1. Introduction
With the arrival of a new era, China’s society and economy have made significant progress, but the impact on the environment has also grown. The government’s emphasis on “green mountains and clear waters” has made water quality management a top priority. Studies show that surface water is highly susceptible to adverse sources of pollution, and the water environment system is facing many urgent problems [
1]. Accurate water quality assessments offer scientific guidance for managing, protecting, and governing water environments, as well as guiding wastewater treatment planning goals and directions [
2].
Water quality is affected by various factors such as organic pollutants, harmful by-products, pathogenic microorganisms, iron, manganese substances, and ammonia nitrogen pollutants. To determine the water quality grade, parameters such as ammonia nitrogen content, dissolved oxygen, permanganate content, total phosphorus, and total nitrogen are usually measured [
2]. Currently, water quality assessment methods using physical and chemical factors can be divided into a single-factor evaluation and a multi-factor comprehensive evaluation. The single-factor evaluation method is simple to use and has low uncertainty. However, it is too narrow to fully evaluate water quality [
2,
3,
4,
5]. Dimensionless processing techniques, such as maximum value, mean value, and normalization, are used to process data. However, these methods are susceptible to the influence of extreme values and are not suitable for areas with poor water quality. Some researchers use multi-factor comprehensive evaluation methods such as grey relational degree analysis [
6], artificial neural network [
7,
8], and support vector machine [
9,
10].
Scholars have improved traditional methods by standardizing the processing of raw data in a dimensionless way, making them less susceptible to the influence of extreme values. They have also rewritten the absolute difference formula to increase the calculation accuracy by using a point-to-interval form. However, these methods are subjective and cannot effectively solve the one-sidedness of the evaluation. Esakkimuthu Tharmar used principal component analysis (PCA) to find out the dominant factors of the overall water quality and its variance coverage [
11]. Neural networks excel in solving nonlinear problems and can approximate nonlinear functions with sufficient training data. The backpropagation (BP) neural network is one of the most basic and widely used in neural networks today [
10]. Applying the BP neural network to water quality evaluations, we analyzed the main factors affecting water quality changes. Compared with the comprehensive index evaluation method, the BP neural network evaluation process is more convenient and the evaluation results are more objective. However, the BP neural network is limited by the convergence speed and may fall into local minimum values. Additionally, when the sample data is small, the error is larger [
3,
7,
12,
13]. Yang Cheng et al. partly solved the problem of traditional methods easily falling into local minimums and enhanced system robustness by using the T-S fuzzy neural network model [
14]. However, the convergence speed and prediction accuracy are still insufficient. Chen Yaoning et al. evaluated and predicted the water quality of Baiyun Lake using the support vector machine method, which has good generalization and extrapolation capabilities and can solve the water quality evaluation accuracy problem well [
15]. However, it is greatly restricted in convergence speed when facing large-scale data training, and the selection of kernel parameters and penalty factors seriously affects the classification accuracy of the support vector machines. Ref. [
16] proposed to use machine learning to predict groundwater quality. Different machine learning methods had good results for different parameters, but no machine learning algorithm had good results for all parameters. Rongli Gai and Zhibin Guo [
17] proposed an improved grey relational degree method and particle swarm optimization multi-classification SVM algorithm to evaluate river water quality. Hítalo Tobias Lôbo Lopes used a nonlinear model to predict data, but the accuracy rate was not high [
18]. Firstly, the correlation indexes of factors affecting the water quality were extracted, and the four indexes with the greatest correlation were found as the input of the particle swarm optimization multi-classification SVM algorithm to evaluate the quality of the river water environment. Although this algorithm can ignore the influencing factors with little correlation, it also ignores the essential characteristics of some original data in this process, which may cause deviations in specific working conditions.
In view of the limitations of the methods proposed in the above papers, this paper improved the model training speed and prediction accuracy. The innovation points are summarized as follows: 1. Aiming at the problem of geometric increase of training time caused by an excessive training set of the SVM model, the concept of Pareto optimal solution is put forward to sparse training set data, which can improve the training speed without affecting the prediction accuracy. 2. The selection of kernel parameters and penalty factors of SVM will affect the classification accuracy of the support vector machine. To solve the problem of the difficult selection of hyperparameters, a particle swarm optimization algorithm is used in this paper to select the hyperparameters and improve the accuracy of the model. By accurately assessing the water quality classification, the degree and source of water pollution can be accurately assessed, the sources of water pollution can be discovered and eliminated in time, and the water resources and ecological environment can be effectively protected, thus promoting environmental protection. At the same time, an accurate water quality assessment method can improve the utilization efficiency of water resources, ensure the supply quality of water resources, and improve the green technology and cost-effectiveness of environmental governance, so as to achieve sustainable development.
3. Results
To verify the effectiveness and reliability of the CPOS-SVM model in water quality prediction, this study used the water quality monitoring data from the Ming Cui Wetland Park in Yinchuan, Ningxia Hui Autonomous Region, from 2014 to 2021 as the research object. To ensure the cognitive and generalization abilities of the trained network, while taking into account both the commonality and individuality of the samples, the study used the different methods between adjacent water quality standards of two categories in the national “Surface Water Environmental Quality Standard” to obtain sample data. A total of 620, 1020, 1520, and 2020 sets of sample data were generated, including 140, 540, 1040, and 1540 sets of data, respectively. The sample data were randomly divided into a test set and a training set. Among them, 50 sets of monitoring data and 100 sets of randomly selected generated sample data were used as a test set to detect the accuracy of the trained model, and the remaining data were used as a training set to train the model.The specific data division is shown in
Table 2. In order to demonstrate the superiority of the proposed algorithm, CPOS-SVM, POS-SVM, POS-BP, and SVM were compared with different model parameter settings. The parameter Settings of the above four algorithms shown in “Algorithm 1, Algorithm 2, Algorithm 3 and Algorithm 4”.
Table 2.
Training model data partitioning.
Table 2.
Training model data partitioning.
| Number of Data Sets | Number of Training Sets | Number of Test Set Groups |
|---|
| 620 groups | 470 | 150 |
| 1020 groups | 870 | 150 |
| 1520 groups | 1370 | 150 |
| 2020 groups | 1870 | 150 |
| Algorithm 1: Using Pareto solutions to sparsify the sample data as the training samples, with a population size of N = 10, a maximum iteration number of T = 200, learning factors = 2, a search range of [−6,6], and control parameters k1 = k2. |
| Algorithm 2: Without sparsifying the sample data, with a population size of N = 10, a maximum iteration number of T = 200, learning factors = 2, a search range of [−6,6], and control parameters k1 = k2. |
| Algorithm 3: With a population size of N = 10, a maximum iteration number of T = 200, learning factors = 2, a search range of [−6,6], control parameters k1 = k2, an input layer node of 5, a hidden layer node of 10, an output layer node of 1, and a maximum training number of 1000 for BP neural network. The transfer functions for the hidden layer and output layer are logsig and purelin, the training function is trainlm, the learning rate is 0.01, and the training error target is 0.001. |
| Algorithm 4: Directly assigning c = 0.5 and g = 3.48 obtained from Algorithm 1 via particle swarm optimization as the penalization factor and kernel function interval for the SVM algorithm. |
The different algorithms were run five times, and the average of the running time and the results on the water quality prediction test set were taken as the final results, as shown in
Figure 5 and
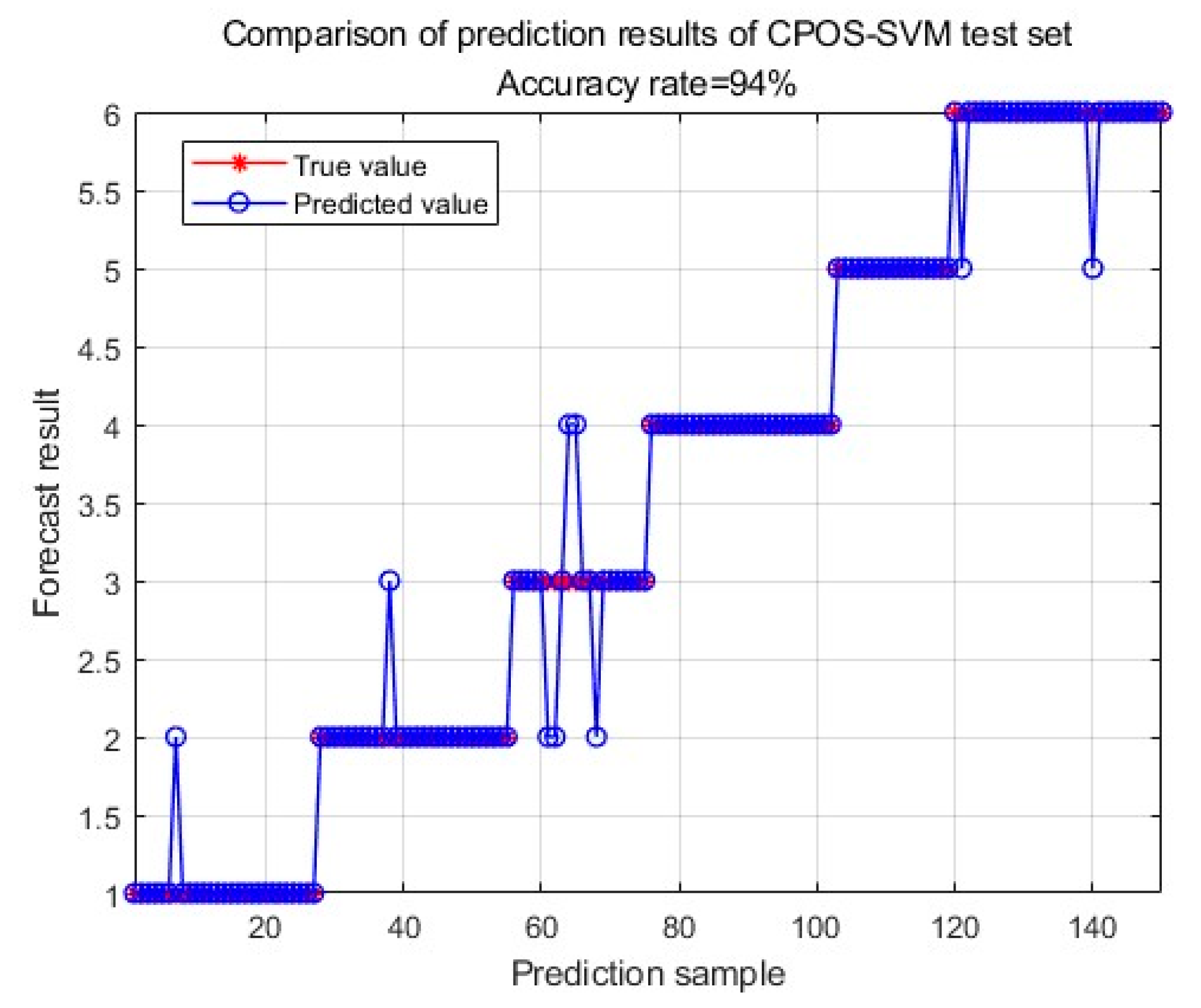
Figure 6. Meanwhile, the comparison between the predicted data and the real data of the best test set results of the four algorithms on the 1020 data sets were given in
Figure 7,
Figure 8,
Figure 9 and
Figure 10.
The computational time varies greatly among the models, with SVM being the fastest due to its parameters being directly given and not requiring the POS algorithm to search. The second fastest is the CPOS-SVM algorithm, which requires data preprocessing when the data set is relatively small. Since there are not many redundant data to be removed, its advantage is not obvious. However, when the data set increases, after data preprocessing and removing excess data, the sample data size is reduced, which only slightly increases the running time. On the other hand, the running time of the other algorithms is relatively long due to the increase in data volume.
In terms of accuracy, the CPOS-SVM model and the POS-SVM model have almost the same accuracy as SVM, which suggests that sparsifying the training set with Pareto optimal solutions does not lead to a loss of the original data features and can fully preserve the characteristics of the data. As the original data increases, the accuracy of the models increases significantly, especially for the POS-BP model. The accuracy of the CPOS-SVM model is better than that of the POS-BP model on both the training set and the test set, which indicates that the CPOS-SVM model has stronger stability and robustness in the water quality evaluation.
Figure 7,
Figure 8,
Figure 9 and
Figure 10 respectively show the specific classification results of the CPOS-SVM, POS-SVM, POS-BP, and SVM algorithms. It can be seen from the figures that the SVM algorithm has the highest accuracy, which is because the SVM algorithm has not undergone data sparsity processing and retains all features of the original data. However, it can be seen from
Figure 5 that its training time is greatly increased. The accuracy of the CPOS-SVM algorithm is slightly affected, but the training speed is greatly improved. This is because the characteristics of the original data are not affected when the CPOS-SVM algorithm is sparse, while the POS-SVM and POS-BP algorithms have advantages in both accuracy and training speed.
4. Conclusions
In this paper, the concept of Pareto optimal solution is used to sparsely process the training data, which greatly improves the operation speed while preserving the characteristics of the original data. To solve the problem of the difficult selection of the kernel parameters and the penalty coefficient of the SVM algorithm, particle swarm optimization was proposed to improve the accuracy of the model. Taking the water quality test data of Ming Cui Lake from 2014 to 2021 as the research object, model parameters of different algorithms were set, and the POS-SVM model, POS-BP model, and SVM model were compared. The results show that the training time of this model is the shortest, only 2 s, and does not slow down with the increase of data volume. The prediction accuracy is about 94%, which proves that the algorithm has a high application value.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









