1. Introduction
During the last thirty years, arid and semi-arid areas have shown an increasing trend of desertification, which is of great concern to the world [
1,
2,
3,
4]. Land desertification typically means that land loses water as well as vegetation and wildlife due to a variety of factors, such as global warming and overexploitation of soil through human activities. Vegetation growth requires water. Global warming, overgrazing, natural disasters, and other factors lead to loss of vegetation, which weakens the capacity of soil and reduces water conservation. The loss of soil and water will, in turn, affect the growth of vegetation and trigger land degradation and desertification. Thus, the change of vegetation cover is a significant indicator of land degradation and reveals the dynamics of ecosystems in the areas [
2,
5,
6,
7,
8]. Accurately monitoring the dynamics of vegetation cover in arid and semi-arid areas has become critical. Percentage vegetation cover (PVC) is defined as the percentage of an area covered by vegetation canopy and quantifies the amount of vegetation. Traditional methods of PVC estimation, including sampling and ocular estimation, as well as visual interpretation using photographs [
9,
10], are costly, inefficient, and subjective, with low accuracy. Remotely-sensed images can capture the characteristics of vegetation cover at different spatiotemporal resolutions with a large coverage and low cost, and thus provide great potential for deriving the spatial distribution and dynamics of PVC at regional, national, and global scales. However, the existence of mixed pixels in images often impedes improvements in estimating PVC. This is especially true in arid and semi-arid regions that are sparsely populated. A cost-effective spectral unmixing analysis method is needed.
The results of spectral unmixing analysis vary depending on many factors, such as landscape complexity and the used methods, images and spatial resolutions, selection of endmembers, and so on [
5,
6,
9]. Various sensor and spatial resolution images have been used for PVC estimation [
1,
5,
9,
11,
12,
13,
14,
15], but medium spatial resolution multispectral data are more commonly utilized because they are cheap and easy to obtain [
5,
11,
14,
16]. High spatial resolution images, such as those from IKONOS, QuickBird, RapidEye, Worldview, and Gaofen-2, can clearly reflect the features of vegetation canopies because of small pixel sizes and relatively small portions of mixed pixels, but are often only used for small areas due to their high costs [
11]. Coarse spatial resolution data, such as those from National Oceanic and Atmospheric Administration/Advanced Very High Resolution Radiometer (NOAA/AVHRR) [
12] and Moderate-resolution Imaging Spectroradiometer (MODIS) [
1,
13,
17,
18,
19], have larger coverage capability and high temporal resolutions, and thus can be used to get near real-time observations of PVC for large areas and at national and global scales. However, large pixels often lead to smoothed results with a low estimation accuracy. Medium spatial resolution images, such as Landsat [
14] and Advanced Spaceborne Thermal Emission and Reflection Radiometer (ASTER) [
15] data, are suitable for PVC estimation at a regional scale due to them being free to download and having relatively large coverage areas. However, the impact of mixed pixels on estimation accuracy of PVC usually cannot be ignored.
Developing a cost-effective spectral unmixing method is critical for increasing the estimation accuracy of PVC using remotely-sensed images [
20,
21,
22]. Most spectral unmixing methods have two steps: extraction of endmembers—that is, pure training samples—and estimation of PVC or fraction of vegetation cover. Endmembers can be obtained from field or laboratory measurements or remote sensing images. Extracting the endmembers from images is often conducted because the obtained endmembers have consistent spatial resolutions with pixels to be estimated and the cost is also low. However, this method requires fine spatial resolution images such as aerial photographs and Worldview satellite images to interpret endmembers (pure pixels). This may lead to a high cost for mapping PVC at regional and national scales. This is especially true when mapping PVC is conducted for large and remote arid and semi-arid areas. Thus, it is necessary to develop a novel method for selecting endmembers from medium and coarse spatial resolution images.
On the other hand, most existing studies use a fixed number of endmembers [
21,
23]. However, Roberts et al. [
24] developed a multiple endmember spectral mixture analysis method. In the method, endmembers varied on a per-pixel basis and were selected from a library of field- and laboratory- measured spectra of leaves, canopies, stems, and soils. The selected endmembers were then used to develop a set of candidate models. Each of the models was assessed in terms of root mean square error (RMSE) by applying them to an airborne visible/infrared imaging spectrometer image to map California chaparral. Dennison and Roberts [
25] further improved this method by using endmember average RMSE to select the endmember models. The multiple and variable endmember-based method theoretically model the complexity of landscapes and spatial variability of endmembers. It provides great potential to improve estimation of PVC and is very promising. However, this method is very complicated and less applicable to large areas, mainly because of the lack of libraries of spectral reflectance for endmembers or because it is labor intensive and costly when collecting a large number of field and laboratory measurements. This suggests that developing a cost-effective method for selecting endmembers is challenging but important. A good alternative is to select endmembers in remote sensing images. This is especially true when mapping of PVC is conducted for large areas.
Various spectral unmixing analysis methods have been developed and can be divided into linear spectral unmixing (LSU) and nonlinear spectral unmixing [
23]. In LSU methods, it is assumed that there is no interaction between endmembers and the reflectivity of a mixed pixel is a linear combination of the reflectivity values from all endmembers [
26,
27]. With simple models and the ability to directly interpret the results, LSU predominates in the area of spectral unmixing. However, the assumption of LSU methods for decomposition of endmembers in mixed pixels is often not true because of multiple scattering from neighboring objects and interactions among the endmembers [
19,
20]. Moreover, decomposition of endmembers in mixed pixels is complex and depends on many factors, including landscape complexity, spatial resolution of images, purity of endmembers, or training samples selected and relationship of PVC with spectral variables derived from images [
5,
6,
9,
11,
17,
19,
20]. Therefore, LSU methods do not work well in many cases. Li et al. [
19] improved the LSU methods by equally weighting the values of ratio vegetation index (RVI) and normalized difference vegetation index (NDVI) to minimize their biases due to bare soil and dense canopy-induced saturation. However, their model used for only two endmembers (bare soil and vegetation) is too simple and needs further improvement for its applicability to more complex landscapes. Moreover, the authors collected the in situ measurements of spectral reflectance for bare soil and vegetation in a limited area due to the high cost. Thus, this method is limited for mapping PVC for large and complex areas.
Nonlinear spectral unmixing methods such as artificial neural networks (ANN) consider the nonlinearity and multiple scattering from endmembers and can be more appropriate for estimation of PVC. Traditionally, these methods are based on radiance theory [
28], which is very complicated. There have also been nonlinear spectral unmixing approaches that were developed based on computational methods, such as ANN [
29,
30] and regressions [
31,
32]. One example of an ANN algorithm is a radial basis function neural network (RBFNN). The RBFNN is a neural network learning method that extends input vectors into a high-dimensional space [
33]. It has strong local generalization ability, overcomes the problem of slow convergence, and it is easy for it to fall into the local minimum of the back-propagation neural network. However, the estimation accuracy of all ANN algorithms varies depending on the size and characteristic representation of training samples. Generally, the larger the sample size and the better the representation of the training samples, the greater the estimation accuracy that can be achieved.
Moreover, random forest (RF) is a nonparametric algorithm based on regression trees that can also be utilized to estimate PVC [
16]. RF uses randomly selected training samples and variable subsets to build multiple regression trees. It can fast and efficiently process a large dataset and improve the prediction accuracy of the model [
34,
35,
36]. Belgiu and Drăguţ [
37] provided a review of remote sensing applications for RF. They pointed out that RF is appropriate to handle high data dimensionality and multicollinearity and select suitable features for reduction of independent variables, being fast and insensitive to overfitting. Similar to ANN methods, however, it is sensitive to sampling design (requiring sufficient samples and substantial representatives) [
37]. This implies that using RF to map PVC may be theoretically appropriate because of its strong ability to handle data and optimize selection of features, but the requirements of large sample sizes and good representatives may lead to a high cost.
Fevotte et al. [
37] developed a mixture model of linear and nonlinear unmixing methods. In the mixture model, a standard linear spectral unmixing method and an additive term that accounts for nonlinear effects were integrated. The idea of the improved method is to consider the macroscopic and intimate mixtures of spectral reflectance within mixed pixels as the combination of a linear trend contribution and a residual term. That is, nonlinearities are merely treated as outliers. The authors validated this method using two hyperspectral images to extract the information of water, soil, tree species, and other vegetation. They found that the improved method successfully picked up the mixed pixels along the borders of different land cover types. Altmann et al. [
38] proposed a Bayesian nonlinear hyperspectral unmixing algorithm that incorporates spatial dependency inherent in an image. The nonlinear mixtures of pixels are decomposed into a linear combination of endmembers, with an additive term accounting for nonlinear effects. A Gamma Markov random field is used to extract nonlinearity variation. This algorithm can identify the nonlinear regions and assign a zero-mean Gaussian prior to the nonlinear coefficient of each pixel. The authors used synthetic and real data for comparisons and demonstrated that the proposed method was compatible with the state-of-the-art approaches.
Dobigeon et al. [
39] conducted a review of spectral unmixing models and algorithms based on hyperspectral imagery. They classified the models into intimate mixture and bilinear models and grouped the algorithms into model-based parametric and model-free nonlinear unmixing approaches. Moreover, after characterizing the models and algorithms, the authors suggested an application strategy of selectively applying linear and nonlinear unmixing methods using a pixel-by-pixel approach. The application strategy was achieved by detecting the characteristics of each mixed pixel and then determining the appropriateness of selecting a linear or nonlinear method. In addition, they pointed out two important challenges: how to integrate the algorithmic approaches and physical models to improve nonlinear unmixing performance; and how to develop new unmixing models to take into account heterogeneous regions in which linear, weakly, and strongly nonlinear pixels exist. Overall, the relatively new developments are promising but complicated and difficult to apply.
The k-nearest neighbors (kNN) is a nonparametric model that uses spectral similarity between an unknown pixel and each of the training samples to predict one or more variables [
40,
41,
42]. It does not require the assumption of data distribution and complex parameters. Because of its simplicity and applicability, kNN has become popular in recent years [
43,
44]. Zhu et al. [
45] improved the measure of spectral similarity by calculating the weighted spectral distance based on correlations among the spectral variables used. Sun et al. [
16] further proposed an improved kNN by finding and using an optimal number of nearest neighbors, k, for each of the estimated locations. Compared with ANN and RF, this method is simpler and cheaper. Integrating the measure of spectral similarity in kNN with spectral unmixing analysis provides the potential to improve the estimation of PVC in arid and semi-arid areas.
China is one of the countries in which serious land degradation and desertification occurs in its north and northwest areas, especially in Inner Mongolia, Xingjiang, Gansu, and Tibet. The total area of desertification land is about 4,354,800 km
2, occupying 45.36% of the national land area. The desertification has brought serious impacts to the population of about 0.4 billion people [
46]. Monitoring the dynamics of vegetated lands in the whole desertification area is critical. Substantial research has been conducted, but there have been no accurate and cost-effective methods available because of the large, remote, and sparsely populated area, large number of mixed pixels on images, and difficulty of collection of field measurements [
17,
18,
19,
47,
48,
49,
50,
51,
52]. Thus, there is a strong need to develop an accurate and cost-effective method to monitor the land degradation and desertification in the northern and northwestern China.
In this study, the overall objective was to develop and evaluate a cost-effective method to map PVC as a significant indicator of land degradation and desertification for the north and northwest areas of China. In these areas, collecting field measurements of PVC is difficult and costly because of the area being remote and sparsely populated. We first presented a method that was used to select and purify endmember pixels from Landsat 8 images by removing those containing multiple components. We then proposed and compared two novel probability-based methods to improve the PVC estimation in a selected study area in terms of accuracy and cost-effectiveness. The methods include a probability-based spectral unmixing analysis (PBSUA) and a probability-based optimal kNN (PBOkNN). The methods were also compared with the widely used LSU, RF, and RBFNN approaches to verify the improvement of estimation accuracy and cost-effectiveness of the proposed methods.
4. Discussion
4.1. Method for Obtaining Endmembers
The estimation accuracy of spectral unmixing analysis varies, to a great extent, depending on the selection and purification of training samples (endmembers) [
19,
24,
25]. Endmembers are often selected from a library of spectral reflectance, field or laboratory measurements, or fine spatial resolution images. For example, Li et al. [
19] selected two endmembers: bare soil and vegetation based on 30 m × 30 m spatial resolution Landsat 8 images and in situ measurements of spectral reflectance and obtained a determination coefficient of 0.54 and a RMSE of 0.17 for estimating fraction of vegetation cover for Inner Mongolia using an improved pixel dichotomy model. This method is simple and easy to apply, but requires endmember field measurements of spectral reflectance. This will greatly increase the cost when it is applied to large areas. Moreover, Roberts et al. [
24] proposed a variable endmember spectral unmixing analysis. Dennison and Roberts [
25] improved the variable endmember method and obtained a classification accuracy of 88.6% to map six land cover types in the Santa Ynez Mountains using an airborne image. However, the method uses libraries of spectral reflectance for endmembers and is not applicable to mapping PVC for the northern and northwestern China because of the lack of spectral libraries.
There are no general rules that can be used to optimize the selection and purification of endmembers from remote sensing images. In this study, we developed a general method for selection and purification of endmembers using Landsat 8 images at the spatial resolution of 30 m × 30 m to map PVC for large areas. Generally, the 30 m spatial resolution is too coarse to select pure pixels. In this study, the disadvantage was overcome by integrating visual interpretation, use of NDVI values, and purification of endmember pixels. The potentially impure pixels were, thus, removed. It was found that the endmember purification significantly improved the estimation accuracy of PVC in the study area by 25.2%. This was mainly because this method greatly reduced the heterogeneity of the endmember pixels and minimized their reflectance variation within each of the endmembers. Integrating the endmember selection method with the proposed method PBSUA led to coefficient of determination values of 0.679 and RRMSE of 22.9%, indicating significant RRMSE decreases of 47.4% and 29.3% compared with those from the LSU methods without and with the purification of the endmembers, respectively. The PBSUA provided an accuracy value similar to those from RF and RBFNN, but the former was much more cost-effective (discussed next). The results are also compatible with the findings from previous studies [
19,
24,
25]. However, the proposed method for selection of endmembers does not require libraries and field measurements of endmember spectral reflectance, and will greatly reduce the cost of collecting the field observations of spectral reflectance. This is especially important for mapping PVC at regional, national, and global scales.
Theoretically, the proposed method integrates visual-interpretation-based image stratification, spectral-reflectance-based vegetation indices, and statistically an outlier removal method to select and purify the endmember pixels. The pixels that are selected by visual interpretation contain multiple endmembers, and are treated as outliers and removed using vegetation indices and statistical methods. This study showed that although the used Landsat images had a 30 m × 30 m spatial resolution, the images could be successfully utilized to select the endmembers with the proposed method. This implied that the disadvantage of the medium spatial resolution images for selecting endmembers could be compensated by using vegetation indices and statistical methods. Thus, this method overcame a gap that currently exists in the use of medium resolution images to select endmembers and advanced the literature in the field. This method is easier and more promising for application to the selection of endmembers for mapping PVC for large areas than the existing methods. This method also provides the potential to use coarser spatial resolution images such as MODIS products to select endmembers and map PVC at national and global scales.
4.2. Method Comparison by Estimation Accuracy
The multiple scattering often leads to a nonlinear relationship of endmember component fractions with the reflectance values within mixed pixels. The LSU methods lack the ability to model the nonlinear relationship because of their assumption that the spectral reflectance value of a mixed pixel is a convex linear combination of the endmember spectra. Thus, the LSU methods do not work well when the assumption is broken down or landscapes are complex, such as urbanized lands, mountainous areas, and sparsely vegetated areas [
20,
37,
38,
39,
53,
54,
55].
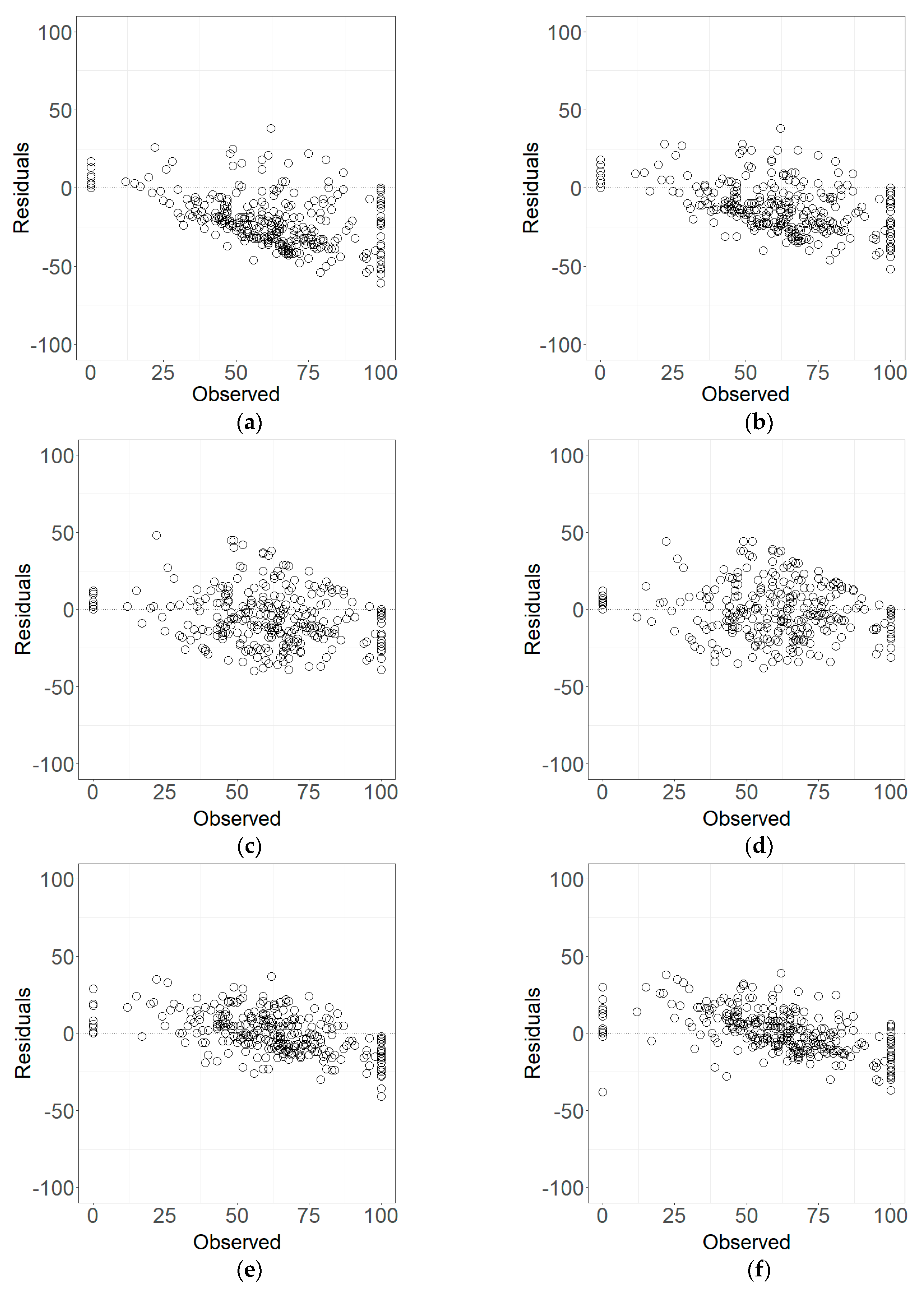
The results of this study showed that compared with two LSU methods with and without the endmember purification, the proposed methods PBSUA and PBOkNN, along with two widely used nonlinear models RF and RBFNN, significantly decreased the RRMSE of PVC estimates (
Table 3). The decrease of RRMSE was represented using the difference of RRMSE values between two methods divided by the RRMSE from the compared method. Compared with LSU without the endmember purification, the PBSUA, PBOkNN, RF, and RBFNN methods decreased the RRMSE by 47.1%, 36.5%, 49.7%, and 47.3%, respectively. Compared with LSU with the endmember purification, the PBSUA, PBOkNN, RF, and RBFNN decreased the RRMSE by 29.3%, 15.1%, 32.8%, and 29.7%, respectively. This finding is consistent with the conclusions from previous studies [
20,
53,
54,
55]. Yu et al. [
54] used Landsat data and compared six linear and nonlinear unmixing methods, including LSU, support vector machine, ANN, and others to estimate fractions of water, forest, and bare land for an area located in Guangxi in China. The authors concluded that all the nonlinear methods decreased the RMSE values by 17.8% to 57.9% compared with the linear approaches. Mitraka et al. [
55] used an ANN trained with nonlinear and linear methods, respectively, and concluded that compared with the linear method, the nonlinear ANN decreased the RMSE by 20.4%, 0.0%, 37.6%, and 4.1% for the fraction estimations of built-up area, vegetated area, nonurban bare land, and water, respectively. Similarly, Ahmed et al. [
20] presented an ANN-based hybrid approach for switching between linear and nonlinear spectral unmixing of hyperspectral data and found that the hybrid method increased the estimation accuracy of twenty-one endmember fractions by 63.0% to 84.8% compared with the linear and nonlinear models alone. This indicated that the hybrid approach was promising. However, their study used the controlled synthetic data, which covered a small area. Thus, further validation based on real datasets from large and complex landscapes is needed.
Compatibly, machine learning, and nonlinear spectral unmixing methods, especially RF and ANN, are more sensitive to modeling the nonlinear relationship in mixed pixels and have greater potential to provide more accurate estimates of endmember fractions within mixed pixels [
20,
39,
53,
54,
55]. The nonlinear methods often uses hyperspectral images rather than cheaper multispectral images [
37,
38,
39]. So far, RF has been widely used for image classification, and there have been almost no reports for its application for mapping PVC. Maxwell et al. [
56] compared six machine learning classifiers to classify alfalfa, corn, soybeans, wheat, hay, grass, oats, and trees using an airborne visible/infrared imaging spectrometer (AVIRIS) image in Tippecanoe County, Indiana. The classifiers included support vector machines, decision trees, RF,-boosted decision trees, ANN, and kNN. The authors obtained overall classification accuracies of 89.1%, 78.3%, 87.1%, 87.2%, 85.1%, and 78.6%, respectively. The authors also utilized the six methods with high spatial resolution aerial images to distinguish trees, grass, soil, concrete, asphalt, buildings, cars, pools, and shadows in Deerfield Beach, Florida, and yielded overall accuracies of 76.3%, 68.1%, 81.5%, 76.9%, 67.5%, and 72.4%, respectively. However, both RF and ANN are sensitive to training sample size and characteristics [
33,
35,
56].
The previous studies also imply that when the information of an interest variable such as PVC is extracted using spectral unmixing analysis and remote sensing images, both linear and nonlinear relationships of the interest variable with spectral variables may exist in a landscape [
20,
37,
55]. The relationships may vary on a pixel-by-pixel basis or by sub-region. An interest variable may also be characterized by both spatial dependency and heterogeneity. The challenges for improving the performance of the information extraction are first to accurately identify the relationships and characteristics, and then to develop methods to take into account the relationships and characteristics.
In this study, the proposed PBOkNN is an integration of the probability-based decomposition of endmembers with kNN. The kNN is a simple local interpolation technique and has been widely used in forest parameter estimation and mapping, as well as land use and land cover classification, because of its advantage of using
k most-similar neighbors in a multiple feature space [
45,
57,
58,
59]. In both the proposed PBSUA and PBOkNN, it is assumed that multiple components within each mixed pixel are characterized by the spectral centers of endmembers. The spectral similarity of the mixed pixel to each of the endmembers is quantified using Euclidean distances of spectral features, and then transformed into the probability of the mixed pixel belonging to each of the endmembers. A constraint is used, specifying that the probability summation for all the endmembers within the mixed pixel equals one. This means that both methods are developed based on spectral clustering of similar pixels and endmembers in a multiple dimensional feature space. Within the mixed pixel, the higher the fraction of the endmember component, the more similar the mixed pixel to the endmember and the greater the probability of the mixed pixel belonging to the endmember. In both methods, there is no assumption of linear or nonlinear relationship of PVC with spectral features to be made. Moreover, both methods also transform spatial dependency and heterogeneity into spectral similarity and dissimilarity in a feature space. Thus, the proposed methods provide solutions for the challenges that currently exist in the area of spectral unmixing analysis.
In this study, overall, the PBSUA, PBOkNN, RF, and RBFNN methods had statistically similar accuracies of PVC predictions, indicating that two proposed methods were compatible with the nonlinear unmixing methods. However, the arid and semi-arid areas are sparsely populated and it is often difficult to collect sample field data. Thus, given an estimation accuracy required, the fewer sample plots a method needs, the better the model. Because the pure pixels of the endmembers were selected from the Landsat image, the proposed PBSUA did not need the field plot data for training, except for the test plots. Both RF and RBFNN required a large number of field sample plots for training in addition to the test plots. Similarly, the proposed PBOkNN also needed the field sample plots to determine the optimized k value in addition to the test plots. Additionally, RBFNN produced the PVC estimates less than 0.0% and greater than 100%, which were not reasonable. This implies that the proposed PBSUA has a more significant advantage in terms of accuracy, reasonable predictions, and cost, and is especially appropriate for mapping PVC for large and sparsely populated areas.
The proposed PBOkNN is similar to PBSUA in terms of selection of endmembers and model training. However, it is still unknown how many sample plots are sufficient to determine the optimal k value for PBOkNN. In order to account for the influence of the sample sizes on the estimation accuracy of PVC using this method, we randomly selected and compared four datasets from the field sample plots to map PVC. The datasets consisted of one-fifth (123 plots), two-fifths (245 plots), three-fifths (368 plots), and four-fifths (490 plots) of the field sample plots. The validation results showed that the average values of the estimates varied from 59.6% to 60.2%, all falling within the confidence interval of the test sample data. The RRMSE values slightly decreased from 28.0% to 27.5%. That is, the estimation accuracies of PVC by the different numbers of the sample plots were not statistically significantly different from each other, implying that the sample sizes did not have a great impact on the estimation accuracy of PVC using PBOkNN. The results of this method became stable and achieved the desired accuracy with 123 training plots. The main reason might be because the k nearest plots at each location were selected based on the smallest RMSE between the estimated and referenced PVC values, and the sample size of 123 training plots was large enough to result in stable estimates. On the other hand, when the number of the sample plots was larger than the required number, the plot data tended to be similar to each other. This implied that once the sample plot data is enough, adding more sample plots would not significantly increase the estimation accuracy. This characteristic of PBOkNN provides the potential to reduce the cost for collection of field plot data, which is favorable for mapping PVC for large areas.
The main objective of this study is to develop a cost-effective method for mapping PVC towards a generalized framework of monitoring the dynamics of vegetation cover for large and sparsely populated arid and semi-arid areas in northern and northwestern China. In this study, we used two Landsat 8 images that had a spatial resolution of 30 m × 30 m and a temporal resolution of 16 days. The advantage of the proposed PBSUA and PBOkNN is that the collection of field data for endmembers to train the model can be greatly reduced or avoided. Moreover, the 16-day temporal resolution of Landsat 8 imagery is relatively too coarse to achieve the near real-time monitoring of PVC in the investigated areas. An alternative is using MODIS products that have finer temporal resolutions. For example, Anees and Aryal [
60] developed a near real-time detection framework for occurrence of beetle infestation in pine forests using the time series of eight-day 500 m spatial resolution MODIS data collected over five years. In this framework, each of seven vegetation indices was fit by an underlying triply modulated cosine model to derive a stationary vegetation index time series. Based on standard martingale central limit theorem and Gaussian distribution, any non-stationarity in the time series could be detected, indicating beetle infestations. Anees et al. [
61] further improved this method so that it could be applied to non-Gaussian time series data to detect near real-time land cover changes using a MODIS NDVI time series. The previous studies imply that the integration of the two proposed methods—especially PBSUA—and the detection framework from Anees and Aryal [
60] would make it possible to develop a near real-time monitoring approach for PVC dynamics for large arid and semi-arid areas. In the integration, PBSUA can be used to select endmember pixels from Landsat images, and the monitoring framework of PVC changes can then be generated by combining PBSUA and the method of Anees and Aryal [
60] based on the times series of vegetation cover probability from MODIS products.
4.3. Method Comparison by Cost-Effectiveness
Substantial research has been conducted to compare classification accuracies of various linear and nonlinear unmixing methods using remote sensing imagery, but there have been almost no reports that deal with direct comparison of cost-effectiveness among the methods. However, the cost-effectiveness analysis becomes very important for mapping PVC for large areas, because some of the methods are sensitive to the training sample size and computation time, while others not. This will lead to different cost-efficiencies. In the studies related to mapping soil erosion induced by vegetation cover disturbance, Anderson et al. [
62] and Wang et al. [
63] defined the per sample unit cost-effectiveness as the product of sampling cost per sample unit and average relative error. The authors found that the cost-effectiveness of local variability-based sampling was 5% to 40% higher than that of random sampling. The reason was mainly because the former resulted in the optimized sampling distances and minimized the duplication of information that often takes place in a random sampling design. Wang et al. [
64] investigated the cost-effectiveness of the data from different sample plot sizes and image pixel sizes for mapping soil erosion, and concluded that the 20 m spatial resolution sample plot data offered the highest cost-effectiveness of predictions.
In this study, we compared and analyzed the cost-effectiveness of the methods. The analysis did not include the LSU without purification of endmembers because it had almost the same cost as the LSU with purification of endmembers, which had a higher estimation accuracy. The cost of mapping PVC in this study was 150 thousand RMB yuan (1$ = 7.05 yuan), consisting of 120 thousand yuan for the collection of the field data and 30 thousand yuan for the data processing and analysis. The LSU with purification of endmembers and the proposed PBSUA used 307 sample plots as the test data, implying a cost of 40 thousand yuan. The proposed PBOkNN, RF, and RBFNN used all the sample plots, and the total cost was 150 thousand yuan. Thus, the cost-efficiencies of LSU with purification of endmembers, PBSUA, PBOkNN, RF, and RBFNN were 0.0441, 0.0624, 0.0243, 0.0307, and 0.0293, respectively. This indicated that the proposed PBSUA was most cost-effective, followed by LSU with purification of endmembers, RF, RBFNN, and PBOkNN. The PBOkNN had a cost-effectiveness of 0.0243 when a total of 613 sample plots were used to determine the optimal k value. In this method, however, when the number of the sample plots used to determine the optimal k value varied from 613 to 490, 368, 245, and 123, its estimation accuracy changed very slightly, while its cost-effectiveness increased from 0.0243 to 0.0266, 0.0302, 0.0350, and 0.0415, respectively. This implied that when a total of 123 sample plots were used, PBOkNN achieved a higher cost-effectiveness than RF and RBFNN.
Due to the difficulty and high cost of collecting field data in the arid and semi-arid areas, the methods with higher cost-effectiveness should provide greater potential for improving PVC estimation. In this study, RF and RBFNN had higher PVC estimation accuracy, but both used a total of 613 sample plots to train the models. The proposed PBOkNN also needed at least 123 sample plots to determine the optimal k value. The use of the training sample plots lowered the cost-effectiveness of RF, RBFNN, and PBOkNN, and thus they were not appropriate for applications to map PVC for large and sparsely populated arid and semi-arid areas. Because of only using the pure pixels from the Landsat 8 image as the endmembers and the fact that field sample plot data was not needed, the LSU with purification of endmembers had a cost-effectiveness higher than that of other methods, except for PBSUA. However, the LSU with purification of endmembers led to average estimates of the sample plots and the prediction map that were out of the confidence interval of the test dataset, and thus should not be selected for mapping. Moreover, the proposed PBSUA also did not need field sample plot data, but resulted in estimation accuracy that was only slightly lower than those from RF and RBFNN. Thus, PBSUA had the highest cost-effectiveness, implying the best performance for mapping PVC in this study. It is expected that this method can be applied to map PVC for the whole arid and semi-arid area of northern and northwestern China.
4.4. Method Application
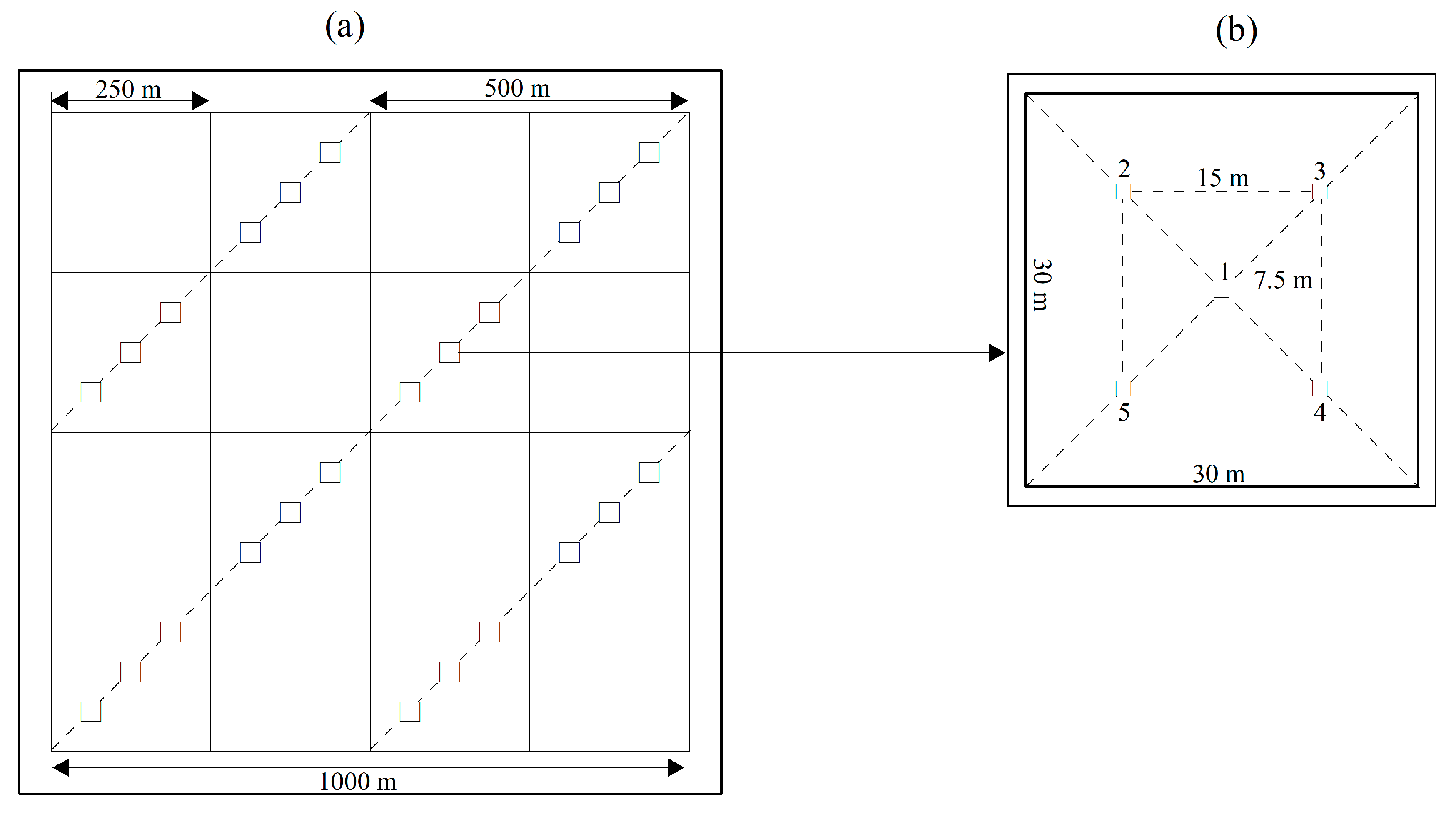
This study is part of a large research project that deals with development and evaluation of cost-effective methods used to map PVC for north and northwest China. In this area, monitoring land degradation and desertification expansion is needed, but collecting field measurements of PVC is difficult and costly because of the area being remote and sparsely populated. In this study, Duolun county is selected because of its representativeness in terms of topography, soil, and vegetation. In addition, there is a need for monitoring the dynamics of PVC and examining the effect of the national key ecological construction project starting in this county in 2000. The size of this study area is relatively small, but it is acceptable because this study focuses on the development and evaluation of the proposed methods, with a large sample size of 920 sample plots of 30 m × 30 m. In the future study, it is expected that the most cost-effective method should be further assessed in larger areas.
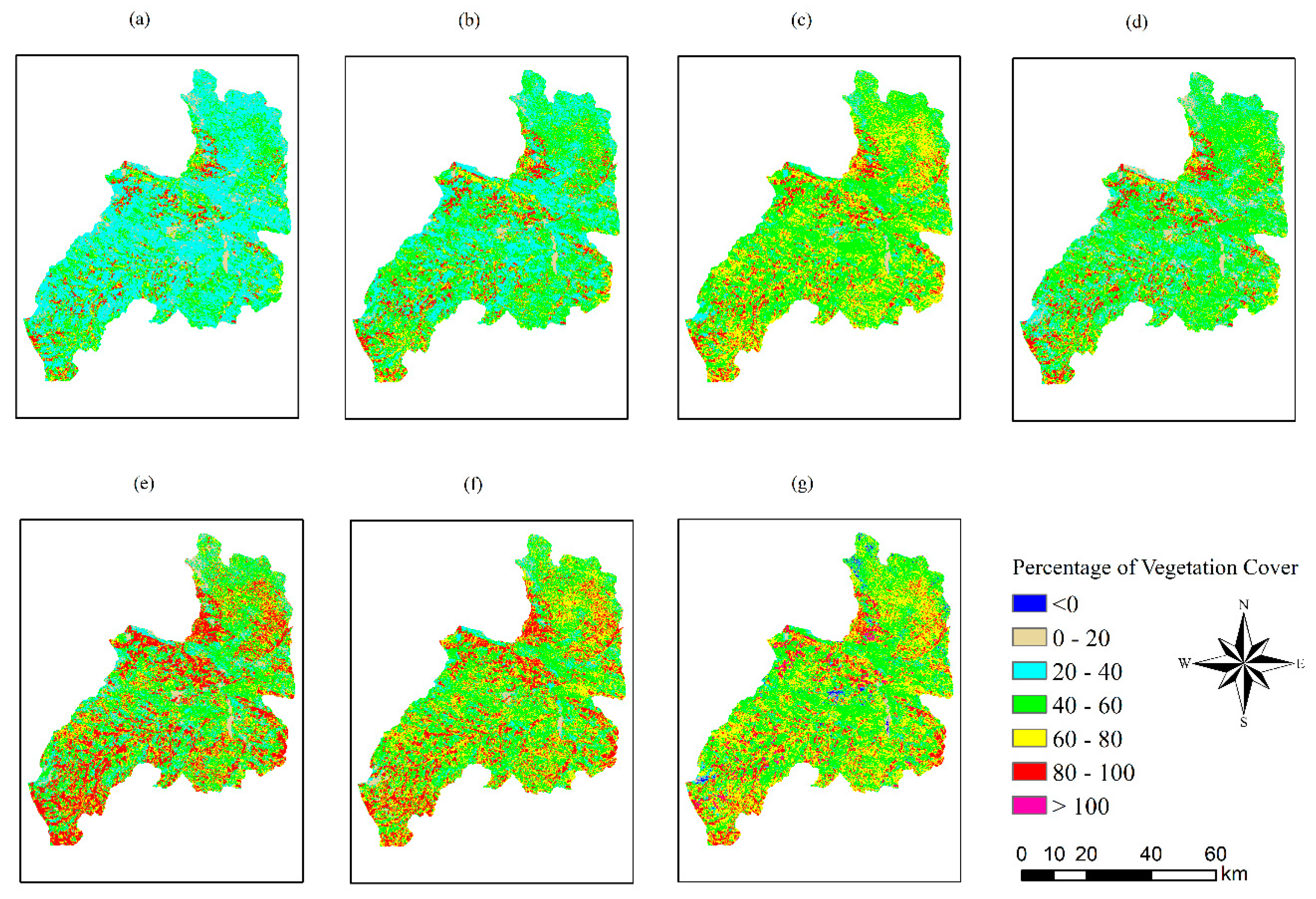
The results showed that the proposed PBSUA method is the most cost-effective for mapping PVC in Duolun county using the Landsat 8 imagery. This method is simple and consists of selecting endmembers, deriving spectral similarity of mixed pixels to each endmember and estimating the probability of each mixed pixel belonging to each endmember. In this method, one standard deviation of the average spectral distance among the selected pixels within the same endmember is utilized to remove the impure pixels. The probability of vegetation cover within a mixed pixel is then estimated based on the spectral similarities of the mixed pixel to the vegetation endmembers. The PVC value of the mixed pixel is finally obtained by summing the probabilities of relevant vegetation cover components, including grassland and crop land in this study. In fact, the grassland area actually consists of grassland and woodland in this study. In future studies, the grassland and woodland areas could be separated and other vegetation relevant components could be added. In addition, this method is generalized and can be applied to any study of spectral unmixing analysis using spectral variables from remote sensing data, such as Sentinel-2 and SPOT imagery.
In this study, we only used the original bands of the Landsat 8 image instead of various vegetation indices. This was mainly because of the following reasons: (1) This study focused on the development of the proposed PBSUA and its comparison with other wisely used methods. Thus, using the same set of spectral variables simplified and standardized the assessment of cost-effectiveness among the methods. (2) Because different methods may be sensitive to different spectral variables, such as vegetation indices, using different spectral variables for the methods would impede the consistent assessment of cost-effectiveness. (3) Using the original bands calibrated the method assessment of cost-effectiveness and did not affect the generalization of applications for the proposed PBSUA. In the future studies, the proposed method can be further evaluated using various vegetation indices.
It has to be pointed out that compared with finer spatial resolution images, such as those from Sentinel 2, using the 30 m × 30 m resolution Landsat images in this study increased the number of mixed pixels. This method is, thus, prone to estimation errors of PVC due to the mixed pixels. On the other hand, using 10 m × 10 m spatial resolution Sentinel 2 images would reduce the number of mixed pixels, and thus the estimation error of PVC due to mixed pixels. Compared with Landsat images, however, using Sentinel 2 images would result in a nine-fold increase of data and computation intensity. This indicates a trade-off. China has a desertification land area of about 4,354,800 km2. Annually providing the decision-makers with information related to land desertification dynamics at the national scale is necessary. Because of the large area, limited budget, and requirement for fast acquisition and analysis of data, developing a cost-effective method to map PVC for the whole desertification area of China is critical. Various spatial resolution satellite images should be analyzed for their cost-effectiveness. This study could be regarded as a pilot study for a larger research project. In the future, a comparison of the uses of Landsat and Sentinel images in terms of accuracy and cost-effectiveness is needed.
5. Conclusions
To develop a cost-effective method to map PVC in the north and northwest arid and semi-arid area of China, a Landsat image-based endmember selection approach was first presented. Then, two probability-based spectral unmixing methods, PBSUA and PBOkNN, were proposed and compared with two LSU methods, with and without purification of endmembers, and two nonlinear methods, RF and RBFNN. The comparisons were conducted to improve the estimation accuracy of PVC in terms of mapping accuracy and cost-effectiveness in Duolun County, located in Inner Mongolia Autonomous Region, China, using Landsat 8 images and 920 sample plots. The study led to the following conclusions: (1) the proposed PBSUA was most cost-effective, followed by the two LSU methods, PBOkNN, RF, and RBFNN, but the two LSU methods led to significant underestimations; (2) the accuracy of mapping PVC using PBSUA was only slightly lower than those using RF and RBFNN, but significantly higher than that using PBOkNN; (3) the PBSUA, PBOkNN, RF, and RBFNN methods resulted in significantly higher estimation accuracies than two LSU methods; (4) the PBSUA, PBOkNN, RF, and RBFNN methods produced average estimates of the sample plots and the predicted maps that fell within the confidence interval of the test plot data, but the two LSU methods did not; and (5) the LSU method with purification of endmembers greatly improved the PVC estimation accuracy compared with the LSU method without purification of endmembers. These findings imply that a cost-effective method should be characterized by the capacity to handle both linear and nonlinear relationships of PVC with spectral variables, and spatial dependency and heterogeneity, with the requirement of few or no field samples. Among the compared methods, the proposed PBSUA method possesses these characteristics, and thus is appropriate for cost-effectively mapping PVC for the arid and semi-arid areas of northern and northwestern China.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}