
Air Pollution Prediction Based on Discrete Wavelets and Deep Learning

Abstract
:1. Introduction
- A feature extraction module is proposed which could extract the time–frequency characteristics and local features of the original data, thus achieving multivariate prediction and achieving better results than univariate prediction superposition.
- A multivariate prediction model named DW-CAE is proposed. The multivariate prediction takes into account the overall prediction accuracy of multiple pollutants and the prediction accuracy of each pollutant which is a significant improvement compared to the based models.
2. Related Work
2.1. Traditional Statistical Models
2.2. Machine Learning Methods
2.3. Deep Learning Models
3. Materials and Methods
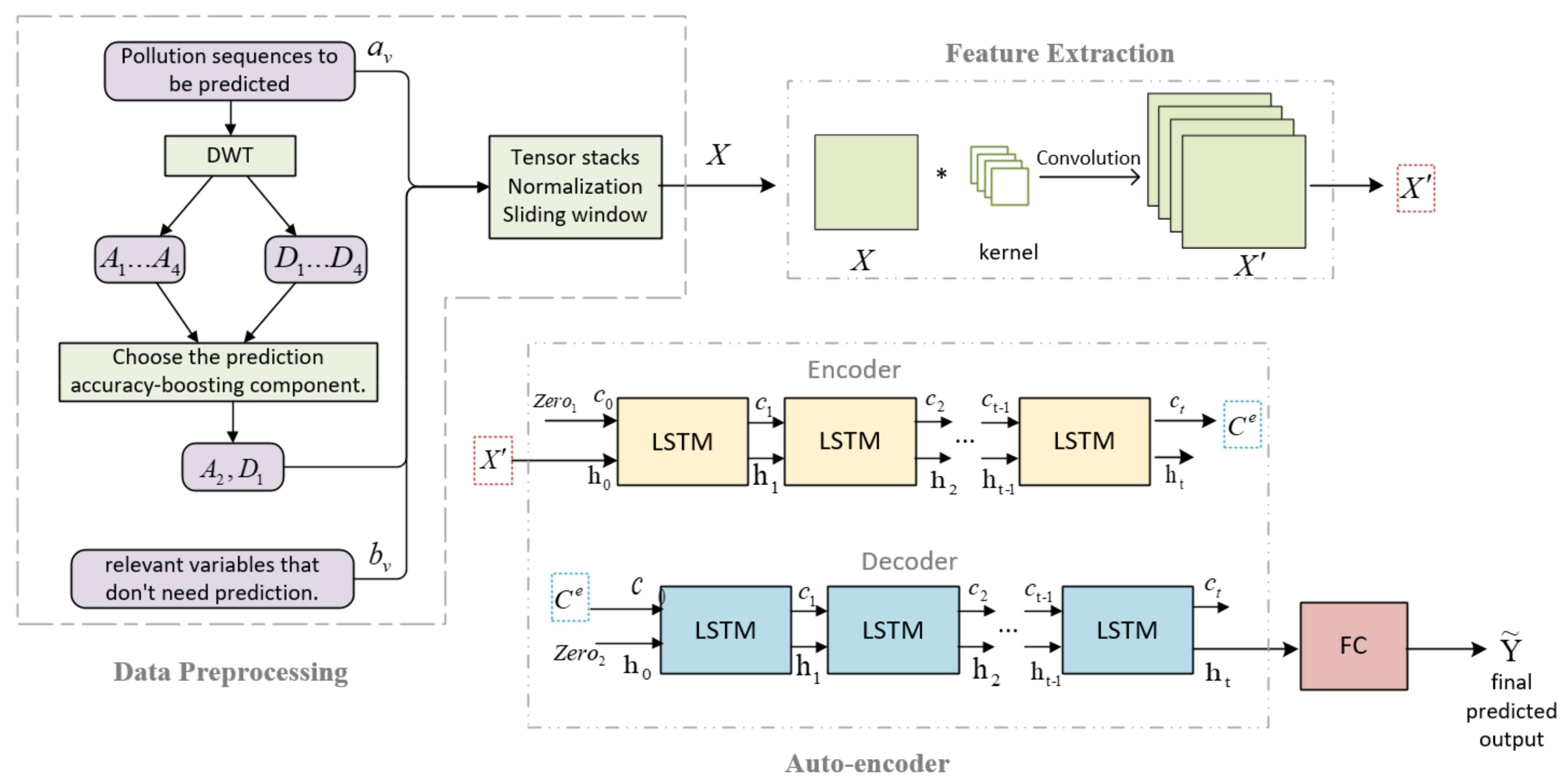
3.1. Data Preprocessing
3.1.1. Outlier and Missing Data Processing
3.1.2. Sequence Decomposition
3.1.3. Sequence Integration
3.2. Data Forecasting
3.2.1. Feature Extraction Module
3.2.2. Auto-Encoder Module
4. Experiment and Discussion
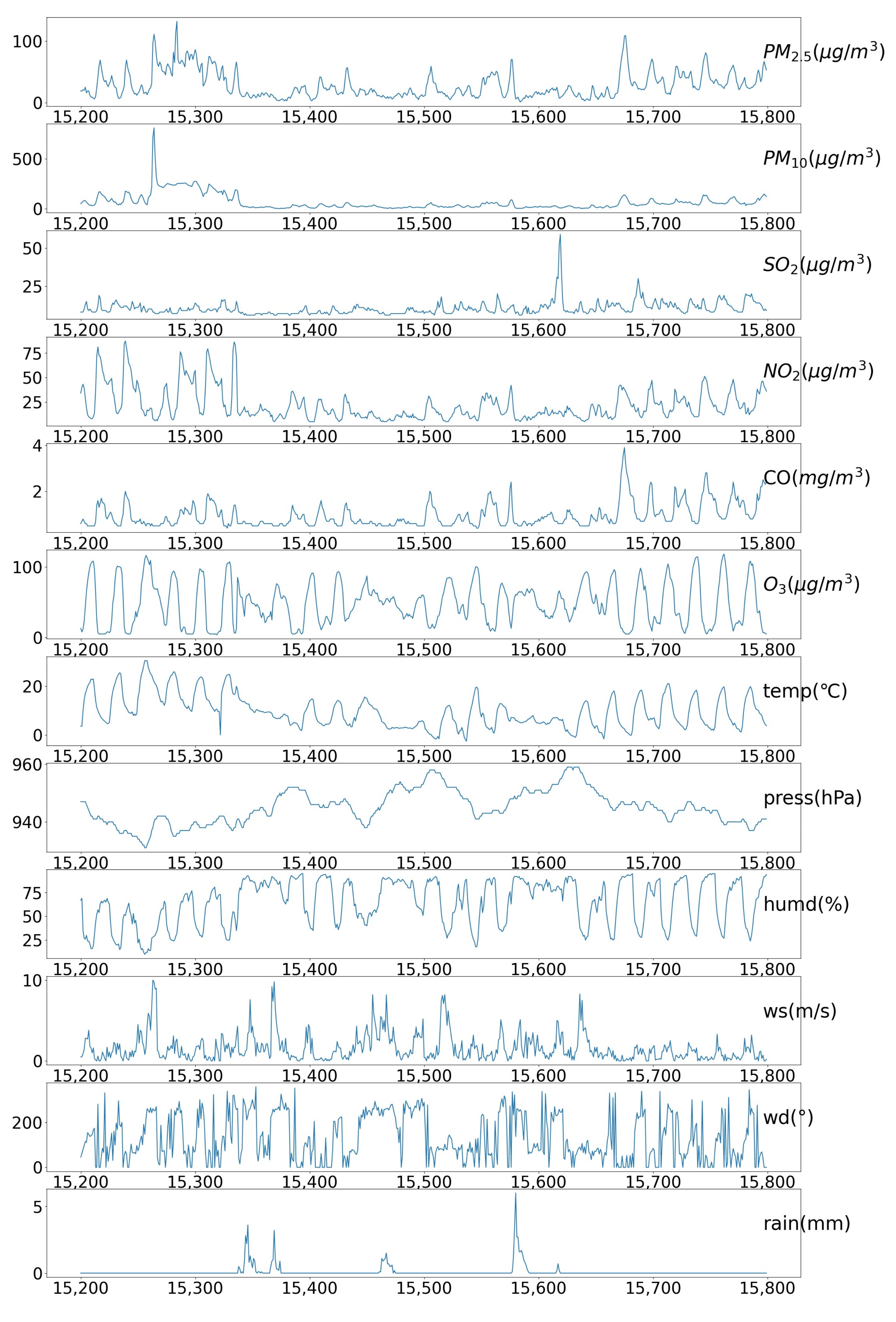
4.1. Data Sets
4.2. Performance Evaluation
4.3. Experimental Parameter Setting
- (1)
- The LSTM model [34] with LSTM and a full connection layer was chosen. The number of LSTM neurons was chosen from 16, 64, and 128, and 64 is the best. The batch size was chosen between 64, 128, and 256, where 128 is optimal. The learning rate was chosen between 0.01 and 0.001, where 0.001 is optimal.
- (2)
- The structure of the bi-directional LSTM model [35] was composed of Bi-LSTM and a full connection layer. The number of LSTM neurons was chosen from 16, 64, and 128, and 128 is the best. The batch size was chosen between 64, 128, and 256, where 128 is optimal. The learning rate was chosen between 0.01 and 0.001, where 0.001 is optimal.
- (3)
- The same LSTM structure is used in both the encoder and decoder in the auto-encoder model [36], selected from one or two layers, unidirectional or bidirectional, with 16, 64, or 128 neurons, respectively, and batch size is selected from 64, 128, or 256. Following testing, the single-layer bidirectional neuron number 128 is determined to have the best structure, and batch size = 128 is chosen.
- (4)
- In the Conv-AE model, the input data are passed through a 2D convolutional layer with filters of 64, a convolutional kernel size of 4, and a step size of 1. The extracted feature values are fed into the above autoencoder.
- (1)
- IMV-Full and IMV-Tensor [37] are two versions of the LSTM that improve the way the hidden state matrix is updated by making each element of the hidden matrix hold information from only one of the input variables.
- (2)
- DA-RNN [18] is a Transformer model that uses an attention mechanism at both the encoder and decoder stages, using an attention to adaptively extract features at each moment before the encoder and using an attention mechanism to select the encoder state associated with it before the decoder.
- (3)
- Multistage Attention [38] also uses a Transformer model with two-stage attention, using multi-stage attention to extract features and input them into a variant encoder structure of TG-LSTM, with the decoder being an LSTM structure incorporating an attention mechanism capable of adaptively selecting the relevant time steps to be used for prediction.
4.4. Decomposition Sequence Selection
4.5. Comparison of Results
4.5.1. Univariate Forecasting
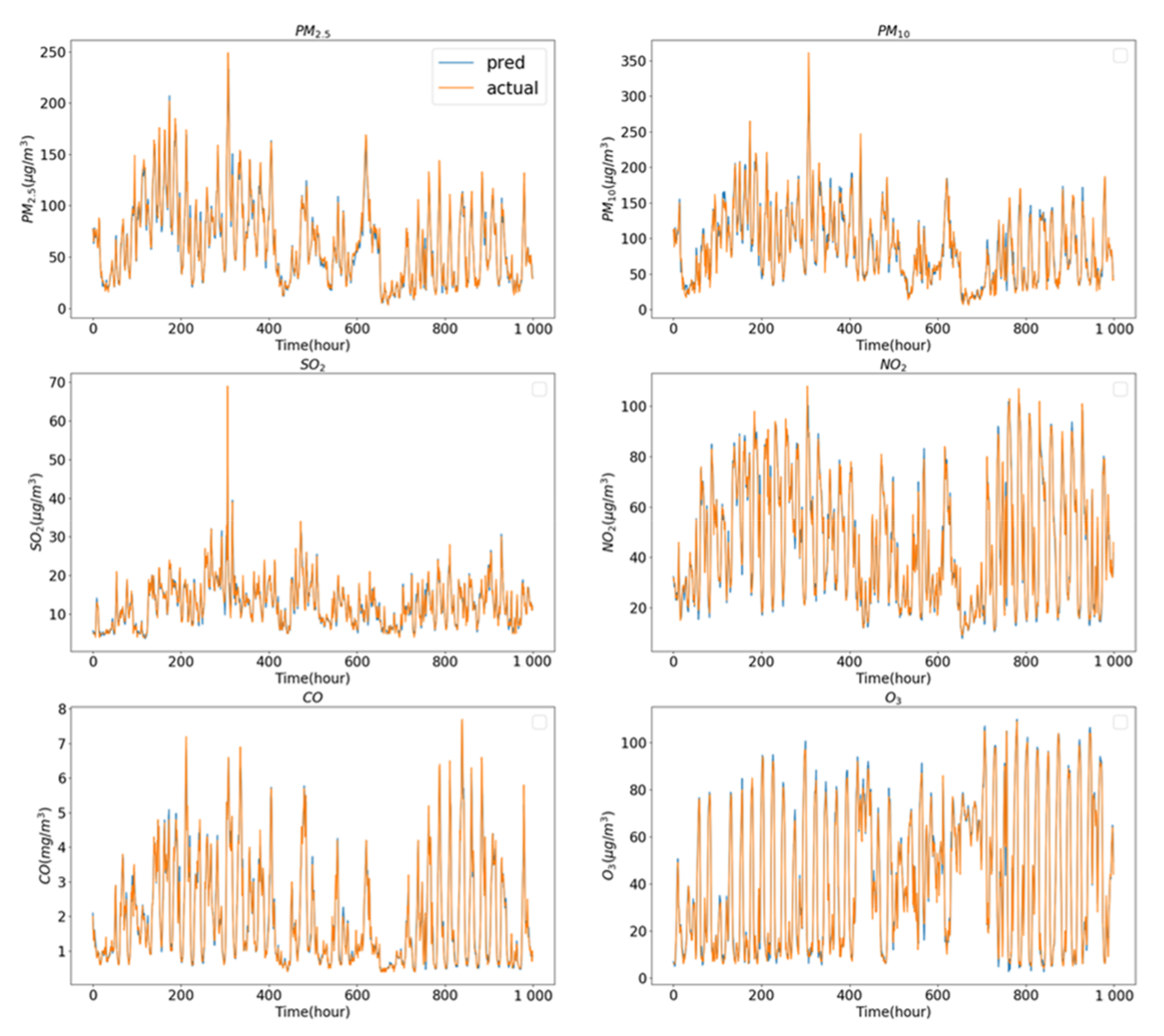
4.5.2. Multivariate Forecasting
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ariyo, A.A.; Adewumi, A.O.; Ayo, C.K. Stock Price Prediction Using the ARIMA Model. In Proceedings of the 2014 UKSim-AMSS 16th International Conference on Computer Modelling and Simulation, Cambridge, UK, 26–28 March 2014. [Google Scholar]
- Everette, G. Exponential smoothing: The state of the art. J. Forecast. 1985, 4, 1–28. [Google Scholar] [CrossRef]
- Harvey, A.C. Forecasting, Structural Time Series Models and the Kalman Filter; Cambridge University Press: Cambridge, UK, 1990; pp. 100–167. [Google Scholar] [CrossRef]
- Siew, L.Y.; Chin, L.Y.; Mah, P.; Jin, W. ARIMA and integrated ARFIMA models for forecasting air pollution index in Shah Alam, Selangor. Malays. J. Anal. Sci. 2008, 12, 257–263. [Google Scholar]
- Jie, Z. Comparison of ARIMA Model and Exponential Smoothing Model on 2014 Air Quality Index in Yanqing County, Beijing, China. Appl. Comput. Math. 2015, 4, 456–461. [Google Scholar] [CrossRef]
- Elsayed, S.; Thyssens, D.; Rashed, A.; Schmidt-Thieme, L.; Jomaa, H.S. Do We Really Need Deep Learning Models for Time Series Forecasting? arXiv 2021. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Liu, H.; Wu, H.; Lv, X.; Ren, Z.; Shi, H. An Intelligent Hybrid Model for Air Pollutant Concentrations Forecasting: Case of Beijing in China. Sustain. Cities Soc. 2019, 47, 101471. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Sun, W.; Sun, J. Daily PM2.5 concentration prediction based on principal component analysis and LSSVM optimized by cuckoo search algorithm. J. Environ. Manag. 2017, 188, 144–152. [Google Scholar] [CrossRef]
- Rzangapuram, S.S.; Seeger, M.W.; Gasthaus, J.; Stella, L.; Wang, Y.; Januschowski, T. Deep State Space Models for Time Series Forecasting. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Neural Information Processing Systems (NIPS): Montreal, QC, Canada, 2018; pp. 7796–7805. [Google Scholar]
- Flunkert, V.; Salinas, D.; Gasthaus, J. DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks. Int. J. Forecast. 2020, 36, 1181–1191. [Google Scholar] [CrossRef]
- Saravanan, D.; Kumar, K.S. Improving air pollution detection accuracy and quality monitoring based on bidirectional RNN and the Internet of Things. Mater. Today Proc. 2021, in press. [Google Scholar] [CrossRef]
- Dua, R.D.; Madaan, D.M.; Mukherjee, P.M.; Lall, B.L. Real time attention based bidirectional long short-term memory networks for air pollution forecasting. In Proceedings of the 2019 IEEE fifth international conference on Big Data computing service and applications (BigDataService), Newark, CA, USA, 4–9 April 2019; pp. 151–158. [Google Scholar]
- Liu, D.R.; Lee, S.J.; Huang, Y.; Chiu, C.J. Air pollution forecasting based on attention-based LSTM neural network and ensemble learning. Expert Syst. 2020, 37, e12511. [Google Scholar] [CrossRef]
- Ma, J.; Li, Z.; Cheng, J.C.; Ding, Y.; Lin, C.; Xu, Z. Air quality prediction at new stations using spatially transferred bi-directional long short-term memory network. Sci. Total Environ. 2020, 705, 135771. [Google Scholar] [CrossRef]
- Hu, J.; Zheng, W. Transformation-gated LSTM: Efficient capture of short-term mutation dependencies for multivariate time series prediction tasks. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019. [Google Scholar]
- Yao, Q.; Song, D.; Chen, H.; Wei, C.; Cottrell, G.W. A Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction. arXiv 2017, arXiv:1704.02971. [Google Scholar]
- Qin, D.; Yu, J.; Zou, G.; Yong, R.; Zhao, Q.; Zhang, B. A novel combined prediction scheme based on CNN and LSTM for urban PM2.5 concentration. IEEE Access 2019, 7, 20050–20059. [Google Scholar] [CrossRef]
- Wu, Z.; Wang, Y.; Zhang, L. MSSTN: Multi-Scale Spatial Temporal Network for Air Pollution Prediction. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019. [Google Scholar]
- Chang, Y.Y.; Sun, F.Y.; Wu, Y.H.; Lin, S.D. A memory-network based solution for multivariate time-series forecasting. arXiv 2018, arXiv:1809.02105. [Google Scholar] [CrossRef]
- Jin, X.-B.; Yang, N.-X.; Wang, X.-Y.; Bai, Y.-T.; Su, T.-L.; Kong, J.-L. Deep Hybrid Model Based on EMD with Classification by Frequency Characteristics for Long-Term Air Quality Prediction. Mathematics 2020, 8, 214. [Google Scholar] [CrossRef]
- Zeng, C.; Ma, C.; Wang, K.; Cui, Z. Predicting vacant parking space availability: A DWT-Bi-LSTM model. Phys. A Stat. Mech. Its Appl. 2022, 599, 127498. [Google Scholar] [CrossRef]
- Wang, P.; Zhang, G.; Chen, F.; He, Y. A hybrid-wavelet model applied for forecasting PM 2.5 concentrations in Taiyuan city, China. Atmos. Pollut. Res. 2019, 10, 1884–1894. [Google Scholar] [CrossRef]
- Livieris, I.E.; Pintelas, E.; Pintelas, P. A CNN–LSTM model for gold price time-series forecasting. Neural Comput. Appl. 2020, 32, 17351–17360. [Google Scholar] [CrossRef]
- Kirisci, M.; Cagcag Yolcu, O. A New CNN-Based Model for Financial Time Series: TAIEX and FTSE Stocks Forecasting. Neural Process. Lett. 2022, 54, 3357–3374. [Google Scholar] [CrossRef]
- Mehtab, S.; Sen, J. Analysis and forecasting of financial time series using CNN and LSTM-based deep learning models. In Proceedings of the Advances in Distributed Computing and Machine Learning, ICADCML 2021, Bhubaneswar, India, 15–16 January 2021; pp. 405–423. [Google Scholar]
- Bai, Y.; Zeng, B.; Li, C.; Zhang, J. An ensemble long short-term memory neural network for hourly PM2.5 concentration forecasting. Chemosphere 2019, 222, 286–294. [Google Scholar] [CrossRef] [PubMed]
- Liang, X.; Zou, T.; Guo, B.; Li, S.; Zhang, H.; Zhang, S.; Huang, H.; Chen, S.X. Assessing Beijing’s PM2.5 pollution: Severity, weather impact, APEC and winter heating. Proc. R. Soc. A Math. Phys. Eng. Sci. 2015, 471, 20150257. [Google Scholar] [CrossRef]
- UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml/datasets/Beijing+PM2.5+Data (accessed on 18 April 2023).
- National Air Quality Release Platform. Available online: https://air.cnemc.cn:18007/ (accessed on 18 April 2023).
- Central Meteorological Station. Available online: http://www.nmc.cn/ (accessed on 18 April 2023).
- Dou, Z.; Sun, Y.; Zhang, Y. Regional manufacturing industry demand forecasting: A deep learning approach. Appl. Sci. 2021, 11, 6199. [Google Scholar] [CrossRef]
- Li, X.; Peng, L.; Yao, X.; Cui, S.; Hu, Y.; You, C.; Chi, T. Long short-term memory neural network for air pollutant concentration predictions: Method development and evaluation. Environ. Pollut. 2017, 231, 997–1004. [Google Scholar] [CrossRef]
- Liu, B.; Yu, Z.; Wang, Q.; Du, P.; Zhang, X. Prediction of SSE Shanghai Enterprises index based on bidirectional LSTM model of air pollutants. Expert Syst. Appl. 2022, 204, 117600. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, H.; Zhao, G.; Lian, J. Constructing a PM2.5 concentration prediction model by combining auto-encoder with Bi-LSTM neural networks. Environ. Model. Softw. 2020, 124, 104600. [Google Scholar] [CrossRef]
- Guo, T.; Lin, T.; Antulov-Fantulin, N. Exploring interpretable lstm neural networks over multi-variable data. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 2494–2504. [Google Scholar]
- Hu, J.; Zheng, W. Multistage attention network for multivariate time series prediction. Neurocomputing 2020, 383, 122–137. [Google Scholar] [CrossRef]
- Announcement on Emergency Response for Heavy Polluted Weather on the Official Website of the People’s Government of Yining City, Xinjiang Province. Available online: http://www.xjyn.gov.cn/xjyn/c113637/202101/7c7973e90df04e258f7e25cb0970-4993.shtml (accessed on 18 April 2023).
- Li, Y.; Zeng, I.Y.; Niu, Z. Predicting vehicle fuel consumption based on multi-view deep neural network. Neurocomputing 2022, 502, 140–147. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Factor | Dataset | Improvement Than LSTM | Performance (RMSE) |
|---|---|---|---|---|
| BiLSTM-A [14] | , , | CPCB (Indian) | 10.18%, 6.42%, and 8.04% | 37.69, 90.38, and 19.79 |
| WALSTM [15] | EPA data | 2.82% | 11.39 | |
| TLS-BLSTM [16] | , , | collected in Anhui | 33.25%, 22.32%, and 26.96% | 7.96, 8.51, and 8.00 |
| TG-LSTM [17] | Beijing dataset | 63.08% | 4.82 | |
| DA-RNN [18] | Beijing dataset | (GRU *) 63.41% | 42.07 | |
| MTNet [21] | Beijing dataset | (GRU *) 66.50% | 38.52 | |
| CNN-LSTM [19] | collected Shanghai data | 20.33% | 14.30 | |
| MSSTN [20] | Urban Air Pollution Datasets in North China | 11.66% | 11.29 | |
| EMDCNN_GRU [22] | beijing data in stateair | 29.29% | 46.26 |
| Batch Size | Learning Rate | Filter | Kernel Size | Strider | Hidden Size |
|---|---|---|---|---|---|
| 64 | 0.001 | 128 | 4 | 1 | 128 |
| Wavelet Basis Functions | Wavelet Basis Functions | ||
|---|---|---|---|
| db2 | 0.9795 | sym2 | 0.9784 |
| db3 | 0.9842 | sym3 | 0.9850 |
| db4 | 0.9877 | sym4 | 0.9863 |
| db5 | 0.9899 | sym5 | 0.9897 |
| db6 | 0.9914 | sym6 | 0.9903 |
| db7 | 0.9919 | sym7 | 0.9929 |
| db8 | 0.9931 | sym8 | 0.9917 |
| db9 | 0.9932 | sym9 | 0.9927 |
| Low Frequency Component | High Frequency Component | ||
|---|---|---|---|
| 0.9754 | 0.9701 | ||
| 0.9785 | 0.9454 | ||
| 0.9641 | 0.9377 | ||
| 0.9476 | 0.9393 |
| Model Name | MSE | MAE | |
|---|---|---|---|
| LSTM [34] | 572.4357 | 14.8971 | 0.9077 |
| Bi-LSTM [35] | 549.3633 | 14.3893 | 0.9115 |
| Auto-encoder [36] | 545.6932 | 14.0922 | 0.9121 |
| Conv-AE | 524.1656 | 11.5053 | 0.9155 |
| IMV_Full [37] | 456.6853 | 11.1016 | 0.9264 |
| IMV_Tensor [37] | 475.2328 | 11.7472 | 0.9234 |
| DA-RNN [18] | 463.4121 | 11.8116 | 0.9253 |
| Multistage Attention [38] | 479.1348 | 12.2256 | 0.9228 |
| DW-CAE (ours) | 35.3004 | 3.6327 | 0.9943 |
| Model Name | MSE | MAE | |
|---|---|---|---|
| LSTM [34] | 40.1417 | 4.2279 | 0.9599 |
| Bi-LSTM [35] | 42.5767 | 4.3007 | 0.9576 |
| Auto-encoder [36] | 38.7649 | 4.1696 | 0.9614 |
| Conv-AE | 41.9782 | 4.2617 | 0.9582 |
| IMV_Full [37] | 38.4223 | 4.0865 | 0.9617 |
| IMV_Tensor [37] | 38.9129 | 4.1865 | 0.9612 |
| DA-RNN [18] | 32.6569 | 3.9665 | 0.9674 |
| Multistage Attention [38] | 28.7293 | 3.6801 | 0.9713 |
| DW-CAE (ours) | 23.2173 | 3.3651 | 0.9768 |
| Model Name | R2_avg | CO | ||||||
|---|---|---|---|---|---|---|---|---|
| LSTM [34] | 0.7658 | MSE | 134.5532 | 733.8629 | 8.0147 | 106.5783 | 0.1982 | 185.7386 |
| MAE | 8.0372 | 17.1066 | 1.9419 | 7.1280 | 0.2499 | 10.4623 | ||
| 0.8661 | 0.6882 | 0.6432 | 0.7530 | 0.8241 | 0.8205 | |||
| Bi-LSTM [35] | 0.7727 | MSE | 129.5385 | 677.9788 | 8.3106 | 102.8892 | 0.1852 | 180.0635 |
| MAE | 8.4016 | 15.4027 | 1.9188 | 7.1539 | 0.2429 | 10.0684 | ||
| 0.8710 | 0.7119 | 0.6301 | 0.7615 | 0.8356 | 0.8259 | |||
| Auto-encoder [36] | 0.7724 | MSE | 109.4557 | 711.7048 | 8.4911 | 101.9029 | 0.1906 | 176.5992 |
| MAE | 7.0865 | 16.5308 | 2.1573 | 6.8780 | 0.2460 | 9.9542 | ||
| 0.8910 | 0.6976 | 0.6220 | 0.7638 | 0.8308 | 0.8293 | |||
| Conv-AE | 0.7490 | MSE | 147.1291 | 697.8124 | 7.8029 | 114.2672 | 0.1967 | 285.6826 |
| MAE | 8.6457 | 16.0268 | 1.9973 | 7.4610 | 0.2530 | 13.5946 | ||
| 0.8535 | 0.7035 | 0.6527 | 0.7352 | 0.8254 | 0.7238 | |||
| IMV_Full [37] | 0.7330 | MSE | 116.3191 | 832.8393 | 8.1901 | 89.6754 | 0.2186 | 158.2858 |
| MAE | 7.2308 | 18.0299 | 1.9100 | 6.6079 | 0.2823 | 9.3379 | ||
| 0.8546 | 0.4998 | 0.6423 | 0.7706 | 0.8008 | 0.8298 | |||
| IMV_Tensor [37] | 0.7449 | MSE | 119.2915 | 748.4123 | 7.5788 | 91.3709 | 0.1980 | 161.1032 |
| MAE | 7.3517 | 16.0682 | 1.9022 | 6.8400 | 0.2638 | 9.4964 | ||
| 0.8621 | 0.5737 | 0.6577 | 0.7479 | 0.8130 | 0.8151 | |||
| DA-RNN [18] | 0.8002 | MSE | 111.0254 | 939.5824 | 9.5175 | 42.9493 | 0.1148 | 62.8973 |
| MAE | 7.1288 | 18.6226 | 2.0695 | 4.5378 | 0.2263 | 5.9188 | ||
| 0.8892 | 0.6008 | 0.5743 | 0.9002 | 0.8975 | 0.9389 | |||
| Multistage Attention [38] | 0.8096 | MSE | 124.4401 | 817.1841 | 9.2226 | 41.8437 | 0.1144 | 61.2233 |
| MAE | 7.4535 | 16.9538 | 2.0737 | 4.5268 | 0.2234 | 5.7116 | ||
| 0.8759 | 0.6528 | 0.5875 | 0.9028 | 0.8979 | 0.9405 | |||
| DW-CAE (ours) | 0.9669 | MSE | 14.6259 | 144.8389 | 1.4094 | 9.8438 | 0.0242 | 15.3215 |
| MAE | 2.6152 | 7.8337 | 0.9072 | 2.2866 | 0.0956 | 2.9775 | ||
| 0.9854 | 0.9384 | 0.9369 | 0.9771 | 0.9783 | 0.9851 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shu, Y.; Ding, C.; Tao, L.; Hu, C.; Tie, Z. Air Pollution Prediction Based on Discrete Wavelets and Deep Learning. Sustainability 2023, 15, 7367. https://doi.org/10.3390/su15097367
Shu Y, Ding C, Tao L, Hu C, Tie Z. Air Pollution Prediction Based on Discrete Wavelets and Deep Learning. Sustainability. 2023; 15(9):7367. https://doi.org/10.3390/su15097367
Chicago/Turabian StyleShu, Ying, Chengfu Ding, Lingbing Tao, Chentao Hu, and Zhixin Tie. 2023. "Air Pollution Prediction Based on Discrete Wavelets and Deep Learning" Sustainability 15, no. 9: 7367. https://doi.org/10.3390/su15097367