1. Introduction
Oil spills on the sea surface have become major environmental and public safety issues that cannot be ignored. With the widespread attention of the development and utilization of marine resources, the marine transportation industry and the offshore oil and gas industry have developed rapidly in recent years. However, oil spill events from ships and offshore oil platforms frequently occur in various seas all over the world, which results in huge ecological and property losses [
1].
Oil spill accidents often occur in areas with complex marine environments. Therefore, it is hard to directly enter the polluted area to clean or make observations in the early stage. Such events usually last days [
2], weeks [
3], or even months [
4], so continuous observations are needed to study the spreading of oil spills and how much they impact environmental safety [
5]. The Synthetic Aperture Radar (SAR) can be regarded as a sensor used to measure the sea surface roughness. Sea surfaces covered with oil films appear dark in SAR images because the capillary waves and short gravity waves that contribute to the sea surface roughness are damped by the surface tension of oil films [
6]. This gives spaceborne SARs the possibility to monitor oil spills in large areas in a highly efficient and relatively cheap way. Compared with spaceborne optical and infrared sensors, spaceborne SARs have obvious advantages in marine oil spill detection because they yield data independent of the time of day and weather conditions [
7].
However, many oceanic and atmospheric phenomena other than oil spills may also reduce the sea surface roughness and appear dark in SAR images. A typical processing framework for automatic SAR oil spill detection usually contains roughly three steps. The first step is to obtain dark patches from SAR images by an image segmentation algorithm, the second step is to extract features from these dark patches to form a feature vector set, and the third step is to train a classifier using the feature vector set. The obtained classifier can then be used to identify oil spills and lookalikes in the dark patches extracted from SAR images by the same segmentation algorithm [
8].
In the last two decades, many classification algorithms have been developed for SAR oil spill detection based on traditional machine learning (ML), such as the linear model [
9], Decision Trees [
10,
11,
12], Artificial Neural Networks (ANNs) [
13,
14,
15,
16,
17], Support Vector Machines (SVMs) [
18,
19,
20], Bayesian Classifiers [
21,
22], Ensemble Learning [
14], and so on. These methods have demonstrated their own effectiveness based on their respective data. However, we can only evaluate these algorithms perceptually, and it is difficult to directly compare their classification performance indicators due to the various data sets they use.
What the ML approaches essentially do is seek a statistically optimal decision surface in the feature space, and mathematically, it comes down to an optimization problem. For a specific classification problem, the more data there is, the more stable the statistical characteristics, and the more generalizable the obtained decision surface and corresponding classification performance indicators in the problem domain following the same statistical characteristics. In this sense, the classification performance indicators of [
14] are relatively reliable, because its data set includes 4843 oil spills and 18,925 lookalikes extracted from 336 SAR images, which is the largest data set used by the ML classifiers mentioned above. In [
14], an Area weighted Adaboost Multi-Layer Perceptron (AAMLP) was proposed, which achieved a classification accuracy, recall, and precision of 92.50%, 81.40%, and 80.95%, respectively.
In recent years, some Deep Learning (DL) methods have been used for SAR oil spill detection. Huang et al. [
23] proposed a three-layer Deep Belief Network (DBN) with a Gray-Level Co-occurrence Matrix (GLCM) as the input to distinguish whether a piece of SAR sample image is oil spill, lookalike, or sea water. Here, the GLCM was calculated from the sample image. The DBN was trained with 240 samples and obtained a recognition rate of 91.25%. Guo et al. [
24] used a Convolutional Neural Network (GCNN) to distinguish crude oil, plant oil, and oil emulsion. The GCNN was trained with 5400 samples and obtained a recognition rate of 91.33%. Gallego et al. [
25] designed a two-stage Convolutional Neural Network (TSCNN) to classify the pixels of a Side-Looking Airborne Radar (SLAR) image into ship, oil spill, coastal, or sea water. This is actually a segmentation algorithm since it works at a pixel level. The TSCNN achieved an accuracy of 98%, recall of 73%, and precision of 52% for oil spill detection based on a data set of 23 SLAR images. Gallego et al. [
26] proposed a very deep Residual Encoder-Decoder Network (RED-Net) to segment out the oil spill from SLAR, which obtained a recall value of 92.92%.
Although there is no accepted definition for how many layers constitute a "deep" learner, a typical deep network should typically include at least four or five layers [
27]. From this point of view, the layers of the DL networks mentioned above are all relatively shallow. So far, we have not seen a DL network for SAR oil spill detection with more than seven weight layers (including convolutional layers and Fully Connected layers (FCs)). Seven is the layer number of LeNet—the first famous DL network [
28]. The depth of the DL network is most likely related to the size of the data sets used. This issue will be discussed in
Section 5.
In this paper, a Deep Convolutional Neural Network (DCNN) with a sufficient depth is proposed to classify SAR dark patches for oil spill detection as an upgrade solution of the AAMLP used in the automatic SAR oil spill detection system [
14].
We will use the same data set as that of AAMLP to construct the proposed DCNN. Firstly, this data set is relatively large, and the number of samples can be increased sufficiently to support a deeper network through the data augmentation technique (see
Section 5.4). Secondly, it provides a chance to compare the DL network with the traditional ML network based on the same relatively large data set (see
Section 5.3).
At present, there are four main branches of DL architecture, namely the Auto-Encoder (AE), the Convolutional Neural Network (CNN), DBN, and the Recurrent Neural Network (RNN) [
27]. Why CNN is chosen in the proposed network lies in the outstanding performance of several well-known CNNs, i.e., AlexNet [
29], ZFNet [
30], VGG-16, and VGG-19 [
31], exhibited in the competition of the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) from 2012 to 2014, and the successful application of CNNs in the SAR oil spill detection research mentioned above. Therefore, it can be expected that based on the same dark patch data set, a DL network with a better classification performance than that of the traditional ML network can be constructed. A distinctive capability of CNN is that it can learn to extract features directly from the data itself through training, while traditional ML methods require "hand-crafted" features [
27]. It can be seen in
Section 5.5 that the distinguishability of the features automatically extracted by the proposed DCNN in this paper is significantly better than the 77 hand-crafted features used by AAMLP. This is an important reason why the classification performance of DCNN is superior to that of ML methods.
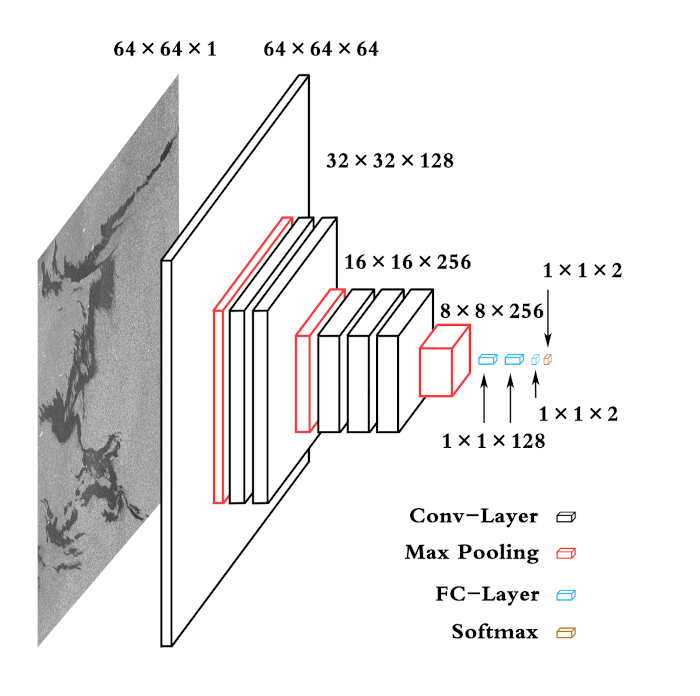
The flowchart employed to build the proposed DCNN is shown in
Figure 1. First, the data set of AAMLP is used to carry out transfer learning in three candidate networks, and then, the best one is taken as the basic network architecture. Next, the network architecture and hyperparameters are adjusted on this basis. The network no longer uses transfer learning, but is trained from scratch, because those adjustment procedures involve changes in both the architecture and hyperparameters. We refer to the resulting network as the Oil Spill Convolutional Network (OSCNet). It should be noted that data augmentation is only applied to the training data set. We believe that it is more objective to evaluate the performance of the classifier using the original test data set.
The rest of the paper is organized as follows:
Section 2 introduces the source and composition of the SAR oil spill dark patch data set and the relevant preprocessing methods; in
Section 3, the basic network architecture is selected from three candidate DCNNs by transfer learning;
Section 4 describes how the architecture is determined and how the hyperparameters are adjusted for establishing the OSCNet; in
Section 5, the experimental results are demonstrated and analyzed, and the comparisons of OSCNet with other classifiers are made; finally, the conclusion and outlooks are given in
Section 6.
2. Data
2.1. Data Set
In 2011, a serious oil spill accident occurred in the Bohai Bay of China, which polluted more than 840 km
2 of sea water and forced the closure of multiple offshore oil and gas platforms. In 2016, an operational automatic SAR oil spill detection system, named CNOOCOM for the China National Offshore Oil Corporation (CNOOC), was developed by the Ocean Remote Sensing Institute, Ocean University of China (ORSI/OUC) [
14]. The system implemented the automatic downloading or manual acquisition of multi-source SAR data, sea-land segmentation, image preprocessing, dark patch extraction by an adaptive threshold segmentation, post-processing of segmentation, feature extraction of dark patches, AAMLP classifiers, and so on. Once an SAR image is received, the system automatically generates a thematic map and reports oil spills found on the SAR image after the series of processing steps described above within about 5 min. The data set used for training AAMLP is composed of 23,768 dark patches extracted from 336 multi-source SAR images by an adaptive threshold segmentation algorithm based on multi-scale background estimation. These dark patches were labeled as 4843 oil slicks and 18,925 lookalikes through an iterative procedure which combined machine and manual classification. The data set covers a large spatial and temporal range, as shown in
Table 1. Additionally, many known big oil spill events, such as the BP oil spill and Bohai oil spill, are included in the data set.
The dark patch generation algorithm is quite complicated and will be introduced in detail in another paper. However, in view of the fact that the data set in this paper is uniformly generated from 336 SAR images using the image segmentation program, it is necessary to briefly introduce the generation process.
First, this algorithm uses an iterative operation to estimate the image intensity component in the sea area as a function of the incident angle. Taking this component as a criterion, the trends of the image intensity with the angle can be eliminated to obtain many coarse dark patches. A series of moving windows with a decreasing size are used to gradually refine the boundary of the dark patches. A distinct advantage of this algorithm is that it is suitable for dark patches of different sizes. Finally, a connected area composed of dark pixels is considered as a single dark patch.
Since an oil spill usually appears as several disconnected dark patches and each one is considered independent, the number of oil spills established through this process is often greater than the number of oil spills identified by experts. Unfortunately, due to the inherent complexity of the SAR image, many small dark patches are inevitably introduced, making the number of dark patches extremely large. To reduce the large number of non-oil dark patches, the image segmentation program also includes a post-processing filtering chain based on simple rules. These rules must be loose enough to guarantee that oil spills will not be removed. Therefore, even with the existence of the filter chain, many non-oil dark patches are still retained. Some of them are not even lookalikes, but since they have become part of the data set, we also consider them as lookalikes. After many post-processing efforts, we successfully reduced the ratio of lookalikes to oil spills from about 100:1 to 3.9:1. This greatly reduced the imbalance of the data set.
As part of the automatic oil spill detection system, the classifier has to process all dark patches generated by the segmentation program when the system is running. Therefore, the data set used for training the classifier must involve all dark patches generated from the 336 images by the segmentation program, so as to ensure that the statistical characteristics of the data set are consistent with those of dark patches to be processed by the classifier in the future.
2.2. Input Size of DCNN
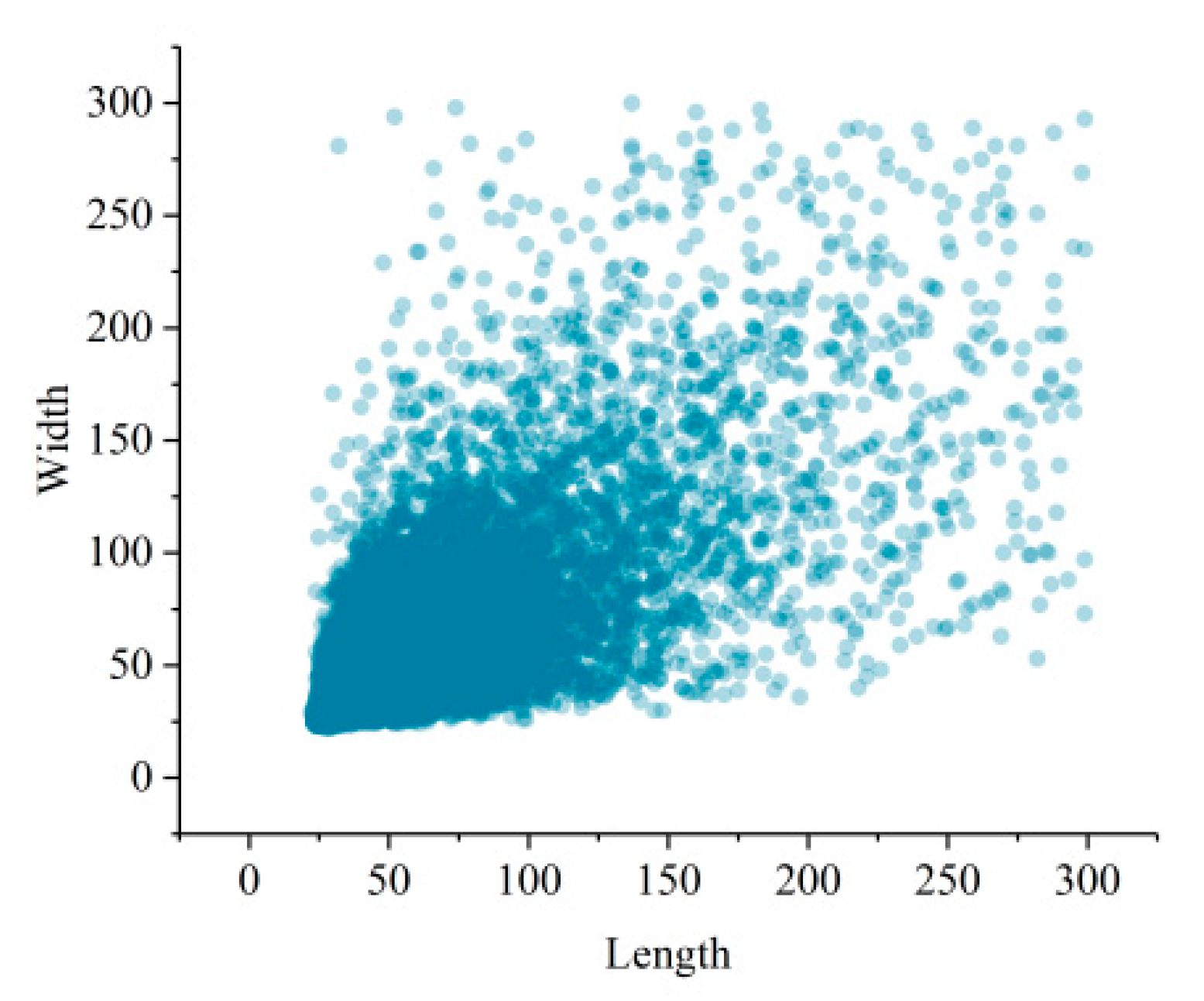
Each dark patch has to be re-sampled to a given size because the DCNN requires the size of the input image to be fixed [
32]. The re-sampled operation will change the aspect ratio of the samples. In order to make the deformation as small as possible, we employed the input size of 64 × 64, which is close to the mean value of the sample size, as shown in
Figure 2. This size was used for all DCNN experiments presented in this paper. The re-sampled operation is performed on-the-fly when a dark patch image is fed to the network during training or evaluating. This facilitates superimposing the samples on the original SAR image to visualize the classification results. In fact, the size of dark patches varies in a very wide range, but as the size increases, the number of dark patches decreases rapidly. The maximum size of an oil spill dark patch is 2136, corresponding to about 150km, which was extracted from a wide swath Envisat ASAR image acquired during the BP oil spill event in the Gulf of Mexico in 2010. In order to show the size distribution more clearly, only samples with a size of less than 300 are plotted.
2.3. Preprocessing
Data set preprocessing is divided into two parts: Data set proportion allocation and data augmentation. Data set proportion allocation is key to guaranteeing the data characteristics of dark patch samples and the ability of network generalization. It is also the basis for a comparison with AAMLP. Data augmentation is employed to maximize the advantage of our data set, without destroying the original data feature distribution, so that the network can avoid over-fitting.
2.3.1. Data Set Proportion Allocation
The proportion of oil spills and lookalikes in the data set is determined by the content of the SAR image and the image segmentation algorithm. The proportion is more dependent on the image segmentation algorithm when the number of SAR images becomes large. Therefore, it is reasonable to assume that the proportion of dark patches fed to the DCNN is statistically stable, since dark patches are obtained for SAR images by a specific segmentation algorithm. For a given dark patch data set, it should be split into a training set and a test set in such a way that both of them have the same proportion as that of the full data set. For the data set in this study, the proportion of oil spills to lookalikes was 1:3.9. Therefore, we randomly picked out 2048 oil spills and 7988 lookalikes from 23,768 dark patches as the test data set, and the remaining were used as the training data set.
2.3.2. Data Augmentation
What the training of DCNN actually does is adjust thousands of weights based on the training data set and labels. In order to make all weights reach the optimal state as much as possible, the number of samples in the training data set should match the number of network parameters [
33]. Data augmentation is a technique used to improve the generalization ability of the network by increasing the number of samples in the training set [
34]. The noise induced by data augmentation also makes the network more robust. Data augmentation has been widely used in the training process of common DL classifiers [
29,
30,
31]. Moreover, this method is also applied in [
25,
26]. Twelve operations of data augmentation are used in our case to expand the training data set. The operations include Rotation (7°, 17°, 27°, 37°, and 47°), Shift(horizontal, H; vertical, V), Scale(H, V) and Flip (H, V, HV), Examples of a typical dark patch sample with data augmentation are shown in
Figure 3. The number of our training set (13,722) was expanded to the order of 10
5-10
6 with data augmentation. The training was done in the network with the original and expanded data set after the proposed network was obtained, respectively, to validate the positive effect of data augmentation (see
Section 5.4 for details).
3. Determine the Basic Architecture of DCNNs
As shown in
Figure 1, we firstly decided on a basic architecture, which was selected from AlexNet, VGG-16, and VGG-19 by transfer learning with our oil spill data set. Here, transfer learning [
35] refers to fine tuning of the model parameters with the dark patch data set based on a model which has already been well trained with the public data set, so as to quickly achieve a good classification performance for our data set. Transfer learning requires an application domain similar to the original one, but allows it to be a little different [
36].
Pre-trained models for the three networks can be downloaded from the Tensorflow group of Google on GitHub—an open source code hosting platform [
37]. These pre-trained models contain the network structures and all parameters and weights trained with public RGB data sets. Transfer learning can actually be considered a special weight initialization method. In our experiments, the SAR image was a one-channel gray image instead of a three-channel RGB image; dark patch images were re-sampled to 64 × 64 on-the-fly before being fed to the network; and only two categories—oil spill and lookalike—were focused on. Therefore, what we needed to do based on these downloaded pre-trained models was to simply set their input image color channel number to 1, input image size to 64 × 64, and output category to 2, and then train further.
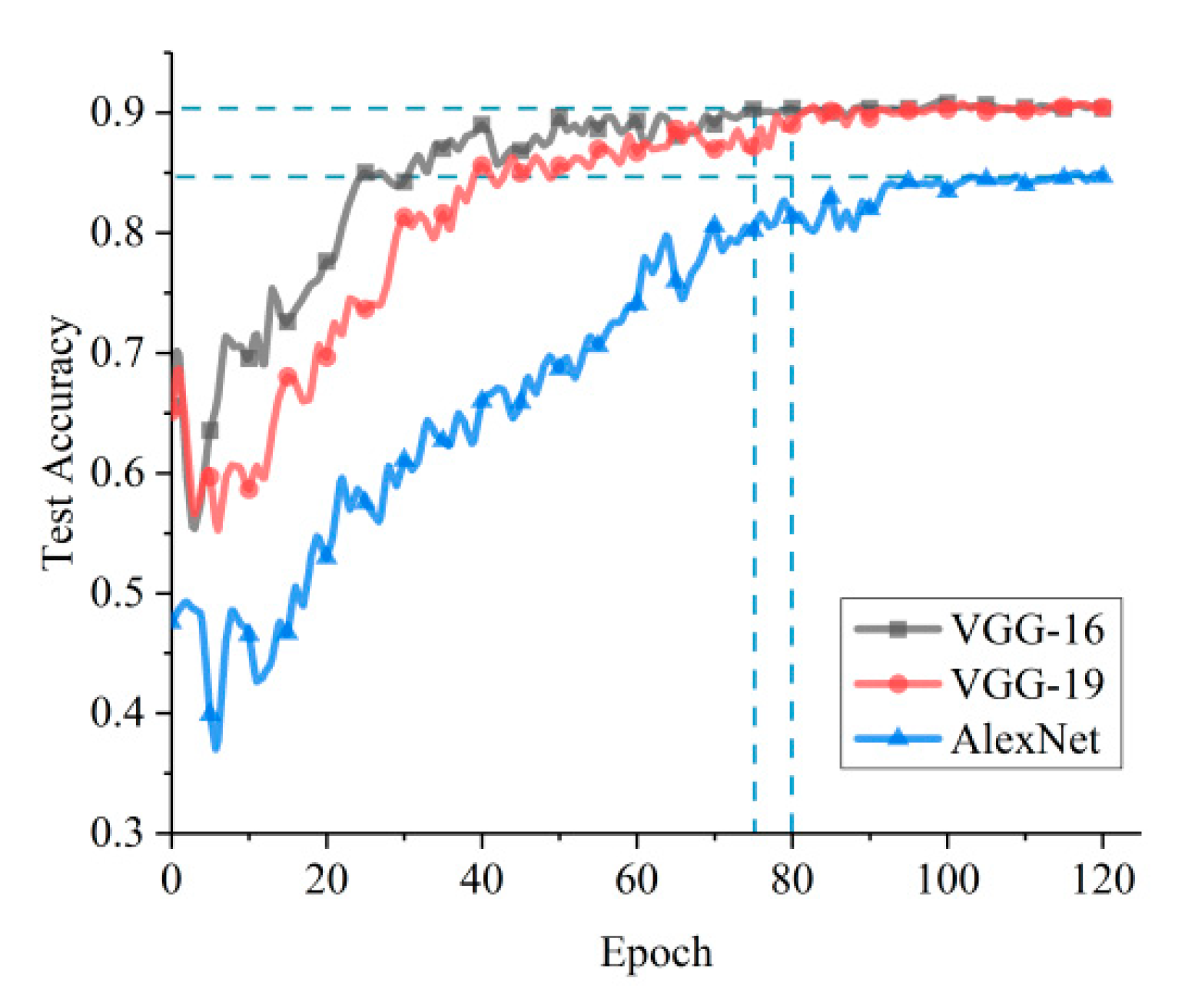
Transfer learning, as a fine-tuning technique, will not stop the training until the model test accuracy is stable. It gives us the opportunity to check how many epochs the network takes to reach a stable status. The training efficiency and classification accuracy obtained by the transfer learning of the three networks—AlexNet, VGG-16, and VGG-19—are shown in
Figure 4. Obviously, the classification performance of VGG-16 and VGG-19 is better than that of AlexNet. VGG-16 and VGG-19 have almost the same classification performance, but the latter converges slower than the former, which implies that the additional three layers of VGG-19 compared to VGG-16 do not improve the classification performance, but reduce the training efficiency. Therefore, VGG-16 was used as the basic structure for further optimization in this study.
4. The Proposed DCNN for SAR Oil Spill Detection
In this section, based on the results of
Section 3, the network hierarchy is designed, which includes the architecture of convolutional layers and Fully Connected layers (FCs). Then, the network hyperparameters are adjusted so that they are suitable for classifying SAR dark patches. This involves many comparative experiments using the data sets described in
Section 2 with data augmentation. In these experiments, the training will be started from scratch instead of using a pre-trained model, since most attributes and hyperparameters, as well as network architecture, will be changed. These comparative experiments only need coarse tuning, which uses a relatively small number of epochs because its goal is to obtain the best value of hyperparameters instead of a well-trained network.
To use the control variable method to further determine attributes and hyperparameters, some initial conditions are employed, as follows: (1) the activation function is ReLU, (2) the loss function is softmax cross entropy, (3) dropout is 0.5, (4) the learning rate is 1e-4, (5) the batch size is 64, (6) weights are initialized in a standard normal distribution, and (7) the optimizer is Stochastic Gradient Descent (SGD) with momentum.
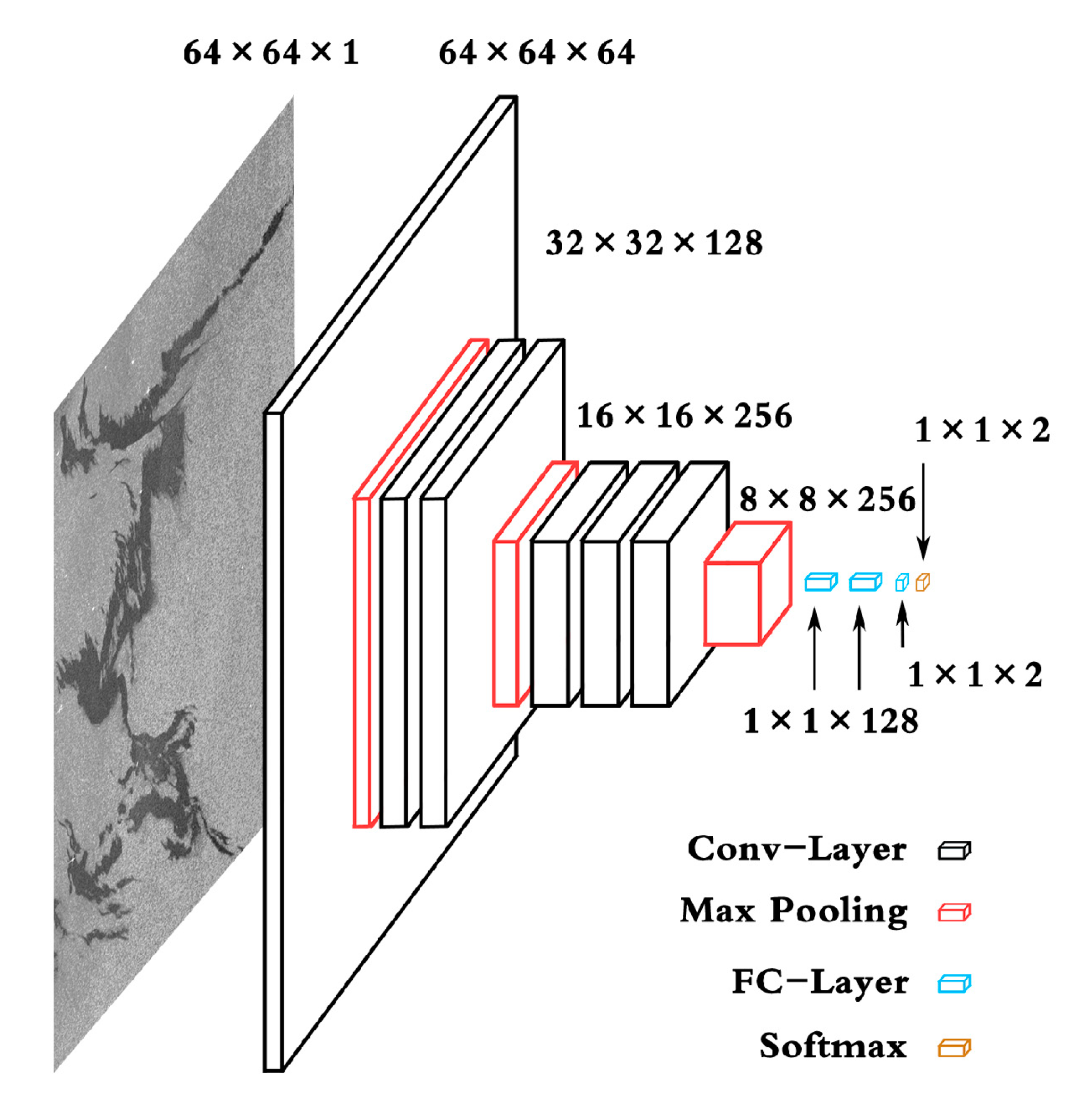
4.1. Structure of Convolutional Layers
According to the previous analysis, the size of input dark patches is 64 × 64, which is smaller than 224 × 224—the input size of VGG-16 based on ImageNet. This difference implies that the new network should be simpler than VGG-16 in terms of receptive fields. For a CNN, a Feature Map (FM) is produced from an input image by applying a convolution kernel. The size of an FM can be expressed as follows [
38]:
where
,
, and
are the size of the FM, input image, and convolution kernel, respectively;
is the stride; and
is the padding value.
The region of the original image where one pixel of an FM is mapped is called the receptive field (RF) [
39]. The size of the receptive field in the first layer is equal to the size of the convolution kernel. Then, the size of the deeper layer receptive field can be iteratively calculated as follows:
where
is the receptive field size of the k-th layer,
is the receptive field size of the (k − 1)-th layer, and
is the stride size of the i-th layer.
When the receptive field of the final layer is closer to, but no larger than, the image region, it is easier for convolution to obtain more information, so as to achieve a better capability of feature extraction [
40]. This means that the new network should be designed so that the receptive field size of the final layer is close to 64 × 64. Shown in
Table 2 is the size of the FM and RF for each layer in VGG-16, calculated by Formulas (1) and (2).
is located between the layers of Stack3 and Stack4. Therefore, as shown in
Table 3, four candidate networks named A, B, C, and D were designed, which include layers deep to Stack3 or Stack4. Network A is an intercept structure of VGG-16 from Stack1 to Stack3, and network B is an intercept structure of VGG-16 from Stack1 to Stack4. Network C and network D use the same structure as network A and network B, respectively, but the number of weight layers in Stack1 is reduced to one. This reduction means that more fine-grained features are obtained by the first pooling layer, thereby improving the ability of the entire network to extract detailed features [
41]. The convolution layers (with different depths in different configurations) are followed by three FCs.
Similar to VGG, both the first and second FC have the same channel number, 1024; the third FC contains only two nodes for the classes of oil spill and lookalike. The configuration of the FCs is the same in networks A, B, C, and D. All of the pooling layers (Pool1, Pool2, and Pool3) in the network use the maximum pooling process, and the Rectified Linear Unit (ReLU) [
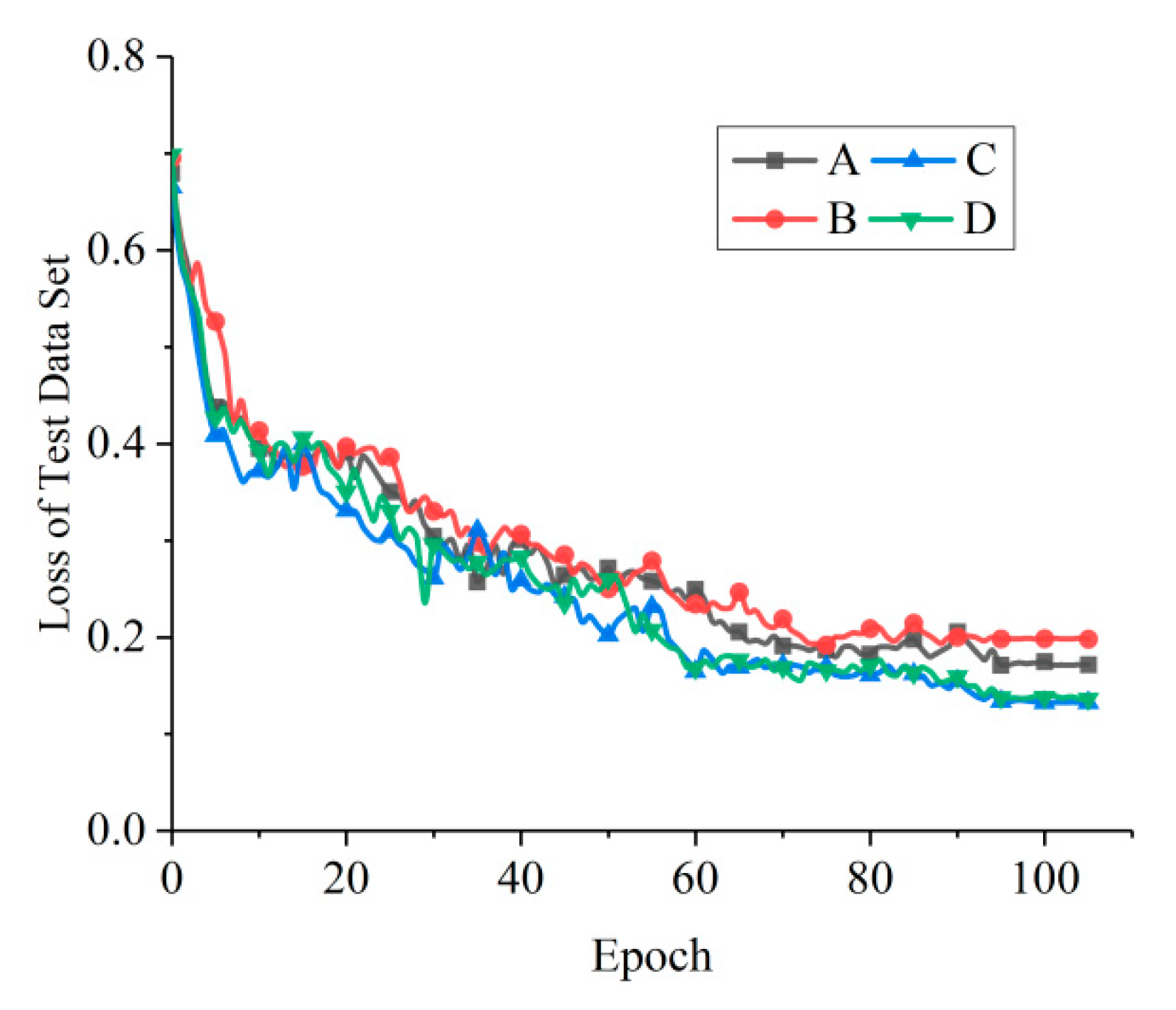
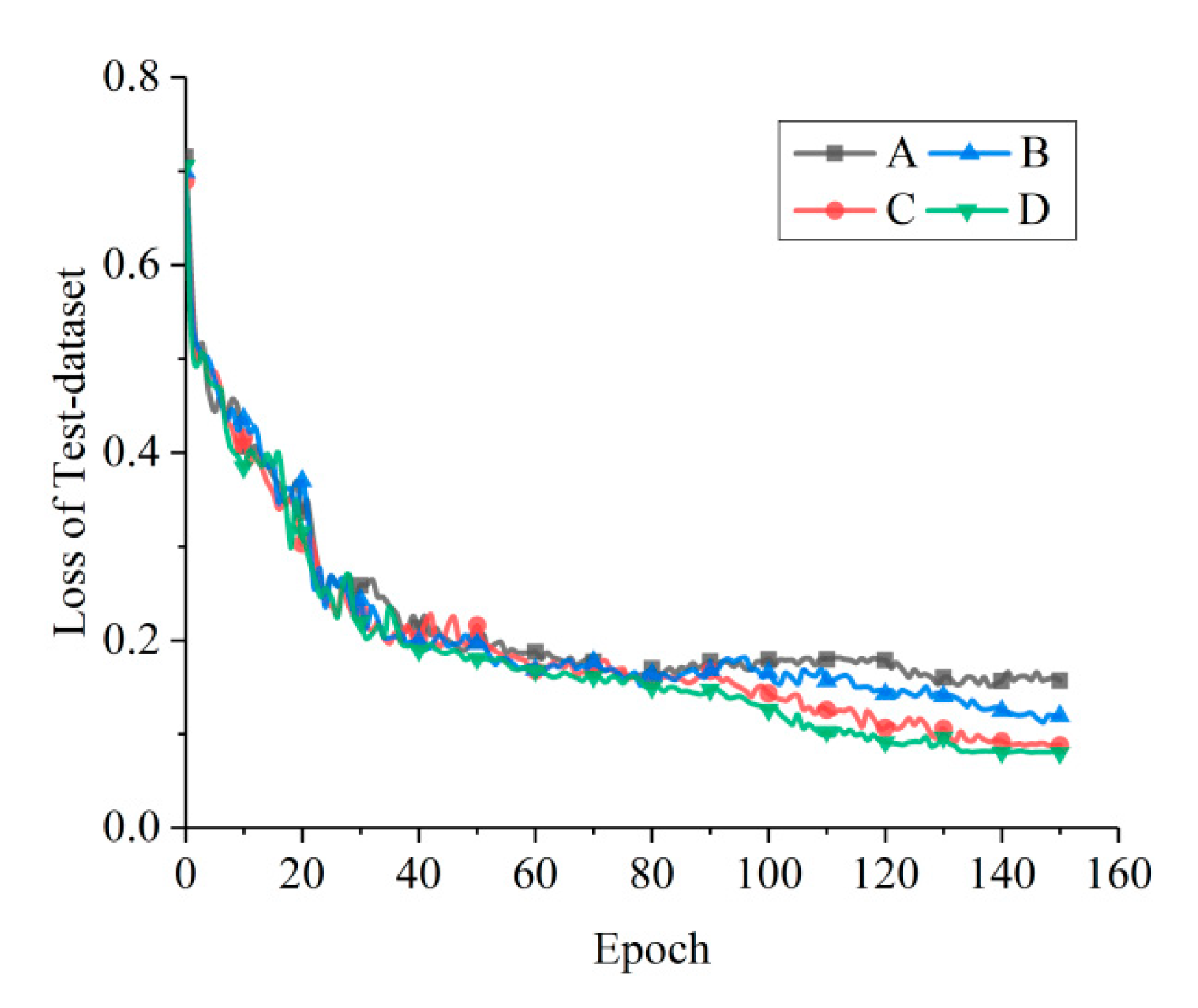
29] is set as the activation function. The loss curves of the test data set obtained by training the four networks are shown in
Figure 5. The losses of C and D converge significantly faster and reach lower values than those of A and B. Both the losses of C and D tend to have the same value, but C converges faster than D. According to
Table 3, the structure of network C is simpler than that of D, which indicates that there is still structural redundancy in network D. Therefore, network C is the one which is most suitable for the oil spill detection data set among the four candidate networks.
4.2. Node Number of FC and Dropout
The number of nodes in one FC layer and dropout rate [
42] jointly determine the number of nodes that are actually effective during training in that layer. Therefore, they should be considered together.
The number of nodes in the first FC layer of OSCNet is equivalent to the number of input features in a traditional ANN. According to the experience of AAMLP [
14], that network achieved satisfactory classification results when using 77 features. This experience provides a clue for finding suitable values for the node number and dropout rate. In this section, we explore the effect of varying the hyperparameter. The comparison was conducted in two situations.
Firstly, the dropout rate was set to a common value of 0.5 [
29], and the network was then trained four times with four different numbers of FC: 1024, 512, 256, and 128. The training accuracy corresponding to the four FC node numbers is shown in
Table 4. The experimental results show that the classification accuracy is relatively high when the number of remaining nodes of FC is 64 or 128, which is close to the empirical value of 77.
Then, such combinations of FC node number and dropout rate (see
Table 5) where the reserved node numbers of FC were between 64 and 128 were adopted to train the network. The results show (see
Figure 6) that combination D has the fastest convergence speed. It is not difficult to see from
Figure 6 that excessive dropouts make network training more difficult, and it is easier to obtain better results by moderate dropout. In subsequent tuning experiments for other hyperparameters, the network was initialized with combination D, i.e., the FC node number of 128 and dropout rate of 0.1.
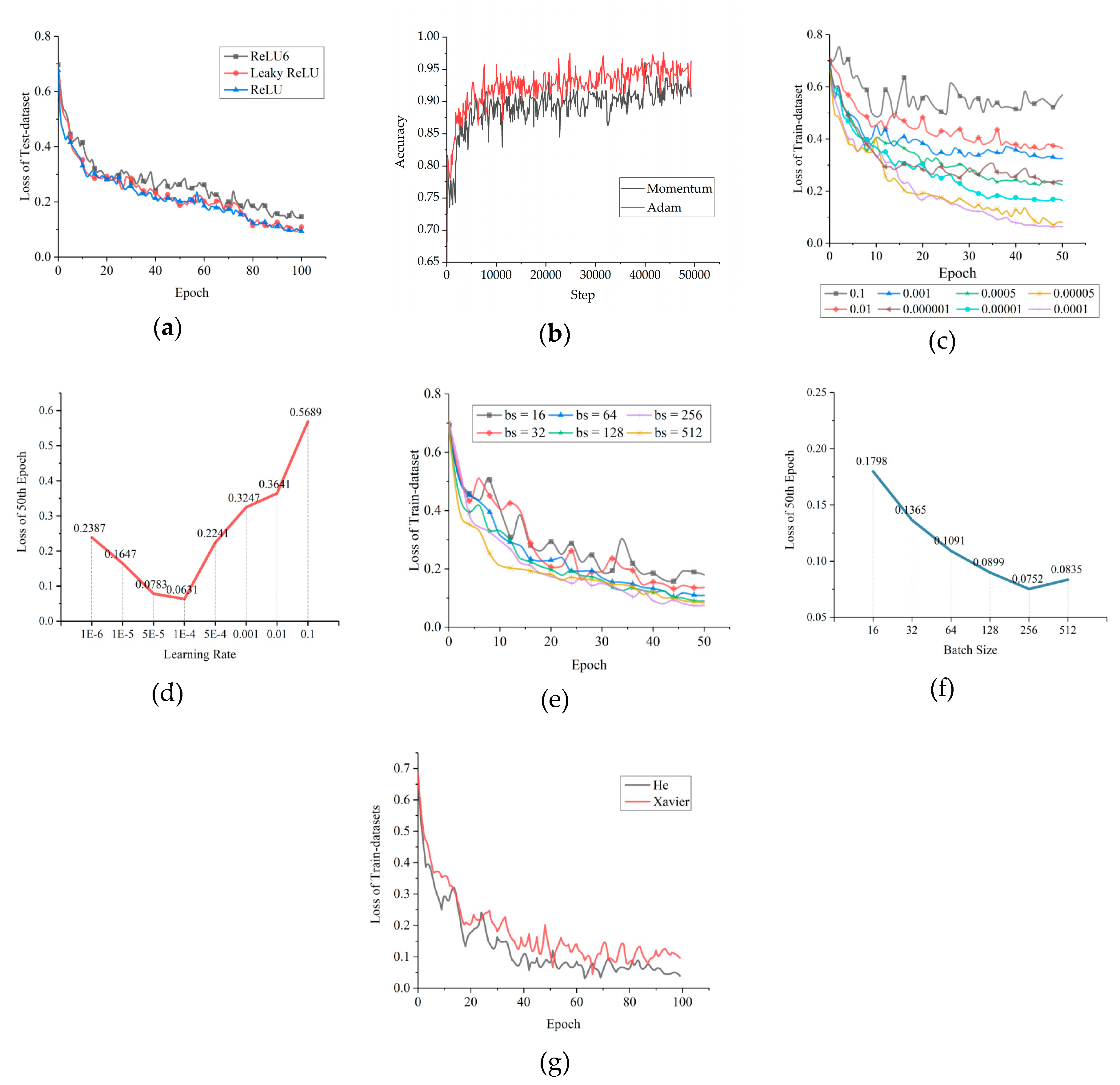
4.3. Hyperparameter Evaluation
Common activation functions include Sigmoid, tanh, ReLU, and the variants of ReLU, such as Leaky ReLU and ReLU6 [
43]. ReLU can avoid the problems of gradient disappearance or gradient explosion, which often happens when Sigmoid or tanh is used in deep networks [
29]. Since ReLU has been widely used in AlexNet, VGG, and other networks, and has been proven to have a good universal adaptability [
29,
31], we only examined the sensitivity of ReLU and its variants using our data set. As shown in
Figure 7a, Leaky ReLU and ReLU fit almost equally. However, compared to ReLU, when adding negative nodes to the operation, Leaky ReLU causes the network to have a greater time and space complexity, which leads to slower convergence. Therefore, we chose ReLU as the activation function. This is different from the case where Leaky ReLU is often better than ReLU in the classification problem of RGB images.
The scale of our training set was in the order of 10
5-10
6, so the training optimization algorithm used Stochastic Gradient Descent (SGD) [
44]. Increasing the momentum in SGD (Momentum) can improve the efficiency of gradient descent and avoid position vibration near the minimum value of the gradient [
45]. This is a popular method that has been adopted by AlexNet, VGG, and other classical CNNs. Meanwhile, Kingma et al. [
46] pointed out that their adaptive moment estimation (Adam) had a better performance than Momentum. Based on SGD, the Momentum and Adam algorithms were used for multiple training. As shown in
Figure 7b, Adam is better than Momentum for the SAR dark patch data set.
According to the method used to determine the initial learning rate proposed by Nielsen [
47], the search direction for the optimal initial learning rate can be determined to be downward by training at the initial rates of 0.001, 0.01, and 0.1. Therefore, many smaller initial learning rates were subsequently checked. Their corresponding learning curves are shown in
Figure 7c,d. According to
Figure 7c,d, the initial learning rate of 5.0 × 10
−5 is best for OSCNet.
Bengio et al. [
48] believed that the batch size could range from one to several hundred, and values over 10 could make full use of the acceleration advantage of matrix–matrix products over matrix–vector products, thereby improving the training efficiency. Considering the hardware conditions, a comparative experiment was performed with a batch size that was increased from 16 to 512 by iterative multiples of 2, shown in
Figure 7e,f. Considering the consumption of computing time, 256 was selected as the batch size for training.
The initialization of weights and biases (parameter initialization) has a significant impact on whether the network can converge, the speed of convergence, and whether it is easy to fall into a local minimum. Glorot et al. [
49] designed an initialization method, known as Xavier Initialization, to ensure that the output variance of each layer is equal. In 2015, considering the influence of the non-linear effect of the ReLU series activation functions on the distribution of output data, He et al. [
43] proposed an initialization method that can more likely guarantee the consistency of input and output variances of the network. The comparison experiment was conducted by training our network with the two initialization methods. The comparison result in
Figure 7g shows that He initialization is better than Xavier initialization for OSCNet.
6. Conclusions and Outlooks
Based on VGG-16, a relatively deep DCNN named OSCNet was built in this study for the classification of SAR dark patches. OSCNet contains as many as 12 weight layers, which benefits from the use of the data augmentation technique for the big data set composed of 23,768 SAR dark patches extracted from 336 SAR images. The distinguishability of the features learned from the data set by OSCNet is much better than that of hand-craft features. Therefore, the classification performance of OSCNet is significantly improved compared to AAMLP—a traditional sophisticated ML classifier. The accuracy, recall, and precision were increased from 92.50%, 81.40%, and 80.95% to 94.01%, 83.51% and 85.70%, respectively. The classification performance of OSCNet might be better than that of the other two CNN-type networks [
24,
25], which are currently available for SAR oil spill detection, but probably not as good as RED-Net [
26]—a pixel-level DL classifier.
Our research shows that the size and statistic characteristic of the data set play a crucial role in the establishment of a DCNN classifier for SAR oil spill detection. In order to build an automatic operational SAR oil spill monitoring system, continuously expanding the data set should be a long-standing task.
For a system based on the three-step processing framework, the procedure used to automatically extract dark patches from SAR images must always be consistent, because the statistical characteristics of the dark patch data set are also affected by the image segmentation program. This effect is mainly reflected in the proportion of lookalikes. The dark patches in this research were all extracted by the same image segmentation program and thus meet the above requirements.
The pixel-level classifier can be used as an image segmentation algorithm in a three-step processing framework if its recall is 100%, at the expense of precision. However, if acceptable values can be obtained for both recall and precision simultaneously, the pixel-level classifier can exist as an independent SAR oil spill detector other than a classifier in the three-step processing framework. At this point, it will pose an important challenge to the three-step processing framework. In future research, we will pay more attention to the pixel-level DL classification algorithms and compare them with dark patch-level DL algorithms based on the same big data set so as to find the better algorithms among them for SAR oil spill detection.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


























