 |
| Belize | 0.81 | 0.73 | 0.28 | 0.94 | 0.78 | 0.24 |
| Sri Lanka | 0.68 | 0.65 | 0.35 | 0.96 | 0.77 | 0.23 |
| Accra–Belize–Sri Lanka | 0.69 | 0.67 | 0.34 | 0.97 | 0.84 | 0.16 |
| Urban Attribute | ENR R2 Difference (VHSR to Sentinel-2) | Random Forest R2 Difference (VHSR to Sentinel-2) |
|---|---|---|
| building area | 0.16 | −0.12 |
| building count | −0.05 | −0.04 |
| building density | −0.26 | −0.08 |
| road area | −0.02 | 0.01 |
| road length | 0.02 | 0.01 |
| road density | −0.13 | −0.08 |
| built-up area | −0.06 | −0.03 |
| built-up percent | −0.06 | −0.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chao, S.; Engstrom, R.; Mann, M.; Bedada, A. Evaluating the Ability to Use Contextual Features Derived from Multi-Scale Satellite Imagery to Map Spatial Patterns of Urban Attributes and Population Distributions. Remote Sens. 2021, 13, 3962. https://doi.org/10.3390/rs13193962
Chao S, Engstrom R, Mann M, Bedada A. Evaluating the Ability to Use Contextual Features Derived from Multi-Scale Satellite Imagery to Map Spatial Patterns of Urban Attributes and Population Distributions. Remote Sensing. 2021; 13(19):3962. https://doi.org/10.3390/rs13193962
Chicago/Turabian StyleChao, Steven, Ryan Engstrom, Michael Mann, and Adane Bedada. 2021. "Evaluating the Ability to Use Contextual Features Derived from Multi-Scale Satellite Imagery to Map Spatial Patterns of Urban Attributes and Population Distributions" Remote Sensing 13, no. 19: 3962. https://doi.org/10.3390/rs13193962