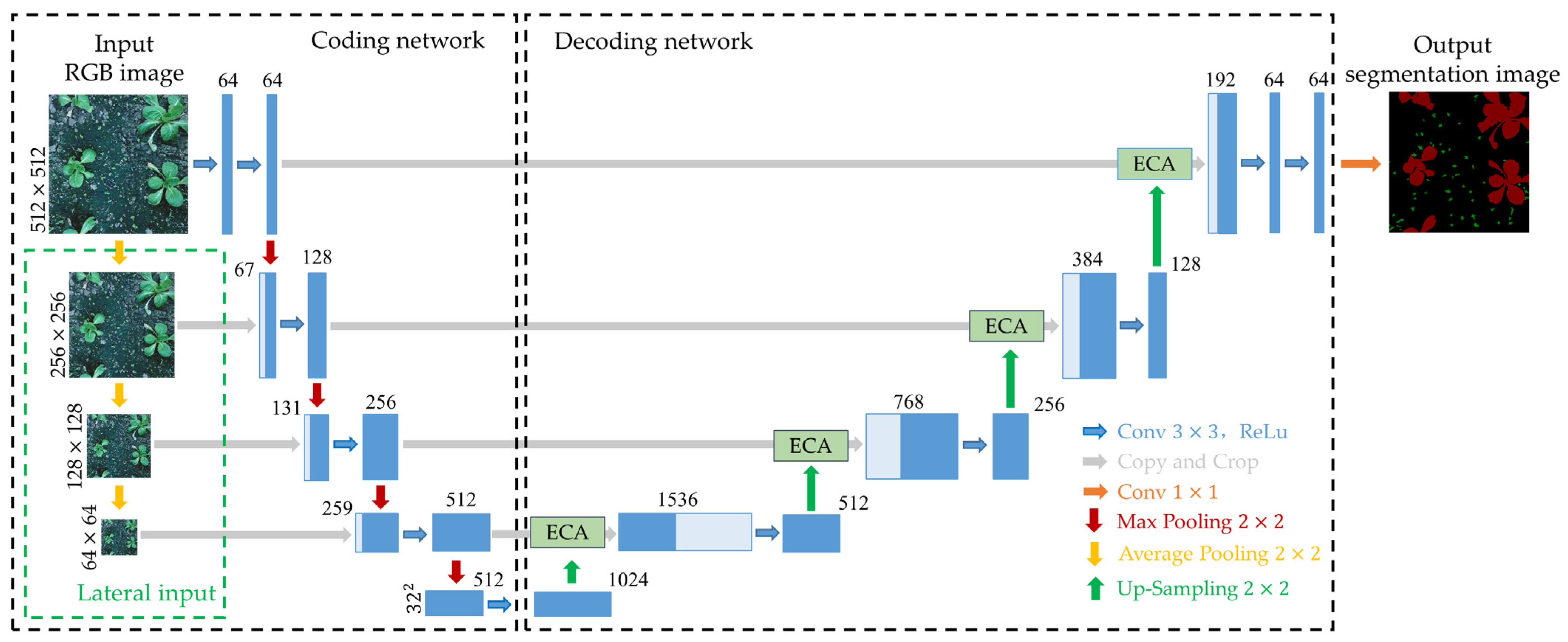
3.1. Ablation Experiment
An ablation experiment was carried out in this study to examine the contribution of the VGG16+Cutting, multi-scale input, and ECA module to enhance U-Net. The results are displayed in
Table 2. The VGG16+Cutting means employing the simplified VGG16 as the coding network of U-Net and cutting the number of the convolutional layers of the decoding network of U-Net, and the details of this approach can be seen in
Figure 6.
The addition of the VGG16+Cutting module, as can be observed in
Table 2, reduces the MIOU of the model by 1.13% but also decreases the model parameters by 49.82% and the single-image time consumption by 13.85 milliseconds. In order to make the model lighter and better suited for real-time detection, we believe that a minor loss of accuracy is worthwhile. The MIOU of the model is increased with the addition of the multi-scale input module by 0.41%, but only at the expense of an increase in single-image time consumption of 1.26 milliseconds and an increase of 0.08% in model parameters. This is due to the fact that the multi-scale input module can increase the input image’s number of channels to retain more information, whereas the number of channels of the image in this study was only increased briefly during the image feature fusion to avoid the model parametric number surge, and then, the number of channels was immediately restored to the original U-Net network with
convolutional layers. Contrarily, although refs. [
35,
46,
48] also enhanced the model by boosting the number of image channels to achieve better segmentation, these enhancements were made by directly fusing RGB and NIR images to create a four-channel image input into the network, and this method would significantly increase the number of model parameters.
Furthermore, the MIOU of the U-Net model increased by 1.63 percentage points when the ECA module was included, showing that the ECA module can significantly improve the model’s segmentation accuracy. The attention gate (AG) module, squeeze and excitation (SE) module, and convolutional block attention module (CBAM) were added to the U-Net model by John et al. [
49], Yu et al. [
50], and Jin et al. [
44], respectively. Although the addition of these attention mechanism modules improves the segmentation accuracy of the model, it also introduces many new model parameters and increases the complexity of the network. In contrast, the ECA module used in this work is a lightweight module, and it can be seen in
Table 2 that the number of model parameters is only slightly increased after the ECA module is added.
3.2. Comparison of the Overall Accuracy of the Model
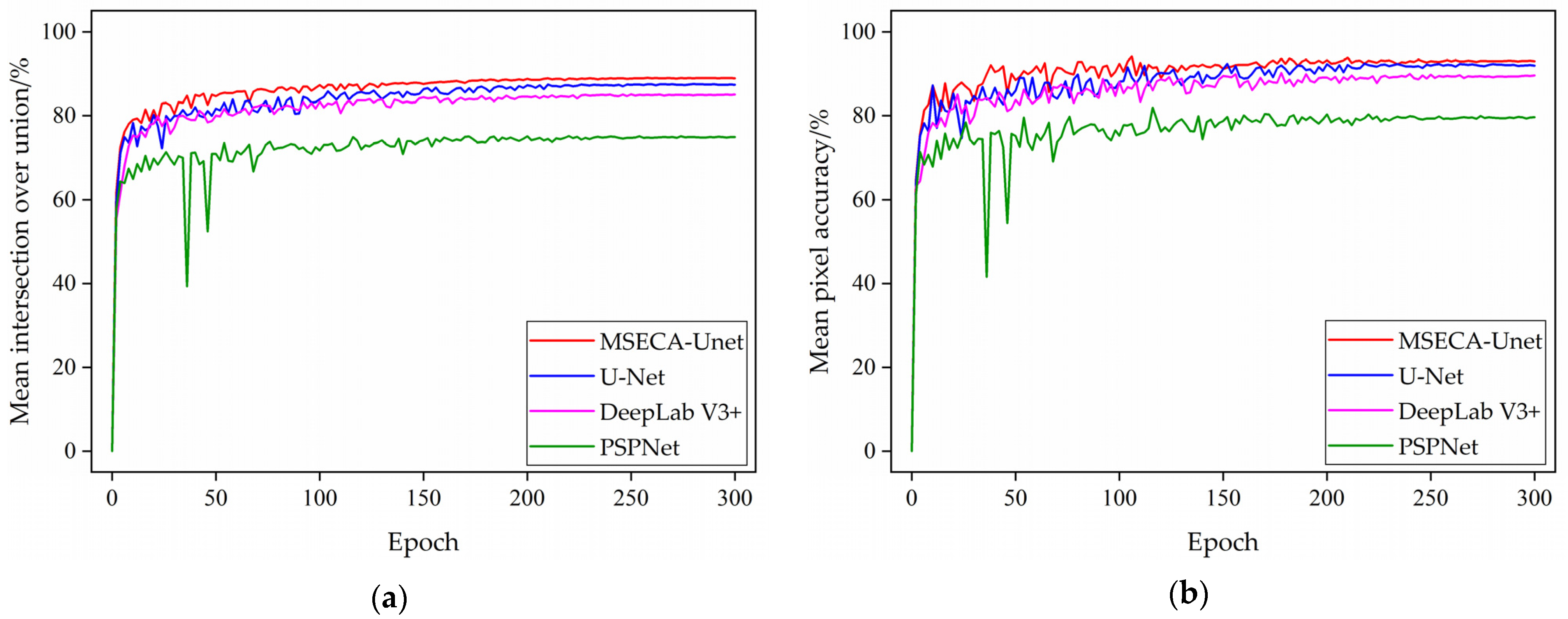
The change curves of the mean intersection over union and mean pixel accuracy on the training set of the improved model in this paper and the original U-Net model as well as the current widely used semantic segmentation models PSPNet and DeepLab V3+ [
51] are shown in
Figure 7. The computational results are shown in
Table 3, and the improved model in this paper is MSECA-Unet.
In contrast to PSPNet, DeepLab V3+ and the original U-Net model, the MIOU and MPA of the MSECA-Unet model on the training set are higher, as shown in
Figure 7. Additionally, as can be seen in
Figure 7a, the improved MSECA-Unet model converged after 130 iterations, stabilized near the highest value earlier, and did so significantly more quickly than the other three comparison models. This is because, in this paper, the ECA module, which can successfully prevent the activation of irrelevant information and noise in the network, is introduced before the fusion of features in the U-Net network, so that it only fuses the feature information that requires attention, which decreases the time loss in feature fusion, and hence, quickens the model’s convergence, which is consistent with the conclusions reached by Zhang et al. [
29] when introducing the ECA module into the YOLOv4-Tiny network, and by Zhao et al. [
52] when introducing the ECA module into DenseNet network.
As shown in
Table 3, the improved MSECA-Unet model’s MIOU is 88.95% and the MPA is 93.02% on the training set, which is higher than the 87.38% and 91.95% of the original U-Net model, and also higher than the corresponding indexes of the other two commonly used semantic segmentation models, which indicates that the improved MSECA-Unet network in this paper significantly improves the model’s segmentation accuracy, and the MSECA-Unet model has a better segmentation effect on the Chinese cabbage and weed training set compared with the U-Net, PSPNet, and DeepLab V3+ models.
The MSECA-Unet model, as well as the U-Net, PSPNet, and DeepLab V3+ models, are also assessed on the test set in this work. The prediction results are displayed in
Table 4, whereas
Table 5 shows the number of model parameters, model size, and prediction speed;
Table 6 shows the model accuracy, precision, and F1-score.
As can be seen in
Table 4, the intersections over union and pixel accuracy of all models for weed segmentation are much lower than their corresponding metrics for background and crop segmentation, which is due to the high density and small area of weeds in the dataset collected in this study, which possess greater segmentation difficulty compared to background and crop with large areas and small numbers. In addition,
Table 4 shows that for background, weeds, and crops, the proposed MSECA-Unet model in this paper produced the best results in terms of the intersection over union and pixel accuracy with 99.24%, 73.62%, 94.02%, and 99.64%, 82.58%, and 93.05%, respectively, as opposed to the original U-Net model with 99.16%, 69.87%, 93.62%, and 99.58%, 80.58%, 96.84%, which are increased by 0.08%, 3.75%, 0.40% and 0.06%, 2.00% and 0.08%, respectively. Thus, it can be seen, in addition to having a higher intersection over union and pixel accuracy than the original U-Net model for all categories in this study, the MSECA-Unet model also significantly increased these metrics for weeds, the hardest category to segment, which strongly supports the efficacy of the improvements made in this paper.
In
Table 4 and
Table 5, we can see that the MIOU of the original U-Net model is 87.55% and the MPA is 92.33%, while the MIOU of the MSECA-Unet model proposed in this paper is 88.96% and the MPA is 93.05%, which are improved by 1.41 and 0.72 percentage points, respectively. This is due to the fact that the original U-Net model down-samples the feature map four times in order to obtain deeper feature information, which causes the network to lose a lot of detailed information that cannot be recovered by the subsequent up-sampling operation, and affects the segmentation accuracy of the network. While this study incorporates the multi-scale feature map produced by average pooling into the network, which effectively addresses the aforementioned information loss issue and boosts the model’s segmentation accuracy. Meanwhile, the original U-Net model uses jump connections to combine the spatial data from the up-sampled paths with the spatial data from the down-sampled paths. However, this brings many redundant underlying features and noise, which affect the segmentation accuracy and speed of the network. In this paper, the ECA module is introduced before the network feature fusion. Increasing the target feature weight and reducing the weight of the useless or small-effect features make the model focus more on the target feature extraction and improve the model’s feature extraction efficiency and accuracy.
Additionally, the proposed MSECA-Unet model has
model parameters and a model size of 60.27 MB, which are both 49.68% less than the original U-Net model’s
and 119.77 MB. Moreover, the proposed MSECA-Unet model’s single-image time consumption is 64.85 ms, which is 9.36% faster than the original U-Net model’s 71.55 ms. This indicates that the proposed MSECA-Unet model has a faster segmentation speed than the original U-Net model, and that it is more capable of meeting the requirements of real-time crop and weed detection. This is because the model coding network is simplified according to the simple features of cabbage and weed in the images. The simplified coding network can maintain the same image feature extraction capability while consuming fewer computational resources. Meanwhile, this study also simplifies the model decoding network by reducing the number of convolutional layers, which is due to the fact that the images in this study are not complex and the decoding network does not need more abstract features. The reduction in the number of convolutional layers of the coding and decoding networks causes a decrease in the number of model parameters and model size, and speeds up the segmentation of the model. In contrast, refs. [
39,
40,
43] directly use the VGG16 network as the encoding network for U-Net without simplifying VGG16, which also achieves better segmentation results but increases the width and depth of the network and requires a more optimal environment configuration to run the model. Chen et al. [
53] achieved the accurate segmentation of grains, branches, and straws in hybrid rice grain images by improving the U-Net model, but the improvement they made was still to make the model extract richer semantic information by increasing the depth of the model. The advancements made in this work, however, strive to obtain the largest gain effect with the fewest possible factors. The ECA module introduced before the network feature fusion is a lightweight module, which has fewer parameters, and also when integrating the multi-scale feature maps into the backbone feature extraction network, it is chosen to integrate from the lateral direction, which effectively avoids the significant growth of the network parameters. Due to these advancements, the model can have fewer model parameters and a smaller model size while still preserving the segmentation effect, and the smaller number of model parameters and model sizes allow the model to run in a relatively low hardware environment configuration, reducing memory costs and saving resource consumption.
In addition, the MSECA-Unet model proposed in this paper also significantly outperforms the current semantic segmentation models DeepLab V3+ and PSPNet. The MSECA-Unet model’s MIOU and MPA are improved by 3.90% and 3.45%, respectively, over DeepLab V3+, while the number of model parameters, model size, and single-picture time consumption are decreased by 61.74%, 61.96%, and 15.03%, respectively. In comparison to PSPNet, the MIOU and MPA of the MSECA-Unet model are increased by 14.03% and 13.38%, and the number of model parameters, model size, and single-image time consumption are reduced by 67.82%, 66.30%, and 3.90%, respectively. In summary, the segmentation speed (single-image time consumption) of the proposed MSECA-Unet model is significantly faster than the other three semantic segmentation models, and its segmentation accuracy (MIOU and MPA) is also significantly improved with a significant reduction in the number of model parameters and model size, indicating that the proposed model is more suitable for application in the recognition of Chinese cabbage crops and weeds.
As can be seen in
Table 6, the MSECA-Unet model proposed in this paper has the best accuracy, precision, and F1-score compared with U-Net, DeepLab V3+ and PSPNet. The accuracy, precision, and F1-score of the MSECA-Unet model each increased by 0.4%, 1.17%, and 0.94%, respectively, when compared to U-Net. In order to make the model more lightweight and improve the segmentation speed of the model, references [
42,
45] decreased the U-Net model’s convolutional layer count in a manner similar to this study. Despite the fact that the segmentation speed of the improved model for farmland weeds was considerably increased, the reduction in a significant number of model parameters resulted in a decrease in model precision, and later, other improvements of the model were unable to make up for this loss. The MSECA-Unet model’s accuracy, precision, and F1-score increased in comparison to DeepLab V3+ by 1.05%, 1.74%, and 2.62%, respectively; in comparison to PSPNet, they increased by 4.4, 6.8, and 10.28 percentage points, respectively.
3.3. Comparison of Model Segmentation Effects
Randomly selected images in the test set are used as sample images to obtain their segmentation effects on each model. In order to observe the segmentation effect more clearly, the original image was fused with the predicted label image after reducing the transparency and the segmentation effect of each model was displayed in
Figure 8. To facilitate the observation of the differences in segmentation effects between different models, certain regions in the segmentation effect map were locally enlarged and the weeds in the locally enlarged map were numbered in the labelled image, as shown in
Figure 9. The Chinese cabbage crop is presented in red in the figure, and the weed is presented in green.
According to
Figure 8, the MSECA-Unet model that was suggested in this study has the optimal segmentation effect and its segmentation effect is most similar to the labeled picture. In contrast, the segmentation effect of the PSPNet model is the least satisfying. In
Figure 8f, it is obvious that the segmentation area of the Chinese cabbage crop by the PSPNet model has deviated seriously from the original area of the image, and the mis-segmentation and under-segmentation of weeds in the image are serious, making it impossible to correctly identify weeds.
The MSECA-Unet model has the best segmentation impact on weeds
,
,
B4, and
, according to the images of regions A, B, and C in
Figure 9, while the DeepLab V3+ model has the lowest segmentation effect, segmenting weeds
and
partially, and failing to segment weeds
and
. Additionally, for weeds
,
, and
, which are close to the crop, the MSECA-Unet model can accurately segment the gap between them and the crop, while the U-Net and DeepLab V3+ models have mis-segmentation issues when segmenting weeds
,
, and
, which incorrectly segment the background as crop or weed, causing the crop and weed prediction labels to be mixed together directly without segmenting the gaps between them. Moreover, the DeepLab V3+ model had the worst segmentation effect, which not only mixed weed
with the crop, but also mixed weed
at the same time. Additionally, the MSECA-Unet model had the best segmentation of weed
, which overlapped with the crop. While the U-Net and DeepLab V3+ models under-segmented weed
severely, the U-Net model only segmented a very tiny region, and the DeepLab V3+ model did not segment it at all.
In summary, compared with U-Net and DeepLab V3+ models, the MSECA-Unet model has the best performance, which can not only accurately segment the weeds overlapping with crops, but also has the most accurate segmentation effect on the gap between crops and weeds, and the accurate segmentation of weeds close to crops and overlapping with crops is an important prerequisite for accurate spraying and accurate weed control.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}