
Investigation of Landslide Susceptibility Decision Mechanisms in Different Ensemble-Based Machine Learning Models with Various Types of Factor Data

 , ,
, ,
Abstract
:1. Introduction
- (1)
- This paper’s innovation is to focus on two critical aspects of landslide susceptibility assessment: accuracy and complexity. The interplay between prediction accuracy and modeling complexity is emphasized. This dual focus is rare in the existing literature and highlights the need for highly accurate prediction and interpretable modeling.
- (2)
- The innovation of the methodology in this paper is mainly reflected in data type and model interpretability. Since different types of factor data may have different effects on model predictions, different types of factor data are introduced, including initial factor data and transformed conditional probability model data. In addition, the SHAP method is used in this paper to explain the model predictions.
- (3)
- The innovation of the experimental design and data analysis consists in its comprehensiveness and diversity. In this paper, two ensemble ML methods, random forest (RF) and XGBoost, were chosen to construct the landslide susceptibility model. In addition, this paper uses different data types and constructs multiple versions of the model for each type.
- (4)
- The innovation in error analysis and prediction error interpretation is reflected in its in-depth analysis of prediction errors. Through local explanations and analysis, this paper delves into the interpretation of model predictions for error samples.
2. Study Region and Data Overview
2.1. Study Region
2.2. Data Acquisition
2.3. Construction of the Modeling Dataset
- (1)
- First, to avoid sampling in areas with similar geography to known landslides, areas beyond 100 m from historical landslides were chosen as the selection range. This helped to maintain sample diversity and avoid introducing unnecessary bias due to geographic similarities.
- (2)
- Second, land areas that do not contain permanent bodies of water were extracted as the area for non-landslide samples. The consideration behind this principle is that landslide events do not usually involve areas of water bodies, ensuring that non-landslide samples were carefully selected; with an emphasis on this aspect, the selected samples were more geographically and geomorphologically similar to landslide events.
- (3)
- Given that landslides typically occur on steep slopes possessing higher slope values, areas with slopes less than 30° were extracted as extraction areas for the non-landslide samples. This selection helps to maintain similarity to landslide events, as steep-slope areas are more prone to landslides. Through this principle, we pursued maintaining a reasonable match of geomorphic features in the sample selection process.
3. Methods
- (1)
- The process involves preparing data and constructing a spatial database that includes both samples from landslides and non-landslides, as well as conditioning factors that contribute to landslides.
- (2)
- Independence testing of landslide conditioning factors, including Pearson correlation analysis and multicollinearity diagnosis, is performed.
- (3)
- Preparation of the modeling dataset. In order to partition and standardize the attribute intervals of each factor, five different conditional probability models were employed: frequency ratio, statistical index, certainty factor, evidential belief function, and weights of evidence. Afterward, the data of the initial and processed factors were extracted to the sample points, resulting in the creation of six modeling datasets.
- (4)
- Landslide susceptibility modeling. Based on the six different modeling datasets, twelve landslide susceptibility prediction models were constructed using the random forest and extreme gradient boosting algorithms, and landslide susceptibility maps were generated.
- (5)
- Evaluation of model predictive performance. The performance of the twelve models as compared and analyzed using different statistical methods, identifying the best-performing model.
- (6)
- Shapley Additive exPlanations (SHAP) analysis. The influence of every factor on the models was investigated through the creation of SHAP models for all twelve landslide susceptibility models and the dependency relationship between the predictive results and features in models built using different machine learning methods and types of factor data.
3.1. Analysis of Conditioning Factors
3.2. Conditional Probability Models
3.2.1. Frequency Ratio
3.2.2. Information Value
3.2.3. Certainty Factor
3.2.4. Evidential Belief Function
3.2.5. Weights of Evidence
3.3. Tree-Based Machine Learning Models
3.3.1. Random Forest
3.3.2. Extreme Gradient Boosting
3.4. Model Evaluation Criteria
3.4.1. Receiver Operating Characteristic
3.4.2. Confusion Matrix
3.4.3. Root Mean Square Error between the Predicted and Actual Values of the Sample
3.5. Shapley Additive ExPlanations
4. Results
4.1. Landslide Conditioning Factors Analysis
4.2. Model Structuring and Optimization
4.3. Landslide Susceptibility Maps for Different Models
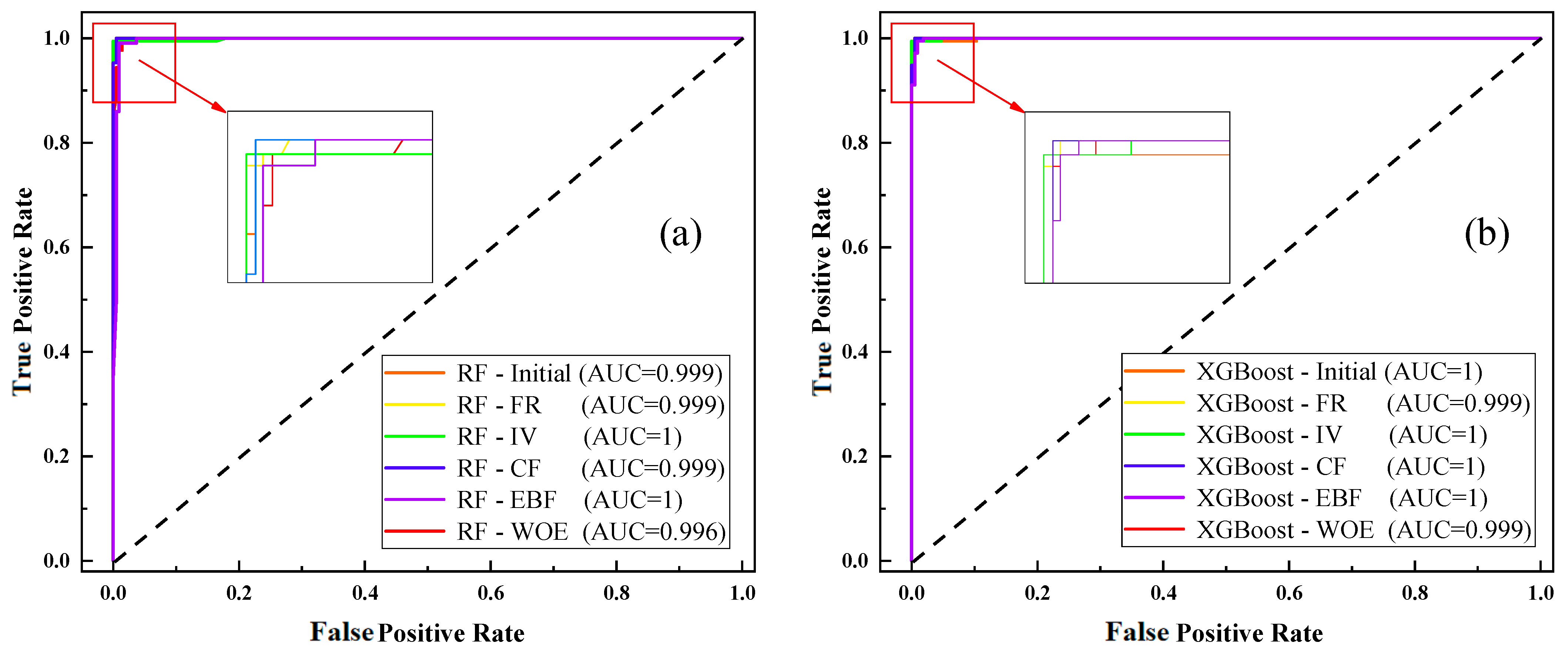
4.4. Model Accuracy Evaluation
4.5. Shapley Additive ExPlanations (SHAP) Analysis
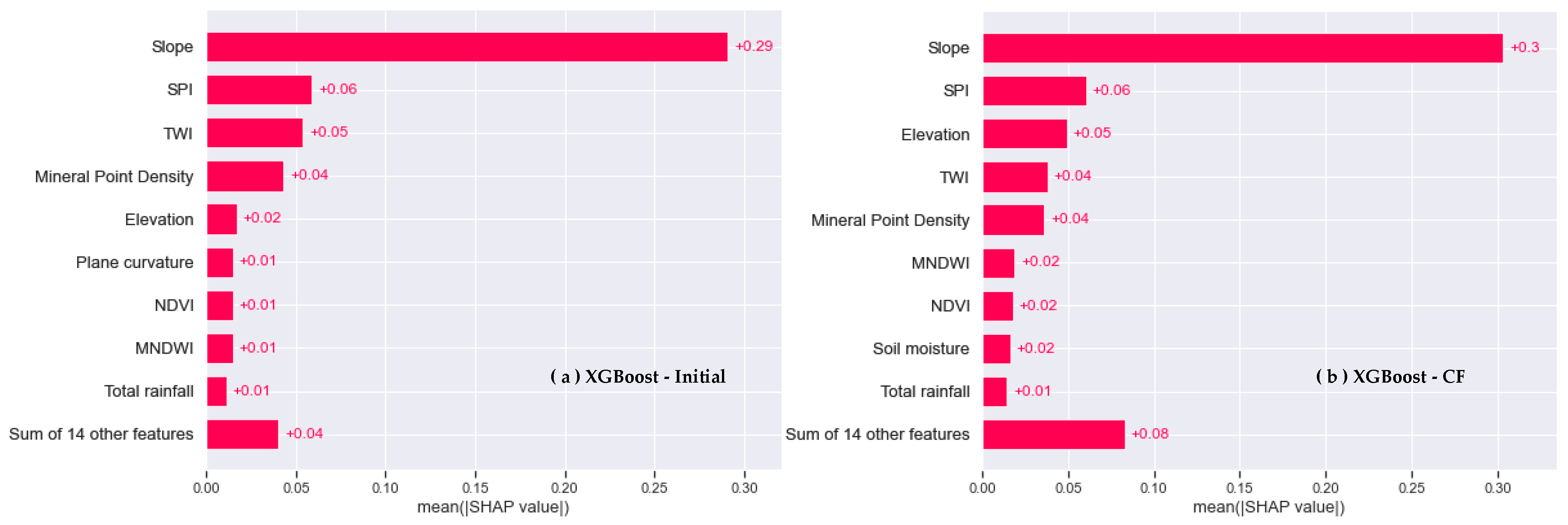
4.5.1. Factor Importance Based on Shapley Value
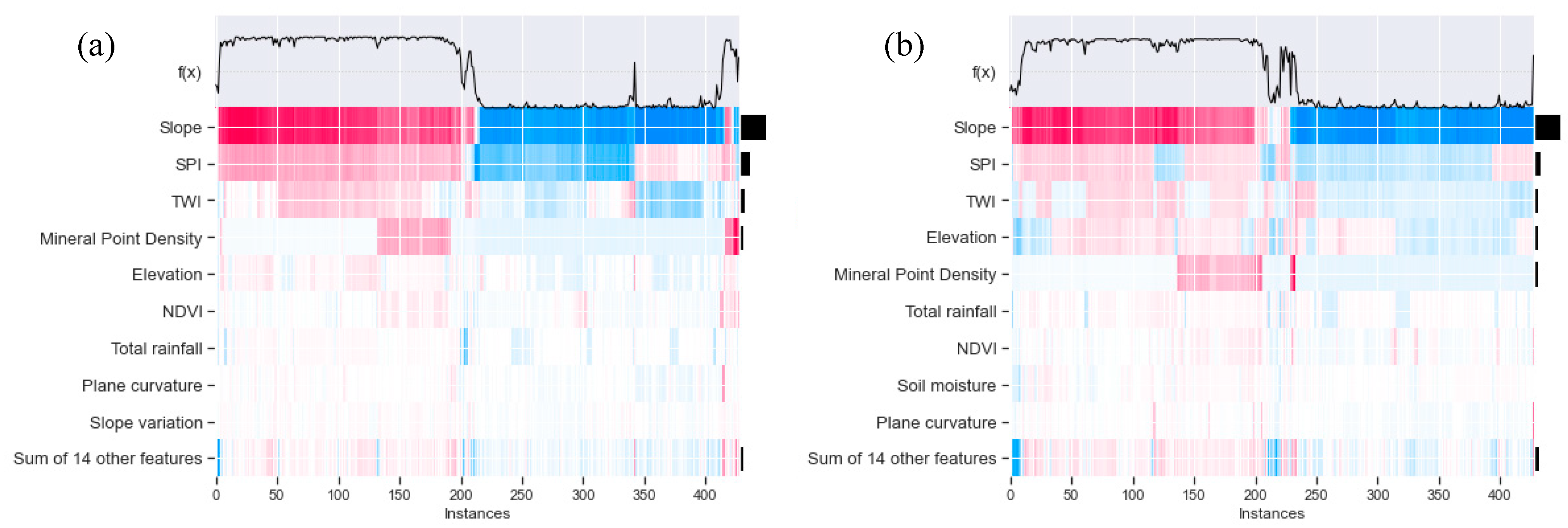
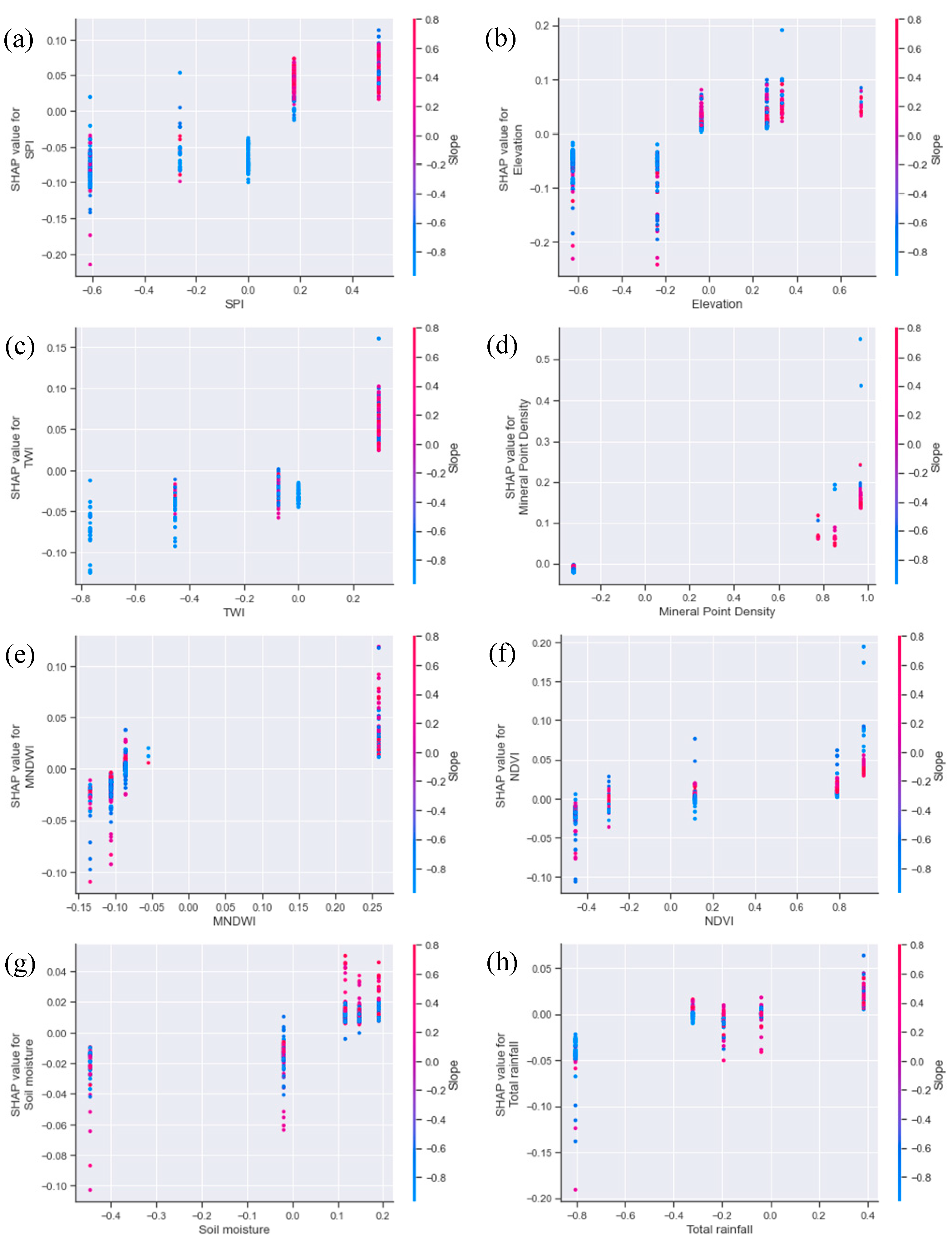
4.5.2. Influence of Factors on Prediction Result
4.5.3. Dependence and Interaction of Factors
5. Discussion
5.1. Features and Advantages of SHAP
- An understanding of whether each feature’s influence on the model’s final decision-making result is positive or negative along with the explanations for the respective influence.
- An ability to find the feature interactions in the model and analyze how the interactions between features affect the prediction results of the landslide susceptibility model.
- A local decision evaluation of the typical sample data in the model besides the global interpretation of the model.
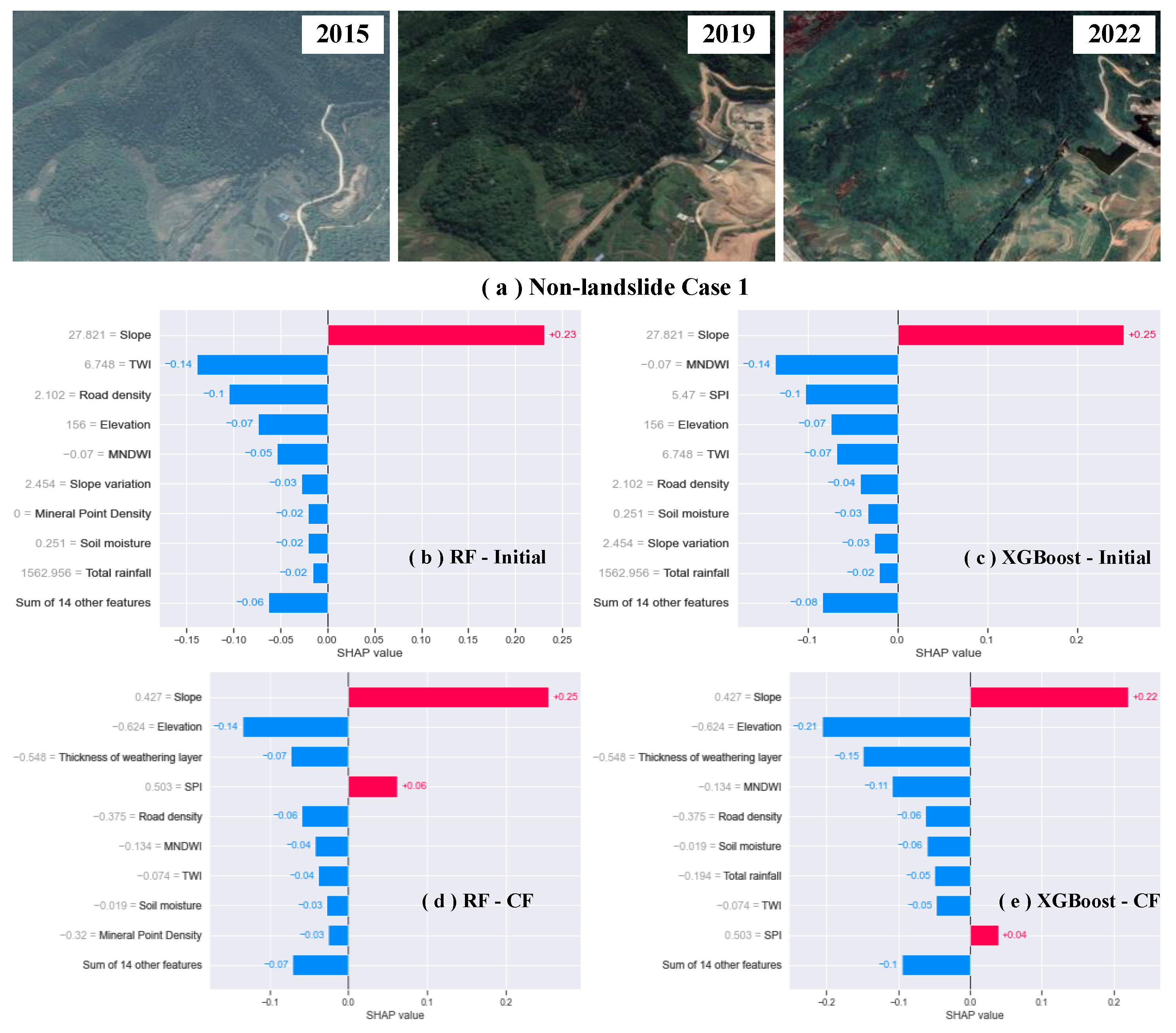
5.2. Local Interpretation of Typical Samples
5.3. Local Interpretation of Samples with Wrong Prediction
5.4. Post-Programming
5.4.1. Exploration and Discussion
- Exploration of different factor data types: Current landslide susceptibility research is mainly focused on exploring the interpretation of different ML models, whereas this paper’s analysis introduces new dimensions in considering different factor data types, which are different from the present condition of research. This paper presents the initial effort to employ the SHAP method in elucidating landslide susceptibility models utilizing various types of factor data. This investigation introduces a fresh standpoint to clarify the impact of diverse factor data types on the decision-making process within the model.
- Interpretability advantage: The research in this paper confirms the advantage of the SHAP method in interpreting landslide susceptibility models constructed based on the ML method. The internal decision-making mechanism of the model is thoroughly explained in this paper through the utilization of the SHAP method, which improves the transparency and interpretability of the model. Since existing studies have emphasized the importance of the SHAP method in providing model explanations [35], this is consistent with the current state of research.
- Comparison and analysis of internal decision-making within models: The study in this paper compared and analyzed the differences in internal decision making within landslide susceptibility models constructed based on different types of factor data. This point, to some extent, contradicts the status quo that current research mainly focuses on exploring the interpretation of different ML models because the research in this paper focusing on the effect of factor data types on the decision-making process within the models is not limited to just selecting and interpreting the models.
5.4.2. A Discussion of Feature Importance Assessment for Fused Decision Tree Models
6. Conclusions
- (1)
- The study successfully constructed 12 landslide susceptibility models, all of which performed exceptionally well. Among these models, the XGBoost-CF model, created using the XGBoost algorithm based on CF values, demonstrated superior stability and reliability in evaluating landslide susceptibility in the study area. It achieved an AUC value of 1, an accuracy value of 99.533, a kappa coefficient value of 0.991, and an RMSE value of 0.0807. The results from the XGBoost-CF model indicated that 91.121% of the landslides occurred within 24.959% of the high- and very-high-susceptibility zones, while only 0.467% of the landslides were located in 44.891% of the low- and very-low-susceptibility zones. This suggests that the model covers landslide risk areas comprehensively and exhibits specificity in the identification of landslide samples, thereby producing optimal zoning results.
- (2)
- The utilization of SHAP as an interpretable approach enables a clear explanation of the correlation between factors and the forecasted outcomes of landslide susceptibility. The results demonstrate that landslide susceptibility models, which are constructed using various machine learning techniques and different types of factor data, employ diverse decision-making processes within the same study area. Specifically, the impact direction and strength of a particular factor vary across different models, and the interaction of the same factor has varying effects on the forecasted outcomes. Moreover, the type of factor data plays a significant role in shaping the decision-making process of the models. By taking into consideration the distinct characteristics of different types of factor data, a more comprehensive understanding of how factors influence the forecasted outcomes of landslide susceptibility can be attained.
- (3)
- Using the interpretable method based on SHAP to analyze the factor importance and factor interaction in different models, it can be determined that the main factor causing landslides in this area is the slope, and it enhances the occurrence of landslides by interacting with other factors.
- (4)
- The explainable landslide susceptibility model proposed in this paper can explain individual samples in the local dimension. It can not only explain and analyze the causes of the occurrence of typical landslides but also be used to test whether the selection of non-landslide samples is reasonable. Most importantly, by using this function to explain and analyze samples with incorrect predictions locally, the causes can be summarized and used to further improve the landslide susceptibility model.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kavzoglu, T.; Teke, A.; Yilmaz, E.O. Shared blocks-based ensemble deep learning for shallow landslide susceptibility mapping. Remote Sens. 2021, 13, 4776. [Google Scholar] [CrossRef]
- Mandal, K.; Saha, S.; Mandal, S. Applying deep learning and benchmark machine learning algorithms for landslide susceptibility modelling in Rorachu river basin of Sikkim Himalaya, India. Geosci. Front. 2021, 12, 101203. [Google Scholar] [CrossRef]
- Han, Y.; Wang, P.; Zheng, Y.; Yasir, M.; Xu, C. Extraction of Landslide Information Based on Object-Oriented Approach and Cause Analysis in Shuicheng, China. Remote Sens. 2022, 14, 502. [Google Scholar] [CrossRef]
- Mustafa, K.; Zhang, B.; Cao, J.; Zhang, X.; Chang, J. Comparative Study of Artificial Neural Network and Random Forest Model for Susceptibility Assessment of Landslides Induced by Earthquake in the Western Sichuan Plateau, China. Sustainability 2022, 14, 13739. [Google Scholar]
- Wang, H.; Zhang, L.; Luo, H.; He, J.; Cheung, R. AI-powered landslide susceptibility assessment in Hong Kong. Eng. Geol. 2021, 288, 106103. [Google Scholar] [CrossRef]
- Yi, Y.; Zhang, Z.; Zhang, W.; Jia, H.; Zhang, J. Landslide susceptibility mapping using multiscale sampling strategy and convolutional neural network: A case study in Jiuzhaigou region. Catena 2020, 195, 104851. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, Q.; Liu, Y. Mapping landslide susceptibility using machine learning algorithms and GIS: A case study in Shexian county, Anhui province, China. Symmetry 2020, 12, 1954. [Google Scholar] [CrossRef]
- Yang, C.; Tong, X.; Chen, G.; Yuan, C.; Lian, J. Assessment of seismic landslide susceptibility of bedrock and overburden layer slope based on shaking table tests. Eng. Geol. 2023, 323, 107197. [Google Scholar] [CrossRef]
- Zou, Q.; Jiang, H.; Cui, P.; Zhou, B.; Jiang, Y.; Qin, M.; Liu, Y.; Li, C. A new approach to assess landslide susceptibility based on slope failure mechanisms. Catena 2021, 204, 105388. [Google Scholar] [CrossRef]
- Chen, Y.; Dong, J.; Guo, F.; Tong, B.; Zhou, T.; Fang, H.; Wang, L.; Zhan, Q. Review of landslide susceptibility assessment based on knowledge mapping. Stoch. Environ. Res. Risk Assess. 2022, 36, 2399–2417. [Google Scholar]
- Lima, P.; Steger, S.; Glade, T. Counteracting flawed landslide data in statistically based landslide susceptibility modelling for very large areas: A national-scale assessment for Austria. Landslides 2021, 18, 3531–3546. [Google Scholar] [CrossRef]
- Reichenbach, P.; Rossi, M.; Malamud, B.D.; Mihir, M.; Guzzetti, F. A review of statistically-based landslide susceptibility models. Earth-Sci. Rev. 2018, 180, 60–91. [Google Scholar] [CrossRef]
- Zhuo, L.; Huang, Y.; Zheng, J.; Cao, J.; Guo, D. Landslide Susceptibility Mapping in Guangdong Province, China, Using Random Forest Model and Considering Sample Type and Balance. Sustainability 2023, 15, 9024. [Google Scholar] [CrossRef]
- Yuan, X.; Liu, C.; Nie, R.; Yang, Z.; Li, W.; Dai, X.; Cheng, J.; Zhang, J.; Ma, L.; Fu, X.; et al. A Comparative Analysis of Certainty Factor-Based Machine Learning Methods for Collapse and Landslide Susceptibility Mapping in Wenchuan County, China. Remote Sens. 2022, 14, 3259. [Google Scholar] [CrossRef]
- Wang, Y.; Feng, L.; Li, S.; Ren, F.; Du, Q. A hybrid model considering spatial heterogeneity for landslide susceptibility mapping in Zhejiang Province, China. Catena 2020, 188, 104425. [Google Scholar] [CrossRef]
- Raja, M.N.A.; Jaffar, S.T.A.; Bardhan, A.; Shukla, S.K. Predicting and validating the load-settlement behavior of large-scale geosynthetic-reinforced soil abutments using hybrid intelligent modeling. J. Rock Mech. Geotech. Eng. 2023, 15, 773–788. [Google Scholar] [CrossRef]
- Merghadi, A.; Yunus, A.P.; Dou, J.; Whiteley, J.; ThaiPham, B.; Bui, D.T.; Avtar, R.; Abderrahmane, B. Machine learning methods for landslide susceptibility studies: A comparative overview of algorithm performance. Earth-Sci. Rev. 2020, 207, 103225. [Google Scholar] [CrossRef]
- Chen, W.; Chen, Y.; Tsangaratos, P.; Ilia, I.; Wang, X. Combining evolutionary algorithms and machine learning models in landslide susceptibility assessments. Remote Sens. 2020, 12, 3854. [Google Scholar] [CrossRef]
- Dou, H.; Huang, S.; Jian, W.; Wang, H. Landslide susceptibility mapping of mountain roads based on machine learning combined model. J. Mt. Sci. 2023, 20, 1232–1248. [Google Scholar] [CrossRef]
- Sun, D.; Ding, Y.; Zhang, J.; Wen, H.; Wang, Y.; Xu, J.; Zhou, X.; Liu, R. Essential insights into decision mechanism of landslide susceptibility mapping based on different machine learning models. Geocarto Int. 2022. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, D.; Wen, H.; Zhang, H.; Zhang, F. Comparison of random forest model and frequency ratio model for landslide susceptibility mapping (LSM) in Yunyang County (Chongqing, China). Int. J. Environ. Res. Public Health 2020, 17, 4206. [Google Scholar] [CrossRef] [PubMed]
- Zhao, B.; Ge, Y.; Chen, H. Landslide susceptibility assessment for a transmission line in Gansu Province, China by using a hybrid approach of fractal theory, information value, and random forest models. Environ. Earth Sci. 2021, 80, 441. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, Z.; Xu, C. Slope Unit-Based Landslide Susceptibility Mapping Using Certainty Factor, Support Vector Machine, Random Forest, CF-SVM and CF-RF Models. Front. Earth Sci. 2021, 9, 589630. [Google Scholar] [CrossRef]
- Fan, H.; Lu, Y.; Hu, Y.; Fang, J.; Lv, C.; Xu, C.; Feng, X.; Liu, Y. A landslide susceptibility evaluation of highway disasters based on the frequency ratio coupling model. Sustainability 2022, 14, 7740. [Google Scholar] [CrossRef]
- Arabameri, A.; Pradhan, B.; Rezaei, K.; Lee, C. Assessment of landslide susceptibility using statistical-and artificial intelligence-based FR–RF integrated model and multiresolution DEMs. Remote Sens. 2019, 11, 999. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Teke, A. Predictive Performances of ensemble machine learning algorithms in landslide susceptibility mapping using random forest, extreme gradient boosting (XGBoost) and natural gradient boosting (NGBoost). Arab. J. Sci. Eng. 2022, 47, 7367–7385. [Google Scholar] [CrossRef]
- Huang, F.; Zhang, J.; Zhou, C.; Wang, Y.; Huang, J.; Zhu, L. A deep learning algorithm using a fully connected sparse autoencoder neural network for landslide susceptibility prediction. Landslides 2020, 17, 217–229. [Google Scholar] [CrossRef]
- Arabameri, A.; Pal, S.C.; Rezaie, F.; Chakrabortty, R.; Saha, A.; Blaschke, T.; Di Napoli, M.; Ghorbanzadeh, O.; Ngo, P.T.T. Decision tree based ensemble machine learning approaches for landslide susceptibility mapping. Geocarto Int. 2022, 37, 4594–4627. [Google Scholar] [CrossRef]
- Pradhan, B.; Dikshit, A.; Lee, S.; Kim, H. An explainable AI (XAI) model for landslide susceptibility modeling. Appl. Soft Comput. J. 2023, 142, 110324. [Google Scholar] [CrossRef]
- Pyakurel, A.; Dahal, B.K.; Gautam, D. Does machine learning adequately predict earthquake induced landslides? Soil Dyn. Earthq. Eng. 2023, 171, 107994. [Google Scholar] [CrossRef]
- Iban, M.C.; Bilgilioglu, S.S. Snow avalanche susceptibility mapping using novel tree-based machine learning algorithms (XGBoost, NGBoost, and LightGBM) with eXplainable Artificial Intelligence (XAI) approach. Stoch. Environ. Res. Risk Assess. 2023, 37, 2243–2270. [Google Scholar] [CrossRef]
- Sun, D.; Chen, D.; Zhang, J.; Mi, C.; Gu, Q.; Wen, H. Landslide Susceptibility Mapping Based on Interpretable Machine Learning from the Perspective of Geomorphological Differentiation. Land 2023, 12, 1018. [Google Scholar] [CrossRef]
- Zhang, J.; Ma, X.; Zhang, J.; Sun, D.; Zhou, X.; Mi, C.; Wen, H. Insights into geospatial heterogeneity of landslide susceptibility based on the SHAP-XGBoost model. J. Environ. Manag. 2023, 332, 117357. [Google Scholar] [CrossRef] [PubMed]
- Ekmekcioğlu, Ö.; Koc, K. Explainable step-wise binary classification for the susceptibility assessment of geo-hydrological hazards. Catena 2022, 216, 106379. [Google Scholar] [CrossRef]
- Al-Najjar, H.A. A novel method using explainable artificial intelligence (XAI)-based Shapley Additive Explanations for spatial landslide prediction using Time-Series SAR dataset. Gondwana Res. 2022. [Google Scholar] [CrossRef]
- Zhou, X.; Wen, H.; Li, Z.; Zhang, H.; Zhang, W. An interpretable model for the susceptibility of rainfall-induced shallow landslides based on SHAP and XGBoost. Geocarto Int. 2022, 37, 13419–13450. [Google Scholar] [CrossRef]
- Lin, Q.; Lima, P.; Steger, S.; Glade, T.; Jiang, T.; Zhang, J.; Liu, T.; Wang, Y. National-scale data-driven rainfall induced landslide susceptibility mapping for China by accounting for incomplete landslide data. Geosci. Front. 2021, 12, 101248. [Google Scholar] [CrossRef]
- Liu, Y.; Zhao, L.; Bao, A.; Li, J.; Yan, X. Chinese High Resolution Satellite Data and GIS-Based Assessment of Landslide Susceptibility along Highway G30 in Guozigou Valley Using Logistic Regression and MaxEnt Model. Remote Sens. 2022, 14, 3620. [Google Scholar] [CrossRef]
- Pham, V.D.; Nguyen, Q.-H.; Nguyen, H.D.; Pham, V.-M.; Vu, V.M.; Bui, Q.-T. Convolutional neural network—Optimized moth flame algorithm for shallow lands.lide susceptible analysis. IEEE Access 2020, 8, 32727–32736. [Google Scholar] [CrossRef]
- Gani, A.M.S.; Rahman, M.S.; Ahmed, N.; Ahmed, B.; Rabbi, M.F.; Rahman, R.M. Improving spatial agreement in machine learning-based landslide susceptibility mapping. Remote Sens. 2020, 12, 3347. [Google Scholar]
- Chen, W.; Yan, X.; Zhao, Z.; Hong, H.; Dieu Tien, B.; Biswajeet, P. Spatial prediction of landslide susceptibility using data mining-based kernel logistic regression, naive Bayes and RBFNetwork models for the Long County area (China). Bull. Eng. Geol. Environ. 2019, 78, 247–266. [Google Scholar] [CrossRef]
- Cheng, J.; Dai, X.; Wang, Z.; Li, J.; Qu, G.; Li, W.; She, J.; Wang, Y. Landslide Susceptibility Assessment Model Construction Using Typical Machine Learning for the Three Gorges Reservoir Area in China. Remote Sens. 2022, 14, 2257. [Google Scholar] [CrossRef]
- Rohan, T.J.; Wondolowski, N.; Shelef, E. Landslide susceptibility analysis based on citizen reports. Earth Surf. Process. Landf. 2021, 46, 791–803. [Google Scholar] [CrossRef]
- Chang, Z.; Du, Z.; Zhang, F.; Huang, F.; Chen, J.; Li, W.; Guo, Z. Landslide susceptibility prediction based on remote sensing images and GIS: Comparisons of supervised and unsupervised machine learning models. Remote Sens. 2020, 12, 502. [Google Scholar] [CrossRef]
- He, W.; Chen, G.; Zhao, J.; Lin, Y.; Qin, B.; Yao, W.; Cao, Q. Landslide Susceptibility Evaluation of Machine Learning Based on Information Volume and Frequency Ratio: A Case Study of Weixin County, China. Sensors 2023, 23, 2549. [Google Scholar] [CrossRef] [PubMed]
- Huang, F.; Cao, Z.; Guo, J.; Jiang, S.; Li, S.; Guo, Z. Comparisons of heuristic, general statistical and machine learning models for landslide susceptibility prediction and mapping. Catena 2020, 191, 104580. [Google Scholar] [CrossRef]
- Mehrabi, M. Landslide susceptibility zonation using statistical and machine learning approaches in Northern Lecco, Italy. Nat. Hazards 2022, 111, 901–937. [Google Scholar] [CrossRef]
- Wen, H.; Wu, X.; Ling, S.; Sun, C.; Liu, Q.; Zhou, G. Characteristics and susceptibility assessment of the earthquake-triggered landslides in moderate-minor earthquake prone areas at southern margin of Sichuan Basin, China. Bull. Eng. Geol. Environ. 2022, 81, 346. [Google Scholar] [CrossRef]
- Saranya, T.; Saravanan, S. Assessment of groundwater vulnerability using analytical hierarchy process and evidential belief function with DRASTIC parameters, Cuddalore, India. Int. J. Environ. Sci. Technol. 2022, 20, 1837–1856. [Google Scholar] [CrossRef]
- Ghosh, B. Spatial mapping of groundwater potential using data-driven evidential belief function, knowledge-based analytic hierarchy process and an ensemble approach. Environ. Earth Sci. 2021, 80, 625. [Google Scholar] [CrossRef]
- Roy, J.; Saha, S.; Arabameri, A.; Blaschke, T.; Bui, D.T. A novel ensemble approach for landslide susceptibility mapping (LSM) in Darjeeling and Kalimpong districts, West Bengal, India. Remote Sens. 2019, 11, 2866. [Google Scholar] [CrossRef]
- Goyes Peñafiel, P.; Hernandez Rojas, A. Landslide susceptibility index based on the integration of logistic regression and weights of evidence: A case study in Popayan, Colombia. Eng. Geol. 2021, 280, 105958. [Google Scholar] [CrossRef]
- Ilinca, V.; Şandric, I.; Jurchescu, M.; Chiţu, Z. Identifying the role of structural and lithological control of landslides using TOBIA and Weight of Evidence: Case studies from Romania. Landslides 2022, 19, 2117–2134. [Google Scholar] [CrossRef]
- Quevedo, R.P.; Maciel, D.A.; Uehara, T.D.T.; Vojtek, M.; Rennó, C.D. Consideration of spatial heterogeneity in landslide susceptibility mapping using geographical random forest model. Geocarto Int. 2021, 37, 8190–8213. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Hong, H. Comparison of convolutional neural networks for landslide susceptibility mapping in Yanshan County, China. Sci. Total Environ. 2019, 666, 975–993. [Google Scholar] [CrossRef]
- Xia, D.; Tang, H.; Sun, S.; Tang, C.; Zhang, B. Landslide Susceptibility Mapping Based on the Germinal Center Optimization Algorithm and Support Vector Classification. Remote Sens. 2022, 14, 2707. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.-I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef]
- Inan, M.S.K.; Rahman, I. Integration of Explainable Artificial Intelligence to Identify Significant Landslide Causal Factors for Extreme Gradient Boosting based Landslide Susceptibility Mapping with Improved Feature Selection. arXiv 2022, arXiv:2201.03225. [Google Scholar]
- Woo, K.Y.; Kim, T.; Shin, J.; Lee, D.; Park, Y.; Kim, Y.; Cha, Y. Validity evaluation of a machine-learning model for chlorophyll a retrieval using Sentinel-2 from inland and coastal waters. Ecol. Indic. 2022, 137, 108737. [Google Scholar]
- Sonkoué, D.; Monkam, D.; Fotso-Nguemo, T.C.; Yepdo, Z.D.; Vondou, D.A. Evaluation and projected changes in daily rainfall characteristics over Central Africa based on a multi-model ensemble mean of CMIP5 simulations. Theor. Appl. Climatol. 2019, 137, 2167–2186. [Google Scholar] [CrossRef]
- Wen, H.; Hu, J.; Zhang, J.; Xiang, X.; Liao, M. Rockfall susceptibility mapping using XGBoost model by hybrid optimized factor screening and hyperparameter. Geocarto Int. 2022, 37, 16872–16899. [Google Scholar] [CrossRef]
- Zhang, Y.; Wen, H.; Xie, P.; Hu, D.; Zhang, J.; Zhang, W. Hybrid-optimized logistic regression model of landslide susceptibility along mountain highway. Bull. Eng. Geol. Environ. 2021, 80, 7385–7401. [Google Scholar] [CrossRef]
- Feng, H.; Miao, Z.; Hu, Q. Study on the Uncertainty of Machine Learning Model for Earthquake-Induced Landslide Susceptibility Assessment. Remote Sens. 2022, 14, 2968. [Google Scholar] [CrossRef]
- Panahi, M.; Rahmati, O.; Rezaie, F.; Lee, S.; Mohammadi, F.; Conoscenti, C. Application of the group method of data handling (GMDH) approach for landslide susceptibility zonation using readily available spatial covariates. Catena 2022, 208, 105779. [Google Scholar] [CrossRef]
- Cha, Y.; Shin, J.; Go, B.; Lee, D.; Kim, Y.; Kim, T.; Park, Y. An interpretable machine learning method for supporting ecosystem management: Application to species distribution models of freshwater macroinvertebrates. J. Environ. Manag. 2021, 291, 112719. [Google Scholar] [CrossRef]
































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Major Data | Source | Data Layer | Scale/Resolution |
|---|---|---|---|
| SRTM DEM | https://gdex.cr.usgs.gov/gdex (accessed on 11 February 2020) | Elevation, slope, TWI, SPI, profile curvature, plane curvature, slope variation, slope direction | 30 m × 30 m |
| Rainfall information | CHIRPS Pentad: Climate Hazards Group InfraRed Precipitation With Station Data | Total rainfall in 2020, number of days with heavy rainfall (rainfall for the day>25 in 2020) | 0.05° × 0.05° |
| Soil moisture information | CLDAS Soil Volume Moisture Content Analysis Product V2.0 (http://data.cma.cn/data (accessed on 11 February 2020)) | Average daily soil moisture in 2020 | 0.0625° × 0.0625° |
| Surface cover information | Landsat-8 Operational Land Imager (OLI) multispectral image (https://earthexplorer.usgs.gov/ (accessed on 11 February 2020)) | NDVI, MNDWI | 30 m × 30 m |
| Ground hydrological traffic information | National Catalogue Service For Geographic Information (in Chinese) (https://www.webmap.cn (accessed on 11 February 2020)) | River density, road density | 1:250,000 |
| Soil information | Harmonized World Soil Database v 1.2 (HWSD) (https://www.fao.org/soils-portal (accessed on 11 February 2020)) | Soil type, soil erodibility | 1:5,000,000 |
| Geological and geomorphological information | National Geological Archives Data Center (in Chinese) (http://dc.ngac.org.cn (accessed on 11 February 2020)) | Mineral point density, fracture zone density, hydrogeology, thickness of weathering layer, type of landform | 1:200,000 |
| Human activity | WordPop Open Population Repository (WOPR) (http://hub.worldpop.org (accessed on 11 February 2020)) | Population density | 1 km × 1 km |
| Factor | TOL | VIF | Factor | TOL | VIF |
|---|---|---|---|---|---|
| MNDWI | 0.8 | 1.25 | Slope | 0.31 | 3.21 |
| NDVI | 0.41 | 2.43 | Slope variation | 0.79 | 1.27 |
| SPI | 0.46 | 2.18 | Slope direction | 0.91 | 1.1 |
| TWI | 0.36 | 2.76 | Profile curvature | 0.61 | 1.65 |
| Thickness of weathering layer | 0.69 | 1.45 | Number of days with heavy rainfall | 0.6 | 1.67 |
| Fracture zone density | 0.67 | 1.5 | Population density | 0.71 | 1.4 |
| Type of landform | 0.55 | 1.82 | Hydrogeology | 0.66 | 1.52 |
| Elevation | 0.31 | 3.24 | Soil erodibility | 0.58 | 1.73 |
| River density | 0.74 | 1.36 | Soil type | 0.74 | 1.35 |
| Mineral point density | 0.45 | 2.2 | Soil moisture | 0.7 | 1.43 |
| Road density | 0.78 | 1.27 | Total rainfall | 0.63 | 1.59 |
| Plane curvature | 0.57 |
| Methods | Hyperparameter | Definition and Explanation |
|---|---|---|
| XGBoost | n_estimators | Number of sub-models |
| learning_rate | The weights of the model generated for each iteration | |
| max_depth | Maximum depth of the tree, often used to avoid over-fitting | |
| min_child_weight | The sum of the minimum leaf node sample weights, which can effectively control overfitting | |
| gamma | Specifies the minimum loss function descent value required for node splitting. The larger the value of this parameter, the more conservative the algorithm | |
| subsample | The proportion of subsamples used to train the model to the entire set of samples | |
| colsample_bytree | The proportion of features randomly sampled when building the tree | |
| RF | n_estimators | The number of decision trees in the forest |
| max_depth | Maximum depth of the tree | |
| max_features | Number of features to consider when finding the optimal segmentation |
| XGBoost-Initial | XGBoost-FR | XGBoost-IV | XGBoost-CF | XGBoost-EBF | XGBoost-WOE | |
|---|---|---|---|---|---|---|
| n_estimators | 60 | 80 | 70 | 90 | 90 | 100 |
| learning_rate | 0.1 | 0.1 | 0.1 | 0.1 | 0.2 | 0.1 |
| max_depth | 10 | 10 | 10 | 10 | 10 | 10 |
| min_child_weight | 2 | 2 | 2 | 2 | 4 | 2 |
| gamma | 0.01 | 0.01 | 0.03 | 0 | 0.02 | 0.01 |
| subsample | 0.8 | 0.8 | 0.7 | 0.9 | 0.8 | 0.8 |
| colsample_bytree | 0.6 | 0.8 | 0.9 | 0.7 | 0.7 | 0.7 |
| RF-Initial | RF-FR | RF-IV | RF-CF | RF-EBF | RF-WOE | |
|---|---|---|---|---|---|---|
| n_estimators | 70 | 80 | 80 | 80 | 80 | 80 |
| max_depth | 9 | 9 | 9 | 9 | 8 | 8 |
| max_features | 7 | 8 | 8 | 8 | 8 | 8 |
| Models | Landslide Susceptibility Partition | Number of Rasters in Partition | Percentage of the Number of Rasters in Partition (%) | Number of Landslides in Partition | Percentage of the Number of Landslides in Partition (%) | Frequency Ratio |
|---|---|---|---|---|---|---|
| RF-Initial | very low | 963,793 | 31.072 | 0 | 0 | 0 |
| low | 399,163 | 12.869 | 1 | 0.467 | 0.036 | |
| medium | 966,350 | 31.155 | 30 | 14.019 | 0.450 | |
| high | 296,372 | 9.555 | 21 | 9.813 | 1.027 | |
| very high | 476,116 | 15.350 | 162 | 75.701 | 4.932 | |
| RF-FR | very low | 985,601 | 31.775 | 1 | 0.467 | 0.015 |
| low | 328,415 | 10.588 | 0 | 0 | 0 | |
| medium | 1,207,486 | 38.929 | 41 | 19.159 | 0.492 | |
| high | 255,378 | 8.233 | 35 | 16.355 | 1.987 | |
| very high | 324,914 | 10.475 | 137 | 64.019 | 6.112 | |
| RF-IV | very low | 1,007,537 | 32.482 | 0 | 0 | 0 |
| low | 306,201 | 9.872 | 2 | 0.935 | 0.095 | |
| medium | 1,152,358 | 37.151 | 37 | 17.290 | 0.465 | |
| high | 276,690 | 8.920 | 36 | 16.822 | 1.886 | |
| very high | 359,008 | 11.574 | 139 | 64.953 | 5.612 | |
| RF-CF | very low | 987,481 | 31.836 | 1 | 0.467 | 0.015 |
| low | 319,689 | 10.307 | 0 | 0 | 0 | |
| medium | 1,128,281 | 36.375 | 48 | 22.430 | 0.617 | |
| high | 267,800 | 8.634 | 25 | 11.682 | 1.353 | |
| very high | 398,543 | 12.849 | 140 | 65.421 | 5.092 | |
| RF-EBF | very low | 951,642 | 30.680 | 0 | 0 | 0 |
| low | 386,748 | 12.469 | 0 | 0 | 0 | |
| medium | 1,090,413 | 35.154 | 39 | 18.224 | 0.518 | |
| high | 279,600 | 9.014 | 41 | 19.159 | 2.125 | |
| very high | 393,391 | 12.683 | 134 | 62.617 | 4.937 | |
| RF-WOE | very low | 970,618 | 31.292 | 0 | 0 | 0 |
| low | 533,070 | 17.186 | 2 | 0.935 | 0.054 | |
| medium | 855,243 | 27.573 | 38 | 17.757 | 0.644 | |
| high | 305,781 | 9.858 | 27 | 12.617 | 1.280 | |
| very high | 437,082 | 14.091 | 147 | 68.692 | 4.875 |
| Models | Landslide Susceptibility Partition | Number of Rasters in Partition | Percentage of the Number of Rasters in Partition (%) | Number of Landslides in Partition | Percentage of the Number of Landslides in Partition (%) | Frequency Ratio |
|---|---|---|---|---|---|---|
| XGBoost-Initial | very low | 1,078,778 | 34.779 | 0 | 0 | 0 |
| low | 315,682 | 10.177 | 1 | 0.467 | 0.046 | |
| medium | 883,914 | 28.497 | 13 | 6.075 | 0.213 | |
| high | 260,888 | 8.411 | 21 | 9.813 | 1.167 | |
| very high | 562,531 | 18.136 | 179 | 83.645 | 4.612 | |
| XGBoost-FR | very low | 969,022 | 31.241 | 1 | 0.467 | 0.015 |
| low | 359,445 | 11.588 | 0 | 0 | 0 | |
| medium | 1,050,424 | 33.865 | 18 | 8.411 | 0.248 | |
| high | 211,581 | 6.821 | 20 | 9.346 | 1.370 | |
| very high | 511,322 | 16.485 | 175 | 81.776 | 4.961 | |
| XGBoost-IV | very low | 990,492 | 31.933 | 0 | 0 | 0 |
| low | 336,805 | 10.858 | 2 | 0.935 | 0.086 | |
| medium | 968,651 | 31.229 | 28 | 13.084 | 0.419 | |
| high | 231,242 | 7.455 | 29 | 13.551 | 1.818 | |
| very high | 574,604 | 18.525 | 155 | 72.430 | 3.910 | |
| XGBoost-CF | very low | 1,000,714 | 32.262 | 1 | 0.467 | 0.014 |
| low | 391,725 | 12.629 | 0 | 0 | 0 | |
| medium | 935,183 | 30.150 | 18 | 8.411 | 0.279 | |
| high | 220,239 | 7.100 | 5 | 2.336 | 0.329 | |
| very high | 553,933 | 17.858 | 190 | 88.785 | 4.972 | |
| XGBoost-EBF | very low | 943,278 | 30.411 | 0 | 0 | 0 |
| low | 449,747 | 14.500 | 0 | 0 | 0 | |
| medium | 993,538 | 32.031 | 24 | 11.215 | 0.350 | |
| high | 200,146 | 6.453 | 28 | 13.084 | 2.028 | |
| very high | 515,085 | 16.606 | 162 | 75.701 | 4.559 | |
| XGBoost-WOE | very low | 931,095 | 30.018 | 0 | 0 | 0 |
| low | 480,175 | 15.481 | 1 | 0.467 | 0.030 | |
| medium | 900,990 | 29.047 | 18 | 8.411 | 0.290 | |
| high | 214,484 | 6.915 | 23 | 10.748 | 1.554 | |
| very high | 575,050 | 18.539 | 172 | 80.374 | 4.335 |
| TP | FN | TN | FP | TPR | TNR | Acc | F1 | KC | |
|---|---|---|---|---|---|---|---|---|---|
| RF-Initial | 213 | 1 | 209 | 5 | 99.533 | 97.664 | 98.598 | 0.986 | 0.972 |
| RF-FR | 213 | 1 | 212 | 2 | 99.533 | 99.065 | 99.299 | 0.993 | 0.986 |
| RF-IV | 212 | 2 | 214 | 0 | 99.065 | 100 | 99.533 | 0.995 | 0.991 |
| RF-CF | 213 | 1 | 212 | 2 | 99.533 | 99.065 | 99.299 | 0.993 | 0.986 |
| RF-EBF | 214 | 0 | 213 | 1 | 100 | 99.533 | 99.766 | 0.998 | 0.995 |
| RF-WOE | 212 | 2 | 212 | 2 | 99.065 | 99.065 | 99.065 | 0.991 | 0.981 |
| TP | FN | TN | FP | TPR | TNR | Acc | F1 | KC | |
|---|---|---|---|---|---|---|---|---|---|
| XGBoost-Initial | 213 | 1 | 209 | 5 | 99.533 | 97.664 | 98.598 | 0.986 | 0.972 |
| XGBoost-FR | 213 | 1 | 213 | 1 | 99.533 | 99.533 | 99.533 | 0.995 | 0.991 |
| XGBoost-IV | 212 | 2 | 214 | 0 | 99.065 | 100 | 99.533 | 0.995 | 0.991 |
| XGBoost-CF | 213 | 1 | 213 | 1 | 99.533 | 99.533 | 99.533 | 0.995 | 0.991 |
| XGBoost-EBF | 214 | 0 | 213 | 1 | 100 | 99.533 | 99.766 | 0.998 | 0.995 |
| XGBoost-WOE | 213 | 1 | 212 | 2 | 99.533 | 99.065 | 99.299 | 0.993 | 0.986 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, J.; Ren, C.; Yue, W.; Zhou, Y.; Xue, X.; Liu, Y.; Ding, C. Investigation of Landslide Susceptibility Decision Mechanisms in Different Ensemble-Based Machine Learning Models with Various Types of Factor Data. Sustainability 2023, 15, 13563. https://doi.org/10.3390/su151813563
Lu J, Ren C, Yue W, Zhou Y, Xue X, Liu Y, Ding C. Investigation of Landslide Susceptibility Decision Mechanisms in Different Ensemble-Based Machine Learning Models with Various Types of Factor Data. Sustainability. 2023; 15(18):13563. https://doi.org/10.3390/su151813563
Chicago/Turabian StyleLu, Jiakai, Chao Ren, Weiting Yue, Ying Zhou, Xiaoqin Xue, Yuanyuan Liu, and Cong Ding. 2023. "Investigation of Landslide Susceptibility Decision Mechanisms in Different Ensemble-Based Machine Learning Models with Various Types of Factor Data" Sustainability 15, no. 18: 13563. https://doi.org/10.3390/su151813563