1. Introduction
Remote sensing image classification is an important link in the application of remote sensing technology. With the progress of remote sensing data acquisition technology [
1], the information of high-resolution remote sensing images shows a trend of massive growth, and the number and diversity of target samples also increase dramatically [
2]. Early image classification is mainly based on manually extracted image features. These methods mainly rely on experts with a lot of professional knowledge and practical experience to design various image features. Several of the most representative manual description features include color histogram, texture feature, direction histogram and scale invariant feature transformation. Although these classification methods are intuitive and easy to understand, the description ability of these features is very limited when faced with complex images. In recent years, machine learning methods [
3] based on probability and statistics have provided many feasible methods for remote sensing image classification. Typical machine learning methods include classification methods such as support vector machine, decision tree, principal component analysis and k-means clustering. The classification methods of machine learning mentioned above belong to shallow learning networks [
4], and it is difficult to establish complex function representations and cannot adapt to remote sensing image classification of complex samples. The emergence of deep learning provides a new method for land cover classification [
5,
6,
7]. Deep learning is a kind of neural network with deep structure, which can extract the features of remote sensing images better than models with shallow structure such as artificial neural network and support vector machine [
8]. Its motivation is to establish neural networks that simulate human brain for analysis and learning. It can learn more useful features through massive training data and deep models with many hidden layers, and ultimately improve the accuracy of classification.
With the rapid development of deep learning [
9,
10,
11], many scholars have proposed effective high-resolution remote sensing image segmentation methods [
12,
13,
14,
15,
16] for remote sensing image feature extraction [
17,
18,
19]. In the process of image acquisition and processing, image noise increases. Noise reduces the visibility of image edges, thus introducing false edge information, resulting in poor segmentation performance of object contours. Full convolution neural network FCN [
20] makes image segmentation enter a new stage. These pixels can not only classify objects according to their categories, but also improve the accuracy of image segmentation. We found that the main problem based on the FCN model at present is the lack of appropriate strategies to use global scene category clues. For the understanding of typical complex scenes, in order to obtain global image level features, the spatial pyramid pool is widely used, in which spatial statistics provide a good descriptor for the overall scene interpretation. Different from these methods, in order to combine appropriate global features, Zhao et al. proposed the Pyramid Scene Parsing Net (PSPNet) [
21]. It can embed the context features of difficult scenes into FCN’s pixel prediction framework, fully understand the scene, and accurately predict each pixel category, position and shape. The local and global information are fused together to make the final prediction more reliable. Ronneberger et al. proposed a U-Net network [
22] for medical image processing, improved the feature fusion method based on the FCN network framework, and fused features of different levels. The PAN [
23] paper combines the Attention mechanism with the pyramid structure, which can extract the relatively low level precise dense features based on the high-level semantic guidance, replacing the complex hole convolution and multiple codec operations in other methods, and jumping out of the usual U-Net structure. Due to the large difference in the scale of the objects contained in the remote sensing image and the complex boundary of the objects, it is difficult to accurately extract the features of the remote sensing image, which makes it difficult to accurately segment the remote sensing image. Chen et al. proposed a multi-level aggregation network [
15] for semantic segmentation of high-resolution remote sensing images, which extracts depth global features by learning the relationship between all positions in the context through a global dependency module, and filters redundant channel information to optimize segmentation results. Xia et al. proposed a separable attention network based on different size fusion [
24]. The method uses residual neural network as the backbone network to obtain the information features of rivers. Through attention modules of different scales, the deep feature information and shallow feature information of rivers are fused. The shallow features and large scale attention module are used to locate the main position of the river, and the deep features and small scale attention module are used to finely segment the river edge, so as to accurately extract the river from the background. Thus, the problems that traditional detection methods cannot identify small tributaries and the edge information is rough are solved.
The above network solves many problems of remote sensing image semantic segmentation [
25,
26]. However, the existing semantic segmentation networks use more multi-scale fusion of feature maps to enhance the effect of image segmentation [
27], and pay less attention to the horizontal direction information, resulting in misjudgment of buildings and loss of local information of water bodies. Generally, the down sampling operation is used to extract abstract semantic features, so high resolution details are easy to lose, and local details are inaccurate, edges are fuzzy, and buildings are misjudged in the segmentation results.Therefore, the land cover classification model based on semantic segmentation needs to be improved to extract feature information between the horizontal directions of the image. In order to solve this problem, a local feature search network for building and water area segmentation in high-resolution remote sensing images is proposed. The network strengthens the semantic extraction of image horizontal direction and location information, reads sensitive information through direction and location, enables the model to more accurately locate and identify the target area, captures cross channel information, and embeds location information into channel attention, To efficiently integrate the spatial coordinate information, so as to improve the local information loss and misjudgment of buildings in the process of building and water area segmentation, enhance the search ability of local features of the network, and ultimately improve the semantic segmentation ability.
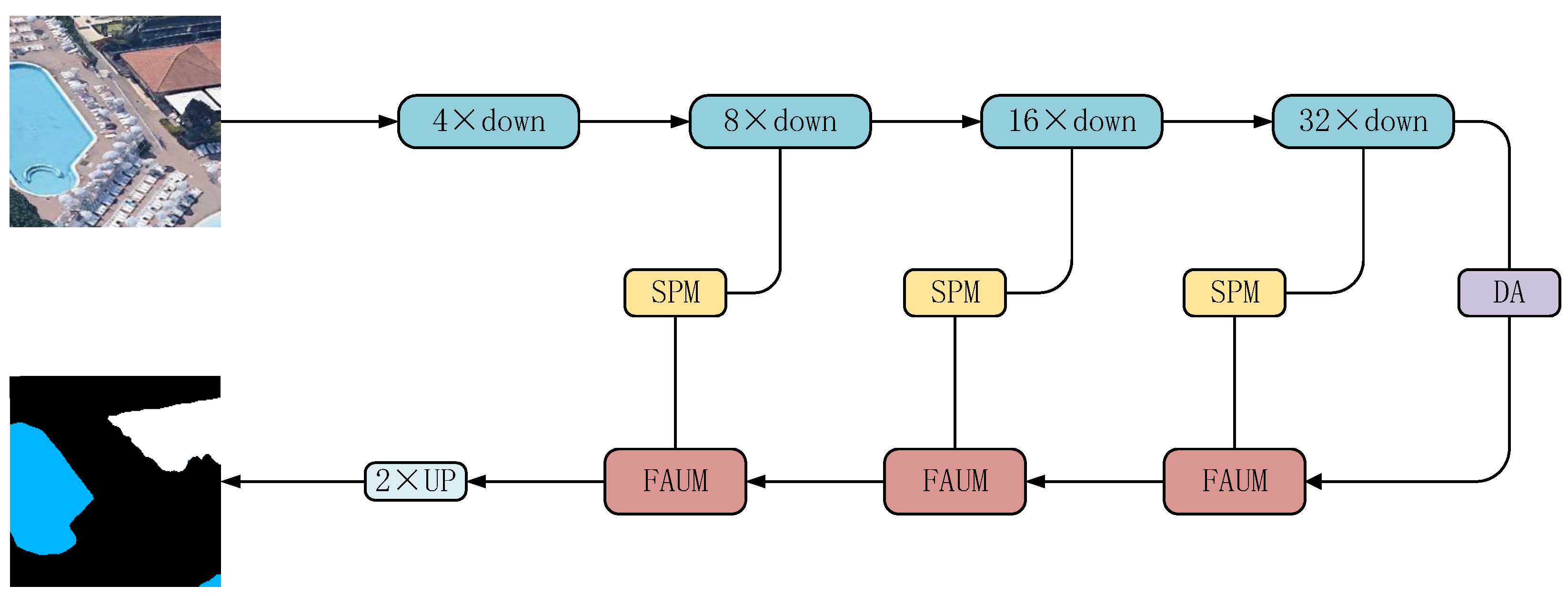
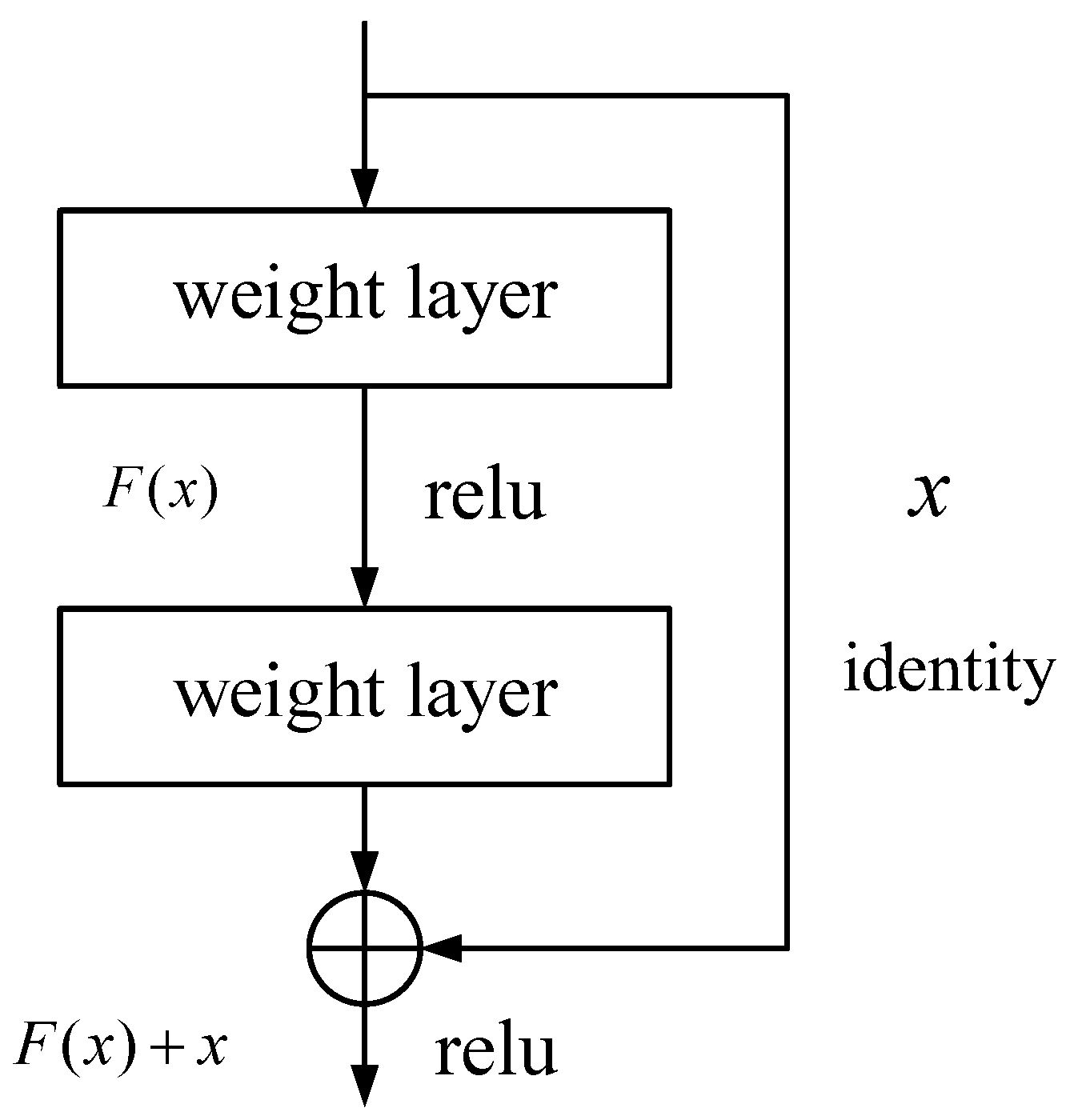
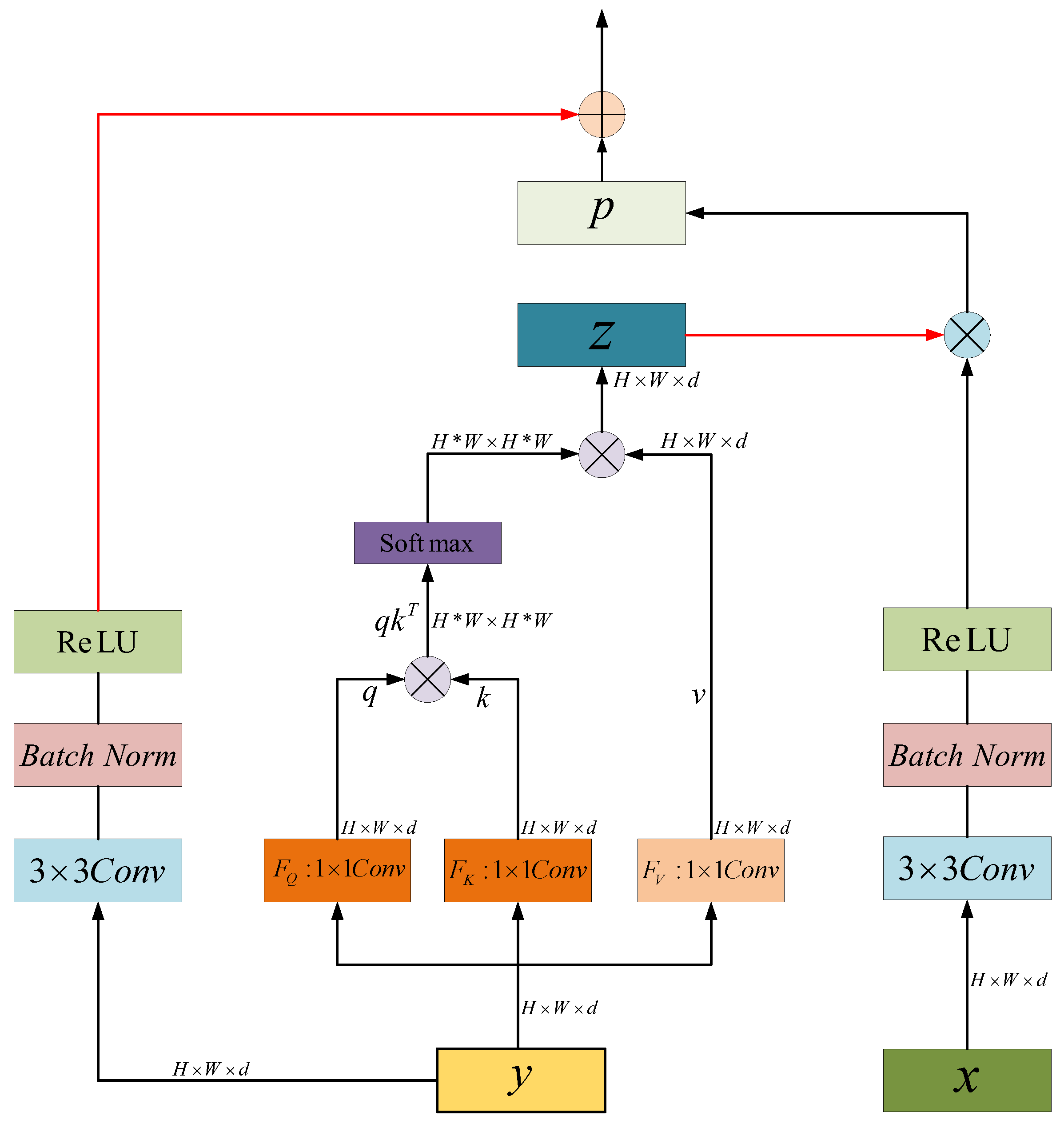
In our proposed local feature search network, ResNet18 is used as the backbone network for feature extraction to obtain feature information with rich semantic information. Then, a discarding attention module DAM is constructed to read sensitive information through direction and location, discard irrelevant information, and make the model locate and identify the target area more accurately. In addition, the SPM chip pooling module we propose can acquire a large receptive field in pixel by pixel prediction tasks through parallel pooling operation, and the network can capture a wide range of context information, thus avoiding the establishment of most unnecessary connections between locations far away from each other, so as to improve the ability to capture remote spatial dependencies and utilize inter channel dependencies. The FAUM fusion attention up sampling module proposed in this paper is used to guide the backbone network feature map to obtain the feature information on the spatial dimension. Finally, the feature map is recovered through up sampling, and the output result is a more detailed prediction image, while providing better pixel level attention for high-level feature maps. Experiments on high resolution remote sensing image semantic segmentation dataset show that the MIoU of the proposed local feature search network, DSFNet, reaches 83.73%. Compared with the existing semantic segmentation model, this model has the highest accuracy, which verifies the effectiveness of this model.
Contributions of this paper are as follows:
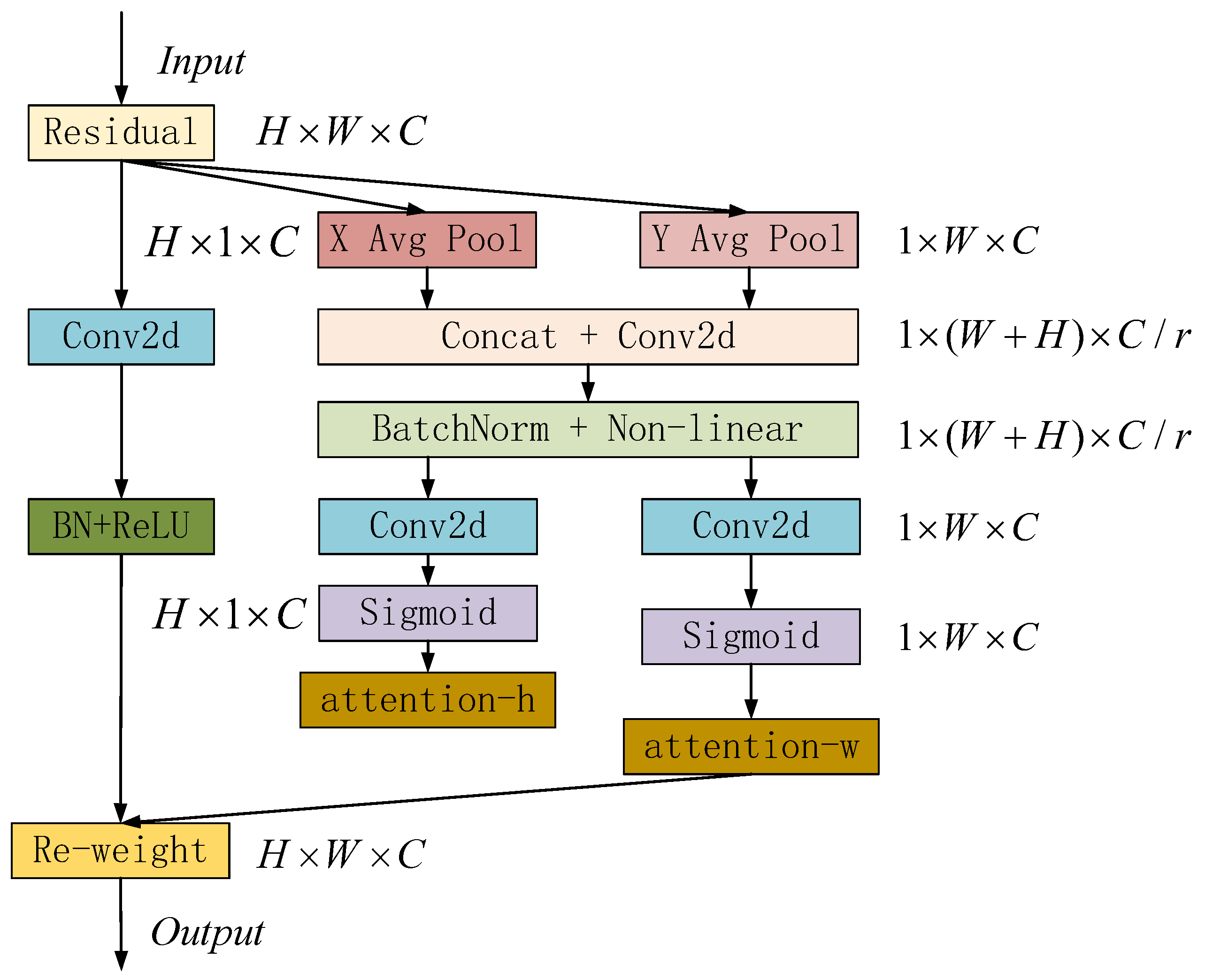
1. This paper proposes a local feature search network for building and water area segmentation in high-resolution remote sensing images. The Discard Attention Module (DAM) reads sensitive information through direction and location, discards irrelevant information, and enables the model to locate and identify the target area more accurately. It can not only capture cross channel information, but also integrate spatial coordinate information efficiently by embedding location information into channel attention, so that mobile networks can obtain larger area information without introducing large overhead. This method can better solve the problems of misjudgment of large areas of buildings and edge blurring in the process of water area segmentation.
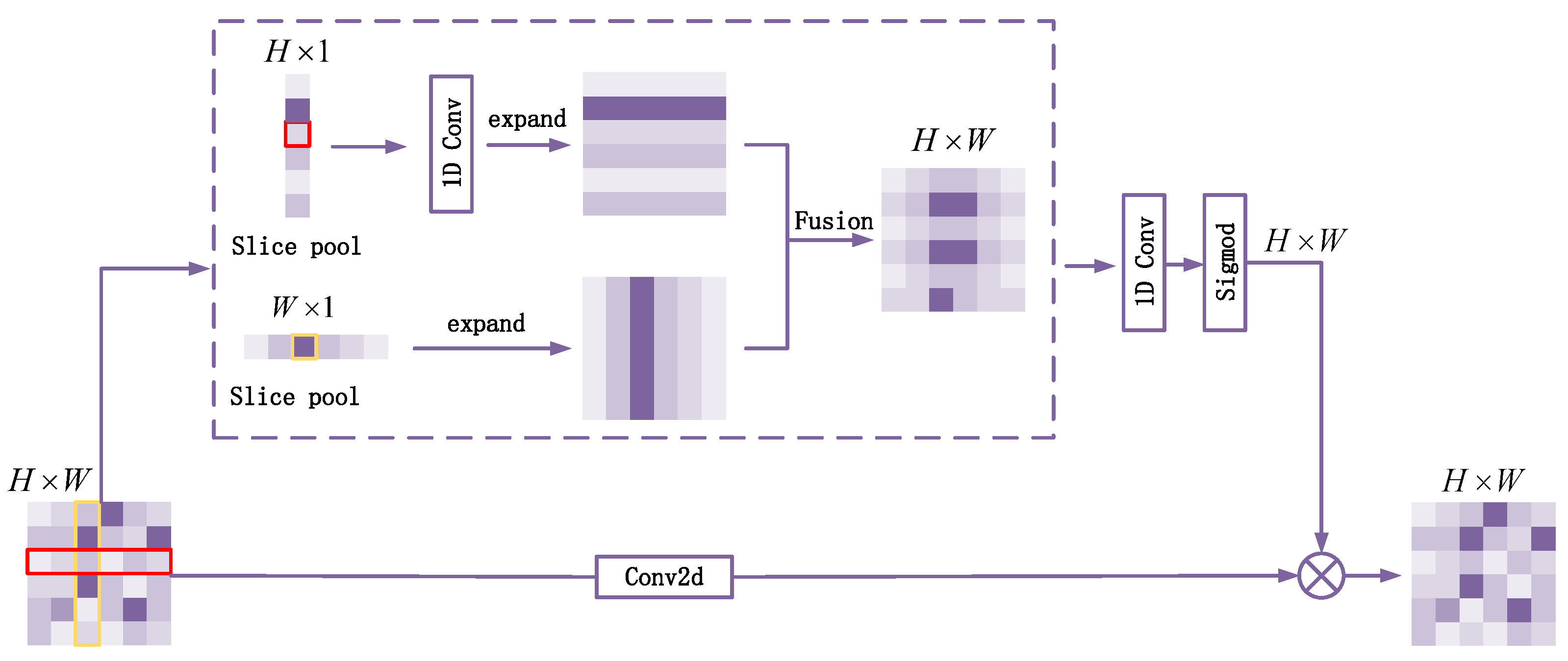
2. In the work, the Slice Pooling Module (SPM) is built to obtain a large receptive field in the pixel by pixel prediction task through parallel pooling operation, so that the network can capture a wide range of context information, and the range of slice pooling considerations is long and narrow, rather than the entire feature map, thus avoiding the establishment of most unnecessary connections between locations that are far away from each other, to improve the ability to capture remote spatial dependencies and utilize inter channel dependencies.
3. The Fusion Attention Upsampling Module (FAUM) built in the project is used to guide the backbone network feature map to capture the feature information of remote spatial dimensions and channels. The feature information of horizontal direction and position is extracted from the discard attention module (DAM) and slice pooling module (SPM), so as to efficiently integrate the spatial coordinate information and provide better pixel level attention for high-level feature maps. It can effectively enhance the local information search ability of the model and improve the segmentation accuracy.
The rest of this article is organized as follows:
Section 2 describes DFSNet and the functions of each module.
Section 3 describes the experimental setup and data details.
Section 4 summarizes the corresponding work of this paper and puts forward the future research direction.
3. Experiment and Result Analysis
In order to verify the effectiveness of the local feature search network (DSFNet) proposed in this paper, we conducted experiments on our own land cover dataset and Massachusetts Buildings Dataset to verify the accuracy and generalization of the model. The quantitative analysis indexes of the experiment were pixel accuracy (PA), category average pixel accuracy (MPA), and average intersection to union ratio (MIoU). The model proposed in this paper is compared with the current excellent semantic segmentation models BisenetV2 [
40], ExtremeC3 [
41], FCN8s, PAN, PSPNet, Unet, SegNet [
42], EsNet [
43], EDANet [
44], LinkNet [
45], DeeplabV3plus [
46], OcrNet [
47], MSResNet [
48]. The experimental results show that the neural network model proposed in this paper is superior to the comparison model in many evaluation indexes, which proves that the local feature search network (DSFNet) proposed in this paper has better segmentation effect in remote sensing image building and water body segmentation.
3.1. Datasets
3.1.1. Landcover Dataset
The main data set comes from Google Earth, which presents satellite photos, aerial photos and GIS in the form of 3D models. Capture several images on Google Earth with a resolution of
. These large maps have a large space span and various shooting angles. They roughly fall into the following categories: villas in North America, villages and forests in Europe, Britain, France and Germany, and coastal rivers in China. To sum up, the coverage of the data set, including many complex terrain environments, realistically simulates the real land cover segmentation task scenarios, and fully examines the real detection capability of the model. These pictures are manually marked as three types of objects: buildings (white, RGB [255,255,255]), waters (blue, RGB [0,180,255]), and backgrounds (black, RGB [0,0,0]). The dataset is composed of 2000 large
images cut into
images. The training data diagram is shown in
Figure 6. The corresponding colors of the categories in
Figure 6 are shown in
Table 2.
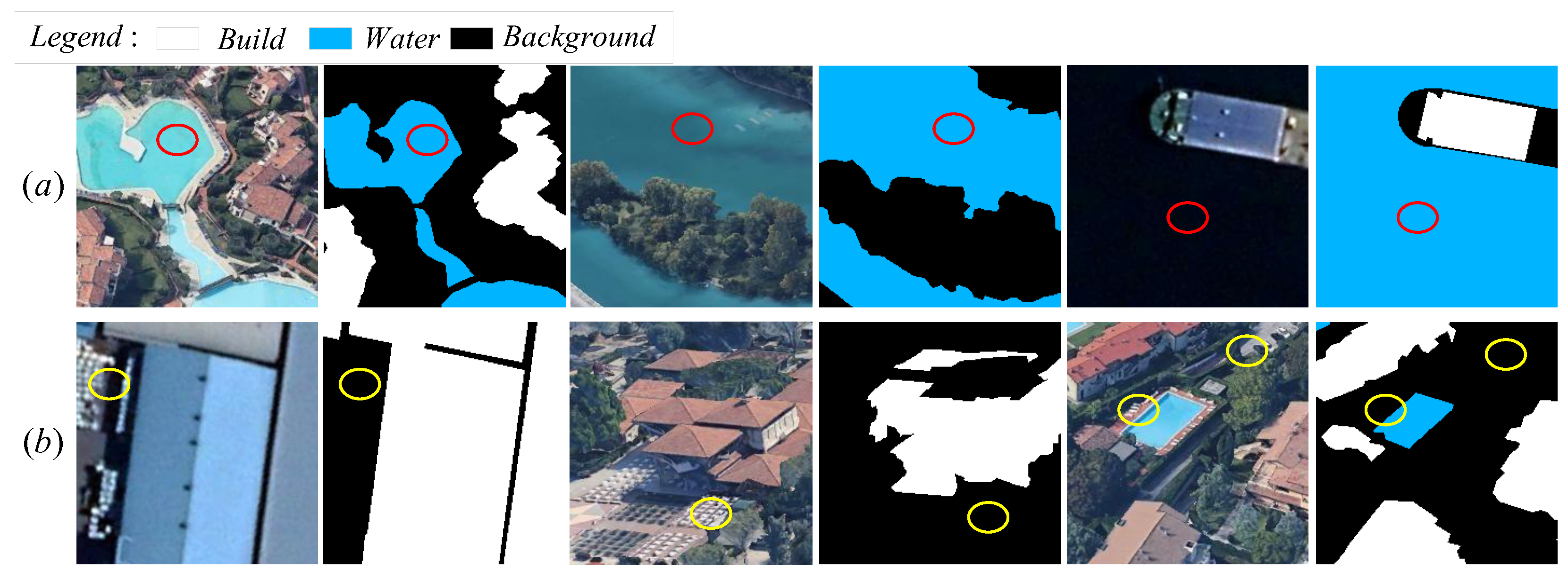
The semantic segmentation of the dataset is difficult. In addition to the multi-resolution and spatiotemporal span mentioned above, there are also strict definitions of three types of objects. The height difference of buildings is large, and the shadow casting of high buildings and trees will affect the edge contour segmentation of low buildings; Some waters will feed back different spectral information in different spaces. These remote sensing images with orthographic projection may cause indiscernibility in appearance. Objects circled by yellow lines look like low buildings, but they are actually roads and rows of storage boxes. To sum up, the entire dataset is complex and difficult to learn, and it is also difficult to make extremely accurate land cover segmentation and perfect target classification. Therefore, the proposed model has a better segmentation effect than the comparison model.
When processing this dataset, all images are segmented from left to right and from top to bottom, and there is no regional overlap during segmentation. As a result, more than 1500 images in total are selected for data enhancement [
49] such as rotation and folding of 200 more complex images. Re-clean the collected data set, remove the solid color image with only black background in the label, and finally obtain the data set of more than 2000 images. Then they are randomly divided into training sets and test sets according to the ratio of 7:3.
3.1.2. Massachusetts Buildings Dataset
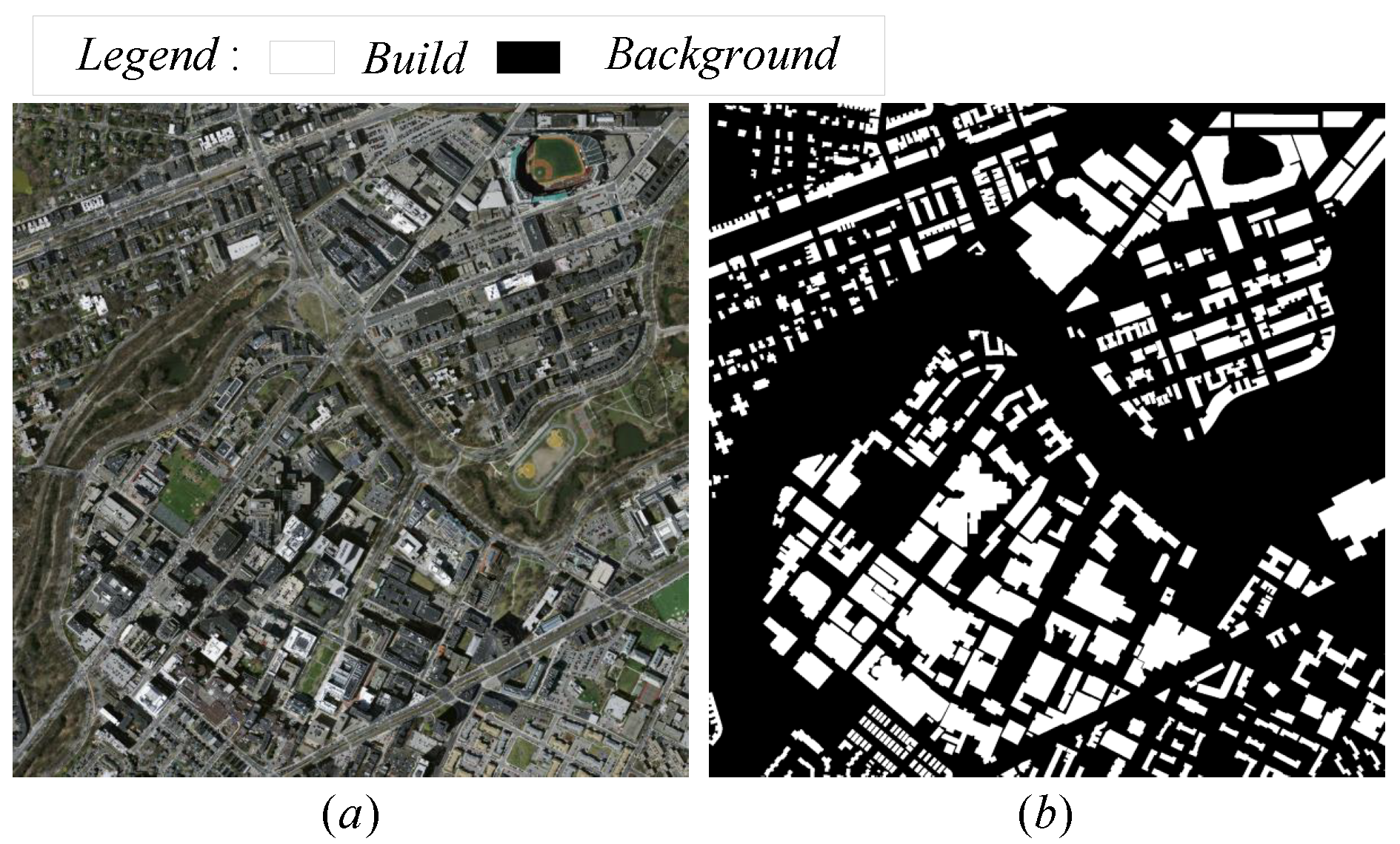
To verify the generalization capability of the proposed model, we used the Massachusetts Building Data Set.The Massachusetts Building Data Set consists of 151 aerial images of the Boston area, each with a pixel of
and an area of 2.25 square kilometers.Therefore, the entire dataset covers about 340 square kilometers. The target map is obtained by rasterizing the building contour lines obtained from the OpenStreetMap project. The Boston area selected in this paper is used for experiments. The data set is named Boston-A, which contains 64 original images and an average size of
. A in
Figure 7 is the original image, and b in
Figure 7 is the label. Boston—A consists of two categories: architecture and background. See
Table 3 for the corresponding colors of the categories in
Figure 7.
Since the original image size of Boston A is too large to directly input model training, we take the original data image (size ) cut into small size pictures, 2176 pictures obtained, of which the size is . Finally, a new data set is obtained. There are 1523 pictures in the training set and 653 pictures in the test set.
3.2. Implementation Details
We take pixel accuracy (PA), category average pixel accuracy (MPA), and average intersection/merge ratio (MIou) as the evaluation indicators of the model. The network training parameters are as follows: use a single GTX3070 graphics card on the Windows platform for reasoning calculation. The model is built using the deep learning framework pytorch. All models have been trained for 300 epochs, with an initial learning rate of 0.001 and a batch size of 3. Set the weight attenuation of Adam optimizer to 0.0001, and the other parameters are the default values.
3.3. Ablation Study of Attention Module
In the ablation experiment, DAM modules are added to the second, third and fourth layers of the decoding path, allowing the attention module to capture the long-term dependence along one spatial direction and save the location information along the other spatial direction, which helps the network locate the target of interest more accurately. SPM module is added in the first layer to capture a wide range of context information. At the same time, the fusion attention up sampling module FAUM is used as the decoding block to fuse the details between channels, providing better pixel level attention for high-level feature maps. In order to verify the effectiveness of the above modules, several ablation experiments were carried out on the master dataset. As shown in
Table 4, the combination of different modules with ResNet18 as the baseline network significantly improves the network performance. Specifically, compared with the baseline, only adding FAUM modules has brought 8.16% improvement to MIoU. These results strongly prove the advantages of decoding paths constructed with FAUM modules. Only adding SPM and FAUM modules further improves the network performance, bringing 6.81% improvement to MIoU, and only adding DAM and FAUM modules brings 6.36% improvement to MIoU. After all the modules proposed in this paper are combined, compared with the best MIoU results of other methods, the classification capacity is increased by 2.89%, with the highest value reaching 83.73%.
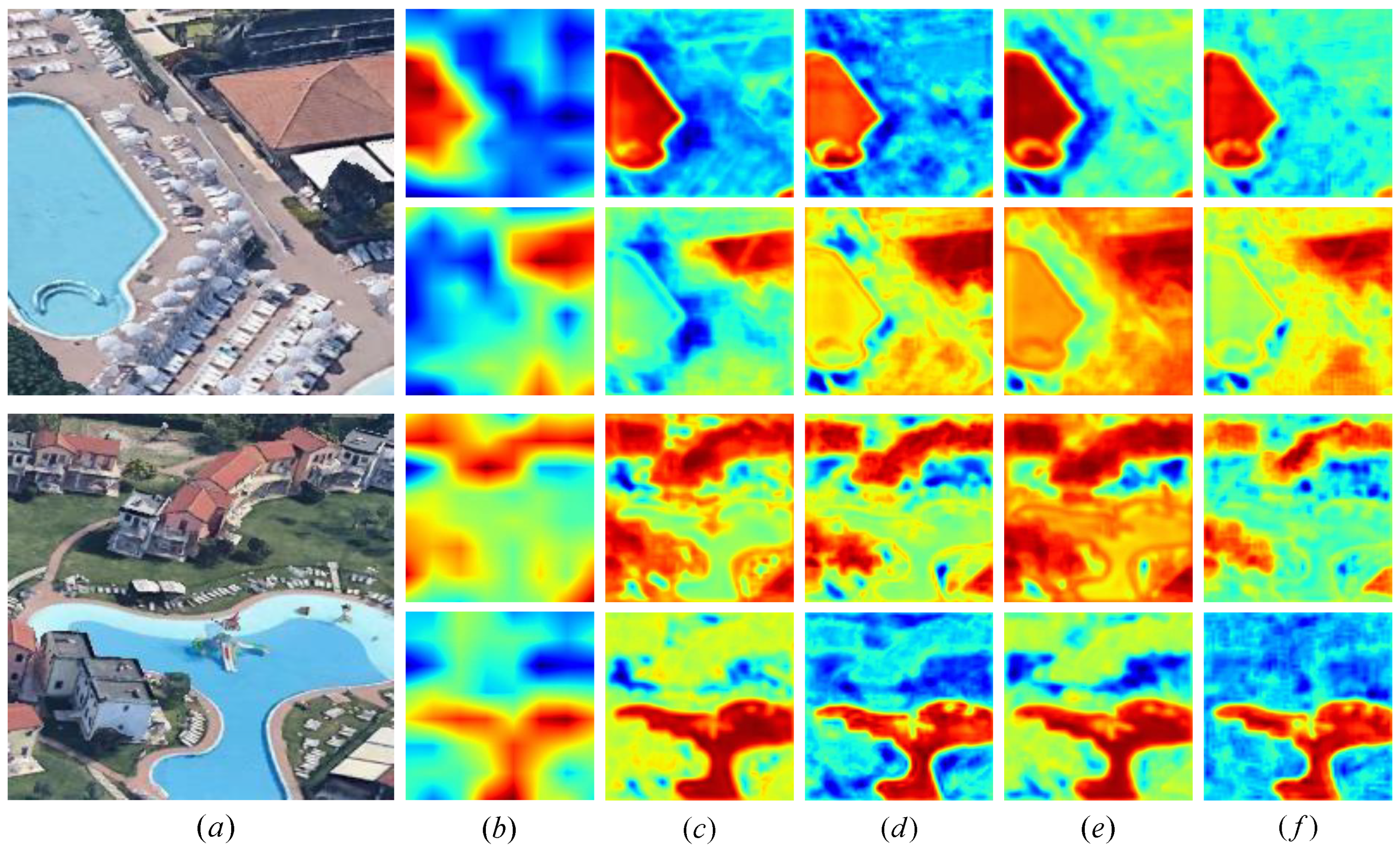
In order to further analyze the impact of different modules, several representative examples of land cover classification results are compared, as shown in
Figure 8. The baseline sensor without decoding path only gives the approximate location of the land cover category, and it is difficult to identify small-scale ground objects (
Figure 8b). As a decoding module, FAUM module improves the ability of DSFNet to recognize spatial details, but it has poor performance in accurately obtaining building and water area edge information (
Figure 8c). SPM module and DA module improve the search ability with low class variance characteristics (
Figure 8d,e) to a certain extent, which proves their ability to capture remote spatial dependencies and utilize inter channel dependencies. As shown in
Figure 8f, DSFNet with baseline and integration of all modules has significantly improved in identifying the confusion features and spatial details between classes, and the local feature information of buildings and water bodies is clearer. In general, each module used in DSFNet enables the network to capture remote spatial dependencies, read local sensitive information through direction and location, enable the model to more accurately locate and identify the target area, and ultimately improve the classification capability.
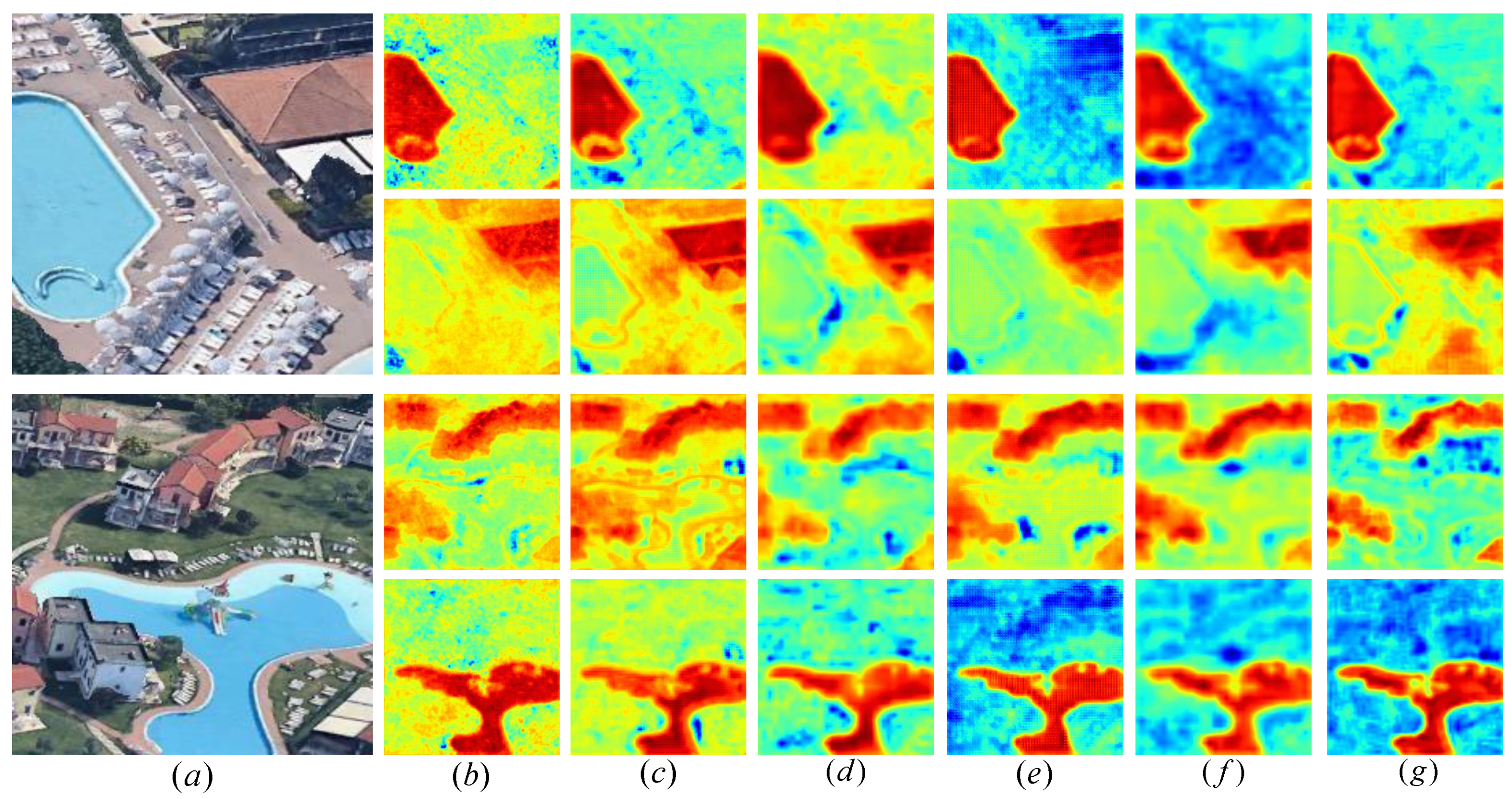
Comparison of the Effects of Thermal Maps of Ablation Experiments
Figure 9 shows the comparison of thermographic effects of different modules added in the ablation experiment. Orange red is the key part of the module, and yellow green and blue are the secondary parts. The first behavior module of each sample focuses on the effect of water, and the second behavior module focuses on the effect of buildings. It can be seen from column (b) that only baseline can not pay enough attention to water and buildings. After the FAUM module is added, the water area and building boundaries become clearer. From column (d), it can be seen that after only the SPM module is integrated, the local information of water area and buildings is supplemented. From column (e), it can be seen that only the color of the focus area of the integrated DAM module is deepened, and the water area and the interior of the building are supplemented. The method proposed in (f) makes the model pay more attention to the target area, especially the local information, so that more accurate target location and boundary segmentation can be obtained.
3.4. Experimental Results and Visual Analysis on the Master Data Set
In order to verify the effectiveness of our model, we conducted experiments on the land cover dataset, and the indicators on the test set exceeded the existing model. The specific experimental results are shown in
Table 5, and the visual contrast effect is shown in
Figure 10 and
Figure 11. The comparison models include BisenetV2, ExtremeC3, FCN8s, PAN, PSPNet, Unet, SegNet, EsNet, EDANet, LinkNet, DeeplabV3plus, OcrNet, and MSResNet. The backbone networks of FCN8s, PAN, DeeplabV3+, PSPNet and MSResNet are VGG16, ResNet-50, ResNet-101, ResNet-50 and ResNet-34 respectively. The backbone networks should be consistent with the original text as much as possible.
It can be seen from
Table 5 that the DSFNet, MPA, PA and MIoU proposed in this paper obtain 91.52%, 91.03% and 83.74% respectively. The network proposed in this paper strengthens the importance search between local features, effectively reads local information through direction and location, so that the model can more accurately locate and identify the target area, thus reducing the misjudgment of buildings in remote sensing images and the loss of water area information. All three indicators exceeded the comparison network. The lowest index is the FCN-8s with VGG16 as the backbone network. The PA and MIoU reach 81.71% and 65.35% respectively. Compared with FCN8s, the index of SegNet obtained by modifying VGG-16 based on FCN has a certain improvement, with PA of 87.78% and MIoU of 75.23%. LinkNet uses each encoder and decoder to connect to recover the spatial information lost in the downsampling operation. Compared with SegNet, the segmentation accuracy is improved to a certain extent. The PA and MIoU are 88.30% and 77.80% respectively. PAN uses the attention mechanism and spatial pyramid structure to extract dense features. Compared with LinkNet, PA and MIoU have a certain improvement, 89.12% and 77.86% respectively. The segmentation accuracy of EDANet using asymmetric convolution is the same as that of PAN, which is not improved, but slightly higher than that of PAN in PA. Compared with EDANet, ExtremeC3Net based on improved C3 module has a certain improvement in segmentation accuracy, with a MIoU of 78.75%.
DeepLabV3+uses expansion convolution to obtain larger receptive field, and the segmentation accuracy MIoU is improved by 0.45% compared with ExremeC3Net. BiseNetV2, which uses auxiliary loss to make the network converge better in shallow layers, has a certain improvement in segmentation accuracy compared with DeepLabV3+in PA and MIoU, which are 89.50% and 79.47% respectively. The nearly symmetric decoder encoder architecture is adopted for the EsNet network, and the segmentation accuracy MIoU is improved to a certain extent compared with BiseNetV2, with a MIoU of 79.65%. Compared with EsNet, the segmentation accuracy of UNet on PA and MIoU has improved to a certain extent, which are 89.35% and 79.98% respectively.
OcrNet uses the representation of corresponding object classes to calculate the representation of object regions. Compared with UNet, the segmentation accuracy of PA and MIoU has improved to a certain extent, 90.06% and 80.49% respectively. PSPNet uses depth convolution network to extract advanced feature information, and uses pyramid module for multi-scale fusion. Compared with OcrNet, the MIoU of segmentation accuracy is improved to a certain extent, and the MIoU is 80.85%. The MIoU index of FENet on the test set exceeds the 12 models compared, and the MIoU index is 2% higher than the highest PSPNet.
In order to facilitate the visual comparison of model prediction results, we visualized the prediction results of different models and obtained
Figure 10 and
Figure 11.
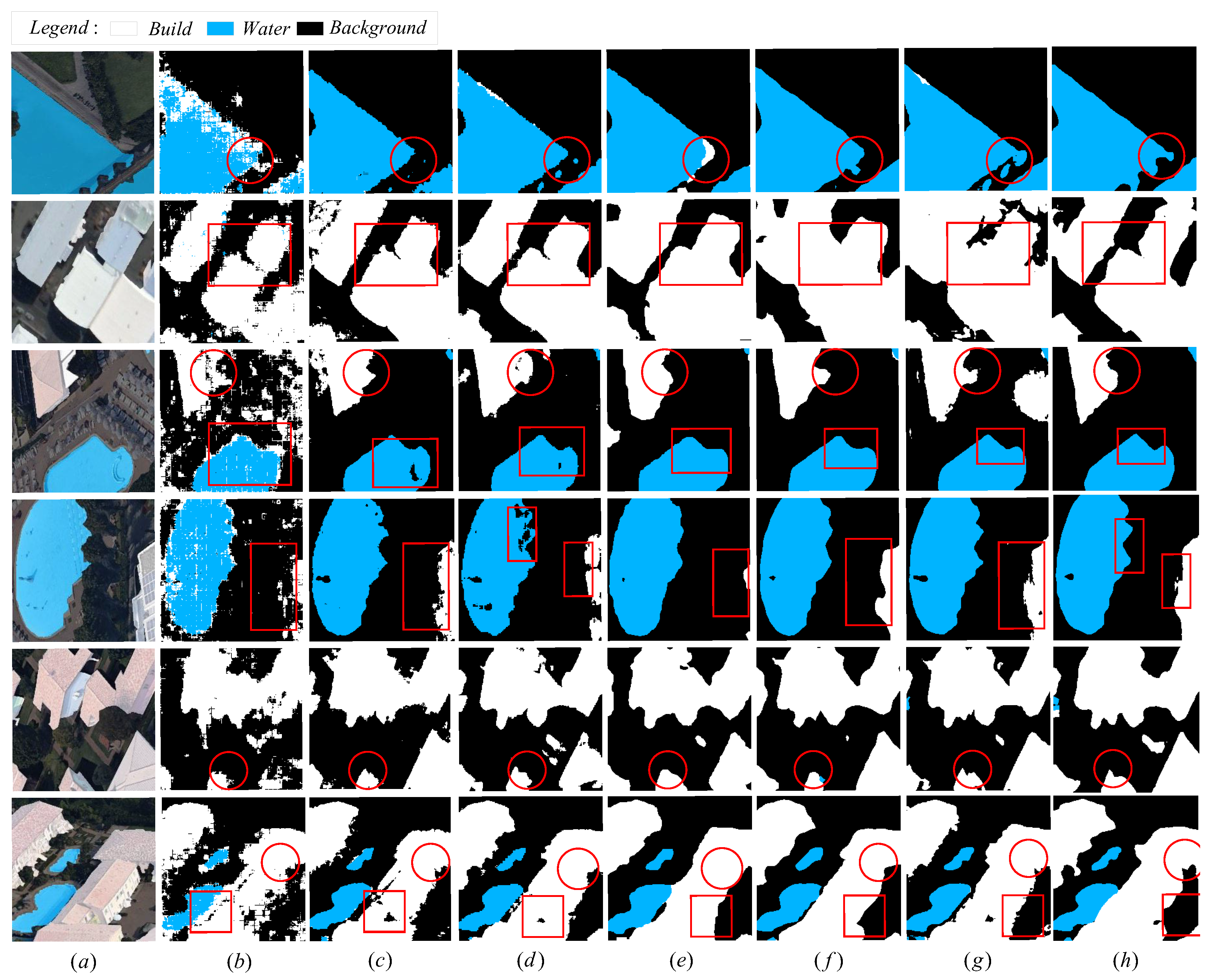
Figure 10 shows a total of six prediction graphs, and each column in
Figure 10 represents the prediction graph of a model.
Figure 10 has 8 columns in total. Column a is the superposition of images and labels, and column b, c, d, e, f, g, h correspond to FCN8s, SegNet, LinkNet, PAN, EDANet, ExtremeC3, DSFNet (Ours) respectively. From the column of b, we can see that the neural network proposed in this paper has good performance in piecewise noise control. The segmentation realizes the accurate extraction of houses and waters, and greatly reduces the misclassification of houses and waters. This achievement is attributed to DSFNet (ours), which makes up for the sensitive information of local locations that is easily ignored by existing networks, and reads local sensitive information fully through directions and locations, thus avoiding the establishment of most unnecessary connections between locations that are far away from each other, so as to improve the ability to capture remote spatial dependencies and make use of inter channel dependencies, and help to achieve accurate classification. It is not difficult to see that there will be obvious misjudgments from columns b, c, d, and e, The local feature search network (DSFNet) proposed by us can overcome these difficulties and accurately classify the background and water. e. Although the columns f and g basically realize the classification of background, water area and buildings, their edges are blurry and water is wrongly identified as a building. From the circles and boxes marked in the figure, we can see that DSFNet has better ability to express local details, thanks to the network’s ability to search for local features, thus giving mask images more details.
Figure 11 shows a total of six prediction graphs. Each row in
Figure 11 represents the prediction graph of a model.
Figure 11 has 8 rows in total. Column a is the superposition of images and labels, and columns b, c, d, e, f, g, h, and i correspond to DeepLapV3+, BiseNetV2, EsNet, UNet, OcrNet, PSPNet, MSResNet, and DSFNet (Ours) respectively. Because the models compared in
Figure 11 want to improve the accuracy of the models compared in
Figure 10, the classification effect is a little better than that of the models compared in
Figure 10. However, lines b, d, and e still clearly misjudge the water area as a building, lines b and c even judge the building as a water area, and line g misjudges the water area as a background. Our local feature search network (DSFNet) model alleviates these problems, The basic contours of buildings and water areas are basically extracted, which effectively solves the problems of misjudgment of buildings and disconnection of water areas, and endows the image with more detailed local features. This is the result of the fusion of the direction and location feature information extracted by SPM and DAM modules with the backbone network feature. The fused feature map contains not only rich location information of the backbone network, but also more local features of horizontal direction and location, The problem of unclear water area and buildings is effectively improved. The DSFNet network proposed by us fully captures the horizontal direction and local location information, provides rich semantic information feature maps, and realizes the effective extraction of building and water area contours.
Comparison of Thermodynamic Diagram Effects of Different Models
Figure 12 shows the comparison of the effects of thermal maps of different models. The first line of each sample focuses on the water area, and the second line focuses on the buildings. The orange red area is the focus of the model, and the yellow green and blue are the secondary parts. According to the results of the thermal map, SegNet did not pay enough attention to the water area and the internal information of the building, which also led to the poor display effect. LinkNet, EDANet, EsNet and PSPNet pay more attention to the target area, but pay less attention to the boundary and local information. Our proposed local feature search network (DSFNet) can significantly enhance the focus on local and boundary information, so it can obtain more accurate target location and clearer boundary segmentation.
3.5. Massachusetts Building Data Set Generalization Experiment Results and Visual Analysis
Since it is difficult for a single data set to reflect the generalization performance of the model, we use the Massachusetts building data set to test the generalization performance of the model. The experimental results on the dataset are shown in
Table 6. It can be seen from
Table 6 that the segmentation accuracy PA and MIoU of the neural network DSFNet proposed by us reach 93.46% and 84.69% respectively. The above indicators exceed the comparative models, proving the effectiveness and good generalization ability of the model proposed in this paper.
In order to intuitively compare the segmentation effect of the model, we show the effect picture in
Figure 13. Through comparison, we can find that our proposed local feature search network (DSFNet) fully captures the horizontal direction and local location information, and greatly reduces the misclassification of buildings. Column g in
Figure 13 is the effect picture of the building we predicted. It can be seen from the red circles and boxes in the picture that compared with other comparison models, the local features of the building we proposed are clearer, and there is no large area of misjudgment and noise. This is due to the excellent search ability of the model for local features. This is the result of the integration of the DAM module and SPM module with the backbone network feature map through the FAUM module. The fused feature map contains not only the rich location information of the backbone network, but also the horizontal direction and location information of the hidden feature map, which realizes the effective extraction of building contour and local features, and fully proves the effectiveness and good generalization ability of the model proposed by us.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}