
DV-LOAM: Direct Visual LiDAR Odometry and Mapping


Abstract
:
1. Introduction
- We proposed DV-LOAM, which is the first framework that combines a depth-enhanced direct visual odometry module and the LiDAR mapping module into location and mapping. It takes advantage of the efficiency of the direct VO module and the accuracy of LiDAR scan-to-map matching method, thereby further improving the performance compared to existing technologies.
- In the front end, we proposed a two-stage direct tracking strategy to ensure real-time performance while maintaining the local accuracy of motion estimation. Firstly, the direct frame-to-frame visual odometry is used to estimate the pose of camera, which is more efficient than ICP-based odometry. Secondly, a thinning module based on a sliding window is used to reduce accumulated drift. Since there is no need to extract and match features, this method is quite fast and can work even in low-texture environments.
- In the back end, a PGLS-LCD module was presented, by fusing the BoW and LiDAR-Iris techniques, our approach can not only greatly compensate for the insufficiency of vision-based LCD capabilities, especially in the case of reverse visit, but also alleviate the problem of not being able to find the correct loop closure when the accumulated drift exceeds the search radius of LiDAR-methods. In addition, using TEASER’s estimate as an initial guess, and applying V-GICP to refine the transform of pose correction between loop pairs, more robust and accurate results can be obtained even in the case of large drift.
- Extensive experiments have been conducted to test and verify the effectiveness of the system in detail from both quantitative evaluation and visualization clues, and analyze the accuracy improvement brought by each module at different positions of the baseline.
2. Related Works
2.1. Visual Odometry Based Methods
2.2. Point-Cloud-Registration Based Methods
2.3. Tightly Coupled Fusion Methods
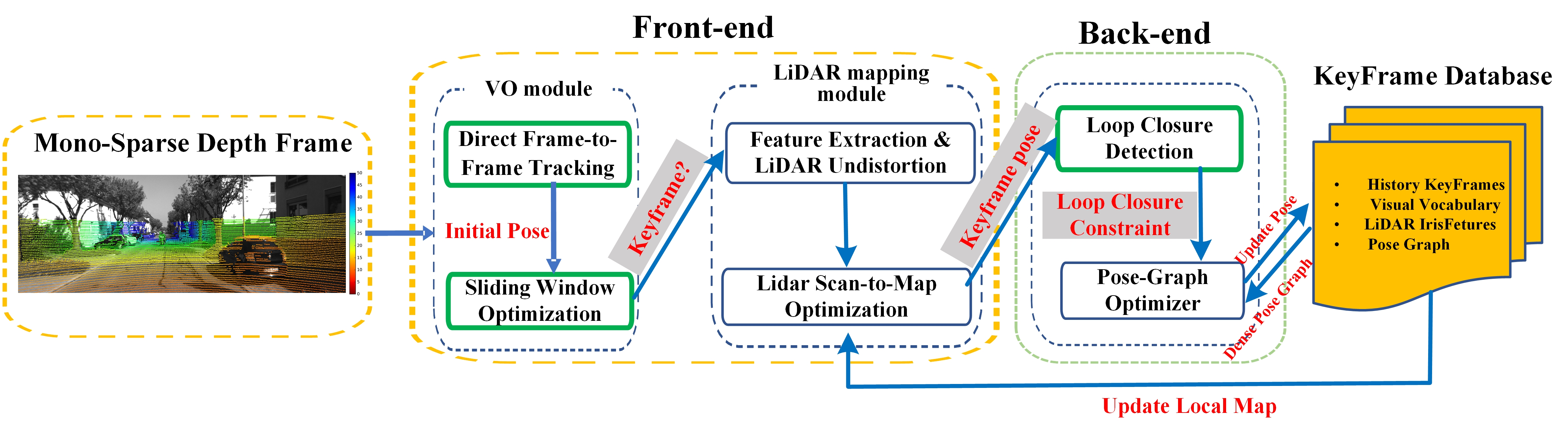
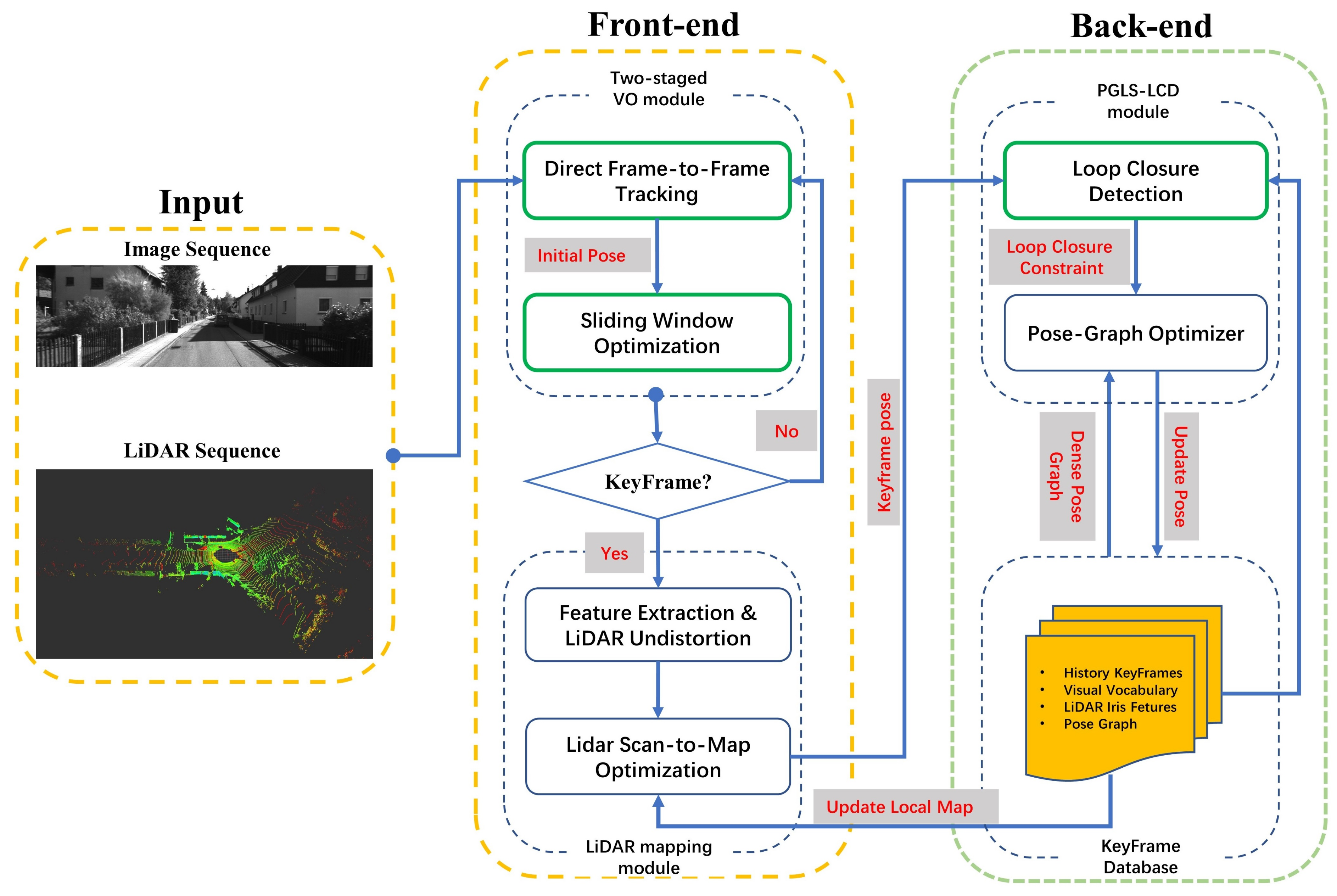
3. System Overview
4. Methods
4.1. Notation
4.2. Direct Frame-to-Frame Tracking
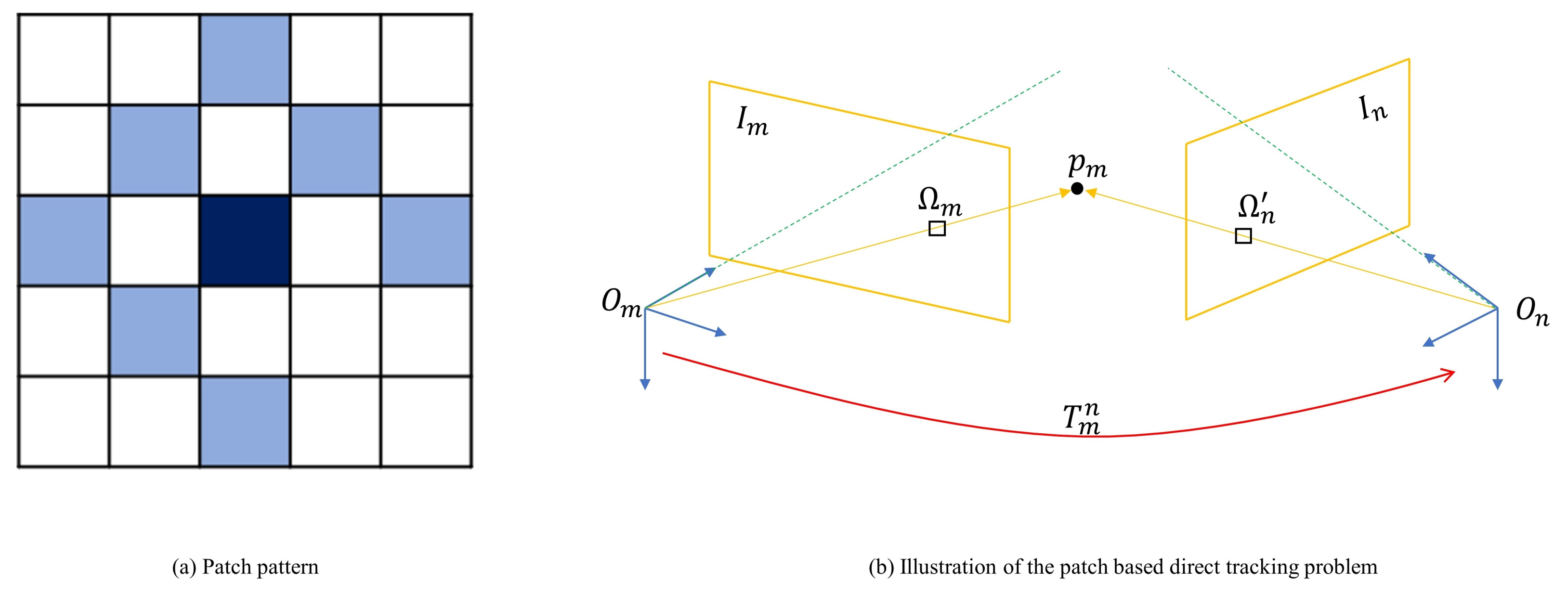
4.2.1. Salient Point Selection
4.2.2. Patch Pattern Selection
4.2.3. Frame-to-Frame Tracking
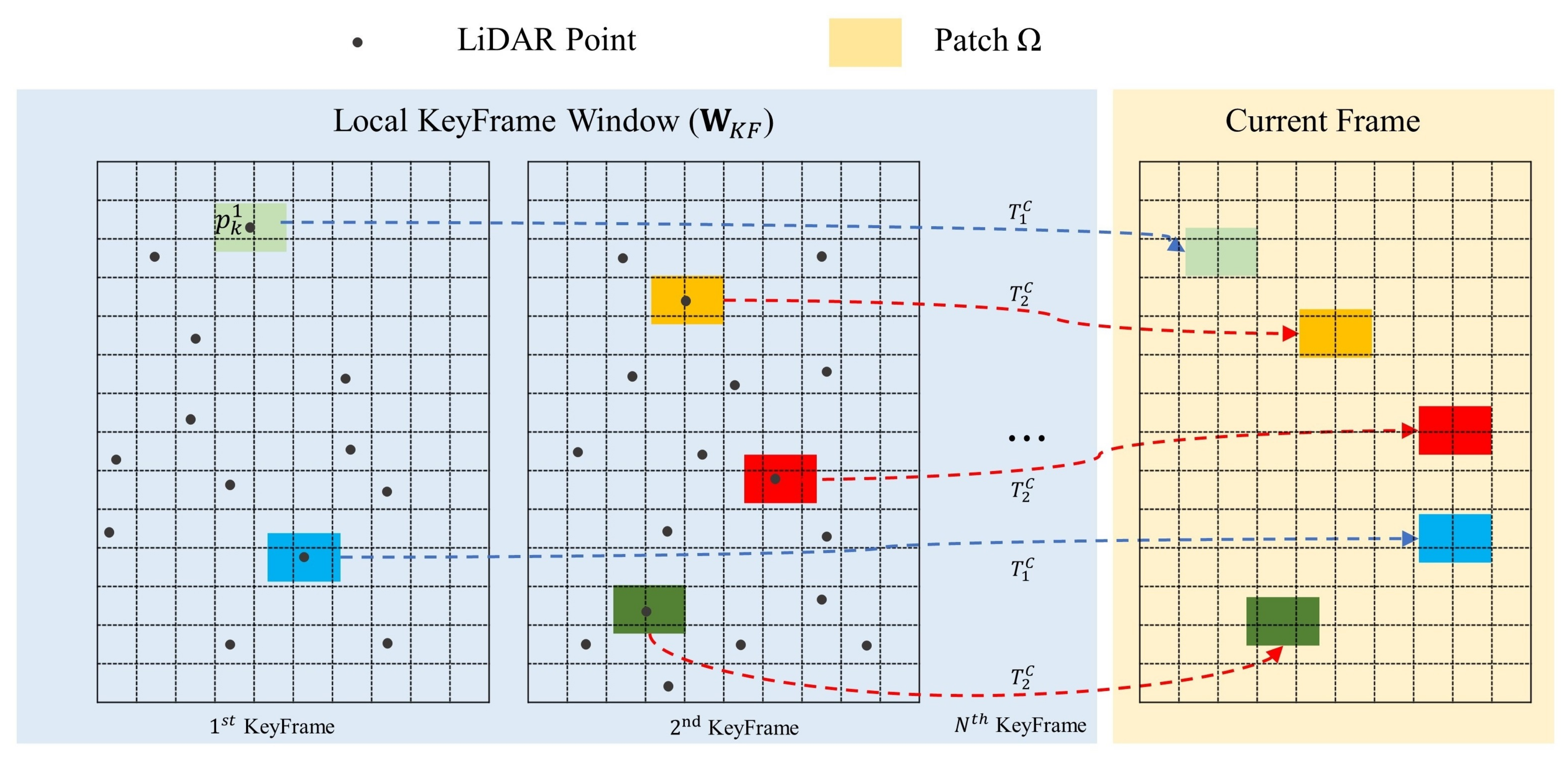
4.3. Sliding Window Optimization
4.3.1. Window-Based Optimization
| Algorithm 1 Two-stage based Direct Visual-LiDAR odometry. |
|
4.3.2. Keyframe Generation and Sliding Window Management
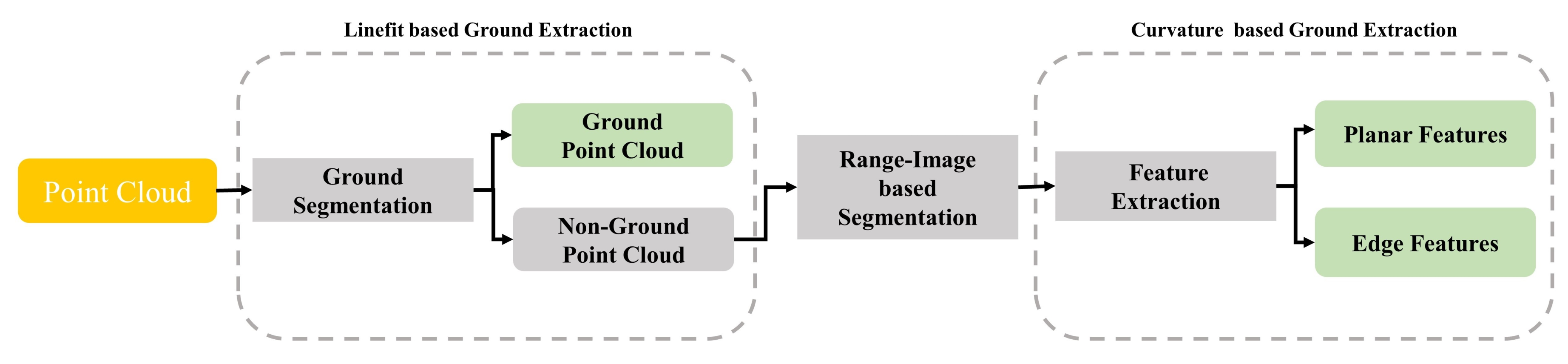
4.4. LiDAR Mapping
4.4.1. Feature Extraction
4.4.2. LiDAR Feature Undistortion
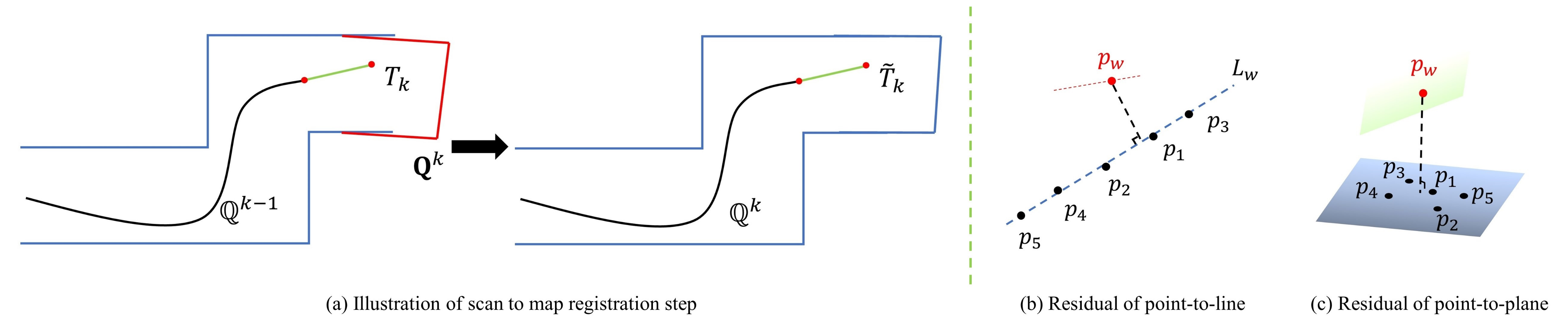
4.4.3. Scan-to-Map Matching
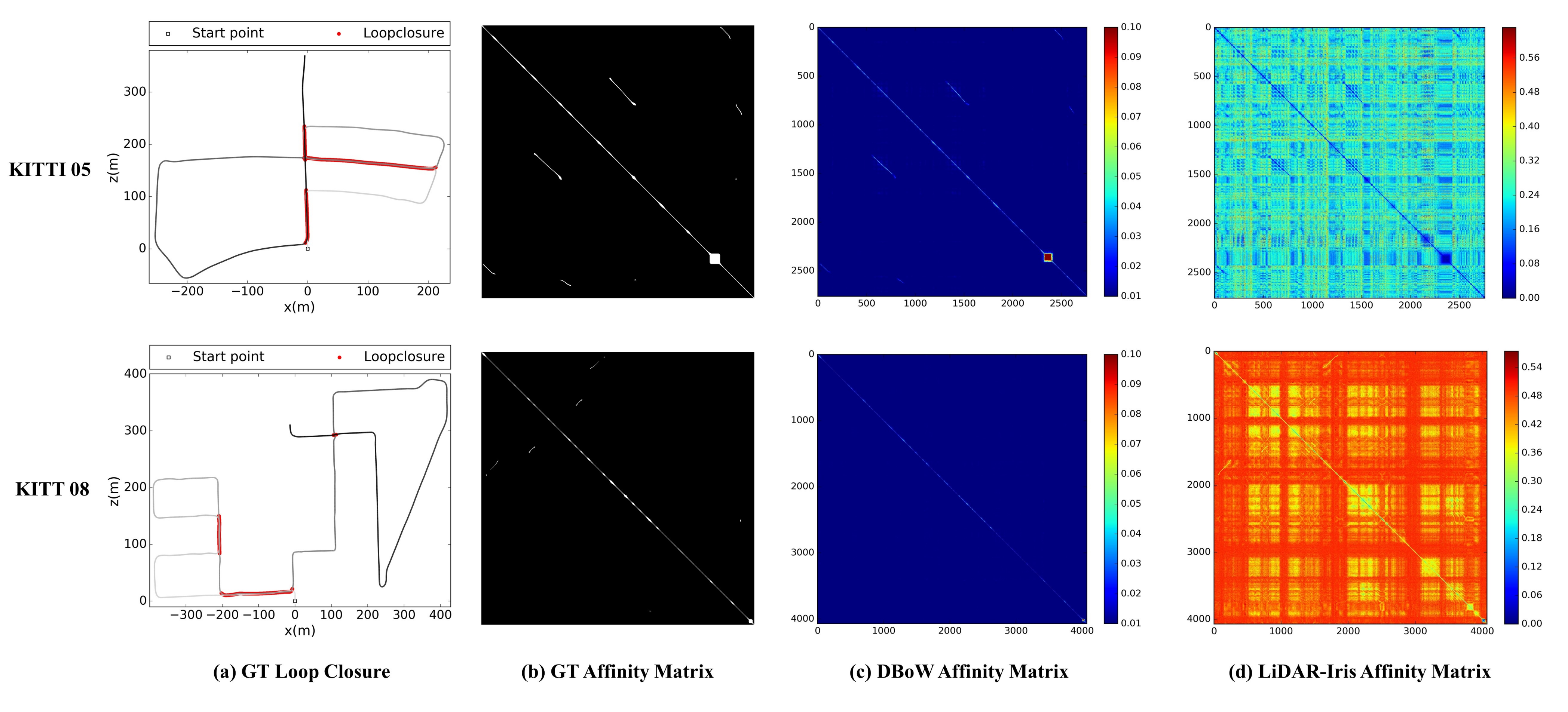
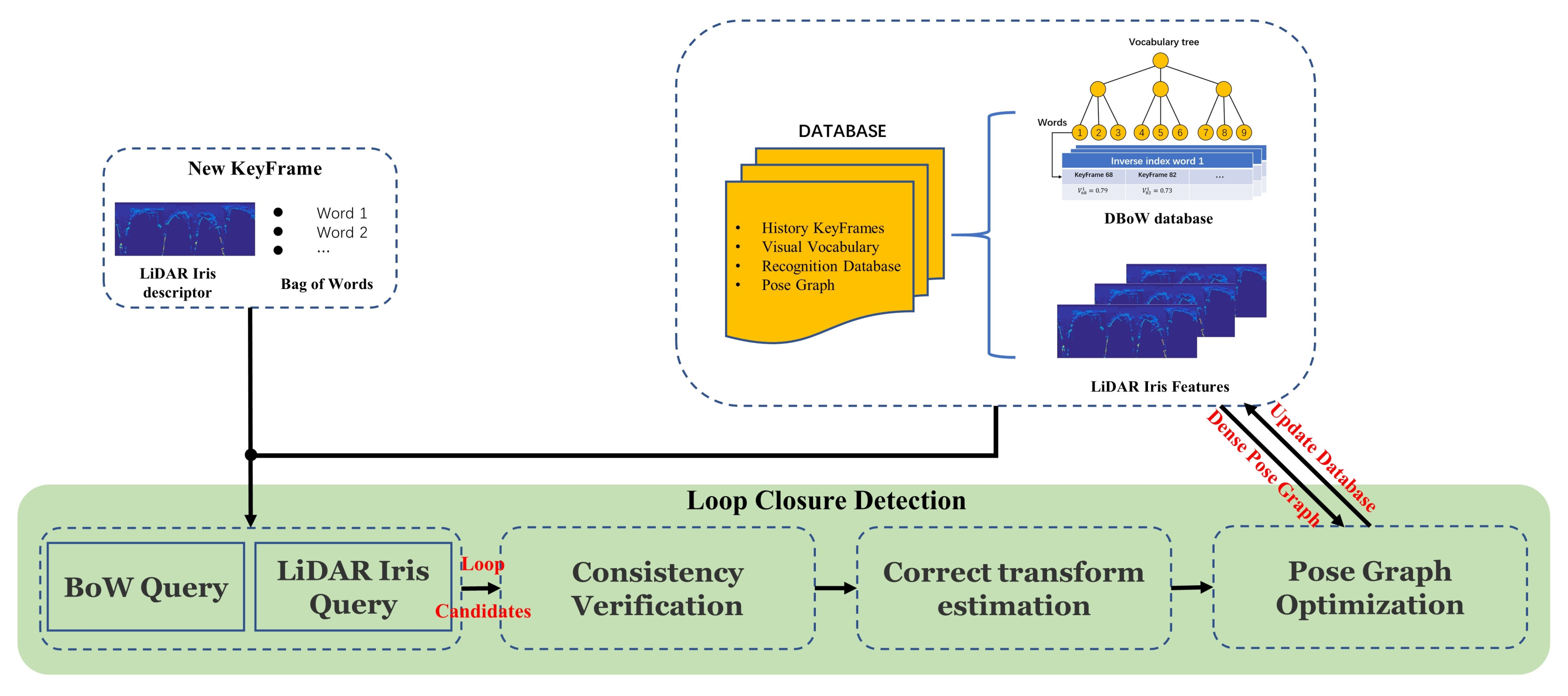
4.5. Loop Closure Detection
4.5.1. The Existing Vision and LiDAR Based Loop Closure Detection Methods and Its Problems
4.5.2. Parallel Globala and Local Serach Loop Closure Detection Approach
4.5.3. BoW Vector Extraction and LiDAR-Iris Descriptor Extraction
4.5.4. Loop Candidates Extraction
| Algorithm 2 Loop closure candidates extraction. |
|
4.5.5. Consistency Verification
- Temporal consistency check:In a SLAM system, it is observed that the occurrence of single loop closure often implies high similarity on the neighbour since the sensor feedback is continuous in time [63]. We can verify the loop closure by measuring the BoW temporal consistency and LiDAR-Iris temporal consistency :where is the number of frames included for temporal consistency verification, and represent the similarity of BoW and LiDAR Iris, and the specific calculation method can be found in [37,44] respectively. Note that if the difference of viewing angle between and is larger than 90 degrees, and become and accordingly. The loop candidate can be accepted by taking threshold on the final temporal consistency score.
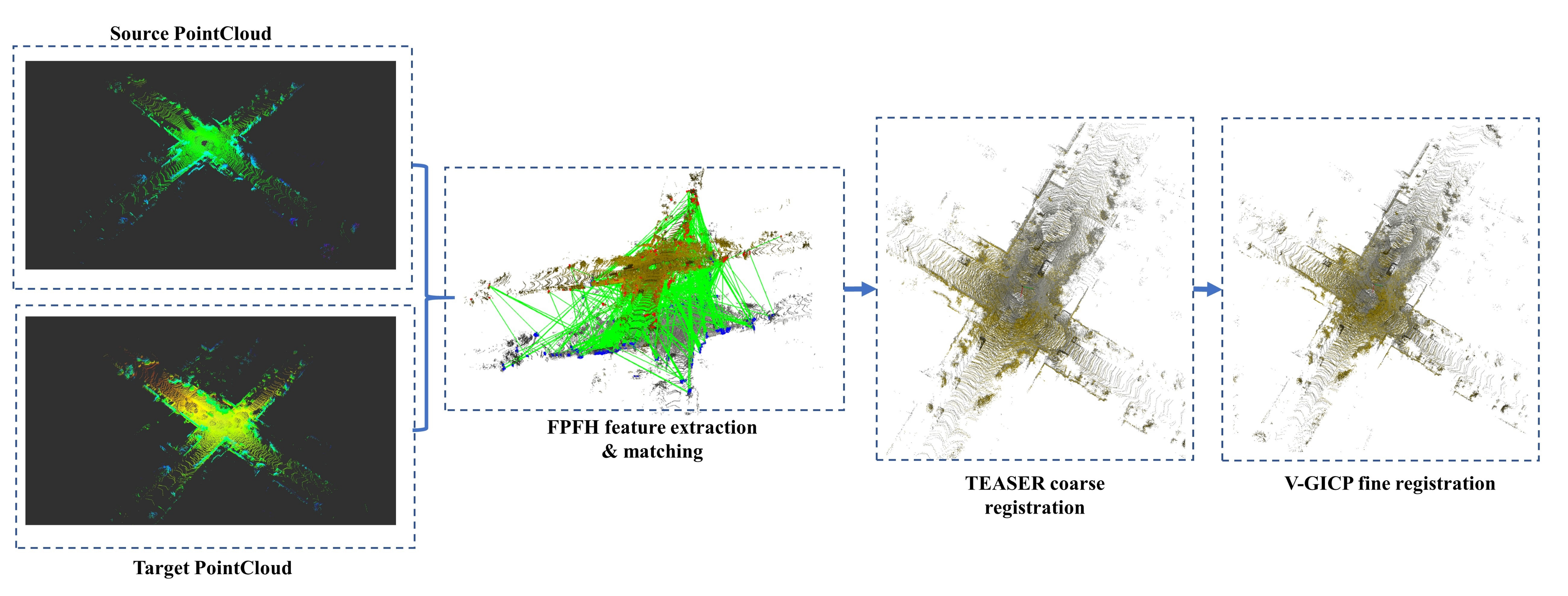
- Geometry consistency check:The geometry consistency check procedure is shown in Figure 11 below. The Fast Point Feature Histogram (FPFH) [64] features are extracted from the local point cloud map constructed from the neighbors of query and candidate keyframe respectively, and then being matched to find feature correspondences. Afterwords, TEASER [47] is used to get an initial guess of the rigid transform matrix through the feature correspondences. Finally, starting from this initial estimate, V-GICP [48] is applied to find minimal distance error between the local point cloud maps generated from the query keyframe and the candidate keyframe . If the fitness score is lower than a threshold , then a loop closure is detected successfully, and the relative pose transform is added to the pose-graph as a loop constraint.Note that, when using ICP based approach, or a direct tracking method (such as in DVL-SLAM), an initial transform is required to calculate the relative pose transformation. However, the initial guess is often unknown in the loop closing module. Therefore, those methods are easy to fall into the local extremum. In this paper, we use TEASER to get an initial guess of the rigid transform matrix. TEASER is a global registration method, which is invariant to initial transform, thus making our approach more robust.
4.6. Pose Graph Optimization
5. Results
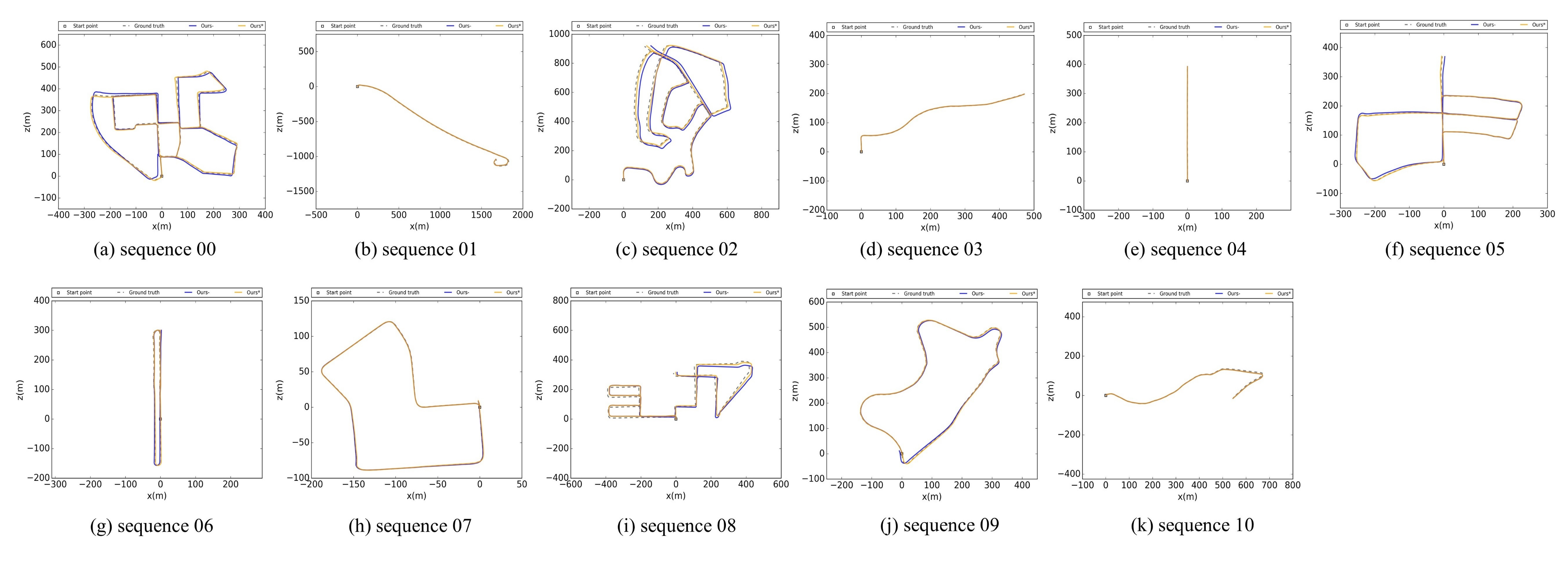
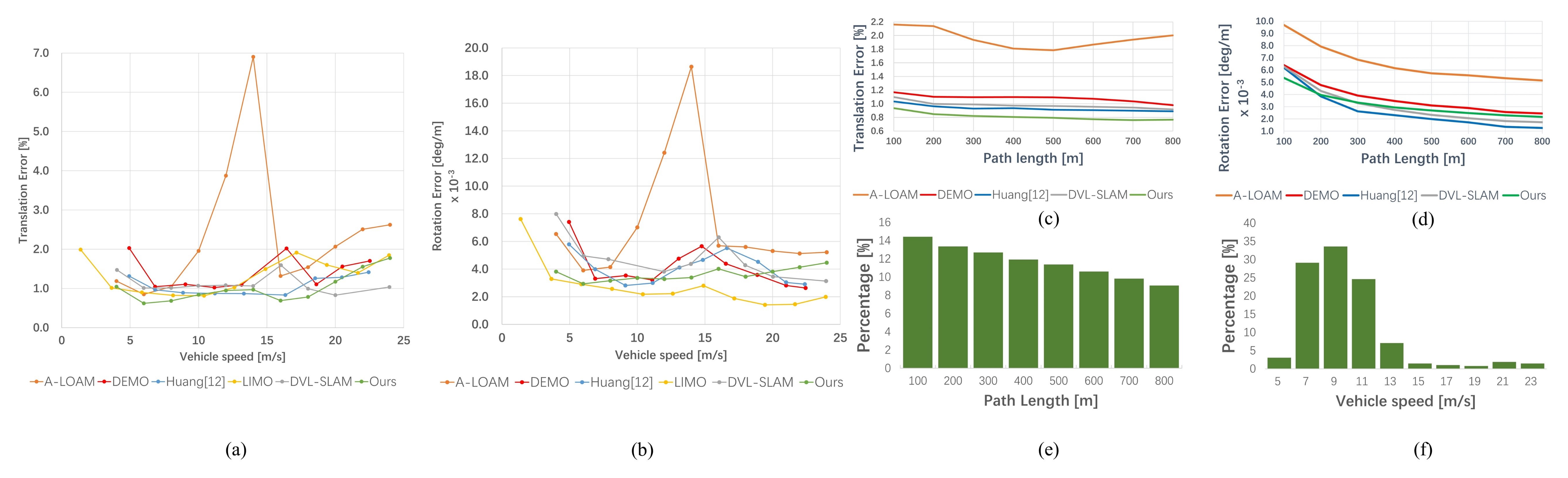
5.1. Validation on the KITTI Odometry Dataset
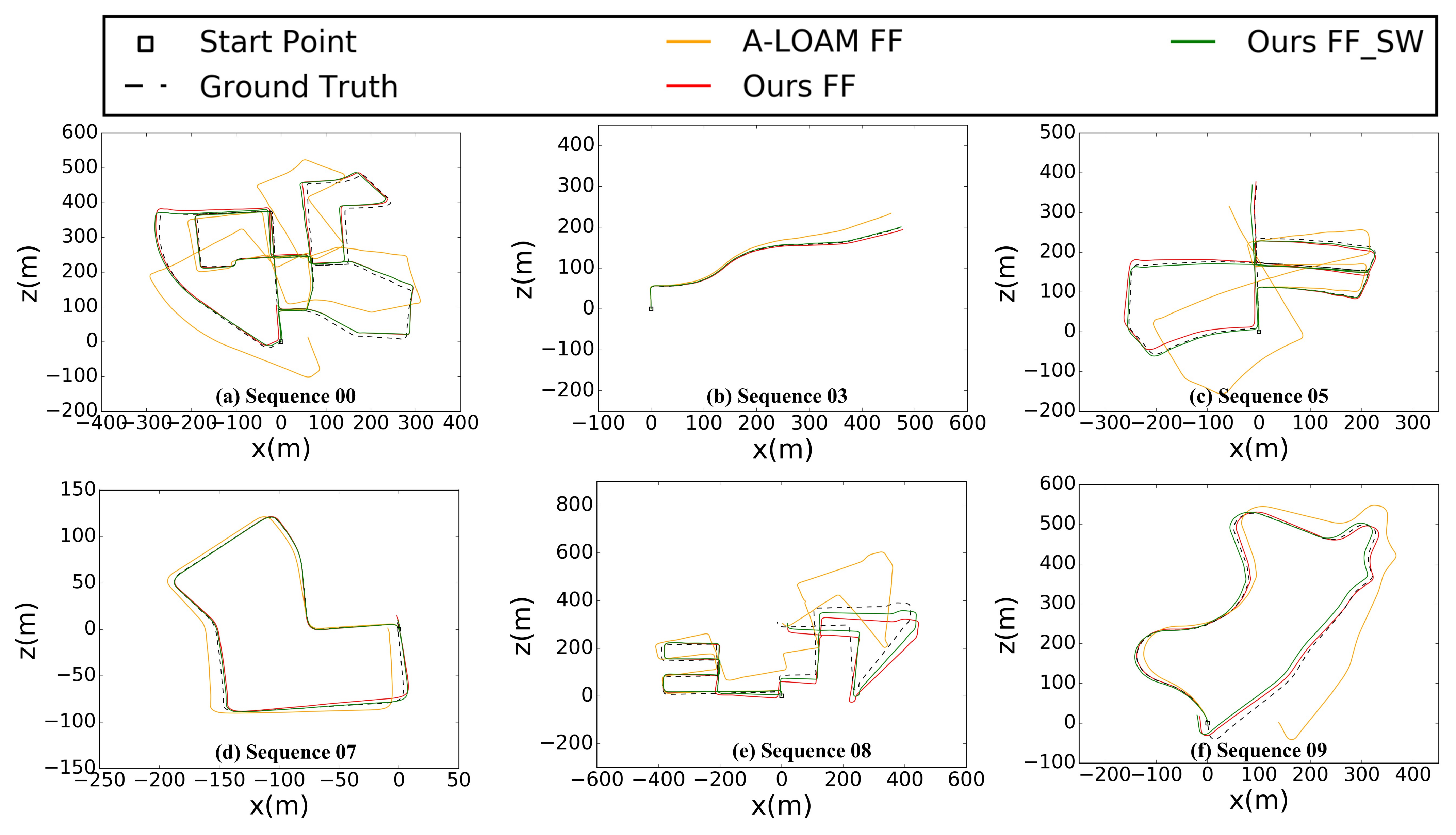
5.1.1. Accuracy Comparison with Existing Methods without Loop Closure
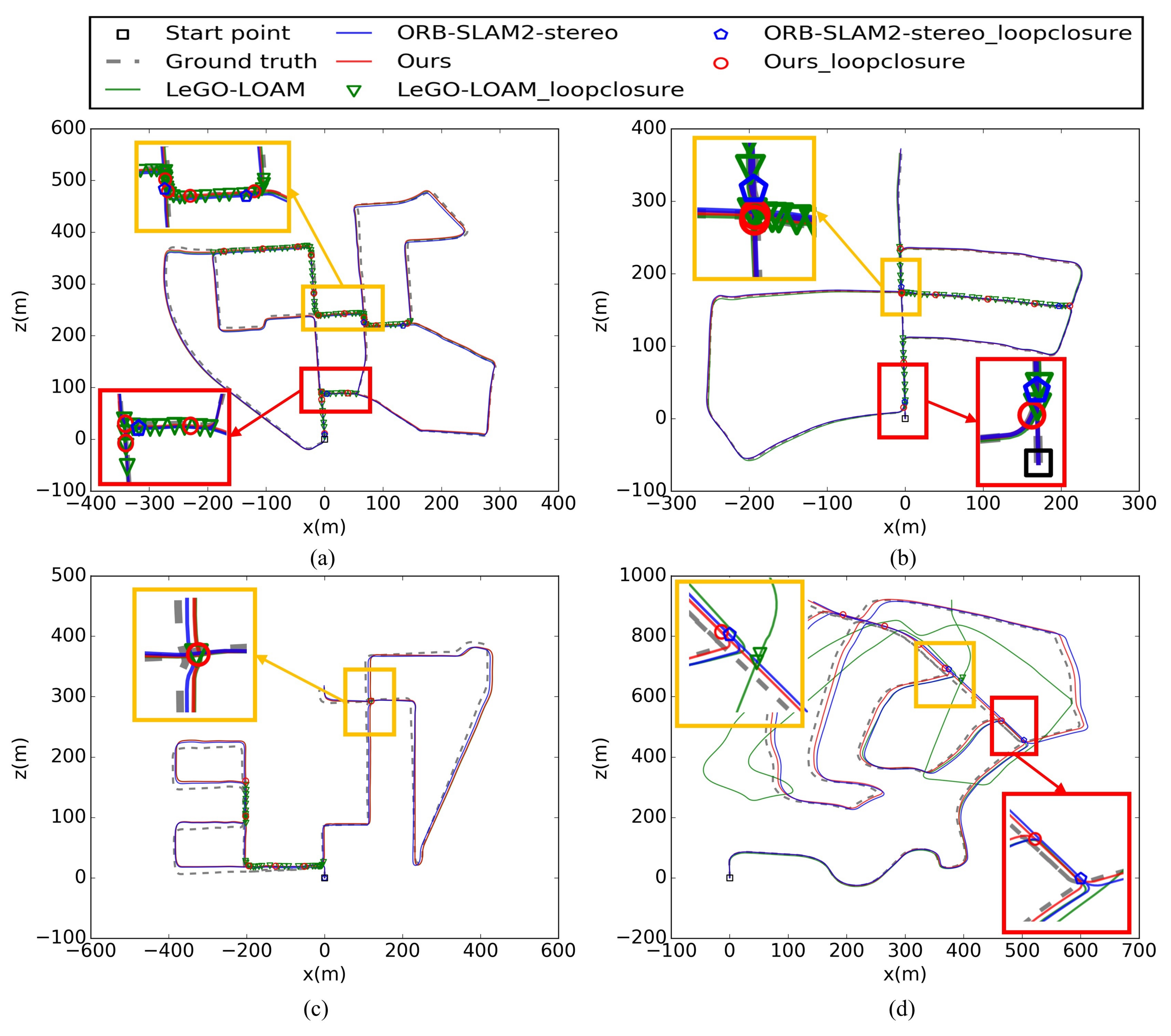
5.1.2. Accuracy Analysis and Global Maps Displaying with Loop Closure
5.2. Evaluation on NuScenes Dataset
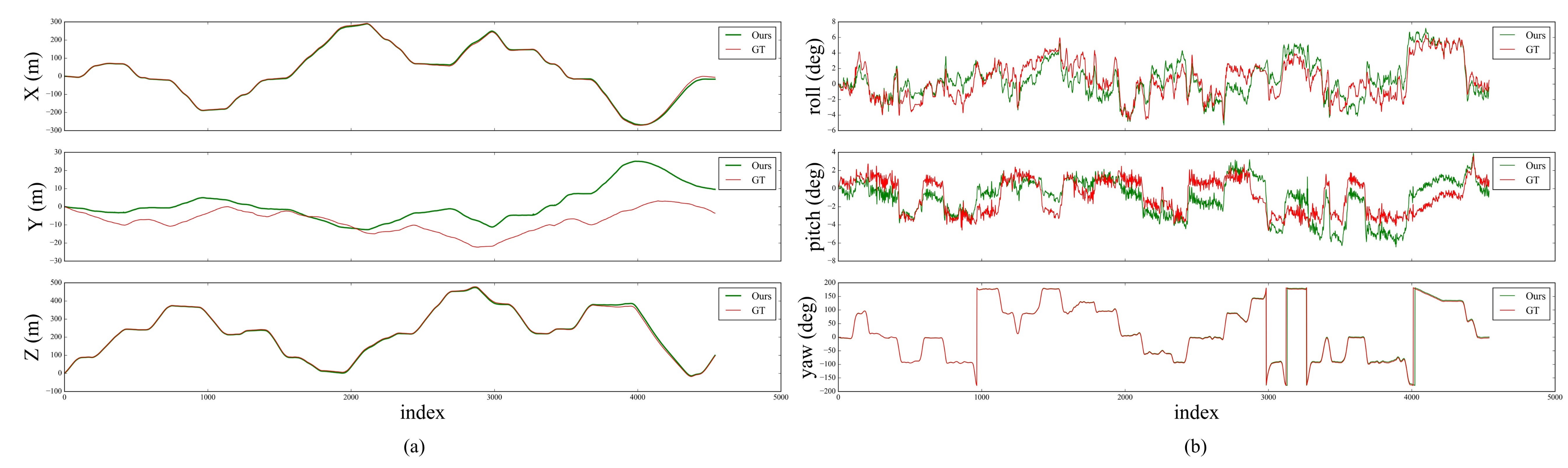
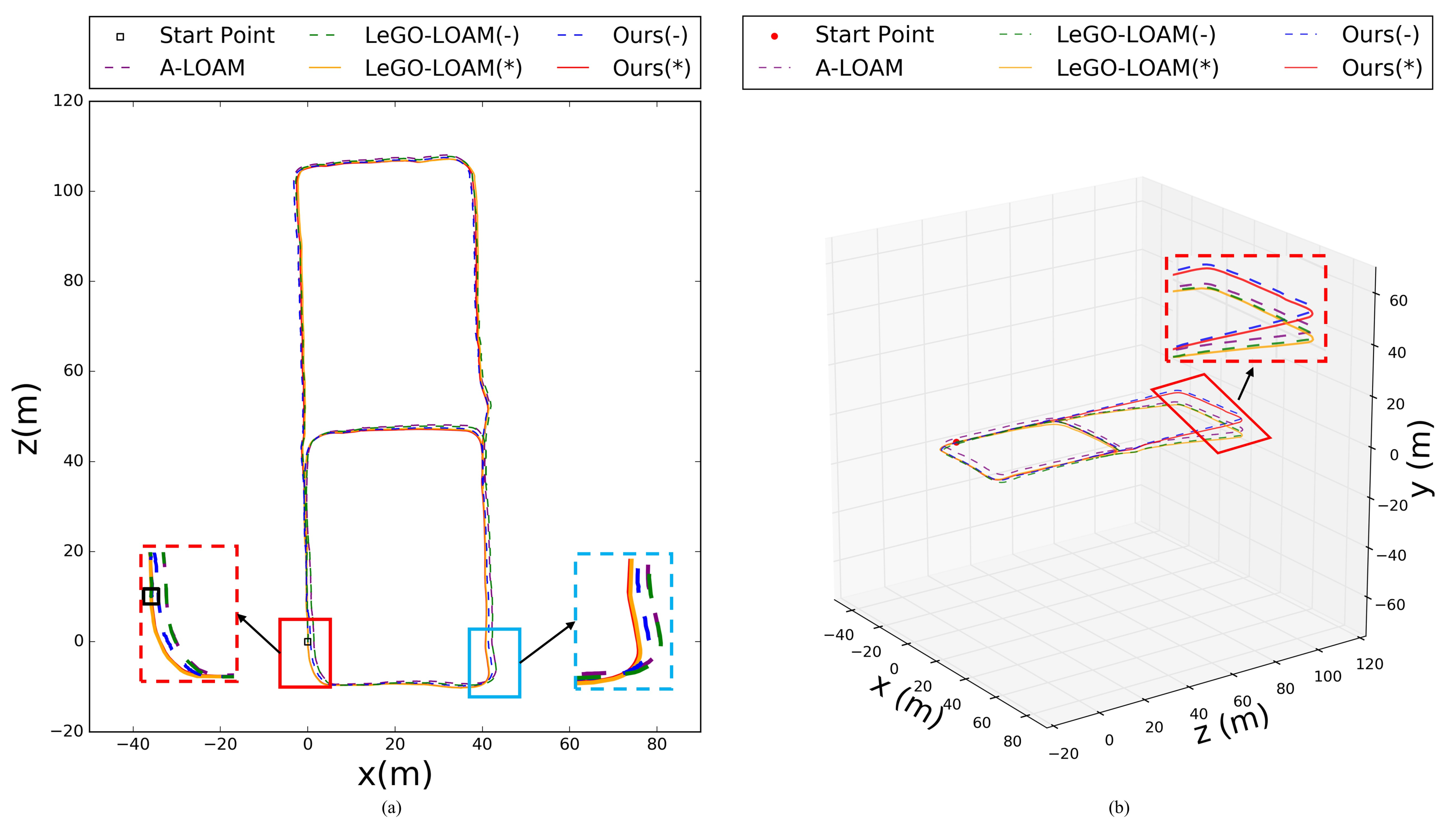
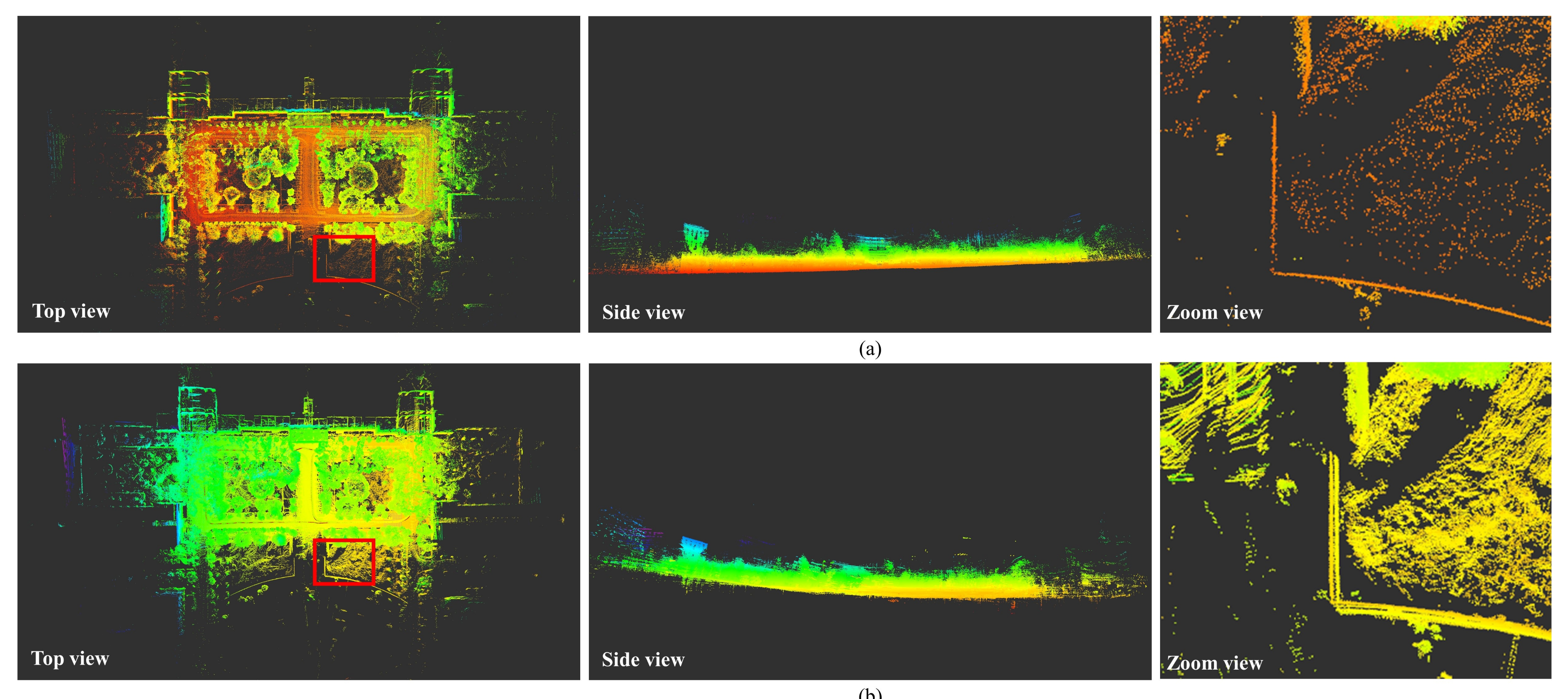
5.3. Evaluation on Our Campus Dataset
5.3.1. Camera LiDAR Extrinsic Calibration
5.3.2. Experiments on the Campus Dataset
5.4. Accuracy Analysis of Each Modules in DV-LOAM
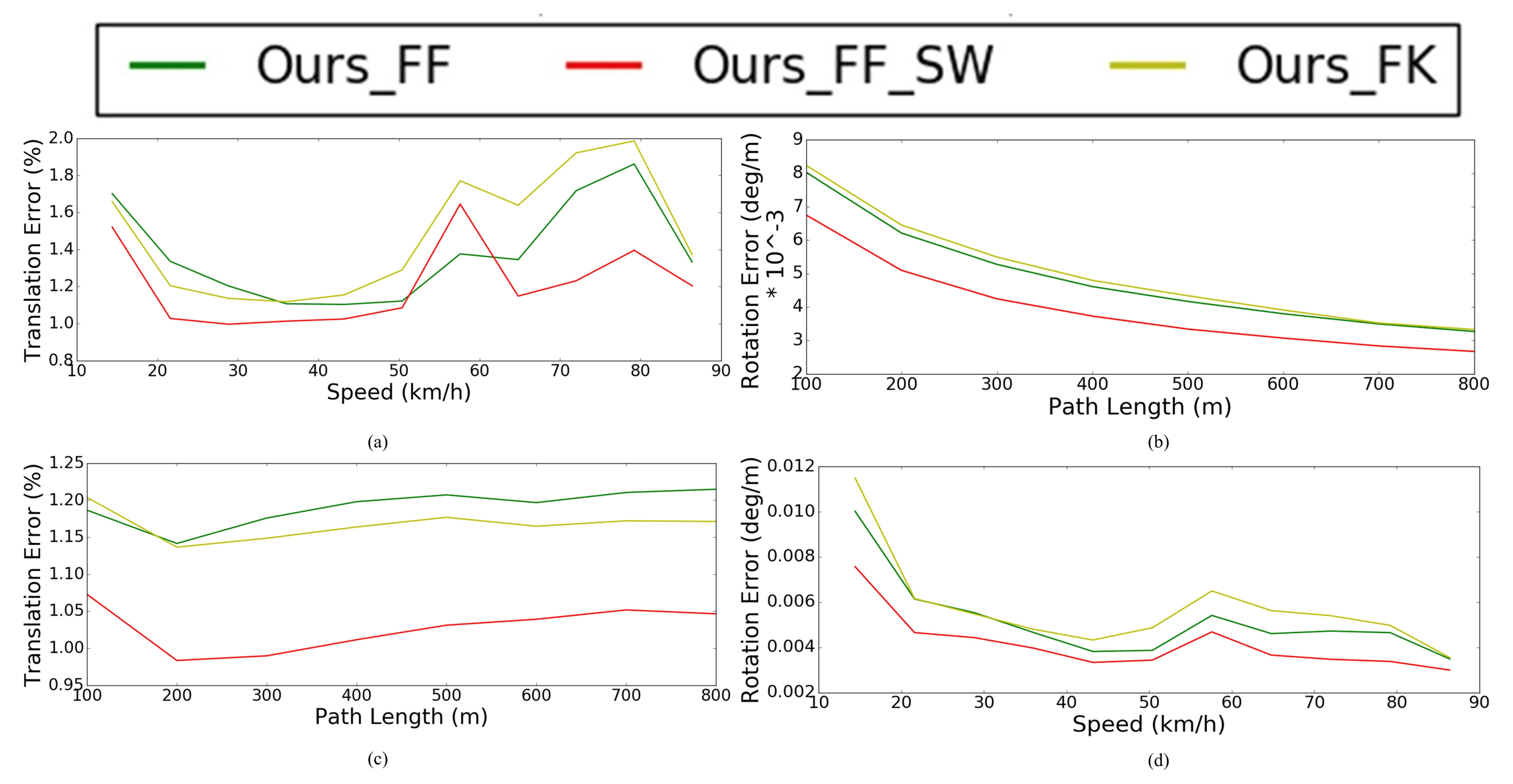
5.4.1. Frame-to-Frame vs. Frame-to-Keyframe Direct Visual LiDAR Odometry
5.4.2. Direct Frame-to-Frame Visual LiDAR Odometry vs. LiDAR Scan Matching Odometry
5.4.3. The Effect of Sliding Window Optimizaiton
5.4.4. The Effect of LiDAR Scan-to-Map Optimization
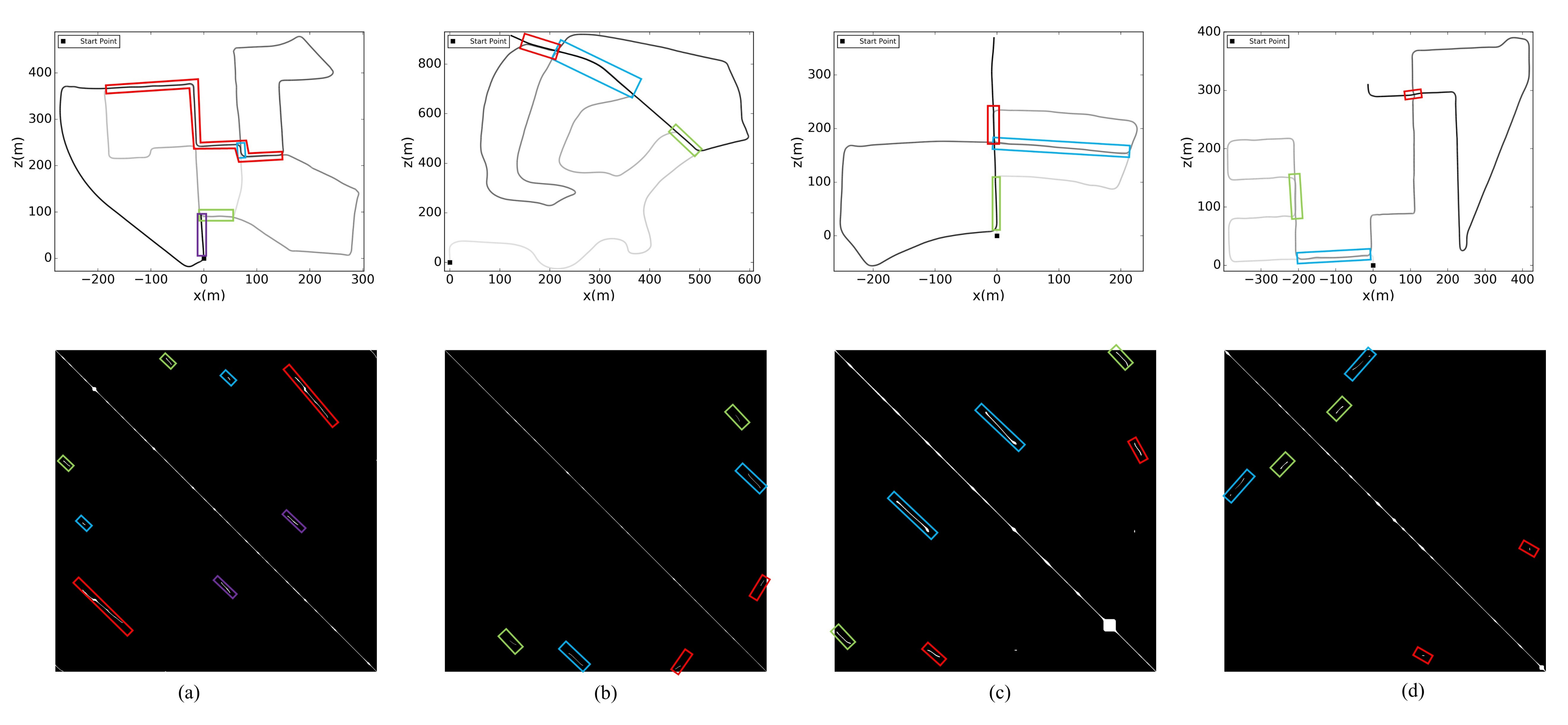
5.5. Loop Closure Results
| Algorithm 3 The precision and recall rate calculation. |
|
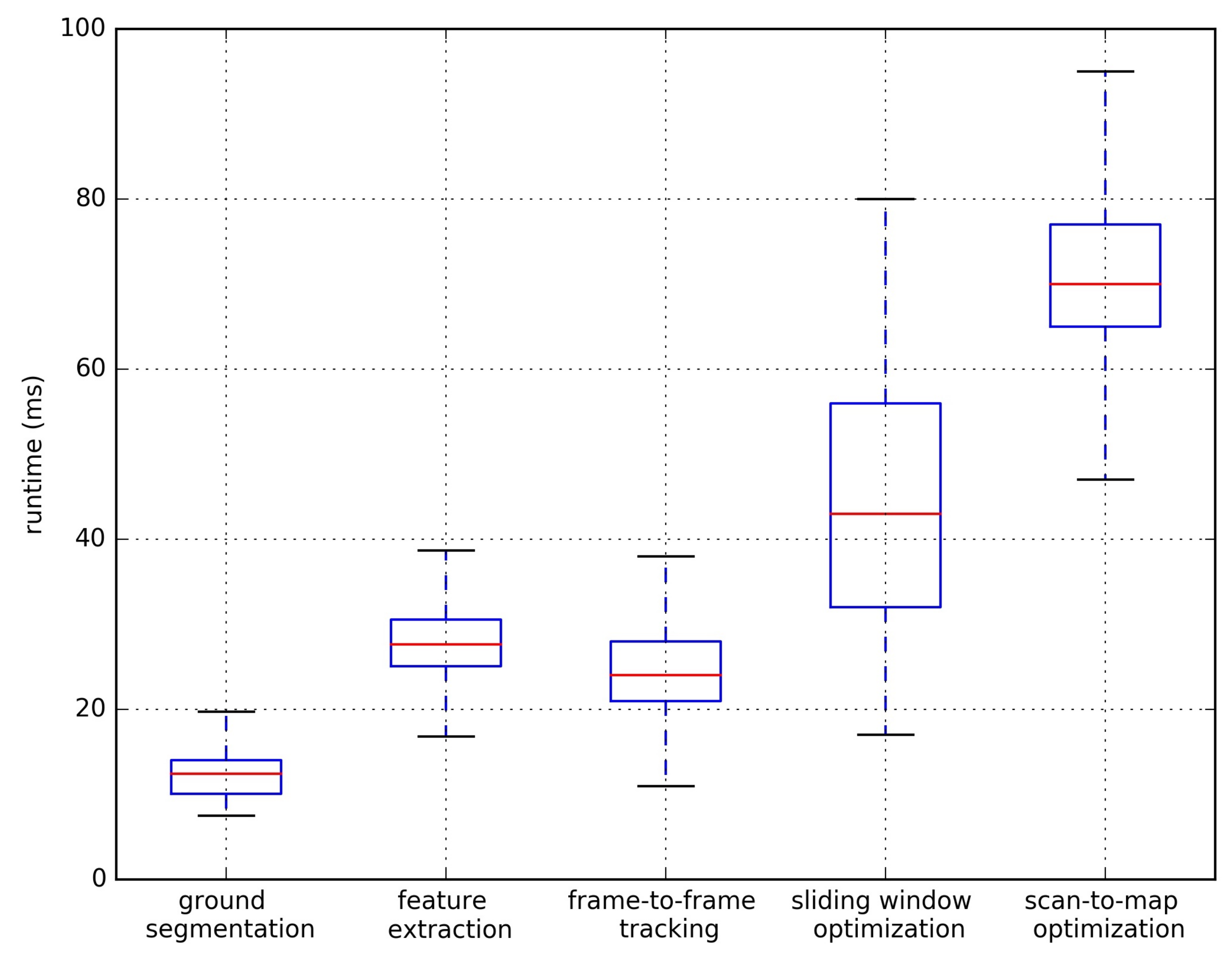
5.6. Time Efficiency Analysis
6. Discussion
- LiDAR frame-to-frame odometry vs. visual-LiDAR fusion odometry: As shown in Table 4, compared to the LiDAR scan-to-scan based odomtery, the visual-LiDAR fusion based odomtery shows better performance in terms of accuracy. This is mainly due to the following reasons. Firstly, the features (edge points and planar points) extracted in LiDAR odometry are selected based on curvature, the distinction between them is not as distinguishable as visual features, and easily affected by noise, especially in unstructured environments such as country. Secondly, due to the inability to perform feature matching, LiDAR-based odomtery often uses Kd-Tree to search for nearest neighbors and then to associate feature points. This often leads to many incorrect matches, which makes the optimization algorithm fail to converge or converge to wrong position, especially when the initial pose is not good at the time. Thirdly, since the visual image has richer textures, and the LiDAR can provide accurate distance measurement, thus the patch-based depth enhanced direct visual-LiDAR odometry can achieve higher accuracy even if the image is blurred. In addition, due to the application of pyramid strategy, this method also performs better in terms of efficiency.
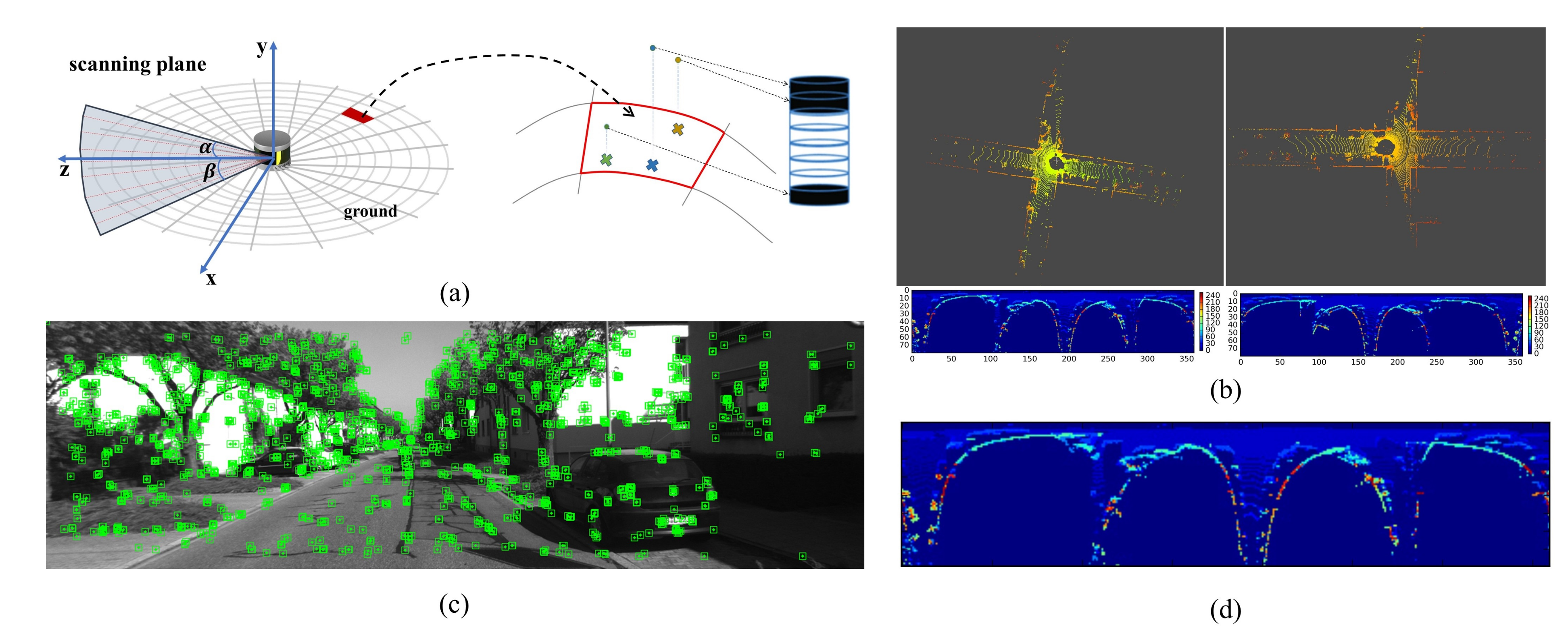
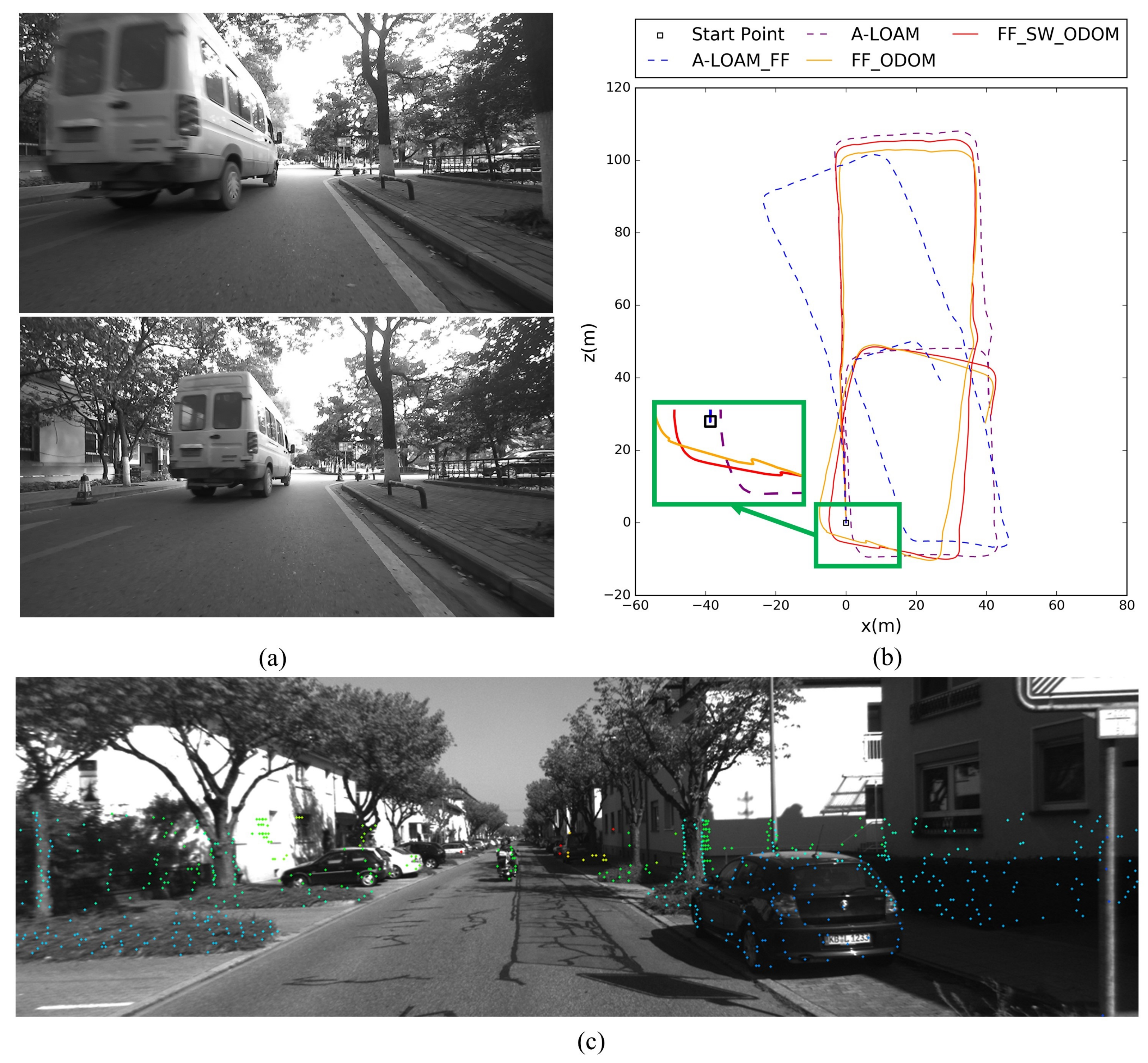
- The effect of dynamic objects: At present, most SLAM methods work under the assumption that the world is static. However, in most real environments, this assumption is difficult to hold strictly. There will always be moving objects in the surrounding environment, such as walking people and moving cars. Since the field of view of the image is much smaller than that of a LiDAR with a 360-degree scan measurements, moving objects have a greater impact on the visual method, especially when there are large moving objects in the image. As shown in the Figure 26a,b, when a moving car passing, the trajectory estimated based on the direct method has obvious errors, while the LiDAR-based odometry method is basically unaffected. This is mainly due to the large field of view of the lidar and the block processing of the LiDAR during feature extraction, and finally only a small part of the features extracted from the moving object. In order to make the algorithm more robust, especially in a dynamic environment, we plan to use the following ideas for improvement. On the one hand, we consider incorporating our previous work: a geometry-based multi-motion segmentation approach [69] to DV-LOAM, thus eliminating the effect of moving objects and obtaining a static point cloud map. On the other hand, we also plan to introduce deep learning based motion segmentation [70,71] to our framework. By removing those salient points located in dynamic objects, the tracking accuracy and positioning accuracy can be further improved.
- The improvement of salient points selection: Currently, we use the strategy described in DVL-SLAM [30] to extract salient points. It first projected all the laser points of the current scan onto the image, and then selected the points with relatively large gradient for ego-motion estimation. There are two problems here. One is that as mentioned in [36], the explicit occluded points often appeared at the borders of the objects, while the gradients of the pixels laid on the borders of objects are relatively larger, so there were many explicit occluded points being selected, which would decrease the accuracy of tracking. On the other hand, as introduced in [51], we noticed that the depth uncertainty of edge points is larger than planar points, and the edge points are shown in Figure 26c. So when the extrinsic parameters are not accurate, or the time synchronization of camera and LiDAR sensors is not precise, the selected salient points which appear at the boundary may bring more uncertainties in the tracking process. As shown in Table 7, we compared the tracking accuracy using different salient points selection strategies, and FF(-) represented the tracking results using all LiDAR points in the salient points selection stage, while FF(*) was the tracking results of only using planar LiDAR points and ground LiDAR points. Although the overall accuracy did not improve much, we can see that on the KITTI 06 dataset, the accuracy of FF(*) improved significantly. The reason is that there are many isolated trees in the KITTI 06 dataset, which will lead to many potential occlusion points. In the future work, we plan to add depth uncertainty into the optimization process as a weight function to improve the performance of the direct visual-LiDAR odometry.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SLAM | Simultaneous Localization and Mapping |
| VO | Visual Odometry |
| LiDAR | Light Detection And Ranging |
| GNSS/INS | Global Navigation Satellite System/Inertial Navigation System |
| IMU | Inertial Measurement Unit |
| TEASER | Truncated least squares Estimation And SEmidefinite Relaxation |
| FPFH | Fast Point Feature Histogram |
| ICP | Iterative Closest Point |
| PGLS-LCD | Parallel Global and Local Search - loop closure detection |
| BoW | Bag of Words |
References
- Wen, W.; Hsu, L.; Zhang, G. Performance Analysis of NDT-based Graph SLAM for Autonomous Vehicle in Diverse Typical Driving Scenarios of Hong Kong. Sensors 2018, 18, 3928. [Google Scholar] [CrossRef] [Green Version]
- Carvalho, H.; Del Moral, P.; Monin, A.; Salut, G. Optimal nonlinear filtering in GPS/INS integration. IEEE Trans. Aerosp. Electron. Syst. 1997, 33, 835–850. [Google Scholar] [CrossRef]
- Mohamed, A.H.; Schwarz, K.P. Adaptive Kalman Filtering for INS/GPS. J. Geod. 1999, 73, 193–203. [Google Scholar] [CrossRef]
- Wang, D.; Xu, X.; Zhu, Y. A Novel Hybrid of a Fading Filter and an Extreme Learning Machine for GPS/INS during GPS Outages. Sensors 2018, 18, 3863. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Ye, Q.; Wang, H.; Chen, L.; Yang, J. A Precise and Robust Segmentation-Based Lidar Localization System for Automated Urban Driving. Remote Sens. 2019, 11, 1348. [Google Scholar] [CrossRef] [Green Version]
- Klein, G.; Murray, D.W. Parallel Tracking and Mapping for Small AR Workspaces. In Proceedings of the Sixth IEEE/ACM International Symposium on Mixed and Augmented Reality, ISMAR 2007, Nara, Japan, 13–16 November 2007; IEEE Computer Society: IEEE: Piscataway, NJ, USA, 2007; pp. 225–234. [Google Scholar] [CrossRef]
- Klein, G.; Murray, D.W. Parallel Tracking and Mapping on a camera phone. In Proceedings of the 8th IEEE International Symposium on Mixed and Augmented Reality 2009, ISMAR 2009, Orlando, FL, USA, 19–22 October 2009; Klinker, G., Saito, H., Höllerer, T., Eds.; IEEE Computer Society: IEEE: Piscataway, NJ, USA, 2009; pp. 83–86. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct Monocular SLAM. In Proceedings of the Computer Vision—ECCV 2014—13th European Conference, Zurich, Switzerland, 6–12 September 2014; Fleet, D.J., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Proceedings, Part II; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2014; Volume 8690, pp. 834–849. [Google Scholar] [CrossRef] [Green Version]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 611–625. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation, ICRA 2014, Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar] [CrossRef] [Green Version]
- Forster, C.; Zhang, Z.; Gassner, M.; Werlberger, M.; Scaramuzza, D. SVO: Semidirect Visual Odometry for Monocular and Multicamera Systems. IEEE Trans. Robot. 2017, 33, 249–265. [Google Scholar] [CrossRef] [Green Version]
- Besl, P.J.; Mckay, H.D. A method for registration of 3-D shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Rusinkiewicz, S.; Levoy, M. Efficient Variants of the ICP Algorithm. In Proceedings of the 3rd International Conference on 3D Digital Imaging and Modeling (3DIM 2001), Quebec, QC, Canada, 28 May–1 June 2001; pp. 145–152. [Google Scholar] [CrossRef] [Green Version]
- Segal, A.; Hähnel, D.; Thrun, S. Generalized-ICP. In Proceedings of the Robotics: Science and Systems V, Seattle, WA, USA, 28 June–1 July 2009; Trinkle, J., Matsuoka, Y., Castellanos, J.A., Eds.; The MIT Press: Cambridge, MA, USA, 2009. [Google Scholar] [CrossRef]
- Zhang, J.; Singh, S. LOAM: Lidar Odometry and Mapping in Real-time. In Proceedings of the Robotics: Science and Systems X, Berkeley, CA, USA, 12–16 July 2014; Fox, D., Kavraki, L.E., Kurniawati, H., Eds.; IEEE: Piscataway, NJ, USA, 2014. [Google Scholar] [CrossRef]
- Zhang, J.; Singh, S. Low-drift and real-time lidar odometry and mapping. Auton. Robot. 2017, 41, 401–416. [Google Scholar] [CrossRef]
- Shan, T.; Englot, B.J. LeGO-LOAM: Lightweight and Ground-Optimized Lidar Odometry and Mapping on Variable Terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2018, Madrid, Spain, 1–5 October 2018; pp. 4758–4765. [Google Scholar] [CrossRef]
- Hong, H.; Lee, B.H. Probabilistic normal distributions transform representation for accurate 3D point cloud registration. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2017, Vancouver, BC, Canada, 24–28 September 2017; pp. 3333–3338. [Google Scholar] [CrossRef]
- Magnusson, M.; Lilienthal, A.J.; Duckett, T. Scan registration for autonomous mining vehicles using 3D-NDT. J. Field Robot. 2007, 24, 803–827. [Google Scholar] [CrossRef] [Green Version]
- Deschaud, J. IMLS-SLAM: Scan-to-Model Matching Based on 3D Data. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation, ICRA 2018, Brisbane, Australia, 21–25 May 2018; pp. 2480–2485. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Milioto, A.; Palazzolo, E.; Giguère, P.; Behley, J.; Stachniss, C. SuMa++: Efficient LiDAR-based Semantic SLAM. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2019, Macau, China, 3–8 November 2019; pp. 4530–4537. [Google Scholar] [CrossRef]
- Ruan, J.; Li, B.; Wang, Y.; Fang, Z. GP-SLAM+: Real-time 3D lidar SLAM based on improved regionalized Gaussian process map reconstruction. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2020, Las Vegas, NV, USA, 24 October–24 January 2020; pp. 5171–5178. [Google Scholar] [CrossRef]
- Qin, T.; Cao, S. A-LOAM. 2018. Available online: https://github.com/HKUST-Aerial-Robotics/A-LOAM (accessed on 2 July 2021).
- Shao, W.; Vijayarangan, S.; Li, C.; Kantor, G. Stereo Visual Inertial LiDAR Simultaneous Localization and Mapping. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2019, Macau, China, 3–8 November 2019; pp. 370–377. [Google Scholar] [CrossRef] [Green Version]
- Gräter, J.; Wilczynski, A.; Lauer, M. LIMO: Lidar-Monocular Visual Odometry. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2018, Madrid, Spain, 1–5 October 2018; pp. 7872–7879. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Kaess, M.; Singh, S. Real-time depth enhanced monocular odometry. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 4973–4980. [Google Scholar] [CrossRef]
- Zhang, J.; Kaess, M.; Singh, S. A real-time method for depth enhanced visual odometry. Auton. Robot. 2017, 41, 31–43. [Google Scholar] [CrossRef]
- Shin, Y.; Park, Y.S.; Kim, A. Direct Visual SLAM Using Sparse Depth for Camera-LiDAR System. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation, ICRA 2018, Brisbane, Australia, 21–25 May 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Shin, Y.; Park, Y.S.; Kim, A. DVL-SLAM: Sparse depth enhanced direct visual-LiDAR SLAM. Auton. Robot. 2020, 44, 115–130. [Google Scholar] [CrossRef]
- Zhang, J.; Singh, S. Visual-lidar odometry and mapping: Low-drift, robust, and fast. In Proceedings of the IEEE International Conference on Robotics and Automation, ICRA 2015, Seattle, WA, USA, 26–30 May 2015; pp. 2174–2181. [Google Scholar] [CrossRef]
- Pandey, G.; Savarese, S.; McBride, J.R.; Eustice, R.M. Visually bootstrapped generalized ICP. In Proceedings of the IEEE International Conference on Robotics and Automation, ICRA 2011, Shanghai, China, 9–13 May 2011; pp. 2660–2667. [Google Scholar] [CrossRef] [Green Version]
- Seo, Y.W.; Chou, C. A Tight Coupling of Vision-Lidar Measurements for an Effective Odometry. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium, IV 2019, Paris, France, 9–12 June 2019; pp. 1118–1123. [Google Scholar] [CrossRef]
- Huang, S.; Ma, Z.; Mu, T.; Fu, H.; Hu, S. Lidar-Monocular Visual Odometry using Point and Line Features. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation, ICRA 2020, Paris, France, 31 May–31 August 2020; pp. 1091–1097. [Google Scholar] [CrossRef]
- Huang, K.; Xiao, J.; Stachniss, C. Accurate Direct Visual-Laser Odometry with Explicit Occlusion Handling and Plane Detection. In Proceedings of the International Conference on Robotics and Automation, ICRA 2019, Montreal, QC, Canada, 20–24 May 2019; pp. 1295–1301. [Google Scholar] [CrossRef]
- Angeli, A.; Filliat, D.; Doncieux, S.; Meyer, J. Fast and Incremental Method for Loop-Closure Detection Using Bags of Visual Words. IEEE Trans. Robot. 2008, 24, 1027–1037. [Google Scholar] [CrossRef] [Green Version]
- Gálvez-López, D.; Tardós, J.D. Bags of Binary Words for Fast Place Recognition in Image Sequences. IEEE Trans. Robot. 2012, 28, 1188–1197. [Google Scholar] [CrossRef]
- Cummins, M.J.; Newman, P.M. FAB-MAP: Probabilistic Localization and Mapping in the Space of Appearance. Int. J. Robot. Res. 2008, 27, 647–665. [Google Scholar] [CrossRef]
- Dubé, R.; Dugas, D.; Stumm, E.; Nieto, J.I.; Siegwart, R.; Cadena, C. SegMatch: Segment based place recognition in 3D point clouds. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation, ICRA 2017, Singapore, 29 May–3 June 2017; pp. 5266–5272. [Google Scholar] [CrossRef] [Green Version]
- Dubé, R.; Gollub, M.G.; Sommer, H.; Gilitschenski, I.; Siegwart, R.; Cadena, C.; Nieto, J.I. Incremental-Segment-Based Localization in 3-D Point Clouds. IEEE Robot. Autom. Lett. 2018, 3, 1832–1839. [Google Scholar] [CrossRef]
- Kim, G.; Kim, A. Scan Context: Egocentric Spatial Descriptor for Place Recognition Within 3D Point Cloud Map. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2018, Madrid, Spain, 1–5 October 2018; pp. 4802–4809. [Google Scholar] [CrossRef]
- Wang, H.; Wang, C.; Xie, L. Intensity Scan Context: Coding Intensity and Geometry Relations for Loop Closure Detection. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation, ICRA 2020, Paris, France, 31 May–31 August 2020; pp. 2095–2101. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Z.; Xu, C.; Sarma, S.E.; Yang, J.; Kong, H. LiDAR Iris for Loop-Closure Detection. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2020, Las Vegas, NV, USA, 24 October–24 January 2020; pp. 5769–5775. [Google Scholar] [CrossRef]
- Chen, X.; Läbe, T.; Milioto, A.; Röhling, T.; Vysotska, O.; Haag, A.; Behley, J.; Stachniss, C. OverlapNet: Loop Closing for LiDAR-based SLAM. CoRR 2021, abs/2105.11344. [Google Scholar]
- Wang, Y.; Qiu, Y.; Cheng, P.; Duan, X. Robust Loop Closure Detection Integrating Visual-Spatial-Semantic Information via Topological Graphs and CNN Features. Remote Sens. 2020, 12, 3890. [Google Scholar] [CrossRef]
- Yang, H.; Shi, J.; Carlone, L. TEASER: Fast and Certifiable Point Cloud Registration. IEEE Trans. Robot. 2021, 37, 314–333. [Google Scholar] [CrossRef]
- Koide, K.; Yokozuka, M.; Oishi, S.; Banno, A. Voxelized GICP for Fast and Accurate 3D Point Cloud Registration; EasyChair: Manchester, UK, 2020. [Google Scholar]
- Lin, J.; Zheng, C.; Xu, W.; Zhang, F. R2 LIVE: A Robust, Real-Time, LiDAR-Inertial-Visual Tightly-Coupled State Estimator and Mapping. IEEE Robot. Autom. Lett. 2021, 6, 7469–7476. [Google Scholar] [CrossRef]
- Zhu, Y.; Zheng, C.; Yuan, C.; Huang, X.; Hong, X. CamVox: A Low-cost and Accurate Lidar-assisted Visual SLAM System. CoRR 2020, abs/2011.11357. [Google Scholar]
- Voges, R.; Wagner, B. Interval-Based Visual-LiDAR Sensor Fusion. IEEE Robot. Autom. Lett. 2021, 6, 1304–1311. [Google Scholar] [CrossRef]
- Reinke, A.; Chen, X.; Stachniss, C. Simple But Effective Redundant Odometry for Autonomous Vehicles. CoRR, 2021; abs/2105.11783. [Google Scholar]
- Chen, S.; Zhou, B.; Jiang, C.; Xue, W.; Li, Q. A LiDAR/Visual SLAM Backend with Loop Closure Detection and Graph Optimization. Remote Sens. 2021, 13, 2720. [Google Scholar] [CrossRef]
- Smith, P.; Reid, I.; Davison, A.J. Real-Time Monocular SLAM with Straight Lines. In Proceedings of the British Machine Vision Conference 2006, Edinburgh, UK, 4–7 September 2006; Chantler, M.J., Fisher, R.B., Trucco, E., Eds.; British Machine Vision Association: Durham, UK, 2006; pp. 17–26. [Google Scholar] [CrossRef] [Green Version]
- Gee, A.P.; Mayol-Cuevas, W.W. Real-Time Model-Based SLAM Using Line Segments. In Proceedings of the Advances in Visual Computing, Second International Symposium, ISVC 2006, Lake Tahoe, NV, USA, 6–8 November 2006; Bebis, G., Boyle, R., Parvin, B., Koracin, D., Remagnino, P., Nefian, A., Gopi, M., Pascucci, V., Zara, J., Molineros, J., et al., Eds.; Proceedings, Part II; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2006; Volume 4292, pp. 354–363. [Google Scholar] [CrossRef] [Green Version]
- Klein, G.; Murray, D.W. Improving the Agility of Keyframe-Based SLAM. In Proceedings of the Computer Vision—ECCV 2008, 10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008; Forsyth, D.A., Torr, P.H.S., Zisserman, A., Eds.; Lecture Notes in Computer Science; Proceedings, Part II. Springer: Berlin/Heidelberg, Germany, 2008; Volume 5303, pp. 802–815. [Google Scholar] [CrossRef] [Green Version]
- Lin, J.; Zhang, F. Loam livox: A fast, robust, high-precision LiDAR odometry and mapping package for LiDARs of small FoV. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2020; pp. 3126–3131. [Google Scholar] [CrossRef]
- Kerl, C.; Sturm, J.; Cremers, D. Robust odometry estimation for RGB-D cameras. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 3748–3754. [Google Scholar] [CrossRef] [Green Version]
- Himmelsbach, M.; von Hundelshausen, F.; Wünsche, H. Fast segmentation of 3D point clouds for ground vehicles. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), 2010, La Jolla, CA, USA, 21–24 June 2010; pp. 560–565. [Google Scholar] [CrossRef]
- Bogoslavskyi, I.; Stachniss, C. Fast range image-based segmentation of sparse 3D laser scans for online operation. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2016, Daejeon, Korea, 9–14 October 2016; pp. 163–169. [Google Scholar] [CrossRef]
- Rusu, R.B.; Cousins, S. 3D is here: Point Cloud Library (PCL). In Proceedings of the IEEE International Conference on Robotics and Automation, ICRA 2011, Shanghai, China, 9–13 May 2011. [Google Scholar] [CrossRef] [Green Version]
- De Berg, M.; Cheong, O.; van Kreveld, M.J.; Overmars, M.H. Computational Geometry: Algorithms and Applications, 3rd ed.; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Milford, M.; Wyeth, G.F. SeqSLAM: Visual route-based navigation for sunny summer days and stormy winter nights. In Proceedings of the IEEE International Conference on Robotics and Automation, ICRA 2012, St. Paul, MI, USA, 14–18 May 2012; pp. 1643–1649. [Google Scholar] [CrossRef]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast Point Feature Histograms (FPFH) for 3D registration. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, ICRA 2009, Kobe, Japan, 12–17 May 2009; pp. 3212–3217. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 11618–11628. [Google Scholar] [CrossRef]
- Quigley, M.; Gerkey, B.P.; Conley, K.; Faust, J.; Ng, A.Y. ROS: An open-source Robot Operating System. In Proceedings of the ICRA Workshop on Open Source Software, Kobe, Japan, 12–17 May 2009. [Google Scholar]
- Yin, L.; Luo, B.; Wang, W.; Yu, H.; Wang, C.; Li, C. CoMask: Corresponding Mask-Based End-to-End Extrinsic Calibration of the Camera and LiDAR. Remote Sens. 2020, 12, 1925. [Google Scholar] [CrossRef]
- Wang, C.; Luo, B.; Zhang, Y.; Zhao, Q.; Yin, L.; Wang, W.; Su, X.; Wang, Y.; Li, C. DymSLAM: 4D Dynamic Scene Reconstruction Based on Geometrical Motion Segmentation. IEEE Robot. Autom. Lett. 2021, 6, 550–557. [Google Scholar] [CrossRef]
- Wang, C.; Li, C.; Liu, J.; Luo, B.; Su, X.; Wang, Y.; Gao, Y. U2-ONet: A Two-Level Nested Octave U-Structure Network with a Multi-Scale Attention Mechanism for Moving Object Segmentation. Remote Sens. 2021, 13, 60. [Google Scholar] [CrossRef]
- Chen, X.; Li, S.; Mersch, B.; Wiesmann, L.; Gall, J.; Behley, J.; Stachniss, C. Moving Object Segmentation in 3D LiDAR Data: A Learning-Based Approach Exploiting Sequential Data. IEEE Robot. Autom. Lett. 2021, 6, 6529–6536. [Google Scholar] [CrossRef]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modules | Parameters | Description | KITTI | NuScenes | Ours |
|---|---|---|---|---|---|
| Visual Odometry | Number of image pyramid levels | 3 | 3 | 3 | |
| Max iteration of direct tracking in each level | 100 | 100 | 100 | ||
| Ration for keyframe creation | 0.7 | 0.8 | 0.8 | ||
| Time for keyframe creation (s) | 1.0 | 1.0 | 1.0 | ||
| Sliding window size (number of frames) | 3 | 3 | 5 | ||
| LiDAR Mapping | , , | The resolution of point cloud voxel downsample (m) | 0.4, 0.8, 0.8 | 0.4, 0.8, 0.8 | 0.3, 0.6, 0.6 |
| Loop Closing | The loop closure searching radius (m) | 10.0 | 10.0 | 10.0 | |
| The geometry consistency threshold | 40.0 | 40.0 | 40.0 | ||
| The suspend detection time after pose graph (s) optimization | 10.0 | 10.0 | 10.0 | ||
| The minimal gaps between candidate keyframe and last loop keyframe | 20 | 20 | 20 |
| Seq. No | Path Len. (m) | Environment | LOAM [18] (-) | A-LOAM [25] (-) | LeGO- LOAM [19] (-) | DEMO [29] (-) | LIMO [27] (-) | Huang [35] (-) | DVL- SLAM [31] (-) | Ours (-) | Ours (*) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 00 | 3714 | Urban | 0.78/- | 0.87/0.36 | 1.51/0.70 | 1.05/- | 1.12/- | 0.99/- | 0.93/- | 0.65/0.30 | 0.66/0.30 |
| 01 | 4268 | Highway | 1.43/- | 2.64/0.55 | -/- | 1.87/- | 0.91/- | 1.87/- | 1.47/- | 1.74/0.43 | 1.74/0.43 |
| 02 | 5075 | Urban+Country | 0.92/- | 4.88/1.55 | 1.96/0.78 | 0.93/- | 1.38/- | 1.11/- | 0.97/0.33 | 0.84/0.36 | |
| 03 | 563 | Country | 0.86/- | 1.20/0.63 | 1.41/1.00 | 0.99/- | 0.65/- | 0.92/- | 0.85/0.48 | 0.85/0.48 | |
| 04 | 397 | Country | 0.71/- | 1.23/0.40 | 1.69/0.83 | 1.23/- | 0.53/- | 0.42/- | 0.67/- | 0.39/0.62 | 0.39/0.62 |
| 05 | 2223 | Urban | 0.57/- | 0.66/0.30 | 1.01/0.54 | 1.04/- | 0.72/- | 0.82/- | 0.54/0.30 | 0.43/0.22 | |
| 06 | 1239 | Urban | 0.65/- | 0.62/0.28 | 0.90/0.47 | 0.96/- | 0.61/- | 0.92/- | 0.65/0.33 | 0.70/0.33 | |
| 07 | 695 | Urban | 0.63/- | 0.58/0.43 | 0.81/0.56 | 1.16/- | 0.56/- | 1.26/- | 0.51/0.33 | 0.42/0.22 | |
| 08 | 3225 | Urban+Country | 1.12/- | 1.18/0.43 | 1.48/0.68 | 1.24/- | 1.27/- | 1.32/- | 0.89/0.32 | 0.93/0.27 | |
| 09 | 1717 | Urban+Country | 0.77/- | 1.10/0.45 | 1.57/0.80 | 1.17/- | 1.06/- | 0.66/- | 0.73/0.32 | 0.75/0.27 | |
| 10 | 919 | Urban+Country | 0.79/- | 1.46/0.53 | 1.81/0.85 | 1.14/- | 0.83/- | 0.70/- | 0.87/0.47 | 0.87/0.47 | |
| avg | 0.84/- | 1.49/0.53 | -/- | 1.14/0.49 | 0.93/0.26 | 0.94/0.36 | 0.98/0.40 | 0.80/0.38 | 0.78/0.36 |
| Scene No. | Environment | LeGO-LOAM [19] | A-LOAM [25] | Ours |
|---|---|---|---|---|
| 77–91 | Urban | 5.19/12.58 | 3.53/3.44 | 1.68/3.28 |
| 111–119 | Urban | 9.60/15.09 | 3.20/3.02 | 1.77/3.74 |
| 140–148 | Country | 8.90/16.32 | 5.71/5.38 | 3.85/3.69 |
| 265–266 | Urban | 3.55/11.46 | 5.74/4.83 | 1.54/3.45 |
| 279–282 | Country | 8.05/17.74 | 3.08/3.14 | 4.33/2.85 |
| 307–314 | Country | 9.03/26.23 | 4.40/4.83 | 4.10/7.0 |
| 333–343 | Urban | 10.70/16.46 | 5.51/4.27 | 1.98/3.3 |
| 547–551 | Urban | 6.34/13.28 | 5.42/2.73 | 1.24/2.17 |
| 602–604 | rain,Urban | 4.53/12.25 | 5.79/4.98 | 1.17/3.15 |
| 606–624 | rain,Urban | 6.97/18.78 | 5.81/4.72 | 1.57/4.00 |
| 833–842 | Country | 9.07/22.05 | 4.34/4.73 | 4.77/6.8 |
| 935–943 | Country | 12.12/21.80 | 5.63/4.18 | 5.37/3.71 |
| 1026–1043 | Country, Dark night | 13.79/20.34 | 3.28/4.06 | 6.04/4.72 |
| avg | 8.30/17.26 | 4.57/4.18 | 3.03/3.99 |
| Seq. No | Path Len. (m) | Environment | A-LOAM [25] FF | Ours FF | Ours FK-3 | Ours FK-5 | Ours FK-* | Ours FF-SW | Ours FF-SW-SM |
|---|---|---|---|---|---|---|---|---|---|
| 00 | 3714 | Urban | 4.11/1.70 | 1.08/0.52 | 1.00/0.50 | 1.67/0.88 | 1.12/0.55 | 0.95/0.43 | 0.65/0.30 |
| 01 | 4268 | Highway | 3.94/0.95 | 1.39/0.41 | -/- | -/- | 1.54/0.45 | 1.30/0.35 | 1.74/0.43 |
| 02 | 5075 | Urban+Country | 7.48/2.51 | 0.98/0.33 | 1.23/0.50 | 1.79/0.76 | 1.08/0.40 | 0.98/0.33 | 0.97/0.33 |
| 03 | 563 | Country | 4.54/2.15 | 1.19/0.48 | 1.14/0.53 | 1.53/1.12 | 1.08/0.50 | 0.95/0.88 | 0.85/0.48 |
| 04 | 397 | Country | 1.74/1.13 | 0.74/0.43 | 0.68/0.39 | 0.77/0.67 | 0.63/0.38 | 0.61/0.26 | 0.39/0.62 |
| 05 | 2223 | Urban | 4.13/1.75 | 1.20/0.58 | 0.88/0.42 | 0.96/0.50 | 0.98/0.48 | 0.79/0.36 | 0.54/0.30 |
| 06 | 1239 | Urban | 1.04/0.55 | 1.32/0.45 | 1.19/0.40 | 0.91/0.36 | 1.27/0.41 | 0.91/0.31 | 0.65/0.33 |
| 07 | 695 | Urban | 3.14/1.99 | 1.26/0.85 | 1.12/0.70 | 1.39/0.88 | 1.39/1.55 | 0.88/0.55 | 0.51/0.33 |
| 08 | 3225 | Urban+Country | 4.85/2.09 | 1.60/0.68 | 1.49/0.62 | 1.68/0.81 | 1.47/0.61 | 1.39/0.51 | 0.89/0.32 |
| 09 | 1717 | Urban+Country | 5.73/1.85 | 0.95/0.46 | 0.87/0.46 | 1.30/0.65 | 0.93/0.46 | 0.71/0.33 | 0.73/0.32 |
| 10 | 919 | Urban+Country | 3.61/1.78 | 1.05/0.49 | 0.96/0.42 | 1.29/0.66 | 0.87/0.43 | 0.77/0.36 | 0.87/0.47 |
| avg | 4.03/1.68 | 1.16/0.51 | -/- | -/- | 1.12/0.57 | 0.94/0.43 | 0.80/0.38 |
| Dateset | Approachs | Precision (%) | Recall Rate (/) |
|---|---|---|---|
| stereo ORB-SLAM2 | 100 | 4/4 | |
| sequence 00 | LeGO-LOAM | 100 | 4/4 |
| Ours | 100 | 4/4 | |
| stereo ORB-SLAM2 | 100 | 2/3 | |
| sequence 02 | LeGO-LOAM | 100 | 1/3 |
| Ours | 100 | 3/3 | |
| stereo ORB-SLAM2 | 100 | 3/3 | |
| sequence 05 | LeGO-LOAM | 100 | 3/3 |
| Ours | 100 | 3/3 | |
| stereo ORB-SLAM2 | 0 | 0/3 | |
| sequence 08 | LeGO-LOAM | 100 | 3/3 |
| Ours | 100 | 3/3 |
| Modules | Sub Modules | KITTI (ms) | nuScenes (ms) | Our Campus (ms) |
|---|---|---|---|---|
| Visual Odometry | frame-to-frame tracking | 25.24 | 8.52 | 13.24 |
| sliding window optimization | 48.34 | 17.76 | 35.73 | |
| LiDAR Mapping | ground extraction | 12.19 | 8.57 | 9.46 |
| feature extraction | 27.84 | 11.30 | 10.23 | |
| scan-to-map optimization | 71.72 | 41.89 | 54.81 | |
| Loop Closing | loop candidates extraction | 3.98 | - | 3.24 |
| consistency verification | 110.37 | - | 102.53 | |
| pose graph optimization | 81.22 | - | 57.78 |
| 00 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 10 | avg | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FF(-) | 1.08/0.52 | 1.39/0.41 | 0.98/0.33 | 1.19/0.48 | 0.74/0.43 | 1.20/0.58 | 1.32/0.45 | 1.26/0.85 | 1.60/0.68 | 0.95/0.46 | 1.05/0.49 | 1.16/0.51 |
| FF(*) | 1.01/0.50 | 1.29/0.40 | 0.96/0.32 | 1.08/0.46 | 0.77/0.41 | 1.06/0.50 | 0.97/0.42 | 1.29/0.93 | 1.60/0.68 | 1.02/0.46 | 1.11/0.46 | 1.11/0.50 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; Liu, J.; Wang, C.; Luo, B.; Zhang, C. DV-LOAM: Direct Visual LiDAR Odometry and Mapping. Remote Sens. 2021, 13, 3340. https://doi.org/10.3390/rs13163340
Wang W, Liu J, Wang C, Luo B, Zhang C. DV-LOAM: Direct Visual LiDAR Odometry and Mapping. Remote Sensing. 2021; 13(16):3340. https://doi.org/10.3390/rs13163340
Chicago/Turabian StyleWang, Wei, Jun Liu, Chenjie Wang, Bin Luo, and Cheng Zhang. 2021. "DV-LOAM: Direct Visual LiDAR Odometry and Mapping" Remote Sensing 13, no. 16: 3340. https://doi.org/10.3390/rs13163340