DeepInSAR—A Deep Learning Framework for SAR Interferometric Phase Restoration and Coherence Estimation

 ,
, 
Abstract
:
1. Introduction
2. Materials and Methods
2.1. Phase Noise Model
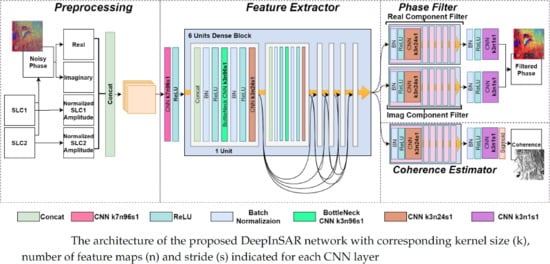
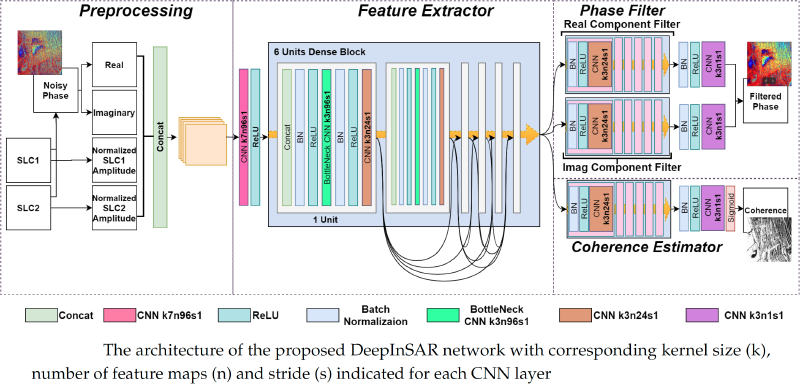
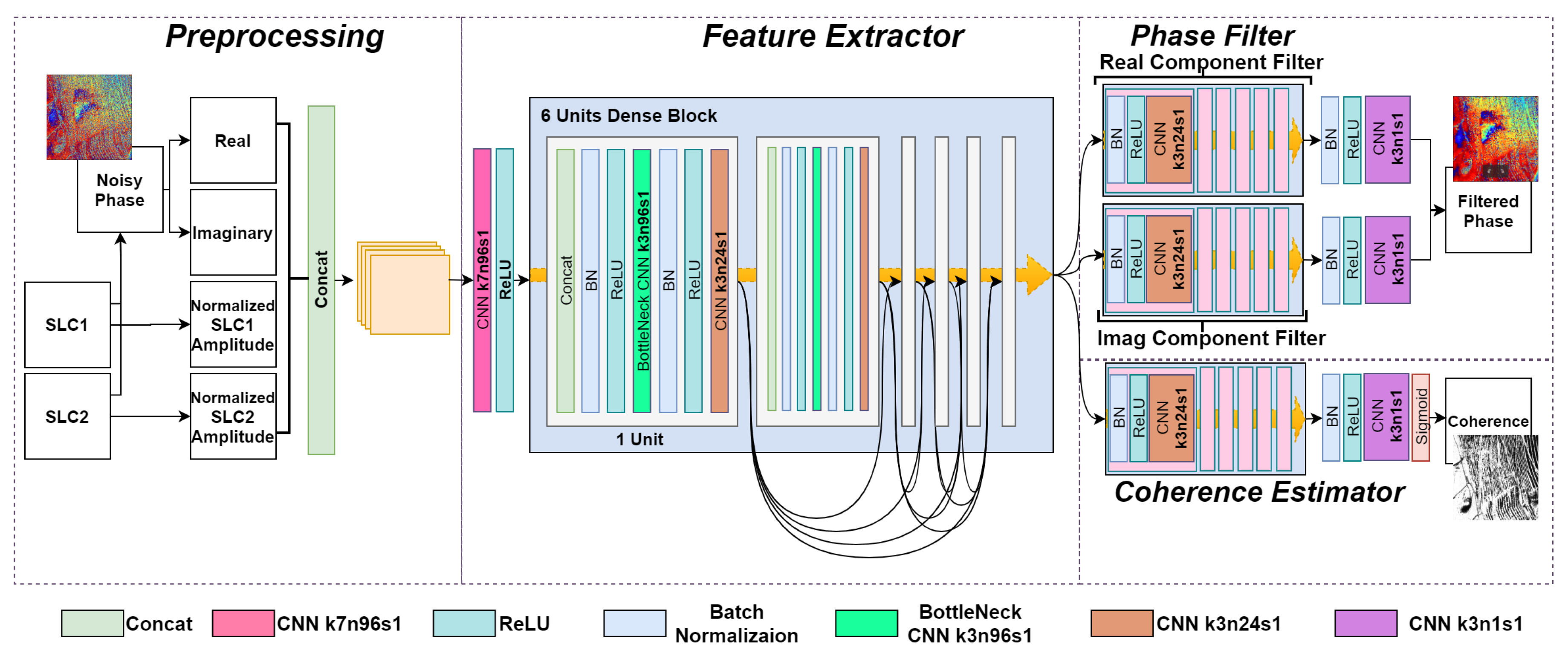
2.2. The Proposed DeepInSAR
2.2.1. Prepossessing of Radar Data
2.2.2. Filtering with Residual Learning
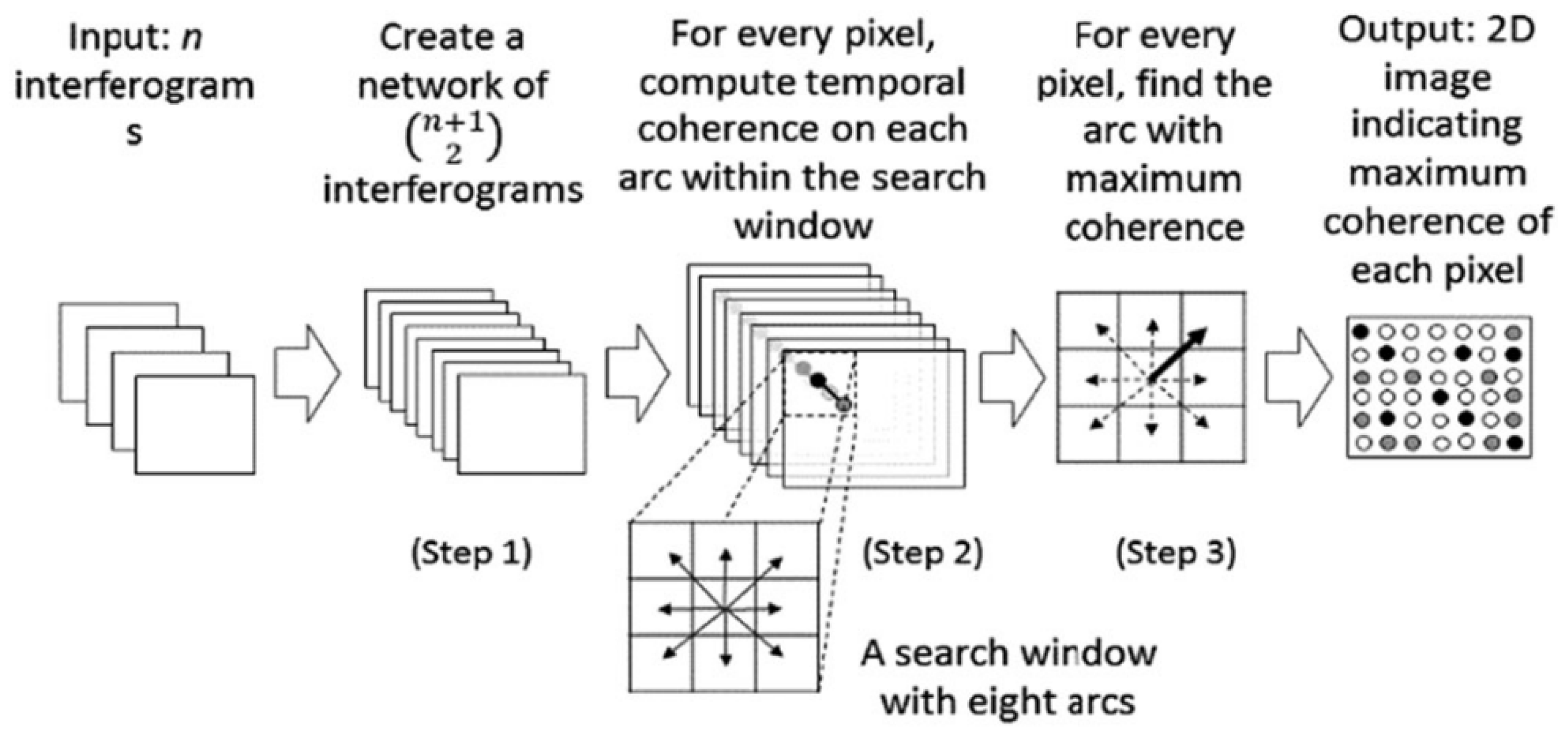
2.2.3. Coherence Estimation
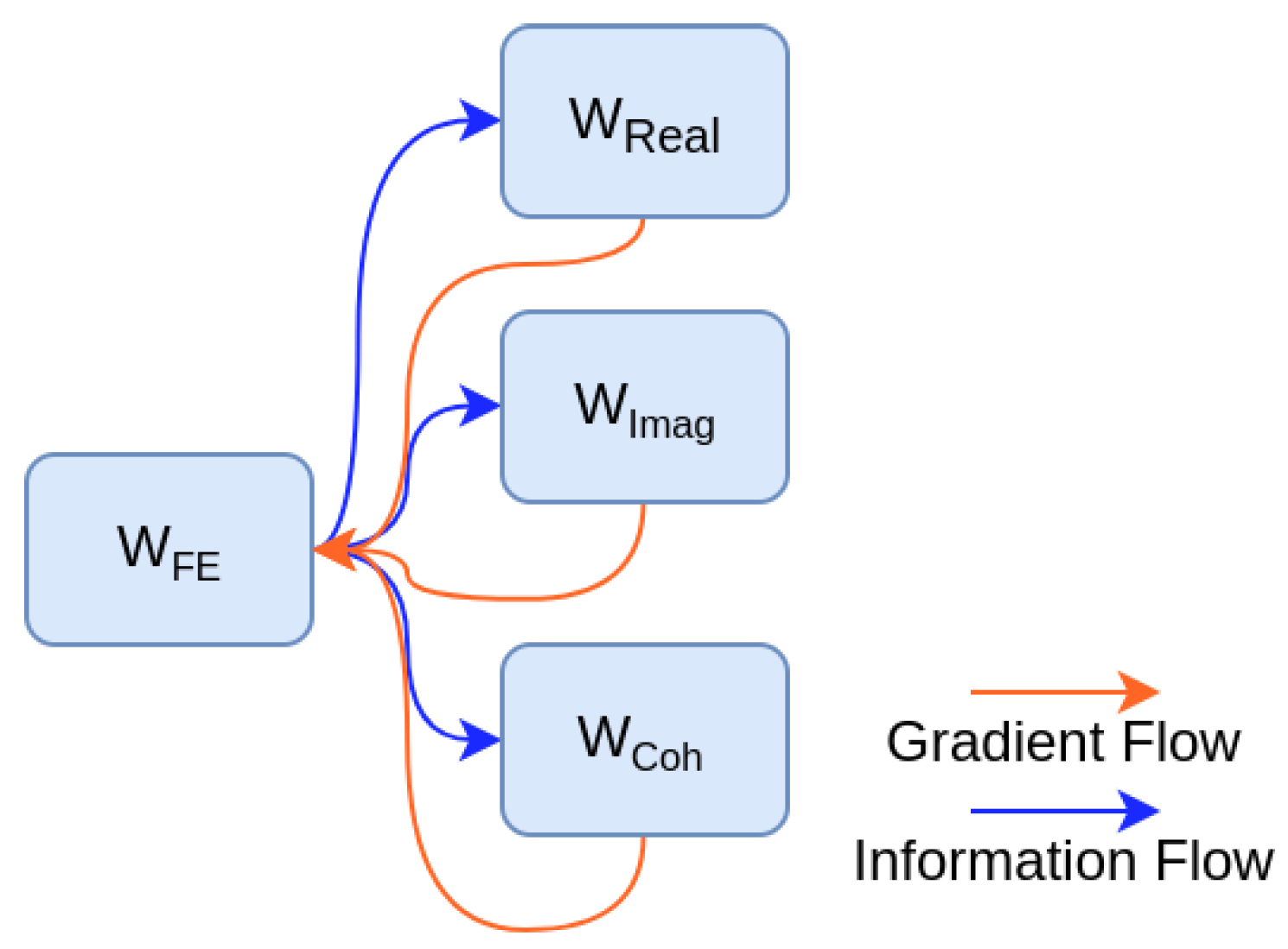
2.2.4. Shared Feature Extractor with Dense Connectivity
2.2.5. Teacher-Student Framework
2.3. Experimental Setup
3. Results
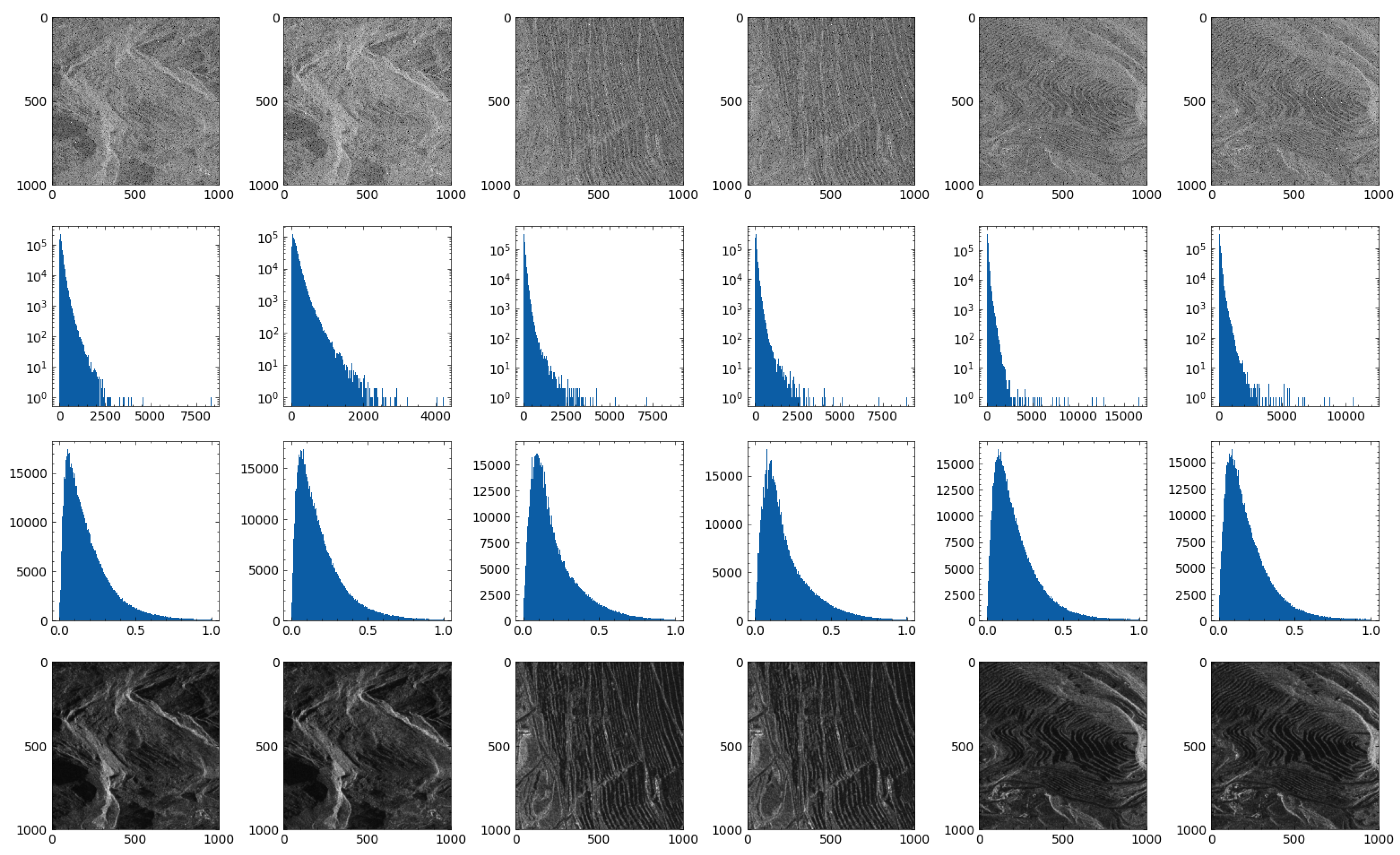
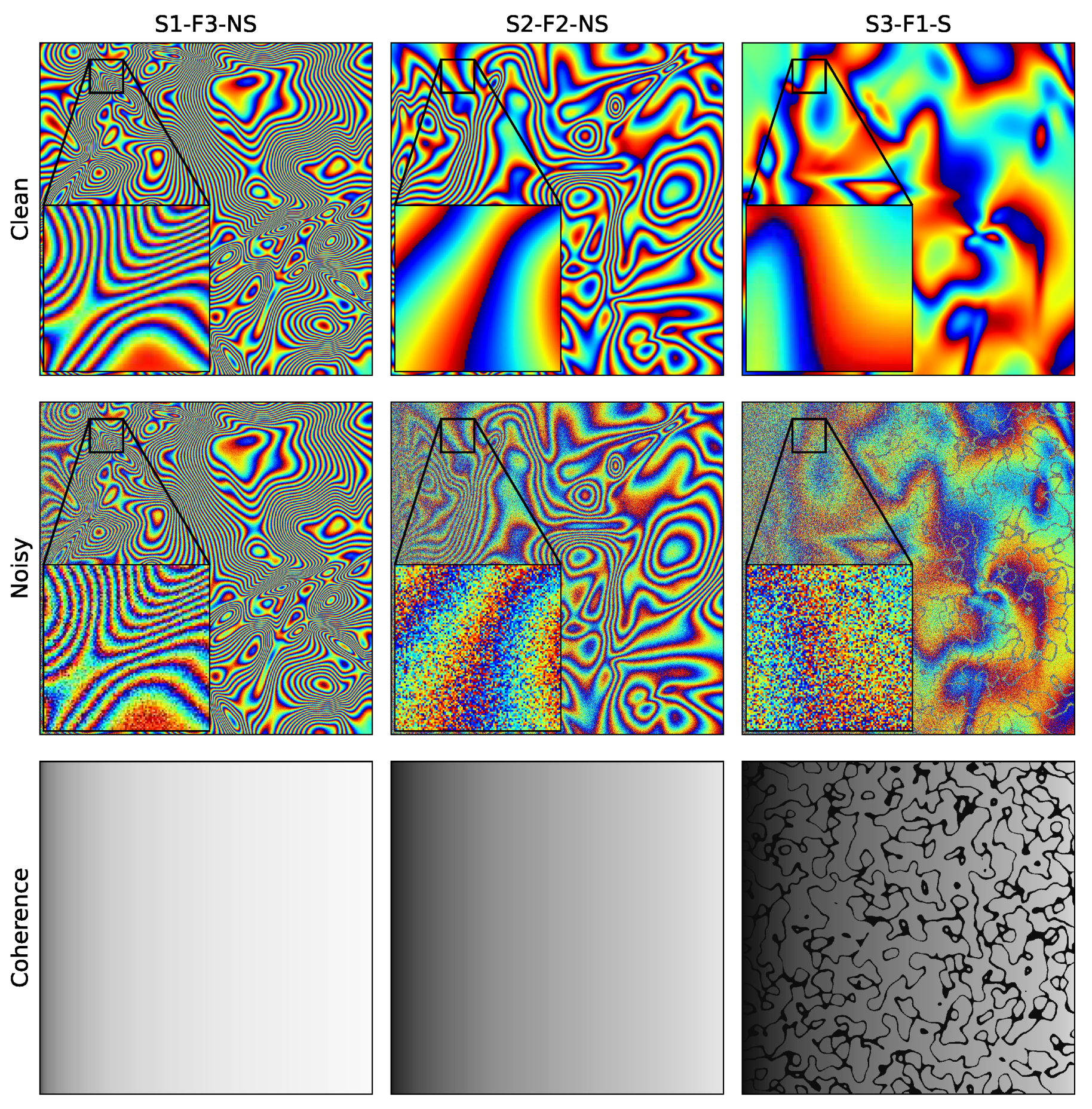
3.1. Results on Simulation Data
- Generate first SLC image with 0 phase value. The amplitude value grows from 0.1 to 1 from the left-most column in the image to the right column following a Rayleigh distribution. This leads to a linearly growing of coherence from left to right.
- Generate second SLC image by adding random Gaussian bubbles as synthetic motion signals to the phase. The amplitude value is equal to ’s amplitude value.
- Add random low-value amplitude bands (less than 0.3) on and to simulate stripe-like low amplitude incoherence areas.
- Generate noisy SLCs and by adding independent additive Gaussian noise v to both real and imaginary channels of and .
- Calculate clean and noisy interferometric phase I and .
- Calculate ground truth coherence using clean amplitude, phase, and the standard deviation of base noise v.
3.2. Results on Real Data
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hanssen, R.F. Radar Interferometry: Data Interpretation and Error Analysis; Springer Science & Business Media: Berlin, Germany, 2001; Volume 2. [Google Scholar]
- Zha, X.; Fu, R.; Dai, Z.; Liu, B. Noise reduction in interferograms using the wavelet packet transform and wiener filtering. IEEE Geosci. Remote Sens. Lett. 2008, 5, 404–408. [Google Scholar]
- Deledalle, C.A.; Denis, L.; Tupin, F. NL-InSAR: Nonlocal interferogram estimation. IEEE Trans. Geosci. Remote Sens. 2011, 49, 1441–1452. [Google Scholar] [CrossRef]
- Seymour, M.; Cumming, I. Maximum likelihood estimation for SAR interferometry. In Proceedings of the IGARSS ’94—1994 IEEE International Geoscience and Remote Sensing Symposium, Pasadena, CA, USA, 8–12 August 1994; Volume 4, pp. 2272–2275. [Google Scholar]
- Lee, J.S.; Papathanassiou, K.P.; Ainsworth, T.L.; Grunes, M.R.; Reigber, A. A new technique for noise filtering of SAR interferometric phase images. IEEE Trans. Geosci. Remote Sens. 1998, 36, 1456–1465. [Google Scholar]
- Chao, C.F.; Chen, K.S.; Lee, J.S. Refined filtering of interferometric phase from InSAR data. IEEE Trans. Geosci. Remote Sens. 2013, 51, 5315–5323. [Google Scholar] [CrossRef]
- Ferraiuolo, G.; Poggi, G. A Bayesian filtering technique for SAR interferometric phase fields. IEEE Trans. Image Process. 2004, 13, 1368–1378. [Google Scholar] [CrossRef]
- Vasile, G.; Trouvé, E.; Lee, J.S.; Buzuloiu, V. Intensity-driven adaptive-neighborhood technique for polarimetric and interferometric SAR parameters estimation. IEEE Trans. Geosci. Remote Sens. 2006, 44, 1609–1621. [Google Scholar] [CrossRef] [Green Version]
- Yu, Q.; Yang, X.; Fu, S.; Liu, X.; Sun, X. An adaptive contoured window filter for interferometric synthetic aperture radar. IEEE Geosci. Remote Sens. Lett. 2007, 4, 23–26. [Google Scholar] [CrossRef]
- Wang, Y.; Huang, H.; Dong, Z.; Wu, M. Modified patch-based locally optimal Wiener method for interferometric SAR phase filtering. ISPRS J. Photogramm. Remote Sens. 2016, 114, 10–23. [Google Scholar] [CrossRef] [Green Version]
- Baselice, F.; Ferraioli, G.; Pascazio, V.; Schirinzi, G. Joint InSAR DEM and deformation estimation in a Bayesian framework. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 398–401. [Google Scholar]
- Goldstein, R.M.; Werner, C.L. Radar interferogram filtering for geophysical applications. Geophys. Res. Lett. 1998, 25, 4035–4038. [Google Scholar] [CrossRef] [Green Version]
- Baran, I.; Stewart, M.; Lilly, P. A modification to the Goldstein radar interferogram filter. IEEE Trans. Geosci. Remote Sens. 2003, 41, 2114–2118. [Google Scholar] [CrossRef] [Green Version]
- Song, R.; Guo, H.; Liu, G.; Perski, Z.; Fan, J. Improved Goldstein SAR interferogram filter based on empirical mode decomposition. IEEE Geosci. Remote Sens. Lett. 2014, 11, 399–403. [Google Scholar] [CrossRef]
- Jiang, M.; Ding, X.; Li, Z.; Tian, X.; Zhu, W.; Wang, C.; Xu, B. The improvement for Baran phase filter derived from unbiased InSAR coherence. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 3002–3010. [Google Scholar] [CrossRef]
- Wang, Q.; Huang, H.; Yu, A.; Dong, Z. An efficient and adaptive approach for noise filtering of SAR interferometric phase images. IEEE Geosci. Remote Sens. Lett. 2011, 8, 1140–1144. [Google Scholar] [CrossRef]
- Cai, B.; Liang, D.; Dong, Z. A new adaptive multiresolution noise-filtering approach for SAR interferometric phase images. IEEE Geosci. Remote Sens. Lett. 2008, 5, 266–270. [Google Scholar]
- Lopez-Martinez, C.; Fabregas, X. Modeling and reduction of SAR interferometric phase noise in the wavelet domain. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2553–2566. [Google Scholar] [CrossRef] [Green Version]
- Bian, Y.; Mercer, B. Interferometric SAR phase filtering in the wavelet domain using simultaneous detection and estimation. IEEE Trans. Geosci. Remote Sens. 2011, 49, 1396–1416. [Google Scholar] [CrossRef]
- Xu, G.; Xing, M.D.; Xia, X.G.; Zhang, L.; Liu, Y.Y.; Bao, Z. Sparse regularization of interferometric phase and amplitude for InSAR image formation based on Bayesian representation. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2123–2136. [Google Scholar] [CrossRef]
- Deledalle, C.A.; Denis, L.; Tupin, F. Iterative weighted maximum likelihood denoising with probabilistic patch-based weights. IEEE Trans. Image Process. 2009, 18, 2661. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Parrilli, S.; Poderico, M.; Angelino, C.V.; Verdoliva, L. A nonlocal SAR image denoising algorithm based on LLMMSE wavelet shrinkage. IEEE Trans. Geosci. Remote Sens. 2012, 50, 606–616. [Google Scholar] [CrossRef]
- Cozzolino, D.; Parrilli, S.; Scarpa, G.; Poggi, G.; Verdoliva, L. Fast adaptive nonlocal SAR despeckling. IEEE Geosci. Remote Sens. Lett. 2014, 11, 524–528. [Google Scholar] [CrossRef] [Green Version]
- Chen, R.; Yu, W.; Wang, R.; Liu, G.; Shao, Y. Interferometric phase denoising by pyramid nonlocal means filter. IEEE Geosci. Remote Sens. Lett. 2013, 10, 826–830. [Google Scholar] [CrossRef]
- Zhu, X.X.; Bamler, R.; Lachaise, M.; Adam, F.; Shi, Y.; Eineder, M. Improving TanDEM-X DEMs by non-local InSAR filtering. In Proceedings of the EUSAR 2014; 10th European Conference on Synthetic Aperture Radar, Berlin, Germany, 3–5 June 2014; pp. 1–4. [Google Scholar]
- Sica, F.; Cozzolino, D.; Zhu, X.X.; Verdoliva, L.; Poggi, G. InSAR-BM3D: A Nonlocal Filter for SAR Interferometric Phase Restoration. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3456–3467. [Google Scholar] [CrossRef] [Green Version]
- Deledalle, C.A.; Denis, L.; Tupin, F.; Reigber, A.; Jäger, M. NL-SAR: A unified nonlocal framework for resolution-preserving (Pol)(In) SAR denoising. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2021–2038. [Google Scholar] [CrossRef] [Green Version]
- Su, X.; Deledalle, C.A.; Tupin, F.; Sun, H. Two-step multitemporal nonlocal means for synthetic aperture radar images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6181–6196. [Google Scholar]
- Sica, F.; Reale, D.; Poggi, G.; Verdoliva, L.; Fornaro, G. Nonlocal adaptive multilooking in SAR multipass differential interferometry. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 1727–1742. [Google Scholar] [CrossRef] [Green Version]
- Lin, X.; Li, F.; Meng, D.; Hu, D.; Ding, C. Nonlocal SAR interferometric phase filtering through higher order singular value decomposition. IEEE Geosci. Remote Sens. Lett. 2015, 12, 806–810. [Google Scholar] [CrossRef]
- Guo, Y.; Sun, Z.; Qu, R.; Jiao, L.; Liu, F.; Zhang, X. Fuzzy Superpixels based Semi-supervised Similarity-constrained CNN for PolSAR Image Classification. Remote Sens. 2020, 12, 1694. [Google Scholar] [CrossRef]
- Ma, F.; Gao, F.; Sun, J.; Zhou, H.; Hussain, A. Attention graph convolution network for image segmentation in big SAR imagery data. Remote Sens. 2019, 11, 2586. [Google Scholar] [CrossRef] [Green Version]
- Krestenitis, M.; Orfanidis, G.; Ioannidis, K.; Avgerinakis, K.; Vrochidis, S.; Kompatsiaris, I. Oil spill identification from satellite images using deep neural networks. Remote Sens. 2019, 11, 1762. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Cui, Z.; Tang, C.; Cao, Z.; Liu, N. D-ATR for SAR images based on deep neural networks. Remote Sens. 2019, 11, 906. [Google Scholar] [CrossRef] [Green Version]
- Anantrasirichai, N.; Biggs, J.; Albino, F.; Bull, D. A deep learning approach to detecting volcano deformation from satellite imagery using synthetic datasets. Remote Sens. Environ. 2019, 230, 111179. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 630–645. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the ICML 2015, Lille, France, 6–11 July 2015. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 3. [Google Scholar]
- Bamler, R.; Hartl, P. Synthetic aperture radar interferometry. Inverse Probl. 1998, 14, R1. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Chia Laguna Resort, Sardinia, Italy, 13–14 May 2010; pp. 249–256. [Google Scholar]
- Shiffler, R.E. Maximum Z scores and outliers. Am. Stat. 1988, 42, 79–80. [Google Scholar]
- Sun, Z.; Han, C. Heavy-tailed Rayleigh distribution: A new tool for the modeling of SAR amplitude images. In Proceedings of the IGARSS 2008—2008 IEEE International Geoscience and Remote Sensing Symposium, Boston, MA, USA, 7–11 July 2008; Volume 4, p. IV-1253. [Google Scholar]
- Iglewicz, B.; Hoaglin, D.C. How to Detect and Handle Outliers; ASQC Quality Press: Milwaukee, WI, USA, 1993; Volume 16. [Google Scholar]
- Pitz, W.; Miller, D. The TerraSAR-X satellite. IEEE Trans. Geosci. Remote Sens. 2010, 48, 615–622. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 4, p. 12. [Google Scholar]
- Timofte, R.; De Smet, V.; Van Gool, L. A+: Adjusted anchored neighborhood regression for fast super-resolution. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 111–126. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Highway networks. arXiv 2015, arXiv:1505.00387. [Google Scholar]
- Reza, T.; Zimmer, A.; Blasco, J.M.D.; Ghuman, P.; Aasawat, T.K.; Ripeanu, M. Accelerating persistent scatterer pixel selection for InSAR processing. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 16–30. [Google Scholar] [CrossRef]
- Reza, T.; Zimmer, A.; Ghuman, P.; Aasawat, T.K.; Ripeanu, M. Accelerating persistent scatterer pixel selection for InSAR processing. In Proceedings of the 2015 IEEE 26th International Conference on Application-Specific Systems, Architectures and Processors (ASAP), Toronto, ON, Canada, 27–29 July 2015; pp. 49–56. [Google Scholar] [CrossRef]
- Vicente, T.F.Y.; Hou, L.; Yu, C.P.; Hoai, M.; Samaras, D. Large-scale training of shadow detectors with noisily-annotated shadow examples. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 816–832. [Google Scholar]
- Goodman, J.W. Speckle Phenomena in Optics: Theory and Applications; Roberts and Company Publishers: Greenwood Village, CO, USA, 2007. [Google Scholar]
- Zimmer, A.; Ghuman, P. CUDA Optimization of Non-local Means Extended to Wrapped Gaussian Distributions for Interferometric Phase Denoising. Procedia Comput. Sci. 2016, 80, 166–177. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.X.; Baier, G.; Lachaise, M.; Shi, Y.; Adam, F.; Bamler, R. Potential and limits of non-local means InSAR filtering for TanDEM-X high-resolution DEM generation. Remote Sens. Environ. 2018, 218, 148–161. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Bovik, A.C. Mean squared error: Love it or leave it? A new look at signal fidelity measures. IEEE Signal Process. Mag. 2009, 26, 98–117. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems 27; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 2672–2680. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Phase RMSE (Radians) | ||||||
| Sim Configuration | Methods | |||||
| BoxCar | NL-SAR | NL-InSAR | Proposed | |||
| S1 | S | F1 | 0.7469 | 0.8401 | 0.8373 | 0.6939 |
| F2 | 1.0697 | 1.2012 | 0.9572 | 0.7422 | ||
| F3 | 1.0699 | 1.2054 | 1.0354 | 0.7890 | ||
| NS | F1 | 0.6675 | 0.7751 | 0.7088 | 0.6570 | |
| F2 | 0.9906 | 1.1015 | 0.8284 | 0.6938 | ||
| F3 | 0.9623 | 1.1348 | 0.9138 | 0.7261 | ||
| S2 | S | F1 | 0.8409 | 0.8782 | 0.9105 | 0.8091 |
| F2 | 1.1252 | 1.2319 | 1.0859 | 0.8854 | ||
| F3 | 1.2096 | 1.2801 | 1.1890 | 0.9593 | ||
| NS | F1 | 0.7863 | 0.8199 | 0.8256 | 0.7715 | |
| F2 | 1.0567 | 1.1687 | 0.9854 | 0.8297 | ||
| F3 | 1.1251 | 1.2186 | 1.0855 | 0.8785 | ||
| S3 | S | F1 | 0.9542 | 0.9332 | 0.9648 | 0.9370 |
| F2 | 1.1920 | 1.2657 | 1.1883 | 1.0239 | ||
| F3 | 1.3080 | 1.3430 | 1.2940 | 1.1156 | ||
| NS | F1 | 0.8886 | 0.8672 | 0.8976 | 0.8709 | |
| F2 | 1.1307 | 1.2203 | 1.1159 | 0.9555 | ||
| F3 | 1.2398 | 1.2927 | 1.2120 | 1.0259 | ||
| Average | 1.0202 | 1.0988 | 1.0020 | 0.8536 | ||
| Phase SSIM | ||||||
| Sim Configuration | Methods | |||||
| BoxCar | NL-SAR | NL-InSAR | Proposed | |||
| S1 | S | F1 | 0.9424 | 0.8897 | 0.8566 | 0.9511 |
| F2 | 0.7372 | 0.6266 | 0.7723 | 0.9333 | ||
| F3 | 0.6937 | 0.5989 | 0.6888 | 0.9015 | ||
| NS | F1 | 0.9665 | 0.8923 | 0.9505 | 0.9585 | |
| F2 | 0.8075 | 0.7413 | 0.8887 | 0.9493 | ||
| F3 | 0.7999 | 0.7074 | 0.8117 | 0.9303 | ||
| S2 | S | F1 | 0.8898 | 0.8590 | 0.8358 | 0.9122 |
| F2 | 0.6624 | 0.5681 | 0.6746 | 0.8647 | ||
| F3 | 0.5150 | 0.4684 | 0.5202 | 0.7976 | ||
| NS | F1 | 0.9221 | 0.8902 | 0.9023 | 0.9312 | |
| F2 | 0.7357 | 0.6577 | 0.7825 | 0.8966 | ||
| F3 | 0.6152 | 0.5647 | 0.6398 | 0.8527 | ||
| S3 | S | F1 | 0.8026 | 0.8168 | 0.7939 | 0.8349 |
| F2 | 0.5717 | 0.4989 | 0.5748 | 0.7670 | ||
| F3 | 0.3747 | 0.3555 | 0.3919 | 0.6675 | ||
| NS | F1 | 0.8570 | 0.8722 | 0.8508 | 0.8824 | |
| F2 | 0.6463 | 0.5736 | 0.6621 | 0.8211 | ||
| F3 | 0.4612 | 0.4375 | 0.4938 | 0.7463 | ||
| Average | 0.7223 | 0.6677 | 0.7273 | 0.8666 | ||
| Coherence RMSE | ||||||
| Sim Configuration | Methods | |||||
| BoxCar | NL-SAR | NL-InSAR | Proposed | |||
| S1 | S | F1 | 0.4360 | 0.4532 | 0.3827 | 0.2125 |
| F2 | 0.5418 | 0.6356 | 0.3526 | 0.1838 | ||
| F3 | 0.5321 | 0.6251 | 0.3639 | 0.1850 | ||
| NS | F1 | 0.2119 | 0.3472 | 0.1436 | 0.2045 | |
| F2 | 0.5458 | 0.6515 | 0.1907 | 0.1633 | ||
| F3 | 0.5444 | 0.6494 | 0.2565 | 0.1564 | ||
| S2 | S | F1 | 0.4284 | 0.4522 | 0.4136 | 0.2688 |
| F2 | 0.4887 | 0.5564 | 0.3802 | 0.2699 | ||
| F3 | 0.4784 | 0.5463 | 0.3869 | 0.2774 | ||
| NS | F1 | 0.2052 | 0.3303 | 0.1878 | 0.2011 | |
| F2 | 0.4768 | 0.5664 | 0.2749 | 0.2038 | ||
| F3 | 0.4766 | 0.5600 | 0.3175 | 0.2166 | ||
| S3 | S | F1 | 0.3780 | 0.3988 | 0.3834 | 0.2549 |
| F2 | 0.4251 | 0.4836 | 0.3726 | 0.2553 | ||
| F3 | 0.4244 | 0.4678 | 0.3805 | 0.2591 | ||
| NS | F1 | 0.2052 | 0.2522 | 0.2086 | 0.1920 | |
| F2 | 0.4117 | 0.4904 | 0.3116 | 0.1955 | ||
| F3 | 0.4207 | 0.4817 | 0.3419 | 0.1998 | ||
| Average | 0.4240 | 0.4971 | 0.3139 | 0.2167 | ||
| Coherence SSIM | ||||||
| Sim Configuration | Methods | |||||
| BoxCar | NL-SAR | NL-InSAR | Proposed | |||
| S1 | S | F1 | 0.5598 | 0.5444 | 0.7150 | 0.9056 |
| F2 | 0.4580 | 0.2859 | 0.5979 | 0.9007 | ||
| F3 | 0.3180 | 0.1280 | 0.4455 | 0.9104 | ||
| NS | F1 | 0.6695 | 0.7234 | 0.9497 | 0.9069 | |
| F2 | 0.5134 | 0.4225 | 0.6767 | 0.9040 | ||
| F3 | 0.3524 | 0.2859 | 0.4318 | 0.8977 | ||
| S2 | S | F1 | 0.3621 | 0.5057 | 0.6257 | 0.7349 |
| F2 | 0.3100 | 0.2860 | 0.4596 | 0.7649 | ||
| F3 | 0.2340 | 0.1967 | 0.2930 | 0.7508 | ||
| NS | F1 | 0.3061 | 0.7688 | 0.8752 | 0.7864 | |
| F2 | 0.2422 | 0.3986 | 0.4855 | 0.7584 | ||
| F3 | 0.1756 | 0.1931 | 0.1853 | 0.7994 | ||
| S3 | S | F1 | 0.2555 | 0.5082 | 0.5734 | 0.6908 |
| F2 | 0.2311 | 0.2952 | 0.4029 | 0.7323 | ||
| F3 | 0.1840 | 0.1728 | 0.2275 | 0.7072 | ||
| NS | F1 | 0.1782 | 0.8209 | 0.8195 | 0.7475 | |
| F2 | 0.1524 | 0.3910 | 0.4391 | 0.7119 | ||
| F3 | 0.1246 | 0.1552 | 0.1416 | 0.7617 | ||
| Average | 0.3126 | 0.3935 | 0.5192 | 0.7984 | ||
| BoxCar | NL-SAR | NL-InSAR | Proposed | |
|---|---|---|---|---|
| T (s) | 1.16 | 12.77 | 19.36 | 0.46 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, X.; Zimmer, A.; Mukherjee, S.; Kottayil, N.K.; Ghuman, P.; Cheng, I. DeepInSAR—A Deep Learning Framework for SAR Interferometric Phase Restoration and Coherence Estimation. Remote Sens. 2020, 12, 2340. https://doi.org/10.3390/rs12142340
Sun X, Zimmer A, Mukherjee S, Kottayil NK, Ghuman P, Cheng I. DeepInSAR—A Deep Learning Framework for SAR Interferometric Phase Restoration and Coherence Estimation. Remote Sensing. 2020; 12(14):2340. https://doi.org/10.3390/rs12142340
Chicago/Turabian StyleSun, Xinyao, Aaron Zimmer, Subhayan Mukherjee, Navaneeth Kamballur Kottayil, Parwant Ghuman, and Irene Cheng. 2020. "DeepInSAR—A Deep Learning Framework for SAR Interferometric Phase Restoration and Coherence Estimation" Remote Sensing 12, no. 14: 2340. https://doi.org/10.3390/rs12142340