
An Artificial Intelligence-Based Stacked Ensemble Approach for Prediction of Protein Subcellular Localization in Confocal Microscopy Images

 ,
,  , ,
, ,  and
and 
Abstract
:1. Introduction
- Three transfer learning models namely VGG16, ResNet152, and DenseNet169 have been used for protein subcellular localization prediction in 28 subcellular compartments and their evaluation of the three models has been conducted on the basis of precision, recall, and F1-score.
- Further improvement in results has been achieved by proposing a stacked ensemble model using the predictions obtained from three transfer learning models, and it has also been evaluated on the basis of precision, recall, and F1 score.
- Comparison in the performance of proposed stacked ensemble model has been made with the three transfer learning models.
2. Related Work
3. Materials and Method
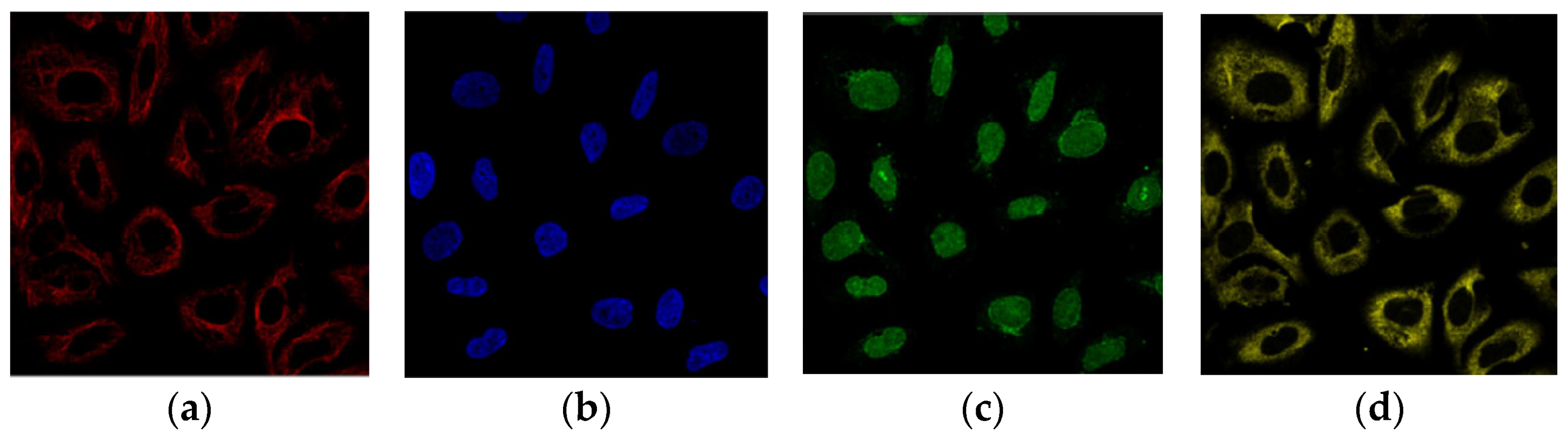
3.1. Dataset Description
3.2. Data Pre-Processing
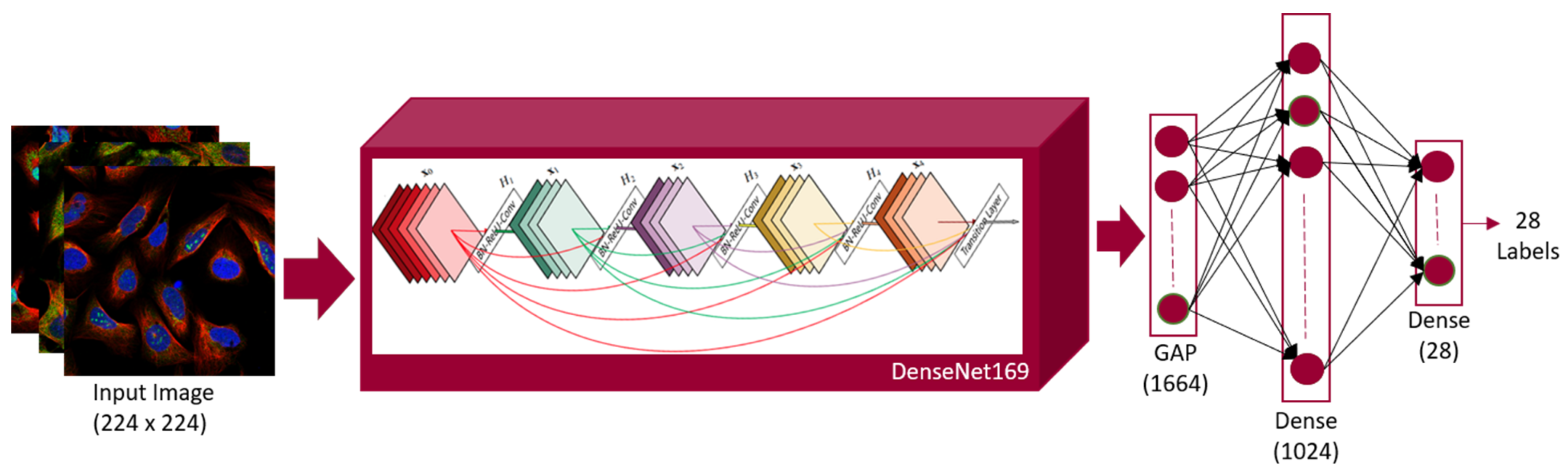
3.3. Architecture of Fine-Tuned Transfer Learning Models
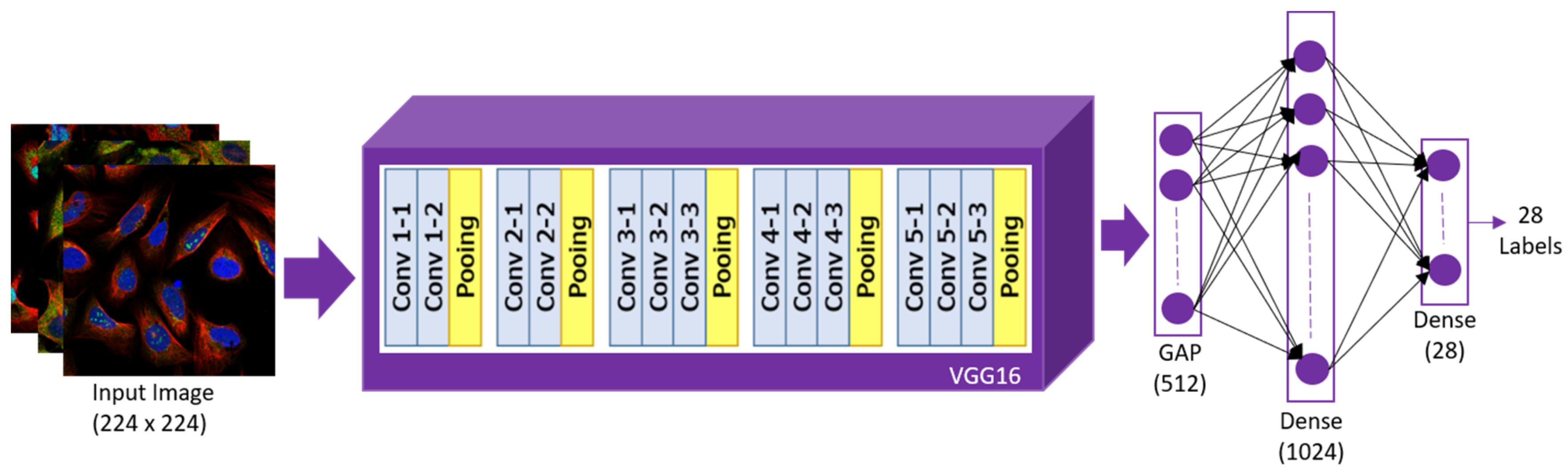
3.4. Architecture of VGG16
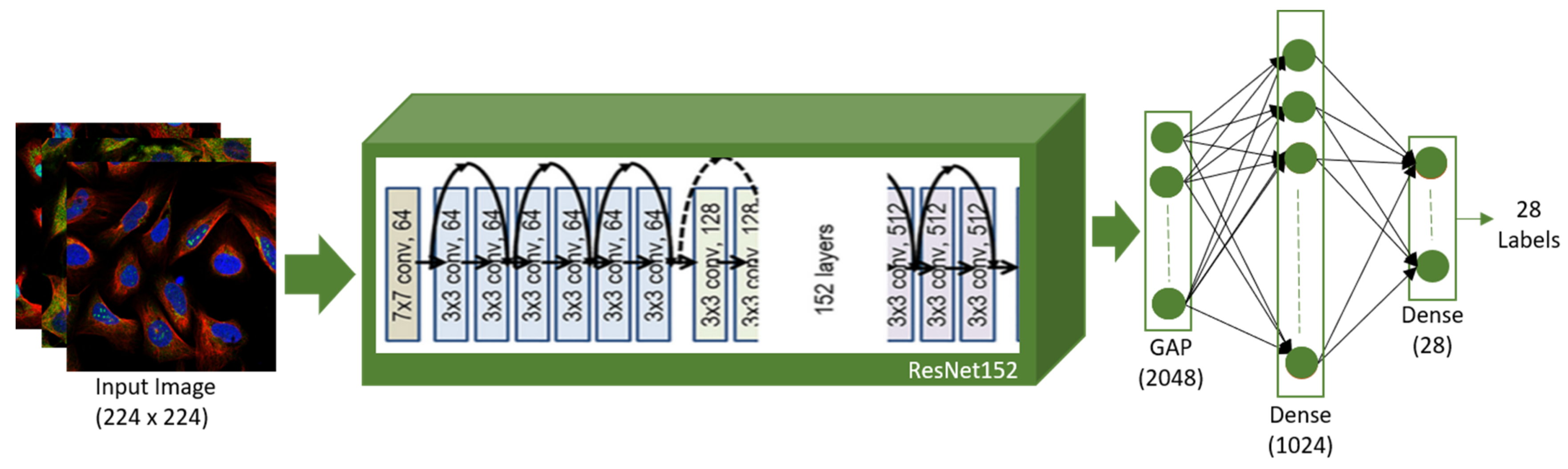
3.4.1. Architecture of ResNet152
3.4.2. Architecture of DenseNet169
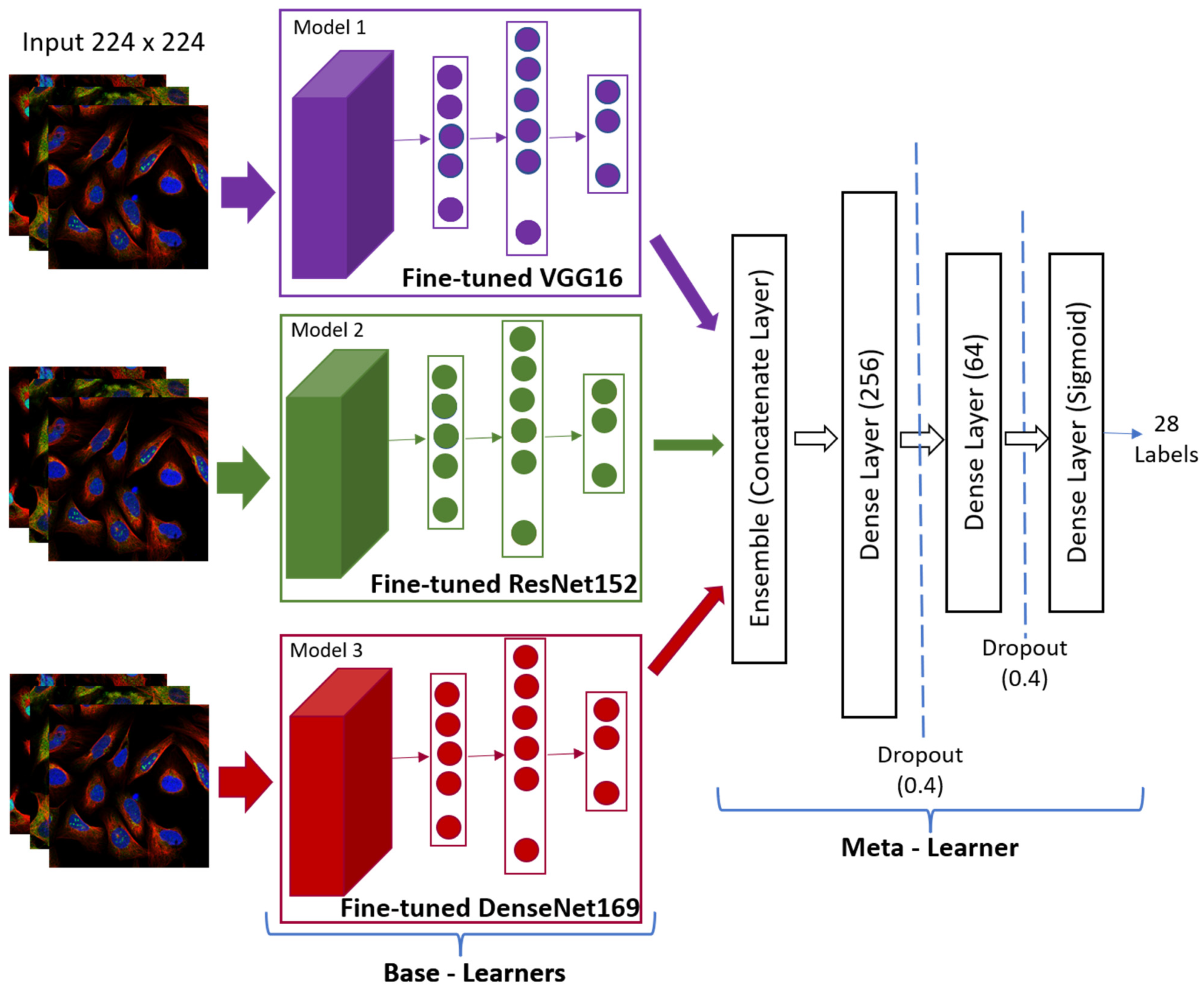
3.4.3. Architecture of the Proposed Stacked Ensemble Model
3.5. Experimental Setup
3.6. Performance Metrics
4. Results and Discussions
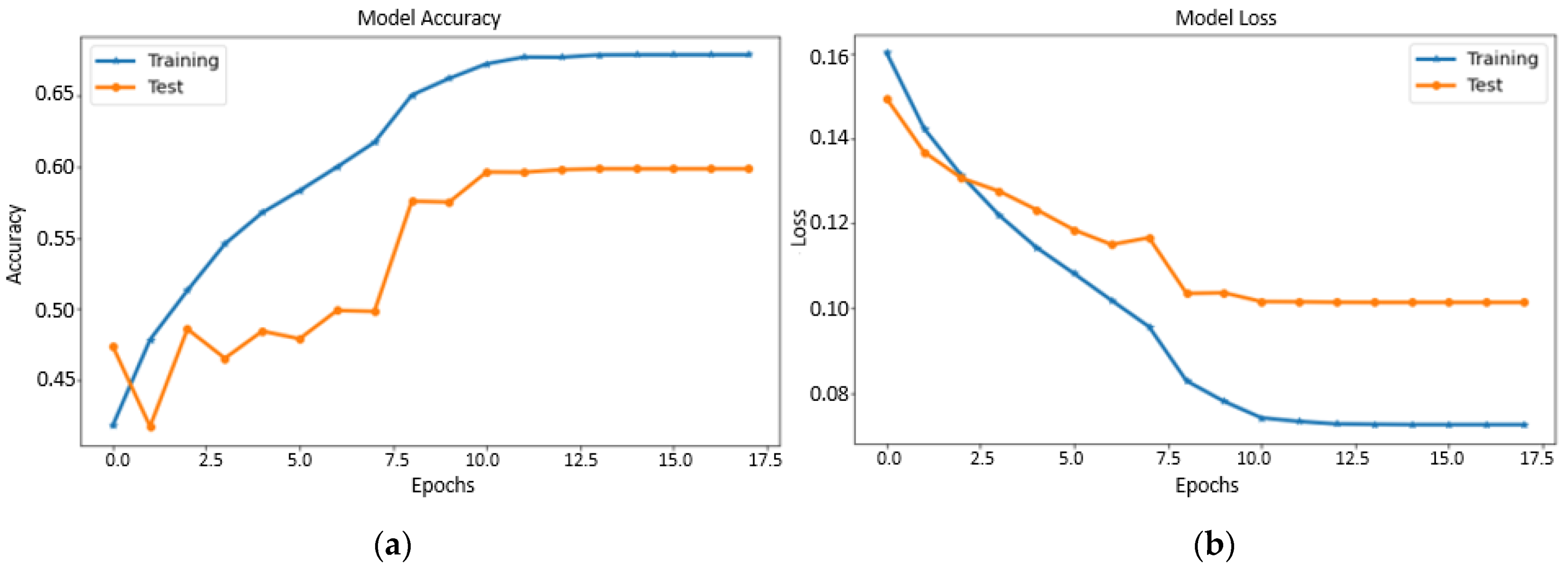
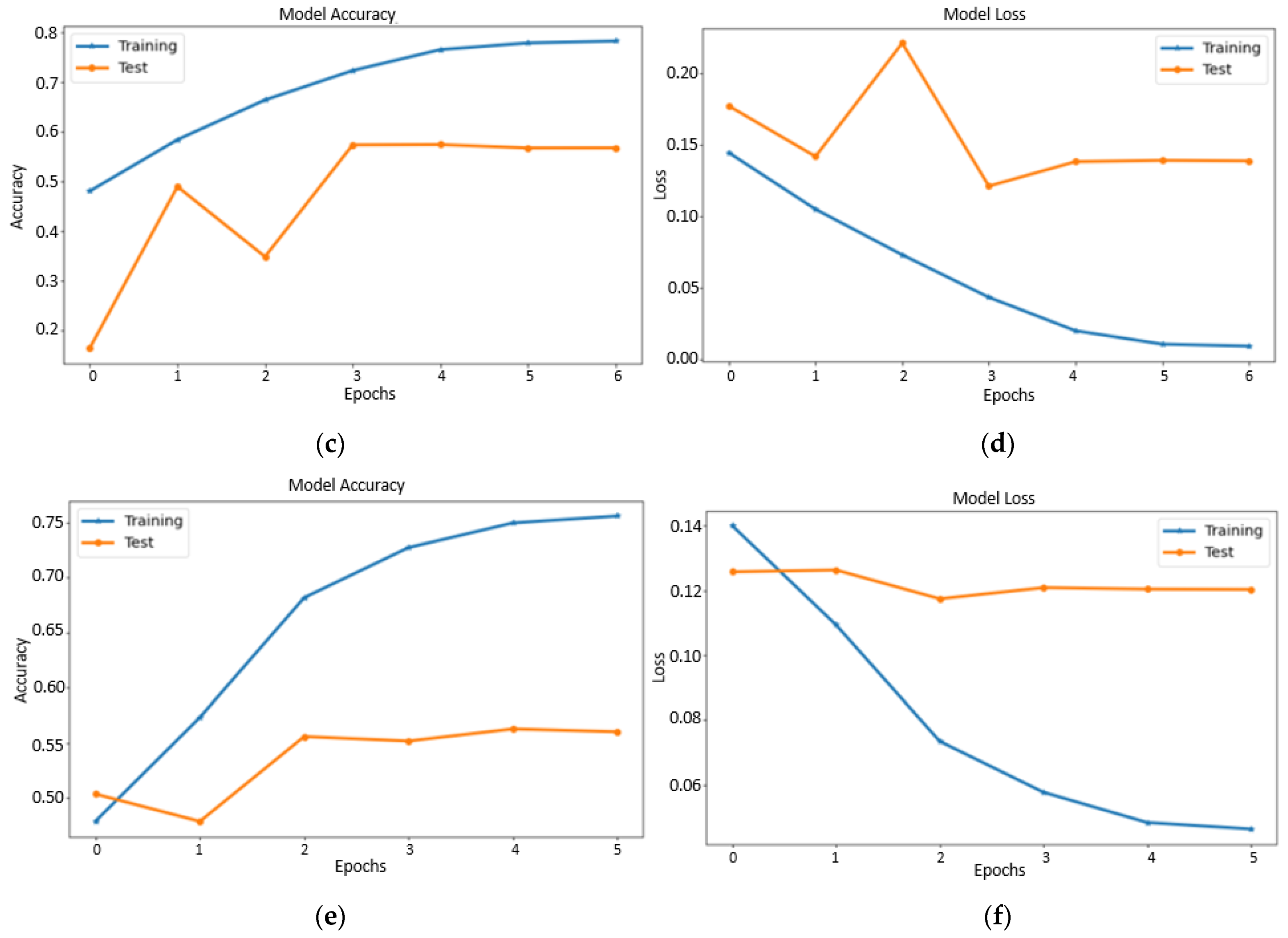
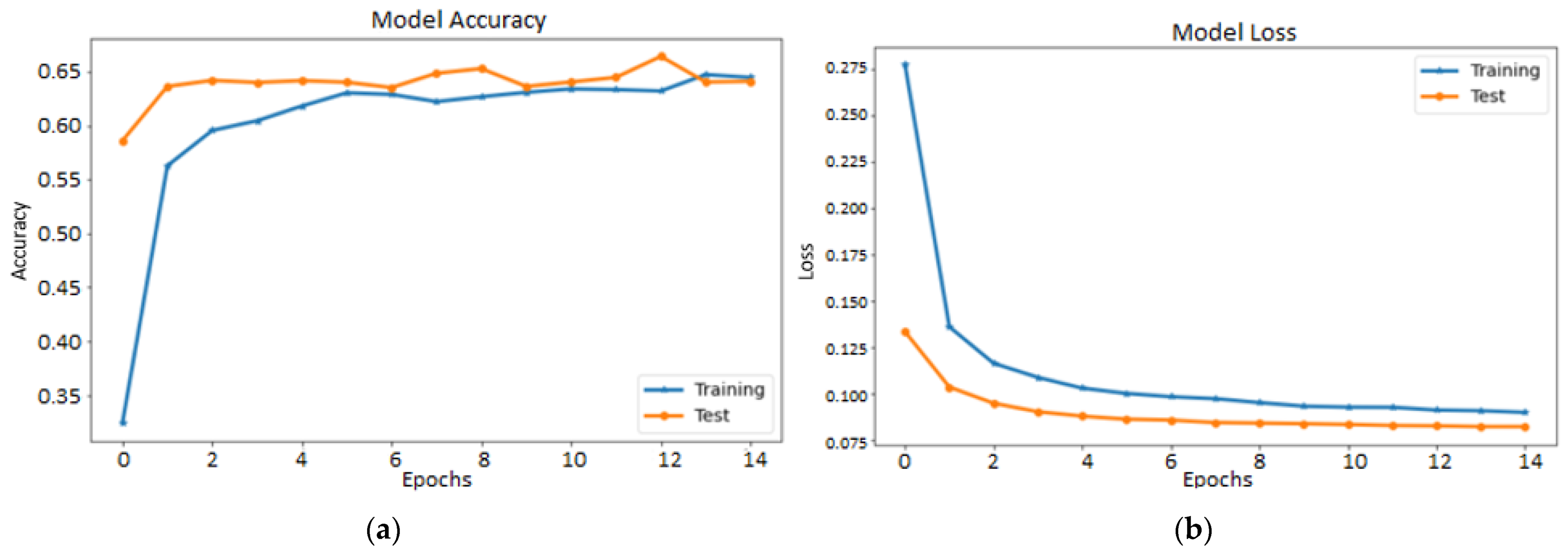
4.1. Performance of Fine-Tuned Pretrained Transfer Learning Models
4.2. Performance of the Proposed Stacked Ensemble Model
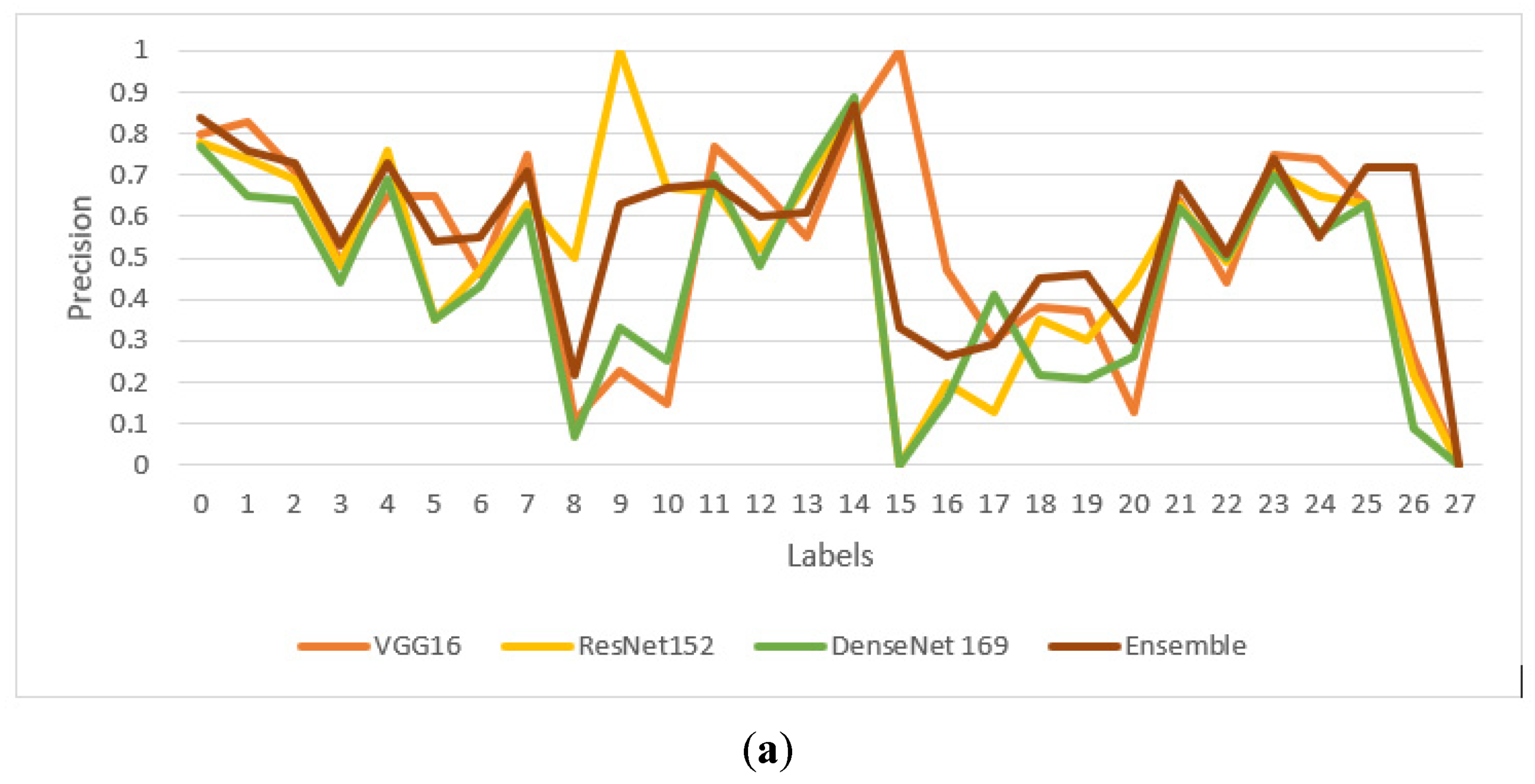
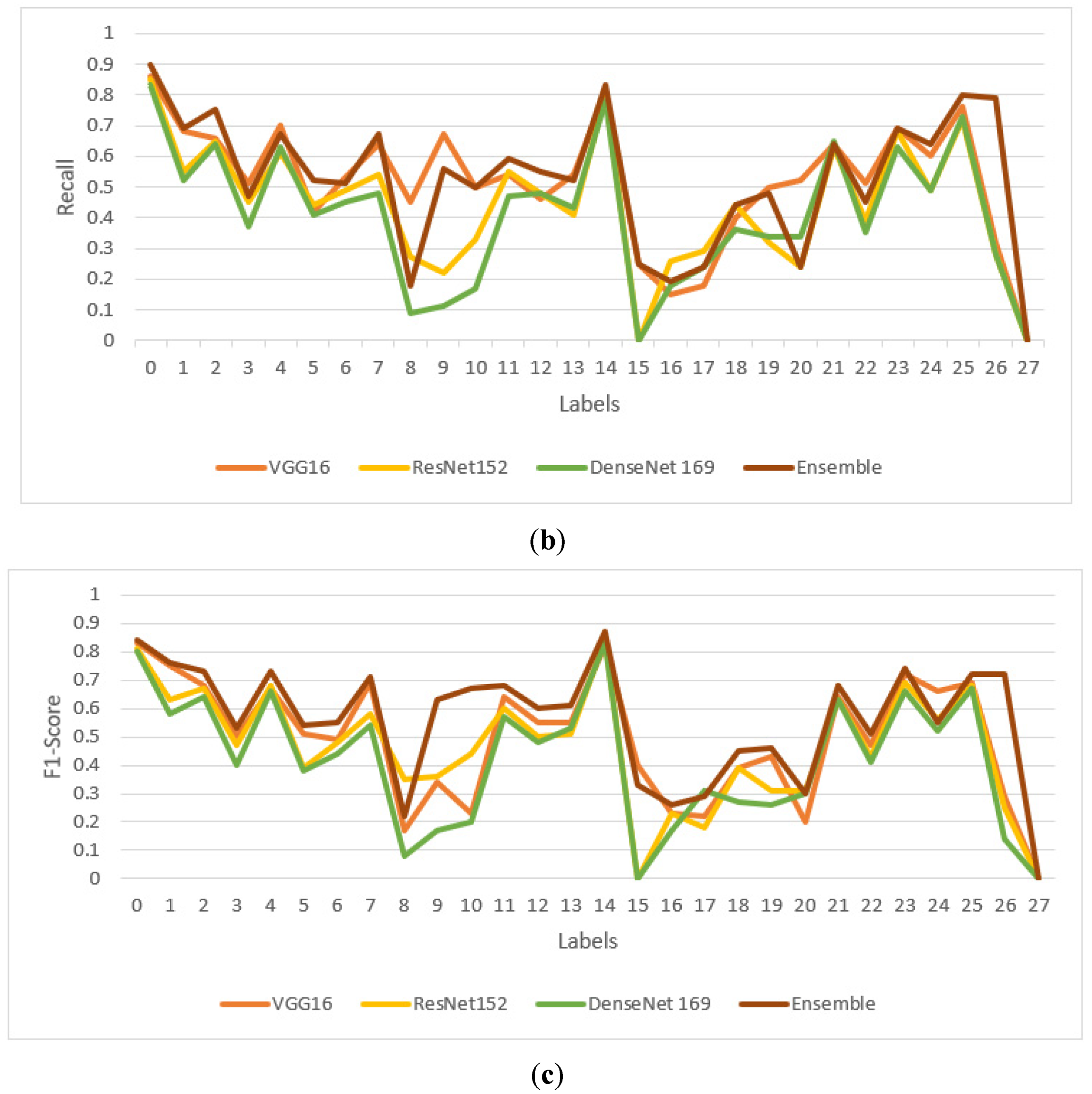
4.3. Performance Comparison of Proposed Model with Transfer Learning Models
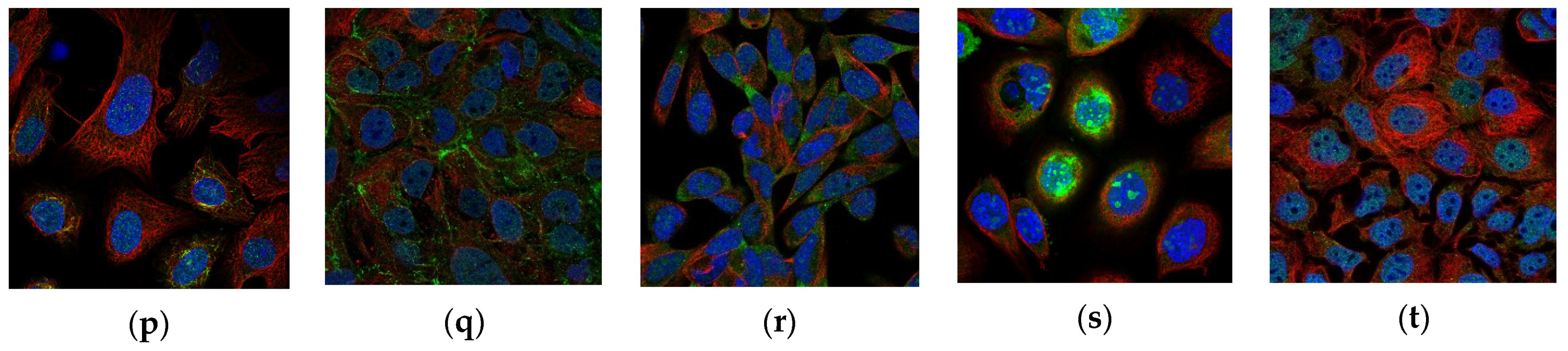
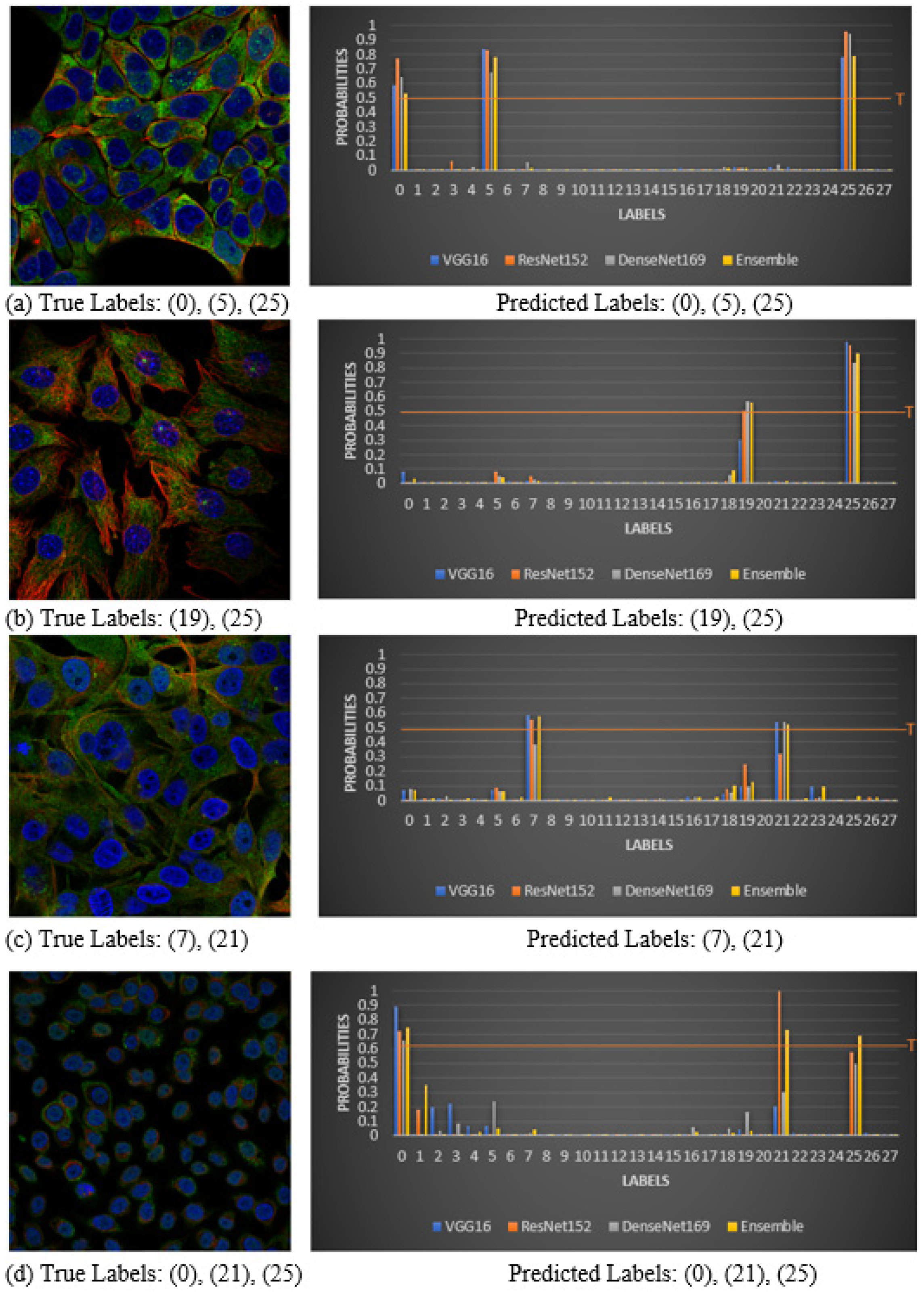
4.4. Visualization of Correct Classifications
4.5. Visualization of Incorrect Classifications
4.6. Comparison with State-of-Art
5. Conclusions and Future Scope
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Butler, G.S.; Overall, C.M. Proteomic identification of multitasking proteins in unexpected locations complicates drug targeting. Nat. Rev. Drug Discov. 2009, 8, 935–948. [Google Scholar] [CrossRef]
- Hung, M.C.; Link, W. Protein localization in disease and therapy. J. Cell Sci. 2011, 124, 3381–3392. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pepperkok, R.; Ellenberg, J. High-throughput fluorescence microscopy for systems biology. Nat. Rev. Mol. Cell Biol. 2006, 7, 690–696. [Google Scholar] [CrossRef] [PubMed]
- Uhlen, M.; Oksvold, P.; Fagerberg, L.; Lundberg, E.; Jonasson, K.; Forsberg, M.; Zwahlen, M.; Kampf, C.; Wester, K.; Hober, S.; et al. Towards a knowledge-based human protein atlas. Nat. Biotechnol. 2010, 28, 1248–1250. [Google Scholar] [CrossRef]
- Xu, Y.Y.; Yao, L.; Shen, H.B. Bioimage-based protein subcellular location prediction: A comprehensive review. Front. Comput. Sci. 2018, 12, 26–39. [Google Scholar] [CrossRef]
- Jha, K.; Doshi, A.; Patel, P.; Shah, M. A comprehensive review on automation in agriculture using artificial intelligence. Artif. Intell. Agric. 2019, 2, 1–12. [Google Scholar] [CrossRef]
- Limone, P.; Toto, G.A.; Guarini, P.; di Furia, M. Online Quantitative Research Methodology: Reflections on Good Practices and Future Perspectives. In Science and Information Conference; Springer: Cham, Switzerland, 2022; pp. 656–669. [Google Scholar]
- Vincent, D.R.; Deepa, N.; Elavarasan, D.; Srinivasan, K.; Chauhdary, S.H.; Iwendi, C. Sensors driven AI-based agriculture recommendation model for assessing land suitability. Sensors 2019, 19, 3667. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mirbabaie, M.; Stieglitz, S.; Frick, N.R. Artificial intelligence in disease diagnostics: A critical review and classification on the current state of research guiding future direction. Health Technol. 2021, 11, 693–731. [Google Scholar] [CrossRef]
- Chen, L.; Chen, P.; Lin, Z. Artificial intelligence in education: A review. IEEE Access 2020, 8, 75264–75278. [Google Scholar] [CrossRef]
- Ma, Y.; Wang, Z.; Yang, H.; Yang, L. Artificial intelligence applications in the development of autonomous vehicles: A survey. IEEE/CAA J. Autom. Sin. 2020, 7, 315–329. [Google Scholar] [CrossRef]
- Poushneh, A. Humanizing voice assistant: The impact of voice assistant personality on consumers’ attitudes and behaviors. J. Retail. Consum. Serv. 2021, 58, 102283. [Google Scholar] [CrossRef]
- Bogatinovski, J.; Todorovski, L.; Džeroski, S.; Kocev, D. Comprehensive comparative study of multi-label classification methods. Expert Syst. Appl. 2022, 203, 117215. [Google Scholar] [CrossRef]
- Cheng, X.; Lin, H.; Wu, X.; Shen, D.; Yang, F.; Liu, H.; Shi, N. Mltr: Multi-label classification with transformer. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Alhammad, M.; Avdelidis, N.P.; Ibarra Castanedo, C.; Maldague, X.; Zolotas, A.; Torbali, E.; Genest, M. Multi-label classification algorithms for composite materials under infrared thermography testing. Quant. InfraRed Thermogr. J. 2022, 1–27. [Google Scholar] [CrossRef]
- Madjarov, G.; Kocev, D.; Gjorgjevikj, D.; Džeroski, S. An extensive experimental comparison of methods for multi-label learning. Pattern Recognit. 2012, 45, 3084–3104. [Google Scholar] [CrossRef]
- Wu, G.; Zheng, R.; Tian, Y.; Liu, D. Joint ranking SVM and binary relevance with robust low-rank learning for multi-label classification. Neural Netw. 2020, 122, 24–39. [Google Scholar] [CrossRef] [Green Version]
- Levatić, J.; Ceci, M.; Kocev, D.; Džeroski, S. Semi-supervised Predictive Clustering Trees for (Hierarchical) Multi-label Classification. arXiv 2022, arXiv:2207.09237. [Google Scholar]
- Zhang, M.L.; Zhou, Z.H. ML-KNN: A lazy learning approach to multi-label learning. Pattern Recognit. 2007, 40, 2038–2048. [Google Scholar] [CrossRef] [Green Version]
- Read, J.; Pfahringer, B.; Holmes, G.; Frank, E. Classifier chains for multi-label classification. Mach. Learn. 2011, 85, 333–359. [Google Scholar] [CrossRef] [Green Version]
- Freitas Rocha, V.; Varejão, F.M.; Segatto, M.E.V. Ensemble of classifier chains and decision templates for multi-label classification. Knowl. Inf. Syst. 2022, 64, 643–663. [Google Scholar] [CrossRef]
- Pengfei, G.; Dedi, L.; Lijiao, Z.; Yue, L.; Yinglong, M. A Three-phase Augmented Classifiers Chain Approach Based on Co-occurrence Analysis for Multi-Label Classification. arXiv 2022, arXiv:2204.06138. [Google Scholar]
- Tsoumakas, G.; Katakis, I.; Vlahavas, I. Random k-labelsets for multilabel classification. IEEE Trans. Knowl. Data Eng. 2011, 23, 1079–1089. [Google Scholar] [CrossRef]
- Luaces, O.; Díez, J.; Barranquero, J.; del Coz, J.; Bahamonde, A. Binary relevance efficacy for multilabel classification. Prog. Artif. Intell. 2012, 1, 303–313. [Google Scholar] [CrossRef]
- Rastogi, R.; Mortaza, S. Imbalance multi-label data learning with label specific features. Neurocomputing 2022, 513, 395–408. [Google Scholar] [CrossRef]
- Moyano, J.M.; Gibaja, E.; Cios, K.; Ventura, S. Review of ensembles of multi-label classifiers: Models, experimental study and prospects. Inf. Fusion 2018, 44, 33–45. [Google Scholar] [CrossRef]
- Rokach, L.; Schclar, A.; Itach, E. Ensemble methods for multi-label classification. Expert Syst. Appl. 2014, 41, 7507–7523. [Google Scholar] [CrossRef] [Green Version]
- Glory, E.; Murphy, R.F. Automated subcellular location determination and high-throughput microscopy. Dev. Cell 2007, 12, 7–16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, X.; Velliste, M.; Murphy, R.F. Automated interpretation of subcellular patterns in fluorescence microscope images for location proteomics. Cytom. Part A 2006, 69A, 631–640. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tahir, M.; Khan, A.; Majid, A.; Lumini, A. Subcellular localization using fluorescence imagery: Utilizing ensemble classification with diverse feature extraction strategies and data balancing. Appl. Soft Comput. 2013, 13, 4231–4243. [Google Scholar] [CrossRef]
- Tahir, M.; Khan, A. Protein subcellular localization of fluorescence microscopy images: Employing new statistical and Texton based image features and SVM based ensemble classification. Inf. Sci. 2016, 345, 65–80. [Google Scholar] [CrossRef]
- Gadekallu, T.R.; Iwendi, C.; Wei, C.; Xin, Q. Identification of malnutrition and prediction of BMI from facial images using real-time image processing and machine learning. IET Image Process. 2021, 16, 647–658. [Google Scholar]
- Gadamsetty, S.; Ch, R.; Ch, A.; Iwendi, C.; Gadekallu, T.R. Hash-based deep learning approach for remote sensing satellite imagery detection. Water 2022, 14, 707. [Google Scholar] [CrossRef]
- Iwendi, C.; Moqurrab, S.; Anjum, A.; Khan, S.; Mohan, S.; Srivastava, G. N-sanitization: A semantic privacy-preserving framework for unstructured medical datasets. Comput. Commun. 2020, 161, 160–171. [Google Scholar] [CrossRef]
- Boland, M.V.; Murphy, R.F. A neural network classifier capable of recognizing the patterns of all major subcellular structures in fluorescence microscope images of HeLa cells. Bioinformatics 2001, 17, 1213–1223. [Google Scholar] [CrossRef] [PubMed]
- Huang, K.; Murphy, R.F. Boosting accuracy of automated classification of fluorescence microscope images for location proteomics. BMC Bioinform. 2004, 5, 78. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Newberg, J.Y.; Li, J.; Rao, A.; Pontén, F.; Uhlén, M.; Lundberg, E.; Murphy, R.F. Automated analysis of human protein atlas immunofluorescence images. In Proceedings of the 2009 IEEE International Symposium on Biomedical Imaging: From Nano to Macro, Boston, MA, USA, 28 June–1 July 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1023–1026. [Google Scholar]
- Coelho, L.P.; Kangas, J.; Naik, A.; Osuna-Highley, E.; Glory-Afshar, E.; Fuhrman, M.; Simha, R.; Berget, P.B.; Jarvik, J.W.; Murphy, R.F. Determining the subcellular location of new proteins from microscope images using local features. Bioinformatics 2013, 29, 2343–2349. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lu, A.X.; Kraus, O.; Cooper, S.; Moses, A.M. Learning unsupervised feature representations for single cell microscopy images with paired cell inpainting. PLoS Comput. Biol. 2019, 15, e1007348. [Google Scholar] [CrossRef] [Green Version]
- Liimatainen, K.; Huttunen, R.; Latonen, L.; Ruusuvuori, P. Convolutional neural network-based artificial intelligence for classification of protein localization patterns. Biomolecules 2021, 11, 264. [Google Scholar] [CrossRef]
- Li, Z.; Togo, R.; Ogawa, T.; Haseyama, M. Classification of subcellular protein patterns in human cells with transfer learning. In Proceedings of the 2019 IEEE 1st Global Conference on Life Sciences and Technologies (LifeTech), Osaka, Japan, 12–14 March 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 273–274. [Google Scholar]
- Shwetha, T.R.; Thomas, S.; Kamath, V. Hybrid Xception model for human protein atlas image classification. In Proceedings of the 2019 IEEE 16th India Council International Conference (INDICON), Rajkot, India, 13–15 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–4. [Google Scholar]
- Sullivan, D.P.; Winsnes, C.; Åkesson, L.; Hjelmare, M.; Wiking, M.; Schutten, R.; Campbell, L.; Leifsson, H.; Rhodes, S.; Nordgren, A.; et al. Deep learning is combined with massive-scale citizen science to improve large-scale image classification. Nat. Biotechnol. 2018, 36, 820–828. [Google Scholar] [CrossRef]
- Kraus, O.Z.; Grys, B.; Ba, J.; Chong, Y.; Frey, B.; Boone, C.; Andrews, B.J. Automated analysis of high-content microscopy data with deep learning. Mol. Syst. Biol. 2017, 13, 924. [Google Scholar] [CrossRef]
- Chang, H.Y.; Wu, C.L. Deep learning method to classification Human Protein Atlas. In Proceedings of the 2019 IEEE International Conference on Consumer Electronics-Taiwan, (ICCE-TW), Taiwan, China, 20–22 May 2019. [Google Scholar]
- Zhang, B.; Pham, T.D. Multiple features based two-stage hybrid classifier ensembles for subcellular phenotype images classification. Int. J. Biom. Bioinform. 2010, 4, 176. [Google Scholar]
- Tahir, M.; Khan, A.; Majid, A. Protein subcellular localization of fluorescence imagery using spatial and transform domain features. Bioinformatics 2012, 28, 91–97. [Google Scholar] [CrossRef] [Green Version]
- Human Protein Atlas Image Classification, November 2021. Available online: https://www.kaggle.com/c/human-protein-atlas-image-classification (accessed on 13 August 2022).
- Sechidis, K.; Tsoumakas, G.; Vlahavas, I. On the stratification of multi-label data. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Athens, Greece, 5–9 September 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 145–158. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Lu, Y.; Zhang, L.; Wang, B.; Yang, J. Feature ensemble learning based on sparse autoencoders for image classification. In Proceedings of the 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1739–1745. [Google Scholar]
- Izmailov, P.; Podoprikhin, D.; Garipov, T.; Vetrov, D.; Wilson, A.G. Averaging weights leads to wider optima and better generalization. arXiv 2018, arXiv:1803.05407. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Sharma, S.; Gupta, S.; Gupta, D.; Juneja, S.; Gupta, P.; Dhiman, G.; Kautish, S. Deep learning model for the automatic classification of white blood cells. Comput. Intell. Neurosci. 2022, 2022, 7384131. [Google Scholar] [CrossRef]
- Juneja, S.; Juneja, A.; Dhiman, G.; Behl, S.; Kautish, S. An approach for thoracic syndrome classification with convolutional neural networks. Comput. Math. Methods Med. 2021, 2021, 3900254. [Google Scholar] [CrossRef] [PubMed]
- Dhiman, G.; Viriyasitavat, W.; Mohafez, H.; Hadizadeh, M.; Islam, M.A.; Gulati, K. A novel machine-learning-based hybrid CNN model for tumor identification in medical image processing. Sustainability 2022, 14, 1447. [Google Scholar] [CrossRef]
- Dhankhar, A.; Bali, V. Kernel parameter tuning to tweak the performance of classifiers for identification of heart diseases. Int. J. E-Health Med. Commun. (IJEHMC) 2021, 12, 1–16. [Google Scholar] [CrossRef]
- Juneja, S.; Juneja, A.; Dhiman, G.; Jain, S.; Dhankhar, A.; Kautish, S. Computer Vision-Enabled character recognition of hand Gestures for patients with hearing and speaking disability. Mob. Inf. Syst. 2021, 2021, 4912486. [Google Scholar] [CrossRef]
- Rashid, J.; Batool, S.; Kim, J.; Nisar, M.W.; Hussain, A.; Kushwaha, R. An augmented artificial intelligence approach for chronic diseases prediction. Front. Public Health 2022, 10, 860396. [Google Scholar] [CrossRef] [PubMed]
- Aggarwal, S.; Gupta, S.; Kannan, R.; Ahuja, R.; Gupta, D.; Juneja, S.; Belhaouari, S.B. A convolutional neural network-based framework for classification of protein localization using confocal microscopy images. IEEE Access 2022, 10, 83591–83611. [Google Scholar] [CrossRef]
- Sharma, S.; Gupta, S.; Gupta, D.; Juneja, S.; Singal, G.; Dhiman, G.; Kautish, S. Recognition of gurmukhi handwritten city names using deep learning and cloud computing. Sci. Program. 2022, 2022, 5945117. [Google Scholar] [CrossRef]
- Sharma, S.; Mahmoud, A.; El–Sappagh, S.; Kwak, K.S. Transfer learning-based modified inception model for the diagnosis of Alzheimer’s disease. Front. Comput. Neurosci. 2022, 16, 1000435. [Google Scholar] [CrossRef] [PubMed]
- Kanwal, S.; Rashid, J.; Anjum, N.; Nisar, M.W. Feature Selection for Lung and Breast Cancer Disease Prediction Using Machine Learning Techniques. In Proceedings of the 2022 1st IEEE International Conference on Industrial Electronics: Developments & Applications (ICIDeA), Chengdu, China, 17–20 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 163–168. [Google Scholar]
- Albarrak, K.; Gulzar, Y.; Hamid, Y.; Mehmood, A.; Soomro, A.B. A Deep Learning-Based Model for Date Fruit Classification. Sustainability 2022, 14, 6339. [Google Scholar] [CrossRef]
- Gulzar, Y.; Hamid, Y.; Soomro, A.B.; Alwan, A.A.; Journaux, L. A Convolution Neural Network-Based Seed Classification System. Symmetry 2020, 12, 2018. [Google Scholar] [CrossRef]
- Hamid, Y.; Wani, S.; Soomro, A.; Alwan, A.; Gulzar, Y. Smart Seed Classification System based on MobileNetV2 Architecture. In Proceedings of the 2022 2nd International Conference on Computing and Information Technology (ICCIT), Tabuk, Saudi Arabia, 25–27 January 2022; pp. 217–222. [Google Scholar] [CrossRef]
- Alshehri, F.; Muhammad, G. A Comprehensive Survey of the Internet of Things (IoT) and AI-Based Smart Healthcare. IEEE Access 2021, 9, 3660–3678. [Google Scholar] [CrossRef]
- Gaur, L.; Bhatia, U.; Jhanjhi, N.; Muhammad, G.; Masud, M. Medical Image-based Detection of COVID-19 using Deep Convolution Neural Networks. Multimed. Syst. 2022. [Google Scholar] [CrossRef]
- Vyas, A.H.; Mehta, M.A.; Kotecha, K.; Pandya, S.; Alazab, M.; Gadekallu, T.R. Tear film breakup time-based dry eye disease detection using convolutional neural network. Neural Comput. Applic 2022. [Google Scholar] [CrossRef]
- Gadekallu, T.R.; Alazab, M.; Kaluri, R.; Maddikunta, P.K.R.; Bhattacharya, S.; Lakshmanna, K. Hand gesture classification using a novel CNN-crow search algorithm. Complex Intell. Syst. 2021, 7, 1855–1868. [Google Scholar] [CrossRef]
- Chowdhary, C.L.; Alazab, M.; Chaudhary, A.; Hakak, S.; Gadekallu, T.R. Computer Vision and Recognition Systems Using Machine and Deep Learning Approaches: Fundamentals, Technologies and Applications; Institution of Engineering and Technology: London, UK, 2021. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label No. | Label Name | Total | Train | Test |
|---|---|---|---|---|
| 0 | Nucleoplasm | 12,885 | 10,306 | 2579 |
| 1 | Nuclear Membrane | 1254 | 999 | 255 |
| 2 | Nucleoli | 3621 | 2880 | 741 |
| 3 | Nucleoli Fibrillar Center | 1561 | 1282 | 279 |
| 4 | Nuclear Speckles | 1858 | 1499 | 359 |
| 5 | Nuclear Bodies | 2513 | 1994 | 519 |
| 6 | Endoplasmic Reticulum | 1008 | 811 | 197 |
| 7 | Golgi Apparatus | 2822 | 2251 | 571 |
| 8 | Peroxisomes | 53 | 42 | 11 |
| 9 | Endosomes | 45 | 36 | 9 |
| 10 | Lysosomes | 28 | 22 | 6 |
| 11 | Intermediate Filaments | 1093 | 888 | 205 |
| 12 | Actin Filaments | 688 | 560 | 128 |
| 13 | Focal Adhesion Sites | 537 | 430 | 107 |
| 14 | Microtubules | 1066 | 839 | 227 |
| 15 | Microtubule End | 21 | 17 | 4 |
| 16 | Cytokinetic Bridge | 530 | 419 | 111 |
| 17 | Mitotic Spindle | 210 | 165 | 45 |
| 18 | Microtubule Organizing Centre | 902 | 701 | 201 |
| 19 | Centrosome | 1482 | 1178 | 304 |
| 20 | Lipid Droplets | 172 | 143 | 29 |
| 21 | Plasma Membrane | 3777 | 3010 | 767 |
| 22 | Cell Junctions | 802 | 648 | 154 |
| 23 | Mitochondria | 2965 | 2358 | 607 |
| 24 | Aggresome | 322 | 255 | 67 |
| 25 | Cytosol | 8228 | 6560 | 1668 |
| 26 | Cytoplasmic Bodies | 328 | 260 | 68 |
| 27 | Rods and Rings | 11 | 9 | 2 |
| Hyper-Parameters | Values |
|---|---|
| Mini Batch Size | 32 |
| Initial Learning Rate | 0.001 |
| Weight Decay | 1.0 × 10−8 |
| Beta | 0.9, 0.999 |
| Optimizer | Adam (Default Parameter) |
| Model | VGG16 | ResNe152 | DenseNet169 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Label No. | Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score |
| 0 | 0.80 | 0.86 | 0.83 | 0.78 | 0.85 | 0.81 | 0.77 | 0.83 | 0.80 |
| 1 | 0.83 | 0.68 | 0.75 | 0.74 | 0.55 | 0.63 | 0.65 | 0.52 | 0.58 |
| 2 | 0.71 | 0.66 | 0.68 | 0.69 | 0.65 | 0.67 | 0.64 | 0.64 | 0.64 |
| 3 | 0.49 | 0.51 | 0.50 | 0.48 | 0.45 | 0.47 | 0.44 | 0.37 | 0.40 |
| 4 | 0.65 | 0.70 | 0.67 | 0.76 | 0.61 | 0.68 | 0.69 | 0.63 | 0.66 |
| 5 | 0.65 | 0.42 | 0.51 | 0.35 | 0.44 | 0.39 | 0.35 | 0.41 | 0.38 |
| 6 | 0.46 | 0.53 | 0.49 | 0.47 | 0.49 | 0.48 | 0.43 | 0.45 | 0.44 |
| 7 | 0.75 | 0.64 | 0.69 | 0.63 | 0.54 | 0.58 | 0.61 | 0.48 | 0.54 |
| 8 | 0.11 | 0.45 | 0.17 | 0.50 | 0.27 | 0.35 | 0.07 | 0.09 | 0.08 |
| 9 | 0.23 | 0.67 | 0.34 | 1.00 | 0.22 | 0.36 | 0.33 | 0.11 | 0.17 |
| 10 | 0.15 | 0.50 | 0.23 | 0.67 | 0.33 | 0.44 | 0.25 | 0.17 | 0.20 |
| 11 | 0.77 | 0.54 | 0.64 | 0.66 | 0.55 | 0.60 | 0.70 | 0.47 | 0.57 |
| 12 | 0.67 | 0.46 | 0.55 | 0.52 | 0.48 | 0.50 | 0.48 | 0.48 | 0.48 |
| 13 | 0.55 | 0.54 | 0.55 | 0.68 | 0.41 | 0.51 | 0.71 | 0.43 | 0.53 |
| 14 | 0.84 | 0.81 | 0.82 | 0.88 | 0.80 | 0.84 | 0.89 | 0.78 | 0.83 |
| 15 | 1.00 | 0.25 | 0.40 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 16 | 0.47 | 0.15 | 0.23 | 0.20 | 0.26 | 0.23 | 0.16 | 0.18 | 0.17 |
| 17 | 0.30 | 0.18 | 0.22 | 0.13 | 0.29 | 0.18 | 0.41 | 0.24 | 0.31 |
| 18 | 0.38 | 0.40 | 0.39 | 0.35 | 0.44 | 0.39 | 0.22 | 0.36 | 0.27 |
| 19 | 0.37 | 0.50 | 0.43 | 0.30 | 0.32 | 0.31 | 0.21 | 0.34 | 0.26 |
| 20 | 0.13 | 0.52 | 0.20 | 0.44 | 0.24 | 0.31 | 0.26 | 0.34 | 0.30 |
| 21 | 0.64 | 0.64 | 0.64 | 0.63 | 0.63 | 0.63 | 0.62 | 0.65 | 0.63 |
| 22 | 0.44 | 0.51 | 0.47 | 0.49 | 0.39 | 0.43 | 0.50 | 0.35 | 0.41 |
| 23 | 0.75 | 0.69 | 0.72 | 0.71 | 0.68 | 0.69 | 0.70 | 0.63 | 0.66 |
| 24 | 0.74 | 0.60 | 0.66 | 0.65 | 0.49 | 0.56 | 0.56 | 0.49 | 0.52 |
| 25 | 0.63 | 0.76 | 0.69 | 0.63 | 0.72 | 0.68 | 0.63 | 0.73 | 0.67 |
| 26 | 0.26 | 0.32 | 0.29 | 0.22 | 0.28 | 0.25 | 0.09 | 0.28 | 0.14 |
| 27 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Weighted Average | 0.67 | 0.68 | 0.67 | 0.64 | 0.65 | 0.64 | 0.62 | 0.63 | 0.62 |
| Label No. | Label Name | Precision | Recall | F1-Score |
|---|---|---|---|---|
| 0 | Nucleoplasm | 0.79 | 0.90 | 0.84 |
| 1 | Nuclear Membrane | 0.84 | 0.69 | 0.76 |
| 2 | Nucleoli | 0.72 | 0.75 | 0.73 |
| 3 | Nucleoli Fibrillar Center | 0.60 | 0.47 | 0.53 |
| 4 | Nuclear Speckles | 0.81 | 0.67 | 0.73 |
| 5 | Nuclear Bodies | 0.56 | 0.52 | 0.54 |
| 6 | Endoplasmic Reticulum | 0.60 | 0.51 | 0.55 |
| 7 | Golgi Apparatus | 0.76 | 0.67 | 0.71 |
| 8 | Peroxisomes | 0.29 | 0.18 | 0.22 |
| 9 | Endosomes | 0.70 | 0.56 | 0.63 |
| 10 | Lysosomes | 1.00 | 0.50 | 0.67 |
| 11 | Intermediate Filaments | 0.81 | 0.59 | 0.68 |
| 12 | Actin Filaments | 0.67 | 0.55 | 0.60 |
| 13 | Focal Adhesion Sites | 0.73 | 0.52 | 0.61 |
| 14 | Microtubules | 0.92 | 0.83 | 0.87 |
| 15 | Microtubule End | 0.50 | 0.25 | 0.33 |
| 16 | Cytokinetic Bridge | 0.41 | 0.19 | 0.26 |
| 17 | Mitotic Spindle | 0.34 | 0.24 | 0.29 |
| 18 | Microtubule Organizing Center | 0.45 | 0.44 | 0.45 |
| 19 | Centrosome | 0.45 | 0.48 | 0.46 |
| 20 | Lipid Droplets | 0.41 | 0.24 | 0.30 |
| 21 | Plasma Membrane | 0.74 | 0.64 | 0.68 |
| 22 | Cell Junctions | 0.58 | 0.45 | 0.51 |
| 23 | Mitochondria | 0.81 | 0.69 | 0.74 |
| 24 | Aggresome | 0.81 | 0.64 | 0.55 |
| 25 | Cytosol | 0.75 | 0.80 | 0.72 |
| 26 | Cytoplasmic Bodies | 0.67 | 0.79 | 0.72 |
| 27 | Rods and Rings | 0.00 | 0.00 | 0.00 |
| Weighted Average | 0.72 | 0.70 | 0.71 | |
| Model Name | Time Taken to Train the Model |
|---|---|
| Fine-tuned VGG16 | 10,839.0 s |
| Fine-tuned ResNet152 | 11,099.3 s |
| Fine-tuned DenseNet169 | 16,928.5 s |
| Proposed Ensemble Model | 5564.8 s |
| Reference No. | Dataset Used | Technique | F1-Score |
|---|---|---|---|
| [30] | Chinese Hamster Ovary (CHO) Dataset | Random Forest and Rotation Forest | 0.53 |
| [31] | CHO Dataset | Ensemble of SVM classifier | 0.64 |
| [40] | HPA Dataset | FCN CNN | 0.696 0.676 |
| [41] | HPA Dataset | Inception V3 | 0.706 |
| [42] | HPA Dataset | Hybrid Xception | 0.69 |
| [45] | HPA Dataset | ResNet | 0.3459 |
| Proposed Model | HPA Dataset | Stacked Ensemble of Transfer Learning models | 0.71 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aggarwal, S.; Gupta, S.; Gupta, D.; Gulzar, Y.; Juneja, S.; Alwan, A.A.; Nauman, A. An Artificial Intelligence-Based Stacked Ensemble Approach for Prediction of Protein Subcellular Localization in Confocal Microscopy Images. Sustainability 2023, 15, 1695. https://doi.org/10.3390/su15021695
Aggarwal S, Gupta S, Gupta D, Gulzar Y, Juneja S, Alwan AA, Nauman A. An Artificial Intelligence-Based Stacked Ensemble Approach for Prediction of Protein Subcellular Localization in Confocal Microscopy Images. Sustainability. 2023; 15(2):1695. https://doi.org/10.3390/su15021695
Chicago/Turabian StyleAggarwal, Sonam, Sheifali Gupta, Deepali Gupta, Yonis Gulzar, Sapna Juneja, Ali A. Alwan, and Ali Nauman. 2023. "An Artificial Intelligence-Based Stacked Ensemble Approach for Prediction of Protein Subcellular Localization in Confocal Microscopy Images" Sustainability 15, no. 2: 1695. https://doi.org/10.3390/su15021695