
Spatio-Temporal Wind Speed Prediction Based on Improved Residual Shrinkage Network

Abstract
:1. Introduction
- (1)
- We propose a novel SDRSU for noise-containing wind speed data. The unit is capable of reducing the probability of neuron death, improving the nonlinear representation of the model, and alleviating the influence of noisy data.
- (2)
- We fuse the wind speed noise reduction module and the spatio-temporal feature extraction module into a deep network. This method can extract useful features from noisy data and reduce the influence of noise on wind speed prediction results. It also extracts the spatio-temporal features of wind speed data more effectively, which leads to more accurate and robust wind speed predictions.
- (3)
- We design four deep spatio-temporal wind speed prediction models under the same spatio-temporal architecture, namely ST-ResNet, ST-SResNet, ST-DRSN, and ST-SDRSN. To demonstrate the superiority of our proposed model ST-SDRSN, we analyze two independent datasets as well as conduct wind speed prediction experiments under various distributions of noise.
2. Problem Description
3. Proposed Model
3.1. Noise Processing Module
3.1.1. Residual Shrinkage Module
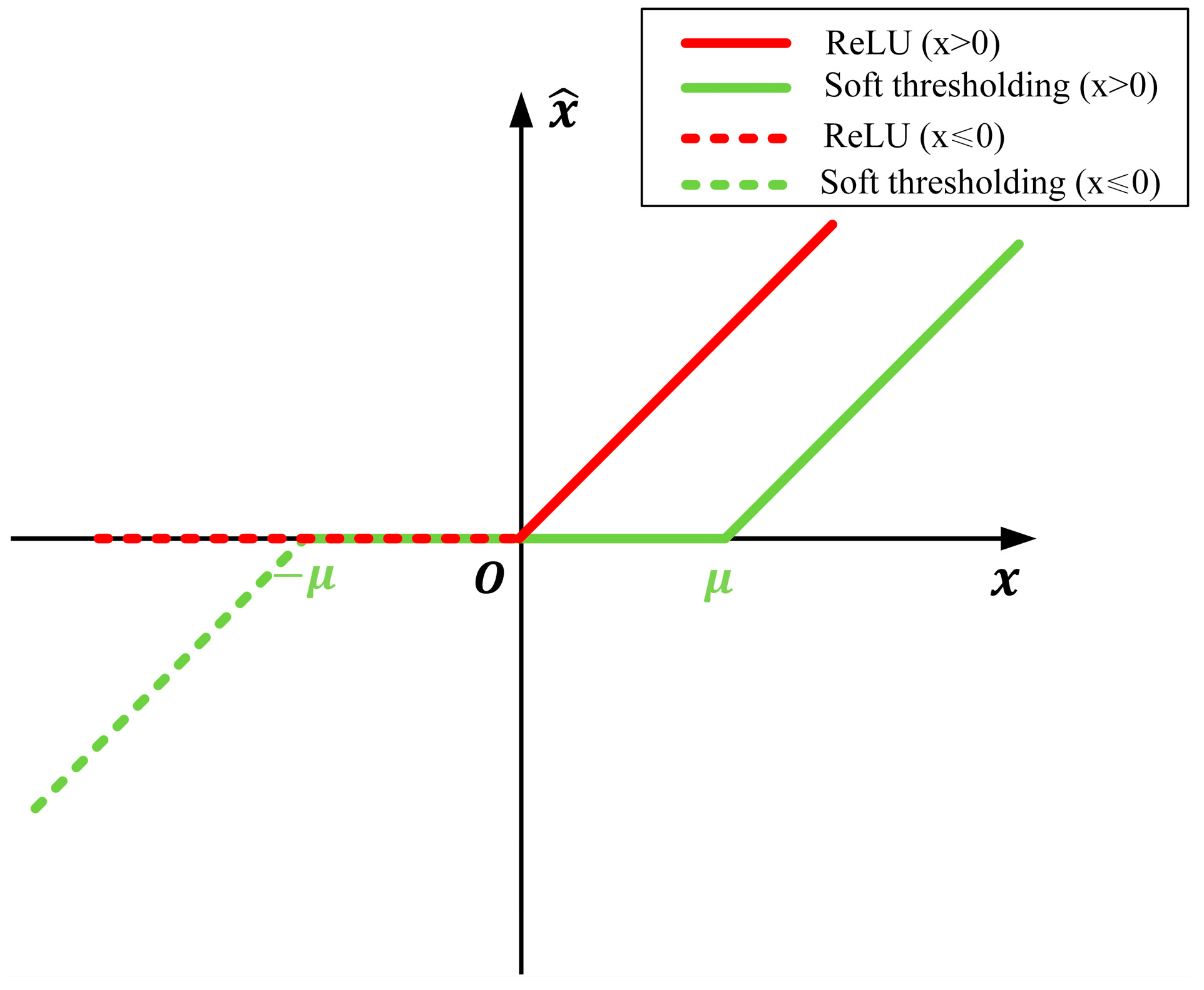
3.1.2. Soft-Activation Block
3.1.3. Soft Residual Shrinkage Unit Based on Soft Activation
3.2. Spatio-Temporal Feature Extraction Module
3.3. Feature Fusion
4. Case Studies
4.1. Data Description
4.2. Evaluation Indicators
4.3. Additional Details
4.4. Analysis of Results
4.4.1. Case from Dataset 1
4.4.2. Case from Dataset 2
5. Conclusions and Discussions
- (1)
- The soft-activation block can significantly reduce the likelihood of neuron death, improve the nonlinear representation of the model, and derive deeper features, thereby demonstrating a good noise-reducing effect. The experimental results after adding the soft-activation block on the ResNet and DRSN show that the block can enhance the prediction performance in most cases.
- (2)
- Comparing with the best results of the benchmark model, the experimental results show that the RMSE, MAE, and MAPE of the ST-SDRSN proposed are reduced in wind speed prediction. The proposed model in this paper can effectively reduce the noise information of the original wind speed and fully extract the spatio-temporal features, which has a better wind speed prediction effect.
- (3)
- The proposed model is shown to be more stable and provide better predictions even when the original wind speed series fluctuates despite superimposing data sets with different degrees of noise disturbance.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, X.; Wu, X.; Lee, K.Y. The mutual benefits of renewables and carbon capture: Achieved by an artificial intelligent scheduling strategy. Energy Convers. Manag. 2021, 233, 113856. [Google Scholar] [CrossRef]
- Javaid, A.; Javaid, U.; Sajid, M.; Rashid, M.; Uddin, E.; Ayaz, Y.; Waqas, A. Forecasting Hydrogen Production from Wind Energy in a Suburban Environment Using Machine Learning. Energies 2022, 15, 8901. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, D.; Li, Z.; Han, X.; Liu, H.; Dong, C.; Wang, J.; Liu, C.; Xia, Y. Power prediction of a wind farm cluster based on spatiotemporal correlations. Appl. Energy 2021, 302, 117568. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, Y.; Kong, C.; Chen, B. A new prediction method based on VMD-PRBF-ARMA-E model considering wind speed characteristic. Energy Convers. Manag. 2020, 203, 112254. [Google Scholar] [CrossRef]
- Lv, M.; Wang, J.; Niu, X.; Lu, H. A newly combination model based on data denoising strategy and advanced optimization algorithm for short-term wind speed prediction. J. Ambient. Intell. Humaniz. Comput. 2022, 1–20. [Google Scholar] [CrossRef]
- Zhen, H.; Niu, D.; Yu, M.; Wang, K.; Liang, Y.; Xu, X. A hybrid deep learning model and comparison for wind power forecasting considering temporal-spatial feature extraction. Sustainability 2020, 12, 9490. [Google Scholar] [CrossRef]
- Jerath, K.; Brennan, S.; Lagoa, C. Bridging the gap between sensor noise modeling and sensor characterization. Measurement 2018, 116, 350–366. [Google Scholar] [CrossRef]
- Mi, X.; Liu, H.; Li, Y. Wind speed prediction model using singular spectrum analysis, empirical mode decomposition and convolutional support vector machine. Energy Convers. Manag. 2019, 180, 196–205. [Google Scholar] [CrossRef]
- Cheng, L.; Zang, H.; Xu, Y.; Wei, Z.; Sun, G. Augmented Convolutional Network for Wind Power Prediction: A New Recurrent Architecture Design with Spatial-Temporal Image Inputs. IEEE Trans. Ind. Inform. 2021, 17, 6981–6993. [Google Scholar] [CrossRef]
- Hong, Y.Y.; Satriani, T.R.A. Day-ahead spatiotemporal wind speed forecasting using robust design-based deep learning neural network. Energy 2020, 209, 118441. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, Y.; Dong, Z.; Su, J.; Han, Z.; Zhou, D.; Zhao, Y.; Bao, Y. 2-D regional short-term wind speed forecast based on CNN-LSTM deep learning model. Energy Convers. Manag. 2021, 244, 114451. [Google Scholar] [CrossRef]
- Zhu, Q.; Chen, J.; Shi, D.; Zhu, L.; Bai, X.; Duan, X.; Liu, Y. Learning temporal and spatial correlations jointly: A unified framework for wind speed prediction. IEEE Trans. Sustain. Energy 2019, 11, 509–523. [Google Scholar] [CrossRef]
- Zheng, L.; Zhou, B.; Or, S.W.; Cao, Y.; Wang, H.; Li, Y.; Chan, K.W. Spatio-temporal wind speed prediction of multiple wind farms using capsule network. Renew. Energy 2021, 175, 718–730. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, Z. A deep attention convolutional recurrent network assisted by k-shape clustering and enhanced memory for short term wind speed predictions. IEEE Trans. Sustain. Energy 2021, 13, 856–867. [Google Scholar] [CrossRef]
- Qian, J.; Zhu, M.; Zhao, Y.; He, X. Short-term wind speed prediction with a two-layer attention-based LSTM. Comput. Syst. Sci. Eng. 2021, 39, 197–209. [Google Scholar] [CrossRef]
- Niu, X.; Wang, J. A combined model based on data preprocessing strategy and multi-objective optimization algorithm for short-term wind speed forecasting. Appl. Energy 2019, 241, 519–539. [Google Scholar] [CrossRef]
- Jaseena, K.U.; Kovoor, B.C. Decomposition-based hybrid wind speed forecasting model using deep bidirectional LSTM networks. Energy Convers. Manag. 2021, 234, 113944. [Google Scholar] [CrossRef]
- Chen, Y.; Dong, Z.; Wang, Y.; Su, J.; Han, Z.; Zhou, D.; Zhang, K.; Zhao, Y.; Bao, Y. Short-term wind speed predicting framework based on EEMD-GA-LSTM method under large scaled wind history. Energy Convers. Manag. 2021, 227, 113559. [Google Scholar] [CrossRef]
- Moreno, S.R.; da Silva, R.G.; Mariani, V.C.; dos Santos Coelho, L. Multi-step wind speed forecasting based on hybrid multi-stage decomposition model and long short-term memory neural network. Energy Convers. Manag. 2020, 213, 112869. [Google Scholar] [CrossRef]
- Wood, D.A. Trend decomposition aids short-term countrywide wind capacity factor forecasting with machine and deep learning methods. Energy Convers. Manag. 2022, 253, 115189. [Google Scholar] [CrossRef]
- Lucas, A.; Iliadis, M.; Molina, R.; Katsaggelos, A.K. Using deep neural networks for inverse problems in imaging: Beyond analytical methods. IEEE Signal Process. Mag. 2018, 35, 20–36. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Wu, Y.X.; Wu, Q.B.; Zhu, J.Q. Data-driven wind speed forecasting using deep feature extraction and LSTM. IET Renew. Power Gener. 2019, 13, 2062–2069. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [Green Version]
- Zhao, M.; Zhong, S.; Fu, X.; Tang, B.; Pecht, M. Deep residual shrinkage networks for fault diagnosis. IEEE Trans. Ind. Inform. 2019, 16, 4681–4690. [Google Scholar] [CrossRef]
- Geng, X.; Xu, L.; He, X.; Yu, J. Graph optimization neural network with spatio-temporal correlation learning for multi-node offshore wind speed forecasting. Renew. Energy 2021, 180, 1014–1025. [Google Scholar] [CrossRef]
- Zhang, J.; Zheng, Y.; Qi, D.; Li, R.; Yi, X.; Li, T. Predicting citywide crowd flows using deep spatio-temporal residual networks. Artif. Intell. 2018, 259, 147–166. [Google Scholar] [CrossRef] [Green Version]
- Peng, Z.; Peng, S.; Fu, L.; Lu, B.; Tang, J.; Wang, K.; Li, W. A novel deep learning ensemble model with data denoising for short-term wind speed forecasting. Energy Convers. Manag. 2020, 207, 112524. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, S.; Zhang, W.; Peng, J.; Cai, Y. Multifactor spatio-temporal correlation model based on a combination of convolutional neural network and long short-term memory neural network for wind speed forecasting. Energy Convers. Manag. 2019, 185, 783–799. [Google Scholar] [CrossRef]
- Draxl, C.; Clifton, A.; Hodge, B.M.; McCaa, J. The Wind Integration National Dataset (WIND) Toolkit. Appl. Energy 2015, 151, 355366. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Zhu, Q.; Shi, D.; Li, Y.; Zhu, L.; Duan, X.; Liu, Y. A multi-step wind speed prediction model for multiple sites leveraging spatio-temporal correlation. Proc. CSEE 2019, 39, 2093–2106. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Noise Type | Distribution Type | (Mean, Variance) |
|---|---|---|
| Noise A | Gauss | (0, 1.0) |
| Noise B | Gauss | (0, 1.5) |
| Noise C | Laplace | (0, 1.0) |
| Noise D | Laplace | (0, 1.5) |
| Noise Type | Model | RMSEA | MAEA | MAPEA |
|---|---|---|---|---|
| Noise A | ST-ResNet | 0.4009 | 0.3117 | 6.4623 |
| ST-SResNet ST-DRSN ST-SDRSN | 0.3812 0.3871 0.3486 | 0.2969 0.3008 0.2697 | 6.4724 6.5297 5.9794 | |
| Noise B | ST-ResNet | 0.4634 | 0.3624 | 7.6540 |
| ST-SResNet ST-DRSN ST-SDRSN | 0.4437 0.4361 0.4056 | 0.3449 0.3408 0.3152 | 7.4940 6.9342 7.1053 | |
| Noise C | ST-ResNet | 0.4268 | 0.3325 | 6.8304 |
| ST-SResNet ST-DRSN ST-SDRSN | 0.4256 0.4264 0.3927 | 0.3288 0.3301 0.3012 | 6.7644 6.5512 6.5076 | |
| Noise D | ST-ResNet | 0.5197 | 0.3978 | 8.0408 |
| ST-SResNet ST-DRSN ST-SDRSN | 0.5114 0.4714 0.4372 | 0.4040 0.3675 0.3387 | 8.4188 7.6037 7.3483 |
| Noise Type | Model | RMSEA | MAEA | MAPEA |
|---|---|---|---|---|
| Noise A | ST-ResNet | 0.7052 | 0.5246 | 9.4597 |
| ST-SResNet ST-DRSN ST-SDRSN | 0.6849 0.7074 0.6374 | 0.5099 0.5255 0.4710 | 9.0287 9.6522 8.6687 | |
| Noise B | ST-ResNet | 0.4634 | 0.3624 | 7.6540 |
| ST-SResNet ST-DRSN ST-SDRSN | 0.4437 0.4361 0.4056 | 0.3449 0.3408 0.3152 | 7.4940 6.9342 7.1053 | |
| Noise C | ST-ResNet | 0.8258 | 0.6216 | 11.486 |
| ST-SResNet ST-DRSN ST-SDRSN | 0.7727 0.8049 0.7374 | 0.5793 0.6024 0.5504 | 10.314 10.771 10.225 | |
| Noise D | ST-ResNet | 0.8958 | 0.6743 | 11.837 |
| ST-SResNet ST-DRSN ST-SDRSN | 0.9032 0.9071 0.8053 | 0.6819 0.6841 0.6022 | 13.313 12.270 10.924 |
| Noise Type | Model | RMSEA | MAEA | MAPEA |
|---|---|---|---|---|
| Noise D | CNN-LSTM | 0.8894 | 0.6973 | 13.110 |
| CNN-GRU LSTM ST-SDRSN | 0.9037 1.1754 0.8053 | 0.6614 0.7468 0.6022 | 11.827 15.790 10.924 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, X.; Hu, F.; Li, X.; Zhang, L.; Cao, H.; Li, H. Spatio-Temporal Wind Speed Prediction Based on Improved Residual Shrinkage Network. Sustainability 2023, 15, 5871. https://doi.org/10.3390/su15075871
Liang X, Hu F, Li X, Zhang L, Cao H, Li H. Spatio-Temporal Wind Speed Prediction Based on Improved Residual Shrinkage Network. Sustainability. 2023; 15(7):5871. https://doi.org/10.3390/su15075871
Chicago/Turabian StyleLiang, Xinhao, Feihu Hu, Xin Li, Lin Zhang, Hui Cao, and Haiming Li. 2023. "Spatio-Temporal Wind Speed Prediction Based on Improved Residual Shrinkage Network" Sustainability 15, no. 7: 5871. https://doi.org/10.3390/su15075871