

Sustainable Analysis of Insulator Fault Detection Based on Fine-Grained Visual Optimization
Abstract
:1. Introduction
2. Methods
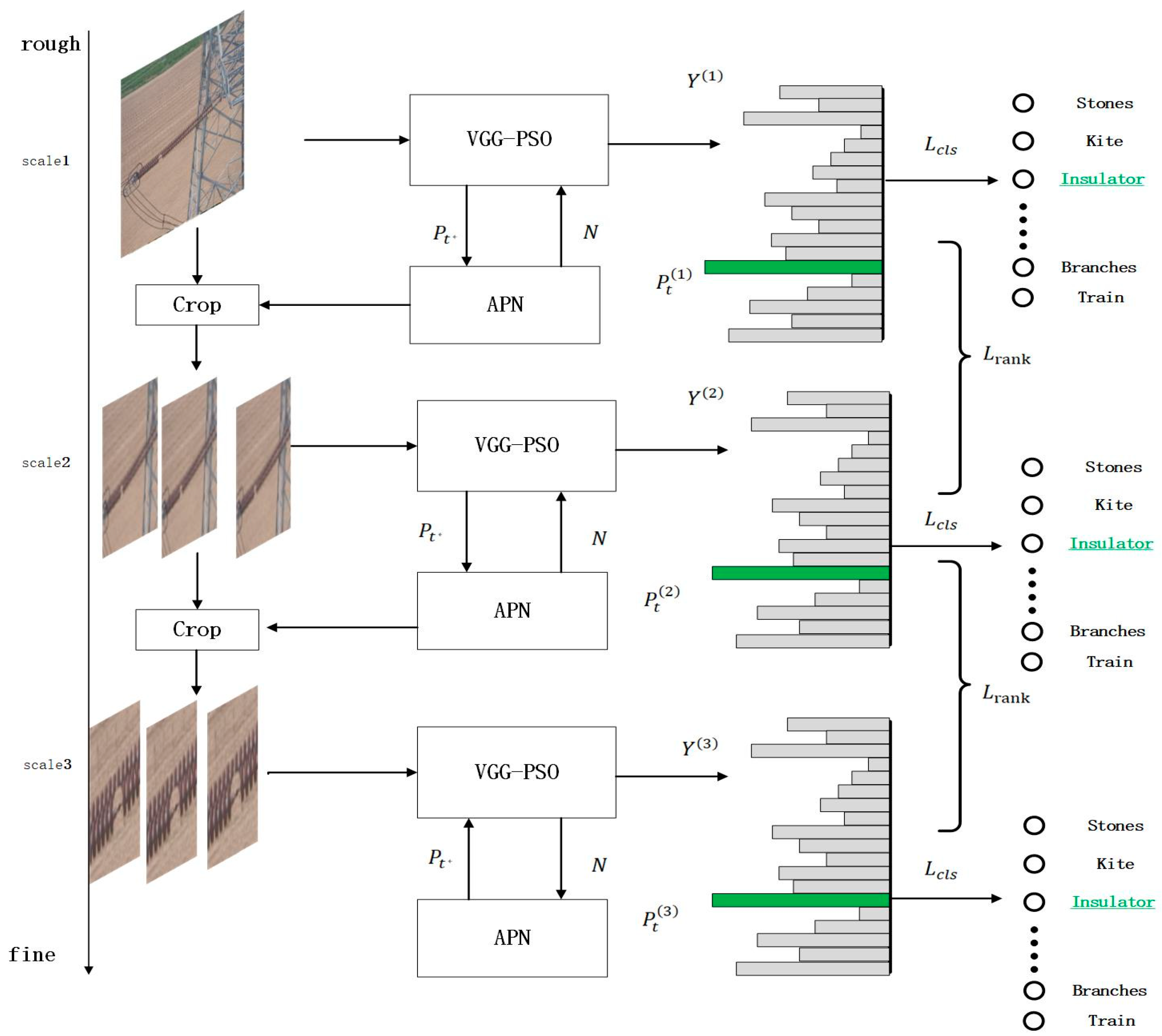
2.1. Experimental Process
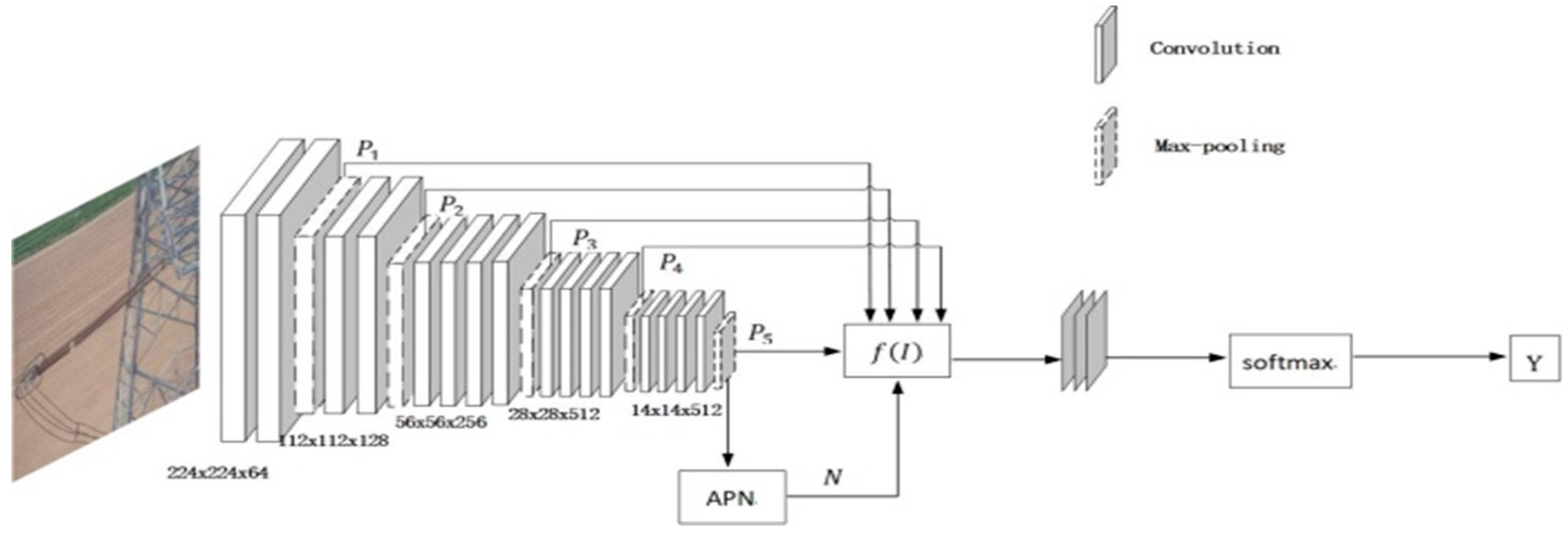
2.2. Classification Module
3. Experiments
4. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, X.Y.; An, J.; Chen, F. A Simple Method of Tempered Glass Insulator Recognition from Airborne Image. In Proceedings of the Processing of Optoelectronics and Image Processing (ICOIP), Haiko, China, 11–12 November 2010; pp. 127–130. [Google Scholar]
- Li, B.; Wu, D.; Cong, Y.; Li, X.Y.; Tang, Y. A method of insulator detection from video sequence. In Proceedings of the 2012 Fourth International Symposium on Information Science and Engineering, Shanghai, China, 14–16 December 2012; pp. 386–389. [Google Scholar]
- Han, Z.-X.; Qiao, Y.-H.; Sun, Y. Research on Insulator Fault detection Method of UAV Transmission line based on image recognition. Mod. Electron. Tech. 2017, 40, 179–181. [Google Scholar]
- Yang, W. Research on Insulator Recognition and State Detection Based on Aerial Photography Image. Ph.D. Thesis, North China Electric Power University, Beijing, China, 2016. [Google Scholar]
- Zhang, J.J.; Han, J.; Liu, L. Insulator recognition and fault diagnosis with shape sensing. J. ImageGraph. 2014, 19, 1194–1201. [Google Scholar]
- Zhao, Z.; Liu, N.; Wang, L. Localization of multiple insulators by orientation angle detection and binary shape prior knowledge. IEEE Trans. Dielectr. Electr. Insul. 2015, 22, 3421–3428. [Google Scholar] [CrossRef]
- Reddy, M.J.B.; Chandra, B.K.; Mohanta, D.K. A DOST based approach for the condition monitoring of 11 kV distribution line insulators. IEEE Trans. Dielectr. Electr. Insul. 2011, 18, 588–595. [Google Scholar] [CrossRef]
- Jiang, Y.; Han, J.; Ding, J. Glass Insulator Identification and Self-detonation Fault Diagnosis Based on Multi-feature Fusion. Electr. Power China 2017, 50, 52–58. [Google Scholar]
- Zhang, G.; Liu, Z. Fault Detection of Catenary Insulator Breakage/Inclusion Foreign Body Based on Corner Matching and Spectral Clustering. Chin. J. Sci. Instrum. 2014, 35, 1370–1377. [Google Scholar]
- Shang, J.; Li, C.; Chen, L. Insulator Location and Self-Detonation Fault Detection Based on Vision. J. Electron. Meas. Instrum. 2017, 31, 844–849. [Google Scholar]
- Feng, W.; Fan, P.; Yao, X.; Gu, S.; Zhou, Z.; Zhou, S. Transmission line insulator Defect Identification based on Deep Learning. J. Hydropower Energy Sci. 2021, 39, 176–178+50. [Google Scholar]
- Wang, Y.; Cao, P.; Wang, X.; Yan, X. Research on Insulator Self-detonation Detection Method Based on Deep Learning. J. Northeast. Dianli Univ. 2020, 40, 33–40. [Google Scholar]
- Qiu, L.; Zhu, Z. Research on Insulator Defect Detection of Transmission Lines Based on Deep Learning. Appl. Res. Comput. 2020, 37 (Suppl. S1), 358–360+365. [Google Scholar]
- Zeng, W. Research on Insulator Detection and Fault Recognition Based on Deep Learning. Ph.D. Thesis, Zhejiang University, Hangzhou, China, 2020. [Google Scholar]
- Prates, R.M.; Cruz, R.; Marotta, A.P.; Ramos, R.P.; Simas Filho, E.F.; Cardoso, J.S. Insulator visual non-conformity detection in overhead powerdistribution lines using deep learning. Comput. Electr. Eng. 2019, 78, 343–355. [Google Scholar] [CrossRef]
- Zhao, Z.; Zhen, Z.; Zhang, L.; Qi, Y.; Kong, Y.; Zhang, K. Insulator Detection Method in Inspection Image Based on Improved Faster R-CNN. Energies 2019, 12, 1204. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Pierre, S.; Scott, R.; Dragomir, A.; Dumitru, E.; Vincent, V.; Andrew, R. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 7–12. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 904–916. [Google Scholar] [CrossRef]
- Shin, H.C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SEGNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ghiasi, G.; Fowlkes, C.C. Laplacian pyramid reconstruction and refinement for semantic segmentation. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 519–534. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Washington, DC, USA, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large kernel matters—Improve semantic segmentation byglobal convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. DenseASPP for semantic segmentation in street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3684–3692. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, L.; Murphy, K.; Yuille, L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image seg-mentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention-MICCAI, Munich, Germany, 5–9 October 2015; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet++: A nested U-Net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Granada, Spain, 20 September 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Zhang, J.; Jin, Y.; Xu, J.; Xu, X.; Zhang, Y. MDU-Net: Multi-scale densely connected U-Net for biomedical image segmentation. arXiv 2018, arXiv:1812.00352. [Google Scholar]
- Song, W.; Zheng, N.; Liu, X.; Qiu, L.; Zheng, R. An improved U-Net convolutional networks for seabed mineral image segmentation. IEEE Access 2019, 7, 82744–82752. [Google Scholar] [CrossRef]
- Su, R.; Zhang, D.; Liu, J.; Cheng, C. MSU-Net: Multi-scale U-Net for 2D medical image segmentation. Front. Genet. 2021, 12, 639930. Available online: https://www.frontiersin.org/article/10.3389/fgene.2021.639930 (accessed on 10 October 2022). [CrossRef] [PubMed]
- Liu, J.; He, J.; Zhang, J.; Ren, J.S.; Li, H. EfficientFCN: Holistically-guided decoding for semantic segmentation. In Proceedings of the Computer Vision—ECCV, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 1–17. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. arXiv 2016, arXiv:1612.01105. [Google Scholar]
- He, J.; Deng, Z.; Zhou, L.; Wang, Y.; Qiao, Y. Adaptive pyramid context network for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7519–7528. [Google Scholar]
- Byeon, W.; Breuel, T.M.; Raue, F.; Liwicki, M. Scene labeling with LSTM recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3547–3555. [Google Scholar]
- Liang, X.; Shen, X.; Feng, J.; Lin, L.; Yan, S. Semantic object parsing with graph LSTM. In Proceedings of the Computer Vision—ECCV, Amsterdam, The Netherland, 11–14 October 2016; Springer International Publishing: Cham, Germany, 2016; pp. 125–143. [Google Scholar]
- Shuai, B.; Zuo, Z.; Wang, B.; Wang, G. Scene segmentation with DAG-recurrent neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1480–1493. [Google Scholar] [CrossRef]
- Lin, D.; Ji, Y.; Lischinski, D.; Cohen-Or, D.; Huang, H. Multi-scale context intertwining for semantic segmentation. In Proceedings of the Computer Vision—ECCV, Munich, Germany, 8–14 September 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 622–638. [Google Scholar]
- Hung, W.-C.; Tsai, Y.H.; Liou, Y.T.; Lin, Y.Y.; Yang, M.H. Adversarial learning for semi-supervised semantic segmentation. arXiv 2018, arXiv:1802.07934. [Google Scholar]
- Luc, P.; Couprie, C.; Chintala, S.; Verbeek, J. Semantic segmentation using adversarial networks. arXiv 2016, arXiv:1611.08408. [Google Scholar]
- Souly, N.; Spampinato, C.; Shah, M. Semi-supervised semantic segmentation using generative adversarial network. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5688–5696. [Google Scholar]
- Li, X.; Li, X.; Zhang, L.; Cheng, G.; Shi, J.; Lin, Z.; Tan, S.; Tong, Y. Improving semantic segmentation via decoupled body and edge supervision. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVII 16. pp. 435–452. [Google Scholar]
- Fan, R.; Wang, H.; Cai, P.; Liu, M. SNE-RoadSeg: Incorporating surface normal information into semantic segmentation for accurate freespace detection. In Proceedings of the Computer Vision—ECCV, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 340–356. [Google Scholar]
- Lin, G.; Shen, C.; Van Den Hengel, A.; Reid, I. Efficient piecewise training of deep structured models for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3194–3203. [Google Scholar]
- Yang, S.; Peng, G. Attention to refine through multi scales for semantic segmentation. In Proceedings of the Advances in Multimedia Information Processing—PCM, Hefei, China, 21–22 September 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 232–241. [Google Scholar]
- Wang, J.; Xing, Y.; Zeng, G. Attention forest for semantic segmentation. In Proceedings of the Pattern Recognition and Computer Vision, Salt Lake City, UT, USA, 18–22 June 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 550–561. [Google Scholar]
- Liu, X.; Xia, T.; Wang, J.; Lin, Y. Fully convolutional at-tention localization networks: Efficient attention localization for fine-grained recognition. arXiv 2016, arXiv:1603.06765. [Google Scholar]
- Wang, D.; Shen, Z.; Shao, J.; Zhang, W.; Xue, X.; Zhang, Z. Multiple granularity descriptors for fine-grained categorization. In Proceedings of the 2015 International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2399–2406. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Parameter | Name | Parameter |
|---|---|---|---|
| DDR | 128 GB | size | 214 × 214 × 3 |
| CPU | Inter Core i7 | iterations | 120 |
| GPU | 1080Ti | batch | 16 |
| system | Windows 10 | threshold | 0.4 |
| editor | Pycharm 3.8 | factor | 0.0005 |
| algorithm | NMS | learning rate | 5 × 10−5 |
| Size (MB) | FLOP/s | mAP (%) | FPS | Training Time (h) | |
|---|---|---|---|---|---|
| FCAN [37] (single-attention) | 31.6 M | 14.453 | 48.3 | 5.3 | 7.5 |
| MG-CNN [38] (single-granularity) | 24.3 M | 15.45 | 51.2 | 4.6 | 8.3 |
| RA-CNN (scale 1 + 3) | 22.3 M | 5.66 | 55.2 | 15.3 | 9.6 |
| RA-CNN (scale 2 + 3) | 24.5 M | 6.32 | 49.3 | 19.8 | 10.5 |
| RA-CNN (scale 1 + 2 + 3) | 20.2 M | 3.82 | 58.6 | 25.4 | 18.43 |
| Approach | Accuracy (%) |
|---|---|
| FCAN (single-attention) | 74.9 |
| MG-CNN (single-attention) | 75.6 |
| RA-CNN (scale 1) without initial | 79.4 |
| RA-CNN (scale 1) | 81.5 |
| RA-CNN (scale 2) | 80.8 |
| RA-CNN (scale 2 + 3) | 83.6 |
| RA-CNN (scale 1 + 2) RA-CNN (scale 1 + 3) | 78.2 81.4 |
| RA-CNN (scale 1 + 2 + 3) | 85.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Wan, H.; Huang, D.; Liu, J.; Tang, X.; Gan, L. Sustainable Analysis of Insulator Fault Detection Based on Fine-Grained Visual Optimization. Sustainability 2023, 15, 3456. https://doi.org/10.3390/su15043456
Wang L, Wan H, Huang D, Liu J, Tang X, Gan L. Sustainable Analysis of Insulator Fault Detection Based on Fine-Grained Visual Optimization. Sustainability. 2023; 15(4):3456. https://doi.org/10.3390/su15043456
Chicago/Turabian StyleWang, Linfeng, Heng Wan, Deqing Huang, Jiayao Liu, Xuliang Tang, and Linfeng Gan. 2023. "Sustainable Analysis of Insulator Fault Detection Based on Fine-Grained Visual Optimization" Sustainability 15, no. 4: 3456. https://doi.org/10.3390/su15043456