

Healthcare Sustainability: Hospitalization Rate Forecasting with Transfer Learning and Location-Aware News Analysis

Abstract
:1. Introduction
2. Related Work
2.1. Sustainable Development in Healthcare
2.2. Time Series Forecasting in Healthcare
2.3. Social Factor Impact on Healthcare
3. Materials and Methods
3.1. Problem Formulation
3.2. Methodological Approach
3.2.1. Non-Linear Correlation Test
- White TestWhite test [71,72] is based on a neural network for neglected non-linearity, which uses hidden layers to detect the relationship between time series vectors. The network is defined aswhere is a linear component, includes nonlinear components, is a parameter vector, is the weight of the neural network model from the hidden layer to the output layer, is the weight of the neural network model from the input layer to the hidden layer, is the activation function, q is the number of hidden layers, and j is the index of hidden layers. Given historical COVID-19 cases data and hospitalization rate data , we test non-linearity between them, where k is the current time stamp and T is the historical window size. The null hypothesis can be defined asThere is a nonlinear correlation between COVID-19 infection cases and hospitalization rates if we reject the null hypothesis according to the chi-square and F distribution.
- Granger Causality TestGranger causality is a statistical hypothesis test that evaluates the causal relationship between multiple time series. It is widely used in economics, financial econometrics, and business [73,74]. Given the time series variables X and Y, Granger causes when happens prior to its effect, and has unique information about the prediction of the future value , where k is the current time stamp and T is the historical window size. The Granger causality is typically calculated with the following bivariate linear autoregressive model:where L is the largest historical window size (lag value), the residual is a white noise series and Granger causes if the null hypothesis is rejected according to the F-test.
- Brownian Distance CorrelationSzékely and Rizzo [75] proposed Brownian distance correlation and distance covariance to measure the nonlinear dependence and test the joint independence of random vectors in multiple dimensions. Given the random variables X and Y, the distance covariance measures the distance between and :where is the norm, t and s are vectors, and are the characteristic functions of X and Y, and is their joint characteristic function. In an empirical version, is designed to test the independence hypothesis:The distance correlation is defined aswhere . In this paper, we aim to use the Brownian distance correlation for testing the non-linear dependence of hospitalization rates in the current time k on the COVID-19 infection cases with window size T. If and , there is a correlation between and .
3.2.2. Sentiment and Semantic Analysis
- Valence Aware Dictionary for sEntiment Reasoning (VADER)VADER [56] is a text analysis method that can be used to measure the word vector’s emotions, sentiments, and attitudes. It is an unsupervised analysis that can leverage the sentiment lexicon to annotate the emotion polarity score for each word of unlabeled data. The range of polarities is [−1, 1], where 1 indicates an extremely positive attitude, 0 indicates a neutral attitude, and −1 indicates an extremely negative attitude. VADER is able to aggregate the polarity scores from individual words in a sentence to represent overall sentence sentiment. Each sentence produces a vector of sentiment scores with negative, neutral, positive, and compound polarities. The compound polarity represents an aggregate measure of all the other sentiments.
- Sentence-BERT (SBERT)BERT [59] is a transformer-based machine learning technique for natural language processing. SBERT [60] is a derivation of the pre-trained BERT network that leverages siamese and triplet network structures to generate semantic embeddings that can be compared using cosine similarity. Given sentences A and B with varying lengths, SBERT creates fixed-size embeddings u and v using BERT and a pooling layer. These pairs of sentences are identical down to every parameter.
3.2.3. TLSS: Transfer Learning Architecture with Dynamic Location-Aware Sentiment and Semantic Analysis
- Heterogeneous Transfer Learning (HTL)HTL [76] focuses on transferring knowledge from the source domain to a different but related target domain, in which data are heterogeneous in both feature and label spaces (see Appendix A). The HTL module of TLSS aims to learn the general patterns of existing epidemics (e.g., flu) and transfer the learned knowledge to forecast the hospitalization rates during the new pandemic (e.g., COVID-19). The base model is a cross-location attention-based graph neural network (Cola-GNN) [77], which is designed to combine the temporal dependencies and geolocation correlation for predicting long-term influenza-like illnesses (ILI). We pre-train the source model and share part of the parameters with the target model as initializations: . Then, we fine-tune the target model TLSS on hospitalization rate data during COVID-19 and collect its hidden states. This transformation is defined as , where i is the index for a location and k is the index for a time stamp. Following the above process, we project the learned representation from the heterogeneous transfer learning module into the prediction module and combine it with news sentiment and semantic features for final predictions.
- Multimodal Data LearningThe multimodal data learning module captures the temporal dependencies of hospitalization rates and encodes sentiment and semantic features over time. It contains a dynamic location-aware analysis for sentiment and semantic features, which dynamically model the public emotions and opinions in different locations during COVID-19 from news data. Given pre-trained news sentiment data and semantic data , where and are the embeddings to represent the average emotion score and semantic feature of day t’s news for location i, the module processes thw data as the following steps:
- (1)
- For each timestamp k, calculate the cosine similarity for news sentiment data () and news semantic data () with window size T between every two locations i and j:where and represent the sentiment and semantic embeddings of location i, respectively, for the time-span . The concat is a concatenation function for reshaping the semantic embedding dimension into .
- (2)
- Implement the location-aware attention mechanism to create an attention coefficient matrix A, for measuring the sentiment/semantic dependencies between every two locations i and j, where the coefficient in A is defined aswhere and are the last hidden state of an RNN model for location i and location j, , , , , and are trainable parameters.
- (3)
- Adopt an element gate to combine the sentiment/semantic cosine similarity matrix / and attention coefficient matrix A:where and are trainable parameters.
- (4)
- Apply linear transformation to the location-aware attention matrix of sentiment and semantics :where and are dynamic matrices of sentiment and semantic features that change over different time stamps, and W and b are the trainable parameters for each equation.
- PredictionTLSS also learns RNN hidden states from historical hospitalization rates with window size T. The prediction module combines the embedding of news sentiment feature (), the embedding of news semantic feature (), the hidden states () from the RNN model, and the hidden states learned from Cola-GNN () in the latent space.where is the activation function, and are trainable parameters. D is the dimension of RNN hidden states and sentiment/semantic embeddings, and F is the dimension of the hidden states from the transferred knowledge of the source model.
3.2.4. Evaluation Metrics
- DM-test measures the difference between the predicted values from two models () and the corresponding observed values :
- The Root Mean Squared Error (RMSE) is the standard deviation of the residuals, which measures the difference between the predicted values from a model and the corresponding observed values :
3.2.5. Comparison Methods
3.3. Data Description
3.3.1. Dataset Description
- Hospitalization rate data are collected from the CDC COVID-19 Reported Patient Impact and Hospital Capacity by State Time Series [78]. It comprises the daily count of newly admitted patients with confirmed COVID-19 (new admission counts) in 50 US states. In the country-level experiment, we aggregate hospitalization rates by location.
- COVID-19 Cases Data are collected from CDC US-COVID-19-Cases [8]. It comprises the daily count of newly confirmed COVID-19 cases (new patient counts) in 50 US states. In the country-level experiment, we aggregate COVID-19 cases by location.
- Country-level COVID-19 Original News Data are collected from Refinitiv Real-time News [79], which comprises news articles related to COVID-19 in the United States.
- State-level COVID-19 Original News Data are collected from the Global Database of Events, Language, and Tone (GDELT) [80], which comprises news articles related to COVID-19 in 50 US states.
- Pre-trained News Sentiment Data (Country-level and State-level) are the sentiment-related features extracted from each news article. We pre-train the original country-level and state-level news data using VADER.
- Pre-trained News Semantic Data (Country-level and State-level) are the semantic-related features extracted from each news article. We pre-train the original country-level and state-level news data using SBERT.
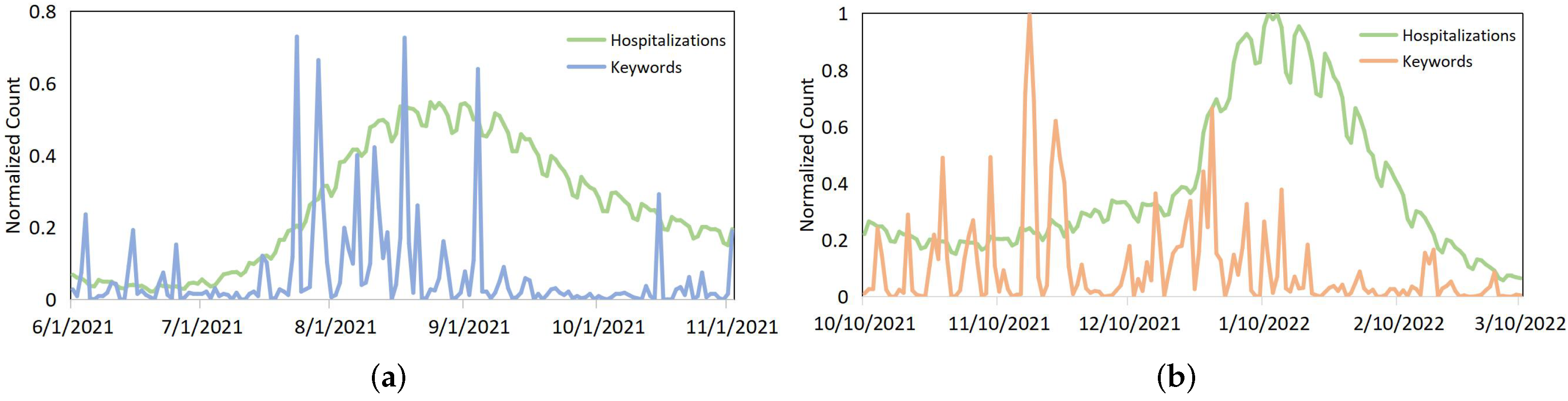
3.3.2. Visual Examples to Describe the Association between Hospitalization Rates and News
3.4. Experiment Setup
3.4.1. Country-Level and State-Level Experiments
3.4.2. Pre-Train Sentiment and Semantic Data
3.4.3. Ablation Test
- TLSS w/o transfer learning: Exclude the transfer learning module in TLSS and conduct training on the hospitalization rate data without utilizing knowledge learned from existing epidemics, such as the flu.
- TLSS w/o sentiment analysis: Exclude the sentiment analysis module in TLSS and ignore the sentiment information in news data.
- TLSS w/o semantic analysis: Exclude the semantic analysis module in TLSS and ignore the semantic information in news data.
4. Results
4.1. Non-Linear Correlation Test Result
4.2. Country-Level Experiment
4.3. State-Level Experiment
4.4. Ablation Test
5. Discussion
5.1. Healthcare Sustainability during an Emerging Pandemic
5.2. Strength and Applicability of TLSS
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Heterogeneous Transfer Learning (HTL)
Appendix B. Comparison Methods
- Autoregressive (AR)AR is a statistical model, which can result in accurate forecasts of time series problems. It uses historical data as an input to linear regression to predict future values. In the experiment, we train independent AR models for different locations. The hyperparameter lag (p) is set up as window size T. The optimization method of AR is gradient descent. Particularly, the AR model is estimated using ordinary least squares (OLS) with the Python function .
- Autoregressive Moving Average (ARMA)ARMA is derived from merging the AR and the moving average (MA) models to optimize the explanation of the behavior of time series. In the experiment, the hyperparameter order(q) is set as smoothing window size 2. The optimization method of ARMA is gradient descent. Particularly, the ARMA model is estimated using ordinary least squares (OLS) with the Python function .
- Vector Autoregressive (VAR)VAR is derived from AR and modeled as a linear combination model that includes the cross-signal dependence of multivariate time series. Thus, it contains more parameters and takes a longer running time than AR.
- Recurrent Neural Network (RNN)RNN is a powerful artificial neural network for temporal dependencies learning. It is composed of hidden layers of neurons to recognize data’s sequential characteristics for predicting the next likely output. In the experiment, we implement it with an input vector of features (e.g., hospitalization rates, COVID-19 cases, and news sentiment and semantic information) of multiple locations.
- Long- and Short-term Time-series network (LSTNet)LSTNet leverages both Convolution Neural Network (CNN) and Recurrent Neural Network (RNN) to capture short-term local dependency patterns from multiple features and to learn long-term patterns in time series.
- Cross-Location Attention Based Graph Neural Network (Cola-GNN)Cola-GNN is a neural network that combines graph structures and time series features at the macroscopic level (e.g., geolocation) for long-term influenza-like illness (ILI) prediction. We apply it in hospitalization rate prediction during COVID-19 in 50 US states. It is the source model of TLSS.
Appendix C. State-Level Non-Linear Correlation Test Results for Hospitalization Rates and Infection Cases during COVID-19

{kind=link}
| State | White Test (p-Value) | Granger Causality Test (p-Value) | Distance Correlation Test (p-Value) | Distance Correlation |
|---|---|---|---|---|
| AK | 0.0000 | 0.0000 | 0.4754 | |
| AL | 0.0000 | 0.0000 | 0.7892 | |
| AR | 0.0000 | 0.0000 | 0.7755 | |
| AZ | 0.0000 | 0.0000 | 0.7597 | |
| CA | 0.0000 | 0.0000 | 0.6424 | |
| CO | 0.0000 | 0.0000 | 0.8058 | |
| CT | 0.0000 | 0.0000 | 0.6481 | |
| DE | 0.0000 | 0.0000 | 0.7851 | |
| FL | 0.0000 | 0.0000 | 0.8502 | |
| GA | 0.0112 | 0.0000 | 0.6864 | |
| HI | 0.0120 | 0.0000 | 0.4844 | |
| IA | 0.0000 | 0.0000 | 0.6769 | |
| ID | 0.0341 | 0.0000 | 0.6621 | |
| IL | 0.0000 | 0.0000 | 0.7025 | |
| IN | 0.0000 | 0.0000 | 0.7405 | |
| KS | 0.2053 | 0.0000 | 0.4463 | |
| KY | 0.0000 | 0.0000 | 0.5497 | |
| LA | 0.0000 | 0.0000 | 0.7255 | |
| MA | 0.0000 | 0.0000 | 0.6663 | |
| MD | 0.0000 | 0.0000 | 0.7391 | |
| ME | 0.0501 | 0.0000 | 0.7308 | |
| MI | 0.0000 | 0.0000 | 0.5963 | |
| MN | 0.0000 | 0.0000 | 0.6457 | |
| MO | 0.0000 | 0.0000 | 0.6697 | |
| MS | 0.0000 | 0.0000 | 0.6909 | |
| MT | 0.0000 | 0.0000 | 0.6552 | |
| NC | 0.0000 | 0.0000 | 0.7902 | |
| ND | 0.0000 | 0.0000 | 0.7423 | |
| NE | 0.0000 | 0.0000 | 0.6837 | |
| NH | 0.0000 | 0.0000 | 0.6019 | |
| NJ | 0.0000 | 0.0000 | 0.8243 | |
| NM | 0.0989 | 0.0000 | 0.6358 | |
| NV | 0.0000 | 0.0000 | 0.6616 | |
| NY | 0.0000 | 0.0000 | 0.8158 | |
| OH | 0.0000 | 0.0000 | 0.7704 | |
| OK | 0.0000 | 0.0000 | 0.6853 | |
| OR | 0.0000 | 0.0000 | 0.6306 | |
| PA | 0.0000 | 0.0000 | 0.8171 | |
| RI | 0.0000 | 0.0000 | 0.7495 | |
| SC | 0.0000 | 0.0000 | 0.8647 | |
| SD | 0.0000 | 0.0000 | 0.6805 | |
| TN | 0.0000 | 0.0000 | 0.8345 | |
| TX | 0.0000 | 0.0000 | 0.7654 | |
| UT | 0.0000 | 0.0000 | 0.6436 | |
| VA | 0.0000 | 0.0000 | 0.6780 | |
| VT | 0.0000 | 0.0000 | 0.5499 | |
| WA | 0.0000 | 0.0000 | 0.7753 | |
| WI | 0.0000 | 0.0000 | 0.7033 | |
| WV | 0.0000 | 0.0000 | 0.7975 | |
| WY | 0.0256 | 0.0000 | 0.6563 |
References
- Ranjbari, M.; Shams Esfandabadi, Z.; Zanetti, M.C.; Scagnelli, S.D.; Siebers, P.O.; Aghbashlo, M.; Peng, W.; Quatraro, F.; Tabatabaei, M. Three pillars of sustainability in the wake of COVID-19: A systematic review and future research agenda for sustainable development. J. Clean. Prod. 2021, 297, 126660. [Google Scholar] [CrossRef] [PubMed]
- Jiang, P.; Klemeš, J.J.; Van Fan, Y.; Fu, X.; Bee, Y.M. More is not enough: A deeper understanding of the COVID-19 impacts on healthcare, energy and environment is crucial. Int. J. Environ. Res. Public Health 2021, 18, 684. [Google Scholar] [CrossRef] [PubMed]
- Thakur, V. Framework for PESTEL dimensions of sustainable healthcare waste management: Learnings from COVID-19 outbreak. J. Clean. Prod. 2021, 287, 125562. [Google Scholar] [CrossRef] [PubMed]
- Countries Where Coronavirus Has Spread—Worldometer. Available online: https://www.worldometers.info/coronavirus/countries-where-coronavirus-has-spread/ (accessed on 5 July 2023).
- Zhu, H.; Wei, L.; Niu, P. The novel coronavirus outbreak in Wuhan, China. Glob. Health Res. Policy 2020, 5, 6. [Google Scholar] [CrossRef]
- Mohan, B.S.; Vinod, N. COVID-19: An insight into SARS-CoV2 pandemic originated at Wuhan city in Hubei province of China. J. Infect. Dis. Epidemiol. 2020, 6, 146. [Google Scholar] [CrossRef]
- WHO Coronavirus (COVID-19) Dashboard. Available online: https://covid19.who.int/ (accessed on 1 May 2023).
- CDC COVID-19 Response. United States COVID-19 Cases and Deaths by State over Time. Available online: https://data.cdc.gov/Case-Surveillance/United-States-COVID-19-Cases-and-Deaths-by-State-o/9mfq-cb36 (accessed on 1 May 2023).
- Hakovirta, M.; Denuwara, N. How COVID-19 Redefines the Concept of Sustainability. Sustainability 2020, 12, 3727. [Google Scholar] [CrossRef]
- Lennox, L.; Doyle, C.; Reed, J.E.; Bell, D. What makes a sustainability tool valuable, practical and useful in real-world healthcare practice? A mixed-methods study on the development of the Long Term Success Tool in Northwest London. BMJ Open 2017, 7, e014417. [Google Scholar] [CrossRef]
- Lennox, L.; Maher, L.; Reed, J. Navigating the sustainability landscape: A systematic review of sustainability approaches in healthcare. Implement. Sci. 2018, 13, 27. [Google Scholar] [CrossRef]
- Sherman, J.D.; Thiel, C.; MacNeill, A.; Eckelman, M.J.; Dubrow, R.; Hopf, H.; Lagasse, R.; Bialowitz, J.; Costello, A.; Forbes, M.; et al. The Green Print: Advancement of Environmental Sustainability in Healthcare. Resour. Conserv. Recycl. 2020, 161, 104882. [Google Scholar] [CrossRef]
- Mortimer, F.; Isherwood, J.; Wilkinson, A.; Vaux, E. Sustainability in quality improvement: Redefining value. Future Healthc. J. 2018, 5, 88. [Google Scholar] [CrossRef]
- Goh, C.Y.; Marimuthu, M. The path towards healthcare sustainability: The role of organisational commitment. Procedia Soc. Behav. Sci. 2016, 224, 587–592. [Google Scholar] [CrossRef]
- Dash, S.; Shakyawar, S.K.; Sharma, M.; Kaushik, S. Big data in healthcare: Management, analysis and future prospects. J. Big Data 2019, 6, 54. [Google Scholar] [CrossRef]
- Duan, W.; Fan, Z.; Zhang, P.; Guo, G.; Qiu, X. Mathematical and computational approaches to epidemic modeling: A comprehensive review. Front. Comput. Sci. 2015, 9, 806–826. [Google Scholar] [CrossRef] [PubMed]
- Afzal, A.; Saleel, C.A.; Bhattacharyya, S.; Satish, N.; Samuel, O.D.; Badruddin, I.A. Merits and limitations of mathematical modeling and computational simulations in mitigation of COVID-19 pandemic: A comprehensive review. Arch. Comput. Methods Eng. 2022, 29, 1311–1337. [Google Scholar] [CrossRef] [PubMed]
- Makridakis, S. A Survey of Time Series. ISR 1976, 44, 29–70. [Google Scholar] [CrossRef]
- Cheng, Q.; Argon, N.T.; Evans, C.S.; Liu, Y.; Platts-Mills, T.F.; Ziya, S. Forecasting emergency department hourly occupancy using time series analysis. Am. J. Emerg. Med. 2021, 48, 177–182. [Google Scholar] [CrossRef]
- Perone, G. Comparison of ARIMA, ETS, NNAR, TBATS and hybrid models to forecast the second wave of COVID-19 hospitalizations in Italy. Eur. J. Health Econ. 2022, 23, 917–940. [Google Scholar] [CrossRef]
- Chen, J.; Li, K.; Zhang, Z.; Li, K.; Yu, P.S. A Survey on Applications of Artificial Intelligence in Fighting Against COVID-19. ACM Comput. Surv. 2020, 54, 1–32. [Google Scholar] [CrossRef]
- Morens, D.M.; Fauci, A.S. Emerging infectious diseases in 2012: 20 years after the institute of medicine report. MBio 2012, 3, e00494-12. [Google Scholar] [CrossRef]
- Morens, D.M.; Daszak, P.; Taubenberger, J.K. Escaping Pandora’s box—Another novel Coronavirus. N. Engl. J. Med. 2020, 382, 1293–1295. [Google Scholar] [CrossRef]
- Creamer, G.G.; Creamer, B. A Non-Linear Dependence Analysis of Oil, Coal and Natural Gas Futures with Brownian Distance Correlation. In Proceedings of the 2014 AAAI Fall Symposia, Arlington, VI, USA, 13–15 November 2014. [Google Scholar]
- Bekalu, M.A.; McCloud, R.F.; Viswanath, K. Association of social media use with social well-being, positive mental health, and self-rated health: Disentangling routine use from emotional connection to use. Health Educ. Behav. 2019, 46, 69–80. [Google Scholar] [CrossRef] [PubMed]
- Al-Dmour, H.; Masa’deh, R.; Salman, A.; Abuhashesh, M.; Al-Dmour, R. Influence of social media platforms on public health protection against the COVID-19 pandemic via the mediating effects of public health awareness and behavioral changes: Integrated model. J. Med. Internet Res. 2020, 22, e19996. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Creamer, G.G.; Ning, Y. Forecasting Emerging Pandemics with Transfer Learning and Location-aware News Analysis. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; pp. 874–883. [Google Scholar]
- Buffoli, M.; Capolongo, S.; Bottero, M.; Cavagliato, E.; Speranza, S.; Volpatti, L. Sustainable Healthcare: How to assess and improve healthcare structures’ sustainability. Ann. Ig. 2013, 25, 411–418. [Google Scholar] [PubMed]
- Ramirez, B.; J. West, D.; M. Costell, M. Development of a culture of sustainability in health care organizations. J. Health Organ. Manag. 2013, 27, 665–672. [Google Scholar] [CrossRef] [PubMed]
- Sun, D.; Wang, F.; Chen, N.; Chen, J. The Impacts of Technology Shocks on Sustainable Development from the Perspective of Energy Structure—A DSGE Model Approach. Sustainability 2021, 13, 8665. [Google Scholar] [CrossRef]
- Jamaludin, N.H.; Habidin, N.F.; Shazali, N.A.; Ali, N.; Khaidir, N.A. Exploring sustainable healthcare service and sustainable healthcare performance: Based on Malaysian healthcare industry. J. Sustain. Dev. Stud. 2013, 3, 14–26. [Google Scholar]
- Ling, T.; Pedersen, J.S.; Drabble, S.; Celia, C.; Brereton, L.; Tiefensee, C. Sustainable development in the National Health Service (NHS): The views and values of NHS leaders. Rand Health Q. 2012, 2, 12. [Google Scholar]
- Khatana, S.A.M.; Groeneveld, P.W. Health Disparities and the Coronavirus Disease 2019 (COVID-19) Pandemic in the USA. J. Gen. Intern. Med. 2020, 35, 2431–2432. [Google Scholar] [CrossRef]
- Capolongo, S.; Bottero, M.C.; Lettieri, E.; Buffoli, M.; Bellagarda, A.; Birocchi, M.; Cavagliato, E.; Dervishaj, A.; di Noia, M.; Gherardi, G.; et al. Healthcare Sustainability Challenge. In Improving Sustainability During Hospital Design and Operation: A Multidisciplinary Evaluation Tool; Capolongo, S., Bottero, M.C., Buffoli, M., Lettieri, E., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 1–9. [Google Scholar]
- Brambilla, A.; Apel, J.M.; Schmidt-Ross, I.; Buffoli, M.; Capolongo, S. Testing of a Multiple Criteria Assessment Tool for Healthcare Facilities Quality and Sustainability: The Case of German Hospitals. Sustainability 2022, 14, 16742. [Google Scholar] [CrossRef]
- Rees, E.M.; Nightingale, E.S.; Jafari, Y.; Waterlow, N.R.; Clifford, S.; Pearson, C.A.B.; CMMID Working Group; Jombart, T.; Procter, S.R.; Knight,, G.M. COVID-19 length of hospital stay: A systematic review and data synthesis. BMC Med. 2020, 18, 270. [Google Scholar] [CrossRef]
- Gul, M.; Celik, E. An exhaustive review and analysis on applications of statistical forecasting in hospital emergency departments. Health Syst. 2020, 9, 263–284. [Google Scholar] [CrossRef] [PubMed]
- Nsoesie, E.O.; Brownstein, J.S.; Ramakrishnan, N.; Marathe, M.V. A systematic review of studies on forecasting the dynamics of influenza outbreaks. Influenza Other Respir. Viruses 2014, 8, 309–316. [Google Scholar] [CrossRef] [PubMed]
- Brockwell, P.J.; Davis, R.A. Time Series: Theory and Methods; Springer: Berlin/Heidelberg, Germany, 1986. [Google Scholar]
- Mahalakshmi, G.; Sridevi, S.; Rajaram, S. A survey on forecasting of time series data. In Proceedings of the ICCTIDE’16, Kovilpatti, India, 7–9 January 2016; pp. 1–8. [Google Scholar]
- Liu, Z.; Zhu, Z.; Gao, J.; Xu, C. Forecast Methods for Time Series Data: A Survey. IEEE Access 2021, 9, 91896–91912. [Google Scholar] [CrossRef]
- Dama, F.; Sinoquet, C. Time Series Analysis and Modeling to Forecast: A Survey. arXiv 2021, arXiv:2104.00164. [Google Scholar]
- Soltani, M.; Farahmand, M.; Pourghaderi, A.R. Machine learning-based demand forecasting in cancer palliative care home hospitalization. J. Biomed. Inform. 2022, 130, 104075. [Google Scholar] [CrossRef]
- Lim, B.; Zohren, S. Time-series forecasting with deep learning: A survey. Philos. Trans. A Math. Phys. Eng. Sci. 2021, 379, 20200209. [Google Scholar] [CrossRef]
- Miotto, R.; Wang, F.; Wang, S.; Jiang, X.; Dudley, J.T. Deep learning for healthcare: Review, opportunities and challenges. Brief. Bioinform. 2018, 19, 1236–1246. [Google Scholar] [CrossRef]
- Cheng, L.; Ren, Y.; Zhang, K.; Pan, L.; Shi, Y. Hospitalization Behavior Prediction Based on Attention and Time Adjustment Factors in Bidirectional LSTM. In Proceedings of the Database Systems for Advanced Applications; Li, G., Yang, J., Gama, J., Natwichai, J., Tong, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 397–401. [Google Scholar]
- Kaushik, S.; Choudhury, A.; Dasgupta, N.; Natarajan, S.; Pickett, L.A.; Dutt, V. Ensemble of Multi-headed Machine Learning Architectures for Time-Series Forecasting of Healthcare Expenditures. In Applications of Machine Learning; Johri, P., Verma, J.K., Paul, S., Eds.; Springer: Singapore, 2020; pp. 199–216. [Google Scholar]
- Hao, T.; Huang, Z.; Liang, L.; Weng, H.; Tang, B. Health Natural Language Processing: Methodology Development and Applications. JMIR Med. Inform. 2021, 9, e23898. [Google Scholar] [CrossRef]
- Solangi, Y.A.; Solangi, Z.A.; Aarain, S.; Abro, A.; Mallah, G.A.; Shah, A. Review on Natural Language Processing (NLP) and Its Toolkits for Opinion Mining and Sentiment Analysis. In Proceedings of the 2018 IEEE 5th ICETAS, Bangkok, Thailand, 22–23 November 2018; pp. 1–4. [Google Scholar]
- Smailhodzic, E.; Hooijsma, W.; Boonstra, A.; Langley, D.J. Social media use in healthcare: A systematic review of effects on patients and on their relationship with healthcare professionals. BMC Health Serv. Res. 2016, 16, 442. [Google Scholar] [CrossRef]
- Househ, M. The use of social media in healthcare: Organizational, clinical, and patient perspectives. Stud. Health Technol. Inform. 2013, 183, 244–248. [Google Scholar]
- Du, E.; Chen, E.; Liu, J.; Zheng, C. How do social media and individual behaviors affect epidemic transmission and control? Sci. Total Environ. 2021, 761, 144114. [Google Scholar] [CrossRef] [PubMed]
- Chen, N.; Sun, D.; Chen, J. Digital transformation, labour share, and industrial heterogeneity. J. Innov. Knowl. 2022, 7, 100173. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Lamsal, R.; Harwood, A.; Read, M.R. Twitter conversations predict the daily confirmed COVID-19 cases. Appl. Soft Comput. 2022, 129, 109603. [Google Scholar] [CrossRef]
- Hutto, C.J.; Gilbert, E.E. VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text. Proc. Int. Aaai Conf. Web Soc. Media 2014, 8, 216–225. [Google Scholar] [CrossRef]
- Le, Q.V.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the 31st International Conference on Machine Learning, PMLR, Beijing, China, 21–26 June 2014. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]
- Abualigah, L.; Alfar, H.E.; Shehab, M.; Hussein, A.M.A. Sentiment analysis in healthcare: A brief review. In Recent Advances in NLP: The Case of Arabic Language; Springer: Berlin/Heidelberg, Germany, 2020; pp. 129–141. [Google Scholar]
- Greaves, F.; Ramirez-Cano, D.; Millett, C.; Darzi, A.; Donaldson, L. Use of sentiment analysis for capturing patient experience from free-text comments posted online. J. Med. Internet Res. 2013, 15, e239. [Google Scholar] [CrossRef]
- Alamoodi, A.; Zaidan, B.; Zaidan, A.; Albahri, O.; Mohammed, K.; Malik, R.; Almahdi, E.; Chyad, M.; Tareq, Z.; Albahri, A.; et al. Sentiment analysis and its applications in fighting COVID-19 and infectious diseases: A systematic review. Expert Syst. Appl. 2021, 167, 114155. [Google Scholar] [CrossRef]
- Gohil, S.; Vuik, S.; Darzi, A. Sentiment Analysis of Health Care Tweets: Review of the Methods Used. JMIR Public Health Surveill. 2018, 4, e43. [Google Scholar] [CrossRef]
- Aslam, F.; Awan, T.M.; Syed, J.H.; Kashif, A.; Parveen, M. Sentiments and emotions evoked by news headlines of coronavirus disease (COVID-19) outbreak. Humanit. Soc. Sci. Commun. 2020, 7, 23. [Google Scholar] [CrossRef]
- Matošević, G.; Bevanda, V. Sentiment analysis of tweets about COVID-19 disease during pandemic. In Proceedings of the 2020 43rd International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 28 September–2 October 2020; pp. 1290–1295. [Google Scholar]
- Mourad, A.; Srour, A.; Harmanani, H.; Jenainati, C.; Arafeh, M. Critical Impact of Social Networks Infodemic on Defeating Coronavirus COVID-19 Pandemic: Twitter-Based Study and Research Directions. IEEE Trans. Netw. Serv. Manag. 2020, 17, 2145–2155. [Google Scholar] [CrossRef]
- Mahdikhani, M. Predicting the popularity of tweets by analyzing public opinion and emotions in different stages of COVID-19 pandemic. IJIM Data Insights 2022, 2, 100053. [Google Scholar] [CrossRef]
- Zeng, K.; Pan, Z.; Xu, Y.; Qu, Y. An Ensemble Learning Strategy for Eligibility Criteria Text Classification for Clinical Trial Recruitment: Algorithm Development and Validation. JMIR Med. Inform. 2020, 8, e17832. [Google Scholar] [CrossRef]
- Gourisaria, M.K.; Chandra, S.; Das, H.; Patra, S.S.; Sahni, M.; Leon-Castro, E.; Singh, V.; Kumar, S. Semantic analysis and topic modelling of web-scrapped COVID-19 tweet corpora through data mining methodologies. Healthcare 2022, 10, 881. [Google Scholar] [CrossRef]
- Testing for neglected nonlinearity in time series models A comparison of neural network methods and alternative tests. J. Econom. 1993, 56, 269–290. [CrossRef]
- Prabowo, H.; Suhartono, S.; Prastyo, D. The Performance of Ramsey Test, White Test and Terasvirta Test in Detecting Nonlinearity. Inferensi 2020, 3, 1. [Google Scholar] [CrossRef]
- Granger, C.W.J. Investigating Causal Relations by Econometric Models and Cross-spectral Methods. Econometrica 1969, 37, 424–438. [Google Scholar] [CrossRef]
- Ghysels, E.; Swanson, N.R.; Watson, M.W. (Eds.) Essays in Econometrics: Collected Papers of Clive W. J. Granger; Cambridge University Press: Cambridge, MA, USA, 2001; Volume 1: Spectral Analysis, Seasonality, Nonlinearity, Methodology, and Forecasting. [Google Scholar]
- Székely, G.J.; Rizzo, M.L. Brownian distance covariance. Ann. Appl. Stat. 2009, 3, 1236–1265. [Google Scholar] [CrossRef]
- Day, O.; Khoshgoftaar, T.M. A survey on heterogeneous transfer learning. J. Big Data 2017, 4, 29. [Google Scholar] [CrossRef]
- Deng, S.; Wang, S.; Rangwala, H.; Wang, L.; Ning, Y. Cola-GNN: Cross-Location Attention Based Graph Neural Networks for Long-Term ILI Prediction. In Proceedings of the 29th ACM CIKM, CIKM ’20, Virtual, 19–23 October 2020; pp. 245–254. [Google Scholar]
- U.S. Department of Health and Human Services. United States COVID-19 reported patient impact and hospital capacity by State over time. Available online: https://beta.healthdata.gov/Hospital/COVID-19-Reported-Patient-Impact-and-Hospital-Capa/g62h-syeh (accessed on 29 September 2023).
- Financial Technology, Data, and Expertise. Available online: https://www.refinitiv.com/ (accessed on 30 January 2023).
- Leetaru, K.; Schrodt, P.A. GDELT: Global data on events, location, and tone. In Proceedings of the ISA Annual Convention, San Francisco, CA, USA, 3–6 April 2013. [Google Scholar]
- Symptoms of COVID-19. Available online: https://www.cdc.gov/coronavirus/2019-ncov/symptoms-testing/symptoms.html (accessed on 26 May 2023).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Fisher, R.A. Statistical Methods and Scientific Inference; Oliver and Boyd: Edinburgh, UK, 1956. [Google Scholar]
- Meng, X.L. Posterior predictive p-values. Ann. Stat. 1994, 22, 1142–1160. [Google Scholar] [CrossRef]
- Student. The probable error of a mean. Biometrika 1908, 6, 1–25. [Google Scholar] [CrossRef]
- Eckelman, M.J.; Huang, K.; Lagasse, R.; Senay, E.; Dubrow, R.; Sherman, J.D. Health Care Pollution And Public Health Damage In The United States: An Update: Study examines health care pollution and public health damage in the United States. Health Affairs 2020, 39, 2071–2079. [Google Scholar] [CrossRef]
- Zhang, D.; Ling, H.; Huang, X.; Li, J.; Li, W.; Yi, C.; Zhang, T.; Jiang, Y.; He, Y.; Deng, S.; et al. Potential spreading risks and disinfection challenges of medical wastewater by the presence of Severe Acute Respiratory Syndrome Coronavirus 2 (SARS-CoV-2) viral RNA in septic tanks of Fangcang Hospital. Sci. Total Environ. 2020, 741, 140445. [Google Scholar] [CrossRef]
- Grimm, C.A. Hospital Experiences Responding to the COVID-19 Pandemic: Results of a National Pulse Survey 23–27 March 2020; US Department of Health and Human Services Office of Inspector General: Washington, DC, USA, 2020; Volume 41. [Google Scholar]
- Ozer, I.; Cetin, O.; Gorur, K.; Temurtas, F. Improved machine learning performances with transfer learning to predicting need for hospitalization in arboviral infections against the small dataset. Neural Comput. Appl. 2021, 33, 14975–14989. [Google Scholar] [CrossRef]
- Wang, Y.; Nazir, S.; Shafiq, M. An Overview on Analyzing Deep Learning and Transfer Learning Approaches for Health Monitoring. Comput. Math. Methods Med. 2021, 2021, 5552743. [Google Scholar] [CrossRef]
- Piechocka-Kałużna, A.; Tłuczak, A.; Łopatka, P. The Impact of CSR/ESG Reporting on the Cost of Capital: An Example of US Healthcare Entities. Eur. Res. Stud. J. 2021, 24, 679–690. [Google Scholar] [CrossRef]
- Brambilla, A.; Lindahl, G.; Dell’Ovo, M.; Capolongo, S. Validation of a multiple criteria tool for healthcare facilities quality evaluation. Facilities 2020, 39, 434–447. [Google Scholar] [CrossRef]
- Ghahremanloo, M.; Hasani, A.; Amiri, M.; Hashemi-Tabatabaei, M.; Keshavarz-Ghorabaee, M.; Ustinovičius, L. A novel DEA model for hospital performance evaluation based on the measurement of efficiency, effectiveness and productivity. Eng. Manag. Prod. Serv. 2020, 12, 7–19. [Google Scholar] [CrossRef]
- Sepetis, A. Sustainable finance in sustainable health care system. Open J. Bus. Manag. 2019, 8, 262. [Google Scholar] [CrossRef]
- Moon, S.; Carbonell, J. Completely Heterogeneous Transfer Learning with Attention—What And What Not To Transfer. In Proceedings of the IJCAI’17: Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 2508–2514.
- Rodríguez, A.; Muralidhar, N.; Adhikari, B.; Tabassum, A.; Ramakrishnan, N.; Prakash, B.A. Steering a Historical Disease Forecasting Model Under a Pandemic: Case of Flu and COVID-19. arXiv 2020, arXiv:2009.11407. [Google Scholar] [CrossRef]
- Prinsen, V.; Jouvet, P.; Al Omar, S.; Masson, G.; Bridier, A.; Noumeir, R. Automatic eye localization for hospitalized infants and children using convolutional neural networks. Int. J. Med. Inform. 2021, 146, 104344. [Google Scholar] [CrossRef] [PubMed]
- Kumar, N.; Gupta, M.; Gupta, D.; Tiwari, S. Novel deep transfer learning model for COVID-19 patient detection using X-ray chest images. J. Ambient. Intell. Human Comput. 2021, 14, 469–478. [Google Scholar] [CrossRef]

| Notation | Description |
|---|---|
| T | window size of one training input |
| k | time index |
| N | number of locations |
| h | horizon/lead time of a prediction |
| feature dimensions | |
| infection cases for N locations of window size T | |
| hospitalization rates for N locations of window size T | |
| sentiment scores for N locations of window size T | |
| semantic embeddings for N locations of window size T | |
| dynamic sentiment cosine similarity of N locations | |
| dynamic semantic cosine similarity of N locations | |
| learned representations from the source model | |
| learned representations from the target model |
| Dataset | Location | Size | Max | Min |
|---|---|---|---|---|
| Hospitalization Rates | 50 | 791 | 2550 | 0 |
| COVID-19 Cases | 50 | 791 | 319,809 | 0 |
| Country-level COVID-19 Original News | - | 419 k | - | - |
| State-level COVID-19 Original News | - | 1103 k | - | - |
| Pre-trained News Sentiment (State-level) | 50 | 791 | 1 | −1 |
| Pre-trained News Semantic (State-level) | 50 | 791 × 50 | 1 | 0 |
| Pre-trained News Sentiment (Country-level) | 1 | 791 | 1 | −1 |
| Pre-trained News Semantic (Country-level) | 1 | 791 × 50 | 1 | 0 |
| White Test | Granger Causality Test | Distance Correlation Test | |
|---|---|---|---|
| p-value | 0.0000 |
| p < 0.01 | p < 0.05 | p < 0.1 | Non-Significant | |
|---|---|---|---|---|
| White Test | 50 | 0 | 0 | 0 |
| Granger Causality Test | 43 | 4 | 2 | 1 |
| Distance Correlation Test | 50 | 0 | 0 | 0 |
| Brownian Distance Correlation | >0.7 | <0.7 and >0.5 | <0.5 |
|---|---|---|---|
| Number of States | 24 | 23 | 3 |
| RMSE | Hospitalizations | Hospitalizations and COVID-19 Cases | Hospitalizations, COVID-19 Cases, and News Sentiment and Semantic Features |
|---|---|---|---|
| AR | 0.1201 | 0.0946 | 0.0928 |
| ARMA | 0.1068 | 0.1030 | 0.0704 |
| AR | 0.0079 | 0.0076 | 0.0073 |
| ARMA | 0.0076 | 0.0078 | 0.0072 |
| VAR | 0.0078 | 0.0074 | 0.0076 |
| RNN | 0.0067 | 0.0077 | 0.0084 |
| lstnet | 0.0080 | 0.0082 | 0.0079 |
| Hospitalizations vs. Hospitalizations and COVID-19 Cases | Hospitalizations vs. Hospitalizations, COVID-19 Cases, and News Sentiment and Semantic Features | Hospitalizations and COVID-19 Cases vs. Hospitalizations, COVID-19 Cases, and News Sentiment and Semantic Features | |
|---|---|---|---|
| t-statistic | 0.3842 | 0.9124 | 0.5706 |
| RMSE | Lead Time | 1 | 7 | 14 | |||
|---|---|---|---|---|---|---|---|
| Window Size | 9 | 15 | 9 | 15 | 9 | 15 | |
| hospitalizations | AR | 0.0893 *** | 0.1046 *** | ||||
| ARMA | 0.0906 *** | 0.0958 *** | |||||
| AR | 0.0427 ** | 0.0428 | 0.0472 *** | 0.0474 ** | 0.0551 *** | 0.0524 * | |
| ARMA | 0.0427 *** | 0.0429 ** | 0.0475 *** | 0.0474 ** | 0.0561 *** | 0.0569 *** | |
| VAR | 0.0488 *** | 0.0545 *** | 0.0542 *** | 0.0592 *** | 0.0686 *** | 0.0721 *** | |
| RNN | 0.0439 *** | 0.0442 *** | 0.0465 ** | 0.0472 * | 0.0556 *** | 0.0535 ** | |
| lstnet | 0.0432 *** | 0.0432 ** | 0.0468 *** | 0.0473 | 0.0524 | 0.0567 *** | |
| hospitalizations, COVID-19 cases | AR | 0.0862 *** | 0.1025 *** | ||||
| ARMA | 0.0836 *** | 0.0921 *** | |||||
| AR | 0.0430 * | 0.0427 * | 0.0489 *** | 0.0482 *** | 0.0550 *** | 0.0546 *** | |
| ARMA | 0.0435 *** | 0.0437 *** | 0.0484 *** | 0.0498 *** | 0.0565 *** | 0.0584 *** | |
| VAR | 0.0566 *** | 0.0606 *** | 0.0617 *** | 0.0671 *** | 0.0781 *** | 0.0872 *** | |
| RNN | 0.0451 *** | 0.0441 *** | 0.0478 *** | 0.0467 * | 0.0547 *** | 0.0528 * | |
| lstnet | 0.0469 *** | 0.0466 *** | 0.0524 *** | 0.0507 *** | 0.0608 *** | 0.0605 *** | |
| hospitalizations, COVID-19 cases, news features | AR | 0.2052 *** | 0.2039 *** | ||||
| ARMA | 0.1052 *** | 0.0995 *** | |||||
| AR | 0.0468 *** | 0.0443 *** | 0.0488 *** | 0.0493 *** | 0.0588 *** | 0.0572 *** | |
| ARMA | 0.0465 *** | 0.0444 *** | 0.0483 *** | 0.0515 *** | 0.0583 *** | 0.0577 *** | |
| VAR | 0.0676 *** | 0.0585 *** | 0.0683 *** | 0.0774 *** | 0.0850 *** | 0.0981 *** | |
| RNN | 0.0446 *** | 0.0453 *** | 0.0483 *** | 0.0503 *** | 0.0537 | 0.0558 *** | |
| lstnet | 0.0469 *** | 0.0469 *** | 0.0527 *** | 0.0514 *** | 0.0623 *** | 0.0638 *** | |
| hospitalizations, geolocation | Cola-GNN | 0.0419 *** | 0.0419 * | 0.0445 *** | 0.0452 * | 0.0523 | 0.0517 |
| hospitalizations, geolocation, news features | TLSS | 0.0410 | 0.0416 | 0.0429 | 0.0449 | 0.0527 | 0.0518 |
| Lead Time = 1 | Lead Time = 7 | Lead Time = 14 | |
|---|---|---|---|
| RMSE | RMSE | RMSE | |
| TLSS | 0.0416 | 0.0449 | 0.0518 |
| TLSS w/o transfer learning | 0.0418 | 0.0497 *** | 0.0581 *** |
| TLSS w/o news sentiment analysis | 0.0427 *** | 0.0466 *** | 0.0555 *** |
| TLSS w/o news semantic analysis | 0.0417 | 0.0464 ** | 0.0573 *** |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Creamer, G.G.; Ning, Y.; Ben-Zvi, T. Healthcare Sustainability: Hospitalization Rate Forecasting with Transfer Learning and Location-Aware News Analysis. Sustainability 2023, 15, 15840. https://doi.org/10.3390/su152215840
Chen J, Creamer GG, Ning Y, Ben-Zvi T. Healthcare Sustainability: Hospitalization Rate Forecasting with Transfer Learning and Location-Aware News Analysis. Sustainability. 2023; 15(22):15840. https://doi.org/10.3390/su152215840
Chicago/Turabian StyleChen, Jing, Germán G. Creamer, Yue Ning, and Tal Ben-Zvi. 2023. "Healthcare Sustainability: Hospitalization Rate Forecasting with Transfer Learning and Location-Aware News Analysis" Sustainability 15, no. 22: 15840. https://doi.org/10.3390/su152215840