


Hyperspectral Estimation of Soil Organic Carbon Content Based on Continuous Wavelet Transform and Successive Projection Algorithm in Arid Area of Xinjiang, China
Abstract
:1. Introduction
2. Materials and Methods
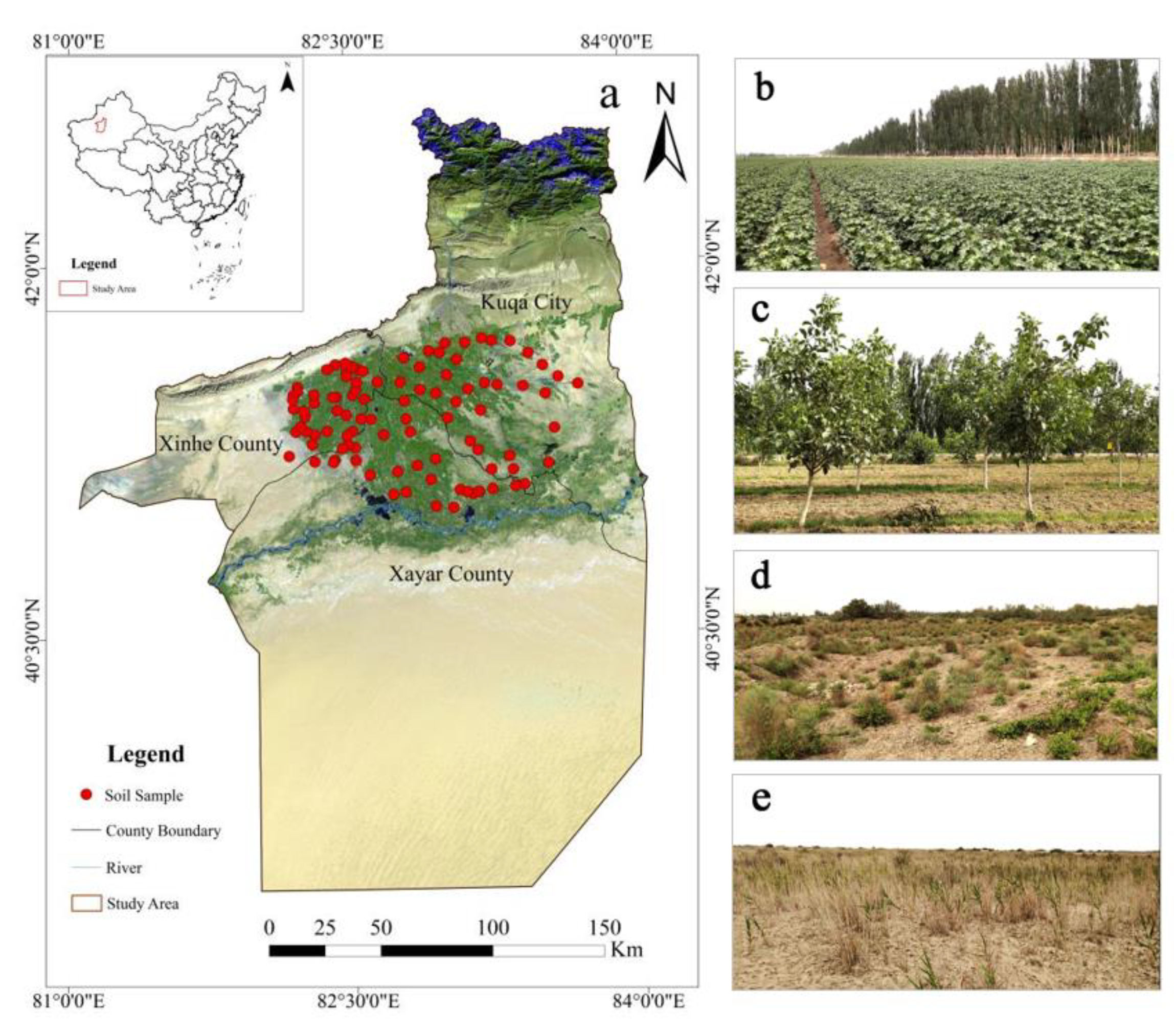
2.1. Soil Sample Collection and Preparation
2.2. Acquiring and Pre-Processing Spectral Data
2.3. Continuous Wavelet
2.4. Successive Projection Algorithm
- (1)
- Initialize the vectors: (first iteration); choose any column vector in the spectral matrix and count it as .
- (2)
- The set of unselected column vectors can be represented asCalculate the projection onto the set of column vectors.
- (3)
- Determine the maximum projection vector’s ordinal number.
- (4)
- Determine the projection vector for the next iteration.
- (5)
- , if < , return to step (2).
2.5. Sample Set Partitioning Algorithm Based on Joint x-y Distance (SPXY)
2.6. Model Building and Validation
3. Results and Analysis
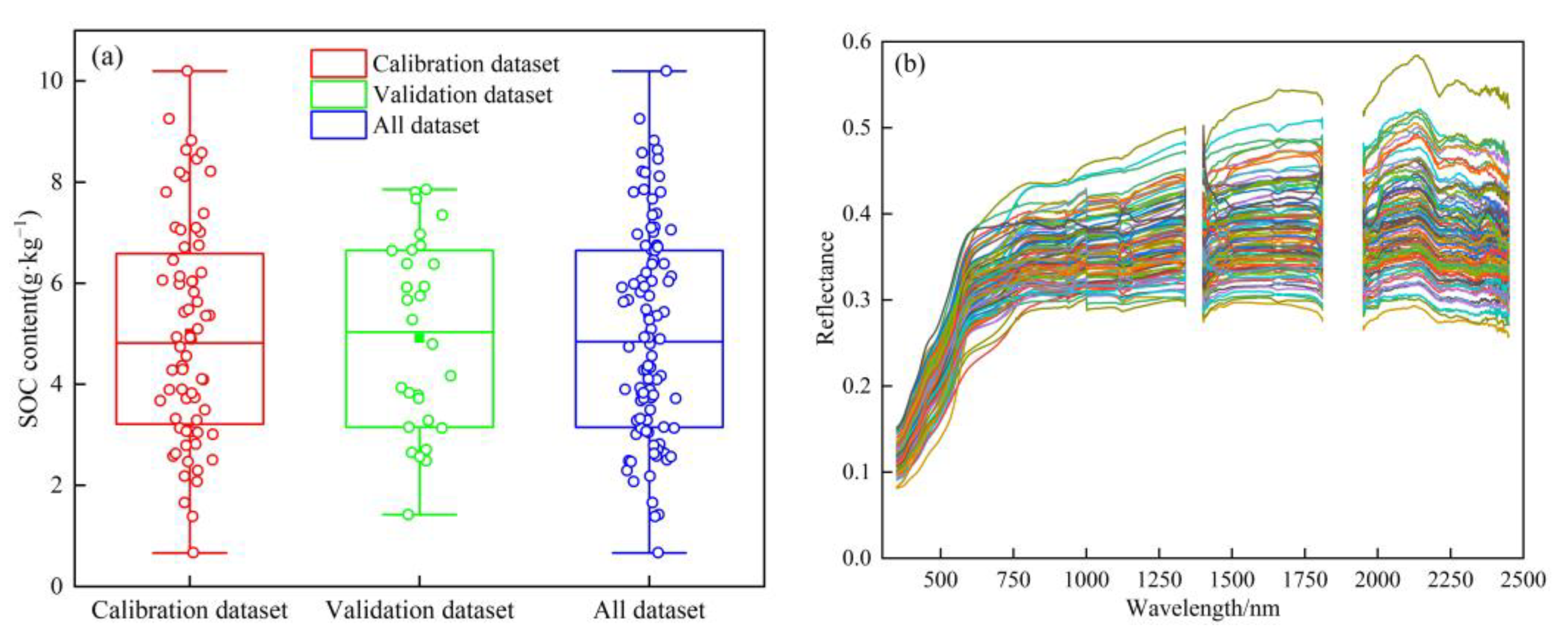
3.1. Soil Organic Carbon Content and Soil Spectral Characteristics Analysis
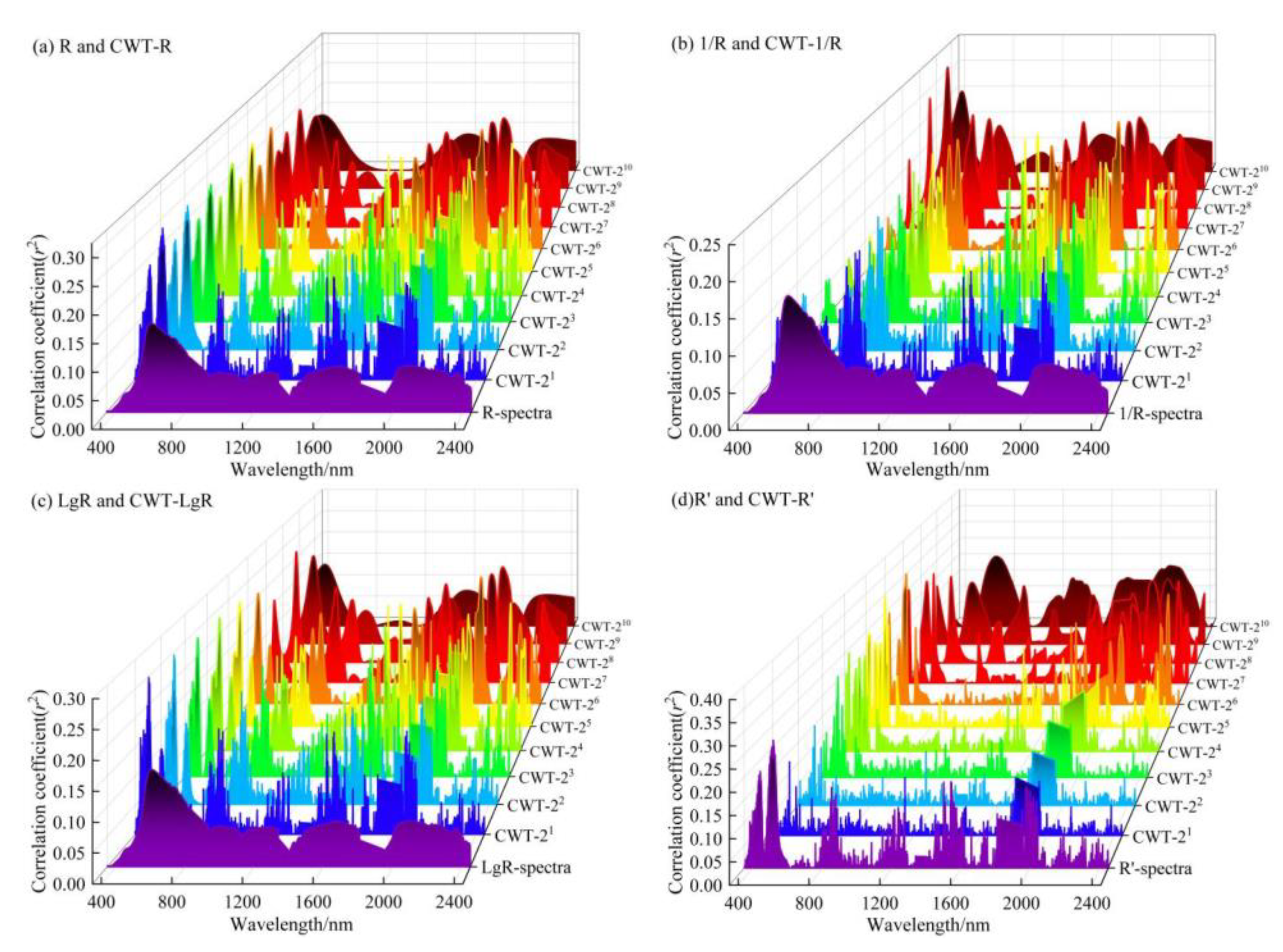
3.2. Correlation Analysis of Spectral Data and Soil Organic Carbon
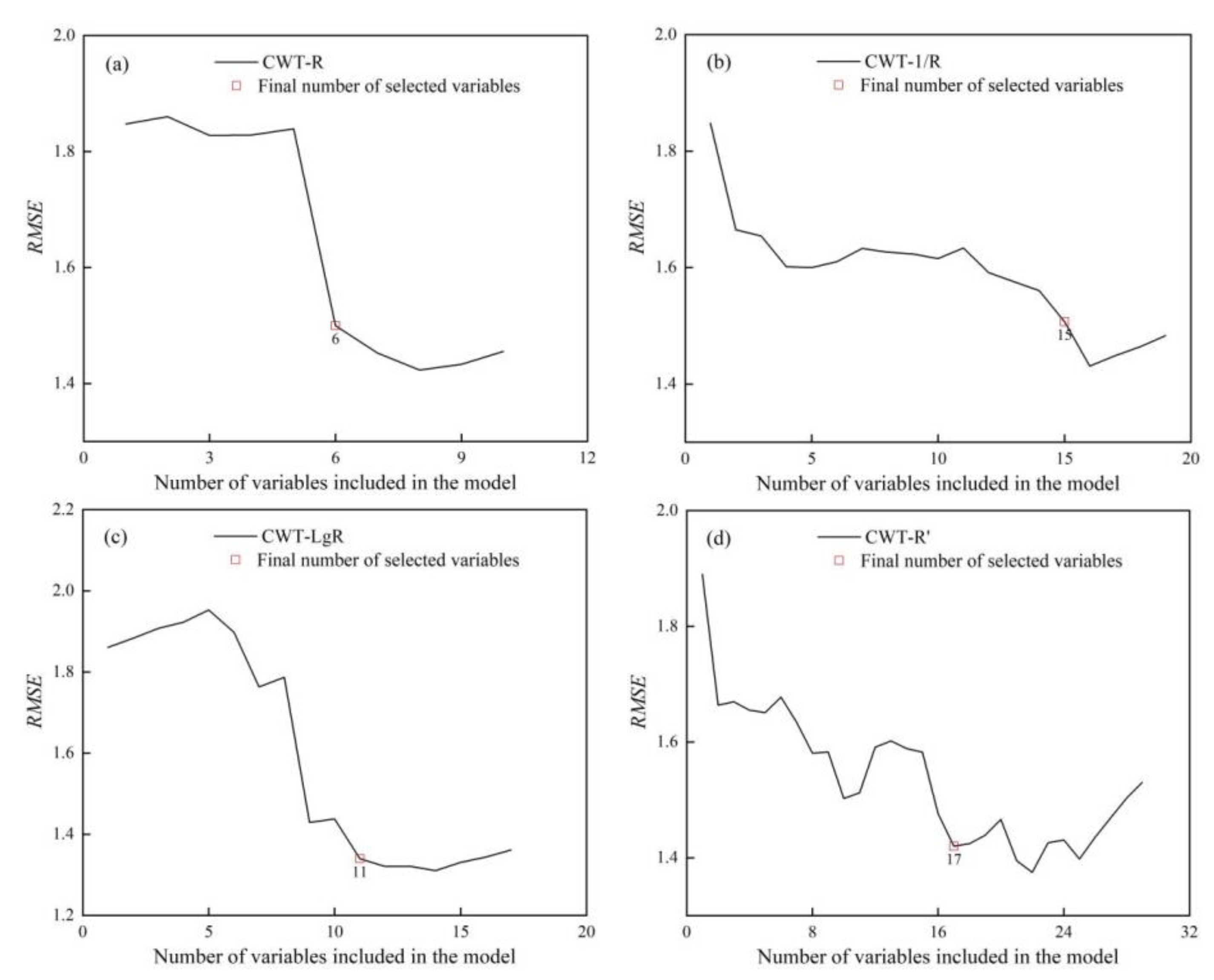
3.3. Feature Band Selection Based on the SPA Algorithm
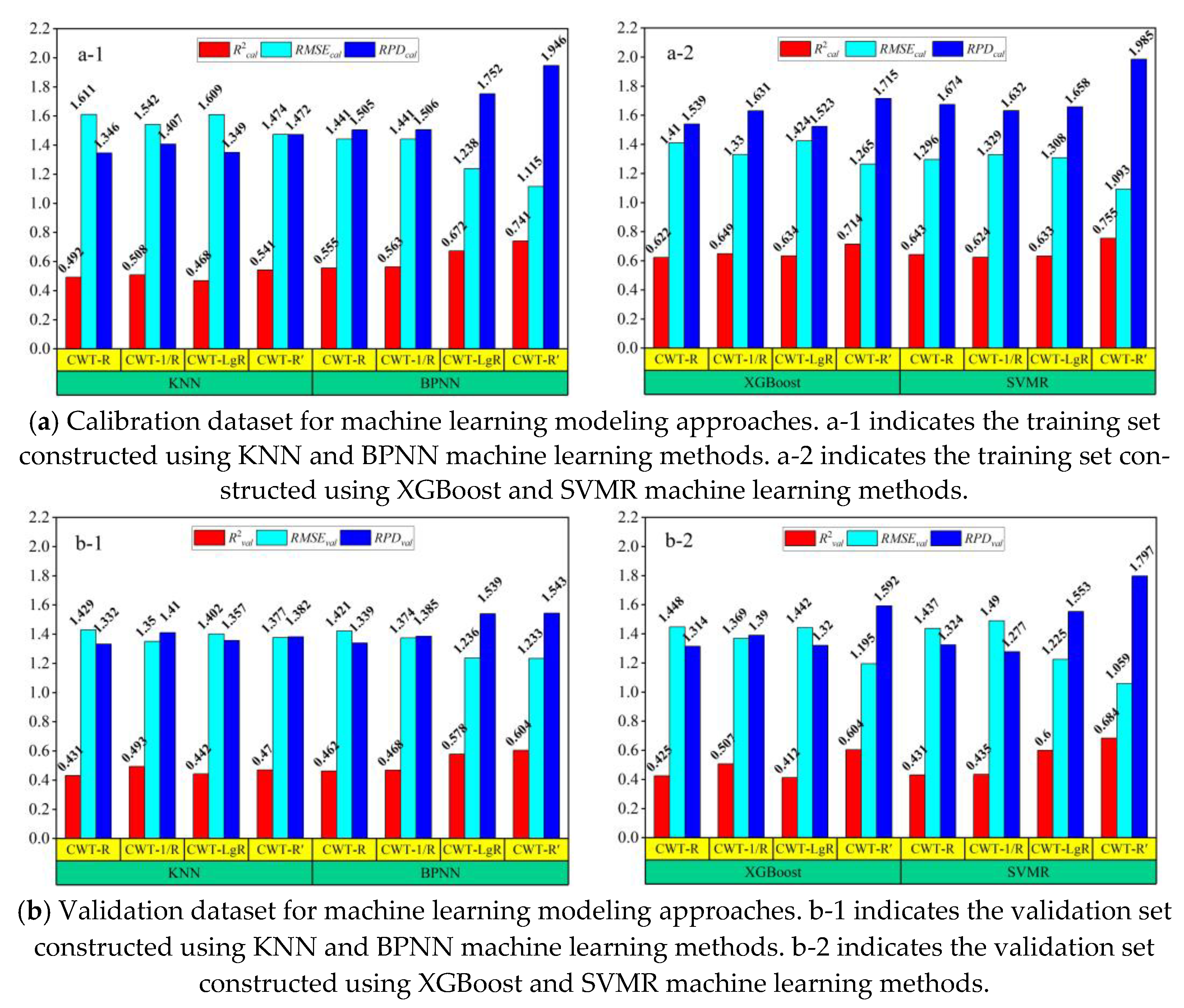
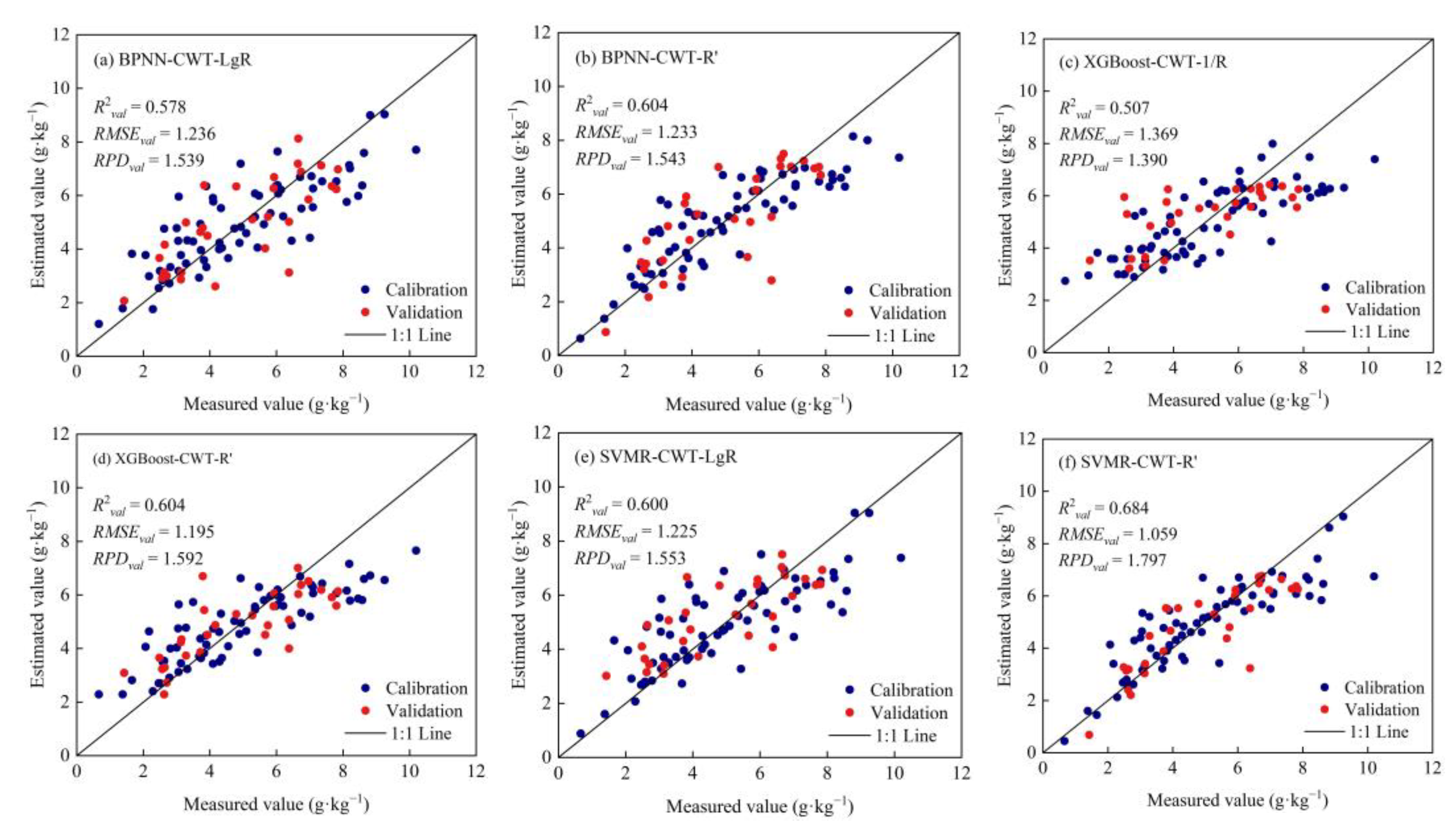
3.4. Hyperspectral Model Building and Comparison
4. Discussion
4.1. Continuous Wavelet Analysis
4.2. Feature Wavelength Analysis
4.3. Prediction Models Analysis
4.4. Future Work and Perspectives
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, T.; Geng, Y.; Ji, C.; Xu, X.; Wang, H.; Pan, J.; Bumberger, J.; Haase, D.; Lausch, A. Prediction of soil organic carbon and the C:N ratio on a national scale using machine learning and satellite data: A comparison between Sentinel-2, Sentinel-3 and Landsat-8 images. Sci. Total Environ. 2021, 755, 142661. [Google Scholar] [CrossRef]
- Mahmoudzadeh, H.; Matinfar, H.R.; Taghizadeh-Mehrjardi, R.; Kerry, R. Spatial prediction of soil organic carbon using machine learning techniques in western Iran. Geoderma Reg. 2020, 21, e00260. [Google Scholar] [CrossRef]
- Six, J.; Conant, R.T.; Paul, E.A.; Paustian, K. Stabilization mechanisms of soil organic matter: Implications for C-saturation of soils. Plant Soil 2002, 241, 155–176. [Google Scholar] [CrossRef]
- Arunrat, N.; Kongsurakan, P.; Sereenonchai, S.; Hatano, R. Soil organic carbon in sandy paddy fields of Northeast Thailand: A review. Agronomy 2020, 10, 1061. [Google Scholar] [CrossRef]
- Arunrat, N.; Sereenonchai, S.; Wang, C. Carbon footprint and predicting the impact of climate change on carbon sequestration ecosystem services of organic rice farming and conventional rice farming: A case study in Phichit province, Thailand. J. Environ. Manag. 2021, 289, 112458. [Google Scholar] [CrossRef]
- Morellos, A.; Pantazi, X.E.; Moshou, D.; Alexandridis, T.; Whetton, R.; Tziotzios, G.; Wiebensohn, J.; Bill, R.; Mouazen, A.M. Machine learning based prediction of soil total nitrogen, organic carbon and moisture content by using VIS-NIR spectroscopy. Biosyst. Eng. 2016, 152, 104–116. [Google Scholar] [CrossRef]
- Shen, Q.; Xia, K.; Zhang, S.; Kong, C.; Hu, Q.; Yang, S. Hyperspectral indirect inversion of heavy-metal copper in reclaimed soil of iron ore area. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2019, 222, 117191. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, T.; Pan, X. Potential of visible and near-infrared reflectance spectroscopy for the determination of rare earth elements in soil. Geoderma 2017, 306, 120–126. [Google Scholar] [CrossRef]
- Olatunde, K.A. Determination of petroleum hydrocarbon contamination in soil using VNIR DRS and PLSR modeling. Heliyon 2021, 7, e06794. [Google Scholar] [CrossRef]
- Xiao, D.; Vu, Q.H.; Le, B.T. Salt content in saline-alkali soil detection using visible-near infrared spectroscopy and a 2D deep learning. Microchem. J. 2021, 165, 106182. [Google Scholar] [CrossRef]
- Gu, X.; Wang, Y.; Sun, Q.; Yang, G.; Zhang, C. Hyperspectral inversion of soil organic matter content in cultivated land based on wavelet transform. Comput. Electron. Agric. 2019, 167, 105053. [Google Scholar] [CrossRef]
- Nocita, M.; Stevens, A.; Noon, C.; van Wesemael, B. Prediction of soil organic carbon for different levels of soil moisture using Vis-NIR spectroscopy. Geoderma 2013, 199, 37–42. [Google Scholar] [CrossRef]
- Dos Santos, U.J.; de Melo Demattê, J.A.; Menezes, R.S.C.; Dotto, A.C.; Guimarães, C.C.B.; Alves, B.J.R.; Primo, D.C.; de Sá Barretto Sampaio, E.V. Predicting carbon and nitrogen by visible near-infrared (Vis-NIR) and mid-infrared (MIR) spectroscopy in soils of Northeast Brazil. Geoderma Reg. 2020, 23, e00333. [Google Scholar] [CrossRef]
- Cambou, A.; Barthès, B.G.; Moulin, P.; Chauvin, L.; Faye, E.H.; Masse, D.; Chevallier, T.; Chapuis-Lardy, L. Prediction of soil carbon and nitrogen contents using visible and near infrared diffuse reflectance spectroscopy in varying salt-affected soils in Sine Saloum (Senegal). CATENA 2022, 212, 106075. [Google Scholar] [CrossRef]
- Pande, C.B.; Kadam, S.A.; Jayaraman, R.; Gorantiwar, S.; Shinde, M. Prediction of soil chemical properties using multispectral satellite images and wavelet transforms methods. J. Saudi Soc. Agric. Sci. 2022, 21, 21–28. [Google Scholar] [CrossRef]
- Zhang, B.; Guo, B.; Zou, B.; Wei, W.; Lei, Y.; Li, T. Retrieving soil heavy metals concentrations based on GaoFen-5 hyperspectral satellite image at an opencast coal mine, Inner Mongolia, China. Environ. Pollut. 2022, 300, 118981. [Google Scholar] [CrossRef]
- Huang, Y.; Tian, Q.; Wang, L.; Geng, J.; Lyu, C. Estimating canopy leaf area index in the late stages of wheat growth using continuous wavelet transform. J. Appl. Remote Sens. 2014, 8, 083517. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, J.; Fan, Y.; Cheng, Y.; Wu, X.; Zhang, J.; Wang, B.; Wang, X.; Yong, T.; Liu, W.; et al. Evaluating photosynthetic pigment contents of maize using UVE-PLS based on continuous wavelet transform. Comput. Electron. Agric. 2020, 169, 105160. [Google Scholar] [CrossRef]
- Zhao, R.; An, L.; Tang, W.; Gao, D.; Qiao, L.; Li, M.; Sun, H.; Qiao, J. Deep learning assisted continuous wavelet transform-based spectrogram for the detection of chlorophyll content in potato leaves. Comput. Electron. Agric. 2022, 195, 106802. [Google Scholar] [CrossRef]
- Liu, F.; He, Y. Application of successive projections algorithm for variable selection to determine organic acids of plum vinegar. Food Chem. 2009, 115, 1430–1436. [Google Scholar] [CrossRef]
- Xiaobo, Z.; Jiewen, Z.; Povey, M.J.W.; Holmes, M.; Hanpin, M. Variables selection methods in near-infrared spectroscopy. Anal. Chim. Acta 2010, 667, 14–32. [Google Scholar] [CrossRef] [PubMed]
- Ghasemi-Varnamkhasti, M.; Mohtasebi, S.S.; Rodriguez-Mendez, M.L.; Gomes, A.A.; Araújo, M.C.U.; Galvão, R.K.H. Screening analysis of beer ageing using near infrared spectroscopy and the Successive Projections Algorithm for variable selection. Talanta 2012, 89, 286–291. [Google Scholar] [CrossRef] [PubMed]
- Shi, T.; Chen, Y.; Liu, H.; Wang, J.; Wu, G. Soil organic carbon content estimation with laboratory-based visible–near-infrared reflectance spectroscopy: Feature selection. Appl. Spectrosc. 2014, 68, 831–837. [Google Scholar] [CrossRef] [PubMed]
- Araújo, M.C.U.; Saldanha, T.C.B.; Galvão, R.K.H.; Yoneyama, T.; Chame, H.C.; Visani, V. The successive projections algorithm for variable selection in spectroscopic multicomponent analysis. Chemom. Intell. Lab. Syst. 2001, 57, 65–73. [Google Scholar] [CrossRef]
- Gao, H.; Lu, Q.; Ding, H.; Peng, Z. Choice of characteristic near-infrared wavelengths for soil total nitrogen based on successive projection algorithm. Spectrosc. Spectr. Anal. 2009, 29, 2951–2954. [Google Scholar]
- Peng, X.; Shi, T.; Song, A.; Chen, Y.; Gao, W. Estimating soil organic carbon using VIS/NIR spectroscopy with SVMR and SPA methods. Remote Sens. 2014, 6, 2699–2717. [Google Scholar] [CrossRef]
- Xiao, Y.; Xin, H.; Wang, B.; Cui, L.; Jiang, Q. Hyperspectral estimation of black soil organic matter content based on wavelet transform and successive projections algorithm. Remote Sens. Nat. Resour. 2021, 33, 33–39. [Google Scholar]
- Ma, G.; Ding, J.; Han, L.; Zhang, Z.; Ran, S. Digital mapping of soil salinization based on Sentinel-1 and Sentinel-2 data combined with machine learning algorithms. Reg. Sustain. 2021, 2, 177–188. [Google Scholar] [CrossRef]
- Zhao, R.; An, L.; Song, D.; Li, M.; Qiao, L.; Liu, N.; Sun, H. Detection of chlorophyll fluorescence parameters of potato leaves based on continuous wavelet transform and spectral analysis. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2021, 259, 119768. [Google Scholar] [CrossRef]
- Soares, S.F.C.; Gomes, A.A.; Filho, A.R.G.; Araújo, M.C.U.; Galvão, R.K.H. The successive projections algorithm. TrAC Trends Anal. Chem. 2013, 42, 84–98. [Google Scholar] [CrossRef]
- Galvão, R.K.H.; Araújo, M.C.U.; José, G.E.; Pontes, M.J.C.; Silva, E.C.; Saldanha, T.C.B. A method for calibration and validation subset partitioning. Talanta 2005, 67, 736–740. [Google Scholar] [CrossRef] [PubMed]
- McRoberts, R.E. Estimating forest attribute parameters for small areas using nearest neighbors techniques. For. Ecol. Manag. 2012, 272, 3–12. [Google Scholar] [CrossRef]
- Mansuy, N.; Thiffault, E.; Paré, D.; Bernier, P.; Guindon, L.; Villemaire, P.; Poirier, V.; Beaudoin, A. Digital mapping of soil properties in Canadian managed forests at 250 m of resolution using the k-nearest neighbor method. Geoderma 2014, 235, 59–73. [Google Scholar] [CrossRef]
- Meng, X.; Bao, Y.; Liu, J.; Liu, H.; Zhang, X.; Zhang, Y.; Wang, P.; Tang, H.; Kong, F. Regional soil organic carbon prediction model based on a discrete wavelet analysis of hyperspectral satellite data. Int. J. Appl. Earth Obs. Geoinf. 2020, 89, 102111. [Google Scholar] [CrossRef]
- Ching, P.M.L.; Zou, X.; Wu, D.; So, R.H.Y.; Chen, G.H. Development of a wide-range soft sensor for predicting wastewater BOD5 using an eXtreme gradient boosting (XGBoost) machine. Environ. Res. 2022, 210, 112953. [Google Scholar] [CrossRef]
- Si, M.; Du, K. Development of a predictive emissions model using a gradient boosting machine learning method. Environ. Technol. Innov. 2020, 20, 101028. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Pham, T.D.; Nguyen, C.T.; Delfos, J.; Archibald, R.; Dang, K.B.; Hoang, N.B.; Guo, W.; Ngo, H.H. A novel intelligence approach based active and ensemble learning for agricultural soil organic carbon prediction using multispectral and SAR data fusion. Sci. Total Environ. 2022, 804, 150187. [Google Scholar] [CrossRef]
- Xu, S.; Zhao, Y.; Wang, M.; Shi, X. Comparison of multivariate methods for estimating selected soil properties from intact soil cores of paddy fields by Vis-NIR spectroscopy. Geoderma 2018, 310, 29–43. [Google Scholar] [CrossRef]
- Ghosh, A.K.; Das, B.S.; Reddy, N. Application of VIS-NIR spectroscopy for estimation of soil organic carbon using different spectral preprocessing techniques and multivariate methods in the middle Indo-Gangetic plains of India. Geoderma Reg. 2020, 23, e00349. [Google Scholar]
- Wang, Z.; Coburn, C.A.; Ren, X.; Teillet, M. Effect of soil surface roughness and scene components on soil surface bidirectional reflectance factor. Can. J. Soil Sci. 2012, 92, 297–313. [Google Scholar] [CrossRef]
- Luan, F.; Xiong, H.; Wang, F.; Zhang, F. The inversion of soil alkaline hydrolysis nutrient content with hyperspectral reflectance based on wavelet analysis. Spectrosc. Spectr. Anal. 2013, 33, 2828–2832. [Google Scholar]
- Yang, H.; Qian, Y.; Yang, F.; Li, J.; Ju, W. Using wavelet transform of hyperspectral reflectance data for extracting spectral features of soil organic carbon and nitrogen. Soil Sci. 2012, 177, 674–681. [Google Scholar] [CrossRef]
- Hong, Y.; Munnaf, M.A.; Guerrero, A.; Chen, S.; Liu, Y.; Shi, Z.; Mouazen, A.M. Fusion of visible-to-near-infrared and mid-infrared spectroscopy to estimate soil organic carbon. Soil Tillage Res. 2022, 217, 105284. [Google Scholar] [CrossRef]
- Wang, Y.; Jin, Y.; Wang, X.; Liao, Q.; Gu, X.; Zhao, Z.; Yang, X. Quantitative inversion of organic matter content based on interconnection traditional spectral transform and continuous wavelet transform. Spectrosc. Spectr. Anal. 2018, 38, 2571–2577. [Google Scholar]
- Zhang, S.; Shen, Q.; Nie, C.; Huang, Y.; Wang, J.; Hu, Q.; Ding, X.; Zhou, Y.; Chen, Y. Hyperspectral inversion of heavy metal content in reclaimed soil from a mining wasteland based on different spectral transformation and modeling methods. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2019, 211, 393–400. [Google Scholar] [CrossRef] [PubMed]
- Cheng, J.H.; Sun, D.W.; Pu, H. Combining the genetic algorithm and successive projection algorithm for the selection of feature wavelengths to evaluate exudative characteristics in frozen-thawed fish muscle. Food Chem. 2016, 197, 855–863. [Google Scholar] [CrossRef]
- Liu, J.; Xie, J.; Meng, T.; Dong, H. Organic matter estimation of surface soil using successive projection algorithm. Agron. J. 2022, 114, 1944–1951. [Google Scholar] [CrossRef]
- Zhang, H.; Luo, W.; Liu, X.; He, Y. Measurement of soil organic matter with near infrared spectroscopy combined with genetic algorithm and successive projection algorithm. Spectrosc. Spectr. Anal. 2017, 37, 584–587. [Google Scholar]
- Xia, K.; Xia, S.; Shen, Q.; Zhang, S.; Li, C.; Cheng, Q.; Zhou, J. Optimization of a soil particle content prediction model based on a combined spectral index and successive projections algorithm using vis-NIR spectroscopy. Spectroscopy 2021, 35, 24–34. [Google Scholar]
- Lark, R.M. Soil-landform relationships at within-field scales: An investigation using continuous classification. Geoderma 1999, 92, 141–165. [Google Scholar] [CrossRef]
- Nawar, S.; Mouazen, A.M. On-line vis-NIR spectroscopy prediction of soil organic carbon using machine learning. Soil Tillage Res. 2019, 190, 120–127. [Google Scholar] [CrossRef]
- Zeraatpisheh, M.; Ayoubi, S.; Mirbagheri, Z.; Mosaddeghi, M.; Xu, M. Spatial prediction of soil aggregate stability and soil organic carbon in aggregate fractions using machine learning algorithms and environmental variables. Geoderma Reg. 2021, 27, e00440. [Google Scholar] [CrossRef]
- Sorenson, P.T.; Small, C.; Tappert, M.C.; Quideau, S.A.; Drozdowski, B.; Underwood, A.; Janz, A. Monitoring organic carbon, total nitrogen, and pH for reclaimed soils using field reflectance spectroscopy. Can. J. Soil Sci. 2017, 97, 241–248. [Google Scholar] [CrossRef]
- Hong, Y.; Chen, S.; Chen, Y.; Linderman, M.; Mouazen, A.M.; Liu, Y.; Guo, L.; Yu, L.; Liu, Y.; Cheng, H.; et al. Comparing laboratory and airborne hyperspectral data for the estimation and mapping of topsoil organic carbon: Feature selection coupled with random forest. Soil Tillage Res. 2020, 199, 104589. [Google Scholar] [CrossRef]
- Guo, J.; Zhao, X.; Guo, X.; Zhu, Q.; Luo, J.; Xu, Z.; Zhong, L.; Ye, Y. Inversion of soil properties in rare earth mining areas (southern Jiangxi, China) based on visible-near-infrared spectroscopy. J. Soils Sediments 2022, 22, 2406–2421. [Google Scholar] [CrossRef]
- Luo, X.; Hong, T.; Luo, K.; Dai, F.; Wu, W.; Mei, H.; Lin, L. Application of wavelet transform and successive projections algorithm in the non-destructive measurement of total acid content of pitaya. Spectrosc. Spectr. Anal. 2016, 36, 1345–1351. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Set | Sample Size | Soil Organic Carbon (g∙kg−1) | CV(%) | |||
|---|---|---|---|---|---|---|
| Minimum | Maximum | Average | Standard Deviation | |||
| Calibration dataset | 68 | 0.67 | 10.20 | 5.00 | 2.17 | 43.37 |
| Validation dataset | 30 | 1.42 | 7.85 | 4.91 | 1.90 | 38.77 |
| All dataset | 98 | 0.67 | 10.20 | 4.97 | 2.08 | 41.87 |
| Methods | Scale | Selected Wavelengths (nm) |
|---|---|---|
| CWT-R | 23,26,27,28 | 23-853,26-1995,27-1994,27-2017,28-493,28-2010 |
| CWT-1/R | 23,24,25,26,29 | 23-1550,24-1548,24-1550,25-1461,25-1541,25-1547,26-2015,26-2018,26-2023,26-2028,26-2031,26-2033,29-428,29-439,29-451 |
| CWT-LgR | 25,26,27,28 | 25-2012,25-2016,26-415,26-2004,26-2038,27-867,27-1998,27-2014,27-2049,28-2011,28-2045 |
| CWT-R′ | 24,26,27,28,210 | 24-454,26-381,26-494,26-569,26-2033,26-2319,26-2324,26-2331,27-581,27-1969,27-2076,28-408,28-572,28-594,28-1960,28-2140,210-761 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Wang, X.; Baishan, K.; An, B. Hyperspectral Estimation of Soil Organic Carbon Content Based on Continuous Wavelet Transform and Successive Projection Algorithm in Arid Area of Xinjiang, China. Sustainability 2023, 15, 2587. https://doi.org/10.3390/su15032587
Huang X, Wang X, Baishan K, An B. Hyperspectral Estimation of Soil Organic Carbon Content Based on Continuous Wavelet Transform and Successive Projection Algorithm in Arid Area of Xinjiang, China. Sustainability. 2023; 15(3):2587. https://doi.org/10.3390/su15032587
Chicago/Turabian StyleHuang, Xiaoyu, Xuemei Wang, Kawuqiati Baishan, and Baisong An. 2023. "Hyperspectral Estimation of Soil Organic Carbon Content Based on Continuous Wavelet Transform and Successive Projection Algorithm in Arid Area of Xinjiang, China" Sustainability 15, no. 3: 2587. https://doi.org/10.3390/su15032587