Distributed Training and Inference of Deep Learning Models for Multi-Modal Land Cover Classification


Abstract
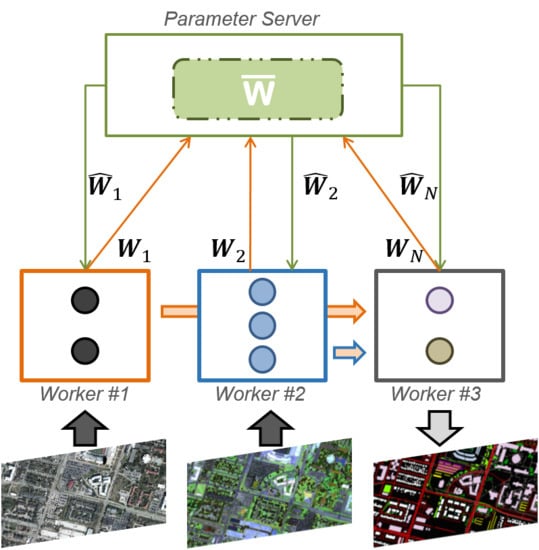
:
1. Introduction
- A detailed analysis on the trade-offs between different parallelization architectures, focusing on the case of remote sensing data analysis.
- Formulation of a novel distributed processing model for the case of multi-modal remote sensing observation classification.
- A detailed experimental investigation of the merits of the proposed scheme compared to single-modality-based learning and non-deep learning methods.
- Comparison between model and data distributed DNN approaches for the problem of multi-modal data classification.
- Insights into model parallelization behavior, providing directions on better allocation of the resources of computer clusters.
2. State of the Art
2.1. Distributed Deep Learning and Model Parallelization
2.2. Deep Learning in Land Cover Classification
3. Proposed Methodology
3.1. Overall CNN Architecture
- Convolution layer:
- Activation layer. Activation layers introduce non-linear operations which enable the networks to act a universal function approximates. Representative examples are ReLU activation, which applies a non-negative thresholding operator, and Sigmoid, which constraints the output to the range and is typically used in the last layer as the predictor.
- Batch normalization layer. This layer add a normalization step to the network, which make the inputs of each trainable layers comparable across features. By doing this, they ensure a high learning rate while keeping the network learning.
- Pooling layer. A pooling layer’s objectives are firstly, to provide invariance to slightly different inputs and secondly, to reduce the dimensionality of feature maps. Max Pooling is most frequent choice, as it avoids cancellation of negative elements, and prevents blurring of activations and gradients throughout the network.
- Dropout layer. Dropout is a most popular techniques for limiting the effects of overfitting by temporarily reducing the total parameters of the network at each training epoch.
- Fully connected layer. A fully Connected layer is responsible for producing predictions, while taking into account the input features.
3.2. Distributed CNN Architectures
4. Distributed Processing Framework
4.1. System Overview
4.2. Cluster Setup
5. Experimental Analysis
5.1. Dataset
5.2. Result Evaluation
5.2.1. Performance of the Proposed Multi-Modal CNN Architecture
5.2.2. Effects of Distributed Environments on Training Time
5.2.3. Impact of Batch Size
5.2.4. Impact of Architectures on Resource Utilization
5.3. Training Using Model and Data Parallelization Comparison
5.4. Inference Using Model and Data Parallelization Comparison
6. Conclusions
- Migrating branches of multimodal CNNs to different machines does not affect the model’s learning capacity, and a distributed deep learning system can show similar behavior to traditional setups.
- The number of samples that will be propagated through the network greatly affects communication overheads between workers of a cluster. Model Parallelization approaches benefit from larger batch sizes, since they significantly reduce network traffic. However, a very big number of samples causes significant degradation in the quality of the model.
- Through this study, we gave insight on model parallelization’s behavior, and as a result, provide directions for better resource allocation on commodity clusters. For instance, since the PS is the most memory consuming module of model parallelism, we can assign it to the machine with the most memory available. Or because the merging part of a multimodal CNN accumulates a lot of traffic, we can assign it to the machine with the most expensive networking cables.
- The way we parallelize our model has a tremendous impact on a cluster’s resource allocation. Smart model split can reduce the load of heavy duty workers and put to use otherwise idle resources, while a naive split can cause severe bottlenecks through heavy network traffic and waiting learning tasks due to a lack of non-allocated resources.
- For land cover classification, model parallelization schemes tend to perform better than data parallelization since they provide significantly faster and slightly more accurate predictions.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| CPU | Central Processing Unit |
| DNN | Deep Neural Network |
| EO | Earth Observation |
| GPU | Graphical Processing Unit |
| GSD | Ground Sampling Distance |
| HSI | Hyperspectral Image |
| PS | Parameter Server |
| RGB | Red-Green-Blue |
| VHR | Very High Resolution |
References
- Guo, H.; Liu, Z.; Jiang, H.; Wang, C.; Liu, J.; Liang, D. Big Earth Data: A new challenge and opportunity for Digital Earth’s development. Int. J. Digit. Earth 2017, 10, 1–12. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Sharma, A.; Liu, X.; Yang, X.; Shi, D. A patch-based convolutional neural network for remote sensing image classification. Neural Netw. 2017, 95, 19–28. [Google Scholar] [CrossRef] [PubMed]
- Tsagkatakis, G.; Aidini, A.; Fotiadou, K.; Giannopoulos, M.; Pentari, A.; Tsakalides, P. Survey of deep-learning approaches for remote sensing observation enhancement. Sensors 2019, 19, 3929. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Sedona, R.; Cavallaro, G.; Jitsev, J.; Strube, A.; Riedel, M.; Benediktsson, J.A. Remote Sensing Big Data Classification with High Performance Distributed Deep Learning. Remote Sens. 2019, 11, 3056. [Google Scholar] [CrossRef] [Green Version]
- Yao, X.; Li, G.; Xia, J.; Ben, J.; Cao, Q.; Zhao, L.; Ma, Y.; Zhang, L.; Zhu, D. Enabling the Big Earth Observation Data via Cloud Computing and DGGS: Opportunities and Challenges. Remote Sens. 2020, 12, 62. [Google Scholar] [CrossRef] [Green Version]
- Gomes, V.C.; Queiroz, G.R.; Ferreira, K.R. An Overview of Platforms for Big Earth Observation Data Management and Analysis. Remote Sens. 2020, 12, 1253. [Google Scholar] [CrossRef] [Green Version]
- Gaunt, A.L.; Johnson, M.A.; Riechert, M.; Tarlow, D.; Tomioka, R.; Vytiniotis, D.; Webster, S. AMPNet: Asynchronous model-parallel training for dynamic neural networks. arXiv 2017, arXiv:1705.09786. [Google Scholar]
- Chahal, K.S.; Grover, M.S.; Dey, K.; Shah, R.R. A hitchhiker’s guide on distributed training of deep neural networks. J. Parallel Distrib. Computi. 2020, 137, 65–76. [Google Scholar] [CrossRef] [Green Version]
- Yu, X.; Wu, X.; Luo, C.; Ren, P. Deep learning in remote sensing scene classification: A data augmentation enhanced convolutional neural network framework. GISci. Remote Sens. 2017, 54, 741–758. [Google Scholar] [CrossRef] [Green Version]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J.; et al. Apache spark: A unified engine for big data processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Zhang, K.; Chen, X.W. Large-scale deep belief nets with mapreduce. IEEE Access 2014, 2, 395–403. [Google Scholar] [CrossRef]
- Oyama, Y.; Ben-Nun, T.; Hoefler, T.; Matsuoka, S. Accelerating deep learning frameworks with micro-batches. In Proceedings of the IEEE International Conference on Cluster Computing (CLUSTER), Belfast, UK, 10–13 September 2018; pp. 402–412. [Google Scholar]
- Bekkerman, R.; Bilenko, M.; Langford, J. Scaling Up Machine Learning: Parallel and Distributed Approaches; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Muller, U.; Gunzinger, A. Neural net simulation on parallel computers. In Proceedings of the 1994 IEEE International Conference on Neural Networks (ICNN’94), Orlando, FL, USA, 28 June–2 July 1994; Volume 6, pp. 3961–3966. [Google Scholar]
- Ericson, L.; Mbuvha, R. On the performance of network parallel training in artificial neural networks. arXiv 2017, arXiv:1701.05130. [Google Scholar]
- Le, Q.V. Building high-level features using large scale unsupervised learning. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 8595–8598. [Google Scholar]
- Li, M.; Andersen, D.G.; Park, J.W.; Smola, A.J.; Ahmed, A.; Josifovski, V.; Long, J.; Shekita, E.J.; Su, B.Y. Scaling distributed machine learning with the parameter server. In Proceedings of the 11th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 14), Broomfield, CO, USA, 6–8 October 2014; pp. 583–598. [Google Scholar]
- Das, D.; Avancha, S.; Mudigere, D.; Vaidynathan, K.; Sridharan, S.; Kalamkar, D.; Kaul, B.; Dubey, P. Distributed deep learning using synchronous stochastic gradient descent. arXiv 2016, arXiv:1602.06709. [Google Scholar]
- Zinkevich, M.; Weimer, M.; Li, L.; Smola, A.J. Parallelized stochastic gradient descent. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010; pp. 2595–2603. [Google Scholar]
- Jiang, J.; Cui, B.; Zhang, C.; Yu, L. Heterogeneity-aware distributed parameter servers. In Proceedings of the 2017 ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017; pp. 463–478. [Google Scholar]
- Le, Q.V.; Ngiam, J.; Coates, A.; Lahiri, A.; Prochnow, B.; Ng, A.Y. On optimization methods for deep learning. In Proceedings of the 28th International Conference on International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 265–272. [Google Scholar]
- Zhang, S.; Zhang, C.; You, Z.; Zheng, R.; Xu, B. Asynchronous stochastic gradient descent for DNN training. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6660–6663. [Google Scholar]
- Krizhevsky, A. One weird trick for parallelizing convolutional neural networks. arXiv 2014, arXiv:1404.5997. [Google Scholar]
- Dean, J.; Corrado, G.; Monga, R.; Chen, K.; Devin, M.; Mao, M.; Ranzato, M.; Senior, A.; Tucker, P.; Yang, K.; et al. Large scale distributed deep networks. In Advances in Neural Information Processing Systems; Google Inc.: Mountain View, CA, USA, 2012; pp. 1223–1231. [Google Scholar]
- Aspri, M.; Tsagkatakis, G.; Panousopoulou, A.; Tsakalides, P. On Realizing Distributed Deep Neural Networks: An Astrophysics Case Study. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- Shen, H.; Meng, X.; Zhang, L. An integrated framework for the spatio–temporal–spectral fusion of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7135–7148. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Guo, Y.; Jia, X.; Paull, D. Effective sequential classifier training for SVM-based multitemporal remote sensing image classification. IEEE Trans. Image Process. 2018, 27, 3036–3048. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Stivaktakis, R.; Tsagkatakis, G.; Tsakalides, P. Deep Learning for Multilabel Land Cover Scene Categorization Using Data Augmentation. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1031–1035. [Google Scholar] [CrossRef]
- Yang, W.; Yin, X.; Xia, G.S. Learning high-level features for satellite image classification with limited labeled samples. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4472–4482. [Google Scholar] [CrossRef]
- Zhang, L.; Ma, W.; Zhang, D. Stacked sparse autoencoder in PolSAR data classification using local spatial information. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1359–1363. [Google Scholar] [CrossRef]
- Qin, F.; Guo, J.; Sun, W. Object-oriented ensemble classification for polarimetric SAR Imagery using restricted Boltzmann machines. Remote Sens. Lett. 2017, 8, 204–213. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, H.; Xu, F.; Jin, Y.Q. Polarimetric SAR image classification using deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1935–1939. [Google Scholar] [CrossRef]
- Duan, Y.; Liu, F.; Jiao, L.; Zhao, P.; Zhang, L. SAR Image segmentation based on convolutional-wavelet neural network and markov random field. Pattern Recognit. 2017, 64, 255–267. [Google Scholar] [CrossRef]
- Geng, J.; Wang, H.; Fan, J.; Ma, X. Deep supervised and contractive neural network for SAR image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2442–2459. [Google Scholar] [CrossRef]
- Hu, J.; Mou, L.; Schmitt, A.; Zhu, X.X. FusioNet: A two-stream convolutional neural network for urban scene classification using PolSAR and hyperspectral data. In Proceedings of the Joint Urban Remote Sensing Event (JURSE), Dubai, UAE, 6–8 March 2017; pp. 1–4. [Google Scholar]
- Hirschmuller, H. Stereo processing by semiglobal matching and mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 30, 328–341. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Semantic segmentation of earth observation data using multimodal and multi-scale deep networks. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Cham, Switzerland, 2016; pp. 180–196. [Google Scholar]
- Sukhanov, S.; Budylskii, D.; Tankoyeu, I.; Heremans, R.; Debes, C. Fusion of LiDAR, hyperspectral and RGB data for urban land use and land cover classification. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 3864–3867. [Google Scholar]
- Lu, X.; Shi, H.; Biswas, R.; Javed, M.H.; Panda, D.K. DLoBD: A Comprehensive Study of Deep Learning over Big Data Stacks on HPC Clusters. IEEE Trans. Multi-Scale Comput. Syst. 2018, 4, 635–648. [Google Scholar] [CrossRef]
- Massie, M.L.; Chun, B.N.; Culler, D.E. The ganglia distributed monitoring system: Design, implementation, and experience. Parallel Comput. 2004, 30, 817–840. [Google Scholar] [CrossRef]
- Xu, Y.; Du, B.; Zhang, L.; Cerra, D.; Pato, M.; Carmona, E.; Prasad, S.; Yokoya, N.; Hänsch, R.; Le Saux, B. Advanced multi-sensor optical remote sensing for urban land use and land cover classification: Outcome of the 2018 IEEE GRSS Data Fusion Contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1709–1724. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Keskar, N.S.; Mudigere, D.; Nocedal, J.; Smelyanskiy, M.; Tang, P.T.P. On large-batch training for deep learning: Generalization gap and sharp minima. arXiv 2016, arXiv:1609.04836. [Google Scholar]
- Pitsis, G.; Tsagkatakis, G.; Kozanitis, C.; Kalomoiris, I.; Ioannou, A.; Dollas, A.; Katevenis, M.G.; Tsakalides, P. Efficient convolutional neural network weight compression for space data classification on multi-fpga platforms. In Proceedings of the ICASSP 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3917–3921. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class ID | Corresponding Label |
|---|---|
| 0 | Healthy Grass |
| 1 | Stressed Grass |
| 2 | Artificial Turf |
| 3 | Evergreen Trees |
| 4 | Deciduous Trees |
| 5 | Bare Earth |
| 6 | Water |
| 7 | Residential Buildings |
| 8 | Non-Residential Buildings |
| 9 | Roads |
| 10 | Sidewalks |
| 11 | Crosswalks |
| 12 | Major thoroughfares |
| 13 | Highways |
| 14 | Railways |
| 15 | Paved Parking Lots |
| 16 | Unpaved Parking Lots |
| 17 | Cars |
| 18 | Trains |
| 19 | Stadium Seats |
| Accuracy (%) | ||
|---|---|---|
| Training | Validation | |
| RGB | 73.3 | 43.1 |
| HSI | 75.5 | 77.6 |
| RGB + HSI | 88.4 | 83.6 |
| Accuracy (%) | |
|---|---|
| SVM (rbf) | 74.1 |
| KNN (k = 5) | 82.4 |
| MM-CNN (proposed) | 83.6 |
| # Examples | Data Parallelization | Model Parallelization | |
|---|---|---|---|
| Baseline | Optimized | ||
| 1 K | 51.7 s | 26.0 s | 25.1s |
| 14 K | 787.2 s | 500.1 s | 364.5s |
| # Examples | Data Parallelization | Model Parallelization | |
|---|---|---|---|
| Baseline | Optimized | ||
| 1 K | 0.86 | 0.86 | 0.86 |
| 14 K | 0.83 | 0.83 | 0.84 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aspri, M.; Tsagkatakis, G.; Tsakalides, P. Distributed Training and Inference of Deep Learning Models for Multi-Modal Land Cover Classification. Remote Sens. 2020, 12, 2670. https://doi.org/10.3390/rs12172670
Aspri M, Tsagkatakis G, Tsakalides P. Distributed Training and Inference of Deep Learning Models for Multi-Modal Land Cover Classification. Remote Sensing. 2020; 12(17):2670. https://doi.org/10.3390/rs12172670
Chicago/Turabian StyleAspri, Maria, Grigorios Tsagkatakis, and Panagiotis Tsakalides. 2020. "Distributed Training and Inference of Deep Learning Models for Multi-Modal Land Cover Classification" Remote Sensing 12, no. 17: 2670. https://doi.org/10.3390/rs12172670