
Sparse Nonnegative Matrix Factorization for Hyperspectral Unmixing Based on Endmember Independence and Spatial Weighted Abundance


Abstract
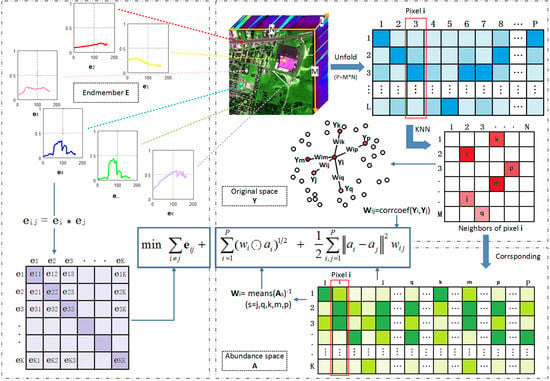
:
1. Introduction
2. Related Work
2.1. LMM
2.2. NMF
3. Sparse NMF for Hyperspectral Unmixing Based on Endmember Independence and Spatial Weighted Abundance
3.1. Endmember Independence Constraint
3.2. Abundance Sparse and Spatial Weighted Constraint
3.3. Manifold Regularization Constraint
| Algorithm 1 Sparse NMF for HU Based on Endmember Independence and Spatial Weighted Abundance |
| 1. Input: The hyperspectral image Y, the number of endmember K, the parameters α, β and γ. |
| 2. Output: Endmember matrix E and abundance matrix A. |
| 3. Initialize E and A by VCA-FCLS algorithm, W by Equation (10), Wg by Equation (12), and D. |
| 4. Repeat: |
| 5. Update E by Equation (15). |
| 6. Augment Y and A separately to get Yf and Af. |
| 7. Update A by Equation (18). |
| 8. Update W by Equation (10). |
| 9. Until stopping criterion is satisfied. |
4. Experiments Results
4.1. Performance Evaluation Criteria
4.2. Data Sets
- Simulated data set 1:
- Simulated data set 2:
- Cuprite data set
4.3. Compared Algorithms
- L1/2-NMF algorithm: it extends the NMF method by incorporating the L1/2 sparsity constraint, which provides a more sparser and accurate results [18].
- GLNMF algorithm: it incorporates the manifold regularization into sparsity NMF, which can preserve the intrinsic geometrical characteristic of HSI data during the unmixing process [35].
- MVCNMF algorithm: it adds the minimum volume constraint into the NMF model and extracts the endmember from highly mixed image data [33].
- CoNMF algorithm: it performs all stages involved in HU process including the endmember number estimation, endmember estimation and abundance estimation [34].
4.4. Initializations and Parameter Settings
- Initialization: the initialization of endmember and abundance is the first issue. In our experiment, we choose the VCA-FCLS algorithm, one basic method for endmember extraction and abundance estimation, as our initialization method to speed up the optimization. VCA algorithm [13] exploits two facts to extract the endmembers: the endmembers are the vertices of a simplex and the affine transformation of a simplex is also a simplex. FCLS algorithm, a quadratic programming technique, is developed to address the fully constrained linear mixing problems, which uses the efficient algorithm to simultaneously implement both the ASC and ANC [14].
- Stopping criterion: it is another important issue and two stopping criteria are adopted for the optimization, i.e., error tolerance and maximum iteration number. When any stop condition is reached, the algorithm stops. When the error is successively within the limits of tolerance, a predefined value, the iteration is stopped. The error tolerance is set as 1.0 × 10−4 for a simulated data set and 1.0 × 10−3 for the real data set in our experiment. The times of iteration meet the maximum iteration number, the optimization ends. The maximum iteration number is set as 1.0 × 106 in experiment.
- ANC and ASC: for the abundance, its initial value obtained by VCA-FCLS algorithm is generally nonnegative. Thus, according to the update rule recorded in Equations (15) and (16), the E and A are obviously nonnegative. Besides, considering the ASC, the A adopted by Equation (18) also satisfies the constraint. Moreover, the parameter ε in Equation (17) controls the convergence rate of ASC. When its value is large, it will lead to an accurate result but with lower convergence rate. As in many papers [35,41], the parameter ε is set as 15 in the experiments for desired tradeoff.
- Parameter setting: there are three parameters in the proposed model, i.e., α, β, γ. They separately control the independence constraint of the endmember, abundance sparse constraint, and the manifold constraint, which will be analyzed in detail in next part of the experiment.
- Endmember number: the endmember number is one of the crucial processes in HU, which is another independent topic. In our experiment, it is considered a topic that does not have much relation to this paper and it is assumed to be known. In fact, the algorithms of HySime [8] and VD [9] could be adopted to estimate the number of endmembers. Hysime algorithm [8] is a new minimum mean square error-based approach to infer the signal subspace in hyperspectral imagery. In the experiment, we can also analyze the number of endmembers around the number estimated by Hysime algorithm via the reconstruction error.
- Computational complexity: here, we analyze the computational complexity of the proposed EASNMF algorithm. It is noticeable that the matrix Wg is sparse and there are m nonzero elements in each row. Therefore, the floating-point addition and multiplication for AWg in Equation (16) cost mPK times. Additionally, the computing cost of A−1/2 is (PK)2. Except for these costs, the other three floating-point calculation times for each iteration are listed in Table 1.
4.5. Experiment on Simulated Data Set 1
4.6. Experiment on Simulated Data Set 2
4.7. Experiment on Cuprite Data Set
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Plaza, A.; Du, Q.; Bioucas-Dias, J.M.; Jia, X.; Kruse, F.A. Foreword to the special issue on spectral unmixing of remotely sensed data. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4103–4110. [Google Scholar] [CrossRef] [Green Version]
- Bioucas-Dias, J.M.; Plaza, A.; Dobigeon, N.; Parente, M.; Du, Q.; Gader, P.; Chanussot, J. Hyperspectral unmixing overview: Geometrical, statistical, and sparse regression-based approaches. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 354–379. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Li, C.; Zhang, J.; Chen, Q.; Jiao, L.; Zhou, H. Hyperspectral unmixing via low-rank representation with space consistency constraint and spectral library pruning. Remote Sens. 2018, 10, 339. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Gao, Z.; Jiao, L.; Zhou, H. Multifeature hyperspectral image classification with local and nonlocal spatial information via Markov random field in semantic space. IEEE Trans. Geosci. Remote Sens. 2018, 56, 1409–1424. [Google Scholar] [CrossRef] [Green Version]
- Huyan, N.; Zhang, X.; Zhou, H.; Jiao, L. Hyperspectral Anomaly Detection via Background and Potential Anomaly Dictionaries Construction. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2263–2276. [Google Scholar] [CrossRef] [Green Version]
- Ma, X.; Zhang, X.; Tang, X.; Zhou, H.; Jiao, L. Hyperspectral Anomaly Detection Based on Low-Rank Representation With Data-Driven Projection and Dictionary Construction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2226–2239. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, J.; Li, C.; Cheng, C.; Jiao, L.; Zhou, H. Hybrid unmixing based on adaptive region segmentation for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3861–3875. [Google Scholar] [CrossRef] [Green Version]
- Bioucas-Dias, J.M.; Nascimento, J.M.P. Hyperspectral subspace identification. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2435–2445. [Google Scholar] [CrossRef] [Green Version]
- Chang, C.I.; Du, Q. Estimation of number of spectrally distinct signal sources in hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2004, 42, 608–619. [Google Scholar] [CrossRef] [Green Version]
- Green, A.A.; Berman, M.; Switzer, P.; Craig, M.D. A transformation for ordering multispectral data in terms of image quality with implications for noise removal. IEEE Trans. Geosci. Remote Sens. 1988, GRS-26, 65–74. [Google Scholar] [CrossRef] [Green Version]
- Boardman, J.; Kruse, F.A.; Green, R.O. Mapping target signatures via partial unmixing of AVIRIS data. Proc. JPL Airborne Earth Sci. Workshop 1995, 1, 23–26. [Google Scholar]
- Winter, M.E. N-FINDR: An algorithm for fast autonomous spectral end-member determination in hyperspectral data. Proc. SPIE 1999, 3753, 266–275. [Google Scholar]
- Nascimento, J.M.P.; Dias, J.M.B. Vertex component analysis: A fast algorithm to unmix hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 898–910. [Google Scholar] [CrossRef] [Green Version]
- Heinz, D.C.; Chang, C.I. Fully constrained least squares linear spectral mixture analysis method for material quantification in hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2001, 39, 529–545. [Google Scholar] [CrossRef] [Green Version]
- Yang, S.; Zhang, X.; Yao, Y.; Cheng, S.; Jiao, L. Geometric nonnegative matrix factorization (gnmf) for hyperspectral unmixing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2696–2703. [Google Scholar] [CrossRef]
- Zhang, Z.; Liao, S.; Zhang, H.; Wang, S.; Wang, Y. Bilateral filter regularized L2 sparse nonnegative matrix factorization for hyperspectral unmixing. Remote Sens. 2018, 10, 816. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Sun, Y.; Zhang, J.; Wu, P.; Jiao, L. Hyperspectral unmixing via deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1755–1759. [Google Scholar] [CrossRef]
- Qian, Y.; Jia, S.; Zhou, J.; Robles-Kelly, A. Hyperspectral unmixing via L1/2 sparsity-constrained nonnegative matrix factorization. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4282–4297. [Google Scholar] [CrossRef] [Green Version]
- Iordache, M.D.; Bioucas-Dias, J.M.; Plaza, A. Sparse unmixing of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2011, 49, 2014–2039. [Google Scholar] [CrossRef] [Green Version]
- Xu, Z.; Zhang, H.; Wang, Y.; Chang, X.; Liang, Y. L1/2 regularizer. Sci. China Inf. Sci. 2010, 53, 1159–1169. [Google Scholar] [CrossRef] [Green Version]
- Iordache, M.D.; Bioucas-Dias, J.M.; Plaza, A. Total variation spatial regularization for sparse hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4484–4502. [Google Scholar] [CrossRef] [Green Version]
- Iordache, M.D.; Bioucas-Dias, J.M.; Plaza, A. Collaborative sparse regression for hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2014, 52, 341–354. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Li, J.; Liu, K.; Deng, C.; Liu, L.; Plaza, A. Hyperspectral unmixing based on local collaborative sparse regression. IEEE Geosci. Remote Sens. Lett. 2016, 13, 631–635. [Google Scholar] [CrossRef]
- Zhang, S.; Li, J.; Wu, Z.; Plaza, A. Spatial discontinuity-weighted sparse unmixing of hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5767–5779. [Google Scholar] [CrossRef]
- Feng, R.; Wang, L.; Zhong, Y. Joint local block grouping with noise-adjusted principal component analysis for hyperspectral remote-sensing imagery sparse unmixing. Remote Sens. 2019, 11, 1223. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Li, J.; Li, H.; Deng, C.; Plaza, A. Spectral-spatial weighted sparse regression for hyperspectral image unmixing. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3265–3276. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Algorithms for non-negative matrix factorization. In Proceedings of the 14th Annual Neural Information Processing Systems Conference, NIPS 2000, Denver, CO, USA, 27 November–2 December 2000; pp. 535–541. [Google Scholar]
- Casalino, G.; Gillis, N. Sequential dimensionality reduction for extracting localized features. Pattern Recognit. 2017, 63, 15–29. [Google Scholar] [CrossRef] [Green Version]
- Peng, J.; Zhou, Y.; Sun, W.; Du, Q.; Xia, L. Self-Paced Nonnegative Matrix Factorization for Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1501–1515. [Google Scholar] [CrossRef]
- Uezato, T.; Fauvel, M.; Dobigeon, N. Hierarchical sparse nonnegative matrix factorization for hyperspectral unmixing with spectral variability. Remote Sens. 2020, 12, 2326. [Google Scholar] [CrossRef]
- Dong, L.; Yuan, Y.; Luxs, X. Spectral-spatial joint sparse nmf for hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2021, 59, 2391–2402. [Google Scholar] [CrossRef]
- He, W.; Zhang, H.; Zhang, L. Sparsity-regularized robust non-negative matrix factorization for hyperspectral unmixing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4267–4279. [Google Scholar] [CrossRef]
- Miao, L.; Qi, H. Endmember extraction from highly mixed data using minimum volume constrained nonnegative matrix factorization. IEEE Trans. Geosci. Remote Sens. 2007, 45, 765–777. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A.; Liu, L. Robust collaborative nonnegative matrix factorization for hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6076–6090. [Google Scholar] [CrossRef] [Green Version]
- Lu, X.; Wu, H.; Yuan, Y.; Yan, P.; Li, X. Manifold regularized sparse NMF for hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2815–2826. [Google Scholar] [CrossRef]
- Wang, X.; Zhong, Y.; Zhang, L.; Xu, Y. Spatial group sparsity regularized nonnegative matrix factorization for hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6287–6304. [Google Scholar] [CrossRef]
- Wang, W.; Qian, Y.; Liu, H. Multiple clustering guided nonnegative matrix factorization for hyperspectral unmixing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5162–5179. [Google Scholar] [CrossRef]
- Xiong, F.; Zhou, J.; Lu, J.; Qian, Y. Nonconvex nonseparable sparse nonnegative matrix factorization for hyperspectral unmixing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 6088–6100. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, X.; Tang, X.; Chen, P.; Jiao, L. Sketch-based region adaptive sparse unmixing applied to hyperspectral image. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8840–8856. [Google Scholar] [CrossRef]
- Li, M.; Zhu, F.; Guo, A.J.X.; Chen, J. A graph regularized multilinear mixing model for nonlinear hyperspectral unmixing. Remote Sens. 2019, 11, 2188. [Google Scholar] [CrossRef] [Green Version]
- He, W.; Zhang, H.; Zhang, L. Total variation regularized reweighted sparse nonnegative matrix factorization for hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3909–3921. [Google Scholar] [CrossRef]
- Wang, M.; Zhang, B.; Pan, X.; Yang, S. Group low-rank nonnegative matrix factorization with semantic regularizer for hyperspectral unmixing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1022–1029. [Google Scholar] [CrossRef]
- Salehani, Y.E.; Gazor, S. Smooth and sparse regularization for nmf hyperspectral unmixing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3677–3692. [Google Scholar] [CrossRef]
- Feng, R.; Zhong, Y.; Zhang, L. Adaptive spatial regularization sparse unmixing strategy based on joint MAP for hyperspectral remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2016, 9, 5791–5805. [Google Scholar] [CrossRef]
- Jimenez, L.I.; Martin, G.; Plaza, A. A new tool for evaluating spectral unmixing applications for remotely sensed hyperspectral image analysis. In Proceedings of the 4th Geographic Object-Based Image Analysis, Rio de Janeiro, Brazil, 7–9 May 2012; pp. 1–5. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Update E | Update A | Total | |
|---|---|---|---|
| Addition | LPK + (2L + P)K2 + 2LK | LPK + (L + P)K2 + (4 + m)PK | 2LPK + (3L + 2P)K2 + 2LK + (4 + m)PK |
| Multiplication | LPK + (2L + P)K2 + LK | LPK + (L + P)K2 + (3 + m)PK | 2LPK + (3L + 2P)K2 + LK + (3 + m)PK |
| Division | LK | PK | (L + P)K |
| L1/2-NMF | GLNMF | MVCNMF | CoNMF | EASNMF | ||
|---|---|---|---|---|---|---|
| RMSE | Average | 0.0257 | 0.0264 | 0.0391 | 0.0973 | 0.0252 |
| Endmember 1 | 0.0173 | 0.0183 | 0.0273 | 0.0883 | 0.0168 | |
| Endmember 2 | 0.0165 | 0.0174 | 0.0255 | 0.0839 | 0.0163 | |
| Endmember 3 | 0.0335 | 0.0368 | 0.0527 | 0.1104 | 0.0341 | |
| Endmember 4 | 0.0203 | 0.0248 | 0.0299 | 0.0945 | 0.0199 | |
| Endmember 5 | 0.0202 | 0.0257 | 0.0259 | 0.0934 | 0.0204 | |
| Endmember 6 | 0.0382 | 0.0357 | 0.0598 | 0.1124 | 0.0368 | |
| Endmember 7 | 0.0129 | 0.0191 | 0.0301 | 0.0631 | 0.0137 | |
| Endmember 8 | 0.0195 | 0.0210 | 0.0371 | 0.0837 | 0.0189 | |
| Endmember 9 | 0.0527 | 0.0385 | 0.0638 | 0.1459 | 0.0500 | |
| SAD | Average | 0.0218 | 0.0318 | 0.0444 | 0.2215 | 0.0188 |
| Endmember 1 | 0.0141 | 0.0346 | 0.0203 | 0.2233 | 0.0138 | |
| Endmember 2 | 0.0083 | 0.0151 | 0.0200 | 0.1250 | 0.0076 | |
| Endmember 3 | 0.0396 | 0.0319 | 0.0974 | 0.3549 | 0.0333 | |
| Endmember 4 | 0.0060 | 0.0101 | 0.0096 | 0.0821 | 0.0054 | |
| Endmember 5 | 0.0151 | 0.0190 | 0.0192 | 0.1102 | 0.0132 | |
| Endmember 6 | 0.0540 | 0.1077 | 0.0713 | 1.4470 | 0.0411 | |
| Endmember 7 | 0.0099 | 0.0074 | 0.0240 | 0.0661 | 0.0100 | |
| Endmember 8 | 0.0075 | 0.0153 | 0.0235 | 0.0476 | 0.0075 | |
| Endmember 9 | 0.0415 | 0.0454 | 0.1141 | 0.8180 | 0.0378 | |
| L1/2-NMF | GLNMF | MVCNMF | CoNMF | EASNMF | ||
|---|---|---|---|---|---|---|
| RMSE | Average | 0.0820 | 0.0812 | 0.0863 | 0.1149 | 0.0783 |
| Endmember 1 | 0.1824 | 0.1596 | 0.2311 | 0.1359 | 0.1567 | |
| Endmember 2 | 0.0410 | 0.0479 | 0.0414 | 0.1060 | 0.0442 | |
| Endmember 3 | 0.0837 | 0.0755 | 0.0839 | 0.1266 | 0.0743 | |
| Endmember 4 | 0.0785 | 0.0406 | 0.0517 | 0.1194 | 0.0458 | |
| Endmember 5 | 0.0570 | 0.0544 | 0.0685 | 0.1418 | 0.0496 | |
| Endmember 6 | 0.2066 | 0.1857 | 0.2109 | 0.1028 | 0.1852 | |
| Endmember 7 | 0.0305 | 0.0459 | 0.0397 | 0.0907 | 0.0377 | |
| Endmember 8 | 0.0514 | 0.0716 | 0.0656 | 0.0979 | 0.0630 | |
| Endmember 9 | 0.0402 | 0.0498 | 0.0800 | 0.1129 | 0.0483 | |
| SAD | Average | 0.0164 | 0.0195 | 0.0184 | 0.1274 | 0.0149 |
| Endmember 1 | 0.0416 | 0.0231 | 0.0466 | 0.0371 | 0.0255 | |
| Endmember 2 | 0.0061 | 0.0089 | 0.0115 | 0.1087 | 0.0065 | |
| Endmember 3 | 0.0088 | 0.0244 | 0.0118 | 0.6776 | 0.0051 | |
| Endmember 4 | 0.0068 | 0.0092 | 0.0066 | 0.0747 | 0.0070 | |
| Endmember 5 | 0.0199 | 0.0245 | 0.0251 | 1.5555 | 0.0161 | |
| Endmember 6 | 0.3723 | 0.7477 | 0.3692 | 0.0464 | 0.6028 | |
| Endmember 7 | 0.0070 | 0.0258 | 0.0064 | 0.1516 | 0.0156 | |
| Endmember 8 | 0.0208 | 0.0101 | 0.0209 | 0.0593 | 0.0124 | |
| Endmember 9 | 0.0047 | 0.0075 | 0.0120 | 0.0857 | 0.0052 | |
| L1/2-NMF | GLNMF | MVCNMF | CoNMF | EASNMF | ||
|---|---|---|---|---|---|---|
| SAD | Average | 0.0772 | 0.0782 | 0.0804 | 0.1428 | 0.0769 |
| Alunite | 0.1137 | 0.1190 | 0.1140 | 0.4430 | 0.1136 | |
| Andradite | 0.0700 | 0.0709 | 0.0708 | 0.1510 | 0.0697 | |
| Buddingtonite | 0.0743 | 0.0731 | 0.0771 | 0.6229 | 0.0700 | |
| Dumortierite | 0.0848 | 0.0840 | 0.0866 | 0.2227 | 0.0825 | |
| Kaolinite1 | 0.0984 | 0.1005 | 0.1039 | 0.2934 | 0.1002 | |
| Kaolinite2 | 0.0742 | 0.0685 | 0.0746 | 0.4582 | 0.0748 | |
| Muscovite | 0.0892 | 0.0856 | 0.0897 | 0.3318 | 0.0878 | |
| Montmorillonite | 0.0594 | 0.0607 | 0.0643 | 0.1357 | 0.0607 | |
| Nontronite | 0.0710 | 0.0746 | 0.0778 | 0.2425 | 0.0739 | |
| Pyrope | 0.0596 | 0.0644 | 0.0602 | 0.1416 | 0.0588 | |
| Sphene | 0.0571 | 0.0674 | 0.0621 | 1.4085 | 0.0584 | |
| Chalcedony | 0.0866 | 0.0810 | 0.0878 | 0.0830 | 0.0883 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Zhang, X.; Jiao, L. Sparse Nonnegative Matrix Factorization for Hyperspectral Unmixing Based on Endmember Independence and Spatial Weighted Abundance. Remote Sens. 2021, 13, 2348. https://doi.org/10.3390/rs13122348
Zhang J, Zhang X, Jiao L. Sparse Nonnegative Matrix Factorization for Hyperspectral Unmixing Based on Endmember Independence and Spatial Weighted Abundance. Remote Sensing. 2021; 13(12):2348. https://doi.org/10.3390/rs13122348
Chicago/Turabian StyleZhang, Jingyan, Xiangrong Zhang, and Licheng Jiao. 2021. "Sparse Nonnegative Matrix Factorization for Hyperspectral Unmixing Based on Endmember Independence and Spatial Weighted Abundance" Remote Sensing 13, no. 12: 2348. https://doi.org/10.3390/rs13122348