1. Introduction
Global food production needs to double by 2050 in order to meet the demand of the rapidly growing population [
1,
2]. On the other hand, the current yield of growth rates for the major cereals that are grown across the globe are not high enough to meet this target [
3]. Environmental changes, particularly global warming and climate variability, are key concerns that have a negative impact on agriculture [
4]. This may result in a decline in crop production [
5], making the world more food insecure. As the global population is projected to reach 9 billion people by 2050, governments all over the world need to be well prepared to deal with supply shocks of major cereals.
The FAO (Food and Agriculture Organization) reports that the demand for and consumption of grains have grown significantly relative to production in developing nations such as India. From 1964 to 2030, there will have been an increase in demand for rice, wheat, and other coarse grains [
6]. Cereal imports in developing countries increased significantly to meet the rising demand, growing from 39 million tons annually in 1970 to 130 million tons annually by 1997–1999. The increase in imports is anticipated to continue and may be accelerated in the upcoming years. These developing nations are predicted to import 265 million tons of grains by 2030, which is 14% of their total yearly consumption [
6]. Nations that do not consider taking action to lessen their overall reliance on imports for conventional crops could suffer greatly as a result of these conditions. Therefore, it is a global challenge to alter the current situation in the future and make nations more and more self-sufficient in meeting their food demands, which in turn requires accurate and timely forecasting of crop yields. Crop yield prediction is one of the most difficult tasks in precision agriculture. The ability to forecast crop yields enables the relevant authorities to make appropriate decisions to ensure food security. In addition to soil, genotype, and management techniques, weather conditions have a significant impact on crop yield [
7]. Around 30% of annual production is lost due to unfavorable weather conditions all over the world [
8]. As a result, there is a significant demand for models that provide accurate yield predictions before a harvest, which may be utilized by the government, policymakers, and farmers to plan ahead of time.
One of the most important and difficult jobs in applied sciences is future prediction. It requires computational and statistical approaches for identifying relationships between past and short-term future values, as well as adequate strategies to deal with longer horizons, in order to create effective predictors from historical data [
9]. Every aspect of modern life is being improved by the incorporation of machine learning, including marketing software, equipment maintenance, health-monitoring systems, crop yield prediction, and the study of soil. For example, Raja and Shukla [
10,
11] employed an extreme learning machine (ELM) and hybrid grey wolf-optimized artificial neural network models to obtain a more realistic prediction of the ultimate bearing capacity and settlement of a geosynthetic-reinforced sandy soil. Machine learning is adding intelligence to the newest generation of items almost everywhere we look [
12].
Traditionally, a crop-cutting experiment was used to measure crop production. However, this takes a long time and requires more human work. Crop yield estimation via crop yield models, which may be constructed using multiple statistical techniques, is another alternative to this old method. Presently, prediction of crop yields using artificial neural networks (ANN), the least absolute shrinkage and selection operator (LASSO), and elastic net (ELNET) is receiving a lot of attention using the relationship of crops to weather datasets [
13,
14,
15,
16,
17]. Das et al. [
14] developed multiple rice yield forecast models for the fourteen different districts on the west coast based on weekly weather indices using LASSO, SMLR, principal component analysis combined with SMLR (PCA-SMLR), ELNET, PCA-ANN, and ANN. Singh et al. [
7] used the SMLR technique to develop a wheat yield forecast model based on weekly weather indices and yield records for the Amritsar, Bhatinda, and Ludhiana districts of Punjab. Based on a dataset of 40 farms in Canterbury, New Zealand, Safa et al. [
18] developed an ANN model for wheat yield production. Sridhara et al. [
19] used the LASSO, ENET, PCA, ANN, and SMLR techniques to forecast the sorghum crop yield at the district level. The researchers discovered that the constructed ANN model could accurately estimate the wheat yield.
Unfortunately, up to today, little scientific effort has been made to develop the yield forecast model using machine learning techniques for the Chhattisgarh region. The majority of research so far relies on predictions based on traditional statistical models. Therefore, in the present research, an attempt has been made to provide a pre-harvest forecast of the rice crop for the Raipur, Surguja, and Bastar districts of Chhattisgarh using SMLR, ANN, LASSO, ELNET, and ridge regression, and a comparison was made among these techniques to select the best model that can be used to provide rice crop yield forecasts for the districts of Chhattisgarh.
2. Materials and Methods
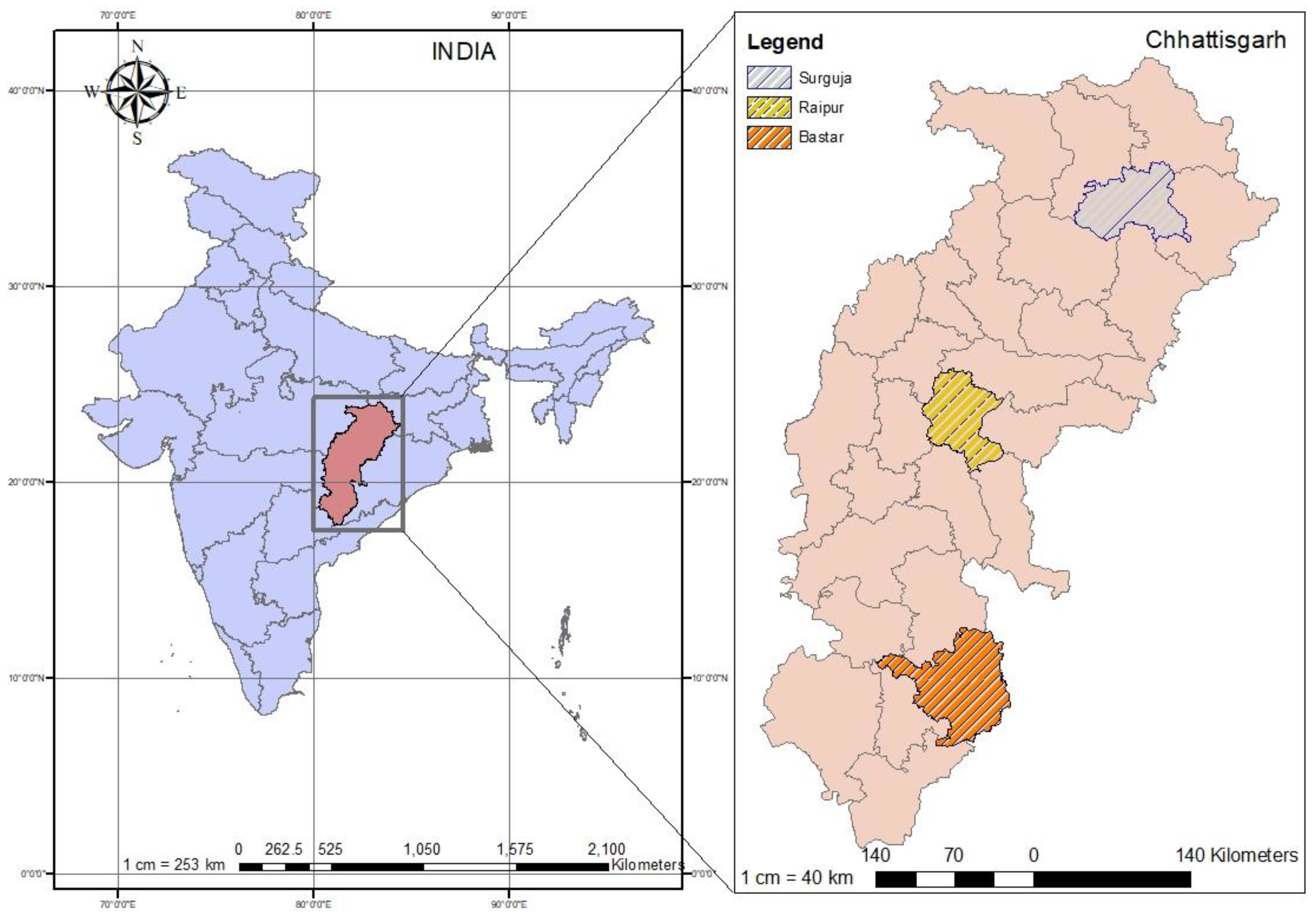
Among the districts of Chhattisgarh, three major districts representing three agro-climatic zones were considered in this study, i.e., Raipur (21°15′ N, 81°37′ E) from the Chhattisgarh plains, Surguja (23°6′ N, 83°11′ E) from the northern hills, and Bastar (19°4′ N, 82°1′ E) from the southern plateau (
Figure 1).
Weather data included maximum temperature (Tmax), minimum temperature (Tmin), rainfall, relative humidity at 7:20 am (RH I) and 2:20 pm (RH II), and sunshine hours of twenty-one years (1998–2018) for all three districts, which were taken from the local observatory situated at the respective districts. The crop yield data for these districts was taken from the Directorate of Economics and Statistics, the Ministry of Agriculture, and Farmers Welfare [
20]. Out of the total dataset, 80% of the data was used for calibration, and the remaining 20% was used for the validation of the developed models.
We used the district-level yield data, for which biophysical factors and farming practices are not uniform all over the region, and it is very hard to track the farming practice of each and every field of the districts. Hence, in the present study, we assume that in such a large area as a district, these factors will be either constant, or spatio-temporal variabilities are nullified by each other. For example, if the sowing of a crop in x region of a district is delayed and of y region is advanced, each will neutralize each other’s effect/impact on district-level crop productivity. Therefore, inter-seasonal variability in crop yield at the district level is largely influenced by the weather variables. The yield data were detrended prior to data analysis, since it is possible that climatic variability as well as technology differences can affect the trend in the yield data over the long term. However, time is also included as an independent variable in this study. It would be pertinent to mention that time is an important factor in deciding yield at the district level or in a large geographical region due to the fact that time represents cumulative technological advancement (including improvement in variety, machinery, disease, insect and weed control measures, etc.) and is a gradual and forward-moving phenomenon. Therefore, considering time as an independent parameter is logical and justifiable. To evaluate the importance of time during model development, these models were redeveloped using only time as an independent variable and without using time as an independent variable. The daily weather data were used to generate the weekly averages. The weighted and unweighted weather indices were then calculated using these average values with the help of formulas provided by Das et al. [
13]:
Unweighted weather indices:
Weighted weather indices:
Here, Z represents the weather index, n is the week of the forecast, is the value of the ith/i′th weather variable, the value of j is 0 for all unweighted indices and 1 for all weighted indices, and is the value of the correlation coefficient of the detrended yield with the ith weather variable/ product of the ith and i′th weather variables in the th week.
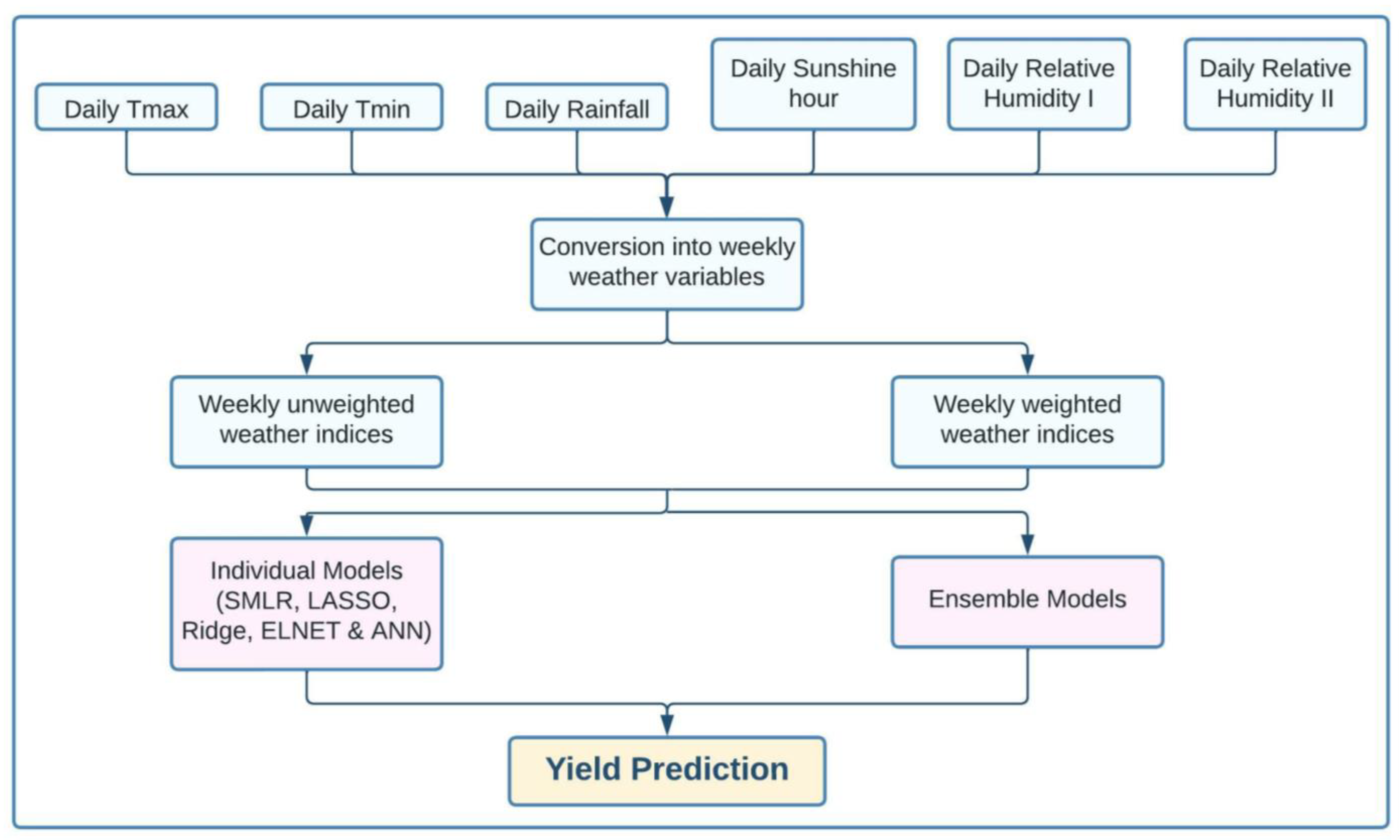
By following the above procedure, 42 weather indices were generated, as shown in
Table 1. The steps involved in model development are shown in
Figure 2 [
14].
2.1. Multivariate Techniques Involved in Model Development
In the present study, we employed statistical (stepwise multiple linear regression (SMLR) and machine learning techniques, such as penalized regression (LASSO, ELNET, ridge regression) and an artificial neural network (ANN). The SMLR is a conventional standard regression model, which is compared with other advanced approaches, and the penalized models address some of the limitations of standard regression for high-dimensional data. LASSO, ELENT, and ridge regression provide shrinkage, which enforces sparsity, that is, many of the parameter estimates are shrunk to exactly zero. Sparse models have several advantages over traditional regression, such as reduced overfitting (which improves prediction), the accommodation of multicollinearity, and a better ability to fit. They can also be used for variable reduction, where a zero-parameter estimate indicates that the variable is not an important predictor. Another model that we used is the ANN, which is a well-documented AI model inspired by the framework of biological human neurons. It has been successfully applied to numerous problems in different disciplines. In essence, it is a powerful tool for finding a relationship between independent and dependent variables. Hence, in addition to the statistical and shrinkage model, we also included the ANN to establish the association of weather variables with crop yield.
Stepwise Multiple Linear Regression (SMLR)
The simplest technique to generate a yield forecast based on a dataset of yield and weather parameters is stepwise multiple linear regression (SMLR). This strategy helps to select the best predictors from a huge number of predictors through a series of automated steps [
7,
14]. At every stage, the significance of the new variable included in the subsequent step is examined, typically using the
t statistics and
p-value.
2.2. Shrinkage Regression Models (LASSO, ELNET, and Ridge Regression)
In a situation in which the number of variables in a dataset exceeds the number of samples, the standard linear model typically performs poorly. A more effective alternative to this situation is penalized regression, in which the number of variables in the model is penalized by adding a constraint to the equation. The process of reducing the original size is also known as shrinkage or regularization. The regularization process permits the coefficients of the less important variables to be near to or equal to zero. The penalized regression methods considered in the present study include ridge regression, LASSO, and ELNET.
2.2.1. Least Absolute Shrinkage and Selection Operator (LASSO)
The LASSO technique shrinks the coefficients of correlated terms to zero, which ensures that correlated features are included when developing the data-driven model, in order to prevent overfitting and ensure generalization. In LASSO modeling, correlated features are penalized by reducing their coefficients to zero. The objective function that is minimized by the LASSO algorithm is expressed as [
21]:
where
β is the regression coefficient associated with the input parameters of the LASSO model;
x and
are the input and output, respectively,
n is the number of samples in the training dataset, and the hyper-parameter
λ is the penalty parameter.
2.2.2. Ridge Regression
Ridge regression is a technique for reducing data overfitting by adding a small degree of bias to regression predictions. The major goal of using ridge regression is to obtain more accurate outcomes. The method allows for the estimation of coefficients in multiple regression models when a high correlation exists between the predictor variables [
22]. Ridge regression may perform slightly poorly on the training set, but overall, it performs consistently well. The L2 regularization approach is used in ridge regression. The loss in ridge regression is defined as:
where
x and
are the input and output vector, respectively,
n is the number of samples in the training dataset,
β is the regression coefficient, and
λ is the penalty parameter.
2.2.3. Elastic Net (ELNET)
In ELNET, the penalty of ridge regression and LASSO, i.e., shrinkage and sparsity, are combined to reap the benefits of both ridge regression and LASSO [
23]. The elastic net estimator minimizes
where
x and
are the input and output, respectively,
n is the number of samples in the training dataset,
β is the regression coefficient,
λ is the penalty parameter, and
α is the mixing parameter between ridge (
α = 0) and LASSO (
α = 1).
2.3. Artificial Neural Network (ANN)
An artificial neural network (ANN) is a type of non-linear machine learning technique. It has three interconnected layers, viz., input (nodes or units), hidden (one to three layers of neurons), and the output layer of neurons. Each connection is associated with a numeric number known as weight. The output hi of neuron i in the hidden layer is [
24]:
Here, is the activation function, N is the number of input neurons, Vij is the weight, xj is the input to the neurons, and is the threshold term of the hidden neurons.
2.4. Ensemble Models
Various researchers [
25,
26] have compared conventional machine learning models with modified and improved ensemble models. Keeping this in mind, the outputs from individual models, namely, SMLR, LASSO, ridge, ELNET, and ANN, were used as inputs, and the observed yield was used as the target variable to build the ensemble models. The ELNET model was optimized through 10-fold cross-validation with 5 repetitions using the “caret” [
27] and “glmnet” [
28] packages in R. Ensemble models provide highly accurate predictions, since multiple versions of a single model are combined to arrive at a final prediction by aggregating the prediction of multiple base learners [
29]. In the present study, we have used four techniques to create an ensemble model, namely, the generalized linear model (GLM), random forest (RF), cubist, and ELNET methods.
Ensemble predictors such as random forest are known to have greater accuracy, though it is difficult to understand their “black-box” prediction. In contrast, a generalized linear model (GLM) is fairly interpretable, especially when forward feature selection is employed to build the model [
29]. ELNET is a type of linear regression with regularization to help prevent overfitting and built-in variable selection. On the other hand, Quinlan [
30] proposed a prediction-oriented regression model known as the cubist model. The key benefit of the cubist method is the addition of multiple training committees to balance case weights.
2.5. Evaluation of Model Performance
The performance of the models was evaluated using the R2, the root mean square error (RMSE), the normalized root mean square error (nRMSE), the mean biased error (MBE), the mean absolute error (MAE) and the concordance correlation coefficient (). A value of R2 and ρc close to 1 and of RMSE, MBE, and MAE near to 0 indicates better model performance. The positive and negative values of the MBE indicate over- and underestimation, respectively. In addition to this, the model performance is considered as excellent, good, fair, or poor based on the value of the nRMSE lying between 0–10%, 10–20%, 20–30%, or >30%, respectively.
The formulas of the model evaluation measures are shown below:
Here, is the observed value, and is the predicted value for i=1, 2,……, n. and are the standard deviation of actual and predicted observations, respectively. and denote the average of the observed and predicted values, and are the means for the observed and predicted values, and is the correlation coefficient between the observed and predicted values.
4. Discussion
4.1. Influence of Weather Parameters on Rice Crop
There is a profound influence of weather parameters on rice yield, and there is extensive literature available on the effect of temperature on rice yield [
34,
35,
36]. The mean weekly temperature for the study regions during the rice-growing season varied from 23.7 to 31.0 °C, 21.2 to 29.6 °C, and 21.2 to 28.9 °C for Raipur, Surguja, and Bastar, respectively, which is quite close to the ideal temperature needed for rice growth i.e., 15–18 to 30–33 °C [
37]. However, the maximum temperature sometimes exceeded 35 °C, and these extreme temperatures have a negative impact on rice yield and growth [
38]. The rate of photosynthesis, respiration, spikelet sterility, and length of the growing season are all impacted by temperature, which also has an impact on crop yield [
39,
40]. Higher temperatures have been observed to shorten the grain filling time, which reduces crop yield as well as the grain quality. Moreover, rice yield is positively influenced by solar radiation, as it directly affects biomass accumulation [
40]. Reduced sun exposure, especially during the reproductive and ripening stages, results in a reduction in the crop yield [
41].
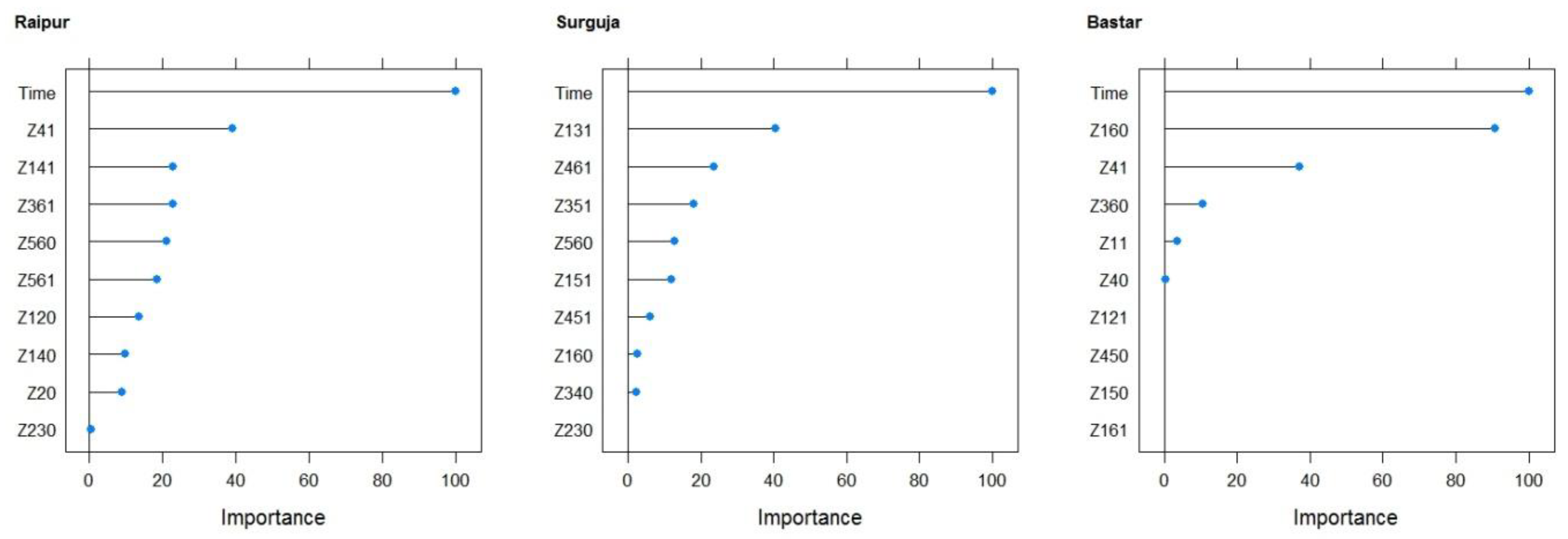
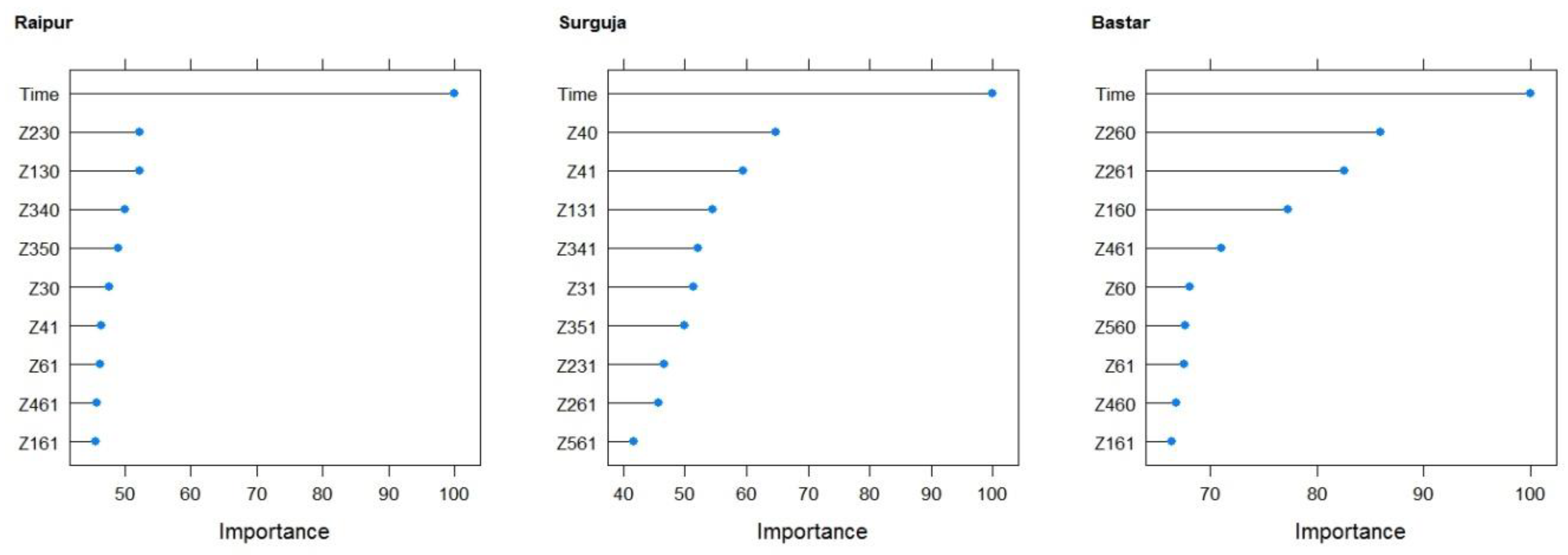
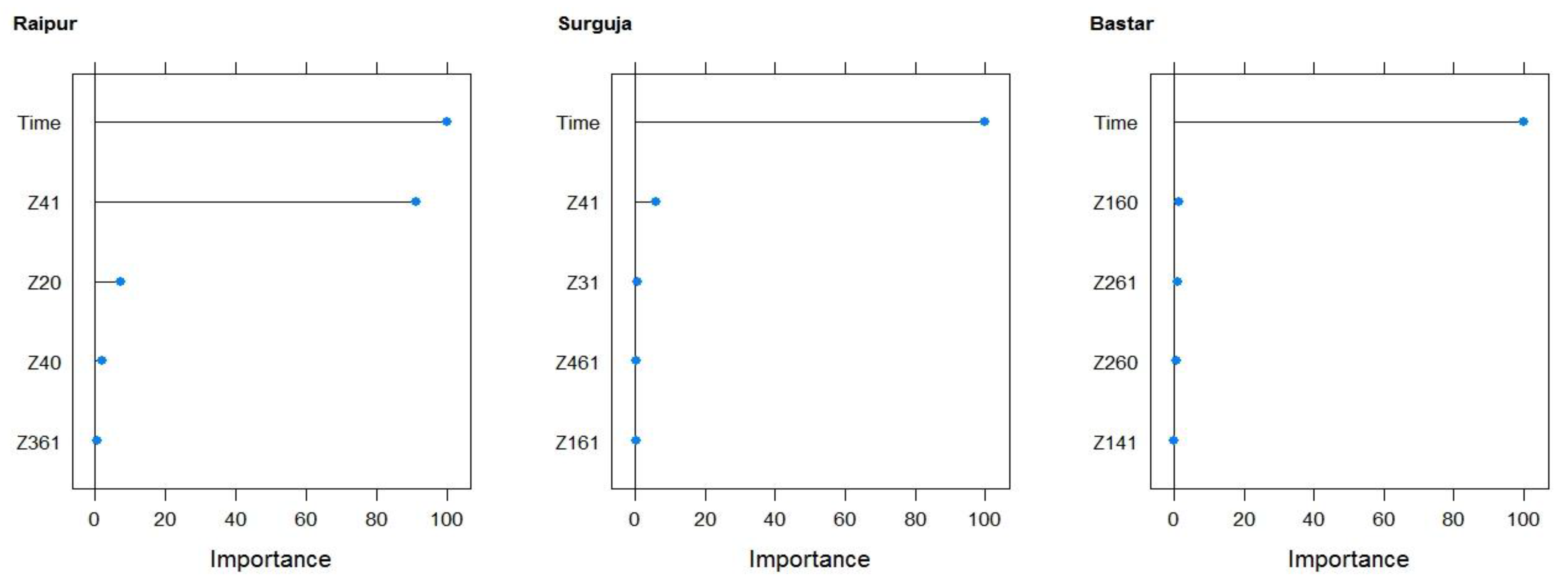
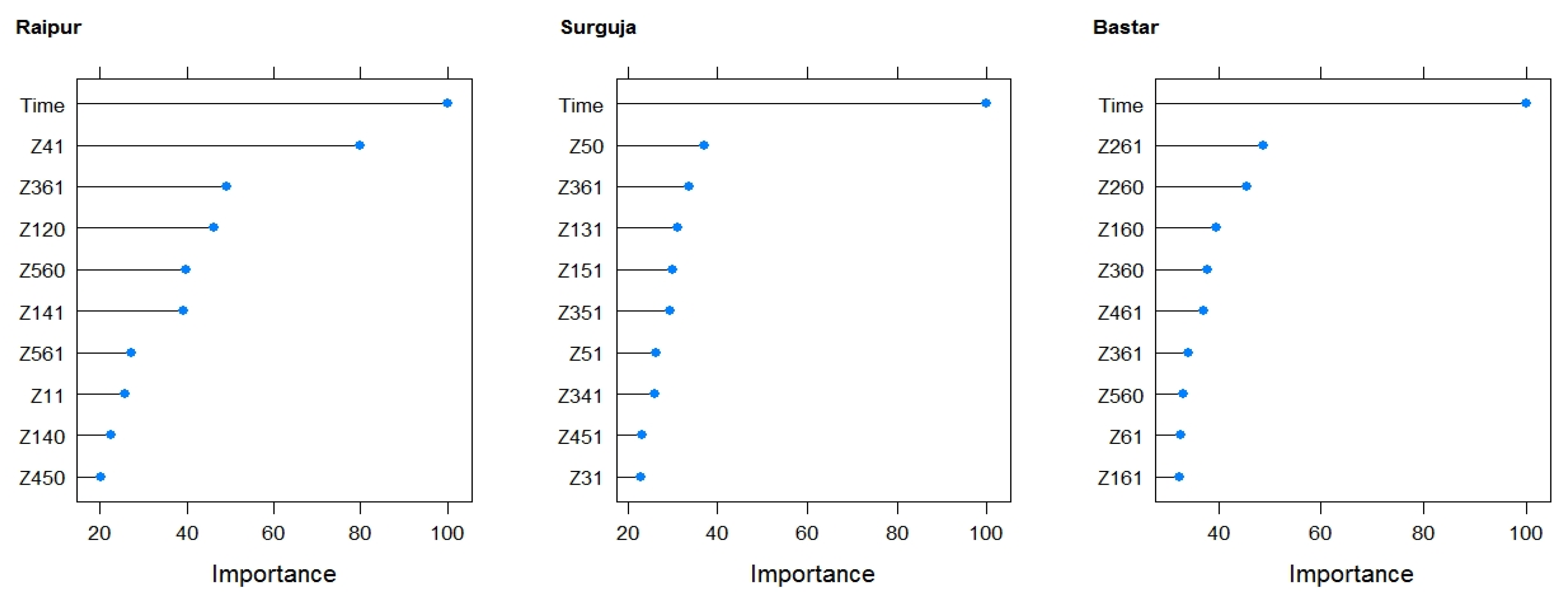
Temperature, relative humidity, and solar radiation were the major weather parameters with the maximum impacts on the rice yield. Solar radiation was selected to be an important variable for rice yield using the ANN and LASSO models for the Raipur and Bastar districts, respectively, which is in agreement with previous studies [
42], and the maximum temperature and relative humidity was found to be the most significant predictors of rice yield for the Surguja district.
4.2. Model Cross-Comparison
In the face of climate change, population growth, and food demand, timely, accurate, and reliable crop yield estimation is much more important than ever before in crop management, food security assessment, and policymaking. In the present study, an attempt has been made to discover the best prediction model for rice yield forecasting for three districts of different agro-climatic zones of Chhattisgarh, India. By combining the weather data with publicly available agricultural production data, a comparison was made among the models developed using multiple approaches, including SMLR, ANN, LASSO, ELNET, and ridge regression. Different statistical measures were used to capture the performance of each model.
The finding showed that based on the value of the coefficient of determination (R
2), SMLR performed well at calibration, whereas at validation, it performed poorly for all the districts, which might be due to the overfitting of data at the calibration stage. On the other hand, the performance of LASSO was good at calibration for all three districts, whereas it was poor at validation for Raipur and Surguja. The LASSO technique was found to be the most accurate for rice yield forecasting for the Bastar district at both the calibration and validation stages. This finding is consistent with the findings of Kumar et al. [
43], Singh et al. [
44], and Parul et al. [
45], who observed that LASSO performed better than SMLR to some extent. The performance of LASSO was good, as the model used the shrinkage technique to deal with the issue of multicollinearity, thus keeping only the most significant variable in the study.
Moreover, for ridge regression, the performance of the model was good at the calibration stage, whereas it was poor at the validation stage for all three districts based on the value of the R2 and nRMSE. For the ELNET model, at the calibration stage, the value of the R2, RMSE, nRMSE, and MBE was excellent for all the districts considered in the study. However, during the validation stage, model performance was good for Raipur and Bastar and poor for Surguja. The overall findings concluded that the ELNET model can be used for the rice yield forecasting for Bastar. The good performance of ELNET may be due to the inclusion of Lasso and ridge penalties, so the model hypothesis space is much broader with ELNET.
Likewise, the ANN works in a non-linear fashion, having a potential advantage in the analysis of variables with complex correlations compared to regression models. The performance of the ANN was excellent for the Raipur and Surguja districts during the calibration as well as the validation stage. Meanwhile, for Bastar, the model performance was good at the calibration and poor at validation stage. Therefore, for Raipur and Surguja, the ANN is a good choice for rice yield forecasting. The results supported the study by Aravind et al. [
16], which demonstrated that the ANN performed better than SMLR, LASSO, and ELNET in the Patiala district of Punjab.
It is worth noticing that different weighted and unweighted climatic indices were selected in different models and districts. All the three districts of the state are part of three different climatic zones of Chhattisgarh state (India), and their climatic conditions are very different from each other. Surguja belongs to the northern hilly region, Raipur is part of the central plains, and Bastar is part of the southern plateau. Hence, it is understandable that different climatic variables could affect the rice yield in different regions.
4.3. Limitations
Many times, commonly used linear regression models to predict crop yields such as SMLR, LASSO, ridge, and ELNET fail to fit complex nonlinear relationships between crop yield and weather data. The poor performance of ridge regression compared to LASSO and ELNET may be due to the inclusion of all predictor variables in the final model. In the case of multiple highly collinear variables, LASSO regression randomly selects one of them, which can lead to incorrect interpretation. The alternative to these mentioned approaches is an ANN, but the ANN is not perfect when it comes to learning patterns, since crop yield is affected by a variety of factors, which are unpredictable and inconsistent. Additionally, we used a single hidden layer for ANN fitting. The inclusion of multiple hidden layers with a large amount of training data may further improve the predictability of the ANN model. Furthermore, an attempt was also made to form an ensemble model. The performance of the ensemble model may not be better than the best individual model, as the ensemble model is built using the individual models only. However, it will definitely be better than the individual model having the worst performance. The biggest limitation of the present study was the unavailability of long-term rice yield and weather data.
5. Conclusions
In the present study, five different methods, viz., SMLR, LASSO, ELNET, ridge regression, and an ANN, were used to study the relationship of yield to weather parameters for three districts of Chhattisgarh, India. The overall ranking based on the RMSE and nRMSE values during validation revealed that the ANN performed the best for the Raipur (R2 = 1) and Surguja (R2 = 1 and 0.99) districts as compared to other models, and for the Bastar district, LASSO (R2 = 0.93 and 0.57) and ELNET (R2 = 0.90 and 0.48) performed better compared to other models included in the study. The study also showed that the performance of SMLR, LASSO, ELNET, and ridge regression was good during calibration but not during the process of validation, which may be due to overfitting. In the ensemble model, the performance was found to be better compared to the individual models. For Raipur and Surguja, the performance of all the ensemble methods was excellent and comparable, whereas for Bastar, random forest (RF) performed better, with R2 = 0.85 and 0.81 for calibration and validation, respectively, as compared to the GLM, cubist, and ELNET approaches.
Future Research
There is no doubt that deep learning has rapidly expanded in the field of agriculture since 2019, including the prediction of crop yields. In future studies, focus should be placed on some deep learning techniques, such as CNN, DNN, RNN, LSTM, MLP, R-CNN, and faster R-CNN, both individually as well as in different combinations.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}