
Multithreading Based Parallel Processing for Image Geometric Coregistration in SAR Interferometry


Abstract
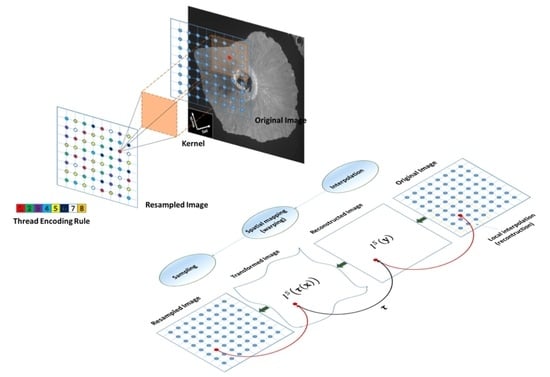
:
1. Introduction
2. Coregistration Functional Scheme
2.1. Coarse Coregistration
2.2. Sub-Pixel Coregistration
2.2.1. Problem Formulation
2.2.2. Warping Functions Evaluation
2.2.3. Warping Function Geometrical Computation
2.2.4. Secondary Image Resampling Scheme
3. Parallel Scheme and Multithreading Implementation
3.1. Overview of Parallel Algorithm Design
3.2. Parallel Pattern Design of the Coregistration Algorithm
3.2.1. Shared-Memory Parallelism for Warping Function Computation
3.2.2. Shared-Memory Parallelism for 2D Resampling Computation
3.3. OPENMP-Based Parallel Implementation
4. Experimental Results and Performance Evaluation
4.1. Processed SAR Data and Experimental Setup
4.2. Quantitative Analysis of Speedup, Parallel Efficiency, and Scalability
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Le Moigne, J.; Netanyahu, N.S.; Eastman, R.D. (Eds.) Image Registration for Remote Sensing; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Fornaro, G.; Franceschetti, G.; Lanari, R.; Sansosti, E.; Tesauro, M. Global and local phase-unwrapping techniques: A comparison. J. Opt. Soc. Am. A 1997, 14, 2702–2708. [Google Scholar] [CrossRef]
- Fornaro, G.; Sansosti, E. A two-dimensional region growing least squares phase unwrapping algorithm for interferometric SAR processing. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2215–2226. [Google Scholar] [CrossRef]
- Imperatore, P.; Pepe, A.; Lanari, R. Multichannel Phase Unwrapping: Problem Topology and Dual-Level Parallel Computational Model. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5774–5793. [Google Scholar] [CrossRef]
- Tian, Q.; Huhns, M.N. Algorithms for subpixel registration. Comput. Vis. Graph. Image Process. 1986, 35, 220–223. [Google Scholar] [CrossRef]
- Brown, L.G. A survey of image registration techniques. ACM Comput. Surv. 1992, 24, 325–376. [Google Scholar] [CrossRef]
- Scheiber, R.; Moreira, A. Coregistration of interferometric SAR images using spectral diversity. IEEE Trans. Geosci. Remote Sens. 2000, 38, 2179–2191. [Google Scholar] [CrossRef]
- Liao, M.; Lin, H.; Zhang, Z. Automatic registration of InSAR data based on least-square matching and multi-step strategy. Photogramm. Eng. Remote Sens. 2004, 70, 1139–1144. [Google Scholar] [CrossRef]
- Sansosti, E.; Berardino, P.; Manunta, M.; Serafino, F.; Fornaro, G. Geometrical SAR image registration. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2861–2870. [Google Scholar] [CrossRef]
- Guizar-Sicairos, M.; Thurman, S.T.; Fienup, J.R. Efficient subpixel image registration algorithms. Opt. Lett. 2008, 33, 156–158. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Z.; Bethel, J. Image coregistration in SAR interferometry. Proc. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2008, 37, 433–438. [Google Scholar]
- Liu, B.Q.; Feng, D.Z.; Shui, P.L.; Wu, N. Analytic search method for interferometric SAR image registration. IEEE Geosci. Remote Sens. Lett. 2008, 8, 294–298. [Google Scholar]
- Nitti, D.O.; Hanssen, R.F.; Refice, A.; Bovenga, F.; Nutricato, R. Impact of DEM Assisted Coregistration on High-Resolution SAR Interferometry. IEEE Trans. Geosci. Remote Sens. 2011, 49, 1127–1143. [Google Scholar] [CrossRef]
- Solaro, G.; Imperatore, P.; Pepe, A. Satellite SAR Interferometry for Earth’s Crust Deformation Monitoring and Geological Phenomena Analysis. In Geospatial Technology—Environmental and Social Applications; InTech: Rijeka, Croatia, 2016. [Google Scholar]
- Franceschetti, G.; Imperatore, P.; Iodice, A.; Riccio, D. Radio-coverage parallel computation on multi-processor platforms. In Proceedings of the 2009 European Microwave Conference (EuMC), Rome, Italy, 29 September–1 October 2009; pp. 1575–1578. [Google Scholar]
- Imperatore, P.; Pepe, A.; Lanari, R. High-performance parallel computation of the multichannel phase unwrapping problem. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4097–4100. [Google Scholar]
- Imperatore, P.; Pepe, A.; Berardino, P.; Lanari, R. A segmented block processing approach to focus synthetic aperture radar data on multicore processors. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 2421–2424. [Google Scholar]
- Imperatore, P.; Pepe, A.; Lanari, R. Spaceborne Synthetic Aperture Radar Data Focusing on Multicore-Based Architectures. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4712–4731. [Google Scholar] [CrossRef]
- Imperatore, P.; Zinno, I.; Elefante, S.; de Luca, C.; Manunta, M.; Casu, F. Scalable performance analysis of the parallel SBAS-DInSAR algorithm. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 350–353. [Google Scholar]
- Plaza, A.; Du, Q.; Chang, Y.L.; King, R.L. Special Issue on High Performance Computing in Earth Observation and Remote Sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 503–507. [Google Scholar] [CrossRef] [Green Version]
- Foster, I. Designing and Building Parallel Programs: Concepts and Tools for Parallel Software Engineering; Addison-Wesley: Reading, MA, USA, 1995. [Google Scholar]
- Dongarra, J.; Foster, I.; Fox, G.; Gropp, W.; Kennedy, K.; Torczon, L.; White, A. Sourcebook of Parallel Computing; Morgan Kaufman Publishers: San Francisco, CA, USA, 2003. [Google Scholar]
- Mattson, T.G.; Sanders, B.; Massingill, B. Patterns for Parallel Programming; Addison-Wesley: Boston, MA, USA, 2005. [Google Scholar]
- Pacheco, P.S. An Introduction to Parallel Programming; Morgan Kaufmann: Burlington, MA, USA, 2011. [Google Scholar]
- Gropp, W.; Gropp, W.D.; Lusk, E.; Skjellum, A.; Lusk, A.D.F.E.E. Using MPI: Portable Parallel Programming with the Message-Passing Interface; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Akl, S.G. The Design and Analysis of Parallel Algorithms; Prentice Hall: Englewood Cliffs, NJ, USA, 1989. [Google Scholar]
- Hager, G.; Wellein, G. Introduction to High Performance Computing for Scientists and Engineers; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- El-Rewini, H.; Abd-El-Barr, M. Advanced Computer Architecture and Parallel Processing; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2005. [Google Scholar]
- Gebali, F. Algorithms and Parallel Computing; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2011. [Google Scholar]
- Chapman, B.; Jost, G.; van der, R.P. Using OpenMP: Portable Shared Memory Parallel Programming; MIT Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Knapp, C.H.; Carter, G.C. The generalized correlation method for estimation of time delay. IEEE Trans. Acoust. Speech Signal Process. 1976, 24, 320–327. [Google Scholar] [CrossRef] [Green Version]
- Glasbey, C.A.; Mardia, K.V. A review of image-warping methods. J. Appl. Stat. 1998, 25, 155–171. [Google Scholar] [CrossRef] [Green Version]
- Wolberg, G. Digital Image Warping; IEEE Computer Society Press: Los Alamitos, CA, USA, 1990; Volume 10662. [Google Scholar]
- Foroosh, H.; Zerubia, J.B.; Berthod, M. Extension of phase correlation to subpixel registration. IEEE Trans. Image Process. 2002, 11, 188–199. [Google Scholar] [CrossRef] [Green Version]
- Sansosti, E. A Simple and Exact Solution for the Interferometric and Stereo SAR Geolocation Problem. IEEE Trans.Geosci. Remote Sens. 2004, 42, 1625–1634. [Google Scholar] [CrossRef]
- Fornaro, G.; Sansosti, E.; Lanari, R.; Tesauro, M. Role of processing geometry in SAR raw data focusing. IEEE Trans. Aerosp. Electron. Syst. 2002, 38, 441–454. [Google Scholar] [CrossRef]
- Pepe, A.; Berardino, P.; Bonano, M.; Euillades, L.D.; Lanari, R.; Sansosti, E. SBAS-Based Satellite Orbit Correction for the Generation of DInSAR Time-Series: Application to RADARSAT-1 Data. IEEE Trans. Geosci. Remote Sens. 2011, 49, 5150–5165. [Google Scholar] [CrossRef]
- Goodman, W.G.; Carrara, R.S.; Majewski, R.M. Spotlight Synthetic Aperture Radar Signal Processing Algorithms; Artech House: Boston, USA, 1995; pp. 245–285. [Google Scholar]
- Knab, J.J. Interpolation of band-limited functions using the approximate prolate series. IEEE Trans. Inf. Theory 1979, IT-25, 717–720. [Google Scholar] [CrossRef]
- Knab, J.J. The sampling window. IEEE Trans. Inf. Theory 1983, IT–29, 157–159. [Google Scholar] [CrossRef]
- Keys, R. Cubic convolution interpolation for digital image processing. IEEE Trans. Acoust. Speech Signal Process. 1981, 29, 1153–1160. [Google Scholar] [CrossRef] [Green Version]
- Hanssen, R.; Bamler, R. Evaluation of interpolation kernels for SAR interferometry. IEEE Trans. Geosci. Remote Sens. 1999, 37, 318–321. [Google Scholar] [CrossRef]
- Migliaccio, M.; Bruno, F. A new interpolation kernel for SAR interferometric registration. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1105–1110. [Google Scholar] [CrossRef]
- Cho, B.L.; Kong, Y.K.; Kim, Y.S. Interpolation using optimum Nyquist filter for SAR interferometry. J. Electromagn. Waves Appl. 2005, 19, 129–135. [Google Scholar] [CrossRef]
- Gmys, J.; Carneiro, T.; Melab, N.; Talbi, E.G.; Tuyttens, D. A comparative study of high-productivity high-performance programming languages for parallel metaheuristics. Swarm Evol. Comput. 2020, 57, 100720. [Google Scholar] [CrossRef]
- Frigo, M.; Johnson, S.G. The design and implementation of FFTW3. Proc. IEEE 2005, 93, 216–231. [Google Scholar] [CrossRef] [Green Version]
- Rauber, T.; Rünger, G. Parallel Programming, for Multicore and Cluster Systems; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Pepe, A.; Impagnatiello, F.; Imperatore, P.; Lanari, R. Hybrid Stripmap–ScanSAR Interferometry: Extension to the X-Band COSMO-SkyMed Data. IEEE Geosci. Remote Sens. Lett. 2018, 15, 330–334. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Reference | Secondary |
|---|---|---|
| Acquisition Date | 11-APR-2018 | 27-APR-2018 |
| Orbit Direction | descending | |
| Image Size (range × azimuth) | 16,600 × 14,200 | |
| Real Azimuth Antenna Dimension [m] | 5.6 | |
| Carrier Frequency [GHz] | 9.60 | |
| Range Sampling Frequency [MHz] | 84.38 | |
| Pulse Repetition Frequency—PRF [Hz] | 3114.62 | |
| Range Bandwidth [MHz] | 69.73 | |
| Processed Range Bandwidth | 100% | |
| Azimuth Bandwidth [kHz] | 2.60 | |
| Processed Azimuth Bandwidth | 100% | |
| Mean Doppler centroid [kHz] | −417.19 | −553.26 |
| Azimuth Pixel Spacing [m] | 2.33 | |
| Range Pixel Spacing [m] | 1.78 | |
| Perpendicular Baseline [m] | 441 | |
| Parallel Baseline [m] | 625 | |
| Platform | CPU | Number of Processors | RAM Physical Memory | Number of Physical Cores | Number of Logical Cores (1) |
|---|---|---|---|---|---|
| A | Intel® Xeon CPU E5-2660 @ 2.20 GHz | 2 | 384 GB | 16 | 32 |
| B | Intel® Core™ i7-6700HQ CPU @2.60 GHz | 1 | 16 GB | 4 | 8 |
| Number of Engaged Threads | 1 | 2 | 4 | 8 | 16 | 32 (1) | Scheduling |
|---|---|---|---|---|---|---|---|
| Speedup | 1 | 1.60 | 2.76 | 4.40 | 5.71 | 6.20 | Static |
| Efficiency | 1 | 0.78 | 0.60 | 0.45 | 0.35 | 0.19 | |
| Execution time (s) | 327 | 204 | 118 | 74 | 57 | 52 | |
| Speedup | 1 | 1.60 | 2.77 | 4.41 | 5.73 | 6.81 | Dynamic |
| Efficiency | 1 | 0.80 | 0.69 | 0.55 | 0.36 | 0.21 | |
| Execution time (s) | 327 | 204 | 118 | 74 | 57 | 48 | |
| Estimated sequential time (s) | 21 | ||||||
| Number of Engaged Threads | 1 | 2 | 4 | 8 (1) | Scheduling |
|---|---|---|---|---|---|
| Speedup | 1 | 1.82 | 2.95 | 4.04 | Static |
| Efficiency | 1 | 0.91 | 0.74 | 0.50 | |
| Execution time (s) | 517 | 284 | 175 | 128 | |
| Speedup | 1 | 1.85 | 3.01 | 4.53 | Dynamic |
| Efficiency | 1 | 0.92 | 0.75 | 0.57 | |
| Execution time (s) | 517 | 280 | 172 | 114 | |
| Estimated sequential time (s) | 10 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Imperatore, P.; Sansosti, E. Multithreading Based Parallel Processing for Image Geometric Coregistration in SAR Interferometry. Remote Sens. 2021, 13, 1963. https://doi.org/10.3390/rs13101963
Imperatore P, Sansosti E. Multithreading Based Parallel Processing for Image Geometric Coregistration in SAR Interferometry. Remote Sensing. 2021; 13(10):1963. https://doi.org/10.3390/rs13101963
Chicago/Turabian StyleImperatore, Pasquale, and Eugenio Sansosti. 2021. "Multithreading Based Parallel Processing for Image Geometric Coregistration in SAR Interferometry" Remote Sensing 13, no. 10: 1963. https://doi.org/10.3390/rs13101963