Building Footprint Extraction from Multispectral, Spaceborne Earth Observation Datasets Using a Structurally Optimized U-Net Convolutional Neural Network


Abstract
:
1. Introduction
2. State-of-the-Art in Building Footprint Extraction
- The solution in [20] employs in-place activated batch normalization, which can save up to 50% of GPU memory. Their network achieves very good results, thanks also to the post-processing step based on watershed transform. However, even with in-place activated batch normalization, the proposed solution is expensive in terms of GPU memory. Indeed, the authors used a 4 GTX 1080-Ti to run it on a batch size of 20. Furthermore, the proposed network is relatively slow: to process 10 samples, it takes 1 s.
- In [21], the authors developed a network that can reliably detect buildings of different sizes, even the smallest ones. However, this result is achieved introducing a notable complexity, which includes four different branches plus a post-processing step. Furthermore, the network is designed to use RGB data, whereas it is proven [31] that higher-dimensional data can achieve better levels in terms of final accuracy.
- In [22], building boundaries are determined accurately thanks to the distance transform, and the authors achieved good overall accuracy, thanks also to three different U-Net architectures. However, their results are good only on larger building, whereas smaller buildings are detected poorly. Good results are achieved only after setting a minimum area—below which buildings are neglected—of 120 pixels for Las Vegas and 180 pixels for Paris, Shanghai, and Khartoum, while for the SpaceNet competition, the minimum area was of 20 pixels.
- Finally, in [30], the proposed networks achieved good results, although not optimal in some cases. Whereas the presence of buildings works well, issues are encountered with the identification of boundaries. The authors indeed plan to integrate distance transform, which is known to mitigate this problem. Our proposed approach can better identify the boundaries of detected buildings, generally.
3. The Dataset Used
4. The Proposed Method
4.1. Pre-Processing of Input Data
4.2. Architecture
5. Results
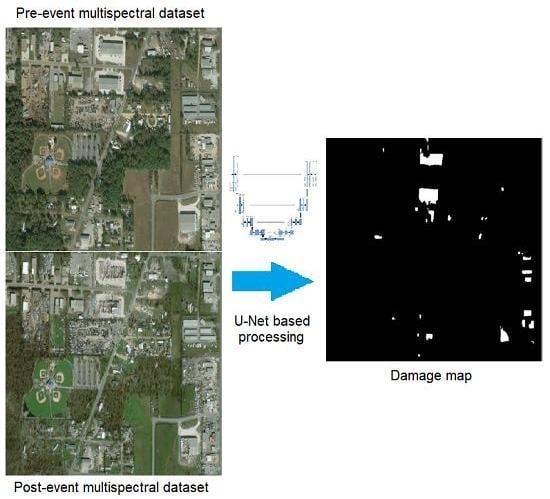
6. Application to Damage Mapping
- Validation loss (binary cross-entropy): 0.1122…
- Validation accuracy (IoU): 0.7001…
- Las Vegas: 0.772,
- Paris: 0.664,
- Shanghai: 0.622,
- Khartoum: 0.55,
- Rio de Janeiro: 0.489.
- Look for all zero-valued pixels in the final map. For each of them, check the corresponding pixels in the pre- and post-event masks. If both equal one, then there exists an intact building that disappeared in the final map (Figure 13), as it should. This occurrence is recorded and used in the next step.
- At this stage, set to zero a contour of pixels around the recorded intact building.
7. Conclusions and Way Forward
- try and apply in-place activated batch normalization to further reduce GPU memory consumption and thus apply other techniques.
- The current system was trained on a set of urban sites that are representative of different contexts across the globe but are still too few in number to make the system usable in any context. Given the high cost of VHR multispectral data and the limited availability of ground truth (GT) information, one identified research line is the determination of a minimum set of training sites to ensure satisfactory performances in a broad range of different local contexts. The performances on new sites are expected to improve when adding new items to the training set, until they plateau when a sufficiently diverse training set has been achieved. A full investigation of whether this really happens, and under what terms, is certainly due.
- Many cases were observed in which the system provided a building map not exactly matching the GT, but visually comparing the apparently incorrect portion of the output with the underlying true color image revealed that the mistake was in the GT rather than in the network output. This may happen because the GT map, generally obtained by visual inspection, is subject to human error due to fatigue or lack of attention to details. Starting from this remark, another challenging research line is an investigation of the possible creation of a second CNN specifically designed to identify mistakes in GT by analyzing the underlying multispectral data in areas where the output map does not match the GT. Where appropriate, the network should raise a flag suggesting further visual inspection and possible correction of the ground truth. Our tests have shown that incorrect GT boundaries come with typical trends in the building recognition network before thresholding, and this will be the starting point for our investigation.
- In the context of post-disaster assessment, when the timely delivery of information is critical, the earliest post-disaster image is often used even when its resolution and incidence angle is not homogeneous with the nearest pre-event one. In Section 6, an ad hoc solution is developed specifically for a slight mismatch in incidence angles, but the solution should be made more general if the method is to be robust to wider angle differences. Systematic orthorectification is not always feasible, especially in remote areas where an accurate DSM may not be available. A specific research line will investigate the possibility of training the network directly on multi-angle images to accommodate possible differences in viewing angles.
- Specifically in terms of resolution, another investigation should be conducted made into the impact of the spatial resolution of input data on system performance and whether training and processing of data whose geometric resolution has been altered by up- or down-sampling is still effective.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ostankovich, V.; Afanasyev, I. Illegal Buildings Detection from Satellite Images using GoogLeNet and Cadastral Map. In Proceedings of the 2018 International Conference on Intelligent Systems (IS), Funchal-Madeira, Portugal, 25–27 September 2018; pp. 616–623. [Google Scholar] [CrossRef]
- Ural, S.; Hussain, E.; Shan, J. Building population mapping with aerial imagery and GIS data. Int. J. Appl. Earth Obs. Geoinf. 2011, 13, 841–852. [Google Scholar] [CrossRef]
- Chesnel, A.; Binet, R.; Wald, L. Object Oriented Assessment of Damage Due to Natural Disaster Using Very High Resolution Images. In Proceedings of the 2007 IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–27 July 2007; pp. 3736–3739. [Google Scholar] [CrossRef]
- Brunner, D.; Lemoine, G.; Bruzzone, L. Earthquake Damage Assessment of Buildings Using VHR Optical and SAR Imagery. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2403–2420. [Google Scholar] [CrossRef]
- Kim, T.; Muller, J.P. Development of a graph-based approach for building detection. Image Vis. Comput. 1999, 17, 3–14. [Google Scholar] [CrossRef]
- Müller, S.; Zaum, D.W. Robust building detection in aerial images. Int. Arch. Photogramm. Remote Sens. 2005, 36, 143–148. [Google Scholar]
- Sirmacek, B.; Unsalan, C. Building detection from aerial images using invariant color features and shadow information. In Proceedings of the 2008 23rd International Symposium on Computer and Information Sciences, Istanbul, Turkey, 27–29 October 2008; pp. 1–5. [Google Scholar] [CrossRef]
- Sirmacek, B.; Unsalan, C. Urban-Area and Building Detection Using SIFT Keypoints and Graph Theory. IEEE Trans. Geosci. Remote Sens. 2009, 47, 1156–1167. [Google Scholar] [CrossRef]
- Gui, R.; Xu, X.; Dong, H.; Song, C.; Pu, F. Individual Building Extraction from TerraSAR-X Images Based on Ontological Semantic Analysis. Remote Sens. 2016, 8, 708. [Google Scholar] [CrossRef]
- Ferro, A.; Brunner, D.; Bruzzone, L. Automatic Detection and Reconstruction of Building Radar Footprints From Single VHR SAR Images. IEEE Trans. Geosci. Remote Sens. 2013, 51, 935–952. [Google Scholar] [CrossRef]
- Ciecholewski, M. River channel segmentation in polarimetric SAR images: Watershed transform combined with average contrast maximisation. Expert Syst. Appl. 2017, 82, 196–215. [Google Scholar] [CrossRef]
- Lang, F.; Yang, J.; Yan, S.; Qin, F. Superpixel Segmentation of Polarimetric Synthetic Aperture Radar (SAR) Images Based on Generalized Mean Shift. Remote Sens. 2018, 10, 1592. [Google Scholar] [CrossRef]
- Wieland, M.; Liu, W.; Yamazaki, F. Learning Change from Synthetic Aperture Radar Images: Performance Evaluation of a Support Vector Machine to Detect Earthquake and Tsunami-Induced Changes. Remote Sens. 2016, 8, 792. [Google Scholar] [CrossRef]
- Yamazaki, F.; Liu, W.; Kojima, S. Use of airborne sar imagery to extract earthquake damage in urban areas. In Proceedings of the Eleventh U.S. National Conference on Earthquake Engineering Integrating Science, Engineering & Policy, Los Angeles, CA, USA, 25–29 June 2018. [Google Scholar]
- Uprety, P.; Yamazaki, F.; Dell’Acqua, F. Damage Detection Using High-Resolution SAR Imagery in the 2009 L’Aquila, Italy, Earthquake. Earthq. Spectra 2013, 29, 1521–1535. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- National Centers for Environmental Information, National Oceanic and Atmospheric Administration. Available online: https://www.ncei.noaa.gov/news/national-climate-201812 (accessed on 20 August 2019).
- Tomasi, C.; Manduchi, R. Bilateral filtering for gray and color images. In Proceedings of the Sixth International Conference on Computer Vision (IEEE Cat. No.98CH36271), Bombay, India, 7 January 1998; pp. 839–846. [Google Scholar] [CrossRef]
- Chaudhuri, D.; Kushwaha, N.K.; Samal, A.; Agarwal, R.C. Automatic Building Detection From High-Resolution Satellite Images Based on Morphology and Internal Gray Variance. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1767–1779. [Google Scholar] [CrossRef]
- Iglovikov, V.; Seferbekov, S.; Buslaev, A.; Shvets, A. TernausNetV2: Fully Convolutional Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 228–2284. [Google Scholar] [CrossRef]
- Hamaguchi, R.; Hikosaka, S. Building Detection from Satellite Imagery using Ensemble of Size-Specific Detectors. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 223–2234. [Google Scholar] [CrossRef]
- Prathap, G.; Afanasyev, I. Deep Learning Approach for Building Detection in Satellite Multispectral Imagery. In Proceedings of the 2018 International Conference on Intelligent Systems (IS), Funchal-Madeira, Portugal, 25–27 September 2018; pp. 461–465. [Google Scholar] [CrossRef]
- Andreoni, A.; Dell’Acqua, F.; Freddi, R. A Novel Technique for Building Roof Mapping in Very-High-Resolution Multispectral Satellite Data. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1256–1259. [Google Scholar] [CrossRef]
- Etten, A.V.; Lindenbaum, D.; Bacastow, T.M. SpaceNet: A Remote Sensing Dataset and Challenge Series. arXiv 2018, arXiv:1807.01232. [Google Scholar]
- Bulò, S.R.; Porzi, L.; Kontschieder, P. In-place Activated BatchNorm for Memory-Optimized Training of DNNs. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5639–5647. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Neiva, M.B.; Manzanera, A.; Bruno, O.M. Binary Distance Transform to Improve Feature Extraction. arXiv 2016, arXiv:1612.06443. [Google Scholar]
- Chhor, G.; Aramburu, C.B. Satellite Image Segmentation for Building Detection Using U-Net; Stanford University Internal Report; Stanford University: Stanford, CA, USA, 2017. [Google Scholar]
- Winning Solution for the Spacenet Challenge: Joint Learning with OpenStreetMap. Available online: https://i.ho.lc/winning-solution-for-the-spacenet-challenge-joint-learning-with-openstreetmap.html (accessed on 15 September 2019).
- Bischke, B.; Helber, P.; Folz, J.; Borth, D.; Dengel, A. Multi-Task Learning for Segmentation of Building Footprints with Deep Neural Networks. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1480–1484. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Open Data AWS. Available online: https://registry.opendata.aws (accessed on 12 September 2019).
- DigitalGlobe. Available online: https://www.digitalglobe.com/ecosystem/open-data (accessed on 17 September 2019).
- National Weather Service, National Oceanic and Atmospheric Administration. Available online: https://www.weather.gov/tae/HurricaneMichael2018 (accessed on 5 October 2019).
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Keras Documentation. Available online: https://keras.io/callbacks/ (accessed on 17 August 2019).
- SpaceNet Challenge Utilities on Github. Available online: https://github.com/SpaceNetChallenge/utilities/blob/master/python/evaluateScene.py (accessed on 7 September 2019).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methodology | References |
|---|---|
| Ensemble of models | [22,31] |
| Distance transforms | [22,32] |
| Incorporation of OpenStreetMap data | [22,31] |
| Rank | Author | Las Vegas | Paris | Shanghai | Khartoum | Total Score | Rio de Janeiro |
|---|---|---|---|---|---|---|---|
| 1 | wleite | 0.255 | |||||
| 2 | marek.cygan | 0.249 | |||||
| 3 | qinhaifang | 0.255 | |||||
| 1 | XD_XD | 0.89 | 0.75 | 0.6 | 0.54 | 0.69 | |
| 2 | wleite | 0.83 | 0.68 | 0.58 | 0.48 | 0.64 | |
| 3 | nofto | 0.79 | 0.58 | 0.52 | 0.42 | 0.58 | |
| proposed model | 0.805 | 0.681 | 0.648 | 0.597 | 0.683 | 0.518 | |
| IoU evaluation | 0.793 | 0.743 | 0.691 | 0.657 | 0.7 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pasquali, G.; Iannelli, G.C.; Dell’Acqua, F. Building Footprint Extraction from Multispectral, Spaceborne Earth Observation Datasets Using a Structurally Optimized U-Net Convolutional Neural Network. Remote Sens. 2019, 11, 2803. https://doi.org/10.3390/rs11232803
Pasquali G, Iannelli GC, Dell’Acqua F. Building Footprint Extraction from Multispectral, Spaceborne Earth Observation Datasets Using a Structurally Optimized U-Net Convolutional Neural Network. Remote Sensing. 2019; 11(23):2803. https://doi.org/10.3390/rs11232803
Chicago/Turabian StylePasquali, Giorgio, Gianni Cristian Iannelli, and Fabio Dell’Acqua. 2019. "Building Footprint Extraction from Multispectral, Spaceborne Earth Observation Datasets Using a Structurally Optimized U-Net Convolutional Neural Network" Remote Sensing 11, no. 23: 2803. https://doi.org/10.3390/rs11232803