Matching Confidence Constrained Bundle Adjustment for Multi-View High-Resolution Satellite Images


Abstract
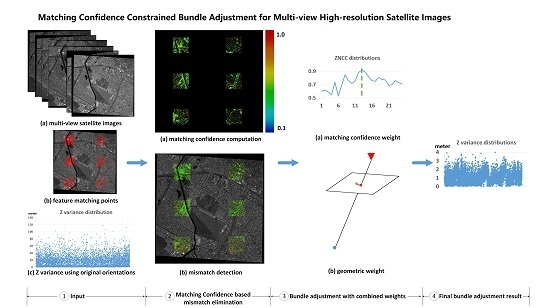
:
1. Introduction
- We improve the matching confidence metrics so that they can be applied in multi-view feature matching scenarios, which can give helpful prior knowledge of the matching accuracy;
- A new matching confidence based mismatch detection algorithm is proposed, which can give a robust match selection result, even though the mismatches are several times more than the correct matches.
- A new weighting strategy by combining the geometric weight and the image weight in BA is proposed. It is the first time to formulate the matching confidences as weights in the BA of multi-view satellite images, which can improve the accuracy of BA results when compared with the state-of-the-art BA process.
2. Methodology
2.1. Workflow
2.2. Improved Matching Confidences for Feature Matching
2.3. Matching Confidence Based Mismatch Elimination
2.3.1. Highest-Confidence Matches Selection
2.3.2. Initial Orientation Correction
2.3.3. Mismatch Elimination
2.4. Accurate Bundle Adjustment with Combined Weights
3. Experiments
3.1. The Performance Analysis of The Matching Confidence Metrics
3.2. The Mismatch Elimination Comparisons
3.3. The Tweighting Strategy Comparisons
3.4. Overall Workflow Comparison
4. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Zhang, Y.; Zhang, Y.; Mo, D.; Zhang, Y.; Li, X. Direct digital surface model generation by semi-global vertical line locus matching. Remote Sens. 2017, 9, 214. [Google Scholar] [CrossRef] [Green Version]
- Yang, K.; Pan, A.; Yang, Y.; Zhang, S.; Ong, S.; Tang, H. Remote sensing image registration using multiple image features. Remote Sens. 2017, 9, 581. [Google Scholar] [CrossRef] [Green Version]
- Song, X.P.; Potapov, P.V.; Krylov, A.; King, L.; Di Bella, C.M.; Hudson, A.; Khan, A.; Adusei, B.; Stehman, S.V.; Hansen, M.C. National-scale soybean mapping and area estimation in the United States using medium resolution satellite imagery and field survey. Remote Sens. Environ. 2017, 190, 383–395. [Google Scholar] [CrossRef]
- Jiao, N.; Wang, F.; You, H.; Yang, M.; Yao, X. Geometric Positioning Accuracy Improvement of ZY-3 Satellite Imagery Based on Statistical Learning Theory. Sensors 2018, 18, 1701. [Google Scholar] [CrossRef] [Green Version]
- Noh, M.J.; Howat, I.M. Automatic relative RPC image model bias compensation through hierarchical image matching for improving DEM quality. J. Photogramm. Remote Sens. 2018, 136, 120–133. [Google Scholar] [CrossRef]
- Zhang, Y.; Wan, Y.; Huang, X.; Ling, X. DEM-assisted RFM block adjustment of pushbroom nadir viewing HRS imagery. IEEE Trans. Geosci. Remote Sens. 2015, 54, 1025–1034. [Google Scholar] [CrossRef]
- Zhang, Y.; Zheng, M.; Xiong, X.; Xiong, J. Multistrip bundle block adjustment of ZY-3 satellite imagery by rigorous sensor model without ground control point. IEEE Geosci. Remote Sens. Lett. 2014, 12, 865–869. [Google Scholar] [CrossRef]
- World View-3 Datasheet. Available online: https://www.spaceimagingme.com/downloads/sensors/datasheets/DG_WorldView3_DS_2014.pdf (accessed on 10 August 2019).
- GF-2 (Gaofen-2) High-resolution Imaging Satellite/CHEOS Series of China. Available online: https://directory.eoportal.org/web/eoportal/satellite-missions/g/gaofen-2 (accessed on 10 August 2019).
- Tatar, N.; Saadatsresht, M.; Arefi, H. Outlier Detection and Relative RPC Modification of Satellite Stereo Images Using RANSAC+ RPC Algorithm. Eng. J. Geospat. Inf. Technol. 2016, 4, 43–56. [Google Scholar] [CrossRef] [Green Version]
- Ozcanli, O.C.; Dong, Y.; Mundy, J.L.; Webb, H.; Hammoud, R.; Victor, T. Automatic geo-location correction of satellite imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 307–314. [Google Scholar]
- Zhang, K.; Li, X.; Zhang, J. A robust point-matching algorithm for remote sensing image registration. IEEE Geosci. Remote Sens. Lett. 2013, 11, 469–473. [Google Scholar] [CrossRef]
- Alidoost, F.; Azizi, A.; Arefi, H. The Rational Polynomial Coefficients Modification Using Digital Elevation Models. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 40, 47. [Google Scholar] [CrossRef] [Green Version]
- Barath, D.; Matas, J. Graph-Cut RANSAC. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6733–6741. [Google Scholar]
- Korman, S.; Litman, R. Latent RANSAC. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6693–6702. [Google Scholar]
- Omidalizarandi, M.; Kargoll, B.; Paffenholz, J.A.; Neumann, I. Robust external calibration of terrestrial laser scanner and digital camera for structural monitoring. J. Appl. Geod. 2019, 13, 105–134. [Google Scholar] [CrossRef]
- Zheng, M.; Zhang, Y. DEM-aided bundle adjustment with multisource satellite imagery: ZY-3 and GF-1 in large areas. IEEE Geosci. Remote Sens. Lett. 2016, 13, 880–884. [Google Scholar] [CrossRef]
- Cao, M.; Li, S.; Jia, W.; Li, S.; Liu, X. Robust bundle adjustment for large-scale structure from motion. Multimed. Tools Appl. 2017, 76, 21843–21867. [Google Scholar] [CrossRef]
- Wieser, A.; Brunner, F.K. Short static GPS sessions: Robust estimation results. GPS Solut. 2002, 5, 70–79. [Google Scholar] [CrossRef]
- Chang, X.; Du, S.; Li, Y.; Fang, S. A Coarse-to-Fine Geometric Scale-Invariant Feature Transform for Large Size High Resolution Satellite Image Registration. Sensors 2018, 18, 1360. [Google Scholar] [CrossRef] [Green Version]
- Pehani, P.; Čotar, K.; Marsetič, A.; Zaletelj, J.; Oštir, K. Automatic geometric processing for very high resolution optical satellite data based on vector roads and orthophotos. Remote Sens. 2016, 8, 343. [Google Scholar] [CrossRef] [Green Version]
- Di, K.; Liu, Y.; Liu, B.; Peng, M.; Hu, W. A Self-Calibration Bundle Adjustment Method for Photogrammetric Processing of Chang′E-2 Stereo Lunar Imagery. IEEE Trans. Geosci. Remote Sens. 2013, 52, 5432–5442. [Google Scholar]
- Park, M.G.; Yoon, K.J. Learning and selecting confidence measures for robust stereo matching. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1397–1411. [Google Scholar] [CrossRef]
- Park, M.G.; Yoon, K.J. Leveraging Stereo Matching With Learning-Based Confidence Measures. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 101–109. [Google Scholar]
- Hu, X.; Mordohai, P. A quantitative evaluation of confidence measures for stereo vision. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2121–2133. [Google Scholar]
- Egnal, G.; Mintz, M.; Wildes, R.P. A stereo confidence metric using single view imagery with comparison to five alternative approaches. Image Vis. Comput. 2004, 22, 943–957. [Google Scholar] [CrossRef]
- Egnal, G.; Wildes, R.P. Detecting binocular half-occlusions: Empirical comparisons of five approaches. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1127–1133. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, B.; Zhang, Z.; Duan, Y.; Zhang, Y.; Sun, M.; Ji, S. Fully automatic generation of geoinformation products with chinese ZY-3 satellite imagery. Photogramm. Rec. 2014, 29, 383–401. [Google Scholar] [CrossRef]
- Zabih, R.; Woodfill, J. Non-parametric local transforms for computing visual correspondence. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 1994; pp. 151–158. [Google Scholar]
- Huang, X.; Zhang, Y.; Yue, Z. Image-guided non-local dense matching with three-steps optimization. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3. [Google Scholar] [CrossRef]
- Grodecki, J.; Dial, G. Block adjustment of high-resolution satellite images described by rational polynomials. Photogramm. Eng. Remote Sens. 2003, 69, 59–68. [Google Scholar] [CrossRef]
- QuickBird Imagery Products. Available online: http://glcf.umd.edu/library/guide/QuickBird_Product_Guide.pdf (accessed on 10 August 2019).
- Bosch, M.; Kurtz, Z.; Hagstrom, S.; Brown, M. A multiple view stereo benchmark for satellite imagery. In Proceedings of the IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 18–20 October 2016; pp. 1–9. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mismatch | Remained | True Value | Number Difference | Difference Ratio |
|---|---|---|---|---|
| Proportion | (N1) | (N0) | dN = N1 − N0 | |dN|/N1 |
| 0.05 | 59048 | −191 | 0.003235 | |
| 0.10 | 59109 | −130 | 0.002199 | |
| 0.20 | 59285 | 46 | 0.000776 | |
| 0.30 | 59195 | −44 | 0.000743 | |
| 0.40 | 59232 | −7 | 0.000118 | |
| 0.50 | 59324 | 85 | 0.001433 | |
| 0.60 | 59390 | 151 | 0.002543 | |
| 0.70 | 59468 | 229 | 0.003851 | |
| 0.80 | 59538 | 59,239 | 299 | 0.005022 |
| 0.90 | 59598 | 359 | 0.006024 | |
| 1.00 | 59678 | 439 | 0.007356 | |
| 1.50 | 59889 | 650 | 0.010853 | |
| 2.00 | 60141 | 902 | 0.014998 | |
| 2.50 | 60417 | 1178 | 0.019498 | |
| 3.00 | 60581 | 1342 | 0.022152 | |
| 3.50 | 60814 | 1575 | 0.025899 | |
| 4.00 | 61053 | 1814 | 0.029712 |
| Proportion of Mismatches | The RGW Method (pixel) | Our Method (pixel) | ||||
|---|---|---|---|---|---|---|
| 0.00 | 1.183 | 1.012 | 1.123 | 0.997 | 0.060 | 0.015 |
| 0.05 | 1.208 | 1.014 | 1.161 | 1.004 | 0.047 | 0.010 |
| 0.10 | 1.207 | 1.025 | 1.160 | 1.004 | 0.047 | 0.021 |
| 0.20 | 1.222 | 1.027 | 1.150 | 1.003 | 0.072 | 0.024 |
| 0.30 | 1.209 | 1.024 | 1.161 | 1.005 | 0.048 | 0.019 |
| 0.40 | 1.213 | 1.036 | 1.163 | 1.005 | 0.049 | 0.031 |
| 0.50 | 1.225 | 1.039 | 1.162 | 1.005 | 0.063 | 0.034 |
| 0.60 | 1.204 | 1.025 | 1.167 | 1.006 | 0.037 | 0.020 |
| 0.70 | 1.207 | 1.038 | 1.160 | 1.004 | 0.047 | 0.034 |
| 0.80 | 1.220 | 1.030 | 1.162 | 1.005 | 0.058 | 0.026 |
| 0.90 | 1.222 | 1.043 | 1.164 | 1.005 | 0.058 | 0.038 |
| 1.00 | 1.231 | 1.040 | 1.159 | 1.005 | 0.072 | 0.035 |
| 1.50 | 1.216 | 1.038 | 1.167 | 1.006 | 0.048 | 0.032 |
| 2.00 | 1.211 | 1.036 | 1.171 | 1.007 | 0.040 | 0.029 |
| 2.50 | 1.212 | 1.043 | 1.170 | 1.007 | 0.042 | 0.036 |
| 3.00 | 1.210 | 1.048 | 1.170 | 1.007 | 0.040 | 0.042 |
| 3.50 | 1.216 | 1.052 | 1.172 | 1.008 | 0.044 | 0.045 |
| 4.00 | 1.233 | 1.047 | 1.172 | 1.008 | 0.060 | 0.040 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ling, X.; Huang, X.; Zhang, Y.; Zhou, G. Matching Confidence Constrained Bundle Adjustment for Multi-View High-Resolution Satellite Images. Remote Sens. 2020, 12, 20. https://doi.org/10.3390/rs12010020
Ling X, Huang X, Zhang Y, Zhou G. Matching Confidence Constrained Bundle Adjustment for Multi-View High-Resolution Satellite Images. Remote Sensing. 2020; 12(1):20. https://doi.org/10.3390/rs12010020
Chicago/Turabian StyleLing, Xiao, Xu Huang, Yongjun Zhang, and Gang Zhou. 2020. "Matching Confidence Constrained Bundle Adjustment for Multi-View High-Resolution Satellite Images" Remote Sensing 12, no. 1: 20. https://doi.org/10.3390/rs12010020