
A Scenario-Based Case Study: Using AI to Analyze Casualties from Landslides in Chittagong Metropolitan Area, Bangladesh




Abstract
:1. Introduction
2. Materials and Methods
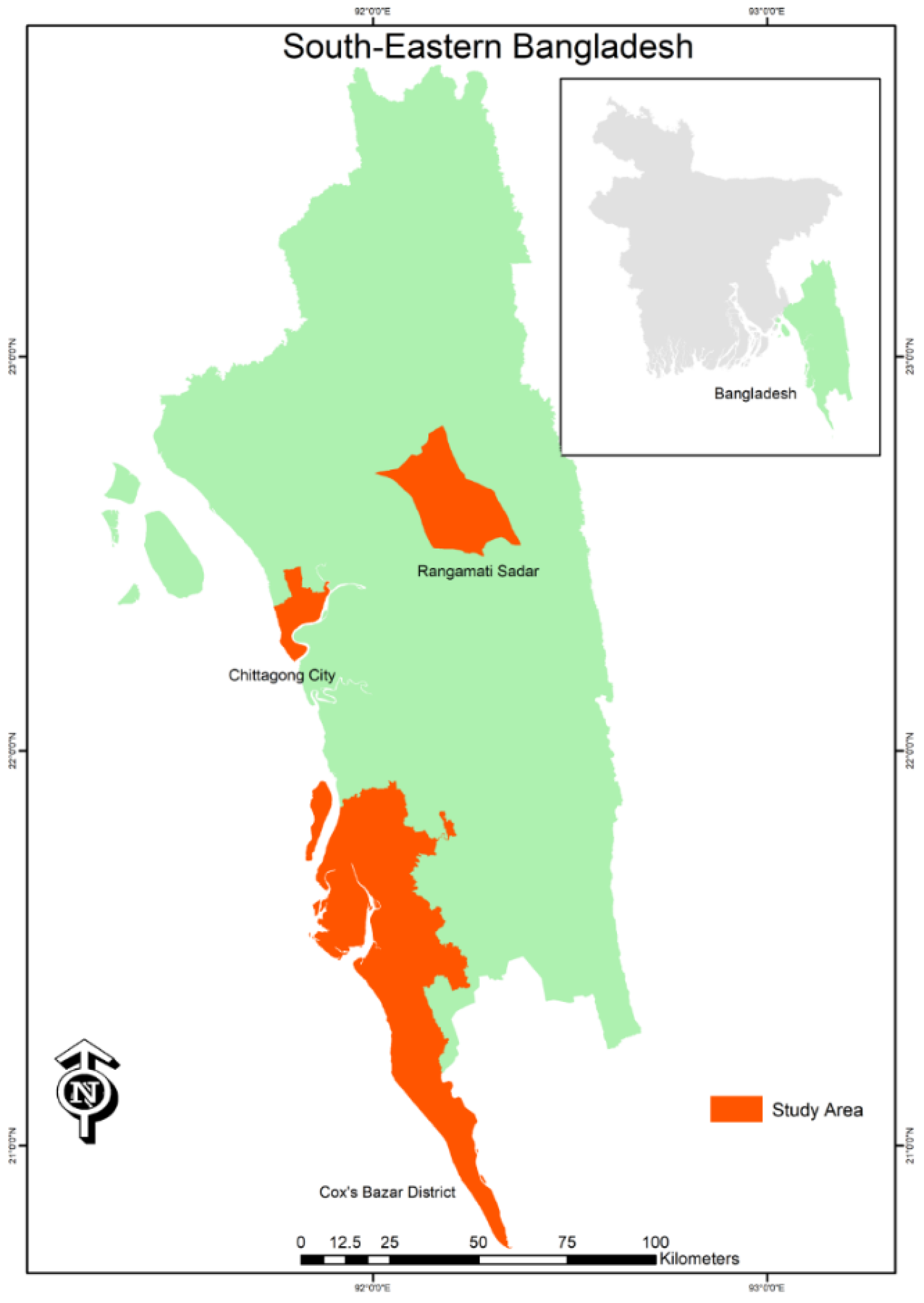
2.1. Study Area Selection
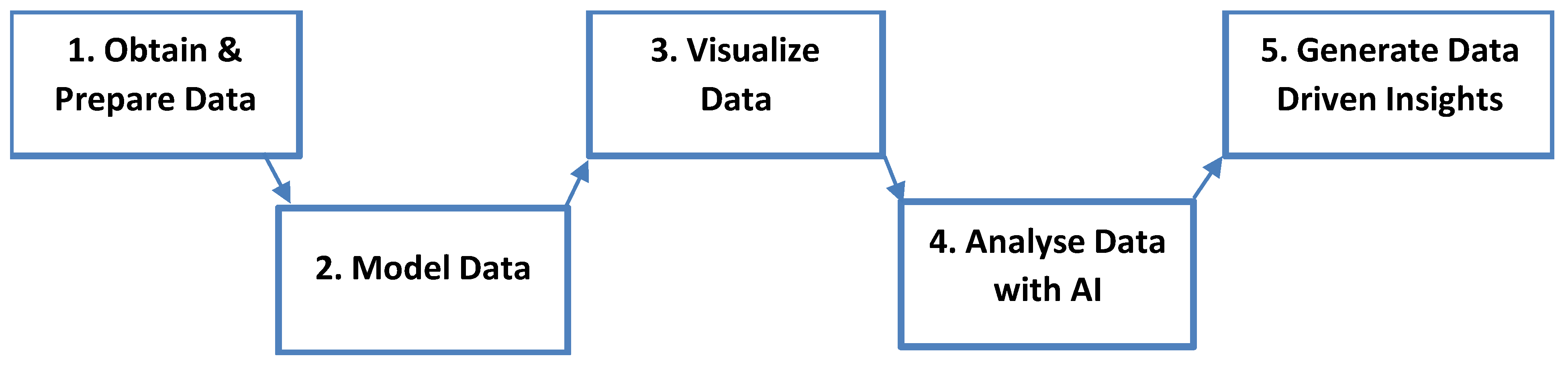
2.2. Obtaining and Preparing the Data
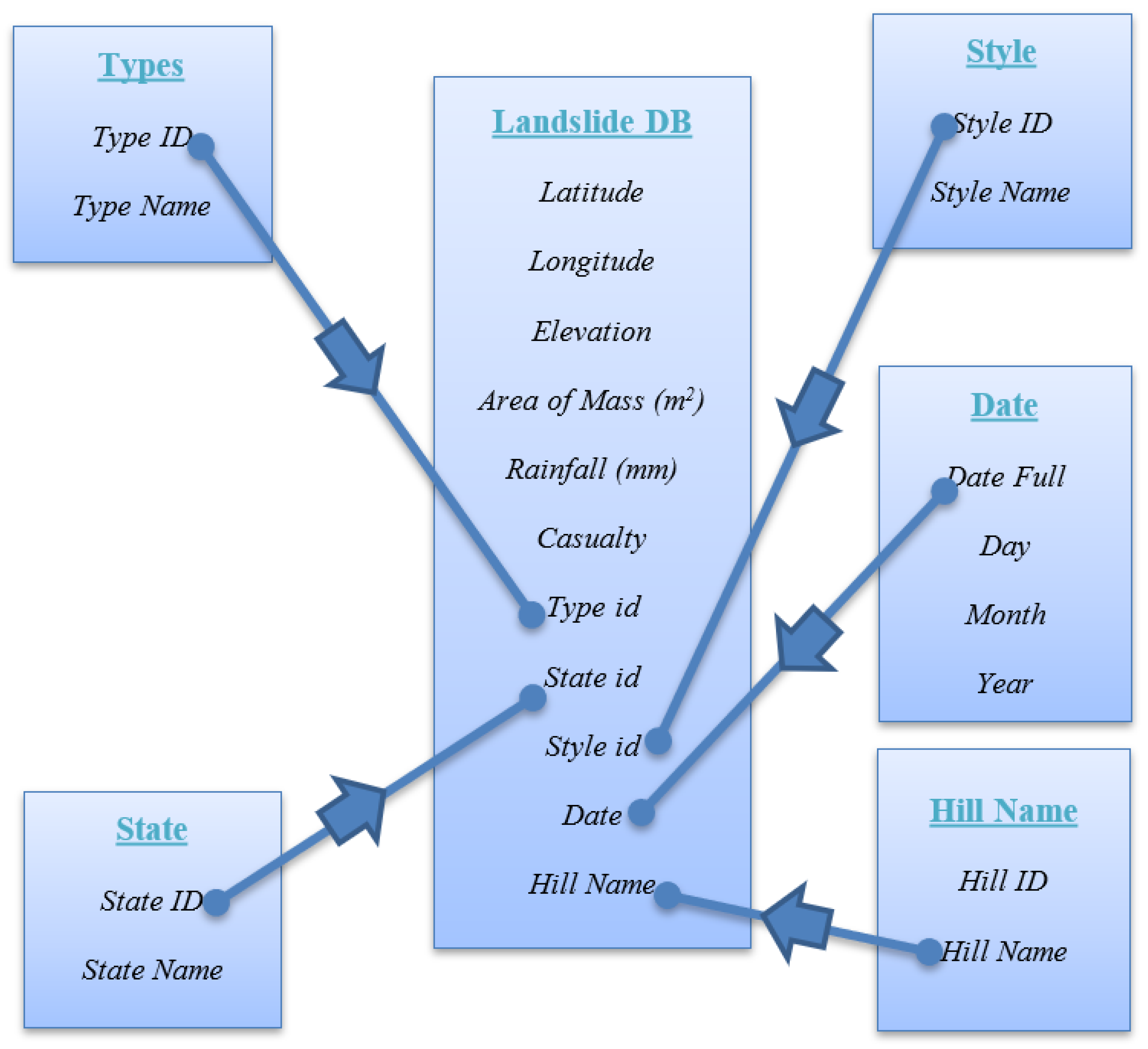
2.3. Modelling the Data
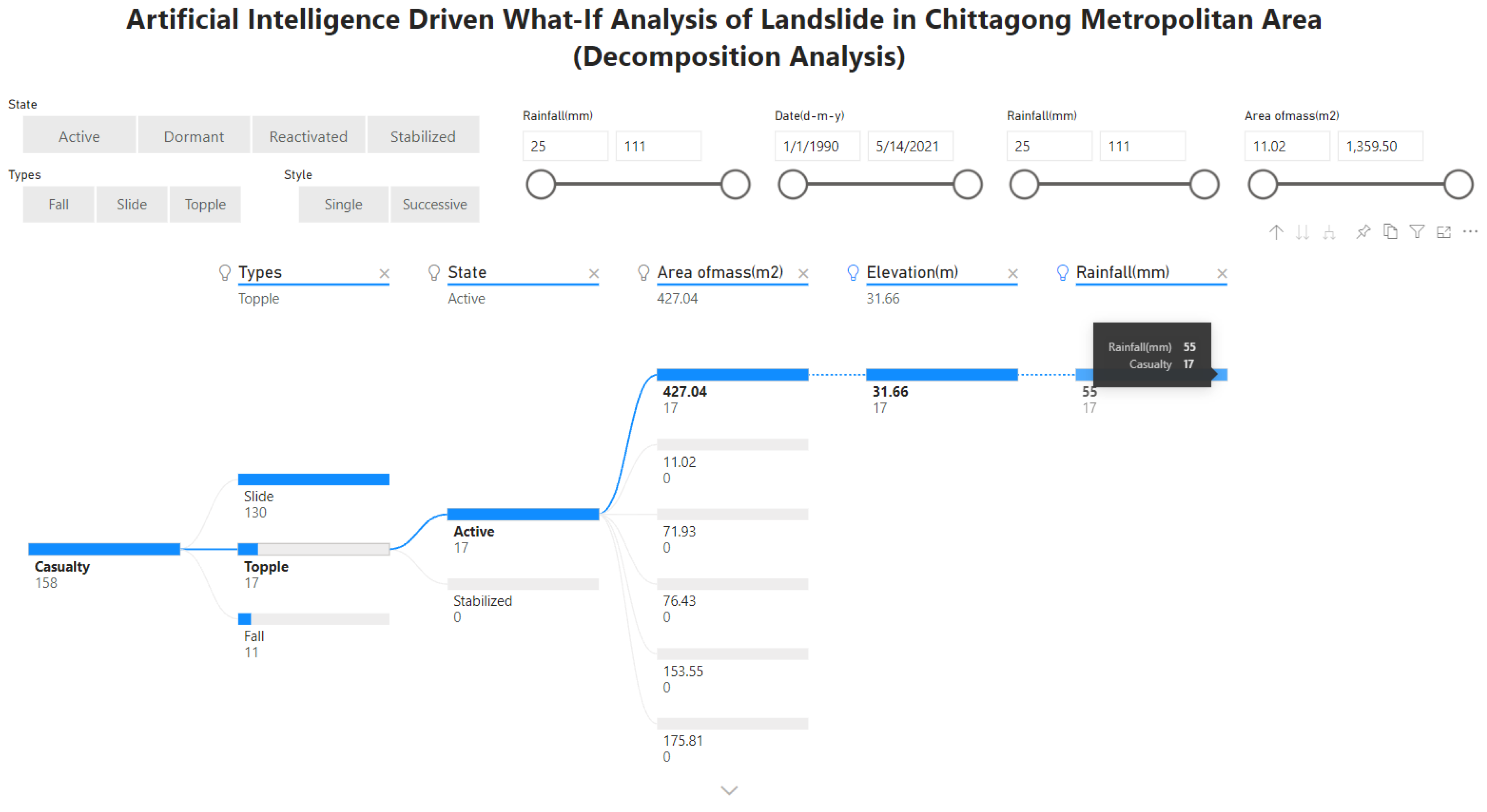
2.4. Visualizing the Data
2.5. Analyzing Data with AI
- Area of Mass (m2)
- Elevation (m)
- Hill Name
- Rain fall (mm)
- State
- Style
- Types
- Date
2.6. Generating Data-Driven Insights
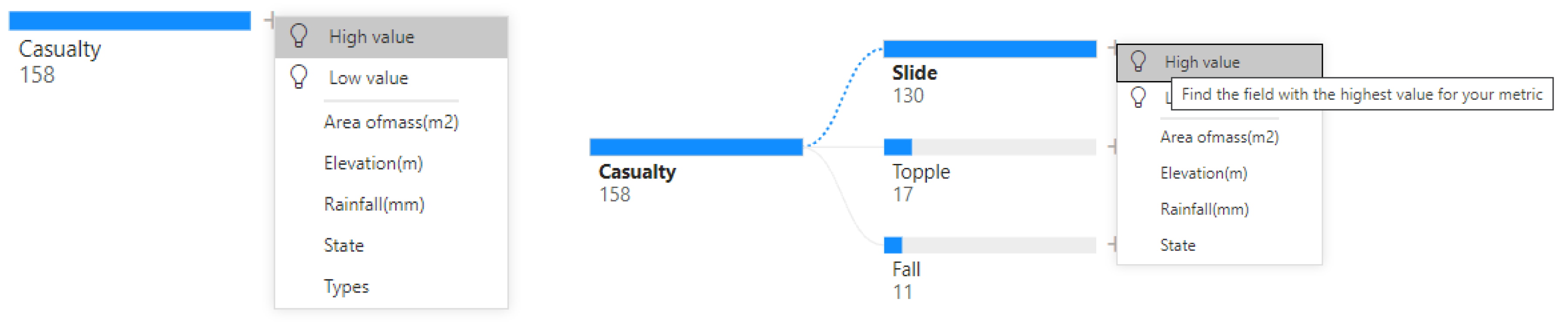
3. Results
- State = “Stabilized”,
- Type = All,
- Style = All,
- Area of Mass = All,
- Date = All,
- Elevation = {p|29.05 ≤ p ≤ 58.72},
- Rainfall = {n|43 ≤ n ≤ 111}
4. Discussion
- Colony para, the University of Chittagong
- Motijharna, Chittagong City
- Matiranga, Rangamati
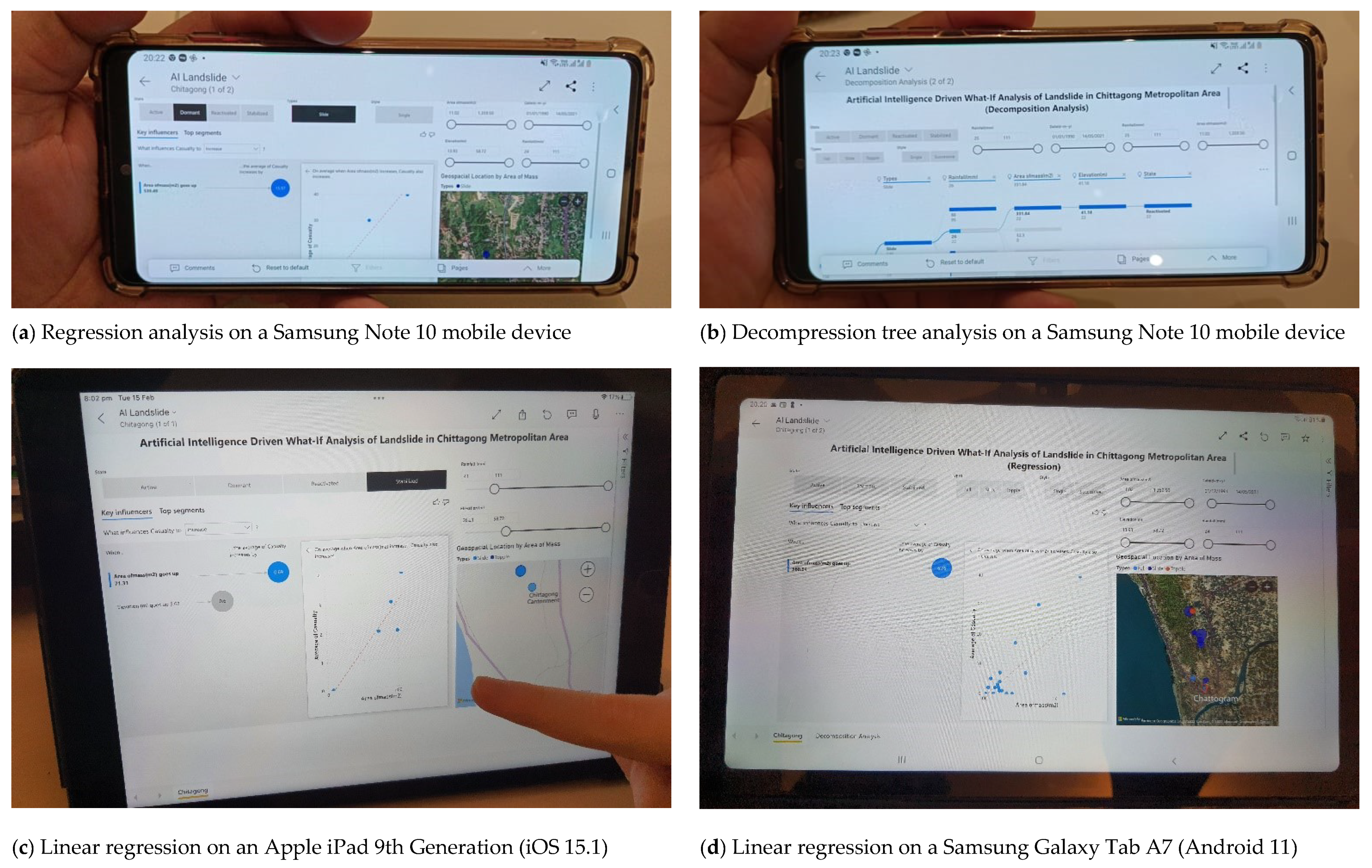
5. User Notes
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rabby, Y.W.; Li, Y. Landslide Inventory (2001–2017) of Chittagong Hilly Areas, Bangladesh. Data 2020, 5, 4. [Google Scholar] [CrossRef] [Green Version]
- Alam, E. Landslide Hazard Knowledge, Risk Perception and Preparedness in Southeast Bangladesh. Sustainability 2020, 12, 6305. [Google Scholar] [CrossRef]
- Ahmed, B. The root causes of landslide vulnerability in Bangladesh. Landslides 2021, 18, 1707–1720. [Google Scholar] [CrossRef]
- Alam, E.; Ray-Bennett, N.S. Disaster risk governance for district-level landslide risk management in Bangladesh. Int. J. Disaster Risk Reduct. 2021, 59, 102220. [Google Scholar] [CrossRef]
- Sultana, N. Analysis of landslide-induced fatalities and injuries in Bangladesh: 2000–2018. Cogent Soc. Sci. 2020, 6, 1737402. [Google Scholar] [CrossRef]
- Lin, L.; Lin, Q.; Wang, Y. Landslide susceptibility mapping on a global scale using the method of logistic regression. Nat. Hazards Earth Syst. Sci. 2017, 17, 1411–1424. [Google Scholar] [CrossRef] [Green Version]
- Stanley, T.; Kirschbaum, D.B. A heuristic approach to global landslide susceptibility mapping. Nat. Hazards 2017, 87, 145–164. [Google Scholar] [CrossRef] [Green Version]
- Lissak, C.; Bartsch, A.; De Michele, M.; Gomez, C.; Maquaire, O.; Raucoules, D.; Roulland, T. Remote Sensing for Assessing Landslides and Associated Hazards. Surv. Geophys. 2020, 41, 1391–1435. [Google Scholar] [CrossRef]
- Tan, Q.; Bai, M.; Zhou, P.; Hu, J.; Qin, X. Geological hazard risk assessment of line landslide based on remotely sensed data and GIS. Measurement 2021, 169, 108370. [Google Scholar] [CrossRef]
- Senouci, R.; Taibi, N.-E.; Teodoro, A.; Duarte, L.; Mansour, H.; Meddah, R. GIS-Based Expert Knowledge for Landslide Susceptibility Mapping (LSM): Case of Mostaganem Coast District, West of Algeria. Sustainability 2021, 13, 630. [Google Scholar] [CrossRef]
- Mohan, A.; Singh, A.K.; Kumar, B.; Dwivedi, R. Review on remote sensing methods for landslide detection using machine and deep learning. Trans. Emerg. Telecommun. Technol. 2021, 32, e3998. [Google Scholar] [CrossRef]
- Guzzetti, F.; Carrara, A.; Cardinali, M.; Reichenbach, P. Landslide hazard evaluation: A review of current techniques and their application in a multi-scale study, Central Italy. Geomorphology 1999, 31, 181–216. [Google Scholar] [CrossRef]
- Duman, T.Y.; Çan, T.; Emre, Ö.; Keçer, M.; Doğan, A.; Ateş, Ş.; Durmaz, S. Landslide inventory of northwestern Anatolia, Turkey. Eng. Geol. 2005, 77, 99–114. [Google Scholar] [CrossRef]
- Godt, J.; Baum, R.; Savage, W.; Salciarini, D.; Schulz, W.; Harp, E. Transient deterministic shallow landslide modeling: Requirements for susceptibility and hazard assessments in a GIS framework. Eng. Geol. 2008, 102, 214–226. [Google Scholar] [CrossRef]
- Yilmaz, I. Landslide susceptibility mapping using frequency ratio, logistic regression, artificial neural networks and their comparison: A case study from Kat landslides (Tokat—Turkey). Comput. Geosci. 2009, 35, 1125–1138. [Google Scholar] [CrossRef]
- Sendir, H.; Yilmaz, I. Structural, geomorphological and geomechanical aspects of the Koyulhisar landslides in the North Anatolian Fault Zone (Sivas, Turkey). Environ. Geol. 2002, 42, 52–60. [Google Scholar]
- Ahmed, B. Landslide susceptibility mapping using multi-criteria evaluation techniques in Chittagong Metropolitan Area, Bangladesh. Landslides 2015, 12, 1077–1095. [Google Scholar] [CrossRef] [Green Version]
- Qi, T.; Zhao, Y.; Meng, X.; Chen, G.; Dijkstra, T. AI-Based Susceptibility Analysis of Shallow Landslides Induced by Heavy Rainfall in Tianshui, China. Remote Sens. 2021, 13, 1819. [Google Scholar] [CrossRef]
- Sufi, F.K.; Alsulami, M. Knowledge Discovery of Global Landslides Using Automated Machine Learning Algorithms. IEEE Access 2021, 9, 131400–131419. [Google Scholar] [CrossRef]
- UN. Sendai Framework for Disaster Risk Reduction 2015–2030. United Nations Office for Disaster Risk Reduction (UNISDR): Geneva, Switzerland. 2015. Available online: http://www.unisdr.org/we/inform/publications/43291 (accessed on 20 November 2021).
- BBS. Bangladesh Population Census-2021; Bangladesh Bureau of Statistics (BBS), Government of Bangladesh: Dhaka, Bangladesh, 2021.
- Rahman, M.S.; Ahmed, B.; Huq, F.F.; Rahman, S.; Al-Hussaini, T.M. Landslide inventory in an urban setting in the context of Chittagong Metropolitan area, Bangladesh. In Proceedings of the 3rd International Conference on Advances in Civil Engineering, CUET, Chittagong, Bangladesh, 21–23 December 2016; pp. 170–178. [Google Scholar]
- Microsoft Documentation. Understand Star Schema and the Importance for Power BI. Available online: https://docs.microsoft.com/en-us/power-bi/guidance/star-schema#:~:text=Star%20schema%20is%20a%20mature,and%20concepts%20including%20time%20itself (accessed on 20 November 2021).
- Ferrai, A. The Importance of Star Schemas in Power BI. 2021. Available online: https://www.sqlbi.com/articles/the-importance-of-star-schemas-in-power-bi/ (accessed on 20 November 2021).
- Sufi, F.K. AI-Landslide: Software for acquiring hidden insights from global landslide data using Artificial Intelligence. Softw. Impacts 2021, 10, 100177. [Google Scholar] [CrossRef]
- Nocedal, J. Updating Quasi-Newton Matrices with Limited Storage. Math. Comput. 1980, 35, 773–782. [Google Scholar] [CrossRef]
- Varnes, D.J. Landslide Hazard Zonation: A Review of Principles and Practice; Unesco: Paris, France, 1984. [Google Scholar]
- Kavzoglu, T.; Teke, A. Predictive Performances of Ensemble Machine Learning Algorithms in Landslide Susceptibility Mapping Using Random Forest, Extreme Gradient Boosting (XGBoost) and Natural Gradient Boosting (NGBoost). Arab. J. Sci. Eng. 2022, 47, 7367–7385. [Google Scholar] [CrossRef]
- Sufi, F.; Alam, E.; Alsulami, M. A new interactive system for analyzing historical records of tornedoes in Bangladesh. Sustainability 2022, 14, 6303. [Google Scholar] [CrossRef]
- Sufi, F.; Alam, E.; Alsulami, M. Automated Analysis of Australian Tropical Cyclones with Regression, Clustering and Convolutional Neural Network. Sustainability 2022, 14, 9830. [Google Scholar] [CrossRef]
- Sufi, F.; Khalil, I. Automated Disaster Monitoring from Social Media Posts using AI based Location Intelligence and Sentiment Analysis. IEEE Trans. Comput. Soc. Syst. 2022, 1–11. [Google Scholar] [CrossRef]
- Sufi, F. A decision support system for extracting artificial intelligence-driven insights from live twitter feeds on natural disasters. Decis. Anal. 2022, 5, 100130. [Google Scholar] [CrossRef]
- Sufi, F.K.; Alsulami, M. Automated Multidimensional Analysis of Global Events with Entity Detection, Sentiment Analysis and Anomaly Detection. IEEE Access 2021, 9, 152449–152460. [Google Scholar] [CrossRef]
- Sufi, F.K. AI-GlobalEvents: A Software for analyzing, identifying and explaining global events with Artificial Intelligence. Softw. Impacts 2022, 11, 100218. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Attribute | Data Type | Attribute Distribution | Other Attribute Details |
|---|---|---|---|
| ID | Integer |  | 57 Distinct, 57 Unique Value Example: Ranges from 1 to 57 |
| Latitude | Decimal |  | 50 Distinct, 44 Unique |
| Longitude | Decimal |  | 54 Distinct, 51 Unique |
| Elevation | Decimal |  | 56 Distinct, 55 Unique |
| Date | Date (dd-mm-yyyy) |  | 6 Distinct, 0 Unique, 34 Empty |
| Hill Name | Text |  | 29 Distinct, 13 Unique Value Example: Lebu Bagan, Ctg. University, Foy’z Lake Zoo Hill, Medical Hill, Tankir Pahar, Sekandar Para, etc. |
| Area of Mass | Decimal |  | 56 Distinct, 55 Unique |
| Types | Text |  | 3 Distinct, 0 Unique Value Example: Slide, Fall, Topple |
| State | Text |  | 4 Distinct, 0 Unique Value Example: Active, Stabilized, Dormant, Reactivated |
| Style | Text |  | 2 Distinct, 0 Unique Value Example: Single, Successive |
| Rainfall | Integer |  | 10 Distinct, 4 Unique, 18 Empty |
| Casualty | Integer |  | 12 Distinct, 8 Unique |
| AI Insight | AI-Based System Settings | Scenario |
|---|---|---|
| 1. When area of mass goes up 241.92, the average of causalities increases by 5.79 |  | State = All, Type = All, Style = All, Area of Mass = All, Date = All, Elevation = All, Rainfall = All |
| 2. When area of mass (m2) goes up 539.49, the average of causalities increases by 15.97 |  | State = “Dormant”, Type = All, Style = All, Area of Mass = All, Date = All, Elevation = All, Rainfall = All |
| 3. When area of mass (m2) goes up 137.08, the average of causalities increases by 1.53 |  | State = “Stabilized”, Type = All, Style = All, Area of Mass = All, Date = All, Elevation = All, Rainfall = All |
| 4. When rainfall (mm) goes up 29.29, the average of causalities increases by 0.49 |  | State = “Stabilized”, Type = All, Style = All, Area of Mass = All, Date = All, Elevation = All, Rainfall = All |
| 5. When area of mass (m2) goes up 71.31, the average of casualties increases by 0.69 |  | State = “Stabilized”, Type = All, Style = All, Area of Mass = All, Date = All, Elevation = {p|29.05 ≤ p ≤ 58.72}, Rainfall = {n|43 ≤ n ≤ 111} |
| 6. When elevation (m) goes up 5.62, the average of casualties increases by 0.6 |  | State = “Stabilized”, Type = All, Style = All, Area of Mass = All, Date = All, Elevation = {p|29.05 ≤ p ≤ 58.72}, Rainfall = {n|43 ≤ n ≤ 111} |
| 7. When, area of mass goes up 149.35, the average of casualties increases by 1.76 |  | State = “Stabilized”, Type = “Slide”, Style = “Single”, Area of Mass = All, Date = All, Elevation = {p|18.25 ≤ p ≤ 58.72}, Rainfall = {n|24 ≤ n ≤ 105} |
| Number of Users | Device Name | OS Version |
|---|---|---|
| 2 | Samsung Note 10 Lite (Mobile) | Android 11 |
| 1 | Samsung Note 10 Lite (Mobile) | Android 12 |
| 2 | Samsung Galaxy Tab A7 (Tablet) | Android 11 |
| 2 | iPhone 13 (Mobile) | iOS 15 |
| 1 | iPhone 12 (Mobile) | iOS 14 |
| 2 | iPad 9th Generation (Tablet) | iOS 15.2 |
| 2 | iPad Mini 6 (Tablet) | iOS 15 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alam, E.; Sufi, F.; Islam, A.R.M.T. A Scenario-Based Case Study: Using AI to Analyze Casualties from Landslides in Chittagong Metropolitan Area, Bangladesh. Sustainability 2023, 15, 4647. https://doi.org/10.3390/su15054647
Alam E, Sufi F, Islam ARMT. A Scenario-Based Case Study: Using AI to Analyze Casualties from Landslides in Chittagong Metropolitan Area, Bangladesh. Sustainability. 2023; 15(5):4647. https://doi.org/10.3390/su15054647
Chicago/Turabian StyleAlam, Edris, Fahim Sufi, and Abu Reza Md. Towfiqul Islam. 2023. "A Scenario-Based Case Study: Using AI to Analyze Casualties from Landslides in Chittagong Metropolitan Area, Bangladesh" Sustainability 15, no. 5: 4647. https://doi.org/10.3390/su15054647